Python爬虫之破解百度翻译--requests案例详解
Posted 梦子mengy7762
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫之破解百度翻译--requests案例详解相关的知识,希望对你有一定的参考价值。
们通过requests模块讲了简单的网页采集方法,这一节课我们讲一下怎么用requests模块破解百度翻译。其中包含的知识点有post请求、Jason、异步加载等内容。这节课由于信息量比较大,所以分两节课介绍:
一、主要提取的内容
我们通过输入一次词,将翻译的结果部分(如下图)提取出来

** **
二、爬取步骤解析
第一步,首先导入requests模块

第二步,分析页面
**
**
1.我们在输入词语的时候,我们会发现翻译结果随之就加载出来了,不像我们上节课在浏览器搜索的时候,需要回车才能够出来,因此我们就引出了一个概念–ajax异步加载
2.ajax异步加载是什么?

3.查看方式发生变化
因为ajax异步加载,我们不能再像以前一样查看数据了(如下图),我们不再是查看network下面的全部数据,我们选择network-xhr下的数据,我们通过查看xhr预览选项发现,v2tranapi文件下的数据是我们想要的,因此我们xhr-v2tranapi–表头进入,查找我们想要的数据。最后,如果你的时间不是很紧张,并且又想快速的提高,最重要的是不怕吃苦,建议你可以联系维:762459510 ,那个真的很不错,很多人进步都很快,需要你不怕吃苦哦!大家可以去添加上看一下~

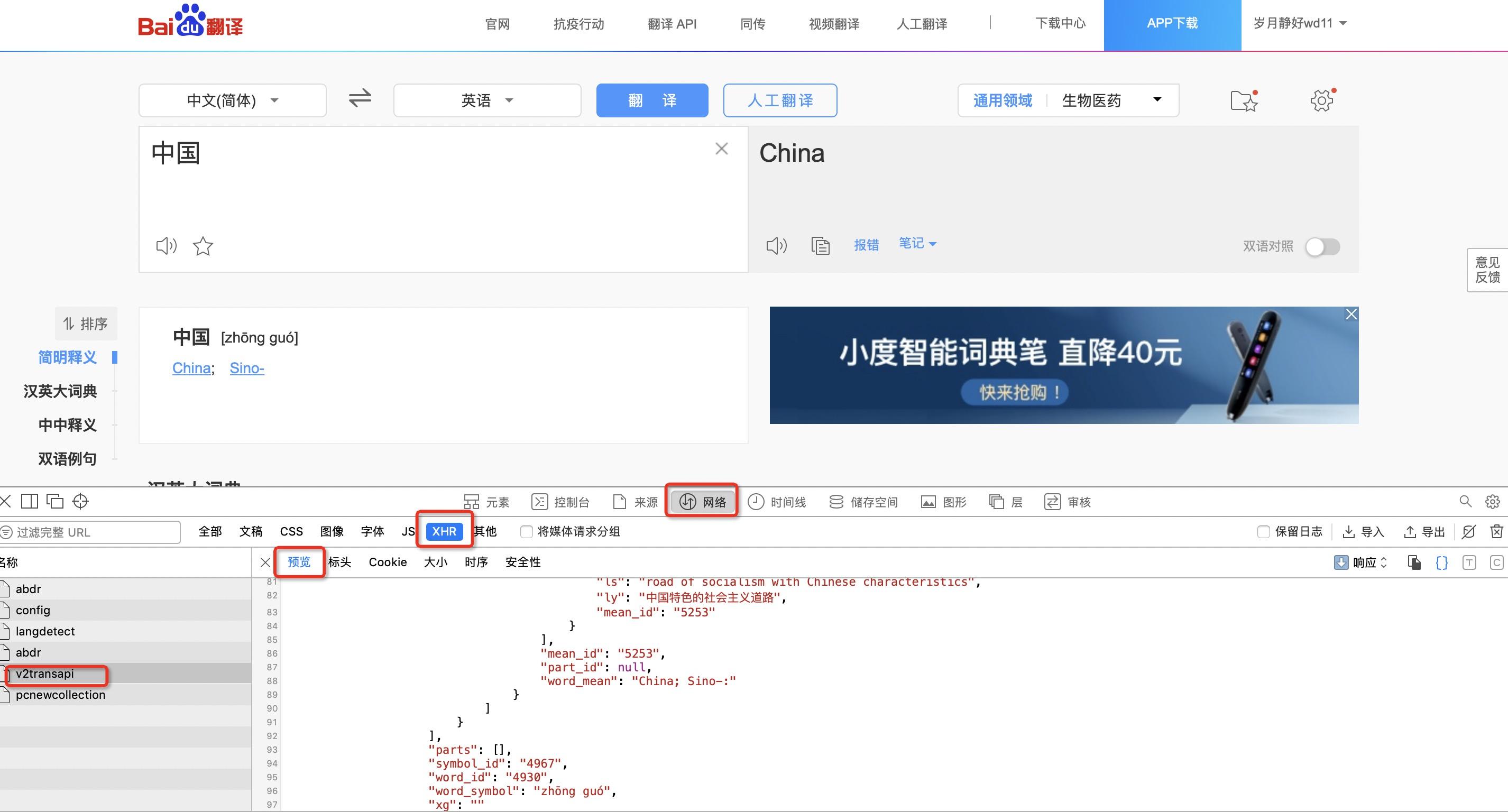
注意:之前用的是谷歌浏览器查看数据,这次用的苹果自带浏览器查看,如果用不习惯可以和谷歌位置对照使用!
分析完了数据,下节课我们就来正式书写代码
以上是关于Python爬虫之破解百度翻译--requests案例详解的主要内容,如果未能解决你的问题,请参考以下文章
Python爬虫实战,破解百度翻译JS加密,制作桌面翻译工具