爬虫案例之网易有道翻译Python代码改写
Posted Dream-Z
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫案例之网易有道翻译Python代码改写相关的知识,希望对你有一定的参考价值。
网易有道翻译之逆向破解[Python代码改写]
***用到的知识点:
(1)requests模块和session模块,发起请求
- 什么是session对象?
- 该对象和requests模块用法几乎一致.
- 对于在请求过程中产生了cookie的请求
- 如果该请求是使用session发起的,则cookie会被自动存储到session中.
session = requests.Session()
(2)headers头部伪装,随机UA伪装
# UA伪装之随机headers模块
from fake_useragent import UserAgent
headers = \'User-Agent\': UserAgent().random, # 这里的random方法不需要random模块支持
(3)md5加密算法,加密数据
# md5加密模块
from hashlib import md5
# 如果需要十六进制的结果与二进制的结果之间的转换,需要的模块
import binascii
# 【1】准备数据
data = \'你好\' #这里是字符串类型
# 字符串转二进制数据方式一
encode_data = s.encode()
# 字符串转二进制数据方式二
encode_data = b\'你好\'
# 【2】数据加密
# 构建md5对象
md5_obj = md5()
# 将数据更新到md5算法中进行数据加密 (参数为二进制数据的明文数据)
#(方法一):直接在加密算法中进行转码
md5_obj.update("你好".encode("utf-8"))
md5_obj.update(data.encode("utf-8"))
#(方法二):先将明文数据进行转码,再传入到加密算法中
md5_obj.update(encode_data)
# 【3】数据提取
# 拿到加密字符串 # 十六进制的结果
result_16 = obj.hexdigest()
# 拿到加密字符串 # 二进制的结果
result_2 = obj.digest()
# 拿到加密字符串 # 十六进制的结果与二进制的结果之间的转换 (参数为result_16 或 result_2)
result_change = binascii.unhexlify(result_16)
(4)AES加密算法,解密部分
# 从算法模块中导入AES加密算法
from Crypto.Cipher import AES
# 导入base64编码模块
import base64
# --------【一】解密部分解释--------#
# (1)将base64数据进行解码
# 先将base64数据解码
base_data = final_data
# encrypt_data = base64.b64decode(这里的数据是二进制数据)
encrypt_data = base64.b64decode(base_data.encode())
# 因为base64编码前就需要转换为二进制数据,所以下面的解码部分转换出来的也是二进制数据
# (2) 重新生成aes对象,将密文数据进行解密
# 声明key:key的长度必须是16的倍数且key为二进制数据(即转码)
key = b\'1314521131452121\'
# 声明iv:iv是CBC模式特有的参数,为数据偏移量,iv的长度必须是16的倍数且iv为二进制数据(即转码)
iv = b\'8384582838458221\'
# 创建aes对象 aes对象 = AES.new(必须参数key, 密文加密模式, 数据偏移量)
aes = AES.new(key, AES.MODE_CBC, iv)
# (3)解密
# 因为base64编码前就需要转换为二进制数据,所以解码部分解出来的也是二进制数据
# 解密后的密文变量名 = aes.decrypt(需要解密的二进制密文数据)
plain_data = aes.decrypt(encrypt_data)
(5)base64编码,解码、base64变种
# # ########### ----------------【部分一:base64解码】 ---------------- ###########
# # ########### ----------------(方法一) ---------------- ###########
# 观察发现base64编码后的数据不是标准的base64编码,存在变种,\'-\', \'/\' --- \'_\', \'+\' 将变种编码转换为标准编码
# standard_base64_data = ret.replace(\'-\', \'/\').replace(\'_\', \'+\')
# # 将标准的base64编码数据进行解码
# decode_base64_data = base64.b64decode(standard_base64_data.encode())
# ########### ----------------(方法二) ---------------- ###########
# 观察发现base64编码后的数据不是标准的base64编码,存在变种,\'-\', \'/\' --- \'_\', \'+\' 调用base64内部自带的标准化方法,将变种编码转换为标准编码并解码
# altchars=b"-_" 参数为需要替换的变种编码
standard_base64_data = base64.b64decode(ret.encode(), altchars=b"-_")
(6)json模块,序列化与反序列化
dataDict = json.loads(decrypt_data.decode())
(7)pad和unpad模块,补全数据长度,去除不必要的数据长度
# pad:模块(填充数据长度)
from Crypto.Util.Padding import pad, unpad
# 以16进制去除解密数据中可能会填充的数据
decrypt_data = unpad(decrypt_data, 16)
详见博客:
【一】分析网站
- 网站主页

- 打开开发者模式进行抓包分析

- 一共抓到了三个包,逐个分析抓到的包里,我们可以发现
- 第一个包的请求方式为post请求
- 且载荷中带着一系列的数据

- post请求所携带的数据data
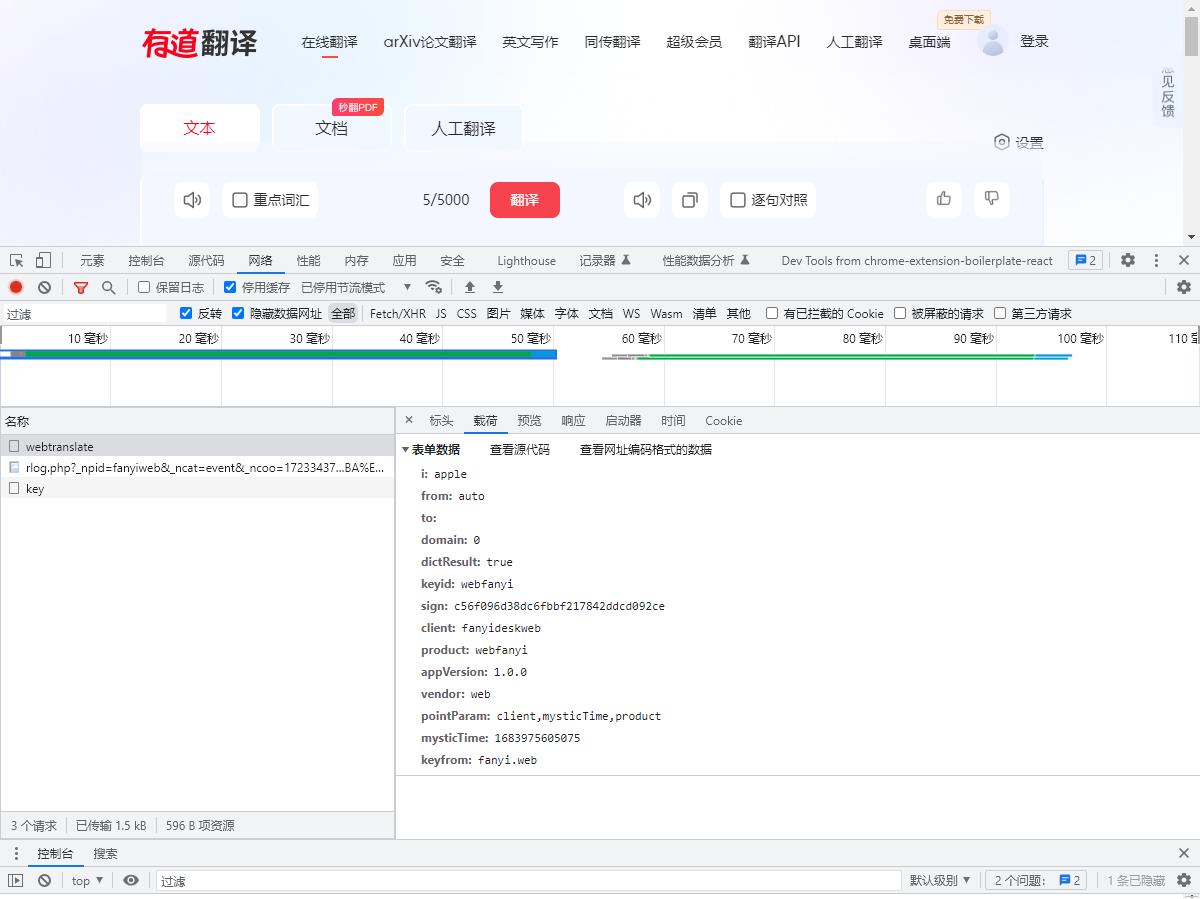
i: apple
from: auto
to:
domain: 0
dictResult: true
keyid: webfanyi
sign: c56f096d38dc6fbbf217842ddcd092ce
client: fanyideskweb
product: webfanyi
appVersion: 1.0.0
vendor: web
pointParam: client,mysticTime,product
mysticTime: 1683975605075
keyfrom: fanyi.web
-
从上述分析以及再次抓包可以发现:
- i : 是我们输入的值
- sign:每次都会发生变化
- 可能是有加密算法进行加密返回
- mysticTime:每次都会发生变化
- 根据经验和验证知道这是时间错
-
再观察返回的response数据可以发现是一堆字符
- 通过观察可以发现,是base64编码返回的结果
- 并且可以发现,其不是标准的base64编码的数据,而是进行了变种
Z21kD9ZK1ke6ugku2ccWu-MeDWh3z252xRTQv-wZ6jddVo3tJLe7gIXz4PyxGl73nSfLAADyElSjjvrYdCvEP4pfohVVEX1DxoI0yhm36ytQNvu-WLU94qULZQ72aml6JKK7ArS9fJXAcsG7ufBIE0gd6fbnhFcsGmdXspZe-8 whVFbRB_8Fc9JlMHh8DDXnskDhGfEscN_rfi-A-AHB3F9Vets82vIYpkGNaJOft_JA-m5cGEjo-UNRDDpkTz_NIAvo5PbATpkh7PSna2tHcE6Hou9GBtPLB67vjScwplB96-zqZKXJJEzU5HGF0oPDY_weAkXArzXyGLBPXFCnn_IWJDkGD4vqBQQAh2n52f48GD_cb-PSCT_8b-ESsKUI9NJa11XsdaUZxAc8TzrYnXwdcQbtl_kZGKhS6_rCtuNEBouA_lvM2CbS7TTtV2U4zVmJKpp-c6nt3yZePK3Av01GWn1pH_3sZbaPEx8DUjSbdp4i4iK-Mj4p2HPoph67DR7B9MFETYku_28SgP9xsKRRvFH4aHBHESWX4FDbwaU=
【二】逆向处理一
【1】包的分析处理
-
首先,我们知道这个请求的网站是:
-
返回的数据也是从这个网站返回的
-
那么,所有的请求和加密操作一定会经过这个网站的调用
-
以此为关键点,我们进行关键字搜索
即在开发者模式搜索 webtranslate 关键字
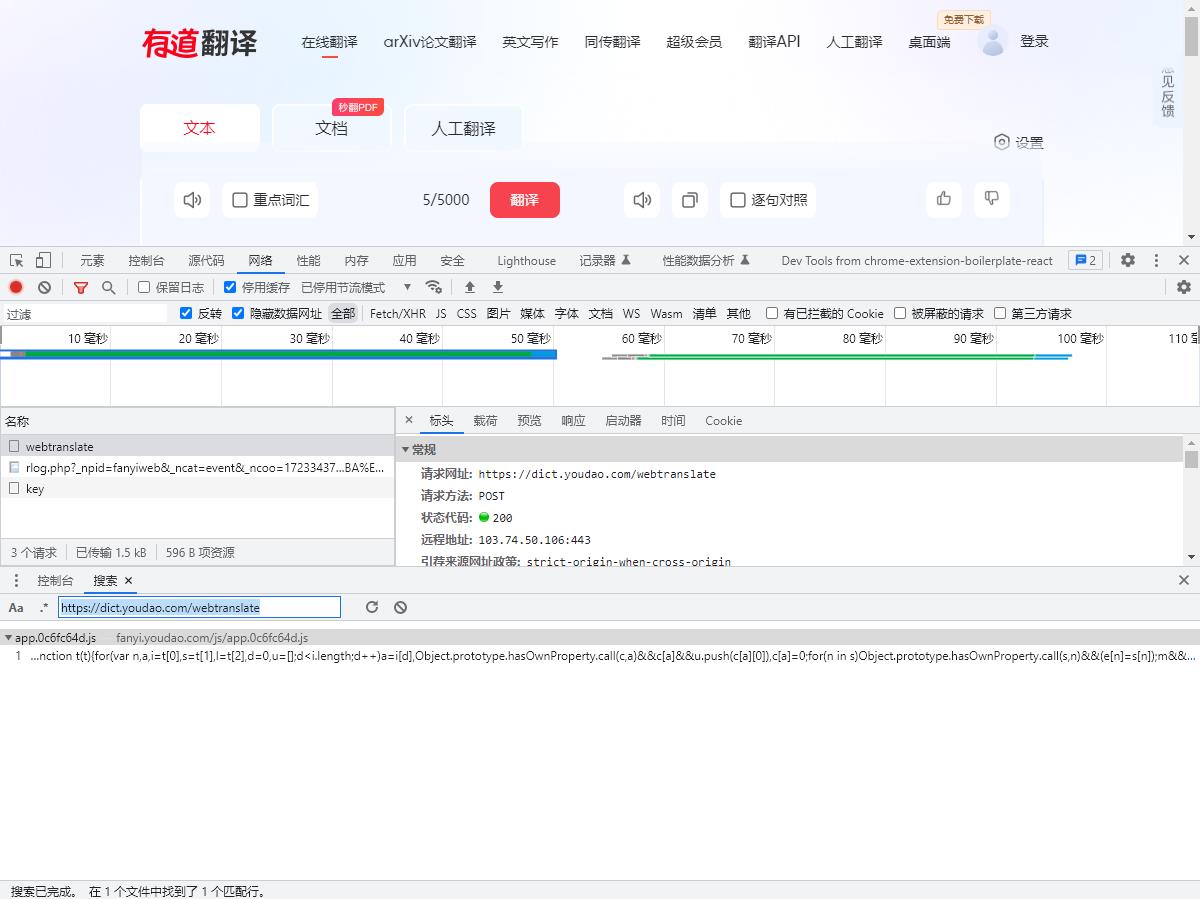
- 得到搜索结果,该结果就是调用此网址的一个函数位置
- 我们进入到这个函数里面

-
我们可以清楚地看到,在函数的内部存在我们请求的网址
-
在该位置打上断点,重新发起请求
- 如果被断住,则是我们想要的数据位置
- 如果没被断住,则二次请求,查看其他位置
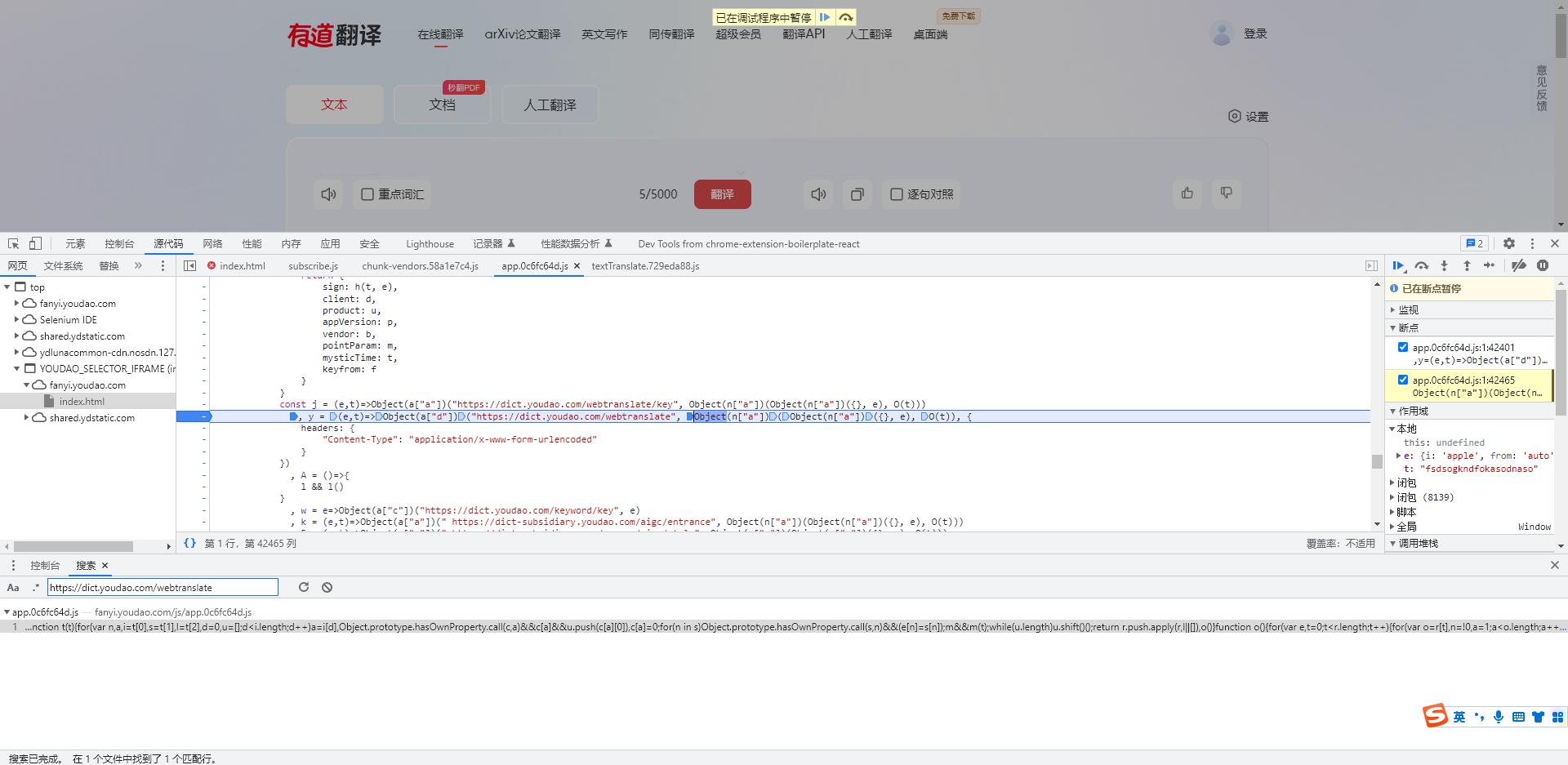
- 在该位置被断住
- 在控制台,输入各个函数或参数即可查看这个参数的结果
- 通过分析这行代码
y = (e,t)=>Object(a["d"])("https://dict.youdao.com/webtranslate", Object(n["a"])(Object(n["a"])(, e), O(t)),
headers:
"Content-Type": "application/x-www-form-urlencoded"
)
-
我们可以发现
-
"https://dict.youdao.com/webtranslate"
- 这个参数是我们请求的网址
-
Object(n["a"])(Object(n["a"])(, e), O(t))
- 这个参数是一个函数调用,我们在控制台将这行代码进行打印查看结果
-

-
我们发现其返回的结果正是我们刚才data数据的一部分
i: \'apple\', from: \'auto\', to: \'\', domain: \'0\', dictResult: true, … appVersion: "1.0.0" client: "fanyideskweb" dictResult: true domain: "0" from: "auto" i: "apple" keyfrom: "fanyi.web" keyid: "webfanyi" mysticTime: 1683977202745 pointParam: "client,mysticTime,product" product: "webfanyi" sign: "77ca196b587d32de00b9b249153ed901" to: "" vendor: "web"
-
【2】sign 值 和 t 值的逆向
-
事实证明,我们没有选错位置
- 我们也可以在控制台查看其他参数的结果
-
通过分析发现 O 函数正是我们想要找的函数

-
我们在 O 函数处打上断点,再次进行请求
-
将鼠标悬浮在 O 函数上,进入到其调用函数里面

- 进入到函数调用处

-
我们可以看到,这里有一个t变量的声明
-
且这个赋值函数正是时间函数,也就是时间戳
-
这里我们将其用Python代码改写
# 构建时间戳,参照逆向,可发现其时间戳为13位,所以要 *1000 。时间戳为整数类型,所以要int mysticTime = int(time.time() * 1000)
-
-
我们向下看,则可以发现,sign 值正是由 h 函数生成
-
同样的方法,我们进入到函数 h 中,分析其代码

- 进入到 h 函数

-
观察发现,需要两个参数,一个参数是 t ,另一个参数是 e
-
这里我们进入到这个断点的函数,观察其生成值
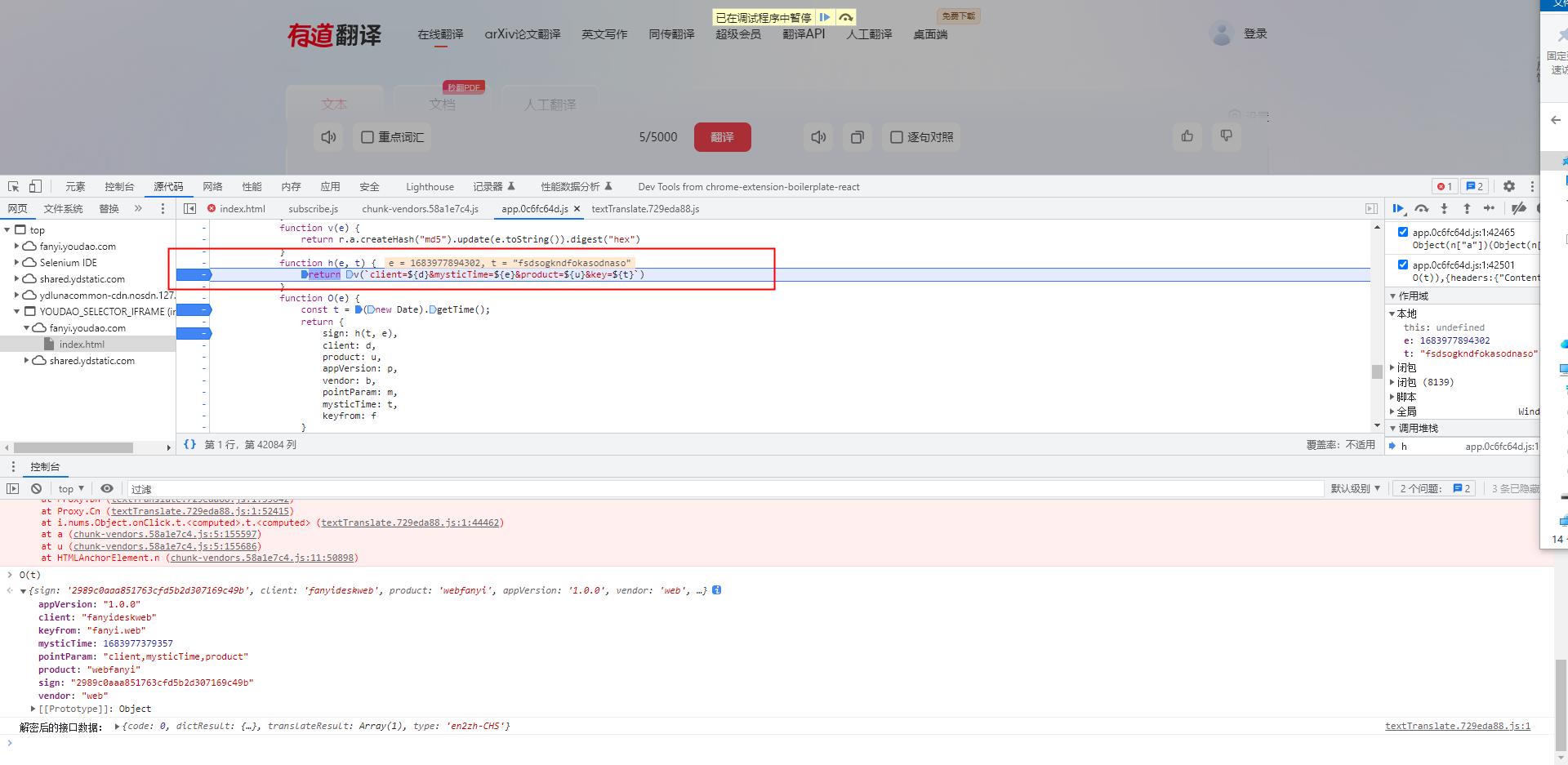
-
我们可以看到传入的值
e : 1683977894302 t : fsdsogkndfokasodnaso -
再次发起请求,观察这两个值是否会发生变化
- 发起请求后发现,e发生了变化正是时间戳
- t没有发生变化,是定值
-
分析这个js代码,h 函数的方法是什么
v(`client=$d&mysticTime=$e&product=$u&key=$t`) # 这段函数其实是ES6的语法,类似于Python中的 name = \'dream\' age = 22 ptint(f\'你好,我叫name,我今年\') #而在ES6语法中相当于 consolo.log(`你好,我叫$name,我今年$name`) -
由此我们知道,其返回的正式一段文本字符串,我们在控制台打印这段函数调用,查看其结果

`client=$d&mysticTime=$e&product=$u&key=$t`
\'client=fanyideskweb&mysticTime=1683977894302&product=webfanyi&key=fsdsogkndfokasodnaso\'
-
由此,我们用Python代码改写生成
# 构建时间戳,参照逆向,可发现其时间戳为13位,所以要 *1000 。时间戳为整数类型,所以要int mysticTime = int(time.time() * 1000) # 逆向可知sign值得构建中,这个参数为固定值 # 固定值 key key = \'fsdsogkndfokasodnaso\' # 构建 sign_before , 未加密之前的明文数据 sign_before = f\'client=fanyideskweb&mysticTime=mysticTime&product=webfanyi&key=key\' -
有上面分析的 js 代码可知
-
h 函数的最终返回值为
return v(`client=$d&mysticTime=$e&product=$u&key=$t`) -
那下一步,我们就要查看这个参数传进去的 v 函数的调用关系及返回结果
-
同样的方法,我们悬浮进入 v 函数
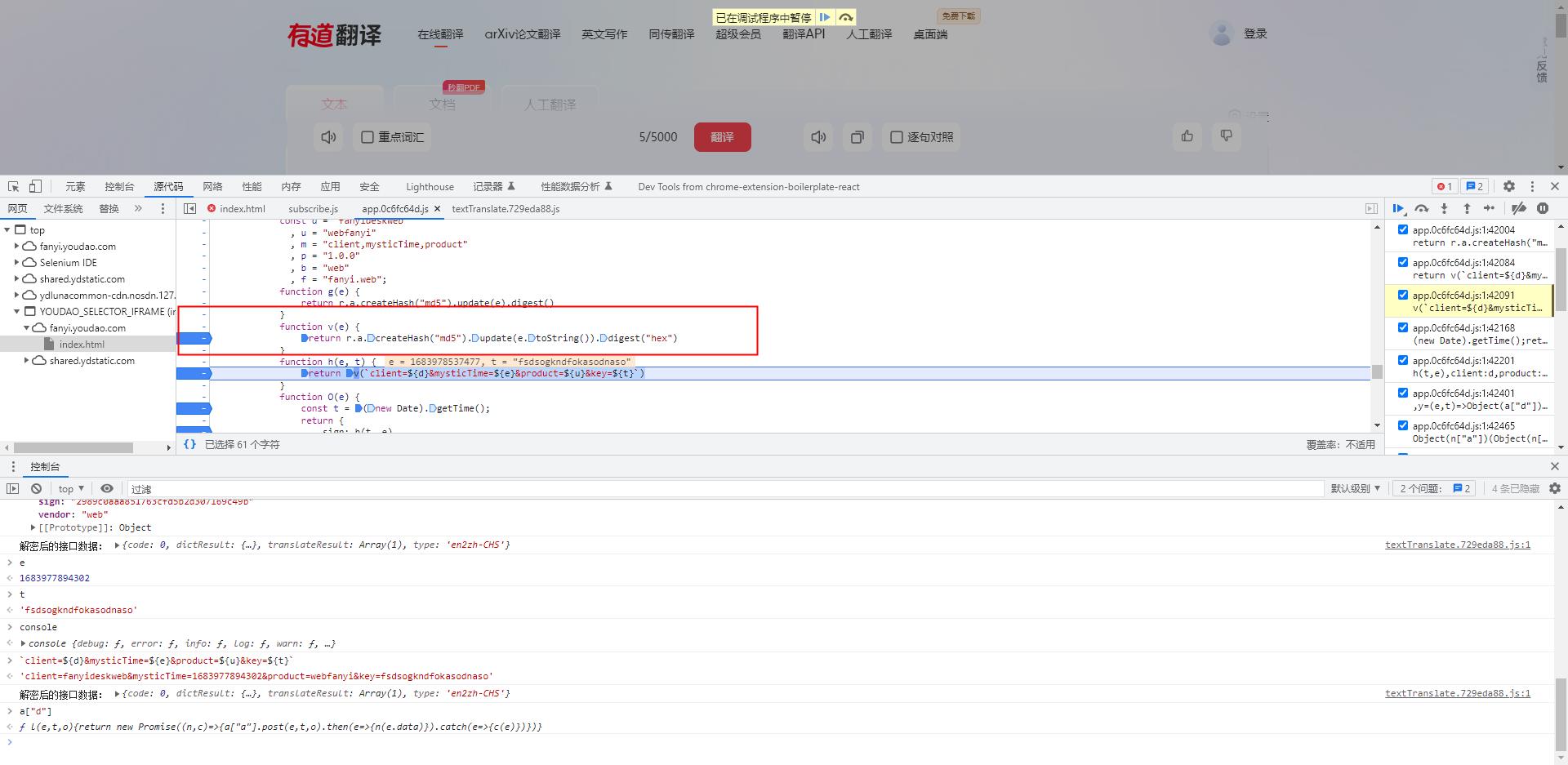
-
可以看到我们的 v 函数正是,其上面的代码部分
function v(e) return r.a.createHash("md5").update(e.toString()).digest("hex") -
其中的参数e就是我们刚才生成的一串字符串
-
分析这段代码,我们不难看出,这正是一个md5加密,并且返回的是其16进制的字符串
-
我们这里用Python代码进行改写
# 构建 md5对象 alg = md5() # 将数据进行更新加密 alg.update(sign_before.encode("utf-8")) # 获取加密数据中心的hex值 sign = alg.hexdigest() -
至此我们的 sign 值和 t 值 就已经完全逆向出来了
-
总结:
- 首先要根据关键字,找到根源
- 接着要根据这个关键字所在的函数找到其参数生成的位置以及参数的调用关系
- 通过值得比较和调用关系的确定,进入到相应的调用函数中
- 分析其代码生成的方式
- 最后根据我们的知识对其进行逆向
- 最后得到我们想要的结果
【3】sign 值 和 t 值的获取
def get_sign():
\'\'\'
word:需要传入的单词/句子
# 逆向获取到时间戳和sign值
:return: 返回获取到md5加密值
\'\'\'
# 构建session对象:携带cookie,防止cookie过期
session = requests.Session()
# 有道翻译对应的主网址
main_url = \'https://dict.youdao.com/webtranslate\'
# headers 请求头
headers =
\'Accept\': \'application/json, text/plain, */*\',
\'Accept-Encoding\': \'gzip, deflate, br\',
\'Accept-Language\': \'zh-CN,zh;q=0.9,en;q=0.8\',
\'Cache-Control\': \'no-cache\',
\'Connection\': \'keep-alive\',
\'Content-Length\': \'239\',
\'Content-Type\': \'application/x-www-form-urlencoded\',
\'Host\': \'dict.youdao.com\',
\'Origin\': \'https://fanyi.youdao.com\',
\'Pragma\': \'no-cache\',
\'Referer\': \'https://fanyi.youdao.com/\',
\'Sec-Fetch-Dest\': \'empty\',
\'Sec-Fetch-Mode\': \'cors\',
\'Sec-Fetch-Site\': \'same-site\',
\'Cookie\': \'OUTFOX_SEARCH_USER_ID=-2102182500@10.110.96.154; OUTFOX_SEARCH_USER_ID_NCOO=1723343714.3489342; YOUDAO_MOBILE_ACCESS_TYPE=0\',
\'User-Agent\': UserAgent().random,
# 构建sign值和时间戳
# 构建时间戳,参照逆向,可发现其时间戳为13位,所以要 *1000 。时间戳为整数类型,所以要int
mysticTime = int(time.time() * 1000)
# 逆向可知sign值得构建中,这个参数为固定值
# 固定值 key
key = \'fsdsogkndfokasodnaso\'
# 构建 sign_before , 未加密之前的明文数据
sign_before = f\'client=fanyideskweb&mysticTime=mysticTime&product=webfanyi&key=key\'
# 进行编码,转为二进制数据
sign_encode = sign_before.encode(\'utf-8\')
# 构建 md5对象
alg = md5()
# 将数据进行更新加密
alg.update(sign_before.encode("utf-8"))
# 获取加密数据中心的hex值
sign = alg.hexdigest()
# 构建 post 请求所需要的data参数
word = input(\'请输入内容:\')
data =
\'i\': word, # 传入的参数(单词/句子)
\'from\': \'auto\',
\'to\': \'\',
\'dictResult\': \'true\',
\'keyid\': \'webfanyi\',
\'sign\': sign, # sign值 -- md5加密
\'client\': \'fanyideskweb\',
\'product\': \'webfanyi\',
\'appVersion\': \'1.0.0\',
\'vendor\': \'web\',
\'pointParam\': \'client,mysticTime,product\',
\'mysticTime\': mysticTime, # --- 时间戳生成
\'keyfrom\': \'fanyi.web\',
# 发送请求,获取到加密的base64编码返回结果
response = session.post(url=main_url, headers=headers, data=data)
ret = response.text
# 返回数据,等待下一步调用
return ret
【二】逆向处理二
【1】承上启下
- 从上面我们进行逆向,返回的结果就是我们响应中的base64变种编码数据
- 接下来我们需要进行的操作就是将base64编码数据进行解码
- 我们知道,我们的base64编码解码后的数据也不是明文数据,一定还存在加密算法
- 所以我们接下来的就是进行解码和解密
【2】js 代码分析
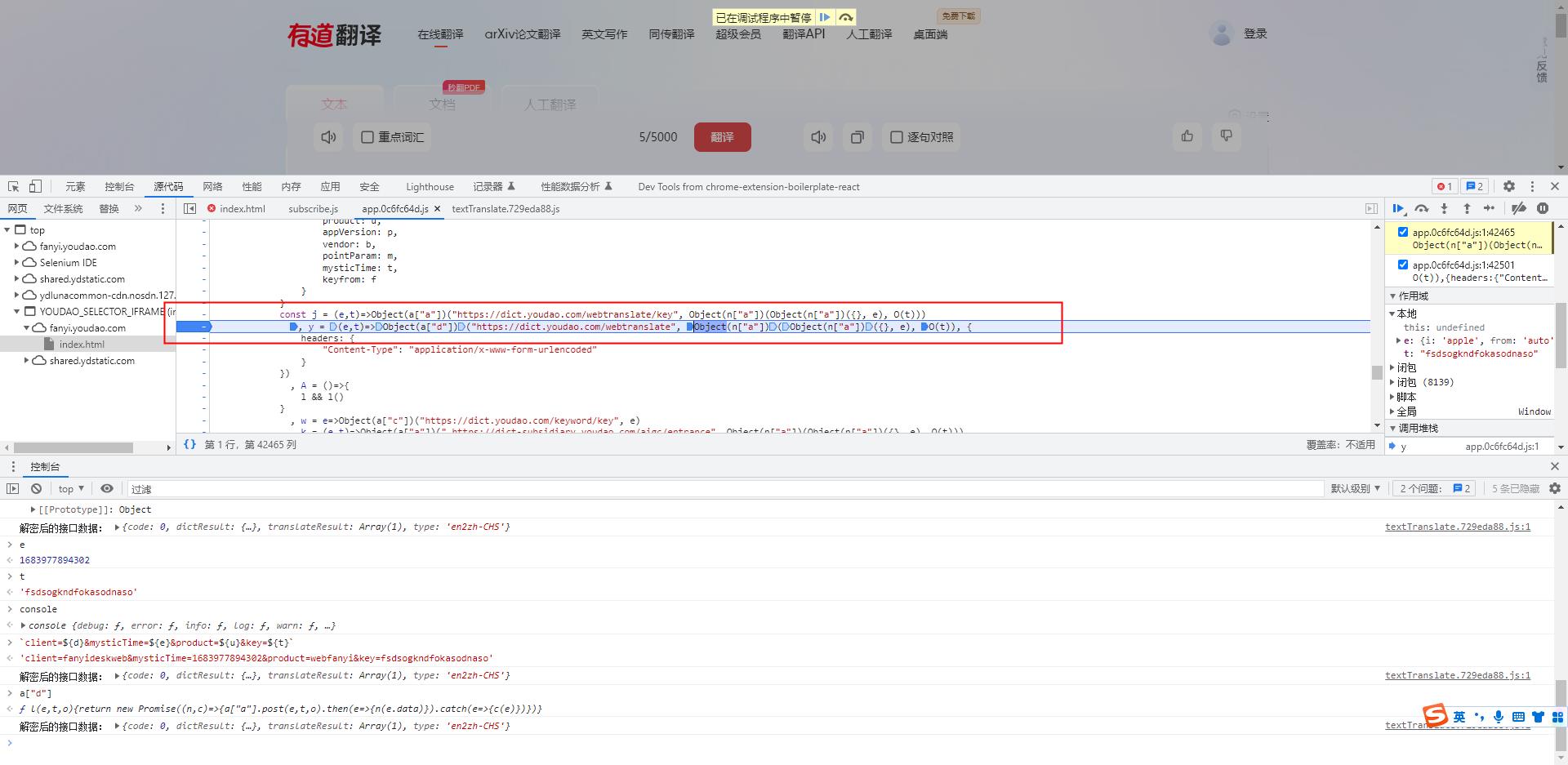
-
再次回到我们这个网址调用的地方,我们知道这个函数就是将我们的数据发送到这网站,并携带一定的请求头
-
那我们只需要找到这个参数到底是被传入到那个函数进行调用,我们就知道了解密的位置
-
通过观察这行js代码,我们分析得到
y = (e,t)=>Object(a["d"])("https://dict.youdao.com/webtranslate", Object(n["a"])(Object(n["a"])(, e), O(t)), headers: "Content-Type": "application/x-www-form-urlencoded" ) -
最后调用的函数是
Object(a["d"]) -
同样的方法我们进入到这个函数
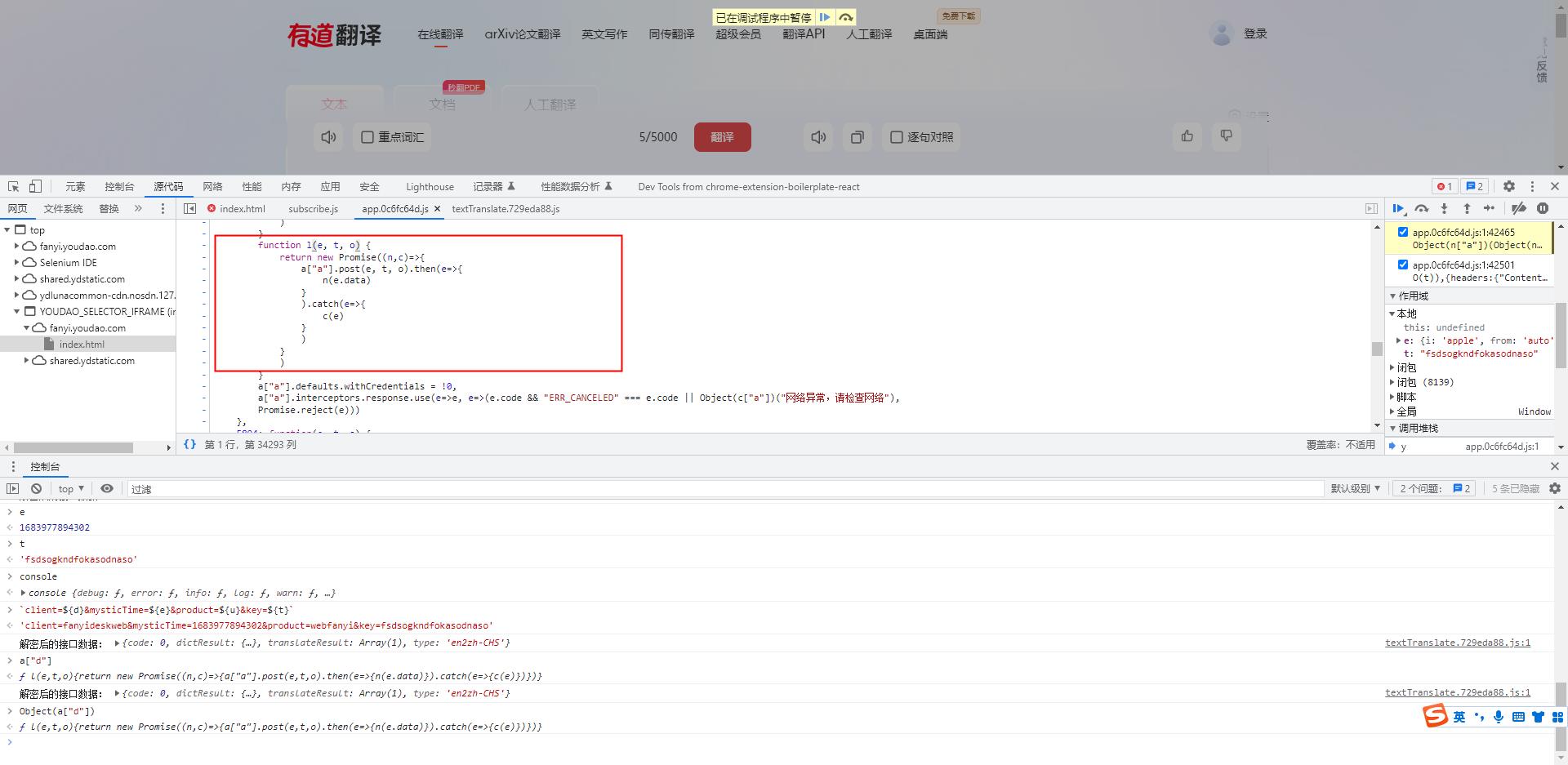
-
分析这段 js 代码
function l(e, t, o) return new Promise((n,c)=> a["a"].post(e, t, o).then(e=> n(e.data) ).catch(e=> c(e) ) ) -
我们可以知道
- Promise 函数是 JS 函数中的一个回调函数
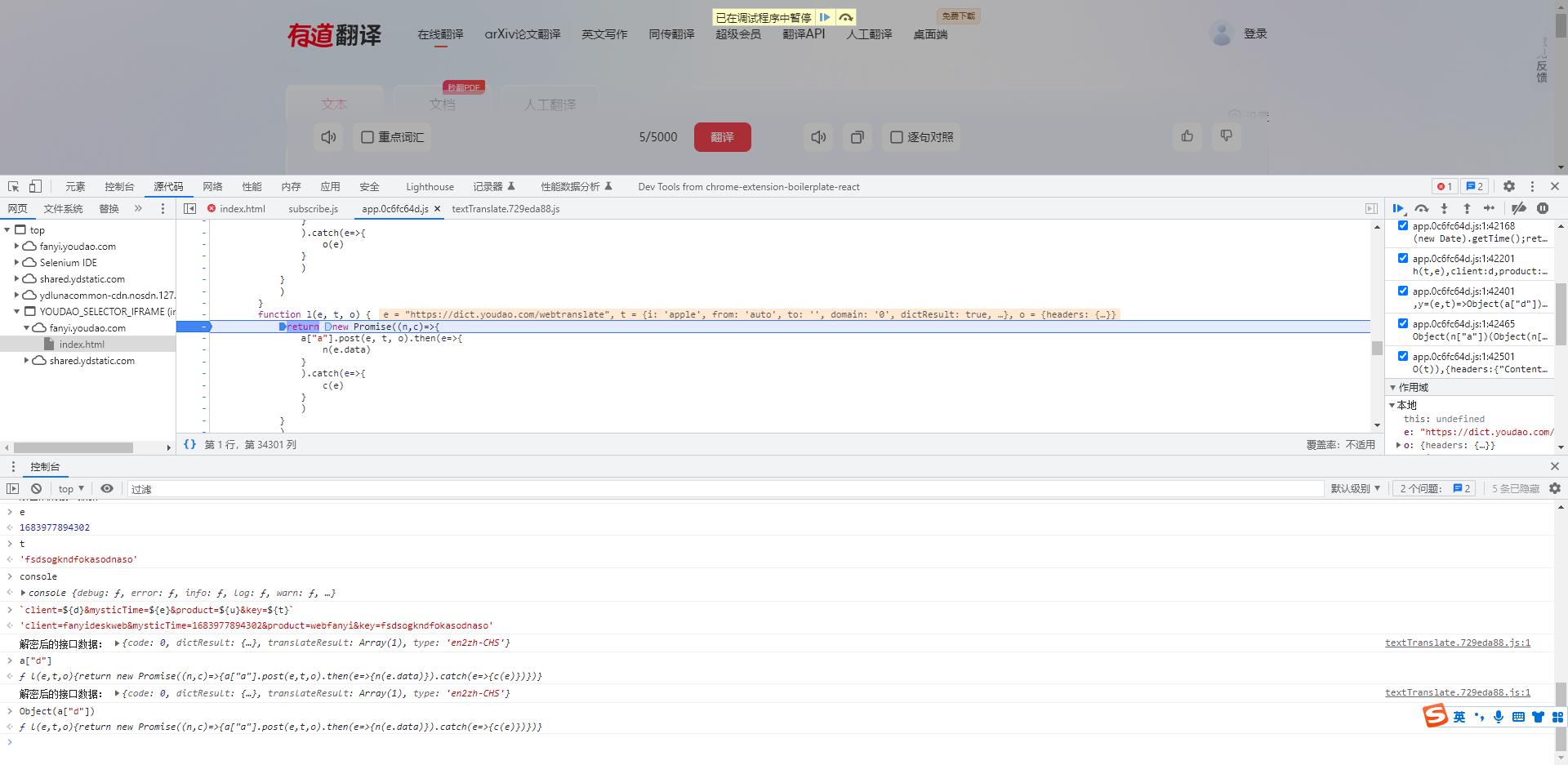
- 通过断点分析这段函数中传入的参数 e t o 正是我们前面对应的,请求网址,data参数 ,和请求头
- 我们再次分析我们请求网址所在的哪行代码
- 我们需要明白的思路是
- 我们需要调用一个函数,如果调用的这个函数的参数是下一个函数所生成的,那我们就要先执行第二个函数,将第二个函数的返回值,给第一个函数进行调用。
- 由此,我们可以利用调用堆栈,调用堆栈就是函数之间逐级的调用关系,其中越靠上表示越被后调用
- 那我们想知道是哪个函数想获得这个函数的调用值进行二次解析
- 那我们只需要向上返回一层
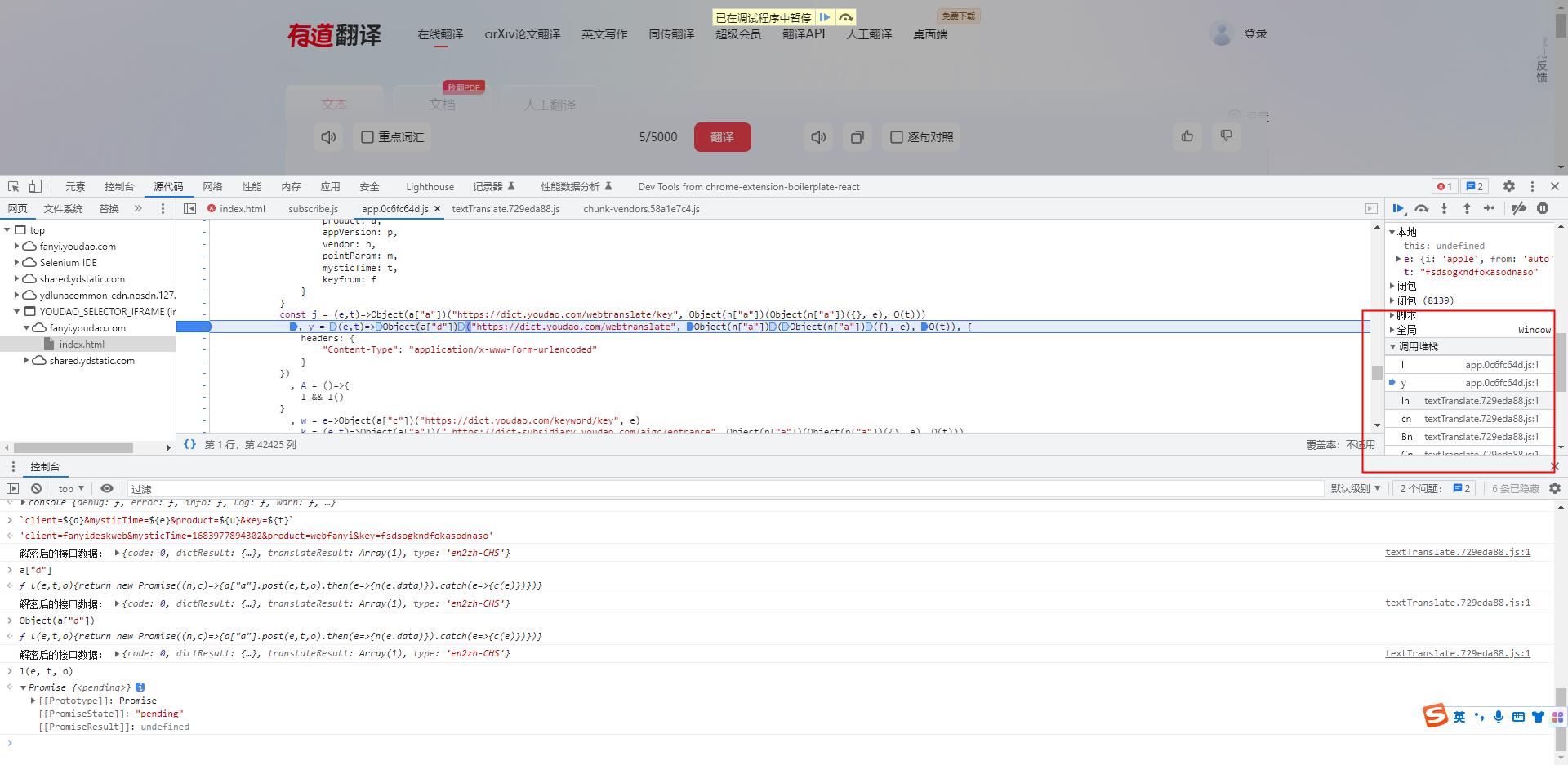
- 我们现在执行的是 y 函数 ,他的上一级调用函数就是 ln 函数 ,ln函数需要对 y 函数的结果进行运算。而我们 y 函数的调用结果我们已经解析出来了,正是我们得到的 base64编码数据
【3】逆向算法分析
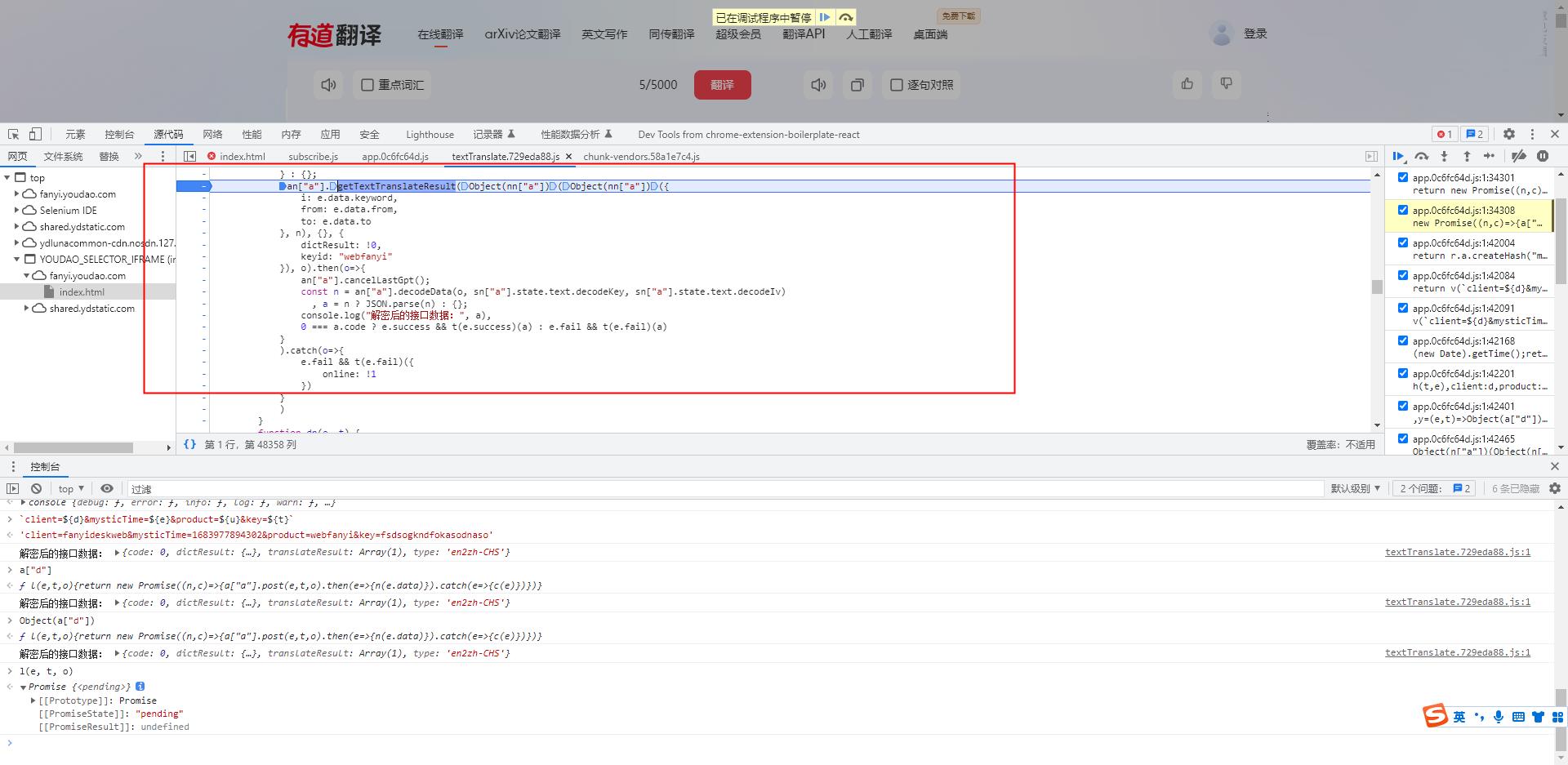
-
我们进入到 ln 函数的调用方法中
an["a"].getTextTranslateResult(Object(nn["a"])(Object(nn["a"])( i: e.data.keyword, from: e.data.from, to: e.data.to , n), , dictResult: !0, keyid: "webfanyi" ), o).then(o=> an["a"].cancelLastGpt(); const n = an["a"].decodeData(o, sn["a"].state.text.decodeKey, sn["a"].state.text.decodeIv) , a = n ? JSON.parse(n) : ; console.log("解密后的接口数据:", a), 0 === a.code ? e.success && t(e.success)(a) : e.fail && t(e.fail)(a) -
从 这个函数的名字我们不难理解,正是得到文本翻译结果的意思
-
这也表明我们的思路是正确的
-
再往下进行分析代码
-
我们看到了很眼熟的代码
const n = an["a"].decodeData(o, sn["a"].state.text.decodeKey, sn["a"].state.text.decodeIv) -
从这段代码,我们不难看出,正是进行了解密动作,同时从函数中的结构我们也不难发现 , 非常 符合我们 AES 中的 CBC 加密模式。参数分别对应 (加密数据,key值,iv偏移量)
-
接下来我们在该处进行断点
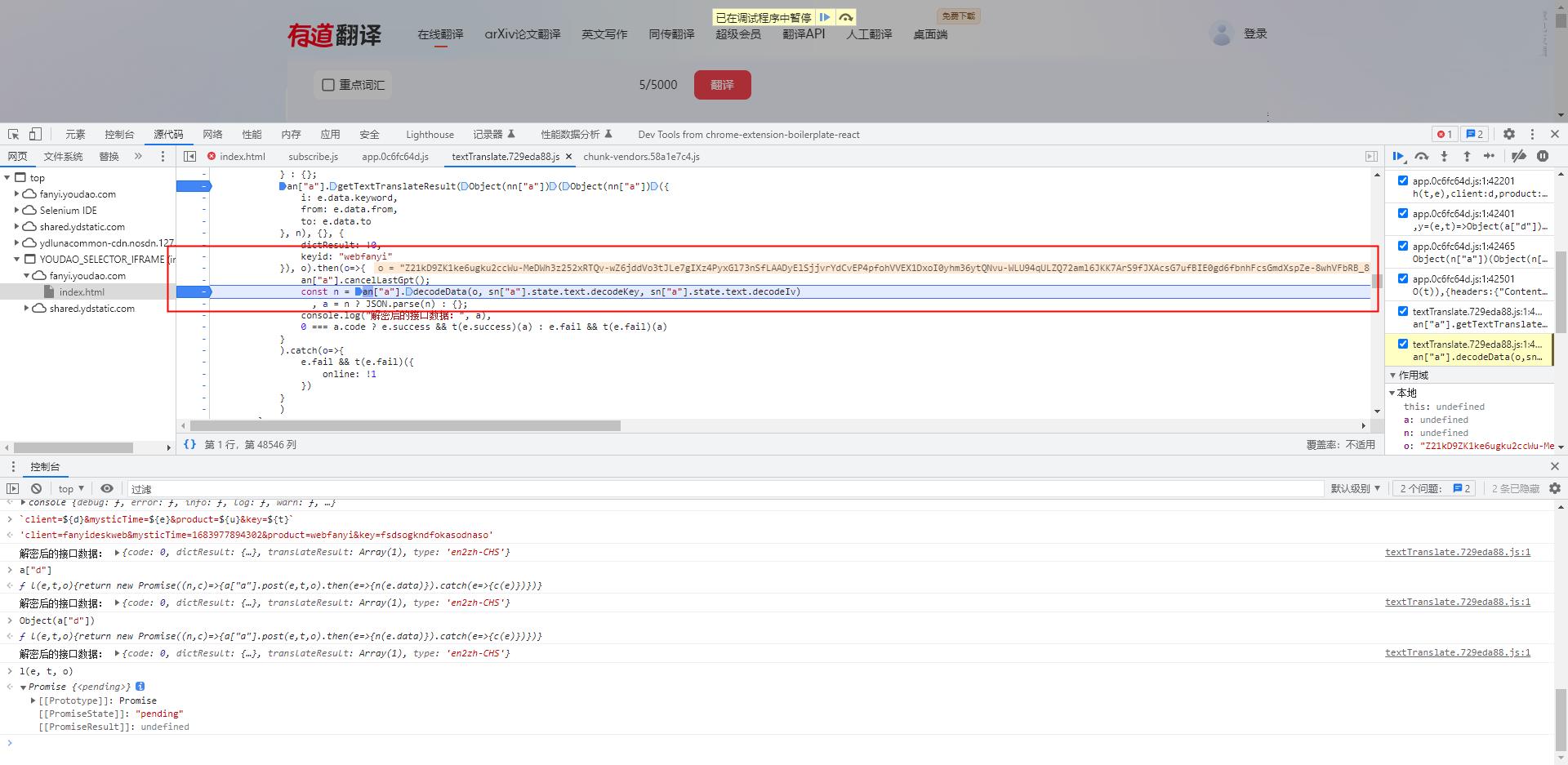
- 从这个位置我们可以很明显的看到,传入进来的 O 值正是我们解密后的base64编码数据,
- 这也更加印证了我们的思路是正确的,并没有跑偏
【4】逆向算法解密
- 接下来我们的思路也很明确
- 首先,我们要分析代码,找到我们加密所用到的key和iv
- 然后进行base64编码的解码
- 最后进行算法解密
- 在断点位置,我们查看这两个值
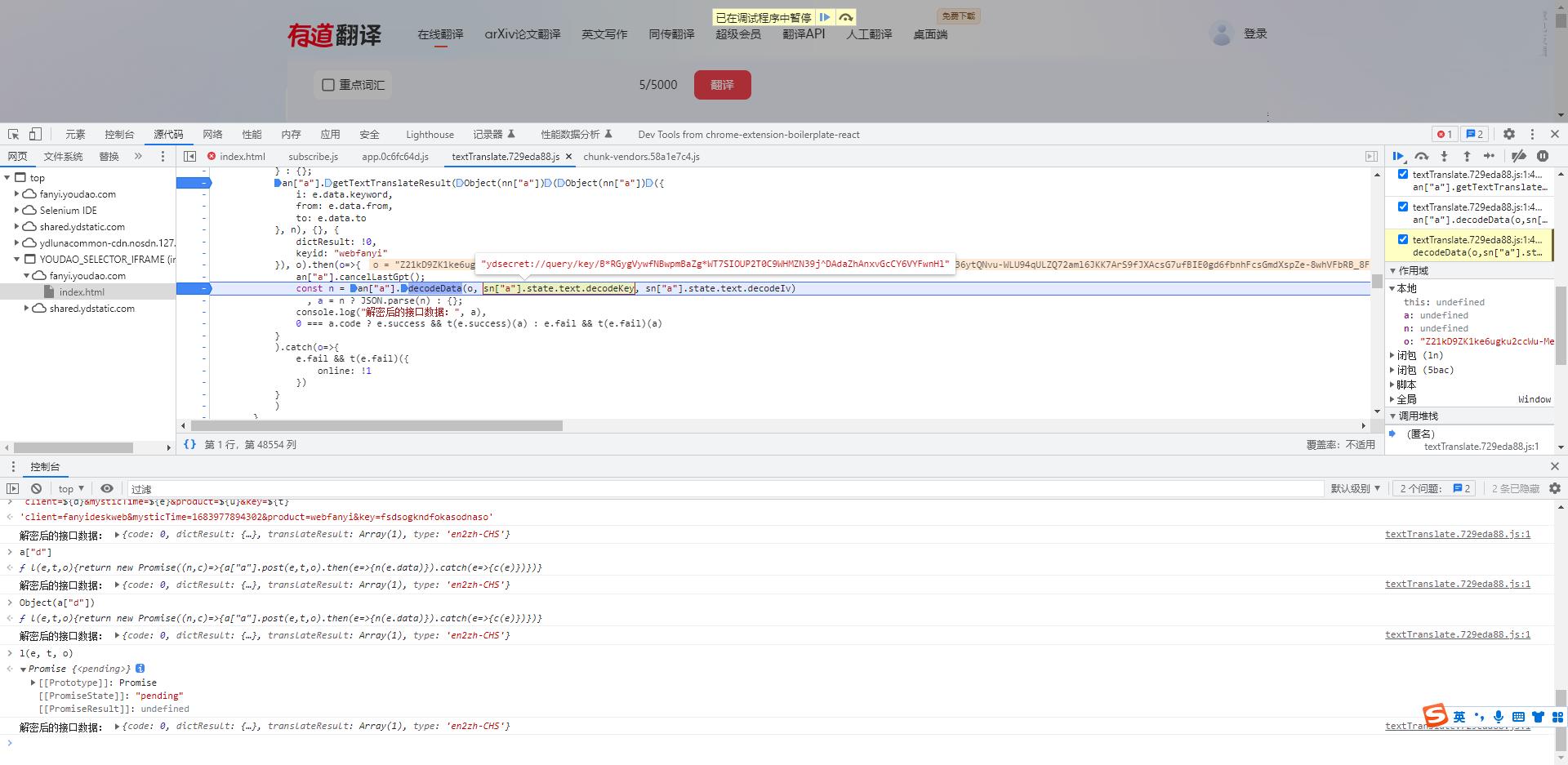
- 通过反复断点,重新进入,分析发现这两个值是定值,并不是随机变化的
decodeKey:"ydsecret://query/key/B*RGygVywfNBwpmBaZg*WT7SIOUP2T0C9WHMZN39j^DAdaZhAnxvGcCY6VYFwnHl"
decodeIv:"ydsecret://query/iv/C@lZe2YzHtZ2CYgaXKSVfsb7Y4QWHjITPPZ0nQp87fBeJ!Iv6v^6fvi2WN@bYpJ4"
-
我们知道,我们AES算法中传入进去的是二进制数据,这是字符串,显然不是,那我们就需要知道这个数据是如何编程二进制的(要考虑到其他的加密方式,而不是简单的就将字符串变成二进制就完事了)
-
我们进入到decode函数中查看其内部代码
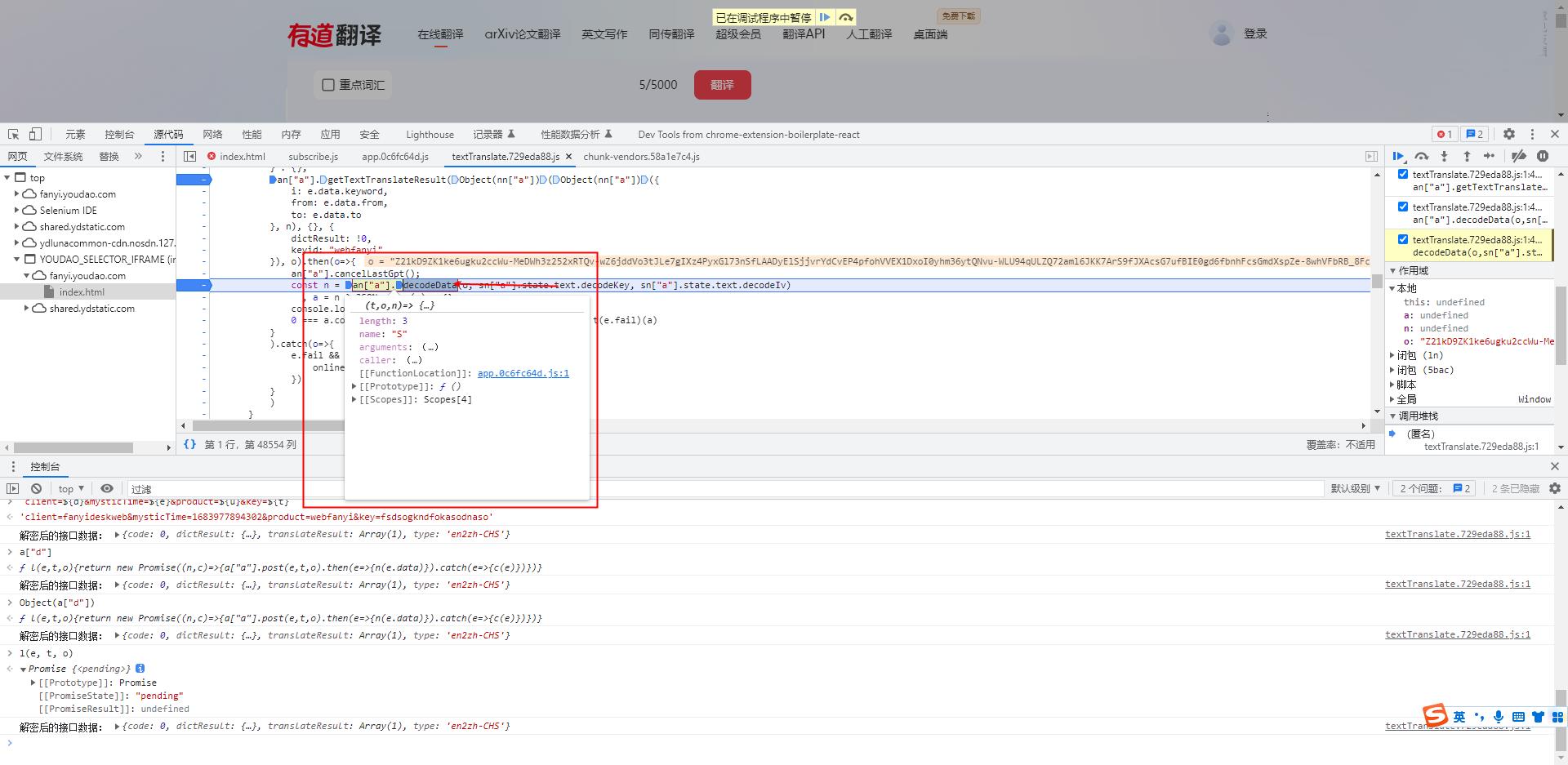
- 在这里我们看到了他完整的AES对象生成过程

- 进入到该断点位置
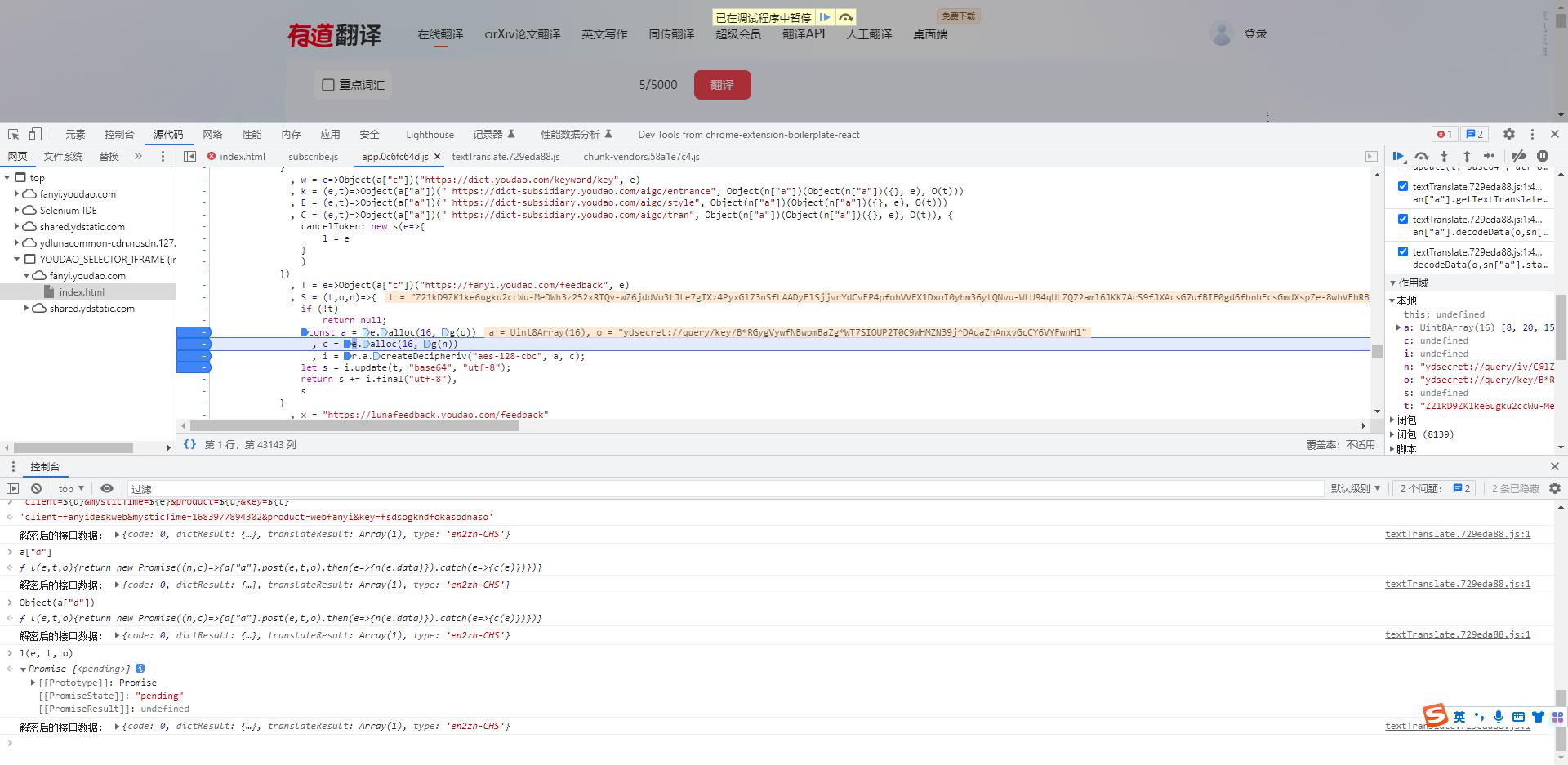
- 从这里我们可以看到,我们的 key 和 iv 传给了我们的 g 函数进行了加密
- 我们进入到 g 函数
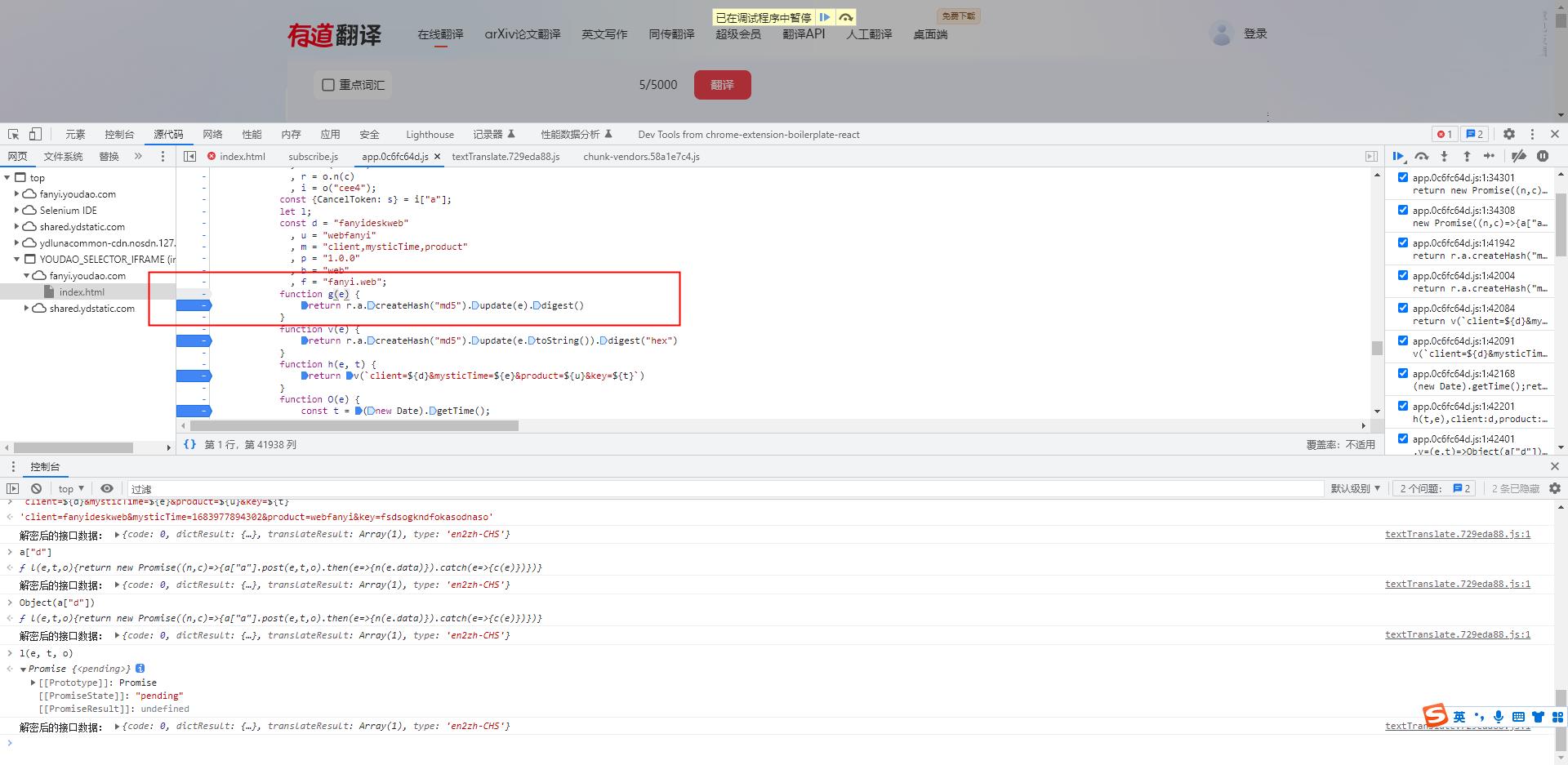
- 在这里我们很明显的可以看到,他也是一个md5加密,但是这次取的是2进制的字符串
function g(e)
return r.a.createHash("md5").update(e).digest()
- 至此,我们的所有参数就都逆向生成完了,接下来需要做的就是Python改写代码
- 小结:
- 首先我们要明白各个函数之间的调用关系
- 处理好各个函数之间的调用关系至关重要
- 知道了各个函数之间的调用关系后,我们再逐层进行分析
- 同时注意每一步出现的每个参数,每一个函数的意义,明白这些才能让我们的解密过程变得更快
- 最后要有耐心
def decript_data(ret):
# # ########### ----------------【部分一:base64解码】 ---------------- ###########
# # ########### ----------------(方法一) ---------------- ###########
# 观察发现base64编码后的数据不是标准的base64编码,存在变种,\'-\', \'/\' --- \'_\', \'+\' 将变种编码转换为标准编码
# standard_base64_data = ret.replace(\'-\', \'/\').replace(\'_\', \'+\')
# # 将标准的base64编码数据进行解码
# decode_base64_data = base64.b64decode(standard_base64_data.encode())
# ########### ----------------(方法二) ---------------- ###########
# 观察发现base64编码后的数据不是标准的base64编码,存在变种,\'-\', \'/\' --- \'_\', \'+\' 调用base64内部自带的标准化方法,将变种编码转换为标准编码并解码
# altchars=b"-_" 参数为需要替换的变种编码
standard_base64_data = base64.b64decode(ret.encode(), altchars=b"-_")
# # ########### ----------------【部分二:AES解密】 ---------------- ###########
# (1) AES 解密 之 key / iv 参数的获取
# 秘钥key : 二进制数据
# 未加密之前的key
key_before = "ydsecret://query/key/B*RGygVywfNBwpmBaZg*WT7SIOUP2T0C9WHMZN39j^DAdaZhAnxvGcCY6VYFwnHl"
# 调用加密函数进行加密,得到加密后的key
key = get_encrypt_key_iv(key_before)
# 偏移量 IV : 二进制数据
# 未加密之前的key
iv_before = "ydsecret://query/iv/C@lZe2YzHtZ2CYgaXKSVfsb7Y4QWHjITPPZ0nQp87fBeJ!Iv6v^6fvi2WN@bYpJ4"
# 调用加密函数进行加密,得到加密后的key
iv = get_encrypt_key_iv(iv_before)
# (2) AES 解密 之 数据的解密
# 实例化 AES对象
aes = AES.new(key=key, mode=AES.MODE_CBC, iv=iv)
# 调用数据解密方法进行解密 # 参数为解码后的base64编码数据(二进制)
decrypt_data = aes.decrypt(standard_base64_data)
# 以16进制去除解密数据中可能会填充的数据
decrypt_data = unpad(decrypt_data, 16)
# 将获取到的数据进行 json 序列化 # 参数为解密数据进行转码后的数据
dataDict = json.loads(decrypt_data.decode())
# 提取翻译后的结果
translate_result = [lineDict.get("tgt") for lineDict in dataDict.get("translateResult")[0]]
# 如果是长句子,考虑到每一句话的拼接
translate_result = "\\n".join(translate_result)
print(translate_result)
【三】代码完善
# requests:发送请求模块
import requests
# UA伪装之随机headers模块
from fake_useragent import UserAgent
# 时间模块
import time
# md5加密模块
from hashlib import md5
# AES 加密模块
from Crypto.Cipher import AES
# base64编码模块
import base64
# json 序列化模块
import json
# pad:模块(填充数据长度)
from Crypto.Util.Padding import pad, unpad
def get_sign():
\'\'\'
word:需要传入的单词/句子
# 逆向获取到时间戳和sign值
:return: 返回获取到md5加密值
\'\'\'
# 构建session对象:携带cookie,防止cookie过期
session = requests.Session()
# 有道翻译对应的主网址
main_url = \'https://dict.youdao.com/webtranslate\'
# headers 请求头
headers =
\'Accept\': \'application/json, text/plain, */*\',
\'Accept-Encoding\': \'gzip, deflate, br\',
\'Accept-Language\': \'zh-CN,zh;q=0.9,en;q=0.8\',
\'Cache-Control\': \'no-cache\',
\'Connection\': \'keep-alive\',
\'Content-Length\': \'239\',
\'Content-Type\': \'application/x-www-form-urlencoded\',
\'Host\': \'dict.youdao.com\',
\'Origin\': \'https://fanyi.youdao.com\',
\'Pragma\': \'no-cache\',
\'Referer\': \'https://fanyi.youdao.com/\',
\'Sec-Fetch-Dest\': \'empty\',
\'Sec-Fetch-Mode\': \'cors\',
\'Sec-Fetch-Site\': \'same-site\',
\'Cookie\': \'OUTFOX_SEARCH_USER_ID=-2102182500@10.110.96.154; OUTFOX_SEARCH_USER_ID_NCOO=1723343714.3489342; YOUDAO_MOBILE_ACCESS_TYPE=0\',
\'User-Agent\': UserAgent().random,
# 构建sign值和时间戳
# 构建时间戳,参照逆向,可发现其时间戳为13位,所以要 *1000 。时间戳为整数类型,所以要int
mysticTime = int(time.time() * 1000)
# 逆向可知sign值得构建中,这个参数为固定值
# 固定值 key
key = \'fsdsogkndfokasodnaso\'
# 构建 sign_before , 未加密之前的明文数据
sign_before = f\'client=fanyideskweb&mysticTime=mysticTime&product=webfanyi&key=key\'
# 进行编码,转为二进制数据
sign_encode = sign_before.encode(\'utf-8\')
# 构建 md5对象
alg = md5()
# 将数据进行更新加密
alg.update(sign_before.encode("utf-8"))
# 获取加密数据中心的hex值
sign = alg.hexdigest()
# 构建 post 请求所需要的data参数
word = input(\'请输入内容:\')
data =
\'i\': word, # 传入的参数(单词/句子)
\'from\': \'auto\',
\'to\': \'\',
\'dictResult\': \'true\',
\'keyid\': \'webfanyi\',
\'sign\': sign, # sign值 -- md5加密
\'client\': \'fanyideskweb\',
\'product\': \'webfanyi\',
\'appVersion\': \'1.0.0\',
\'vendor\': \'web\',
\'pointParam\': \'client,mysticTime,product\',
\'mysticTime\': mysticTime, # --- 时间戳生成
\'keyfrom\': \'fanyi.web\',
# 发送请求,获取到加密的base64编码返回结果
response = session.post(url=main_url, headers=headers, data=data)
ret = response.text
# 返回数据,等待下一步调用
return ret
def get_encrypt_key_iv(text):
\'\'\'
:param text: 传入的key / iv
:return: 返回加密后的 key / iv
\'\'\'
# 构建md5对象
m = md5()
# 传入数据进行,md5加密数据更新
m.update(text.encode())
# 返回加密数据的digest值
return m.digest()
def decript_data(ret):
# # ########### ----------------【部分一:base64解码】 ---------------- ###########
# # ########### ----------------(方法一) ---------------- ###########
# 观察发现base64编码后的数据不是标准的base64编码,存在变种,\'-\', \'/\' --- \'_\', \'+\' 将变种编码转换为标准编码
# standard_base64_data = ret.replace(\'-\', \'/\').replace(\'_\', \'+\')
# # 将标准的base64编码数据进行解码
# decode_base64_data = base64.b64decode(standard_base64_data.encode())
# ########### ----------------(方法二) ---------------- ###########
# 观察发现base64编码后的数据不是标准的base64编码,存在变种,\'-\', \'/\' --- \'_\', \'+\' 调用base64内部自带的标准化方法,将变种编码转换为标准编码并解码
# altchars=b"-_" 参数为需要替换的变种编码
standard_base64_data = base64.b64decode(ret.encode(), altchars=b"-_")
# # ########### ----------------【部分二:AES解密】 ---------------- ###########
# (1) AES 解密 之 key / iv 参数的获取
# 秘钥key : 二进制数据
# 未加密之前的key
key_before = "ydsecret://query/key/B*RGygVywfNBwpmBaZg*WT7SIOUP2T0C9WHMZN39j^DAdaZhAnxvGcCY6VYFwnHl"
# 调用加密函数进行加密,得到加密后的key
key = get_encrypt_key_iv(key_before)
# 偏移量 IV : 二进制数据
# 未加密之前的key
iv_before = "ydsecret://query/iv/C@lZe2YzHtZ2CYgaXKSVfsb7Y4QWHjITPPZ0nQp87fBeJ!Iv6v^6fvi2WN@bYpJ4"
# 调用加密函数进行加密,得到加密后的key
iv = get_encrypt_key_iv(iv_before)
# (2) AES 解密 之 数据的解密
# 实例化 AES对象
aes = AES.new(key=key, mode=AES.MODE_CBC, iv=iv)
# 调用数据解密方法进行解密 # 参数为解码后的base64编码数据(二进制)
decrypt_data = aes.decrypt(standard_base64_data)
# 以16进制去除解密数据中可能会填充的数据
decrypt_data = unpad(decrypt_data, 16)
# 将获取到的数据进行 json 序列化 # 参数为解密数据进行转码后的数据
dataDict = json.loads(decrypt_data.decode())
# 提取翻译后的结果
translate_result = [lineDict.get("tgt") for lineDict in dataDict.get("translateResult")[0]]
# 如果是长句子,考虑到每一句话的拼接
translate_result = "\\n".join(translate_result)
print(translate_result)
def choose_y_n(choose_result):
if choose_result == \'y\':
use()
else:
print(\'感谢您的使用!祝您生活愉快!\')
def use():
ret = get_sign()
decript_data(ret)
choose_result = input(\'继续使用请输入y:::\')
choose_y_n(choose_result)
if __name__ == \'__main__\':
use()
Python爬虫之破解百度翻译--requests案例详解
这节课我们接着上节课的内容,继续学习requests之破解百度翻译案例。我们上节课已经知道了解题思路,这节课我们来看看代码怎么写。
1.首先导入requests模块
**
**

** **
2.获取请求类型以及网址信息
**
**
通过页面信息(如下图)可知,百度翻译的请求类型是post类型,并且我们获取到了网页的URL

但是我么通过查看网址知道,并不全,需要参数信息进行补充,我们通过网页获取到参数(如下图)

3.书写代码
通过上一步骤我们获取到了data,URL,类型为post,以及headers,便可书写如下代码:

** **
4.获取网页的响应类型信息
**
**
通过代码信息我们可以知道,响应类型信息为JSON类型,而非前几节课讲的text文本格式,因此我们需要先导入JSON,然后通过JSON获取网页的内容(如下图)

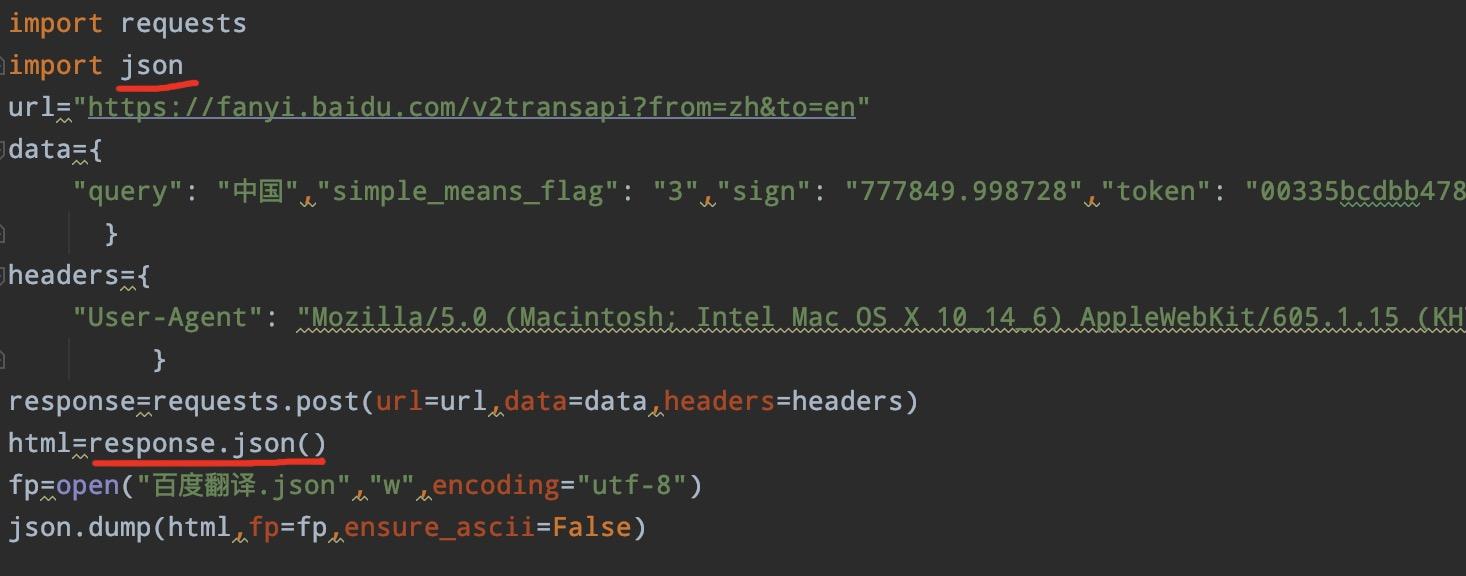
** **
5.保存网页信息
JSON格式保存与text,还是有差别的,按照下面代码直接照猫画虎即可。

这是我们这个练习的完整代码,大家可以试着运行一下,我们会发现使用requests模块,我们需要判断请求类型(post/get),然后根据类型选择参数(data/params),再接着我们根据相应的类型(text/Json),获取到网页信息,最后再保存数据信息即可。
以上是关于爬虫案例之网易有道翻译Python代码改写的主要内容,如果未能解决你的问题,请参考以下文章