python爬虫百度翻译
Posted unidl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫百度翻译相关的知识,希望对你有一定的参考价值。
-
python3,爬取的是百度翻译手机版的网页
-
运用requests,json模块
-
英汉互译,运行结果
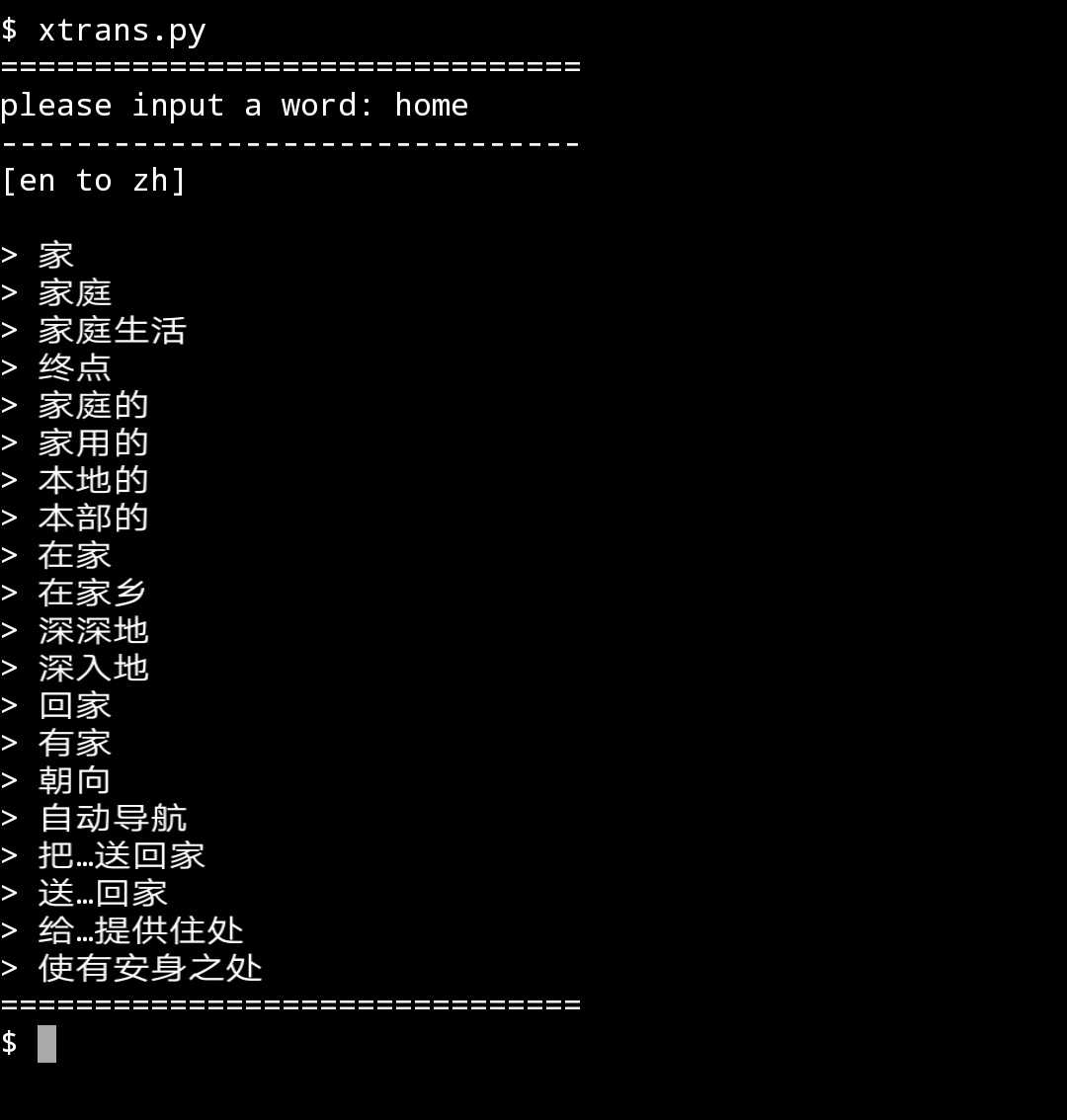
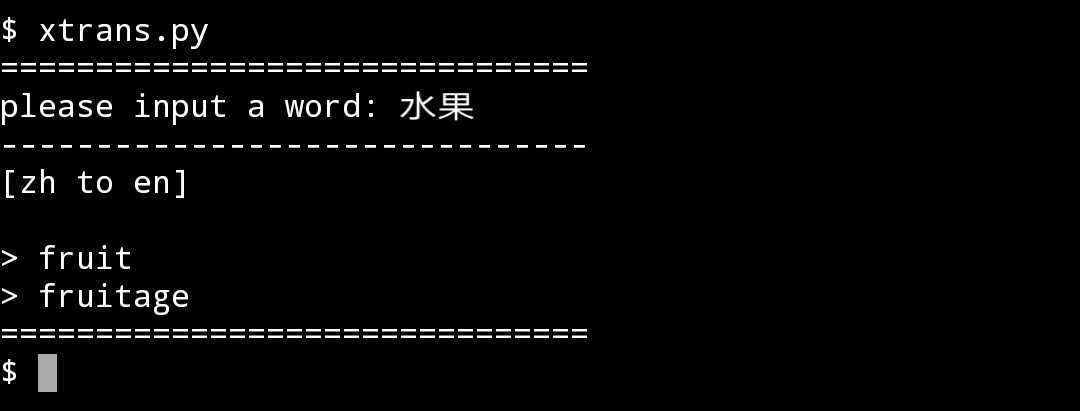
#!/bin/python3 # -*- coding: UTF-8 -*- #============================================= #describe:an en to zh and zh to en translater #version:1 #update:2018-08-03 #--- #author:unihon #E-mail:[email protected] #github:https://github.com/unihon #============================================= import requests import json def trans(): userAgent = "Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1" header = { "Host": "fanyi.baidu.com", "Origin": "http://fanyi.baidu.com", "User-Agent": userAgent } postUrl="http://fanyi.baidu.com/basetrans" wd = input("please input a word: ") print(‘-------------------------------‘) if wd == ‘‘: trans() return for c in wd: if c < u‘u4e00‘ or c > u‘u9fa5‘: print(‘[en to zh] ‘) mdata = { "from":"en", "to":"zh", "query" : wd } break elif c == wd[-1]: print(‘[zh to en] ‘) mdata = { "from":"zh", "to":"en", "query" : wd } try: response = requests.post(postUrl, data = mdata, headers = header) except: print(‘connect error!‘) return 1 result = response.text result=json.loads(result) if len(result["dict"]) == 0: print(‘is null‘) else: try: for i in result["dict"]["word_means"]: print(‘> ‘+ i) except KeyError: print(‘key is null‘) if __name__ == "__main__": print("===============================") trans() print("===============================")
-
小结
需要注意的是,爬到的json数据,中文一般是unicode编码的形式,可以用json模块处理。
以上是关于python爬虫百度翻译的主要内容,如果未能解决你的问题,请参考以下文章