大数据Spark Structured Streaming集成 Kafka
Posted 赵广陆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据Spark Structured Streaming集成 Kafka相关的知识,希望对你有一定的参考价值。
1 Kafka 数据消费
Apache Kafka 是目前最流行的一个分布式的实时流消息系统,给下游订阅消费系统提供了并行处理和可靠容错机制,现在大公司在流式数据的处理场景,Kafka基本是标配。StructuredStreaming很好的集成Kafka,可以从Kafka拉取消息,然后就可以把流数据看做一个DataFrame, 一张无限增长的大表,在这个大表上做查询,Structured Streaming保证了端到端的 exactly-once,用户只需要关心业务即可,不用费心去关心底层是怎么做的。
StructuredStreaming集成Kafka,官方文档如下:
http://spark.apache.org/docs/2.4.5/structured-streaming-kafka-integration.html
目前仅支持Kafka 0.10.+版本及以上,底层使用Kafka New Consumer API拉取数据,如果公司Kafka版本为0.8.0版本,StructuredStreaming集成Kafka参考文档:
https://github.com/jerryshao/spark-kafka-0-8-sql
StructuredStreaming既可以从Kafka读取数据,又可以向Kafka 写入数据,添加Maven依赖:
<!-- Structured Streaming + Kafka 依赖 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql-kafka-0-10_2.11</artifactId>
<version>2.4.5</version>
</dependency>
Maven Project工程中目录结构如下:
Kafka把生产者发送的数据放在不同的分区里面,这样就可以并行进行消费了。每个分区里面的数据都是递增有序的,跟structured commit log类似,生产者和消费者使用Kafka 进行解耦,消费者不管你生产者发送的速率如何,只要按照一定的节奏进行消费就可以了。每条消息在一个分区里面都有一个唯一的序列号offset(偏移量),Kafka 会对内部存储的消息设置一个过期时间,如果过期了,就会标记删除,不管这条消息有没有被消费。Kafka 可以被看成一个无限的流,里面的流数据是短暂存在的,如果不消费,消息就过期滚动没了。涉及一个问题:如果开始消费,就要定一下从什么位置开始。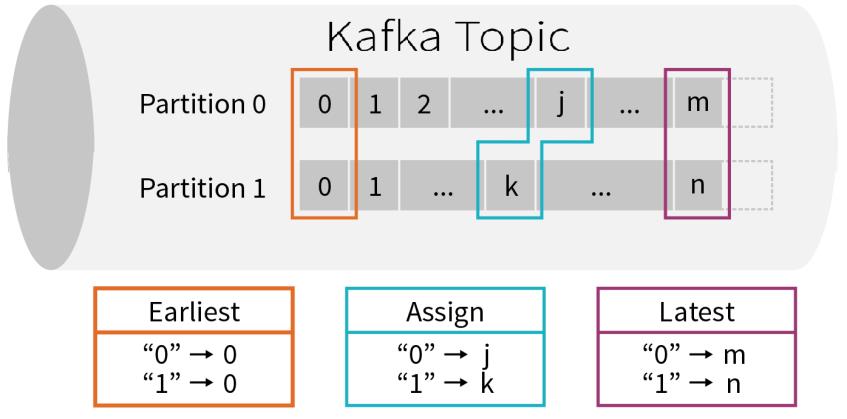
- 第一、earliest:从最起始位置开始消费,当然不一定是从0开始,因为如果数据过期就清掉了,所以可以理解为从现存的数据里最小位置开始消费;
- 第二、latest:从最末位置开始消费;
- 第三、per-partition assignment:对每个分区都指定一个offset,然后从offset位置开始消费;当第一次开始消费一个Kafka 流的时候,上述策略任选其一,如果之前已经消费了,而且做了checkpoint ,比如消费程序升级了,这时候就会从上次结束的位置开始继续消费。目前StructuredStreaming和Flink框架从Kafka消费数据时,采用的就是上述的策略。
2 Kafka 数据源
Structured Streaming消费Kafka数据,采用的是poll方式拉取数据,与Spark Streaming中NewConsumer API集成方式一致。从Kafka Topics中读取消息,需要指定数据源(kafka)、Kafka集群的连接地址(kafka.bootstrap.servers)、消费的topic(subscribe或subscribePattern), 指定topic的时候,可以使用正则来指定,也可以指定一个 topic 的集合。官方提供三种方式从Kafka topic中消费数据,主要区别在于每次消费Topic名称指定,
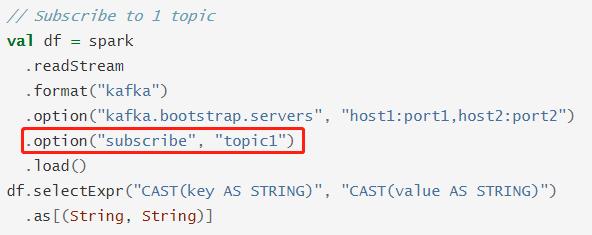
- 方式一:消费一个Topic数据
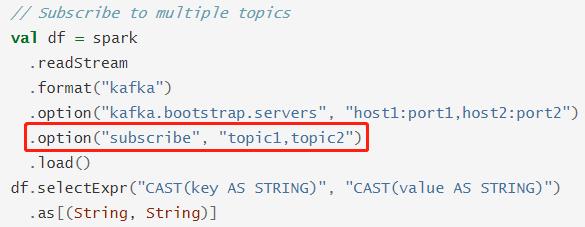
- 方式二:消费多个Topic数据
- 方式三:消费通配符匹配Topic数据
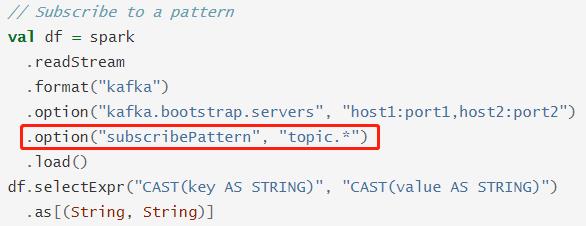
从Kafka 获取数据后Schema字段信息如下,既包含数据信息有包含元数据信息: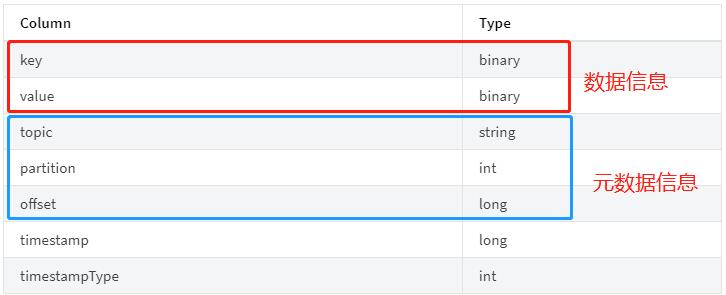
在实际开发时,往往需要获取每条数据的消息,存储在value字段中,由于是binary类型,需要转换为字符串String类型;此外了方便数据操作,通常将获取的key和value的DataFrame转换为Dataset强类型,伪代码如下:

从Kafka数据源读取数据时,可以设置相关参数,包含必须参数和可选参数: - 必须参数:kafka.bootstrap.servers和subscribe,可以指定开始消费偏移量assign。
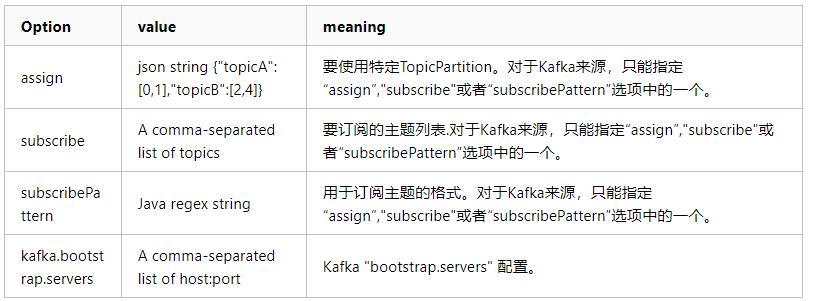
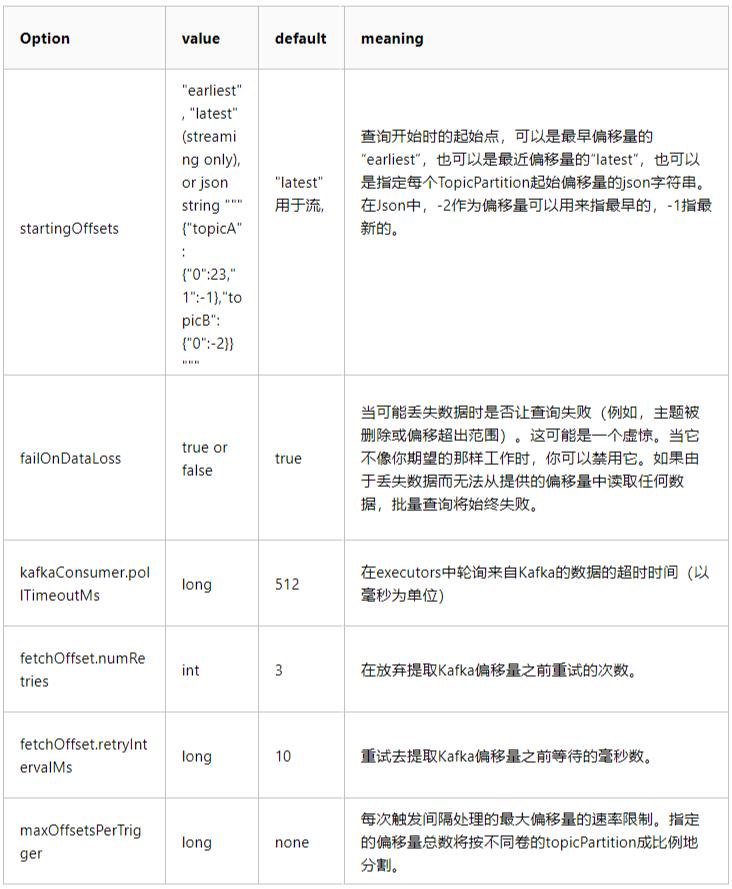
- 可选参数:
范例演示:从Kafka消费数据,进行词频统计,Topic为wordsTopic。 - 第一步、创建Topic,相关命令如下:
# 启动Zookeeper
/export/server/zookeeper/bin/zkServer.sh start
# 启动Kafka Broker
/export/server/kafka/bin/kafka-server-start.sh -daemon /export/server/kafka/config/server.properties
## ================================= wordsTopic =================================
# 查看Topic信息
/export/server/kafka/bin/kafka-topics.sh --list --zookeeper node1.oldlu.cn:2181/kafka200
# 创建topic
/export/server/kafka/bin/kafka-topics.sh --create --zookeeper node1.oldlu.cn:2181/kafka200 --replicatio
n-factor 1 --partitions 3 --topic wordsTopic
# 模拟生产者
/export/server/kafka/bin/kafka-console-producer.sh --broker-list node1.oldlu.cn:9092 --topic wordsTopic
- 第二步、编写代码,其中设置每批次消费数据最大量
package cn.oldlu.spark.kafka.source
import org.apache.spark.sql.streaming.{OutputMode, StreamingQuery}
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* 使用Structured Streaming从Kafka实时读取数据,进行词频统计,将结果打印到控制台。
*/
object StructuredKafkaSource {
def main(args: Array[String]): Unit = {
// 构建SparkSession实例对象
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[3]")
// 设置Shuffle分区数目
.config("spark.sql.shuffle.partitions", "3")
.getOrCreate()
// 导入隐式转换和函数库
import spark.implicits._
import org.apache.spark.sql.functions._
// TODO: 从Kafka读取数据,底层采用New Consumer API
val kafkaStreamDF: DataFrame = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "node1.oldlu.cn:9092")
.option("subscribe", "wordsTopic")
// TODO: 设置每批次消费数据最大值
.option("maxOffsetsPerTrigger", "100000")
.load()
// TODO: 进行词频统计
val resultStreamDF: DataFrame = kafkaStreamDF
// 获取value字段的值,转换为String类型
.selectExpr("CAST(value AS STRING)")
// 转换为Dataset类型
.as[String]
// 过滤数据
.filter(line => null != line && line.trim.length > 0)
// 分割单词
.flatMap(line => line.trim.split("\\\\s+"))
// 按照单词分组,聚合
.groupBy($"value").count()
// 设置Streaming应用输出及启动
val query: StreamingQuery = resultStreamDF.writeStream
.outputMode(OutputMode.Complete())
.format("console").option("numRows", "10").option("truncate", "false")
.start()
query.awaitTermination() // 查询器等待流式应用终止
query.stop() // 等待所有任务运行完成才停止运行
}
}
3 Kafka 接收器
往Kafka里面写数据类似读取数据,可以在DataFrame上调用writeStream来写入Kafka,设置参
数指定value,其中key是可选的,如果不指定就是null。如果key为null,有时候可能导致分区数据
不均匀。
3.1 配置说明
将DataFrame写入Kafka时,Schema信息中所需的字段:
需要写入哪个topic,可以像上述所示在操作DataFrame 的时候在每条record上加一列topic字段指定,也可以在DataStreamWriter上指定option配置。写入数据至Kafka,需要设置Kafka Brokers地址信息及可选配置:
- 必选参数:kafka.bootstrap.servers,使用逗号隔开【host:port】字符;
- 可选参数:topic,如果DataFrame中没有topic列,此处指定topic表示写入Kafka Topic。
官方提供示例代码如下: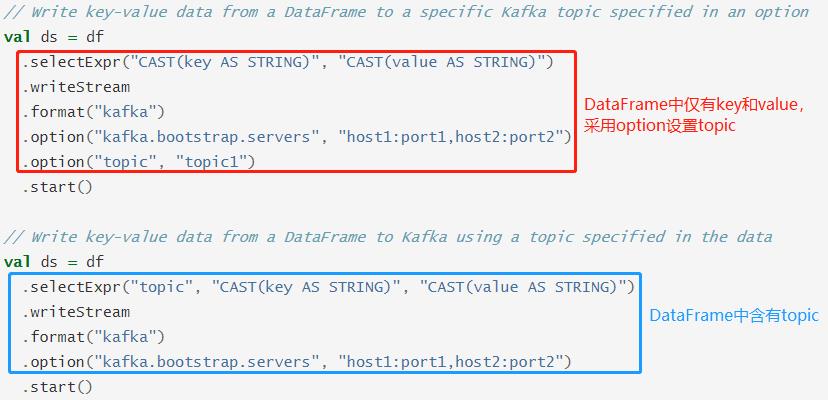
3.2 实时数据ETL架构
在实际实时流式项目中,无论使用Storm、SparkStreaming、Flink及Structured Streaming处理流式数据时,往往先从Kafka 消费原始的流式数据,经过ETL后将其存储到Kafka Topic中,以便其他业务相关应用消费数据,实时处理分析,技术架构流程图如下所示: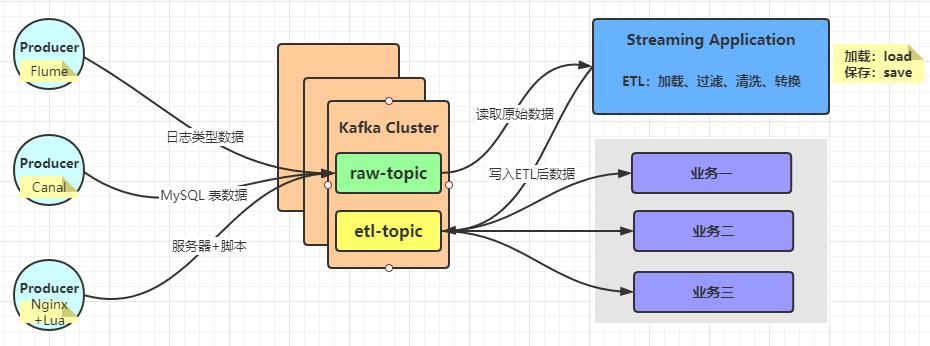
接下来模拟产生运营商基站数据,实时发送到Kafka 中,使用StructuredStreaming消费,经过ETL(获取通话状态为success数据)后,写入Kafka中,便于其他实时应用消费处理分析。
3.3 模拟基站日志数据
模拟产生运营商基站通话日志数据,封装到样例类中,字段信息如下
package cn.oldlu.spark.kafka.mock
/**
* 基站通话日志数据,字段如下:
*
* @param stationId 基站标识符ID
* @param callOut 主叫号码
* @param callIn 被叫号码
* @param callStatus 通话状态
* @param callTime 通话时间
* @param duration 通话时长
*/
case class StationLog(
stationId: String, //
callOut: String, //
callIn: String, //
callStatus: String, //
callTime: Long, //
duration: Long //
) {
override def toString: String = s"$stationId,$callOut,$callIn,$callStatus,$callTime,$duration"
}
创建Topic,相关命令如下:
# 启动Zookeeper
/export/server/zookeeper/bin/zkServer.sh start
# 启动Kafka Broker
/export/server/kafka/bin/kafka-server-start.sh -daemon /export/server/kafka/config/server.properties
## ================================= stationTopic =================================
# 创建topic
/export/server/kafka/bin/kafka-topics.sh --create --zookeeper node1.oldlu.cn:2181/kafka200 --replication-
factor 1 --partitions 3 --topic stationTopic
# 模拟生产者
/export/server/kafka/bin/kafka-console-producer.sh --broker-list node1.oldlu.cn:9092 --topic stationTopic
# 模拟消费者
/export/server/kafka/bin/kafka-console-consumer.sh --bootstrap-server node1.oldlu.cn:9092 --topic station
Topic --from-beginning
# 删除topic
/export/server/kafka/bin/kafka-topics.sh --delete --zookeeper node1.oldlu.cn:2181/kafka200 --topic statio
nTopic
## ================================= etlTopic =================================
# 创建topic
/export/server/kafka/bin/kafka-topics.sh --create --zookeeper node1.oldlu.cn:2181/kafka200 --replication-
factor 1 --partitions 3 --topic etlTopic
# 模拟生产者
/export/servers/kafka/bin/kafka-console-producer.sh --broker-list node1.oldlu.cn:9092 --topic etlTopic
# 模拟消费者
/export/server/kafka/bin/kafka-console-consumer.sh --bootstrap-server node1.oldlu.cn:9092 --topic etlTopi
c --from-beginning
编写代码,实时产生日志数据,发送Kafka Topic:
package cn.oldlu.spark.kafka.mock
import java.util.Properties
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerRecord}
import org.apache.kafka.common.serialization.StringSerializer
import scala.util.Random
/**
* 模拟产生基站日志数据,实时发送Kafka Topic中,数据字段信息:
* 基站标识符ID, 主叫号码, 被叫号码, 通话状态, 通话时间,通话时长
*/
object MockStationLog {
def main(args: Array[String]): Unit = {
// 发送Kafka Topic
val props = new Properties()
props.put("bootstrap.servers", "node1.oldlu.cn:9092")
props.put("acks", "1")
props.put("retries", "3")
props.put("key.serializer", classOf[StringSerializer].getName)
props.put("value.serializer", classOf[StringSerializer].getName)
val producer = new KafkaProducer[String, String](props)
val random = new Random()
val allStatus = Array(
"fail", "busy", "barring", "success", "success", "success",
"success", "success", "success", "success", "success", "success"
)
while (true) {
val callOut: String = "1860000%04d".format(random.nextInt(10000))
val callIn: String = "1890000%04d".format(random.nextInt(10000))
val callStatus: String = allStatus(random.nextInt(allStatus.length))
val callDuration = if ("success".equals(callStatus)) (1 + random.nextInt(10)) * 1000L else 0L
// 随机产生一条基站日志数据
val stationLog: StationLog = StationLog(
"station_" + random.nextInt(10), //
callOut, //
callIn, //
callStatus, //
System.currentTimeMillis(), //
callDuration //
)
println(stationLog.toString)
Thread.sleep(100 + random.nextInt(100))
val record = new ProducerRecord[String, String]("stationTopic", stationLog.toString)
producer.send(record)
}
producer.close() // 关闭连接
}
}
运行程序,基站通话日志数据格式如下:
station_7,18600009710,18900000269,success,1590709965144,4000
station_6,18600003894,18900000028,success,1590709965333,8000
station_7,18600007207,18900001057,busy,1590709965680,0
3.4 实时增量ETL
编写应用实时从Kafka的【stationTopic】消费数据,经过处理分析后,存储至Kafka的
【etlTopic】,其中需要设置检查点目录,保证应用一次且仅一次的语义。
package cn.oldlu.spark.kafka.sink
import org.apache.spark.sql.streaming.{OutputMode, StreamingQuery}
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
/**
* 实时从Kafka Topic消费基站日志数据,过滤获取通话转态为success数据,再存储至Kafka Topic中
* 1、从KafkaTopic中获取基站日志数据(模拟数据,JSON格式数据)
* 2、ETL:只获取通话状态为success日志数据
* 3、最终将ETL的数据存储到Kafka Topic中
*/
object StructuredEtlSink {
def main(args: Array[String]): Unit = {
// 构建SparkSession实例对象
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[3]")
// 设置Shuffle分区数目
.config("spark.sql.shuffle.partitions", "3")
.getOrCreate()
// 导入隐式转换和函数库
import spark.implicits._
import org.apache.spark.sql.functions._
// 1. 从KAFKA读取数据
val kafkaStreamDF: DataFrame = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "node1.oldlu.cn:9092")
.option("subscribe", "stationTopic")
.load()
// 2. 对基站日志数据进行ETL操作
// station_0,18600004405,18900009049,success,1589711564033,9000
val etlStreamDF: Dataset[String] = kafkaStreamDF
// 获取value字段的值,转换为String类型
.selectExpr("CAST(value AS STRING)")
// 转换为Dataset类型
.as[String]
// 过滤数据:通话状态为success
.filter { log =>
null != log && log.trim.split(",").length == 6 && "success".equals(log.trim.split(",")(3))
}
etlStreamDF.printSchema()
// 3. 针对流式应用来说,输出的是流
val query: StreamingQuery = etlStreamDF.writeStream
// 对流式应用输出来说,设置输出模式
.outputMode(OutputMode.Append())
.format("kafka")
.option("kafka.bootstrap.servers", "node1.oldlu.cn:9092")
.option("topic", "etlTopic")
// 设置检查点目录
.option("checkpointLocation", s"datas/structured/etl-100001")
// 流式应用,需要启动start
.start()
// 查询器等待流式应用终止
query.awaitTermination()
query.stop() // 等待所有任务运行完成才停止运行
}
}
4 Kafka 特定配置
从Kafka消费数据时,相关配置属性可以通过带有kafka.prefix的DataStreamReader.option进行
设置,例如前面设置Kafka Brokers地址属性:stream.option(“kafka.bootstrap.servers”, “host:port”),
更多关于Kafka 生产者Producer Config配置属和消费者Consumer Config配置属性,参考文档:
- 生产者配置(Producer Configs):
- http://kafka.apache.org/20/documentation.html#producerconfigs
- 消费者配置(New Consumer Configs):
- http://kafka.apache.org/20/documentation.html#newconsumerconfigs
注意以下Kafka参数属性可以不设置,如果设置的话,Kafka source或者sink可能会抛出错误:
- 1)、group.id:Kafka source将会自动为每次查询创建唯一的分组ID;
- 2)、auto.offset.reset:在将source选项startingOffsets设置为指定从哪里开始。结构化流管理
内部消费的偏移量,而不是依赖Kafka消费者来完成。这将确保在topic/partitons动态订阅时不
会遗漏任何数据。注意,只有在启动新的流式查询时才会应用startingOffsets,并且恢复操作
始终会从查询停止的位置启动; - 3)、key.deserializer/value.deserializer:Keys/Values总是被反序列化为ByteArrayDeserializer
的字节数组,使用DataFrame操作显式反序列化keys/values; - 4)、key.serializer/value.serializer:keys/values总是使用ByteArraySerializer或StringSerializer
进行序列化,使用DataFrame操作将keysvalues/显示序列化为字符串或字节数组; - 5)、enable.auto.commit:Kafka source不提交任何offset;
- 6)、interceptor.classes:Kafka source总是以字节数组的形式读取key和value。使用
ConsumerInterceptor是不安全的,因为它可能会打断查询;
以上是关于大数据Spark Structured Streaming集成 Kafka的主要内容,如果未能解决你的问题,请参考以下文章
大数据Spark Structured Streaming集成 Kafka
Structured Streaming教程 —— 基本概念与使用
Structured Streaming系列-4集成 Kafka