机器学习笔记:神经网络层的各种normalization
Posted UQI-LIUWJ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习笔记:神经网络层的各种normalization相关的知识,希望对你有一定的参考价值。
1 Normalization的引入
1.1 独立同分布
机器学习,尤其是深度学习的模型,如果它的数据集时独立同分布的(i.i.d. independent and identically distributed),那么模型的效果最好。
独立同分布的数据可以简化常规机器学习模型的训练、提升机器学习模型的预测能力
因此,很多模型在将数据喂入机器学习模型之前,都会有一步“白化”(whitening)操作。
白化一般包含两个目的:
(1)去除特征之间的相关性 —> 独立;
(2)使得所有特征具有相同的均值和方差 —> 同分布。
1.2 内部协变量偏移(Internal Covariate Shift, ICS)
神经网络模型,尤其是深度神经网络模型,训练困难的一个重要原因是,深度神经网络涉及到很多层的叠加,而每一层的参数更新会导致上层的输入数据分布发生变化。
通过层层叠加,高层的输入分布变化相比于底层来说,回有很大的出入。
为了训好模型,我们需要非常谨慎地去设定学习率、初始化权重、以及尽可能细致的参数更新策略。
1.2.1 用公式解释ICS
统计机器学习中的一个经典假设是,“源空间(source domain)和目标空间(target domain)的数据分布是一致的。(如果不一致,那么就出现了新的机器学习问题,如 迁移学习transfer learning等)
而 ICS就是分布不一致假设之下的一个分支问题,它是指源空间和目标空间的条件概率是一致的,但是其边缘概率不同
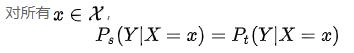

对于神经网络的各层输出,由于它们经过了层内操作作用,其分布会有很大的概率与各层对应的输入信号分布不同(所以 )。
)。
这个层内输出和输入之间的差异会随着网络深度增大而增大。可是它们所能“指示”的样本标记(即P(Y|X),已知输入X之后的输出Y)仍然是不变的。
1.2.2 ICS的问题
- 神经网络不同层的参数需要不断适应新的输入数据分布,降低学习速度。
- 下层输入的变化可能趋向于变大或者变小,导致上层落入饱和区(比如下层的输出很大,上层又接了一个tanh激活函数,上层输出没有什么区别),使得学习过早停止
-
每层的更新都会影响到其它层,因此每层的参数更新策略需要尽可能的谨慎。
1.2.3 梯度饱和
sigmoid激活函数和tanh激活函数存在梯度饱和的区域,其原因是激活函数的输入值过大或者过小,其得到的激活函数的梯度值会非常接近于0,使得网络的收敛速度减慢
传统的方法是使用不存在梯度饱和区域的激活函数,例如ReLU等。
batch normalization(BN)也可以缓解梯度饱和的问题,它的策略是在调用激活函数之前将Wx+b 的值归一化到梯度值比较大的区域。
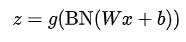
2 Batch normalization
本小节主要来自:【 深度学习李宏毅 】 Batch Normalization (中文)_哔哩哔哩_bilibili
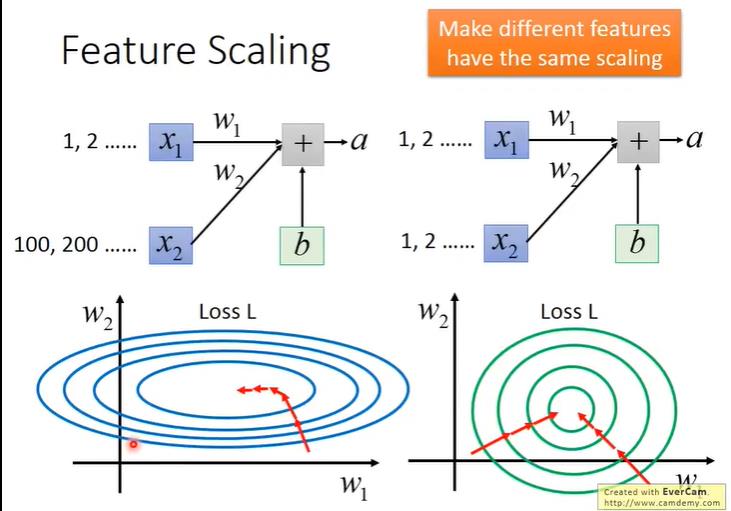
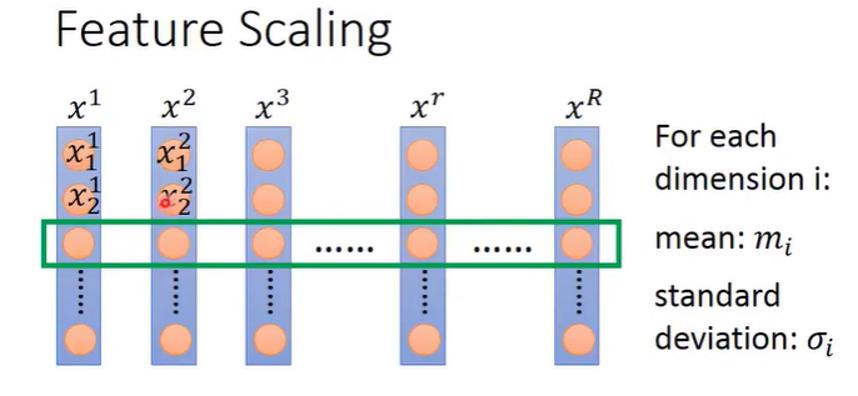
2.1 feature scaling
我们回想一下之前说的feature scaling(机器学习笔记:梯度下降_UQI-LIUWJ的博客-CSDN博客)
假设参数x1和参数x2的重要性是一样的,但是由于x2参数的数量级远远大于x1参数,所以如果w1,w2同等变化的话,x2对于loss的影响会更大。
这种情况我们可以对不同变量设置不同的learning rate,但是这样的话,比较繁琐,而且参数量多的情况下也不一定好做。
于是我们对参数进行normalization的方法,将x1和x2参数都归一化到相同的数量级(相同的分布)【如上图右所示】,此时w1,w2同等变化的时候,x1,x2对loss的影响相似。
于是对输入参数x1,x2,...xn,我们对参数的每一个维度,计算一个均值一个标准差,将参数的每一个维度分别进行归一化。
2.2 batch normalization的引入
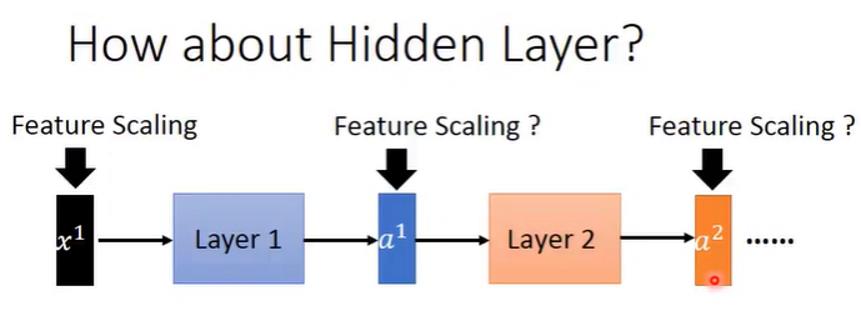
现在我们有很多层的神经网络。我们从layer2的角度看,layer1的输出a1,就是layer2的输入。
那么对于layer2来说,我们也希望它的输入也可以被normalize一下。
但是,此时layer2的输入和layer1的输入不同之处在于,layer1的输入就是整个模型的输入,取决于数据集,是固定不变的。
但是随着网络的不断训练,layer1参数的不断更新,layer2的输入也会相应的一直变动,于是我们需要在训练过程中不断地计算均值和方差。
这时候我们就需要一种技术来计算均值和方差,这种技术就是batch normalization
2.3 Batch
在开始介绍batch normalization之前,我们再回顾一下batch的知识。
在数据集很大的时候,我们一般会挑出一些数据组成一个batch,来更新神经网络各层的参数(SGD,stochastic gradient descent)
以上图为例,我们的batch_size=3,那么每一次我们选择三条数据x1,x2,x3,就会分别取计算它们经过神经网络之后的output,然后利用output反向传播更新参数
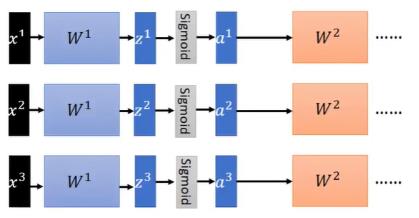
而如果我们在GPU上进行这个training的操作,GPU会把一个batch的数据contact起来,拼成一个大矩阵,然后将这个大矩阵和神经网络中的各个参数进行运算操作。
这也是GPU可以加速运算的一个方面

2.4 batch normalization
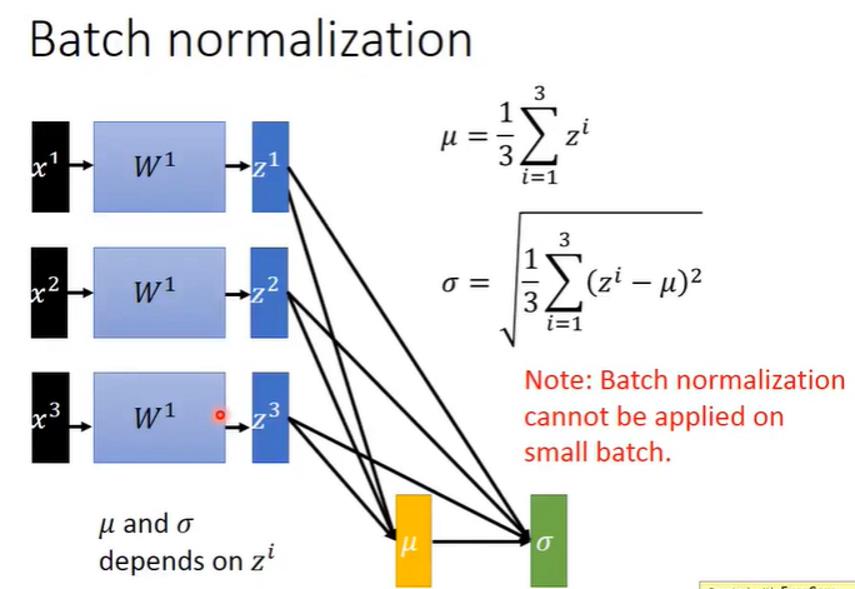
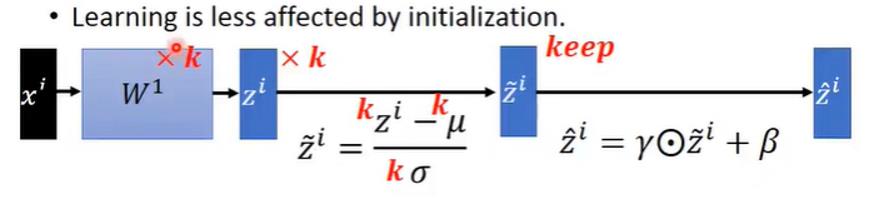
下图是一个很简略的batch normalization的示意。注意这里的μ,σ都是Z的每一个维度计算一个相应的值(换句话说,μ和σ都是向量。向量的每一个维度相当于对应维度Z的均值和方差)
假设一个批量有 m 个样本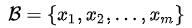 ,每个样本有d个特征。那么这个批量的每个样本第 k 个特征的归一化后的值为
,每个样本有d个特征。那么这个批量的每个样本第 k 个特征的归一化后的值为
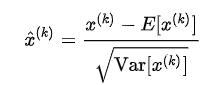
一般来说,都是先batch normalization,再进行激活函数。
理论上,μ和σ应该是整个数据集的μ和σ。但是实际操作中,一般都是一个batch算一个μ和一个σ。因为如果算整个数据集的话,会有两点弊端:
- 数据集可能很大,计算会很耗时
- 由于训练的时候,W也是在batch与batch之间不断更新的。所以一个很大的数据集里面,不同的batch遇到的W是不一样的
2.4.1 Batch normalization 反向传播
现在有一个问题:batch normalization怎么反向传播?
如果认为,减去的μ和除掉的σ都是常数,所以和原来不用normalization的情况下一样反向传播,那就错了。 因为这里的μ和σ都是通过z来计算得到的,并不是一个常数。
我们可以想成:在原来的基础上,多了计算μ、计算σ以及计算归一化结果三个神经网络层(只不过这三个神经网络层的参数是不用更新的)
所以我们反向传播的时候,误差也要经过这三个“神经网络层”
2.4.2 batch normalization 变体
对于某些激活函数来说,可能别的均值和方差比N(0,1)要好一些
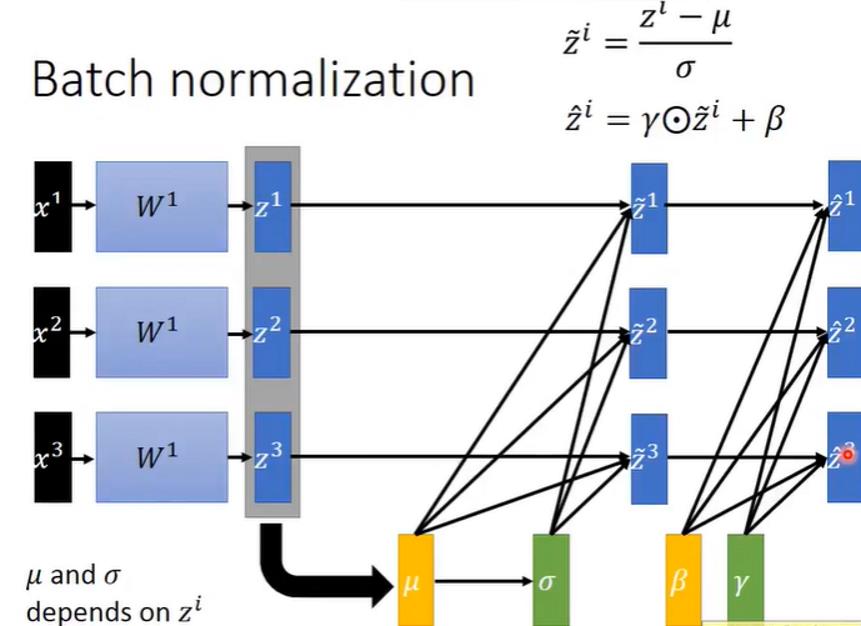
这是我们也可以接上一个类似于全连接层的东西,是z从N(0,1)变换到N(γ,β)
如果γ=σ,μ=β,那么是不是batch normalization就没有意义了?
其实不是,μ和σ是根据z求出来的,而γ和μ则是神经网络根据自身特点决定的
2.4.3 batch normalization的testing
test的时候,只有一笔数据,不好估计它的均值和方差
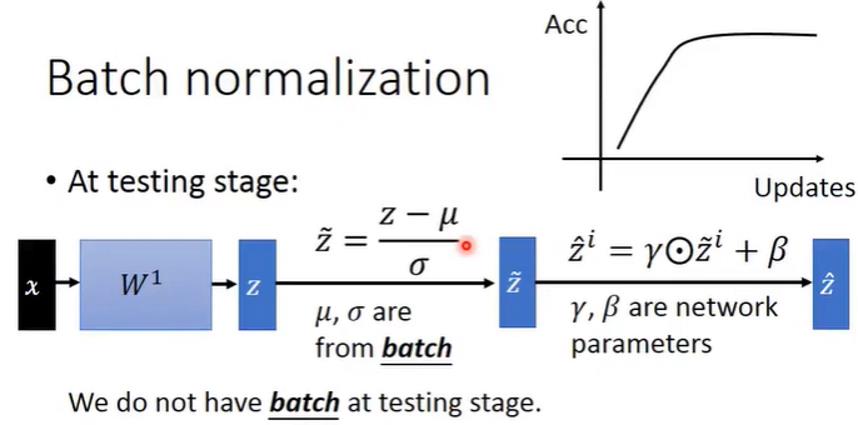
这里有两个方法:
1)训练好神经网络之后,再用所有的训练集求得各层z对应的μ和σ(当traing data很大的时候,不太适用)
2)记录训练过程中的μ,加权就和(一开始的权重少,后来的权重大)

2.5 Batch normalization的优点
1)解决了ICS的问题,这就可以让我们的学习率大一点
2)缓解了梯度爆炸
3)参数初始化的影响很小了
3 layer normalization
本节参考:NLP中 batch normalization与 layer normalization - 知乎 (zhihu.com)
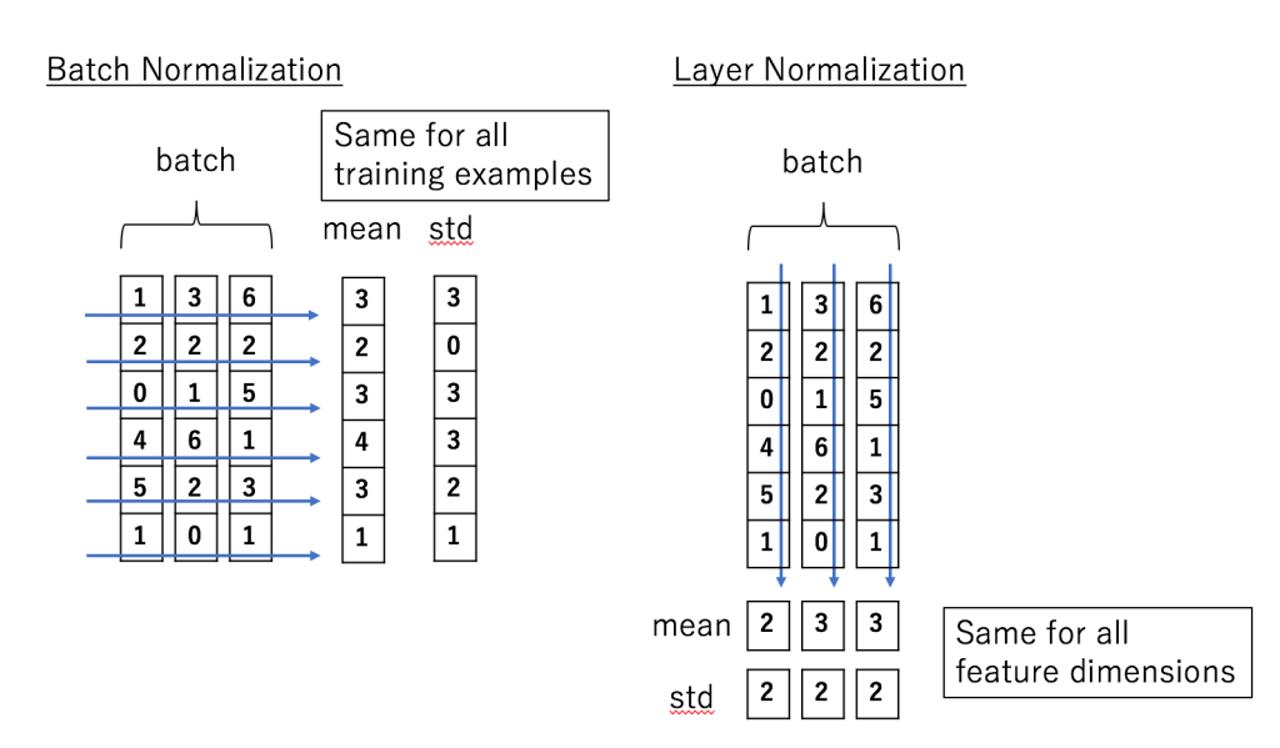
相比于batch normalization,layer normalization要做的事情是:对于每一个变量,将这个变量的所有的特征进行缩放 ,使得这些特征满足N(0,1)
以NLP 为例
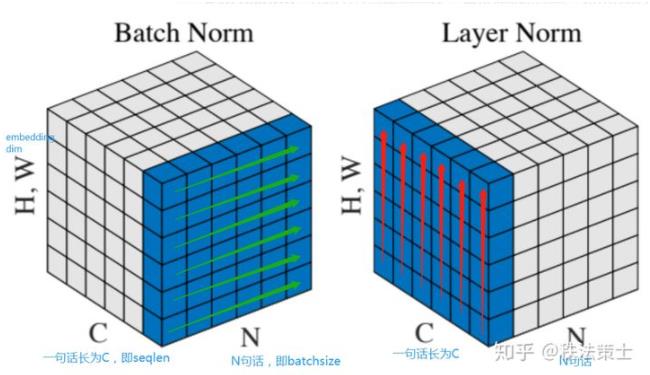
假设我一句话的维度是:[N,C,HW],对应的是 [batchsize, seq_len, dims]
batch normalization可以看成:我一共C(seq_len)个不同的特征,一共N*HW个(batch_size*dims)参数。每次将C个特征中的一个,即N*HW个参数进行归一化操作

layer normalization可以看成:我一共C*HW(seq_len*dims)个不同的特征,一共N个(batch_size)参数。每次将N个参数中的一个,即C*HW(seq_len*dims)个不同的特征进行归一化操作
4 normalization适用场景
| batch normalization ——一个特征一趟归一化 | 每个 mini-batch 比较大,数据分布比较接近。 BN 需要在运行过程中统计每个 mini-batch 的一阶统计量和二阶统计量,因此不适用于 动态的网络结构 和 RNN 网络 |
| layer normalization ——一个样本一趟归一化 | N 针对单个训练样本进行,不依赖于其他数据,因此可以避免 BN 中受 mini-batch 数据分布影响的问题,可以用于 小 mini-batch 场景、动态网络场景和 RNN,特别是自然语言处理领域。 LN 不需要保存 mini-batch 的均值和方差,节省了额外的存储空间。 ***BN 的转换是针对单个神经元可训练的——不同神经元的输入经过再平移和再缩放后分布在不同的区间,而 LN 对于一整层的神经元训练得到同一个转换——所有的输入都在同一个区间范围内。如果不同输入特征不属于相似的类别(比如颜色和大小),那么 LN 的处理可能会降低模型的表达能力。 |
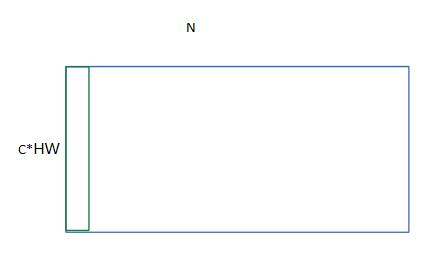
N——一个batch的通道个数;C一个样本的特征数量
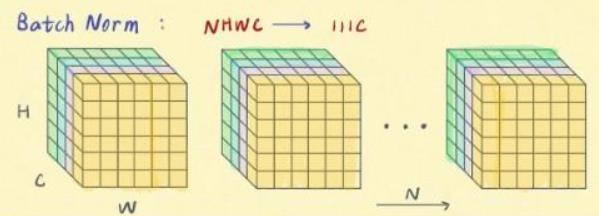
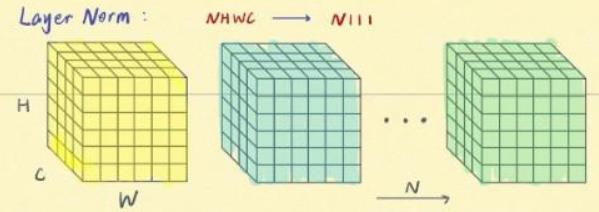
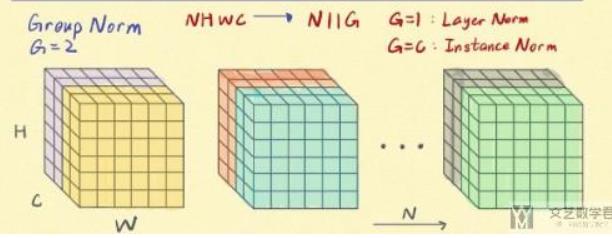
上面三张图来自BatchNorm, LayerNorm, InstanceNorm和GroupNorm总结 | 文艺数学君 (mathpretty.com)
可以看到,只有Batch normalization是和batch的大小有关的
参考文献:
详解深度学习中的Normalization,BN/LN/WN - 知乎 (zhihu.com)
NLP中 batch normalization与 layer normalization - 知乎 (zhihu.com)
【 深度学习李宏毅 】 Batch Normalization (中文)_哔哩哔哩_bilibili
BatchNorm, LayerNorm, InstanceNorm和GroupNorm总结 | 文艺数学君 (mathpretty.com)
以上是关于机器学习笔记:神经网络层的各种normalization的主要内容,如果未能解决你的问题,请参考以下文章
机器学习笔记:MLP的万能逼近特性( Universal Approximation Property)
Neural Networks: Learning 学习笔记
[机器学习] UFLDL笔记 - Convolutional Neural Network - 矩阵运算
[机器学习] UFLDL笔记 - Convolutional Neural Network - 矩阵运算