Pytorch Note50 Gym 介绍
Posted 风信子的猫Redamancy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pytorch Note50 Gym 介绍相关的知识,希望对你有一定的参考价值。
Pytorch Note50 Gym 介绍
全部笔记的汇总贴: Pytorch Note 快乐星球
在前面的笔记中,简单的介绍了强化学习的例子,但是我们会发现构建强化学习的环境非常麻烦,需要耗费我们大量的时间,这个时候我们可以使用一个开源的工具,叫做 gym,是由 open ai 开发的。
在这个库中从简单的走格子到毁灭战士,提供了各种各样的游戏环境可以让大家放自己的 AI 进去玩耍。取名叫 gym 也很有意思,可以想象一群 AI 在健身房里各种锻炼,磨练技术。
使用起来也非常方便,首先在终端内输入如下代码进行安装。
# Github源
git clone https://github.com/openai/gym
cd gym
pip install -e .[all]
# 直接下载gym包
pip install gym[all]
我们可以访问这个页面看到 gym 所包含的环境和介绍。
在上面的环境页面,可以 gym 内置了很多环境,我们可以使用前面讲过的 q learning 尝试一个 gym 中的小例子,mountain car。
mounttain car
这是这样一个问题,一辆汽车在一维轨道上,位于两座“山”之间。 目标是在右边开车上山; 然而,这辆车的引擎不够强劲,无法一次性翻越这座山。 因此,成功的唯一方法是来回驱动以积聚动力。
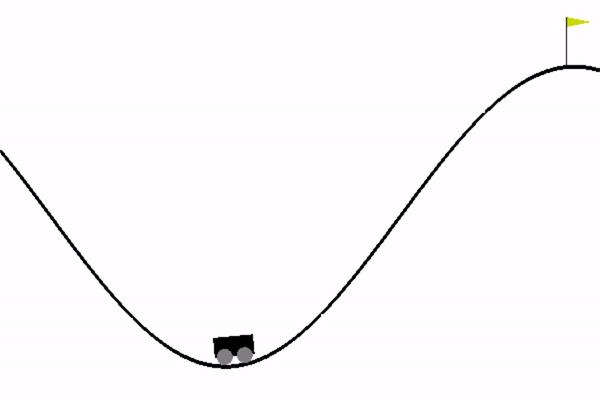
在 mounttain car,我们能够观察到环境中小车的位置,也就是坐标,我们能够采取的动作是向左或者向右。
为了使用 q learning,我们必须要建立 q 表,而这里的状态空间是连续不可数的,所以我们需要离散化连续空间,将 x 坐标和 y 坐标都平均分成很多份,具体的实现可以运行 mount-car.py 看看结果。
代码如下
import numpy as np
import gym
n_states = 40 # 取样 40 个状态
iter_max = 10000
initial_lr = 1.0 # Learning rate
min_lr = 0.003
gamma = 1.0
t_max = 10000
eps = 0.02
def run_episode(env, policy=None, render=False):
obs = env.reset()
total_reward = 0
step_idx = 0
for _ in range(t_max):
if render:
env.render()
if policy is None: # 如果没有策略,就随机取样
action = env.action_space.sample()
else:
a, b = obs_to_state(env, obs)
action = policy[a][b]
obs, reward, done, _ = env.step(action)
total_reward += gamma ** step_idx * reward
step_idx += 1
if done:
break
return total_reward
def obs_to_state(env, obs):
"""
将观察的连续环境映射到离散的输入的状态
"""
env_low = env.observation_space.low
env_high = env.observation_space.high
env_dx = (env_high - env_low) / n_states
a = int((obs[0] - env_low[0]) / env_dx[0])
b = int((obs[1] - env_low[1]) / env_dx[1])
return a, b
if __name__ == '__main__':
env_name = 'MountainCar-v0'
env = gym.make(env_name)
env.seed(0)
np.random.seed(0)
print('----- using Q Learning -----')
q_table = np.zeros((n_states, n_states, 3))
for i in range(iter_max):
obs = env.reset()
total_reward = 0
## eta: 每一步学习率都不断减小
eta = max(min_lr, initial_lr * (0.85 ** (i // 100)))
for j in range(t_max):
x, y = obs_to_state(env, obs)
if np.random.uniform(0, 1) < eps: # greedy 贪心算法
action = np.random.choice(env.action_space.n)
else:
logits = q_table[x, y, :]
logits_exp = np.exp(logits)
probs = logits_exp / np.sum(logits_exp) # 算出三个动作的概率
action = np.random.choice(env.action_space.n, p=probs) # 依概率来选择动作
obs, reward, done, _ = env.step(action)
total_reward += reward
# 更新 q 表
x_, y_ = obs_to_state(env, obs)
q_table[x, y, action] = q_table[x, y, action] + eta * (
reward + gamma * np.max(q_table[x_, y_, :]) -
q_table[x, y, action])
if done:
break
if i % 100 == 0:
print('Iteration #%d -- Total reward = %d.' % (i + 1,
total_reward))
solution_policy = np.argmax(q_table, axis=2) # 在 q 表中每个状态下都取最大的值得动作
solution_policy_scores = [
run_episode(env, solution_policy, False) for _ in range(100)
]
print("Average score of solution = ", np.mean(solution_policy_scores))
# Animate it
run_episode(env, solution_policy, True)
----- using Q Learning ----- Iteration #1 -- Total reward = -200. Iteration #101 -- Total reward = -200. Iteration #201 -- Total reward = -200. Iteration #301 -- Total reward = -200. Iteration #401 -- Total reward = -200. Iteration #501 -- Total reward = -200. Iteration #601 -- Total reward = -200. Iteration #701 -- Total reward = -200. Iteration #801 -- Total reward = -200. Iteration #901 -- Total reward = -200. Iteration #1001 -- Total reward = -200. Iteration #1101 -- Total reward = -200. Iteration #1201 -- Total reward = -200. Iteration #1301 -- Total reward = -200. Iteration #1401 -- Total reward = -200. Iteration #1501 -- Total reward = -200. Iteration #1601 -- Total reward = -200. Iteration #1701 -- Total reward = -200. Iteration #1801 -- Total reward = -200. Iteration #1901 -- Total reward = -200. Iteration #2001 -- Total reward = -200. Iteration #2101 -- Total reward = -200. Iteration #2201 -- Total reward = -200. Iteration #2301 -- Total reward = -200. Iteration #2401 -- Total reward = -200. Iteration #2501 -- Total reward = -200. Iteration #2601 -- Total reward = -200. Iteration #2701 -- Total reward = -200. Iteration #2801 -- Total reward = -200. Iteration #2901 -- Total reward = -200. Iteration #3001 -- Total reward = -200. Iteration #3101 -- Total reward = -200. Iteration #3201 -- Total reward = -200. Iteration #3301 -- Total reward = -200. Iteration #3401 -- Total reward = -200. Iteration #3501 -- Total reward = -200. Iteration #3601 -- Total reward = -200. Iteration #3701 -- Total reward = -200. Iteration #3801 -- Total reward = -200. Iteration #3901 -- Total reward = -200. Iteration #4001 -- Total reward = -200. Iteration #4101 -- Total reward = -200. Iteration #4201 -- Total reward = -200. Iteration #4301 -- Total reward = -200. Iteration #4401 -- Total reward = -200. Iteration #4501 -- Total reward = -200. Iteration #4601 -- Total reward = -200. Iteration #4701 -- Total reward = -200. Iteration #4801 -- Total reward = -200. Iteration #4901 -- Total reward = -200. Iteration #5001 -- Total reward = -200. Iteration #5101 -- Total reward = -200. Iteration #5201 -- Total reward = -200. Iteration #5301 -- Total reward = -200. Iteration #5401 -- Total reward = -200. Iteration #5501 -- Total reward = -200. Iteration #5601 -- Total reward = -200. Iteration #5701 -- Total reward = -200. Iteration #5801 -- Total reward = -200. Iteration #5901 -- Total reward = -200. Iteration #6001 -- Total reward = -200. Iteration #6101 -- Total reward = -200. Iteration #6201 -- Total reward = -200. Iteration #6301 -- Total reward = -200. Iteration #6401 -- Total reward = -200. Iteration #6501 -- Total reward = -200. Iteration #6601 -- Total reward = -200. Iteration #6701 -- Total reward = -200. Iteration #6801 -- Total reward = -200. Iteration #6901 -- Total reward = -200. Iteration #7001 -- Total reward = -200. Iteration #7101 -- Total reward = -200. Iteration #7201 -- Total reward = -200. Iteration #7301 -- Total reward = -200. Iteration #7401 -- Total reward = -200. Iteration #7501 -- Total reward = -200. Iteration #7601 -- Total reward = -200. Iteration #7701 -- Total reward = -200. Iteration #7801 -- Total reward = -200. Iteration #7901 -- Total reward = -200. Iteration #8001 -- Total reward = -198. Iteration #8101 -- Total reward = -200. Iteration #8201 -- Total reward = -200. Iteration #8301 -- Total reward = -200. Iteration #8401 -- Total reward = -200. Iteration #8501 -- Total reward = -200. Iteration #8601 -- Total reward = -200. Iteration #8701 -- Total reward = -200. Iteration #8801 -- Total reward = -200. Iteration #8901 -- Total reward = -200. Iteration #9001 -- Total reward = -200. Iteration #9101 -- Total reward = -200. Iteration #9201 -- Total reward = -200. Iteration #9301 -- Total reward = -200. Iteration #9401 -- Total reward = -200. Iteration #9501 -- Total reward = -200. Iteration #9601 -- Total reward = -200. Iteration #9701 -- Total reward = -200. Iteration #9801 -- Total reward = -200. Iteration #9901 -- Total reward = -200. Average score of solution = -129.96
如果运行完之后,可以看到 q 表的收敛非常慢,reward 一直都很难变化,我们需要很久才能将小车推到终点,这个时候我们需要一个更加强大的武器,那就 deep q network。
以上是关于Pytorch Note50 Gym 介绍的主要内容,如果未能解决你的问题,请参考以下文章