加性注意力机制训练推理效率优于其他Transformer变体,这个Fastformer的确够快...
Posted Charmve
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了加性注意力机制训练推理效率优于其他Transformer变体,这个Fastformer的确够快...相关的知识,希望对你有一定的参考价值。
点击上方“迈微AI研习社”,选择“星标★”公众号
重磅干货,第一时间送达
来源丨机器之心
从训练与推理效率来看,清华和微软亚研提出的 Fastformer 无愧于「fast」。
在过去的几年里,Transformer 及其变体在很多领域取得了巨大成功,但由于其复杂度与序列长度的二次方成正比,它的计算效率并不高。虽然之前已经有很多研究致力于 Transformer 的加速,但在遇到长序列时,这些方法要么低效,要么无效。
在这篇论文中,来自清华大学、微软亚洲研究院的研究者提出了一种基于加性注意力的 Transformer 变体——Fastformer,它能以线性复杂度实现有效的上下文建模。

论文链接:https://arxiv.org/pdf/2108.09084.pdf
在这个模型中,研究者首先使用加性注意力机制对全局上下文进行建模,然后根据每个 token 表示与全局上下文表示的交互进一步转换这些 token 表示。通过这种方式,Fastformer 能够以线性复杂度实现高效的上下文建模。
为了检验 Fastformer 的效果,研究者在五个基准数据集上进行了多个任务的实验,包括情感分类、话题预测、新闻推荐和文本摘要。实验结果表明,Fastformer 比很多 Transformer 模型都要高效,在长文本建模中取得了非常有竞争力的结果。
论文公布之后,Youtube 知名深度学习频道 Yannic Kilcher 对该文章进行了解读。
视频来源:https://www.youtube.com/watch?v=qgUegkefocg
架构细节
Fastformer 的整体架构如下图所示。
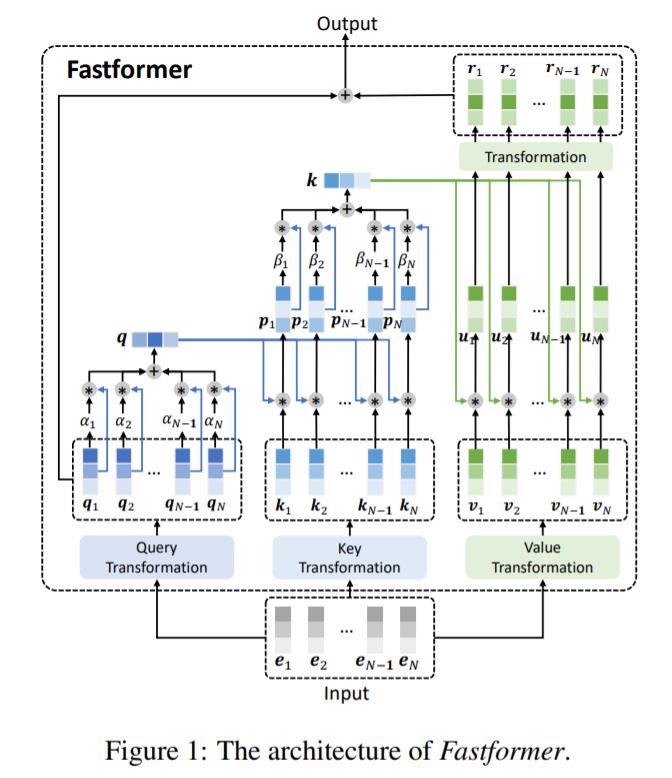
在该模型中,研究者首先使用加性注意力机制将输入注意力查询矩阵归纳为一个全局查询向量,然后通过逐元素积建模注意力键和全局查询向量之间的交互,以学习全局上下文感知的键矩阵,并通过加性注意力将其归纳为一个全局键向量。接下来,他们使用逐元素积来聚合全局键和注意力值,再通过线性变换来处理它们,以计算全局上下文感知的注意力值。最后,他们将原始的注意查询和全局上下文感知的注意值相加,形成最终输出。具体细节如下。
Fastformer 模型首先将输入嵌入矩阵转换为查询、键和值序列。输入矩阵记为 E ∈ R^(N×d),其中 N 为序列长度,d 为隐藏维度。其从属向量表示为 [e_1, e_2, ..., e_N ]。遵循标准 Transformer,每个注意力头使用 3 个独立的线性变换层将输入转换为注意力查询、键和值矩阵 Q, K, V∈R^(d×d),即 Q = [q_1, q_2,…],K = [k_1, k_2,…, k_N] 和 V = [v_1, v_2,…, v_N]。
基于注意力查询、键和值之间的交互对输入序列的上下文信息进行建模是类似 Transformer 架构的关键问题。在 vanilla Transformer 中,点积注意力机制用于对查询和键之间的交互进行全面建模。不幸的是,它的二次复杂性使得它在长序列建模中效率低下。降低计算复杂度的一个潜在方法是在对注意力矩阵(如查询)进行交互建模之前对其进行总结。
加性注意力是注意力机制的一种形式,它可以在线性复杂度的序列中有效地总结重要信息。因此,该研究首先使用加性注意力将查询矩阵总结为一个全局查询向量 q∈R^(d×d),该向量压缩了注意力查询中的全局上下文信息。具体来说,第 i 个查询向量的注意力权重α_i 计算如下:
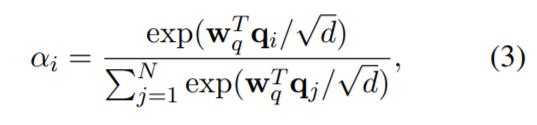
其中,w_q∈R^d 为可学习的参数向量,全局注意力查询向量的计算如下:
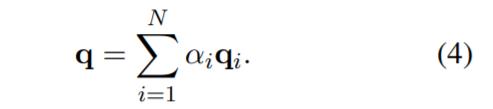
Fastformer 的一个核心问题是如何对总结的全局查询向量与键矩阵进行交互建模。有几个直观的选项,例如将全局查询添加或连接到键矩阵中的每个向量。然而,这样不能区别全局查询对不同键的影响,这不利于理解上下文。逐元素积是对两个向量之间的非线性关系建模的有效操作。因此,该研究使用全局查询向量和每个键向量之间的逐元素积来建模它们的交互,并将它们组合成一个全局上下文感知的键矩阵。矩阵中的第 i 个向量表示为 p_i,公式表示为 p_i = q∗k_i。
同样的,考虑到效率原因,该研究使用加性注意机制来总结全局上下文感知键矩阵。其中第 i 个向量的加性注意力权值计算如下:
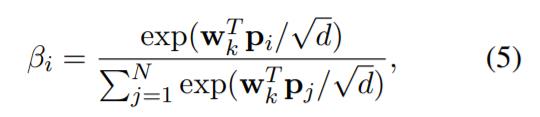
其中 w_k∈r^d 为注意力参数向量。全局键向量 k ∈ R^d 计算如下:

最后,该研究建立了注意力值矩阵与全局键向量之间的交互模型,以更好地进行上下文建模。与查询 - 键交互建模类似,该研究还将全局键和每个值向量之间的元素进行乘积,以计算键 - 值交互向量 u_i,其表达式为 u_i = k∗v_i。受 vanilla Transformer 影响,该研究还将线性变换层用于每个键 - 值交互向量,来学习其隐藏表示。这一层的输出矩阵记为 R = [r_1, r_2, ..., r_N ] ∈ R^(N×d)。这个矩阵与查询矩阵进一步相加,形成 Fastformer 的最终输出。
在 Fastformer 中,每个键和值向量都可以与全局查询或键向量交互以学习上下文表示。通过叠加多个 Fastformer 层,可以完全建模上下文信息。受 (Wang et al., 2020b)研究中使用权值共享技术的启发,该研究通过共享值和查询转换参数以降低内存成本。此外,该研究还在不同的 Fastformer 层之间共享参数,以进一步减小参数大小并降低模型过度拟合的风险。
实验
研究者在五个基准数据集上针对不同任务进行了大量实验,这五个数据集是 Amazon、IMDB、MIND、CNN/DailyMail 和 PubMed。
下表 1 为情感与新闻主题分类数据集 Amazon、IMDB 和 MIND。

下表 3 为文本摘要数据集 CNN/DailyMail 和 PubMed。

性能比较
研究者在 Amazon、IMDB 和 MIND 三个分类数据集上,对 Fastformer 与 Transformer、Longformer、BigBird、Linformer 以及 Linear Transformer 和 Poolingformer 等基准方法的性能进行了比较。
结果如下表 4 所示,他们发现高效的 Transformer 变体往往优于标准的 Transformer 模型。在长文本和短文本建模任务上,Fastformer 媲美或优于其他高效的 Transformer 变体,其原因在于 Fastformer 可以高效地建模全局上下文以及它们与不同 token 的关系,由此有助于准确地理解上下文信息。

研究者还对不同方法在新闻推荐任务上的性能进行了比较。如下表所示,Fastformer 在所有 Transformer 架构中实现 SOTA 性能,并优于基础 NRMS 模型。
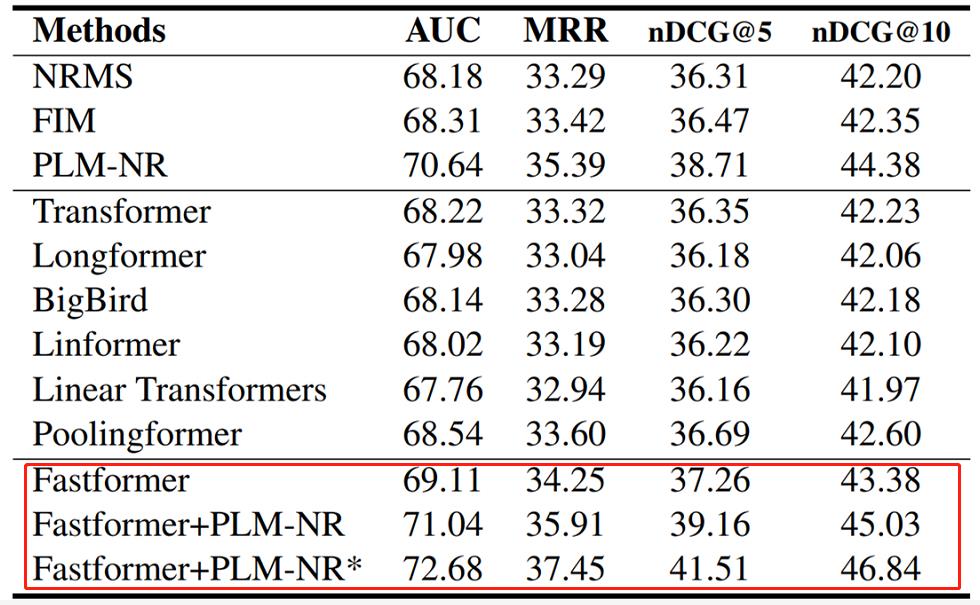
此外,Fastformer 进一步提升了 PLM-NR 的性能,两者组合的模型在 MIND 排行榜上实现了最佳结果。这些结果表明,Fastformer 不仅在文本建模方面非常高效,在理解用户兴趣方面也表现出色。
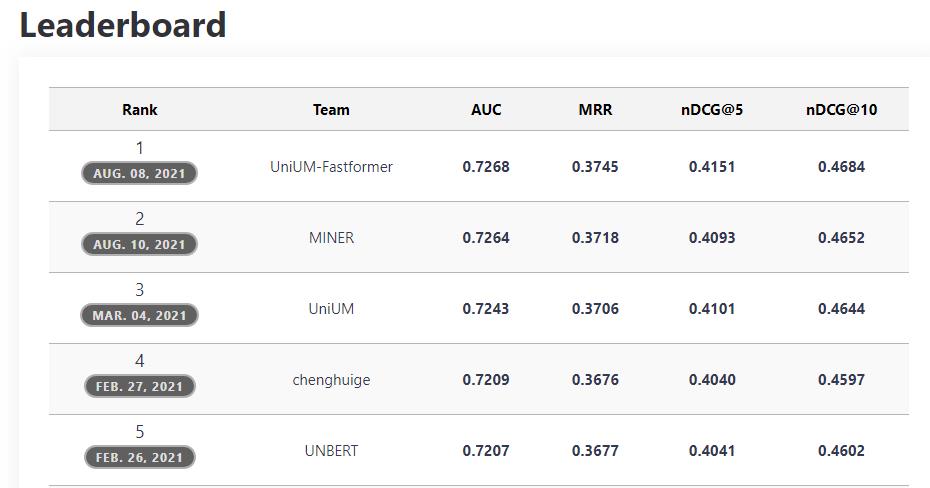
排行榜地址:https://msnews.github.io/
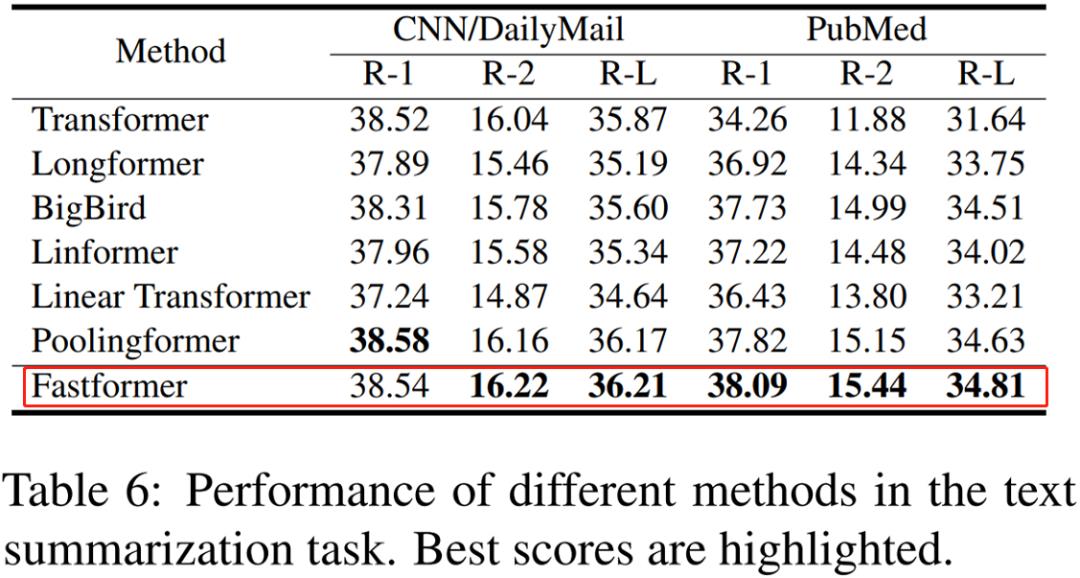
研究者在 CNN/DailyMail 和 PubMed 两个文本摘要任务上比较了 Fastformer 与其他 Transformer 变体模型在自然语言生成中的有效性。结果如下表 6 所示,Fastformer 在大多数指标上都实现了 SOTA 性能,显示出其在自然语言生成中的优势。
效率比较
研究者评估了不同模型的效率。他们首先比较了不同模型的理论计算复杂度,如下表 7 所示,Fastformer 在理论上是高效的。

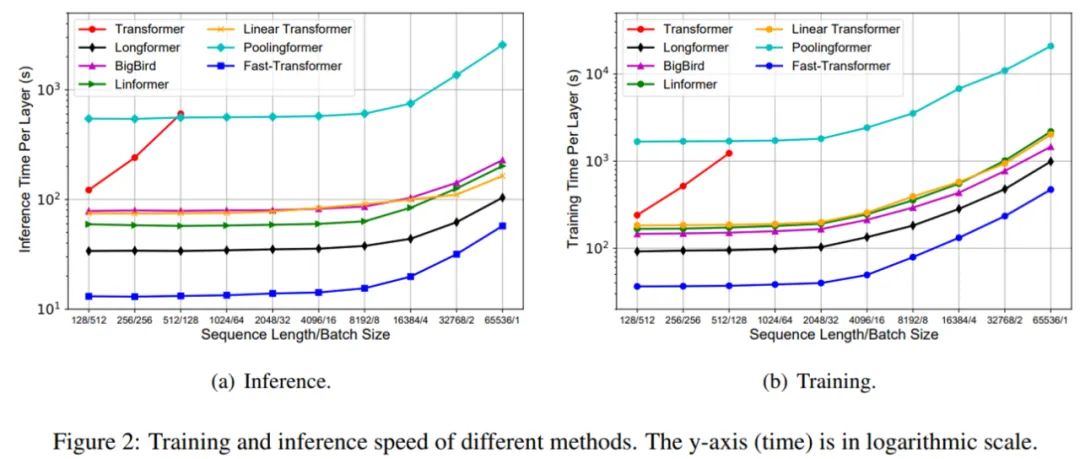
接着,研究者度量了不同模型的真实训练和推理成本。结果如下图 2 所示,Fastformer 在训练和推理时间上均显著优于其他线性复杂度 Transformer 变体,从而验证了 Fastformer 的效率。
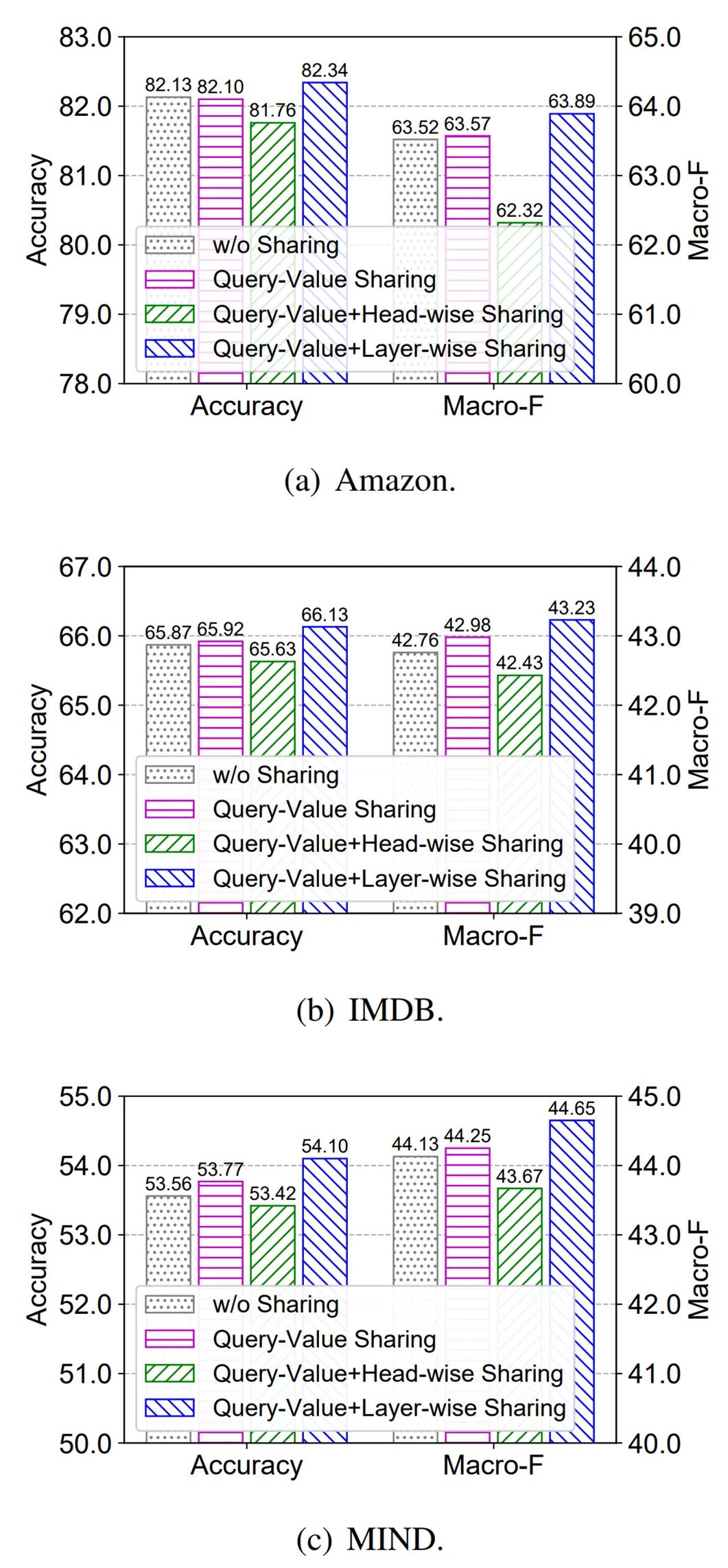
参数共享的影响
最后,研究者探究了不同参数共享方法对 Fastformer 性能的影响,这些方法包括共享查询和值变换矩阵、在不同注意力头之间共享参数和在不同层之间共享参数。结果如下图 4 所示,他们发现当使用查询 - 值参数共享时,Fastformer 模型的性能媲美或略优于未使用任何参数共享方法的情况。
作者简介

个人主页:https://wuch15.github.io/
该论文一作为武楚涵(Chuhan Wu),他是清华大学电子工程系博士研究生。武楚涵主要研究方向包括推荐系统、用户建模和社交媒体挖掘。他在人工智能、自然语言处理和数据挖掘领域相关会议和期刊上发表了多篇论文。仅 2021 年,他就发表了 7 篇顶会接收论文。

更多细节可参考论文原文,更多精彩内容请关注迈微AI研习社,每天晚上七点不见不散!

△长按添加迈微官方微信号
备注:姓名-学校/公司-研究方向-城市
(如:小C-北大-目标检测-北京)
推荐阅读
(点击标题可跳转阅读)
迈微AI研习社
微信号: MaiweiE_com
GitHub: @Charmve
CSDN、知乎: @Charmve
投稿: yidazhang1@gmail.com
主页: github.com/Charmve

如果觉得有用,就请点赞、转发吧!
以上是关于加性注意力机制训练推理效率优于其他Transformer变体,这个Fastformer的确够快...的主要内容,如果未能解决你的问题,请参考以下文章