翻译: 详细图解Transformer多头自注意力机制 Attention Is All You Need
Posted AI架构师易筋
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了翻译: 详细图解Transformer多头自注意力机制 Attention Is All You Need相关的知识,希望对你有一定的参考价值。
1. 前言
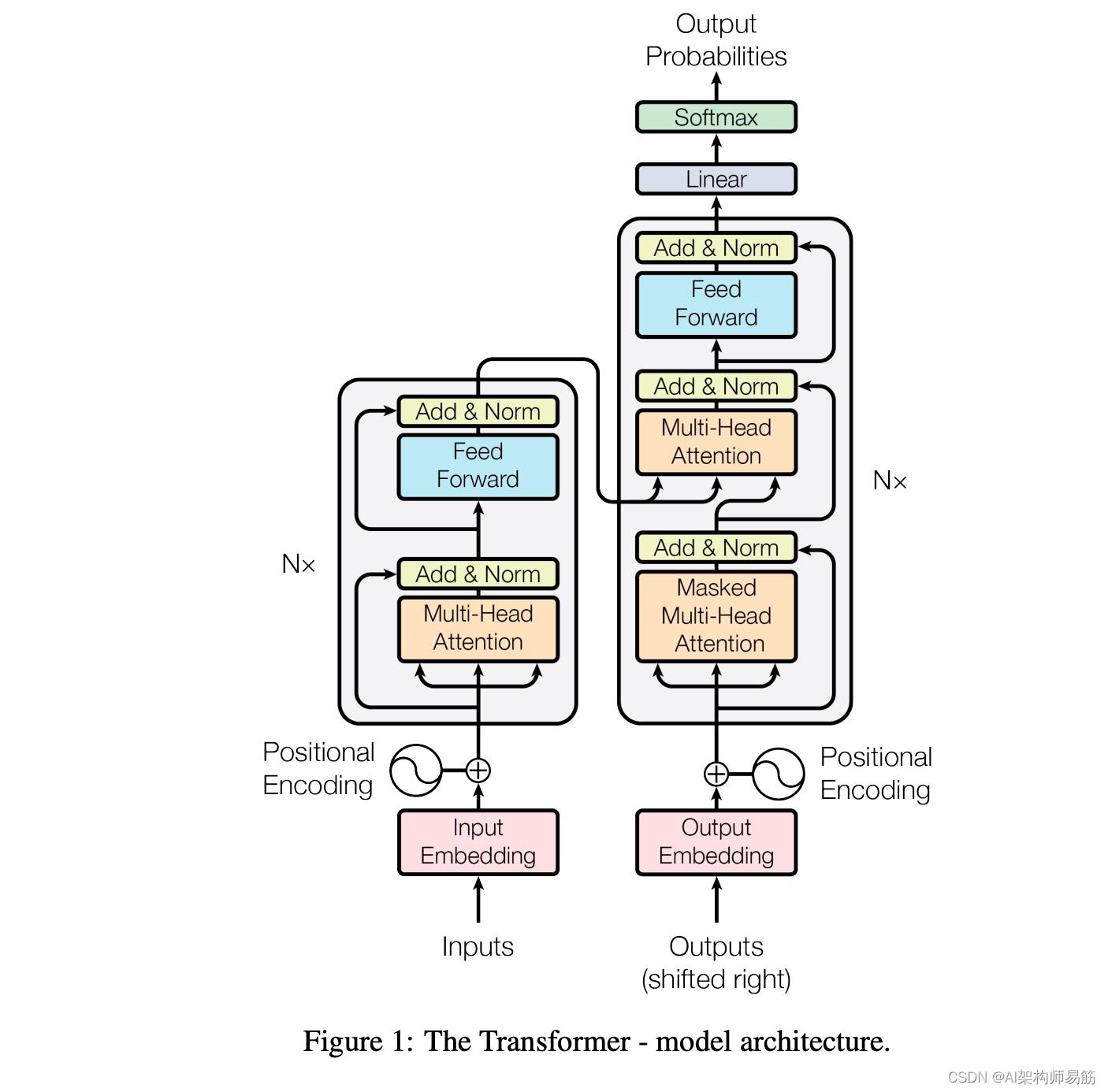
The Transformer——一个使用注意力来提高这些模型的训练速度的模型。Transformer 在特定任务中的表现优于谷歌神经机器翻译模型。然而,最大的好处来自于 The Transformer 如何使自己适合并行化。事实上,Google Cloud 建议使用 The Transformer 作为参考模型来使用他们的Cloud TPU产品。所以让我们试着把模型拆开,看看它是如何运作的。
Transformer 是在论文Attention is All You Need中提出的。它的 TensorFlow 实现作为Tensor2Tensor包的一部分提供。哈佛大学的 NLP 小组创建了一个指南,用 PyTorch 实现对论文进行注释。在这篇文章中,我们将尝试将事情过分简单化,并一一介绍这些概念,以期使没有深入了解该主题的人更容易理解。
Query,Key,Value的概念取自于信息检索系统,举个简单的搜索的例子来说。当你在某电商平台搜索某件商品(年轻女士冬季穿的红色薄款羽绒服)时,你在搜索引擎上输入的内容便是Query,然后搜索引擎根据Query为你匹配Key(例如商品的种类,颜色,描述等),然后根据Query和Key的相似度得到匹配的内容(Value)。
self-attention中的Q,K,V也是起着类似的作用,在矩阵计算中,点积是计算两个矩阵相似度的方法之一,因此式1中使用了 Q K T QK^T QKT 进行相似度的计算。接着便是根据相似度进行输出的匹配,这里使用了加权匹配的方式,而权值就是query与key的相似度。
下面是英语翻译成法语的Encoding和Decoding的例子,句子"I arrived at the"

2. 自注意力机制(self-Attention)和Transformer
自注意力(Attention)机制[2]由Bengio团队与2014年提出并在近年广泛的应用在深度学习中的各个领域,例如在计算机视觉方向用于捕捉图像上的感受野,或者NLP中用于定位关键token或者特征。谷歌团队近期提出的用于生成词向量的BERT[3]算法在NLP的11项任务中取得了效果的大幅提升,堪称2018年深度学习领域最振奋人心的消息。而BERT算法的最重要的部分便是本文中提出的Transformer的概念。
正如论文的题目所说的,Transformer中抛弃了传统的CNN和RNN,整个网络结构完全是由Attention机制组成。更准确地讲,Transformer由且仅由self-Attenion和Feed Forward Neural Network组成。一个基于Transformer的可训练的神经网络可以通过堆叠Transformer的形式进行搭建,作者的实验是通过搭建编码器和解码器各6层,总共12层的Encoder-Decoder,并在机器翻译中取得了BLEU值得新高。
作者采用Attention机制的原因是考虑到RNN(或者LSTM,GRU等)的计算限制为是顺序的,也就是说RNN相关算法只能从左向右依次计算或者从右向左依次计算,这种机制带来了两个问题:
- 时间片
t的计算依赖t-1时刻的计算结果,这样限制了模型的并行能力; - 顺序计算的过程中信息会丢失,尽管LSTM等门机制的结构一定程度上缓解了长期依赖的问题,但是对于特别长期的依赖现象,LSTM依旧无能为力。
Transformer的提出解决了上面两个问题,首先它使用了Attention机制,将序列中的任意两个位置之间的距离是缩小为一个常量;其次它不是类似RNN的顺序结构,因此具有更好的并行性,符合现有的GPU框架。论文中给出Transformer的定义是:Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequence aligned RNNs or convolution。
3. Transformer 简化架构图
让我们首先将模型视为一个黑盒子。在机器翻译应用程序中,它会用一种语言输入一个句子,然后用另一种语言输出它的翻译。例子:法语翻译为英语。

简化Transformer的优点,我们会看到一个编码组件Encoders、一个解码组件Decoders以及它们之间的连接。
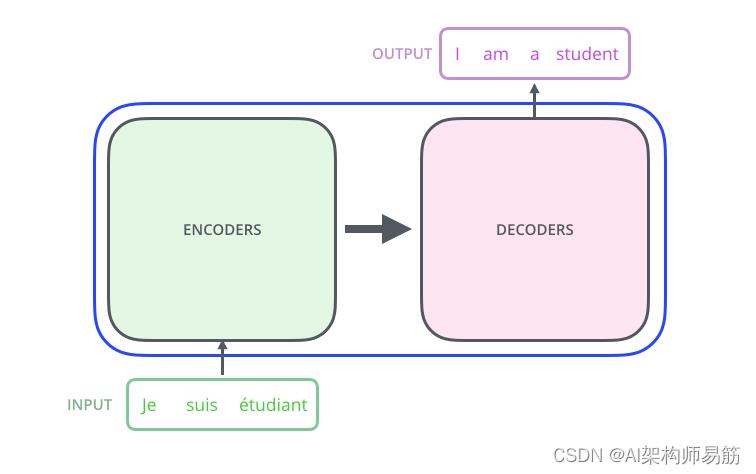
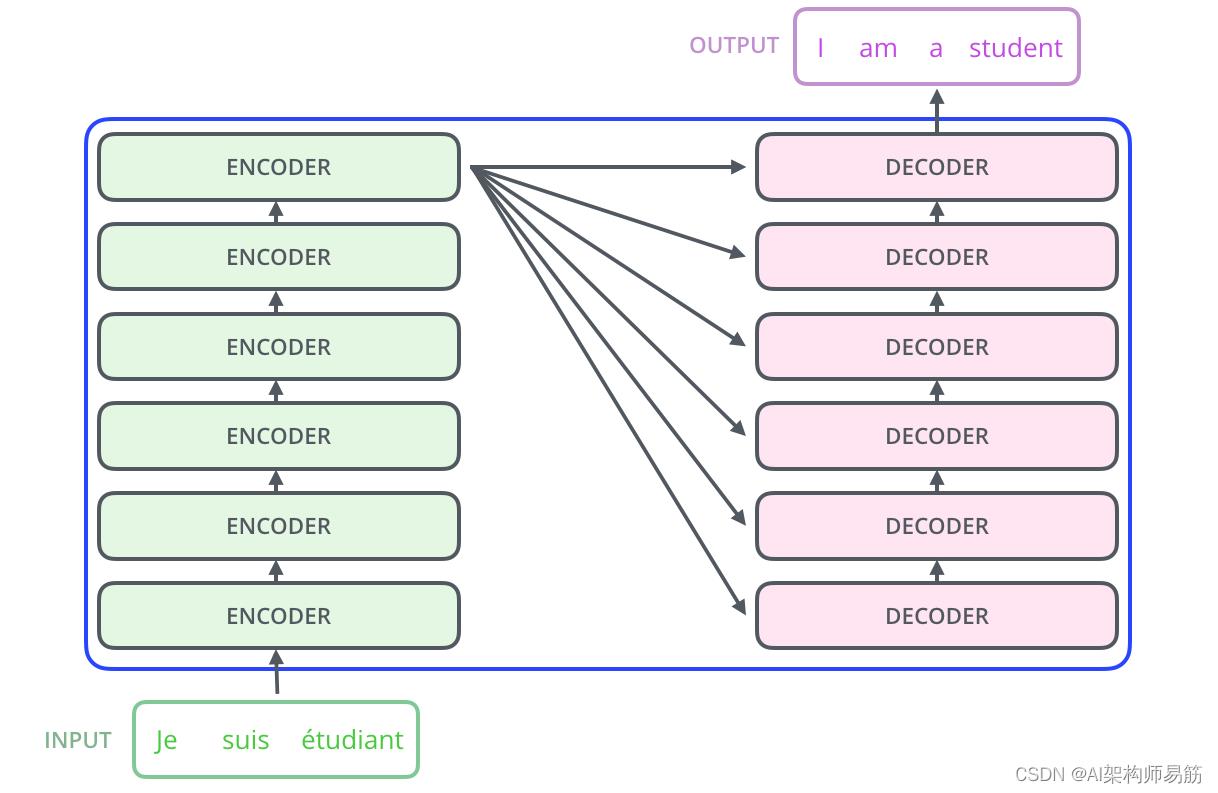
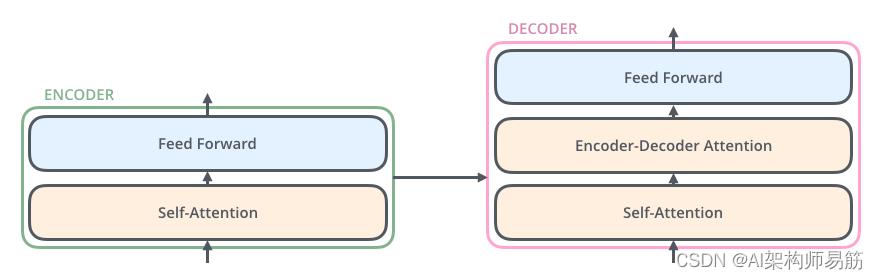
Encoder编码组件是一堆编码器(论文上将其中六个堆叠在一起——数字 6 并没有什么神奇之处,当然可以尝试其他排列方式)。解码组件是一堆相同数量的解码器。
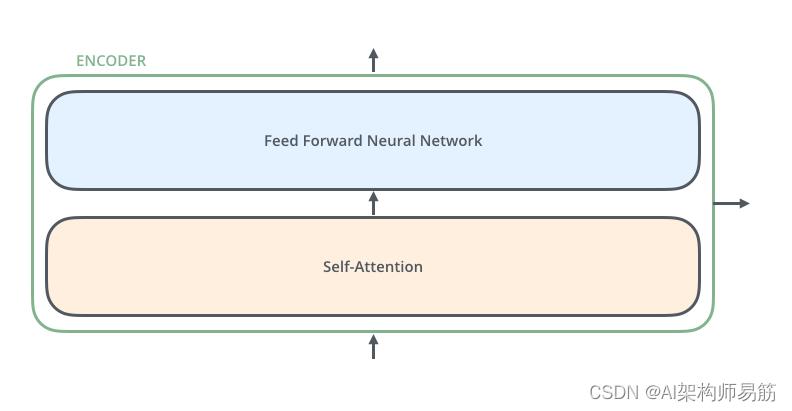
Encoder编码器在结构上都是相同的(但它们不共享权重)。每一个都分为两个子层:
-
编码器的输入首先流经自注意力层Self-Attention——该层帮助编码器在对特定单词进行编码时查看输入句子中的其他单词。我们将在后面的文章中仔细研究自注意力层。
-
自注意力层的输出被馈送到前馈神经网络Feed Forward Neural Network。完全相同的前馈网络独立应用于每个位置。
解码器具有这两个层,但在它们之间多了一个注意力层Encoder-Decoder Attention,帮助解码器专注于输入句子的相关部分(类似于seq2seq 模型中的注意力)。
4. 输入编码
现在我们已经了解了模型的主要组件,让我们开始研究各种向量/张量Tensor以及它们如何在这些组件之间流动,以将训练模型的输入转化为输出。
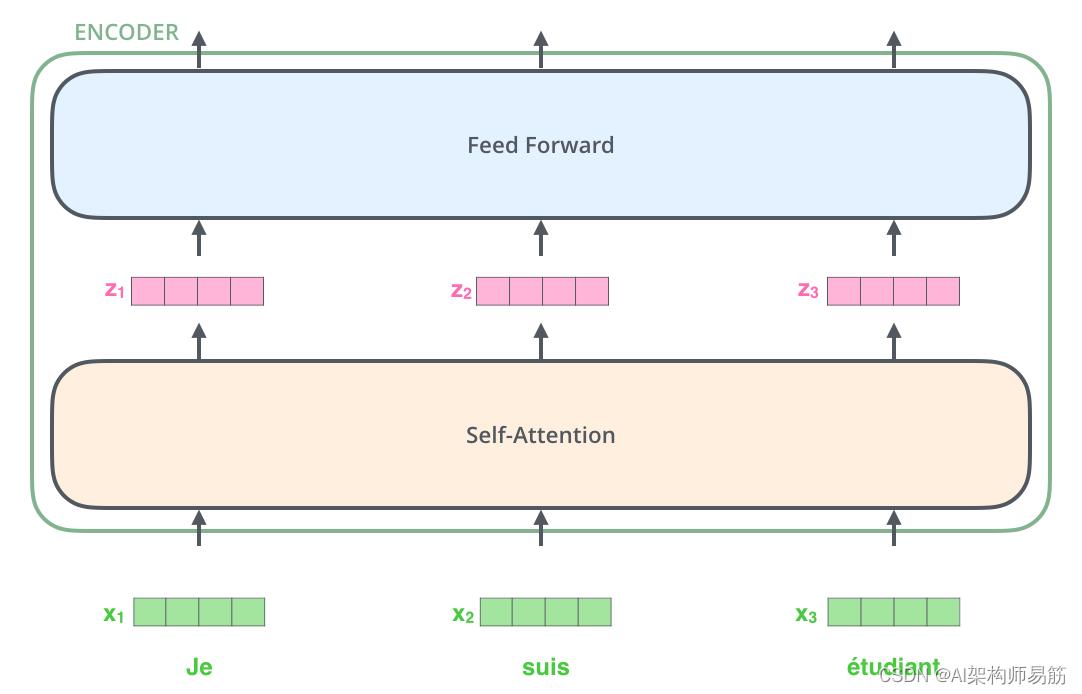
与一般 NLP 应用程序中的情况一样,我们首先使用Embedding嵌入算法将每个输入单词转换为向量。

每个单词都嵌入到一个大小为 512 的向量中。我们将用这些简单的框来表示这些向量。
Embedding嵌入仅发生在最底部的编码器中。所有编码器共有的抽象是它们接收一个大小为 512 的向量列表——在底部的编码器中,这将是词嵌入,但在其他编码器中,它将是直接在下方的编码器的输出. 这个列表的大小是我们可以设置的超参数——基本上它是我们训练数据集中最长句子的长度。
在我们的输入序列中嵌入单词之后,它们中的每一个都流过编码器的两层中的每一层。
在这里,我们开始看到 Transformer 的一个关键属性,那就是每个位置的单词在Encoders编码器中流过自己的路径。在自注意力层Self-Attention中,这些路径之间存在依赖关系。然而,Feed Forward前馈层没有这些依赖关系,因此各种路径可以在流过前馈层的同时并行执行。
接下来,我们将把这个例子转换成一个更短的句子,我们将看看在编码器的每个子层中发生了什么。
4.1 现在我们正在编码!
正如我们已经提到的,编码器接收向量列表作为输入。它通过将这些向量传递到“自注意力Self-Attention ”层来处理这个列表,然后传递到前馈神经网络Feed Forward Neural Network,然后将输出向上发送到下一个编码器。
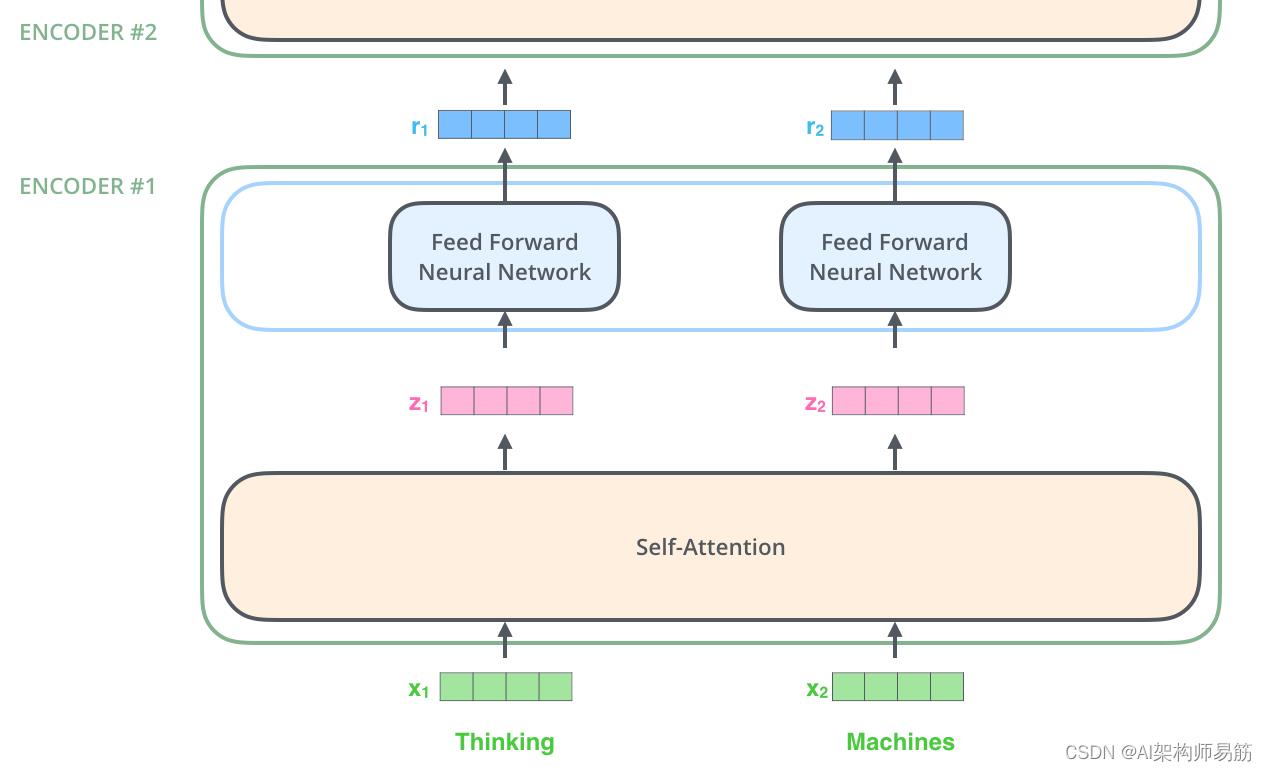
每个位置的单词都会经过一个自注意力过程。然后,它们每个都通过一个前馈神经网络——完全相同的网络,每个向量分别流过它。
5. Self-Attention 自注意力机制
假设以下句子是我们要翻译的输入句子:
” The animal didn’t cross the street because it was too tired”
这句话中的“it”指的是什么?it指的是street还是animal?这对人类来说是一个简单的问题,但对算法来说却不是那么简单。
当模型处理“it”这个词时,self-attention 允许它把“it”和“animal”联系起来。
当模型处理每个单词(输入序列中的每个位置)时,自注意力允许它查看输入序列中的其他位置以寻找有助于更好地编码该单词的线索。
如果您熟悉 RNN,请考虑如何保持隐藏状态允许 RNN 将其已处理的先前单词/向量的表示与其正在处理的当前单词/向量结合起来。自注意力是 Transformer 用来将其他相关单词的“理解”融入我们当前正在处理的单词的方法。

当我们在编码器#5(堆栈中的顶部编码器)中对单词“it”进行编码时,部分注意力机制专注于“The Animal”(连线权重比较大),并将其表示的一部分集成到“it”的编码中。
请务必查看Tensor2Tensor jupyter notebook,您可以在其中加载 Transformer 模型,并使用此交互式可视化进行检查。
5.1 自注意力细节
让我们先看看如何使用向量计算自注意力,然后继续看看它是如何实际实现的——使用矩阵。
计算自注意力的第一步是从每个编码器的输入向量创建三个向量Q、K、V(在这种情况下,每个词的嵌入)。因此,对于每个单词,我们创建一个查询向量Q、一个键向量K和一个值向量V。这些向量是通过将嵌入乘以我们在训练过程中训练的三个矩阵来创建的。
请注意,这些新向量Q、K、V的维度小于嵌入向量。它们的维数为 64,而嵌入和编码器输入/输出向量的维数为 512。它们不必更小,这是使多头注意力(大部分)的计算保持不变的架构选择。
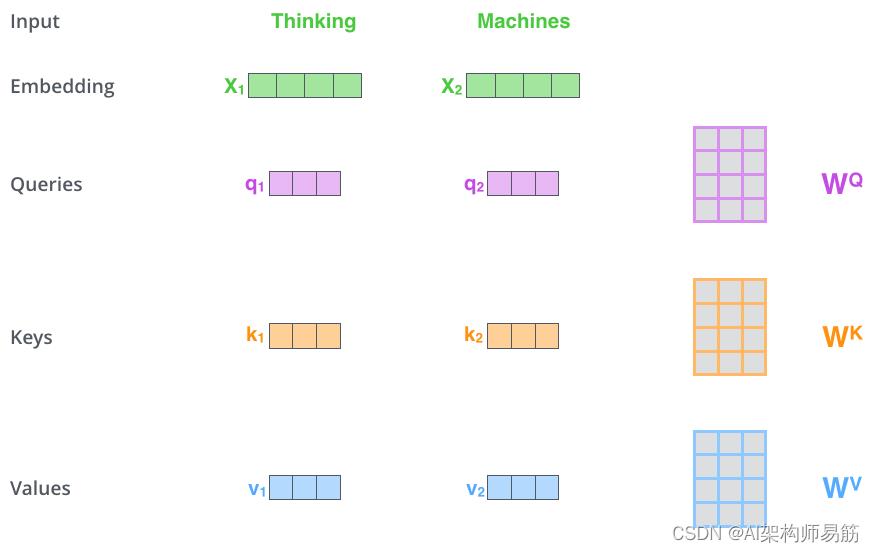
将
x
1
x_1
x1 乘以
W
Q
W^Q
WQ权重矩阵会产生
q
1
q_1
q1 ,即与该词关联的“查询”向量。我们最终为输入句子中的每个单词创建了一个“查询Q”、一个“键K”和一个“值V”投影。
5.2 什么是“查询Q”、“键K”和“值V”向量?
它们是用于计算和思考注意力的抽象概念。一旦你继续阅读下面的注意力是如何计算的,你就会知道几乎所有你需要知道的关于每个向量所扮演的角色。
计算self-attention的第二步是计算一个分数。假设我们正在计算本例中第一个单词“Thinking”的自注意力。我们需要根据这个词对输入句子的每个词进行评分。当我们在某个位置对单词进行编码时,分数决定了对输入句子其他部分的关注程度。
分数是通过查询向量与我们正在评分的各个单词的关键向量的点积来计算的。因此,如果我们正在处理位置#1中单词的自注意力,第一个分数将是
q
1
q_1
q1和
k
1
k_1
k1的点积。第二个分数是
q
2
q_2
q2和
k
2
k_2
k2的点积。

第三步和第四步是将分数除以 8(论文中使用的关键向量维度的平方根 64。这会导致梯度更稳定。这里可能还有其他可能的值,但这是默认),然后通过 softmax 操作传递结果。Softmax 将分数归一化,因此它们都是正数并且加起来为 1。
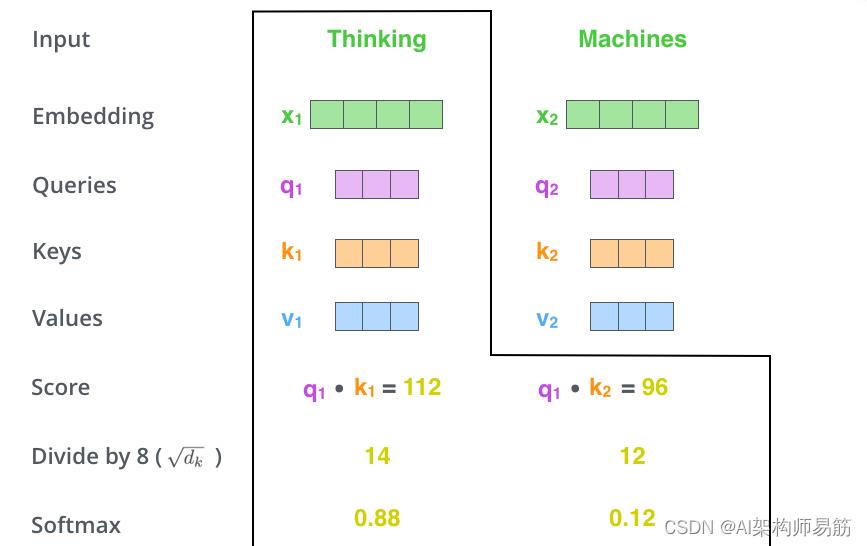
这个 softmax 分数决定了每个单词在这个位置上的表达量。显然,这个位置的单词将具有最高的 softmax 分数,但有时关注与当前单词相关的另一个单词很有用。
第五步是将每个值向量乘以 softmax 分数(准备将它们相加)。这里的直觉是保持我们想要关注的单词的值不变,并淹没不相关的单词(例如,将它们乘以 0.001 之类的小数字)。
第六步是对加权值向量求和。这会在这个位置产生自注意力层的输出(对于第一个词)。
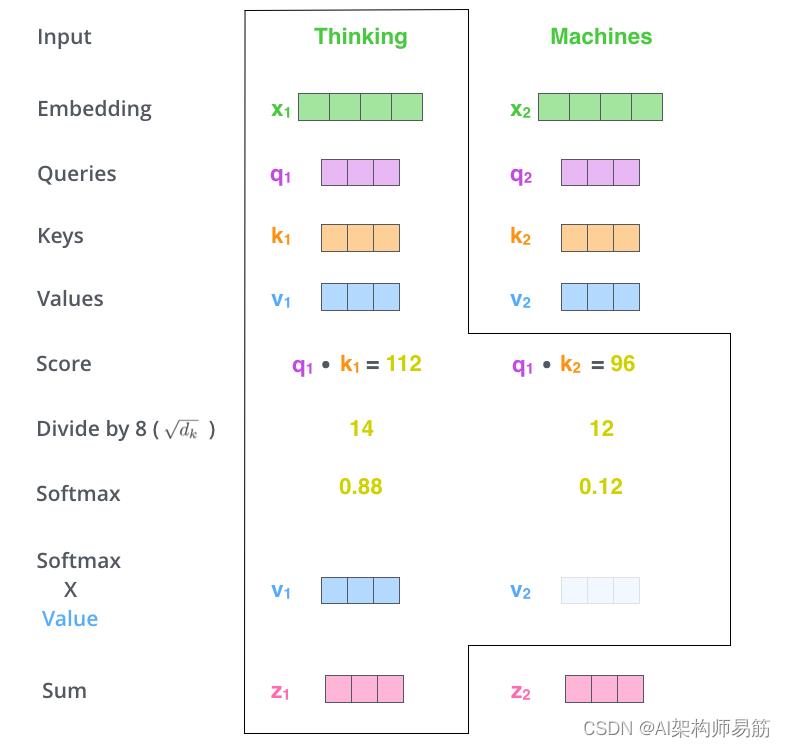
自注意力计算到此结束。结果向量是我们可以发送到前馈神经网络的向量。然而,在实际实现中,这种计算是以矩阵形式进行的,以便更快地处理。既然我们已经看到了单词级别的计算直觉,那么让我们来看看。
5. 3 自注意力的矩阵计算
第一步是计算查询Q、键K和值V矩阵。我们通过将嵌入打包到矩阵X中,并将其乘以我们训练的权重矩阵(
W
Q
W^Q
WQ、
W
K
W^K
WK、
W
V
W^V
WV)来做到这一点。
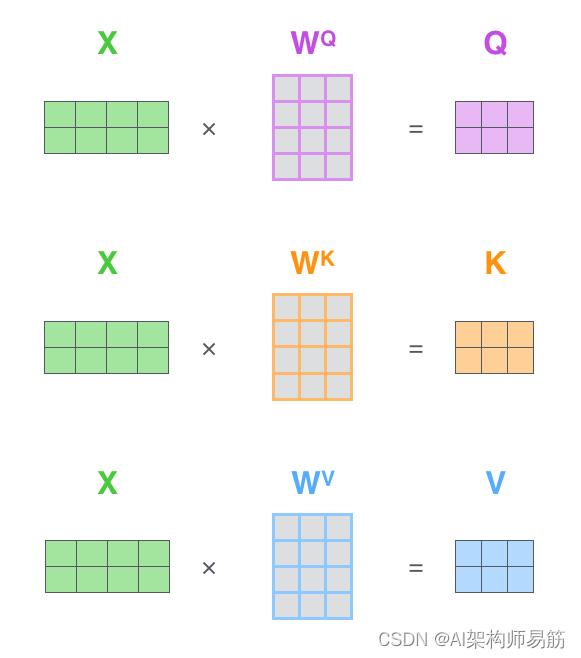
X矩阵 中的每一行对应于输入句子中的一个单词。我们再次看到嵌入向量(512,或图中 4 个框)和 q/k/v 向量(64,或图中 3 个框)大小的差异
最后,由于我们处理的是矩阵,我们可以将步骤二到六合一公式来计算自注意力层的输出。
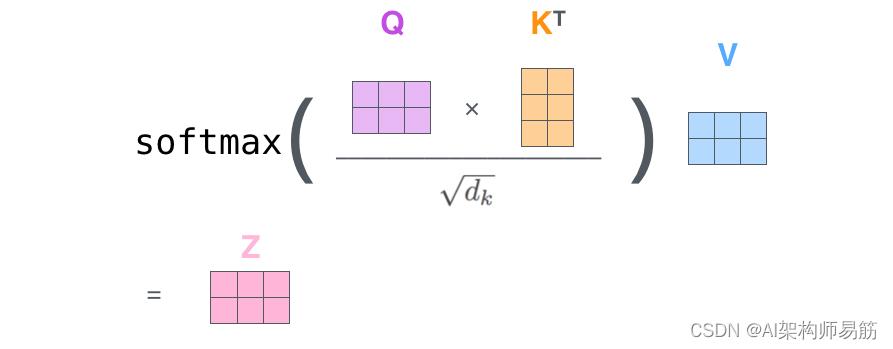
矩阵形式的self-attention计算
5.4 “多头”注意力Multi-Head Attention
该论文通过添加一种称为“多头”注意力的机制进一步完善了自注意力层self attention。

这通过两种方式提高了注意力层的性能:
-
它扩展了模型关注不同位置的能力。是的,在上面的示例中,z1 包含一点其他编码,但它可能由实际单词本身主导。如果我们要翻译“The animal didn’t cross the street because it was too tired”这样的句子,那么知道“it”指的是哪个词会很有用。
-
它为注意力层提供了多个“表示子空间”。正如我们接下来将看到的,使用多头注意力,我们不仅有一个,而且还有多组查询/键/值权重矩阵(Transformer 使用八个注意力头,所以我们最终每个编码器/解码器都有八个集合) . 这些集合中的每一个都是随机初始化的。然后,在训练之后,每个集合用于将输入嵌入(或来自较低编码器/解码器的向量)投影到不同的表示子空间中。
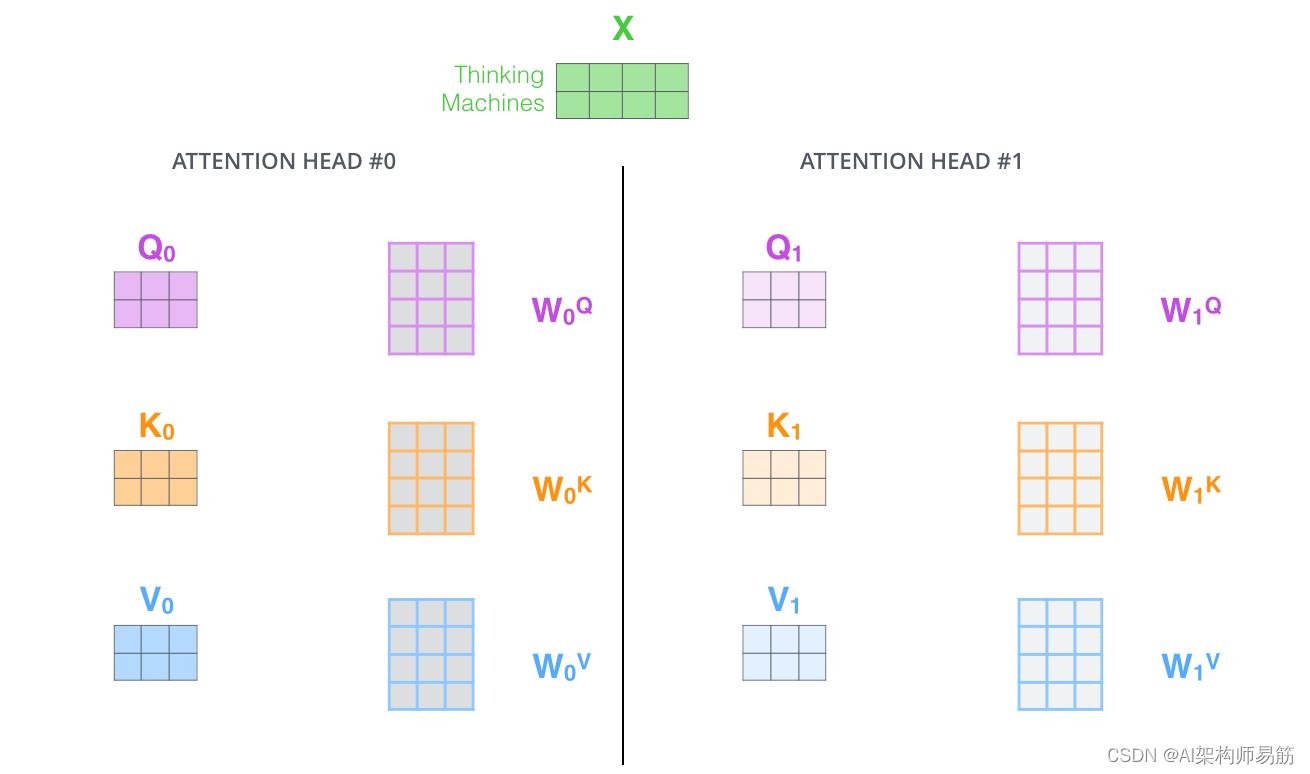
通过多头注意力,我们为每个头维护单独的 Q/K/V 权重矩阵,从而产生不同的 Q/K/V 矩阵。正如我们之前所做的那样,我们将 X 乘以
W
Q
W^Q
WQ/
W
K
W^K
WK/
W
V
W^V
WV 矩阵以产生 Q/K/V 矩阵。
如果我们进行与上述相同的自注意力计算,只是使用不同的权重矩阵进行八次不同的计算,我们最终会得到八个不同的 Z 矩阵
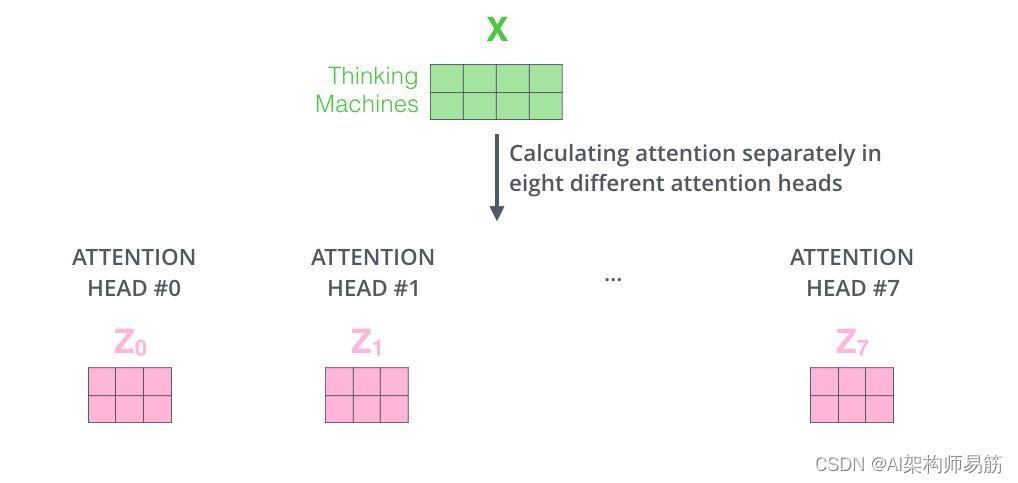
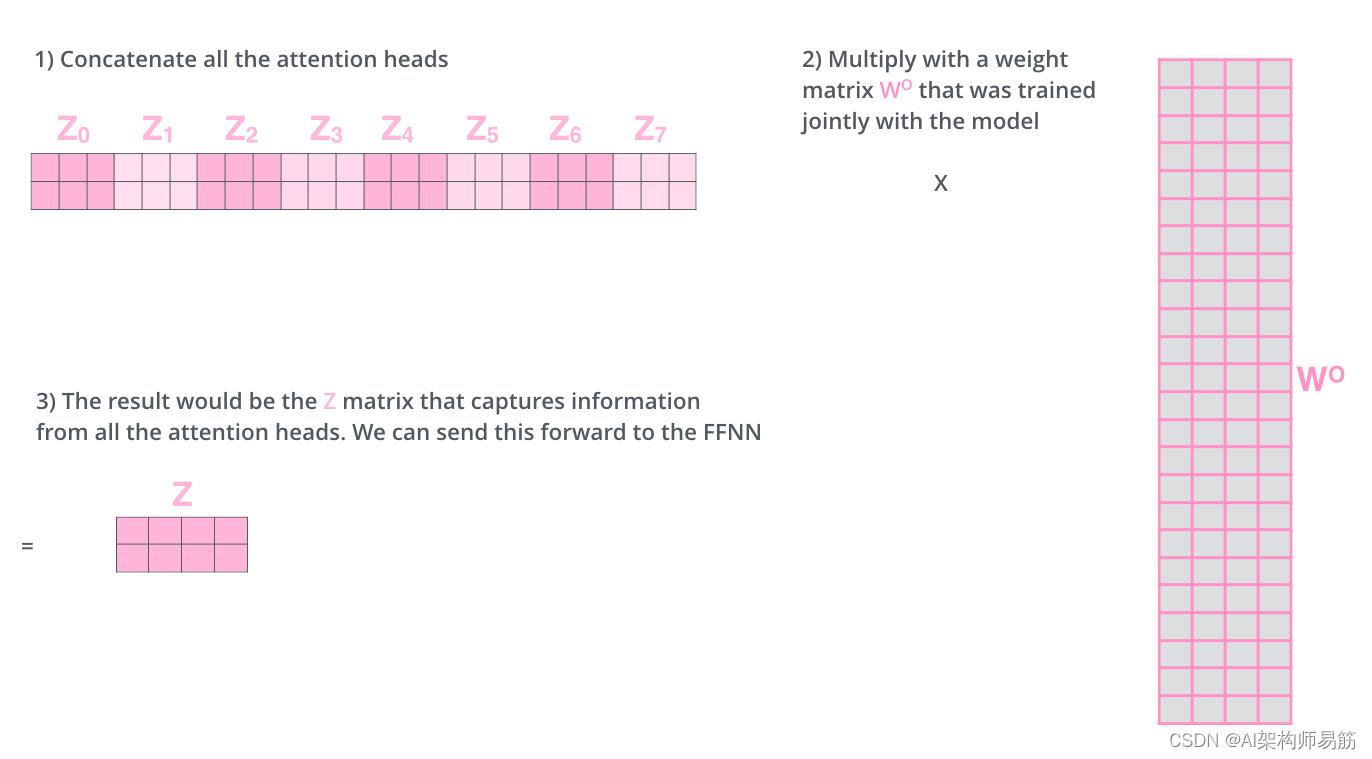
这给我们带来了一些挑战。前馈层不需要八个矩阵——它需要一个矩阵(每个单词的向量)。所以我们需要一种方法将这八个Concatenate浓缩成一个矩阵。
我们如何做到这一点?我们连接这些矩阵,然后将它们乘以一个额外的权重矩阵
W
O
W^O
WO。
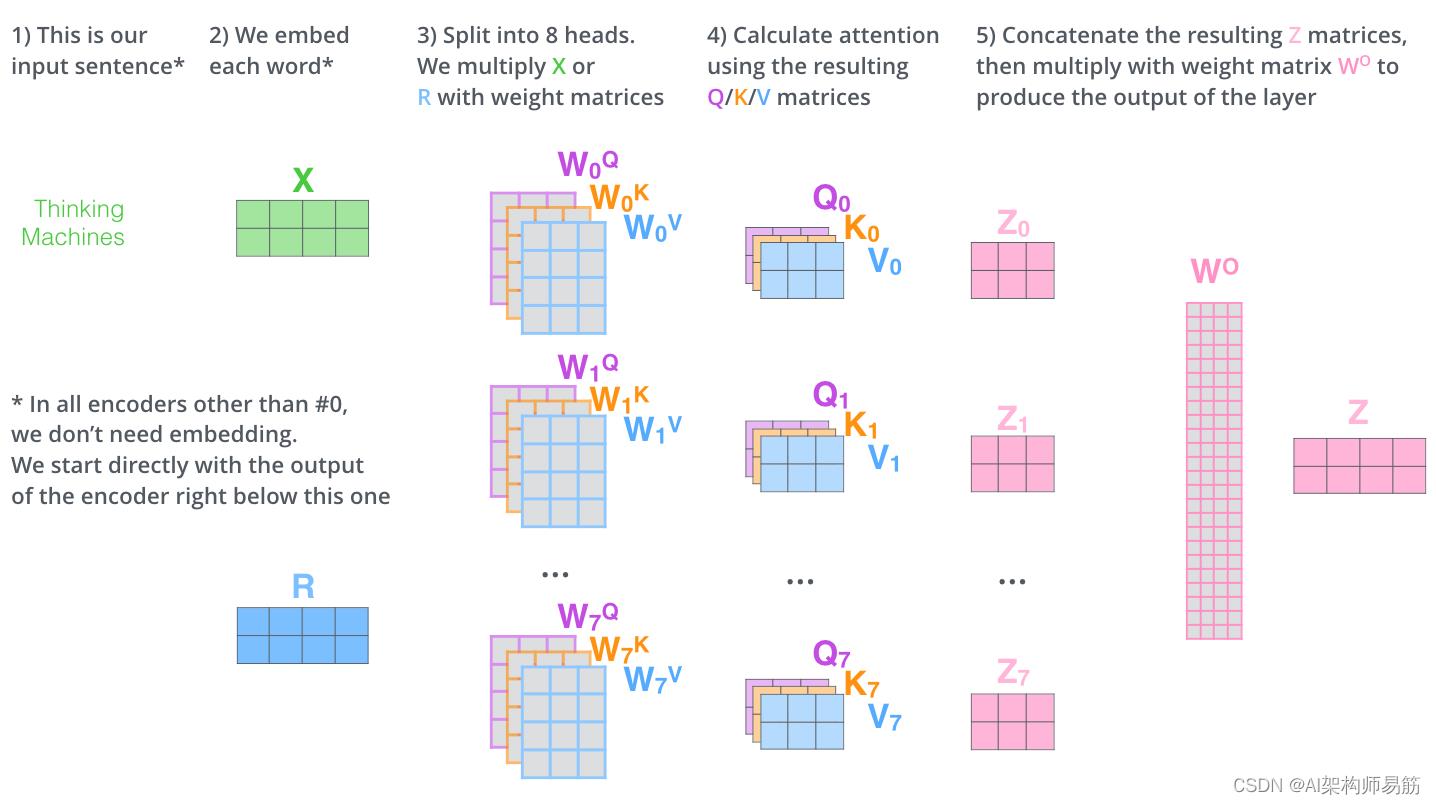
这就是多头自注意力的全部内容。我意识到,这是相当多的矩阵。让我尝试将它们全部放在一个视觉效果中,以便我们可以在一个地方查看它们
既然我们已经接触了自注意力头,让我们重新回顾之前的例子,看看当我们在例句中编码单词“it”时不同的注意力头在哪里集中:
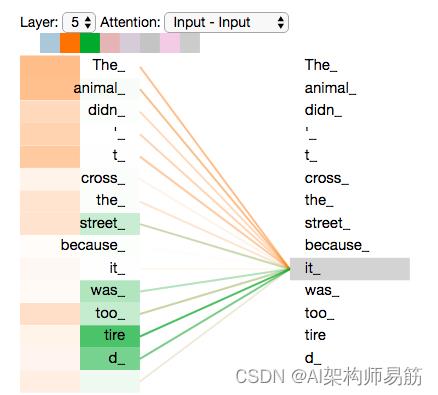
当我们对“it”这个词进行编码时,一个注意力头最关注“animal”,而另一个注意力头则专注于“tire”——在某种意义上,模型对“it”这个词的表示包含了一些表示“animal”和“tire”。
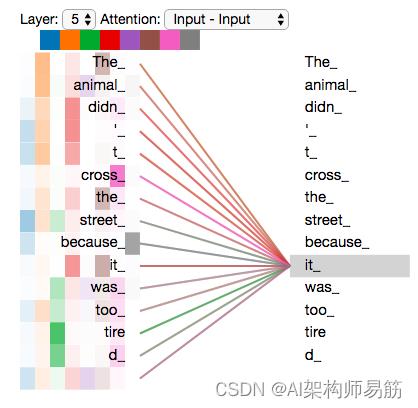
但是,如果我们将所有注意力都添加到图片中,事情可能会更难解释:
6. 使用位置编码表示序列的顺序
正如我们到目前为止所描述的,模型中缺少的一件事是一种解释输入序列中单词顺序的方法。
为了解决这个问题,转换器为每个输入嵌入添加了一个向量。这些向量遵循模型学习的特定模式,这有助于确定每个单词的位置,或序列中不同单词之间的距离。这里的直觉是,一旦将这些值投影到 Q/K/V 向量中以及在点积注意力期间,将这些值添加到嵌入中会在嵌入向量之间提供有意义的距离。
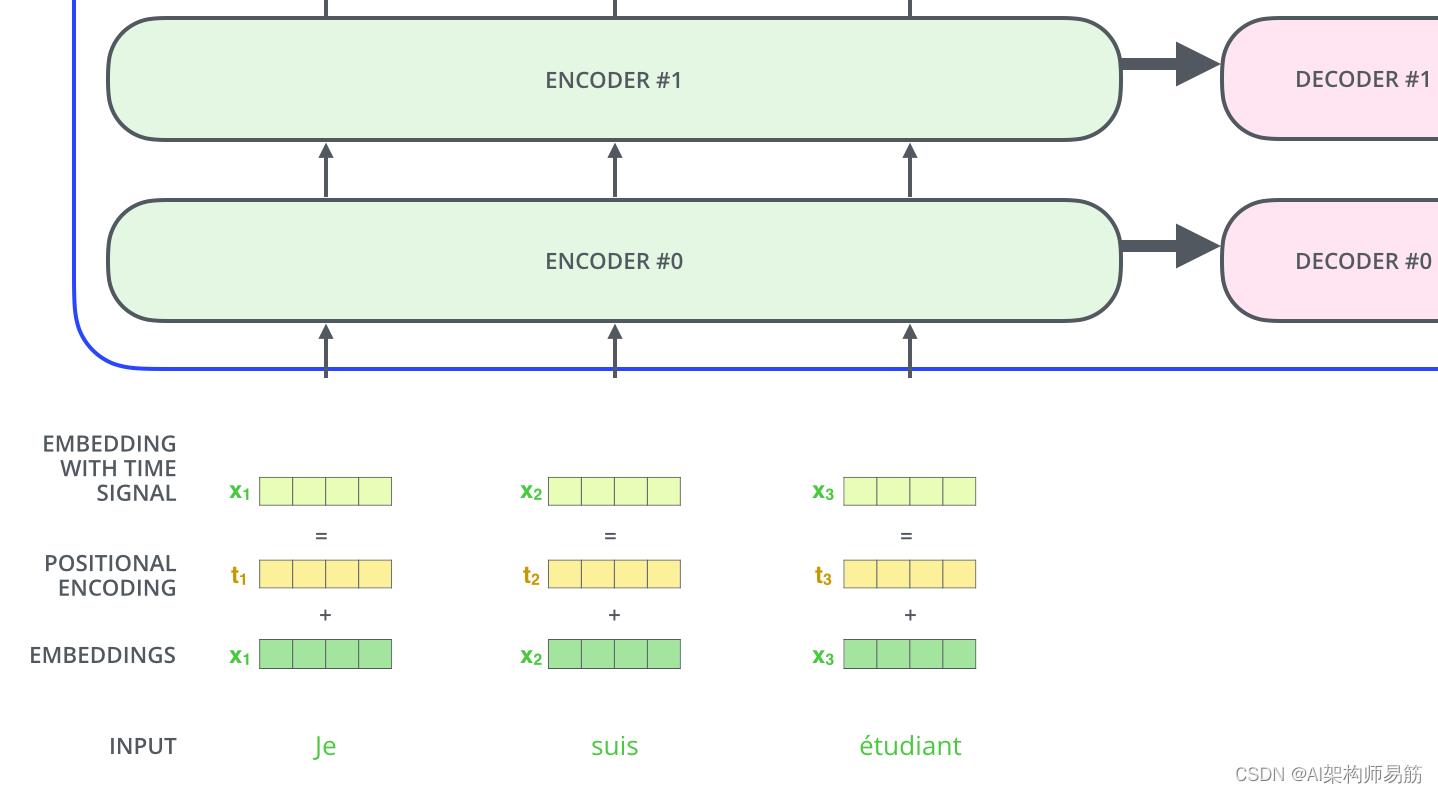
为了让模型了解单词的顺序,我们添加了位置编码向量——其值遵循特定的模式。
如果我们假设嵌入的维度为 4,那么实际的位置编码将如下所示:
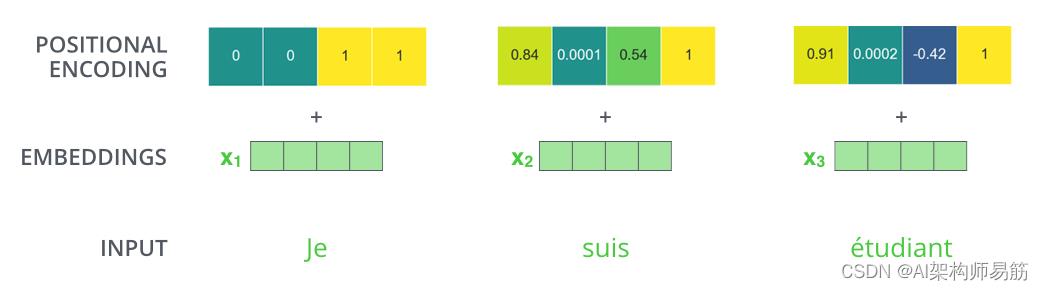
嵌入大小为 4 的位置编码的真实示例
这种模式可能是什么样子?
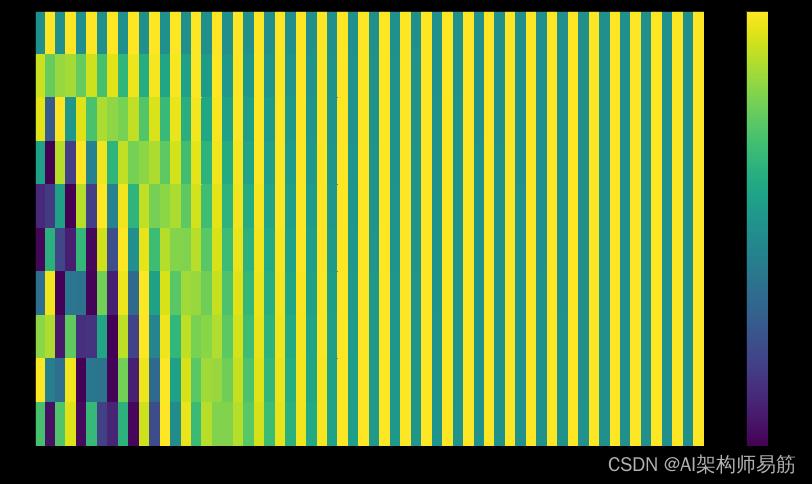
在下图中,每一行对应一个向量的位置编码。所以第一行将是我们添加到输入序列中第一个词的嵌入的向量。每行包含 512 个值——每个值都介于 1 和 -1 之间。我们对它们进行了颜色编码,因此图案可见。

嵌入大小为 512(列)的 20 个单词(行)的位置编码的真实示例。您可以看到它在中间被分成两半。这是因为左半部分的值是由一个函数(使用正弦Sin)生成的,而右半部分是由另一个函数(使用余弦Cos)生成的。然后将它们连接起来形成每个位置编码向量。
论文中描述了位置编码的公式(第 3.5 节)。您可以在 中查看生成位置编码的代码get_timing_signal_1d()。这不是位置编码的唯一可能方法。然而,它具有能够扩展到看不见的序列长度的优势(例如,如果我们训练的模型被要求翻译比我们训练集中的任何一个句子更长的句子)。
上面显示的位置编码来自 Transformer 的 Tranformer2Transformer 实现。论文中展示的方法略有不同,它不是直接串联,而是将两个信号交织在一起。下图显示了它的外观。这是生成它的代码:
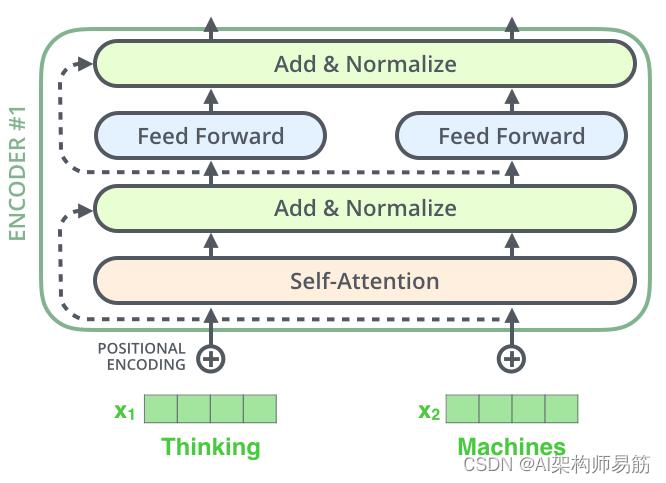
7. 残差 The Residuals Network
在继续之前我们需要提到的编码器架构中的一个细节是,每个编码器中的每个子层(self-attention)在其周围都有一个残差连接,然后是一个层归一化步骤。
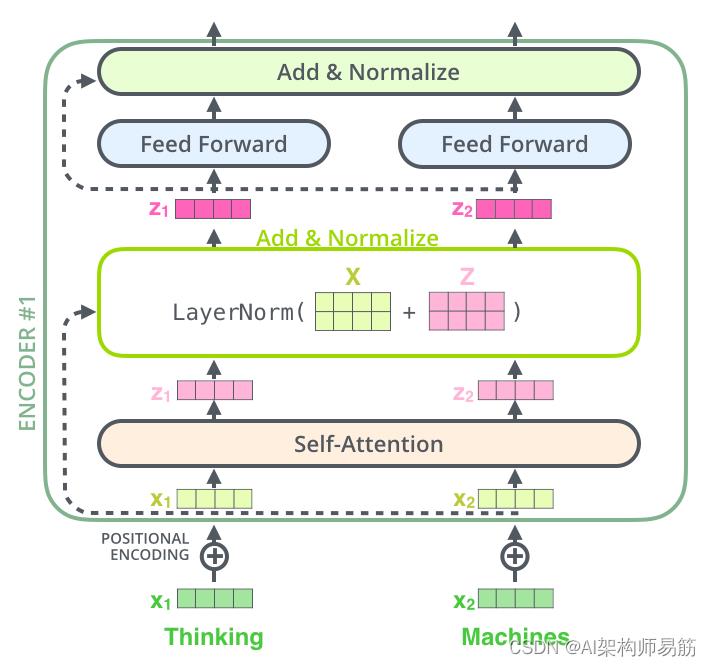
如果我们要可视化与 self attention 相关的向量和 layer-norm 操作,它看起来像这样:
这也适用于解码器的子层。如果我们想一个由 2 个堆叠编码器和解码器组成的 Transformer,它看起来像这样:
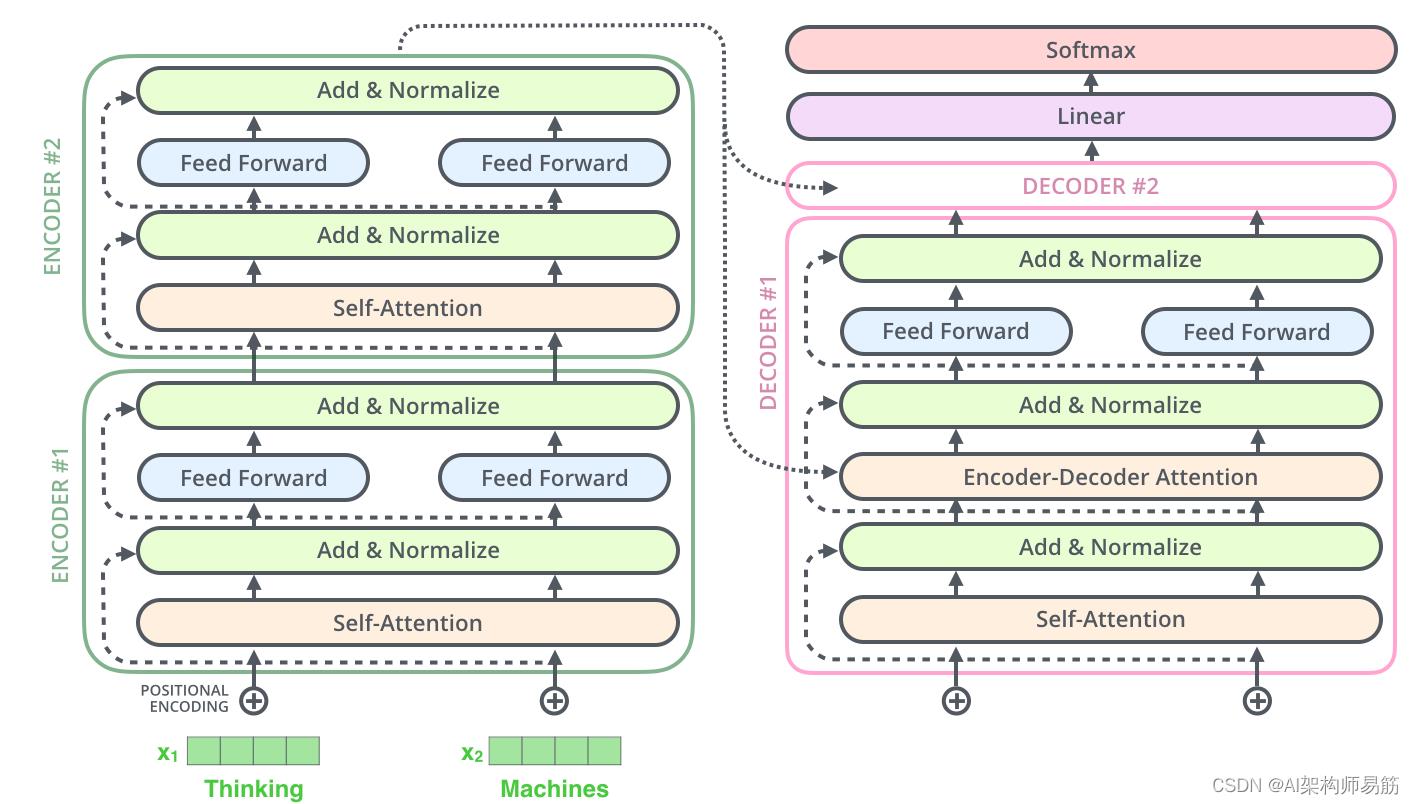
8. 解码器端 The Decoder Side
现在我们已经涵盖了编码器方面的大部分概念,我们基本上知道解码器的组件是如何工作的。但是让我们来看看它们是如何协同工作的。
编码器首先处理输入序列。然后将顶部编码器的输出转换为一组注意向量 K 和 V。这些将由每个解码器在其“编码器-解码器注意”层中使用,这有助于解码器将注意力集中在输入序列中的适当位置:
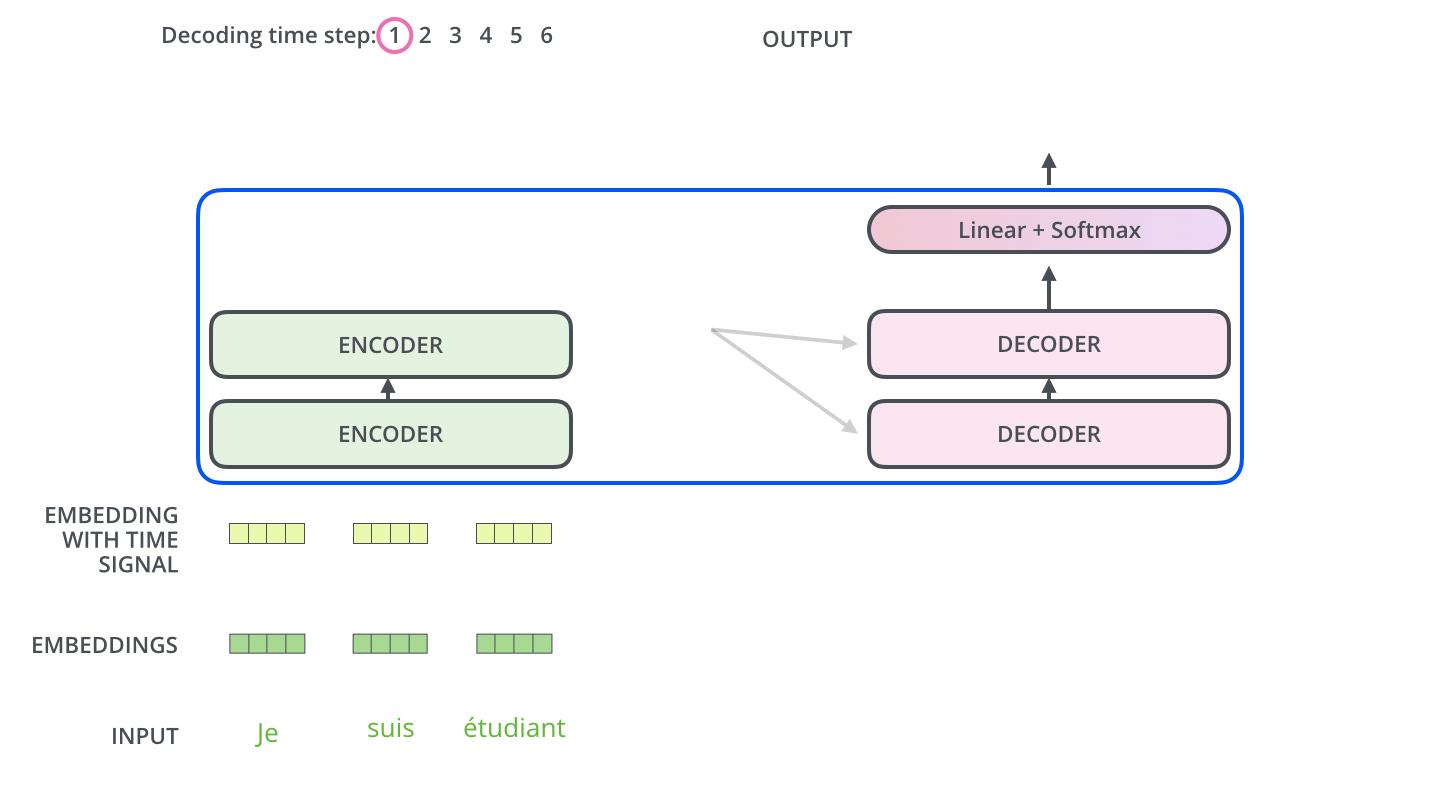
以下步骤重复该过程,直到出现特殊到达符号表示变压器解码器已完成其输出。每一步的输出在下一个时间步被馈送到底部的解码器,解码器就像编码器一样冒泡它们的解码结果。就像我们对编码器输入所做的那样,我们将位置编码嵌入并添加到这些解码器输入中,以指示每个单词的位置。
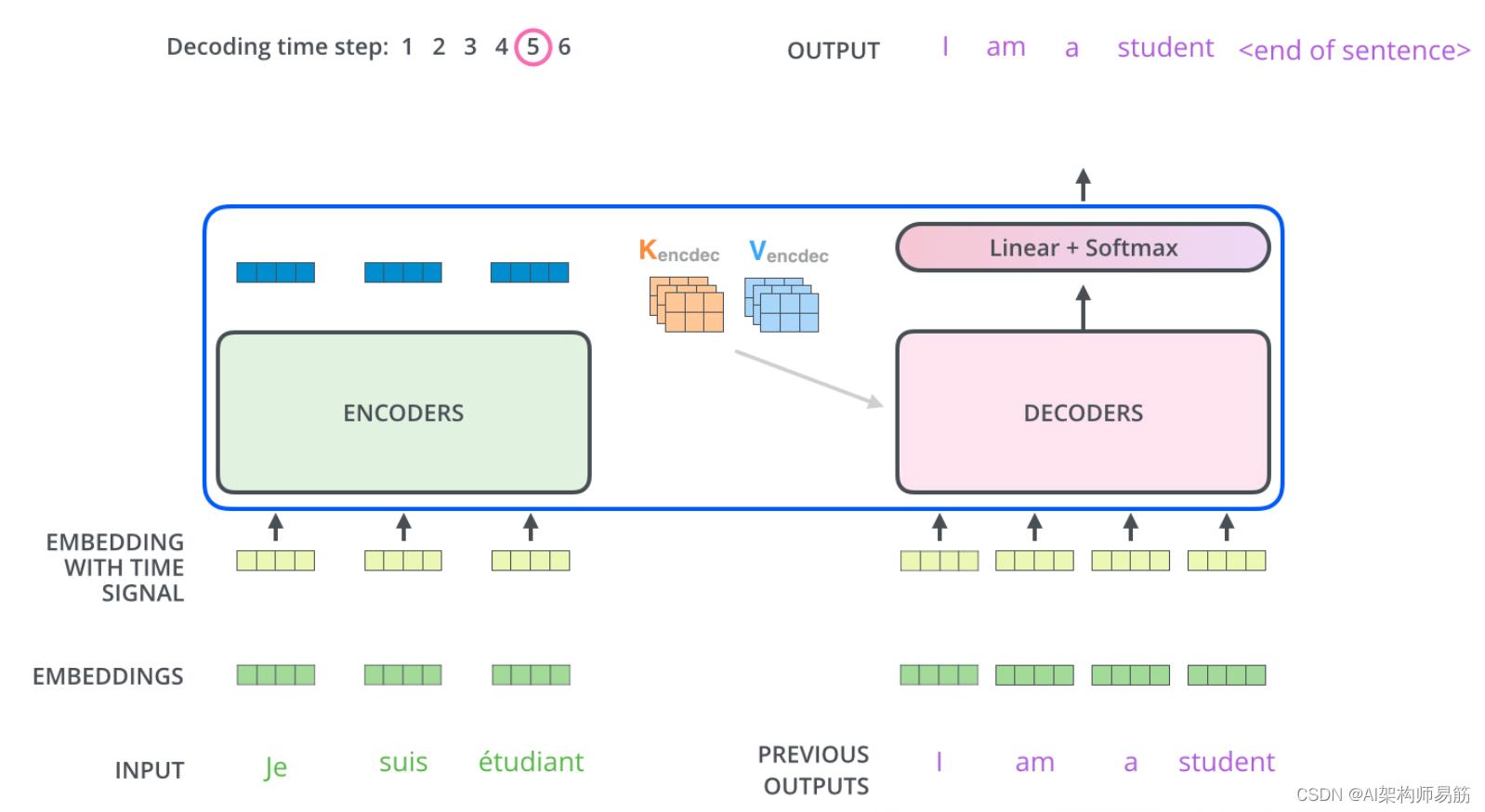
解码器中的自注意力层的操作方式与编码器中的方式略有不同:
在解码器中,自注意力层只允许关注输出序列中较早的位置。这是通过在 self-attention 计算中的 softmax 步骤之前masking屏蔽未来位置(将它们设置为 )来完成的。
“Encoder-Decoder Attention”层的工作方式与多头自注意力相似,不同之处在于它从其下方的层创建其查询矩阵,并从编码器堆栈的输出中获取 Keys 和 Values 矩阵。
9. 最终的线性和 Softmax 层
解码器堆栈输出一个浮点向量。我们如何把它变成一个词?这是最后一个线性层的工作,后面是一个 Softmax 层。
线性层是一个简单的全连接神经网络,它将解码器堆栈产生的向量投影到一个更大的向量中,称为 logits 向量。
假设我们的模型知道从训练数据集中学习到的 10,000 个独特的英语单词(我们模型的“输出词汇”)。这将使 logits 向量有 10,000 个单元格宽——每个单元格对应一个唯一单词的分数。这就是我们如何解释模型的输出,然后是线性层。
然后,softmax 层将这些分数转化为概率(全部为正,全部加起来为 1.0)。选择概率最高的单元格,并生成与其关联的单词作为该时间步的输出。

10. 总结
现在我们已经通过一个训练有素的 Transformer 介绍了整个前向传递过程,看看训练模型的直觉会很有用。
在训练期间,未经训练的模型将通过完全相同的前向传递。但是由于我们是在一个带标签的训练数据集上训练它,我们可以将它的输出与实际正确的输出进行比较。
为了形象化,假设我们的输出词汇表只包含六个单词(“a”、“am”、“i”、“thanks”、“student”和“”(“end of sentence”的缩写)) .
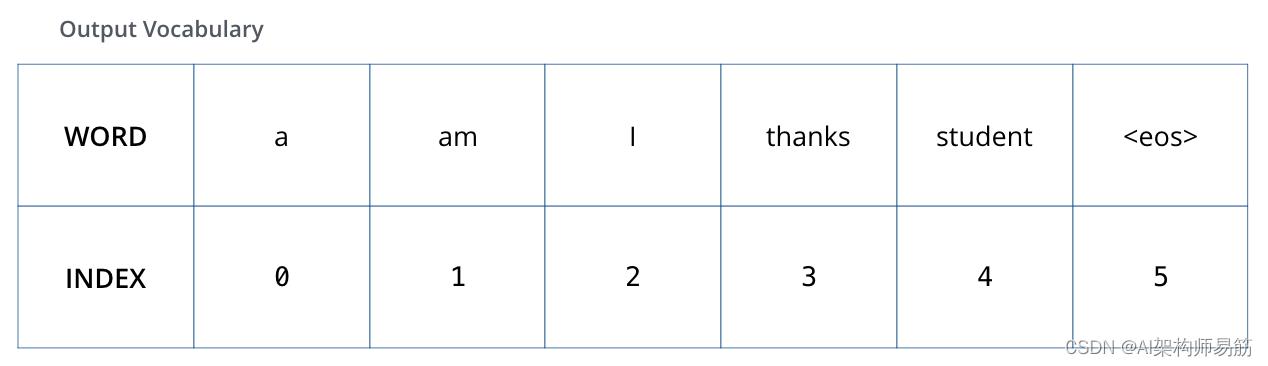
我们模型的输出词汇表是在我们开始训练之前的预处理阶段创建的。
一旦我们定义了我们的输出词汇表,我们就可以使用一个相同宽度的向量来表示我们词汇表中的每个单词。这也称为 one-hot 编码。因此,例如,我们可以使用以下向量表示单词“am”:

示例:我们的输出词汇表的 one-hot 编码
在此回顾之后,让我们讨论模型的损失函数——我们在训练阶段正在优化的指标,以生成一个经过训练的并且希望非常准确的模型。
10.1 损失函数
假设我们正在训练我们的模型。假设这是我们在训练阶段的第一步,我们正在通过一个简单的例子来训练它——将“merci”翻译成“thanks”。
这意味着,我们希望输出是一个概率分布,表示“谢谢”这个词。但由于这个模型还没有经过训练,所以现在还不太可能发生。
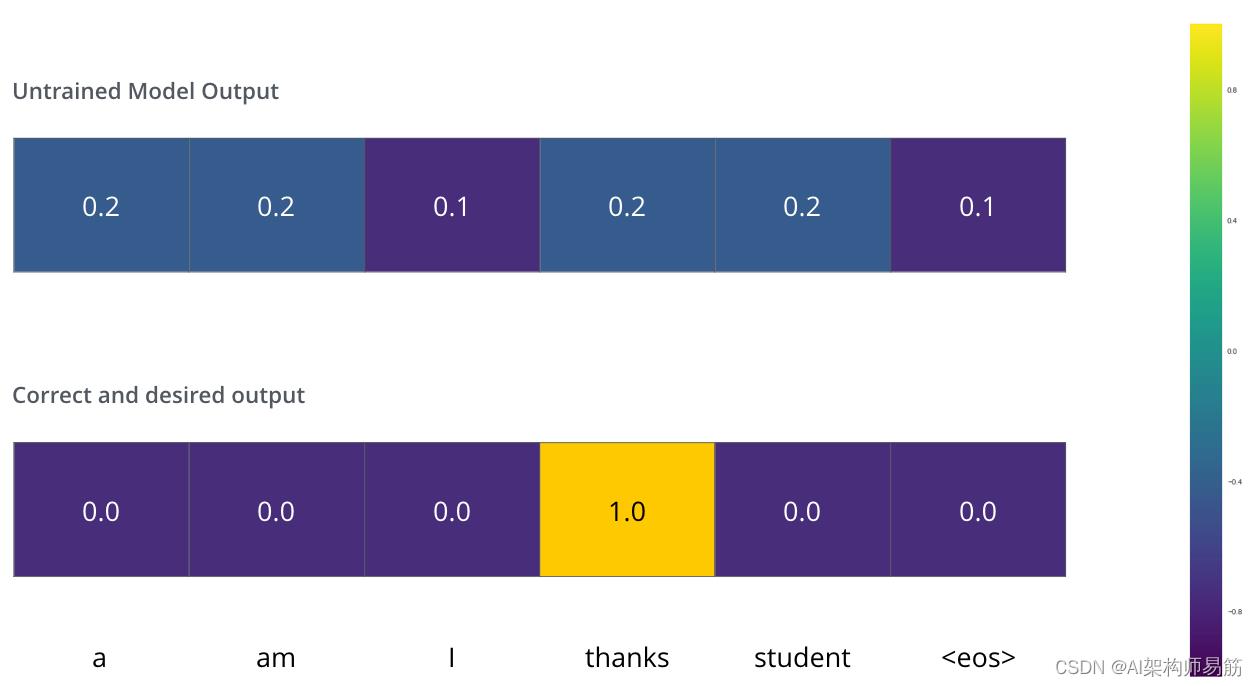
由于模型的参数(权重)都是随机初始化的,因此(未经训练的)模型会为每个单元格/单词生成具有任意值的概率分布。我们可以将其与实际输出进行比较,然后使用反向传播调整所有模型的权重,以使输出更接近所需的输出。
你如何比较两个概率分布?我们只是从另一个中减去一个。有关更多详细信息,请查看 交叉熵和Kullback-Leibler 散度。
但请注意,这是一个过于简单的示例。更实际的是,我们会使用比一个词更长的句子。例如——输入:“je suis étudiant”,预期输出:“I am a student”。这真正意味着,我们希望我们的模型能够连续输出概率分布,其中:
- 每个概率分布都由一个宽度为 vocab_size 的向量表示(在我们的示例中为 6,但更实际的是一个数字,例如 30,000 或 50,000)
- 第一个概率分布在与单词“i”相关的单元格中具有最高概率
- 第二个概率分布在与单词“am”相关的单元格中具有最高概率
- 依此类推,直到第五个输出分布指示 ’ ’ 符号,它也有一个来自 10,000 个元素词汇表的单元格与之关联。
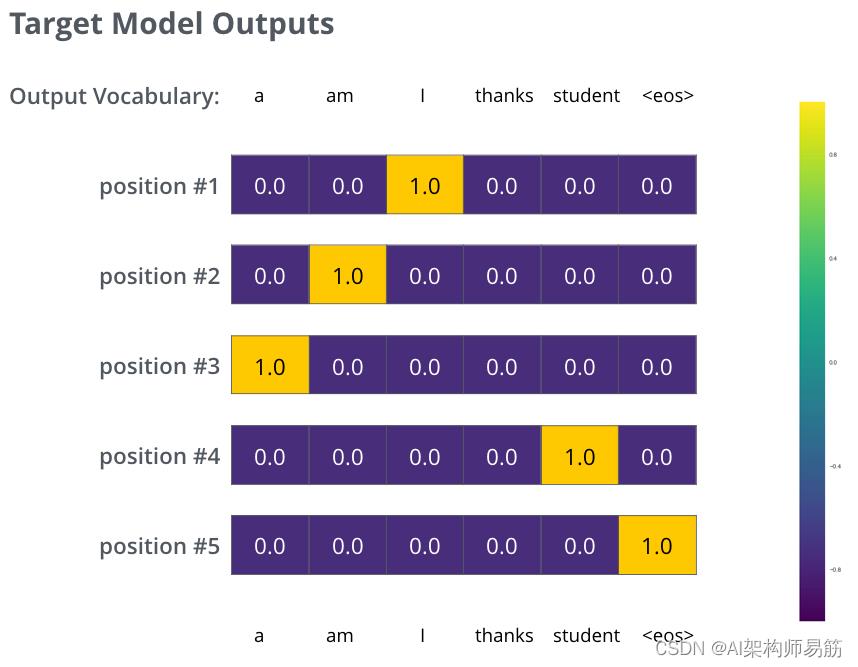
我们将在训练示例中针对一个样本句子训练模型的目标概率分布。
在足够大的数据集上训练模型足够的时间后,我们希望生成的概率分布如下所示:
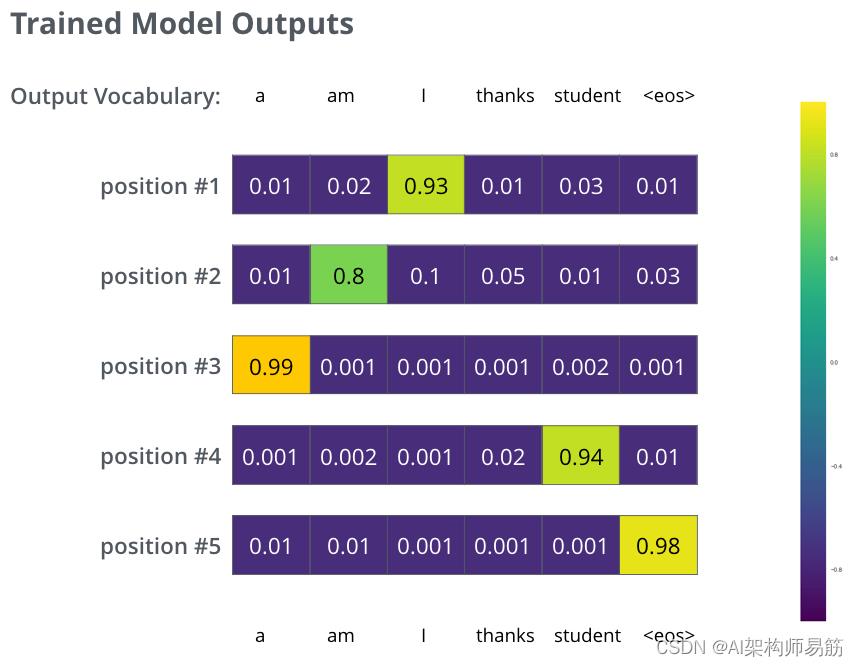
希望在训练后,模型会输出我们期望的正确翻译。当然,如果这个短语是训练数据集的一部分,这并没有真正的迹象(参见:交叉验证)。请注意,每个位置都有一点概率,即使它不太可能是那个时间步的输出——这是 softmax 的一个非常有用的属性,有助于训练过程。
现在,因为模型一次产生一个输出,我们可以假设模型正在从该概率分布中选择具有最高概率的单词并丢弃其余的单词。这是一种方法(称为贪婪解码)。另一种方法是保留前两个单词(例如,“I”和“a”),然后在下一步中运行模型两次:假设第一个输出位置是单词’I’,另一次假设第一个输出位置是单词’a’,并且考虑到位置#1和#2,无论哪个版本产生的错误更少。我们对#2 和#3 等位置重复此操作。这种方法称为“beam search”,在我们的示例中,beam_size 为 2(这意味着在任何时候,两个部分假设(未完成的翻译)都保存在内存中),并且 top_beams 也是两个(意味着我们将返回两个翻译)。这些都是您可以试验的超参数。
11. 延伸阅读
我希望您发现这是一个有用的地方,可以开始使用 Transformer 的主要概念打破僵局。如果您想更深入,我建议您执行以下步骤:
观看原作的视频:https://youtu.be/-QH8fRhqFHM
- 阅读Attention Is All You Need论文、Transformer 博客文章(Transformer: A Novel Neural Network Architecture for Language Understanding)和Tensor2Tensor 公告。
- 观看Łukasz Kaiser 的演讲,了解模型及其细节
- 使用作为 Tensor2Tensor 存储库的一部分提供的Jupyter Notebook
- 探索Tensor2Tensor repo。
参考
- https://arxiv.org/abs/1706.03762
- https://jalammar.github.io/illustrated-transformer/
- https://zhuanlan.zhihu.com/p/48508221
以上是关于翻译: 详细图解Transformer多头自注意力机制 Attention Is All You Need的主要内容,如果未能解决你的问题,请参考以下文章
翻译: 详细图解Transformer多头自注意力机制 Attention Is All You Need
自注意力 self attention Transformer 多头注意力代码 Transformer 代码 动手学深度学习v2
自注意力 self attention Transformer 多头注意力代码 Transformer 代码 动手学深度学习v2
[Python人工智能] 三十六.基于Transformer的商品评论情感分析 keras构建多头自注意力(Transformer)模型
[Python人工智能] 三十六.基于Transformer的商品评论情感分析 keras构建多头自注意力(Transformer)模型