菜品识别系统(Faster-RCNN目标检测算法)
Posted 钟良堂的学习笔记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了菜品识别系统(Faster-RCNN目标检测算法)相关的知识,希望对你有一定的参考价值。
一、Faster-RCNN目标检测算法的介绍
Faster-RCNN 算法由于其较高的检测准确率成为主流的目标检测算法之一,相比较 YOLO系列算法,Faster-RCNN 速度方面略显不足,平均检测精度(mAP)很高,它将 region proposal提取和 Fast-RCNN 部分融合进了一个网络模型 (区域生成网络 RPN 层)。
算法大概可以分为特征提取层,区域建议层(RPN),ROIpooling(池化)层,分类与回归四个部分。具体执行步骤如下:
(1)首先利用特征提取网络对输入进行特征提取:特征提取网络通常由卷积层、池化层,激活层组成,可以使用训练好的网络,有不同的网络架构如(VGG、Resnet、Inception)等。
(2)将产生的 feature map传入 RPN网络产生建议框,然后进行是否含有目标的二分类,同时 feature map 传入 ROIpooling 层进行池化操作,产生固定大小的候选区域特征图。
(3)对产生的候选区域特征图进行分类和回归,得到物体种类和位置。
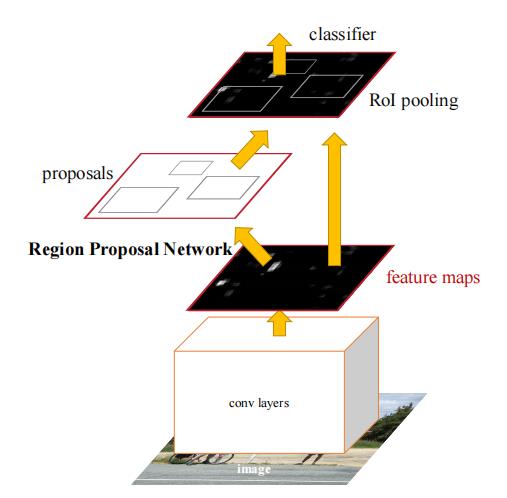
Faster-RCNN 相较以往算法有几点重大改进:其核心是提出了 RPN(Region Proposal Network)网络,它的出现代替了传统产生候选区域的方法,实现了端到端的训练,并且将整个物体检测的流程统一到同一个神经网络中去,使得 RPN 和 Fast RCNN 实现了共享卷积特征,减少了训练时间;采用 ROI Pooling 使用最大值池化将特征图上 ROI 固定为特定大小的特征图;采用 NMS(非极大值抑制,Non-maximum suppression)技术,筛选候选框数量。
Faster-RCNN目标检测算法执行思路可参考以下这篇文章:
https://blog.csdn.net/ELSA001/article/details/119983070?spm=1001.2014.3001.5501
二、效果展示
由于数据集过少(每一类只有120张图片)加上训练只有90代,因此预测精度不高。



三、环境配置
Anaconda:4.10.3
Python:3.6.13
tensorflow-gpu:2.2.0
四、图片数据集准备
Faster-RCNN目标检测算法的图片数据集采用VOC格式进行训练,使用labelimg制作VOC格式数据集使用方法可以参考以下文章:
https://blog.csdn.net/ELSA001/article/details/119987024?spm=1001.2014.3001.5501
也可以参考以下教学视频:
https://www.bilibili.com/video/BV1kV411k7D8
https://www.bilibili.com/video/BV1db411U7BB
图片打完标签之后,即可运行voc2faster-rcnn.py文件来生成这些训练相关的txt文件:

voc2faster-rcnn.py
#----------------------------------------------------------------------#
# 验证集的划分在train.py代码里面进行
# test.txt和val.txt里面没有内容是正常的。训练不会使用到。
#----------------------------------------------------------------------#
'''
#--------------------------------注意----------------------------------#
如果在pycharm中运行时提示:
FileNotFoundError: [WinError 3] 系统找不到指定的路径。: './VOCdevkit/VOC2007/Annotations'
这是pycharm运行目录的问题,最简单的方法是将该文件复制到根目录后运行。
可以查询一下相对目录和根目录的概念。在VSCODE中没有这个问题。
#--------------------------------注意----------------------------------#
'''
import os
import random
random.seed(0)
xmlfilepath=r'E:\\python-run-env\\Faster-RCNN\\VOCdevkit\\VOC2007\\Annotations'
saveBasePath=r"E:\\python-run-env\\Faster-RCNN\\VOCdevkit\\VOC2007\\ImageSets\\Main"
#----------------------------------------------------------------------#
# 想要增加测试集修改trainval_percent
# train_percent不需要修改
#----------------------------------------------------------------------#
trainval_percent=1
train_percent=1
temp_xml = os.listdir(xmlfilepath)
total_xml = []
for xml in temp_xml:
if xml.endswith(".xml"):
total_xml.append(xml)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
print("train and val size",tv)
print("traub suze",tr)
ftrainval = open(os.path.join(saveBasePath,'trainval.txt'), 'w')
ftest = open(os.path.join(saveBasePath,'test.txt'), 'w')
ftrain = open(os.path.join(saveBasePath,'train.txt'), 'w')
fval = open(os.path.join(saveBasePath,'val.txt'), 'w')
for i in list:
name=total_xml[i][:-4]+'\\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest .close()
接着运行voc_annotation.py文件来生成2007_train.txt文件:
voc_annotation.py
#---------------------------------------------#
# 运行前一定要修改classes
# 如果生成的2007_train.txt里面没有目标信息
# 那么就是因为classes没有设定正确
#---------------------------------------------#
import xml.etree.ElementTree as ET
from os import getcwd
sets=[('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
#-----------------------------------------------------#
# 这里设定的classes顺序要和model_data里的txt一样
#-----------------------------------------------------#
# classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]
classes = ["cabbage", "carrot", "nori", "potato"]
# E:\\python-run-env\\Faster-RCNN\\VOCdevkit\\VOC2007\\ImageSets\\Main\\train.txt
def convert_annotation(year, image_id, list_file):
in_file = open('E:/python-run-env/Faster-RCNN/VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id), encoding='utf-8')
tree=ET.parse(in_file)
root = tree.getroot()
for obj in root.iter('object'):
difficult = 0
if obj.find('difficult')!=None:
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (int(float(xmlbox.find('xmin').text)), int(float(xmlbox.find('ymin').text)), int(float(xmlbox.find('xmax').text)), int(float(xmlbox.find('ymax').text)))
list_file.write(" " + ",".join([str(a) for a in b]) + ',' + str(cls_id))
wd = getcwd()
for year, image_set in sets:
image_ids = open('E:/python-run-env/Faster-RCNN/VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set), encoding='utf-8').read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w', encoding='utf-8')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg'%(wd, year, image_id))
convert_annotation(year, image_id, list_file)
list_file.write('\\n')
list_file.close()
五、代码具体实现
由于我的电脑显卡配置有限(但其实我的环境可以训练和预测),因此我的图片数据集都在kaggle上面训练(https://www.kaggle.com/),每周可以免费使用GPU训练42小时,预测的代码在我自己的电脑上面执行,在这篇文章里,我将会展示我在kaggle的notebook里面的训练代码。
在kaggle上面训练模型时,需要注意以下几点:
1、训练时需要在kaggle上面上传2007_train.txt和自己的图片数据,如果有预训练权重文件的话也要上传上去。

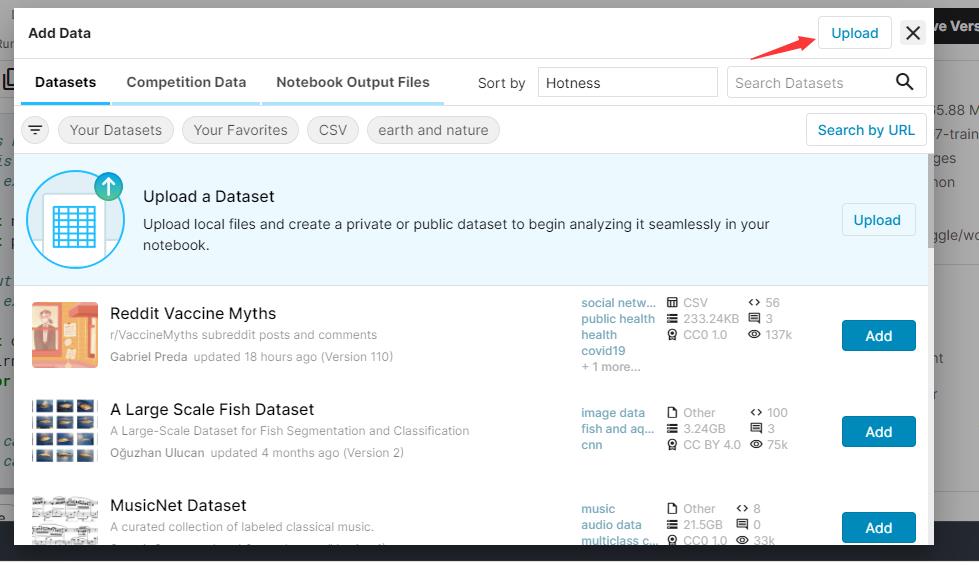

上传后在训练文件(train.py)修改自己的2007_train.txt路径:
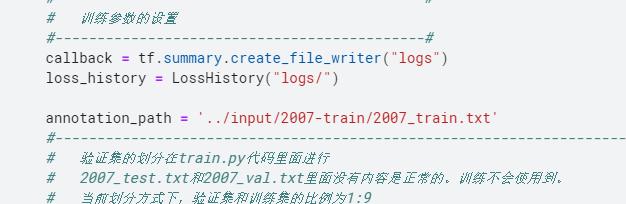
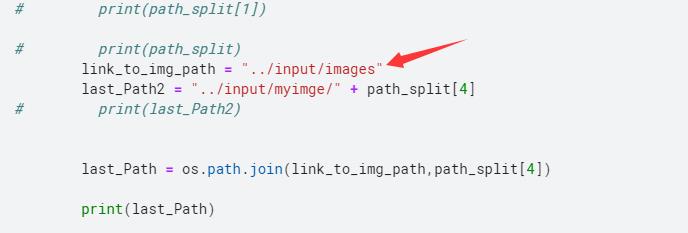
在frcnn_training3.py文件修改自己的图片数据位置:

2、由于notebook上面无法像正常编译器一样调用其他python文件,因此在每一个notebook上面都需要添加这样的一行代码:%%writefile filename.py,然后点击运行这个notebook,训练文件的notebook才可以正常调用。
教程如下:
https://www.tqwba.com/x_d/jishu/350998.html
3、训练过程中最好把鼠标点击一个notebook里面的代码,这样系统以为你就是在编辑代码的状态,不会判定你离开,如果系统判定你离开了,训练好的模型就都没有了,必须重新开始。
(1)预测代码(自己电脑上面预测)
预测代码(predict.py):
#----------------------------------------------------#
# 对视频中的predict.py进行了修改,
# 将单张图片预测、摄像头检测和FPS测试功能
# 整合到了一个py文件中,通过指定mode进行模式的修改。
#----------------------------------------------------#
import time
import cv2
import numpy as np
import tensorflow as tf
from PIL import Image
from frcnn import FRCNN
gpus = tf.config.experimental.list_physical_devices(device_type='GPU')
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
if __name__ == "__main__":
frcnn = FRCNN()
#-------------------------------------------------------------------------#
# mode用于指定测试的模式:
# 'predict'表示单张图片预测
# 'video'表示视频检测
# 'fps'表示测试fps
#-------------------------------------------------------------------------#
mode = "predict"
#-------------------------------------------------------------------------#
# video_path用于指定视频的路径,当video_path=0时表示检测摄像头
# video_save_path表示视频保存的路径,当video_save_path=""时表示不保存
# video_fps用于保存的视频的fps
# video_path、video_save_path和video_fps仅在mode='video'时有效
# 保存视频时需要ctrl+c退出才会完成完整的保存步骤,不可直接结束程序。
#-------------------------------------------------------------------------#
# video_path = r"E:/python-run-env/Faster RCNN/img/12.mp4"
video_path = 0
video_save_path = r"C:/Users/asus/Desktop/Test/12.mp4"
video_fps = 25.0
if mode == "predict":
'''
1、该代码无法直接进行批量预测,如果想要批量预测,可以利用os.listdir()遍历文件夹,利用Image.open打开图片文件进行预测。
具体流程可以参考get_dr_txt.py,在get_dr_txt.py即实现了遍历还实现了目标信息的保存。
2、如果想要进行检测完的图片的保存,利用r_image.save("img.jpg")即可保存,直接在predict.py里进行修改即可。
3、如果想要获得预测框的坐标,可以进入frcnn.detect_image函数,在绘图部分读取top,left,bottom,right这四个值。
4、如果想要利用预测框截取下目标,可以进入frcnn.detect_image函数,在绘图部分利用获取到的top,left,bottom,right这四个值
在原图上利用矩阵的方式进行截取。
5、如果想要在预测图上写额外的字,比如检测到的特定目标的数量,可以进入frcnn.detect_image函数,在绘图部分对predicted_class进行判断,
比如判断if predicted_class == 'car': 即可判断当前目标是否为车,然后记录数量即可。利用draw.text即可写字。
'''
while True:
img = input('Input image filename:')
try:
image = Image.open(img)
except:
print('Open Error! Try again!')
continue
else:
r_image = frcnn.detect_image(image)
r_image.show()
elif mode == "video":
capture=cv2.VideoCapture(video_path)
if video_save_path!="":
fourcc = cv2.VideoWriter_fourcc(*'XVID')
size = (int(capture.get(cv2.CAP_PROP_FRAME_WIDTH)), int(capture.get(cv2.CAP_PROP_FRAME_HEIGHT)))
out = cv2.VideoWriter(video_save_path, fourcc, video_fps, size)
fps = 0.0
while(True):
t1 = time.time()
# 读取某一帧
ref,frame=capture.read()
# 格式转变,BGRtoRGB
frame = cv2.cvtColor(frame,cv2.COLOR_BGR2RGB)
# 转变成Image
frame = Image.fromarray(np.uint8(frame))
# 进行检测
frame = np.array(frcnn.detect_image(frame))
# RGBtoBGR满足opencv显示格式
frame = cv2.cvtColor(frame,cv2.COLOR_RGB2BGR)
fps = ( fps + (1./(time.time()-t1)) ) / 2
print("fps= %.2f"%(fps))
frame = cv2.putText(frame, "fps= %.2f"%(fps), (0, 40), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
cv2.imshow("video",frame)
c= cv2.waitKey(1) & 0xff
if video_save_path!="":
out.write(frame)
if c==27:
capture.release()
break
capture.release()
out.release()
cv2.destroyAllWindows()
elif mode == "fps":
test_interval = 100
img = Image.open('img/street.jpg')
tact_time = frcnn.get_FPS(img, test_interval)
print(str(tact_time) + ' seconds, ' + str(1/tact_time) + 'FPS, @batch_size 1')
else:
raise AssertionError("Please specify the correct mode: 'predict', 'video' or 'fps'.")
frcnn.py
import colorsys
import copy
import os
import time
import numpy as np
import tensorflow as tf
from PIL import Image, ImageDraw, ImageFont
from tensorflow.keras.applications.imagenet_utils import preprocess_input
import nets.frcnn as frcnn
from nets.frcnn_training import get_new_img_size
from utils.anchors import get_anchors
from utils.config import Config
from utils.utils import BBoxUtility
#--------------------------------------------#
# 使用自己训练好的模型预测需要修改2个参数
# model_path和classes_path都需要修改!
# 如果出现shape不匹配
# 一定要注意训练时的NUM_CLASSES、
# model_path和classes_path参数的修改
#--------------------------------------------#
# E:\\python-run-env\\Faster-RCNN\\model_data\\voc_classes.txt
class FRCNN(object):
_defaults = {
# E:\\python-run-env\\Faster-RCNN\\model_data\\voc_weight.h5
"model_path" : r'E:\\python-run-env\\Faster-RCNN\\model_data\\Epoch90-Total_Loss0.5199-Val_Loss0.5419.h5',
"classes_path" : r'E:\\python-run-env\\Faster-RCNN\\model_data\\classes.txt',
"confidence" : 0.5,
"iou" : 0.3
}
@classmethod
def get_defaults(cls, n):
if n in cls._defaults:
return cls._defaults[n]
else:
return "Unrecognized attribute name '" + n + "'"
#---------------------------------------------------#
# 初始化faster RCNN
#---------------------------------------------------#
def __init__(self, **kwargs):
self.__dict__.update(self._defaults)
self.class_names = self._get_class()
self.config = Config()
self.generate()
self.bbox_util = BBoxUtility()
#---------------------------------------------------#
# 获得所有的分类
#---------------------------------------------------#
def _get_class(self):
classes_path = os.path.expanduser(self.classes_path)
with open(classes_path) as f:
class_names = f.readlines()
class_names = [c.strip() for c in class_names]
return class_names
#---------------------------------------------------#
# 获得所有的分类
#---------------------------------------------------#
def generate(self):
model_path = os.path.expanduser(self.model_path)
assert model_path.endswith('.h5'), 'Keras model or weights must be a .h5 file.'
#-------------------------------#
# 计算总的类的数量
#-------------------------------#
self.num_classes = len(self.class_names)+1
#-------------------------------#
# 载入模型与权值
#-------------------------------#
self.model_rpn, self.model_classifier = frcnn.get_predict_model(self.config, self.num_classes)
self.model_rpn.load_weights(self.model_path, by_name=True)
self.model_classifier.load_weights(self.model_path, by_name=True)
print('{} model, anchors, and classes loaded.'.format(model_path))
# 画框设置不同的颜色
hsv_tuples = [(x / len(self.class_names), 1., 1.)
for x in range(len(self.class_names))]
self.colors = list(map(lambda x: colorsys.hsv_to_rgb(*x), hsv_tuples))
self.colors = list(
map(lambda x: (int(x[0] * 255), int(x[1] * 255), int(x[2] * 255)),
self.colors))
#---------------------------------------------------#
# 用于计算共享特征层的大小
#---------------------------------------------------#
def get_img_output_length(self, width, height):
def get_output_length(input_length):
# input_length += 6
filter_sizes = [7, 3, 1, 1]
padding = [3,1,0,0]
stride = 2
for i in range(4):
# input_length = (input_length - filter_size + stride) // stride
input_length = (input_length+2*padding[i]-filter_sizes[i]) // stride [Python图像识别] 四十八.Pytorch构建Faster-RCNN模型实现小麦目标检测