目标检测SSD相对于YOLO与faster-RCNN做了哪些改进?效果如何
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了目标检测SSD相对于YOLO与faster-RCNN做了哪些改进?效果如何相关的知识,希望对你有一定的参考价值。
参考技术A 但是由于运行selective—search实在是太慢,希望用更快的方法。逗直接上YOLO呗可以参考博文:物体检测-从RCNN到YOLO参考列表中地YouOnlyLo好Once逗一项,包括YOLO的论文、视频、源码、使用方式。
目标检测 — one-stage检测
one-stage检测算法,其不需要region proposal阶段,直接产生物体的类别概率和位置坐标值,经过单次检测即可直接得到最终的检测结果,因此有着更快的检测速度,比较典型的算法如YOLO,SSD,Retina-Net。
4、SSD(2016)
SSD结合了YOLO中的回归思想和Faster-RCNN中的Anchor机制,使用全图各个位置的多尺度区域特征进行回归,既保持了YOLO速度快的特性,也保证了窗口预测的跟Faster-RCNN一样比较精准。
SSD的核心是在特征图上采用卷积核来预测一系列Default Bounding Boxes的类别、坐标偏移。为了提高检测准确率,SSD在不同尺度的特征图(5个)上进行预测。
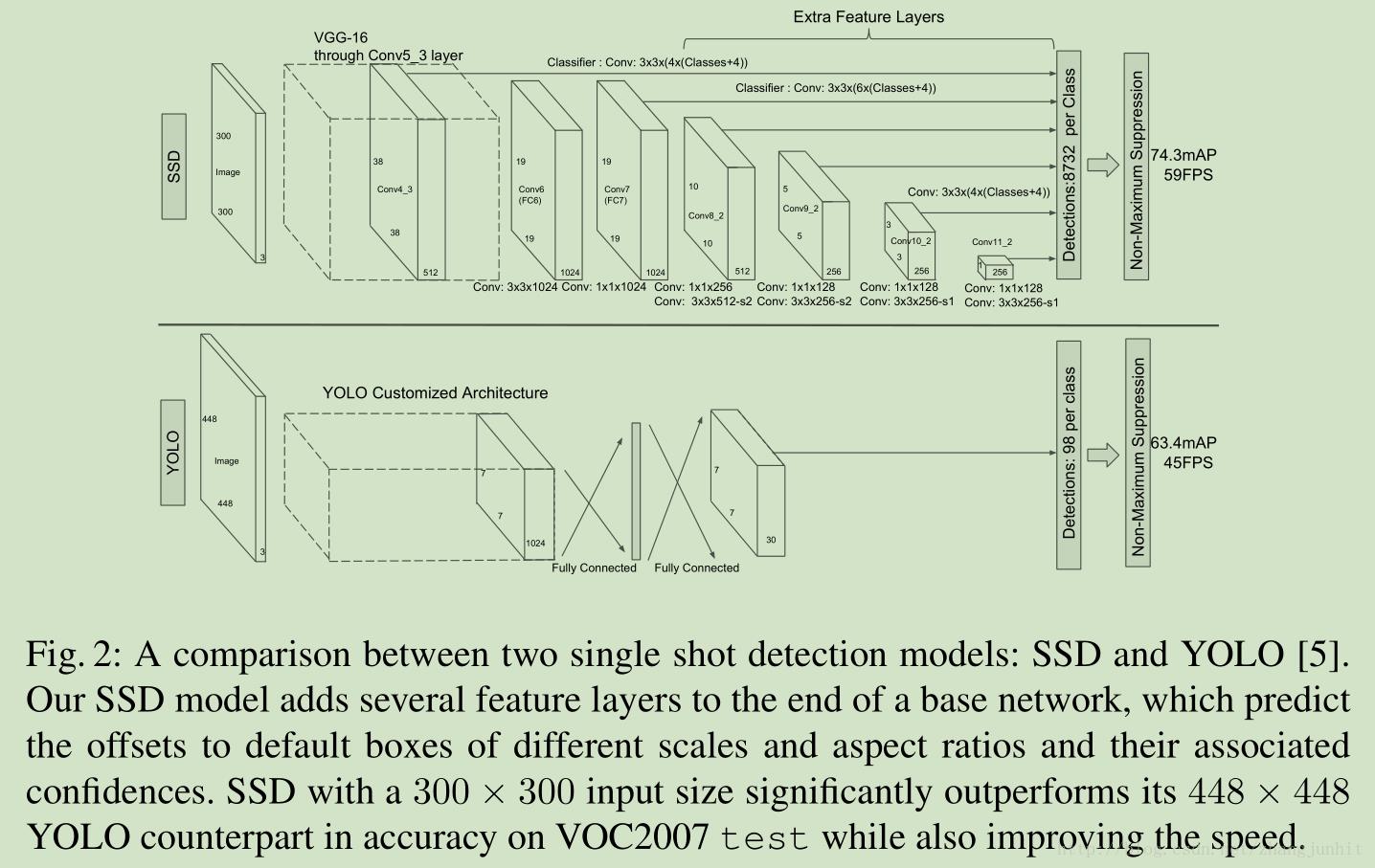
模型设计:
(1)采用多尺度特征图用于检测
所谓多尺度采用大小不同的特征图,CNN网络一般前面的特征图比较大,后面会逐渐采用stride=2的卷积或者pool来降低特征图大小,利用多个尺度图来做检测,比较大的特征图来用来检测相对较小的目标,而小的特征图负责检测大目标。
(2)采用卷积进行检测
SSD直接采用卷积对不同的特征图来进行提取检测结果。对于形状为m*m*p的特征图,只需要采用 3*3* p这样比较小的卷积核得到检测值。减少参数量。
(3)设置先验框
SSD借鉴了Faster R-CNN中anchor的理念,每个单元设置尺度或者长宽比不同的先验框,预测的边界框(bounding boxes)是以这些先验框为基准的,在一定程度上减少训练难度。
训练技巧:
(1)先验框匹配
在训练过程中,首先要确定训练图片中的ground truth(真实目标)与哪个先验框来进行匹配,与之匹配的先验框所对应的边界框将负责预测它。
SSD的先验框与ground truth的匹配原则主要有两点。首先,对于图片中每个ground truth,找到与其IOU最大的先验框,该先验框与其匹配。第二个原则是:对于剩余的未匹配先验框,若某个ground truth的 大于某个阈值(一般是0.5),那么该先验框也与这个ground truth进行匹配。
为了保证正负样本尽量平衡,SSD采用了hard negative mining,就是对负样本进行抽样,抽样时按照置信度误差(预测背景的置信度越小,误差越大)进行降序排列,选取误差的较大的top-k作为训练的负样本,以保证正负样本比例接近1:3。
(2)损失函数
与Faster-RCNN中的RPN是一样的,不过RPN是预测Box里面有Object或者没有,没有分类,SSD直接用的Softmax分类。Location的损失,还是一样,都是用Predict box和Default Box/Anchor的差 与Ground Truth Box和Default Box/Anchor的差进行对比,求损失。
损失函数定义为位置误差(locatization loss, loc)与置信度误差(confidence loss, conf)的加权和。对于位置误差,其采用Smooth L1 loss,对于置信度误差,其采用softmax loss。


(3)对每一张特征图,按照不同的大小(Scale) 和长宽比(Ratio)生成生成k个默认框(Default Boxes)
(4)数据扩增
主要采用的技术有水平翻转(horizontal flip),随机裁剪加颜色扭曲(random crop & color distortion),随机采集块域(Randomly sample a patch)(获取小目标训练样本)
- 数据扩增技术很重要,对于mAP的提升很大;
- 使用不同长宽比的先验框可以得到更好的结果;
- 采用多尺度的特征图用于检测也是至关重要的。
5、DSSD(2017)
最大的贡献,在常用的目标检测算法中加入上下文信息。
SSD算法对小目标不够鲁棒的最主要的原因是浅层feature map的表征能力不够强。DSSD就使用了更好的基础网络(ResNet-101)和Deconvolution层,skip连接来给浅层feature map更好的表征能力。
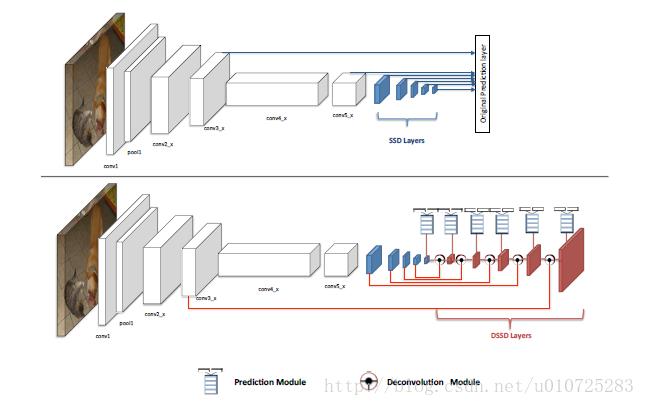
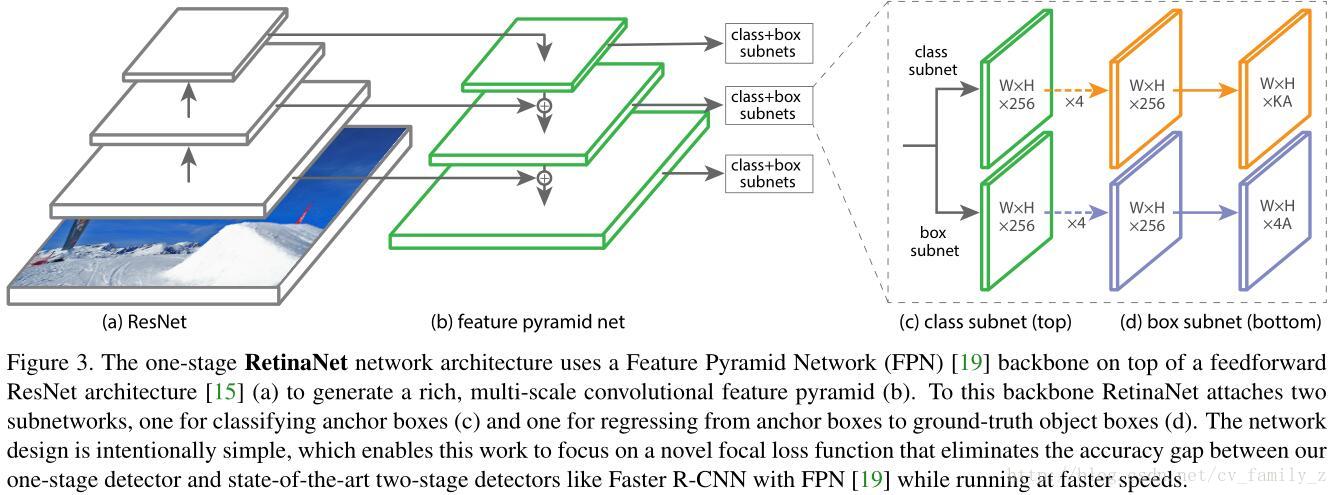
6、RetinaNet(2017)
提出Single stage detector不好的原因完全在于:
- 极度不平衡的正负样本比例: anchor近似于sliding window的方式会使正负样本接近1000:1,而且绝大部分负样本都是easy example,这就导致下面一个问题:
- gradient被easy example dominant的问题:往往这些easy example虽然loss很低,但由于数 量众多,对于loss依旧有很大贡献,从而导致收敛到不够好的一个结果。
作者提出了一个新的one-stage的检测器RetinaNet,达到了速度和精度很好地trade-off。使用改进的损失函数Focal Loss。
Focal Loss从交叉熵损失而来。二分类的交叉熵损失如下:

参考博客:http://lanbing510.info/2017/08/28/YOLO-SSD.html
以上是关于目标检测SSD相对于YOLO与faster-RCNN做了哪些改进?效果如何的主要内容,如果未能解决你的问题,请参考以下文章
深度学习之目标检测常用算法原理+实践精讲 YOLO / Faster RCNN / SSD / 文本检测 / 多任务网络
目标检测算法(R-CNN,fast R-CNN,faster R-CNN,yolo,SSD,yoloV2,yoloV3)