[Python图像识别] 四十八.Pytorch构建Faster-RCNN模型实现小麦目标检测
Posted Eastmount
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[Python图像识别] 四十八.Pytorch构建Faster-RCNN模型实现小麦目标检测相关的知识,希望对你有一定的参考价值。
该系列文章是讲解Python OpenCV图像处理知识,前期主要讲解图像入门、OpenCV基础用法,中期讲解图像处理的各种算法,包括图像锐化算子、图像增强技术、图像分割等,后期结合深度学习研究图像识别、图像分类应用。希望文章对您有所帮助,如果有不足之处,还请海涵~
上一篇文章主要通过Keras深度学习构建CNN模型识别阿拉伯手写文字图像,一篇非常经典的图像分类文字。本文将详细讲解Pytorch构建Faster-RCNN模型实现小麦目标检测,主要参考kaggle大佬和刘兄的模型,推荐大家关注。这是一篇非常经典的图像识别文字,希望您喜欢,且看且珍惜。
第二阶段我们进入了Python图像识别,该部分主要以目标检测、图像识别以及深度学习相关图像分类为主,将会分享近50篇文章,感谢您一如至往的支持。作者也会继续加油的!
同时,该部分知识均为作者查阅资料撰写总结,并且开设成了收费专栏,为小宝赚点奶粉钱,感谢您的抬爱。如果有问题随时私聊我,只望您能从这个系列中学到知识,一起加油。代码下载地址(如果喜欢记得star,一定喔):
图像识别:
- [Python图像识别] 四十五.对象检测案例入门及ImageAI基础用法
- [Python图像识别] 四十六.图像预处理之图像去雾详解(ACE算法和暗通道先验去雾算法)
- [Python图像识别] 四十七.Keras深度学习构建CNN识别阿拉伯手写文字图像
- [Python图像识别] 四十八.Pytorch构建Faster-RCNN模型实现小麦目标检测
图像处理:
- [Python图像处理] 一.图像处理基础知识及OpenCV入门函数
- [Python图像处理] 二.OpenCV+Numpy库读取与修改像素
- [Python图像处理] 三.获取图像属性、兴趣ROI区域及通道处理
- [Python图像处理] 四.图像平滑之均值滤波、方框滤波、高斯滤波及中值滤波
- [Python图像处理] 五.图像融合、加法运算及图像类型转换
- [Python图像处理] 六.图像缩放、图像旋转、图像翻转与图像平移
- [Python图像处理] 七.图像阈值化处理及算法对比
- [Python图像处理] 八.图像腐蚀与图像膨胀
- [Python图像处理] 九.形态学之图像开运算、闭运算、梯度运算
- [Python图像处理] 十.形态学之图像顶帽运算和黑帽运算
- [Python图像处理] 十一.灰度直方图概念及OpenCV绘制直方图
- [Python图像处理] 十二.图像几何变换之图像仿射变换、图像透视变换和图像校正
- [Python图像处理] 十三.基于灰度三维图的图像顶帽运算和黑帽运算
- [Python图像处理] 十四.基于OpenCV和像素处理的图像灰度化处理
- [Python图像处理] 十五.图像的灰度线性变换
- [Python图像处理] 十六.图像的灰度非线性变换之对数变换、伽马变换
- [Python图像处理] 十七.图像锐化与边缘检测之Roberts算子、Prewitt算子、Sobel算子和Laplacian算子
- [Python图像处理] 十八.图像锐化与边缘检测之Scharr算子、Canny算子和LOG算子
- [Python图像处理] 十九.图像分割之基于K-Means聚类的区域分割
- [Python图像处理] 二十.图像量化处理和采样处理及局部马赛克特效
- [Python图像处理] 二十一.图像金字塔之图像向下取样和向上取样
- [Python图像处理] 二十二.Python图像傅里叶变换原理及实现
- [Python图像处理] 二十三.傅里叶变换之高通滤波和低通滤波
- [Python图像处理] 二十四.图像特效处理之毛玻璃、浮雕和油漆特效
- [Python图像处理] 二十五.图像特效处理之素描、怀旧、光照、流年以及滤镜特效
- [Python图像处理] 二十六.图像分类原理及基于KNN、朴素贝叶斯算法的图像分类案例
- [Python图像处理] 二十七.OpenGL入门及绘制基本图形(一)
- [Python图像处理] 二十八.OpenCV快速实现人脸检测及视频中的人脸
- [Python图像处理] 二十九.MoviePy视频编辑库实现抖音短视频剪切合并操作
- [Python图像处理] 三十.图像量化及采样处理万字详细总结(推荐)
- [Python图像处理] 三十一.图像点运算处理两万字详细总结(灰度化处理、阈值化处理)
- [Python图像处理] 三十二.傅里叶变换(图像去噪)与霍夫变换(特征识别)万字详细总结
- [Python图像处理] 三十三.图像各种特效处理及原理万字详解(毛玻璃、浮雕、素描、怀旧、流年、滤镜等)
- [Python图像处理] 三十四.数字图像处理基础与几何图形绘制万字详解(推荐)
- [Python图像处理] 三十五.OpenCV图像处理入门、算数逻辑运算与图像融合(推荐)
- [Python图像处理] 三十六.OpenCV图像几何变换万字详解(平移缩放旋转、镜像仿射透视)
- [Python图像处理] 三十七.OpenCV和Matplotlib绘制直方图万字详解(掩膜直方图、H-S直方图、黑夜白天判断)
- [Python图像处理] 三十八.OpenCV图像增强万字详解(直方图均衡化、局部直方图均衡化、自动色彩均衡化)
- [Python图像处理] 三十九.Python图像分类万字详解(贝叶斯图像分类、KNN图像分类、DNN图像分类)
- [Python图像处理] 四十.全网首发Python图像分割万字详解(阈值分割、边缘分割、纹理分割、分水岭算法、K-Means分割、漫水填充分割、区域定位)
- [Python图像处理] 四十一.Python图像平滑万字详解(均值滤波、方框滤波、高斯滤波、中值滤波、双边滤波)
- [Python图像处理] 四十二.Python图像锐化及边缘检测万字详解(Roberts、Prewitt、Sobel、Laplacian、Canny、LOG)
- [Python图像处理] 四十三.Python图像形态学处理万字详解(腐蚀膨胀、开闭运算、梯度顶帽黑帽运算)
- 万字长文告诉新手如何学习Python图像处理 (上篇完结 四十四)
一.Pytorch安装
Pytorch安装需要在官网选择对应的环境,接着按自动生成的安装命令执行。
选择与自己相匹配的版本,这里显示是我安装的选择。
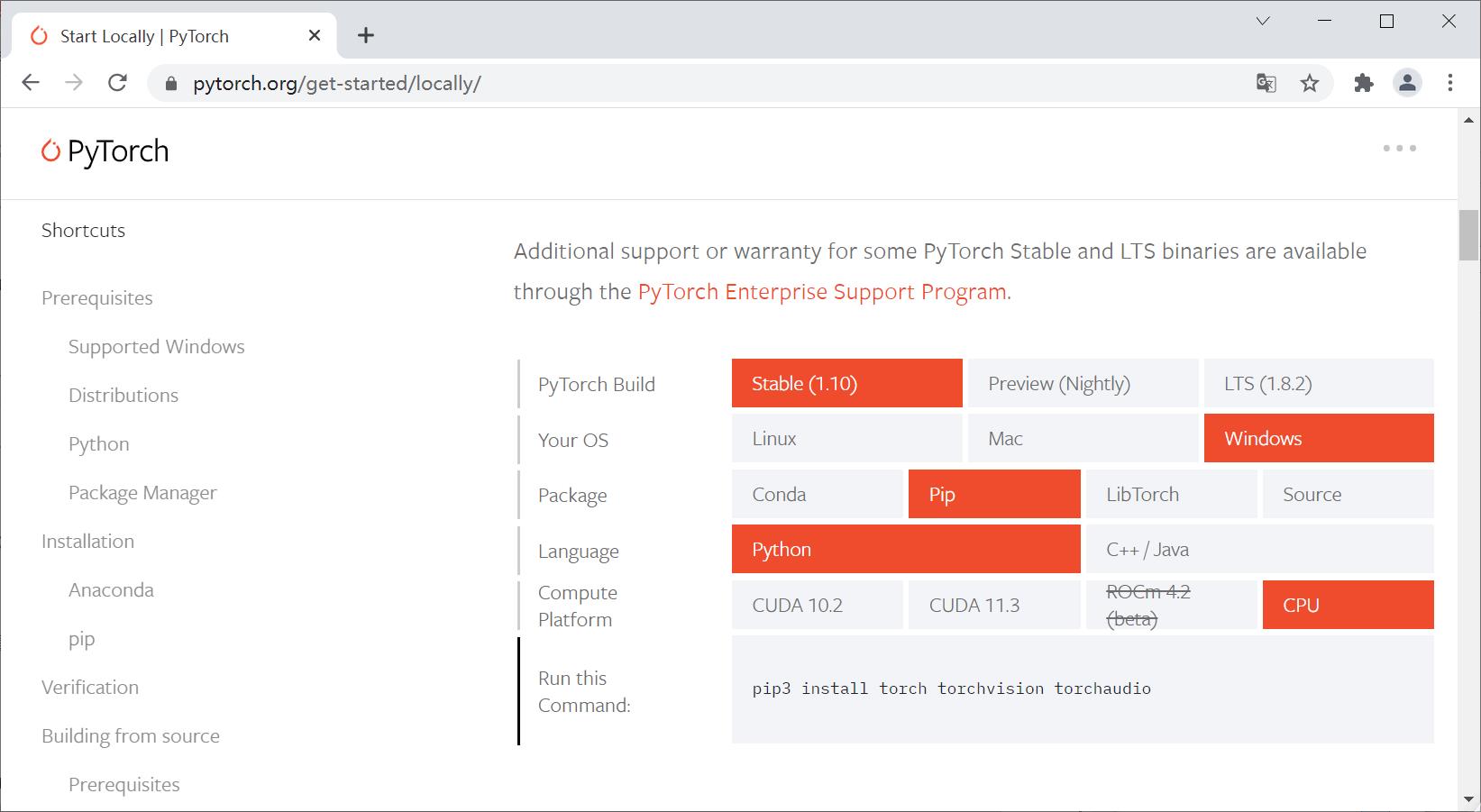
安装代码:
- pip3 install torch torchvision torchaudio
- conda install pytorch torchvision torchaudio cpuonly -c pytorch
同时安装扩展包albumentations。
- pip install albumentations

二.数据集描述
1.Kaggle赛题
数据集是来自Kaggle的——全球小麦检测数据,题目是“您能使用图像分析帮助识别小麦吗?”

题目介绍:
打开您的食品储藏室,您很可能会找到几种小麦产品。事实上,您的早餐吐司或麦片可能依赖于这种常见的谷物。它作为一种流行的食物和作物,让小麦得到了广泛的研究。为了获得有关全球麦田的大量准确数据,植物科学家使用“小麦头”的图像,检测含有谷物的植物顶部尖峰。这些图像用于估计不同品种小麦的密度和大小。农民在他们的田地做出管理决策时,可以使用这些数据来评估其健康和成熟度。
然而,在室外田间图像中准确检测麦头在视觉上具有挑战性。密密麻麻的小麦植株经常重叠,风会模糊照片。两者都使识别单个头部变得困难。此外,外观因成熟度、颜色、基因类型和头部方向而异。最后,由于小麦在世界范围内种植,因此必须考虑不同的品种、种植密度、模式和田间条件。小麦开发模型需要在不同的生长环境之间进行概括。当前的检测方法涉及一级和二级检测器(Yolo-v3 和 Faster-RCNN),但即使使用大型数据集进行训练,对训练区域的偏差仍然存在。
在全球小麦头数据集是由来自七个国家的九个研究机构主导,包括东京大学等。此后,许多机构都加入了他们追求准确检测小麦头部的行列,包括全球食品安全研究所、DigitAg、Kubota 和 Hiphen。在本次比赛中,您将从小麦植物的室外图像中检测小麦头,包括来自全球的小麦数据集。使用全球数据,您将专注于通用解决方案来估计小麦头的数量和大小。为了更好地衡量未知基因型、环境和观察条件的性能,训练数据集涵盖多个区域。您将使用来自欧洲(法国、英国、瑞士)和北美(加拿大)的 3,000 多张图像。测试数据包括来自澳大利亚、日本和中国的约 1,000 张图像。
小麦是全球的主食,这就是为什么这种竞争必须考虑到不同的生长条件。为小麦表型开发的模型需要能够在环境之间进行概括。如果成功,研究人员可以准确估计不同品种小麦头的密度和大小。通过改进的检测,农民可以更好地评估他们的作物,最终将谷物、烤面包和其他喜爱的菜肴带到您的餐桌上。有关数据采集和过程的更多详细信息,请访问:

2.数据集介绍
我们应该期望数据格式是什么?
数据是麦田的图像,每个识别的麦头都有边界框,并非所有图像都包含小麦头/边界框。这些图像被记录在世界各地的许多地方。
- CSV 数据很简单:图像 ID 与给定图像的文件名相匹配,并且包含图像的宽度和高度以及边界框(见下文)。train.csv每个边界框都有一行,并非所有图像都有边界框。大多数测试集图像是隐藏的,包含一小部分测试图像供您在编写代码时使用。
我们在预测什么?
您正在尝试预测图像中每个小麦头周围的边界框。如果没有小麦头,则必须预测没有边界框。
数据集包含四个文件
- train.csv - 训练数据
- sample_submission.csv - 格式正确的示例提交文件
- train.zip - 训练图像
- test.zip - 测试图像
数据集如下图所示:

文件夹中包含小麦图像,名称是其ID。

train.csv中对应五列结果,分别是:
- image_id - 唯一的图像 ID
- width - 图像的宽度
- height - 图像的高度
- bbox - 一个边界框,格式为 [xmin, ymin, width, height] 的 Python 样式列表
- source - 图像对应的类别
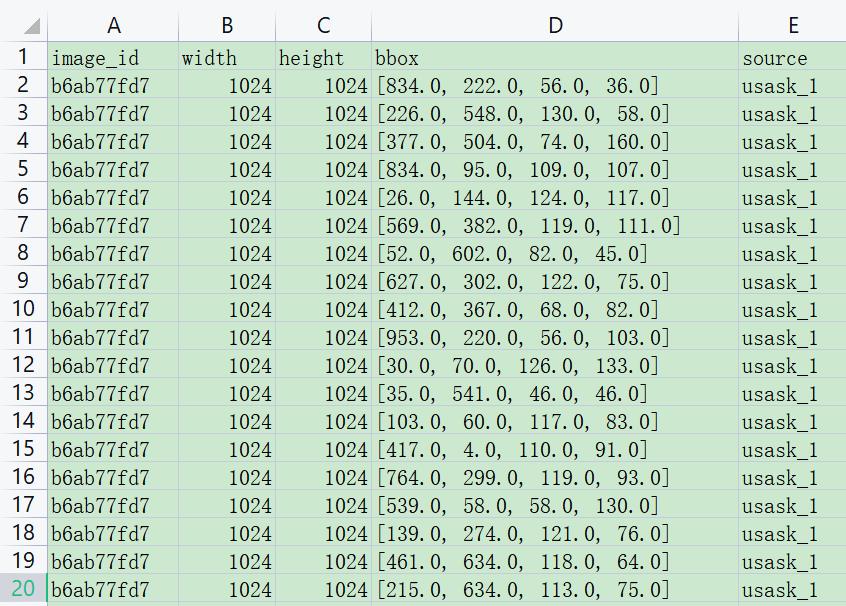
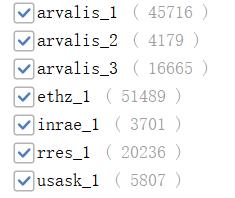
训练集中各小麦类型分布如下图所示:
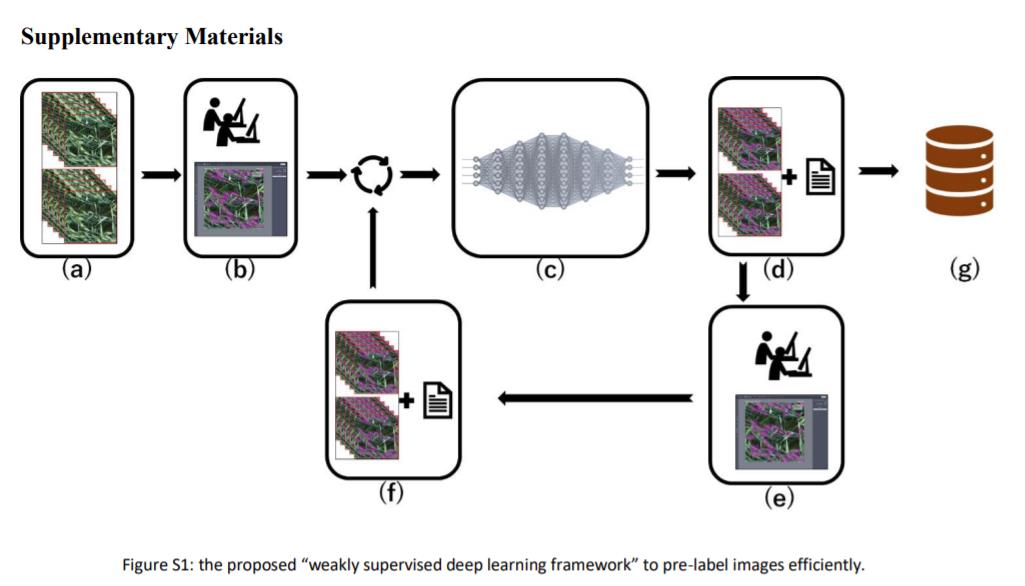
整个小麦预测的大致流程如下图所示:
模型评估参数如下所示,推荐大家阅读kaggle官网介绍。

提交格式需要以空格分隔的一组边界框。例如:
- ce4833752, 0.5 0 0 100 100
表示图像ce4833752有一个边界框,aconfidence为 0.5,在x== 0 和y== 0,awidth和height为 100。
该文件应包含标题并具有以下格式,您提交的每一行都应包含给定图像的所有边界框。
image_id,PredictionString
ce4833752,1.0 0 0 50 50
adcfa13da,1.0 0 0 50 50
6ca7b2650,
1da9078c1,0.3 0 0 50 50 0.5 10 10 30 30
7640b4963,0.5 0 0 50 50
三.代码实现
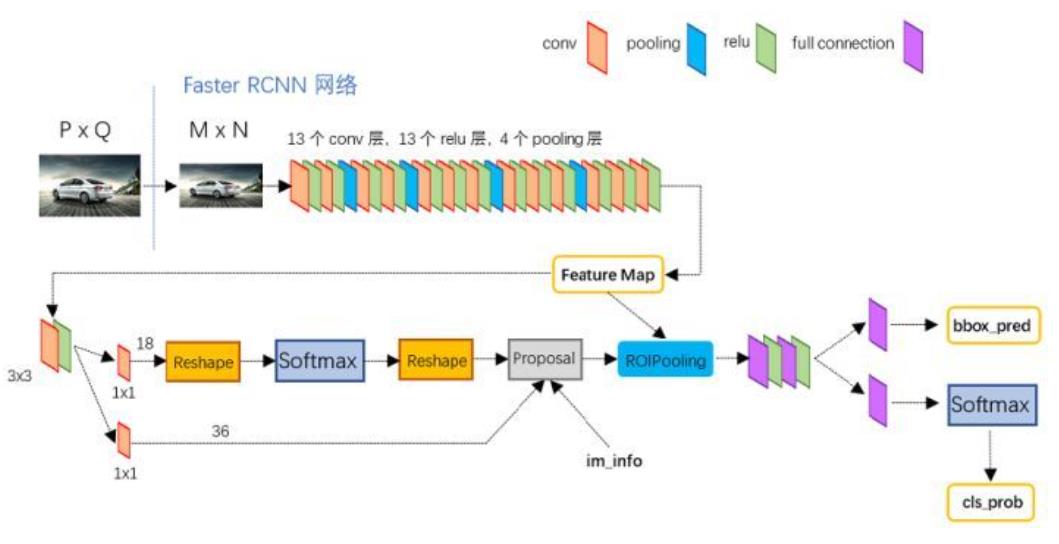
下面我们参考Kaggle Peter老师的代码,来复现Faster-RCNN模型。
模型的框架如下图所示,相信大家都比较熟悉,也推荐大家使用并深入了解背后的原理。
1.读取小麦数据
读取小麦数据集的代码如下:
# -*- coding: utf-8 -*-
"""
Created on Fri Oct 29 13:42:38 2021
@author: xiuzhang
"""
import os
import re
import cv2
import pandas as pd
import numpy as np
from PIL import Image
import albumentations as A
from matplotlib import pyplot as plt
from albumentations.pytorch.transforms import ToTensorV2
import torch
import torchvision
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
from torchvision.models.detection import FasterRCNN
from torchvision.models.detection.rpn import AnchorGenerator
from torch.utils.data import DataLoader, Dataset
from torch.utils.data.sampler import SequentialSampler
from dataset import WheatDataset
#-----------------------------------------------------------------------------
#第一步 函数定义
#----------------------------------------------------------------------------
#提取box的四个坐标
def expand_bbox(x):
r = np.array(re.findall("([0-9]+[.]?[0-9]*)", x))
if len(r) == 0:
r = [-1, -1, -1, -1]
return r
#训练图像增强 Albumentations
def get_train_transform():
return A.Compose([
A.Flip(0.5),
ToTensorV2(p=1.0)
], bbox_params={'format': 'pascal_voc', 'label_fields': ['labels']})
#验证图像增强
def get_valid_transform():
return A.Compose([
ToTensorV2(p=1.0)
], bbox_params={'format': 'pascal_voc', 'label_fields': ['labels']})
def collate_fn(batch):
return tuple(zip(*batch))
#-----------------------------------------------------------------------------
#第二步 定义变量并读取数据
#-----------------------------------------------------------------------------
DIR_INPUT = 'data'
DIR_TRAIN = f'{DIR_INPUT}/train'
DIR_TEST = f'{DIR_INPUT}/test'
train_df = pd.read_csv(f'{DIR_INPUT}/train.csv')
print(train_df.shape)
train_df['x'] = -1
train_df['y'] = -1
train_df['w'] = -1
train_df['h'] = -1
#读取box四个坐标
train_df[['x', 'y', 'w', 'h']] = np.stack(train_df['bbox'].apply(lambda x: expand_bbox(x)))
train_df.drop(columns=['bbox'], inplace=True)
train_df['x'] = train_df['x'].astype(np.float)
train_df['y'] = train_df['y'].astype(np.float)
train_df['w'] = train_df['w'].astype(np.float)
train_df['h'] = train_df['h'].astype(np.float)
#获取图像id
image_ids = train_df['image_id'].unique()
valid_ids = image_ids[-665:]
train_ids = image_ids[:-665]
valid_df = train_df[train_df['image_id'].isin(valid_ids)]
train_df = train_df[train_df['image_id'].isin(train_ids)]
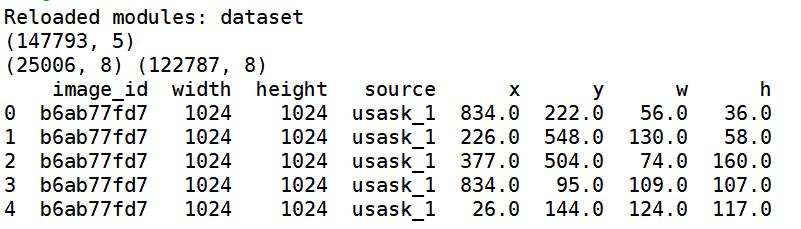
print(valid_df.shape, train_df.shape)
print(train_df.head())
显示结果如下图所示,分别获取图像id和数据,并划分为train(训练)和valid(验证)。
其中,dataset.py文件代码如下:
- 获取图像id
- 获取图像像素值并归一化处理
- 获取图像对应的边界(x | y | w | h)
# -*- coding: utf-8 -*-
"""
Created on Fri Oct 29 13:42:38 2021
@author: xiuzhang
"""
import numpy as np
import cv2
import torch
from torch.utils.data import Dataset
class WheatDataset(Dataset):
def __init__(self, dataframe, image_dir, transforms=None):
super().__init__()
self.image_ids = dataframe['image_id'].unique()
self.df = dataframe
self.image_dir = image_dir
self.transforms = transforms
def __getitem__(self, index: int):
image_id = self.image_ids[index]
records = self.df[self.df['image_id'] == image_id]
image = cv2.imread(f'{self.image_dir}/{image_id}.jpg', cv2.IMREAD_COLOR)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB).astype(np.float32)
image /= 255.0
boxes = records[['x', 'y', 'w', 'h']].values
boxes[:, 2] = boxes[:, 0] + boxes[:, 2]
boxes[:, 3] = boxes[:, 1] + boxes[:, 3]
area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0])
area = torch.as_tensor(area, dtype=torch.float32)
# there is only one class
labels = torch.ones((records.shape[0],), dtype=torch.int64)
# suppose all instances are not crowd
iscrowd = torch.zeros((records.shape[0],), dtype=torch.int64)
target = {}
target['boxes'] = boxes
target['labels'] = labels
# target['masks'] = None
target['image_id'] = torch.tensor([index])
target['area'] = area
target['iscrowd'] = iscrowd
if self.transforms:
sample = {
'image': image,
'bboxes': target['boxes'],
'labels': labels
}
sample = self.transforms(**sample)
image = sample['image']
target['boxes'] = torch.stack(tuple(map(torch.tensor, zip(*sample['bboxes'])))).permute(1, 0)
return image, target, image_id
def __len__(self) -> int:
return self.image_ids.shape[0]
2.可视化展示
接下来我们对小麦图像进行简单的可视化操作,代码如下:
# -*- coding: utf-8 -*-
"""
Created on Fri Oct 29 13:42:38 2021
@author: xiuzhang
"""
import os
import re
import cv2
import pandas as pd
import numpy as np
from PIL import Image
import albumentations as A
from matplotlib import pyplot as plt
from albumentations.pytorch.transforms import ToTensorV2
import torch
import torchvision
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
from torchvision.models.detection import FasterRCNN
from torchvision.models.detection.rpn import AnchorGenerator
from torch.utils.data import DataLoader, Dataset
from torch.utils.data.sampler import SequentialSampler
from dataset import WheatDataset
#-----------------------------------------------------------------------------
#第一步 函数定义
#----------------------------------------------------------------------------
#提取box的四个坐标
def expand_bbox(x):
r = np.array(re.findall("([0-9]+[.]?[0-9]*)", x))
if len(r) == 0:
r = [-1, -1, -1, -1]
return r
#训练图像增强 Albumentations
def get_train_transform():
return A.Compose([
A.Flip(0.5),
ToTensorV2(p=1.0)
], bbox_params={'format': 'pascal_voc', 'label_fields': ['labels']})
#验证图像增强
def get_valid_transform():
return A.Compose([
ToTensorV2(p=1.0)
], bbox_params={'format': 'pascal_voc', 'label_fields': ['labels']})
def collate_fn(batch):
return tuple(zip(*batch))
#-----------------------------------------------------------------------------
#第二步 定义变量并读取数据
#-----------------------------------------------------------------------------
DIR_INPUT = 'data'
DIR_TRAIN = f'{DIR_INPUT}/train'
DIR_TEST = f'{DIR_INPUT}/test'
train_df = pd.read_csv(f'{DIR_INPUT}/train.csv')
print(train_df.shape)
train_df['x'] = -1
train_df['y'] = -1
train_df['w'] = -1
train_df['h'] = -1
#读取box四个坐标
train_df[['x', 'y', 'w', 'h']] = np.stack(train_df['bbox'].apply(lambda x: expand_bbox(x)))
train_df.drop(columns=['bbox'], inplace=True)
train_df['x'[Python从零到壹] 四十八.图像增强及运算篇之形态学开运算闭运算和梯度运算
[Python图像识别] 四十七.Keras深度学习构建CNN识别阿拉伯手写文字图像
[Python图像识别] 四十五.目标检测入门普及和ImageAI“傻瓜式”对象检测案例详解