大数据Spark Structured Streaming
Posted 赵广陆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据Spark Structured Streaming相关的知识,希望对你有一定的参考价值。
目录
1 Spark Streaming 不足
Apache Spark在2016年的时候启动了Structured Streaming项目,一个基于Spark SQL的全新流计算引擎Structured Streaming,让用户像编写批处理程序一样简单地编写高性能的流处理程序。
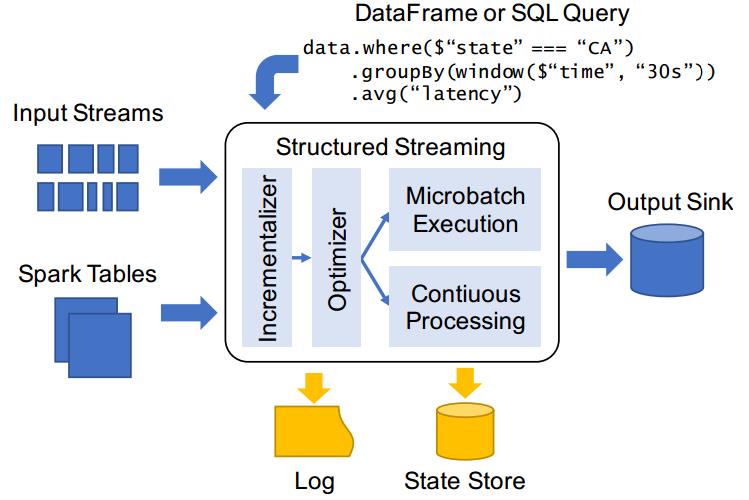
Structured Streaming并不是对Spark Streaming的简单改进,而是吸取了在开发SparkSQL和Spark Streaming过程中的经验教训,以及Spark社区和Databricks众多客户的反馈,重新开发的全新流式引擎,致力于为批处理和流处理提供统一的高性能API。同时,在这个新的引擎中,也很容易实现之前在Spark Streaming中很难实现的一些功能,比如EventTime(事件时间)的支持,Stream-Stream Join(2.3.0 新增的功能),毫秒级延迟(2.3.0即将加入的 Continuous Processing)。
Spark Streaming是Apache Spark早期基于RDD开发的流式系统,用户使用DStream API来编写代码,支持高吞吐和良好的容错。其背后的主要模型是Micro Batch(微批处理),也就是将数据流切成等时间间隔(BatchInterval)的小批量任务来执行。
Structured Streaming则是在Spark 2.0加入的,经过重新设计的全新流式引擎。它的模型十分简洁,易于理解。一个流的数据源从逻辑上来说就是一个不断增长的动态表格,随着时间的推移,新数据被持续不断地添加到表格的末尾,用户可以使用Dataset/DataFrame 或者 SQL 来对这个动态数据源进行实时查询。
文档:http://spark.apache.org/docs/2.4.5/structured-streaming-programming-guide.html
Spark Streaming 会接收实时数据源的数据,并切分成很多小的batches,然后被Spark Engine执行,产出同样由很多小的batchs组成的结果流。

本质上,这是一种micro-batch(微批处理)的方式处理,用批的思想去处理流数据。这种设计让Spark Streaming面对复杂的流式处理场景时捉襟见肘。
Spark Streaming 存在哪些不足,总结一下主要有下面几点:
- 第一点:使用 Processing Time 而不是 Event Time
- Processing Time 是数据到达 Spark 被处理的时间,而 Event Time 是数据自带的属性,
一般表示数据产生于数据源的时间。 - 比如 IoT 中,传感器在 12:00:00 产生一条数据,然后在 12:00:05 数据传送到 Spark,
那么 Event Time 就是 12:00:00,而 Processing Time 就是 12:00:05。 - Spark Streaming是基于DStream模型的micro-batch模式,简单来说就是将一个微小时间段(比如说 1s)的流数据当前批数据来处理。如果要统计某个时间段的一些数据统计,毫无疑问应该使用 Event Time,但是因为 Spark Streaming 的数据切割是基于Processing Time,这样就导致使用 Event Time 特别的困难。
- 第二点:Complex, low-level api
- DStream(Spark Streaming 的数据模型)提供的API类似RDD的API,非常的low level;
- 当编写Spark Streaming程序的时候,本质上就是要去构造RDD的DAG执行图,然后通过
Spark Engine运行。这样导致一个问题是,DAG 可能会因为开发者的水平参差不齐而导
致执行效率上的天壤之别;
- 第三点:reason about end-to-end application
- end-to-end指的是直接input到out,如Kafka接入Spark Streaming然后再导出到HDFS中;
- DStream 只能保证自己的一致性语义是 exactly-once 的,而 input 接入 Spark
Streaming 和 Spark Straming 输出到外部存储的语义往往需要用户自己来保证;
- 第四点:批流代码不统一
- 尽管批流本是两套系统,但是这两套系统统一起来确实很有必要,有时候确实需要将的流
处理逻辑运行到批数据上面;
Streaming尽管是对RDD的封装,但是要将DStream代码完全转换成RDD还是有一点工作
量的,更何况现在Spark的批处理都用DataSet/DataFrameAPI;
流式计算一直没有一套标准化、能应对各种场景的模型,直到2015年Google发表了The
Dataflow Model的论文( https://yq.aliyun.com/articles/73255 )。Google开源Apache Beam项
目,基本上就是对Dataflow模型的实现,目前已经成为Apache的顶级项目,但是在国内使用不多。
国内使用的更多的是Apache Flink,因为阿里大力推广Flink,甚至把花7亿元把Flink母公司收购。
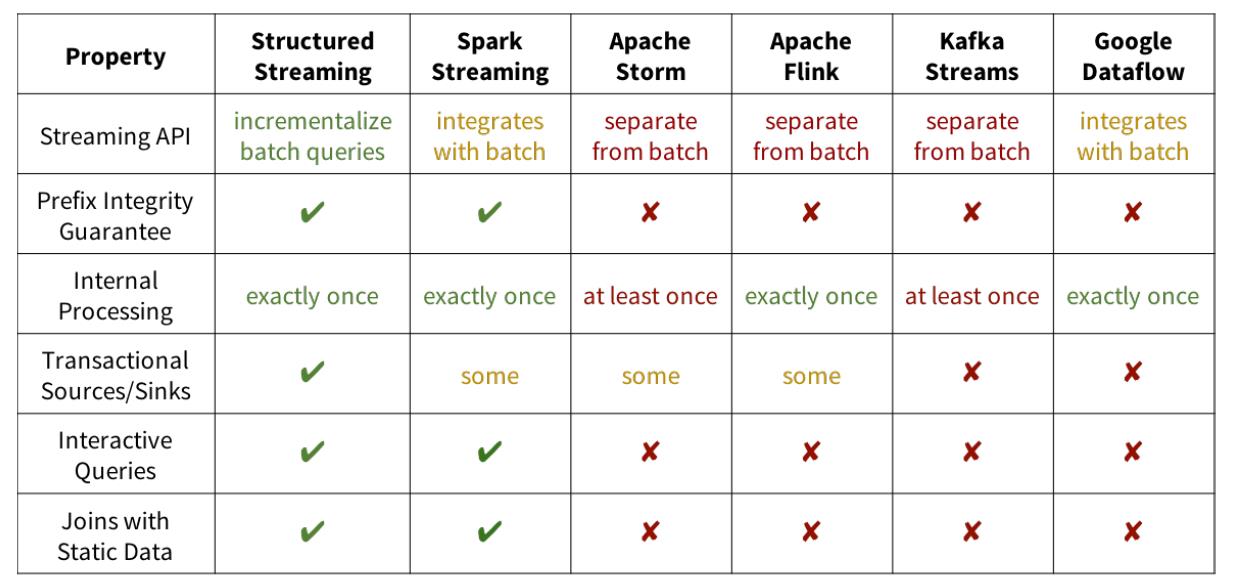
使用Yahoo的流基准平台,要求系统读取广告点击事件,并按照活动ID加入到一个广告活动的
静态表中,并在10秒的event-time窗口中输出活动计数。比较了Kafka Streams 0.10.2、Apache Flink1.2.1和Spark 2.3.0,在一个拥有5个c3.2*2大型Amazon EC2 工作节点和一个master节点的集群上(硬件条件为8个虚拟核心和15GB的内存)。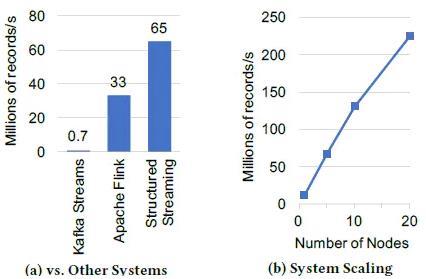
上图(a)展示了每个系统最大稳定吞吐量(积压前的吞吐量),Flink可以达到3300万,而
Structured Streaming可以达到6500万,近乎两倍于Flink。这个性能完全来自于Spark SQL的内置
执行优化,包括将数据存储在紧凑的二进制文件格式以及代码生成。
2 Structured Streaming 概述
或许是对Dataflow模型的借鉴,也许是英雄所见略同,Spark在2.0版本中发布了新的流计算的
API:Structured Streaming结构化流。Structured Streaming是一个基于Spark SQL引擎的可扩展、容错的流处理引擎。统一了流、批的编程模型,可以使用静态数据批处理一样的方式来编写流式计算操作,并且支持基于event_time的时间窗口的处理逻辑。随着数据不断地到达,Spark 引擎会以一种增量的方式来执行这些操作,并且持续更新结算结果。

2.1 模块介绍
Structured Streaming 在 Spark 2.0 版本于 2016 年引入,设计思想参考很多其他系统的思想,比如区分 processing time 和 event time,使用 relational 执行引擎提高性能等。同时也考虑了和 Spark 其他组件更好的集成。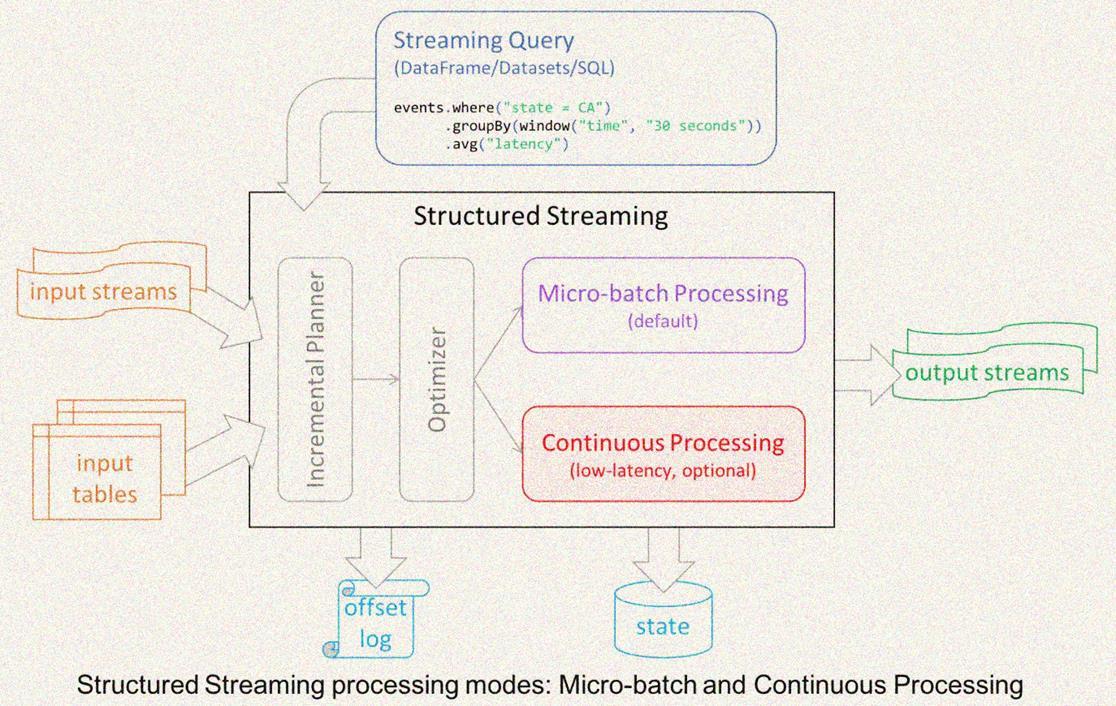
Structured Streaming 和其他系统的显著区别主要如下:
- 第一点:Incremental query model(增量查询模型)
- Structured Streaming 将会在新增的流式数据上不断执行增量查询,同时代码的写法和批处理 API(基于Dataframe和Dataset API)完全一样,而且这些API非常的简单。
- 第二点:Support for end-to-end application(支持端到端应用)
- Structured Streaming 和内置的 connector 使的 end-to-end 程序写起来非常的简单,而且 “correct by default”。数据源和sink满足 “exactly-once” 语义,这样我们就可以在此基础上更好地和外部系统集成。
- 第三点:复用 Spark SQL 执行引擎
- Spark SQL 执行引擎做了非常多的优化工作,比如执行计划优化、codegen、内存管理等。这也是Structured Streaming取得高性能和高吞吐的一个原因。
1.2.2 核心设计
2016年,Spark在2.0版本中推出了结构化流处理的模块Structured Streaming,核心设计如下:
- 第一点:Input and Output(输入和输出)
- Structured Streaming 内置了很多 connector 来保证 input 数据源和 output sink 保证 exactly-once 语义。
- 实现 exactly-once 语义的前提:
- Input 数据源必须是可以replay的,比如Kafka,这样节点crash的时候就可以重新读
取input数据,常见的数据源包括 Amazon Kinesis, Apache Kafka 和文件系统。 - Output sink 必须要支持写入是幂等的,这个很好理解,如果 output 不支持幂等写入,那么一致性语义就是 at-least-once 了。另外对于某些 sink, StructuredStreaming 还提供了原子写入来保证 exactly-once 语义。
- 补充:幂等性:在HTTP/1.1中对幂等性的定义:一次和多次请求某一个资源对于资源本身应该具有同样的结果(网络超时等问题除外)。也就是说,其任意多次执行对资源本身所产生的影响均与一次执行的影响相同。幂等性是系统服务对外一种承诺(而不是实现),承诺只要调用接口成功,外部多次调用对系统的影响是一致的。声明为幂等的服务会认为外部调用失败是常态,并且失败之后必然会有重试。
- 第二点:Program API(编程 API)
- Structured Streaming 代码编写完全复用 Spark SQL 的 batch API,也就是对一个或者多个 stream 或者 table 进行 query。

- query 的结果是 result table,可以以多种不同的模式(追加:append, 更新:update, 完全:complete)输出到外部存储中。
- 另外,Structured Streaming 还提供了一些 Streaming 处理特有的 API:Trigger,watermark, stateful operator。
- 第三点:Execution Engine(执行引擎)
- 复用 Spark SQL 的执行引擎;
- Structured Streaming 默认使用类似 Spark Streaming 的 micro-batch 模式,有很多好
处,比如动态负载均衡、再扩展、错误恢复以及 straggler (straggler 指的是哪些执行明显慢于其他 task 的 task)重试; - 提供了基于传统的 long-running operator 的 continuous(持续) 处理模式;
- 第四点:Operational Features(操作特性)
- 利用 wal 和状态State存储,开发者可以做到集中形式的 rollback 和错误恢复FailOver。
2.3 编程模型
Structured Streaming将流式数据当成一个不断增长的table,然后使用和批处理同一套API,都是基于DataSet/DataFrame的。如下图所示,通过将流式数据理解成一张不断增长的表,从而就可以像操作批的静态数据一样来操作流数据了。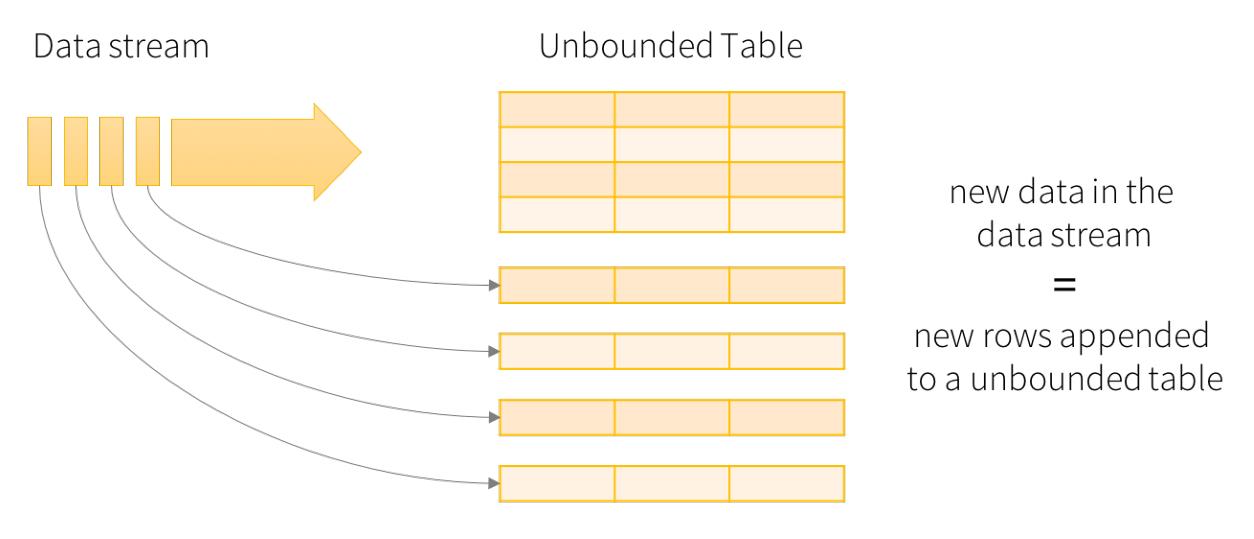
在这个模型中,主要存在下面几个组成部分:
- 第一部分:Input Table(Unbounded Table),流式数据的抽象表示,没有限制边界的,表的
数据源源不断增加; - 第二部分:Query(查询),对 Input Table 的增量式查询,只要Input Table中有数据,立即(默认情况)执行查询分析操作,然后进行输出(类似SparkStreaming中微批处理);
- 第三部分:Result Table,Query 产生的结果表;
- 第四部分:Output,Result Table 的输出,依据设置的输出模式OutputMode输出结果;
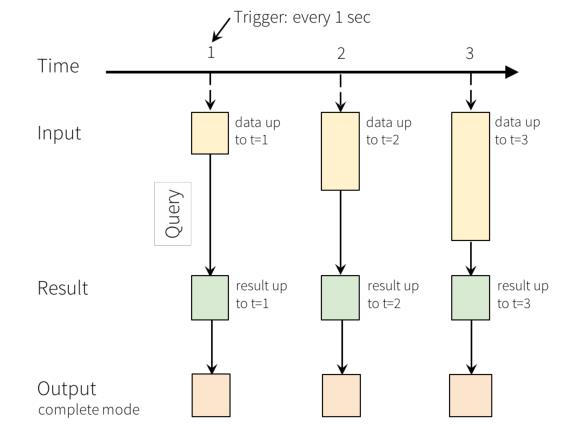
Structured Streaming最核心的思想就是将实时到达的数据看作是一个不断追加的unboundtable无界表,到达流的每个数据项就像是表中的一个新行被附加到无边界的表中,用静态结构化数据的批处理查询方式进行流计算。
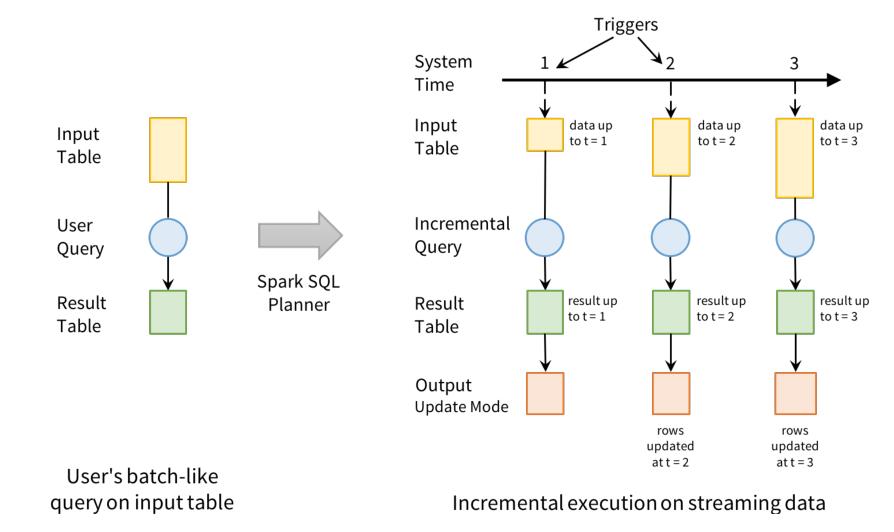
以词频统计WordCount案例,Structured Streaming实时处理数据的示意图如下,各行含义: - 第一行、表示从TCP Socket不断接收数据,使用【nc -lk 9999】;
- 第二行、表示时间轴,每隔1秒进行一次数据处理;
- 第三行、可以看成是“input unbound table",当有新数据到达时追加到表中;
- 第四行、最终的wordCounts是结果表,新数据到达后触发查询Query,输出的结果;
- 第五行、当有新的数据到达时,Spark会执行“增量"查询,并更新结果集;该示例设置为CompleteMode,因此每次都将所有数据输出到控制台;
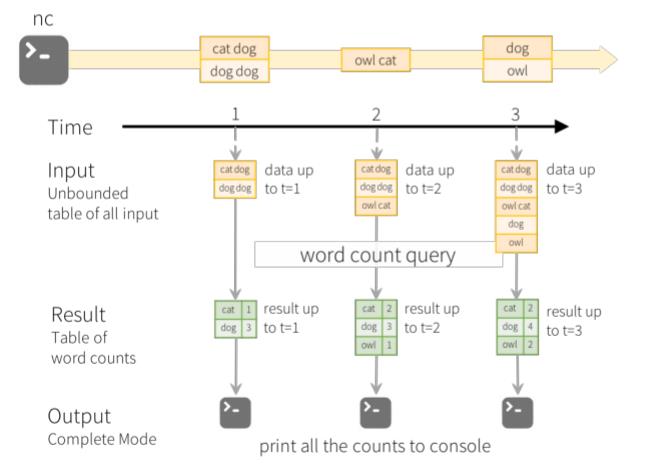
上图中数据实时处理说明: - 第一、在第1秒时,此时到达的数据为"cat dog"和"dog dog",因此可以得到第1秒时的结果集cat=1dog=3,并输出到控制台;
- 第二、当第2秒时,到达的数据为"owl cat",此时"unbound table"增加了一行数据"owl cat",执
行word count查询并更新结果集,可得第2秒时的结果集为cat=2 dog=3 owl=1,并输出到控制台; - 第三、当第3秒时,到达的数据为"dog"和"owl",此时"unbound table"增加两行数据"dog"和
“owl”,执行word count查询并更新结果集,可得第3秒时的结果集为cat=2 dog=4 owl=2;使用Structured Streaming处理实时数据时,会负责将新到达的数据与历史数据进行整合,并完成正确的计算操作,同时更新Result Table。
3 入门案例:WordCount
入门案例与SparkStreaming的入门案例基本一致:实时从TCP Socket读取数据(采用nc)实时进行词频统计WordCount,并将结果输出到控制台Console。
文档:http://spark.apache.org/docs/2.4.5/structured-streaming-programming-guide.html#quick-example
3.1 功能演示
运行词频统计WordCount程序,从TCP Socket消费数据,官方演示说明截图如下: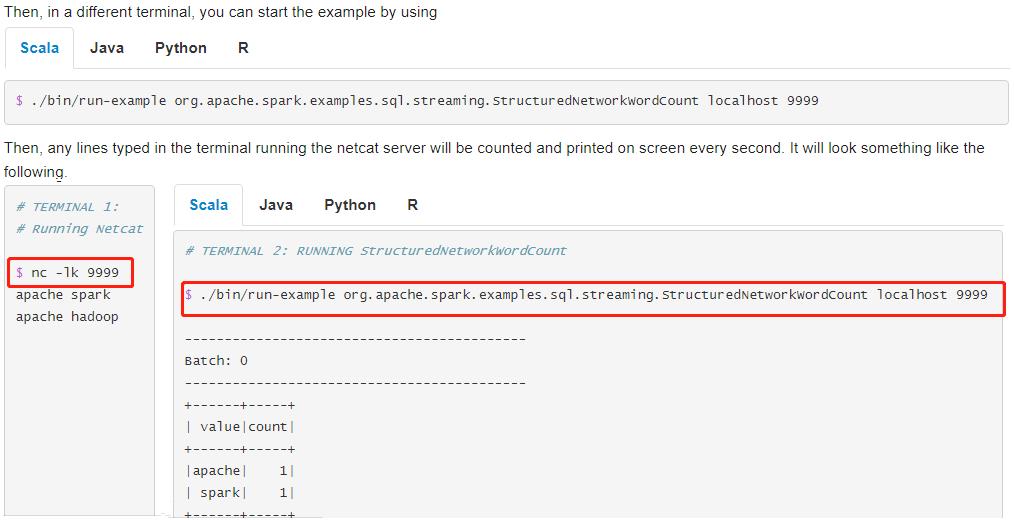
演示运行案例步骤:
- 第一步、打开终端Terminal,运行NetCat,命令为:nc -lk 9999
- 第二步、打开另一个终端Terminal,执行如下命令
# 官方入门案例运行:词频统计
/export/server/spark/bin/run-example \\
--master local[2] \\
--conf spark.sql.shuffle.partitions=2 \\
org.apache.spark.examples.sql.streaming.StructuredNetworkWordCount \\
node1.itcast.cn 9999
# 测试数据
spark hadoop spark hadoop spark hive
spark spark spark
spark hadoop hive
发送数据以后,最终统计输出结果如下:
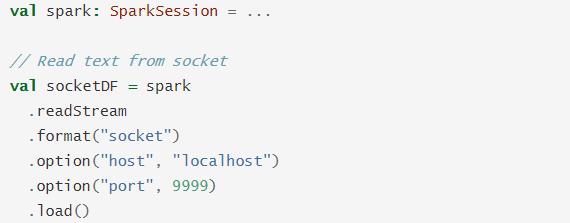
3.2 Socket 数据源
从Socket中读取UTF8文本数据。一般用于测试,使用nc -lk 端口号向Socket监听的端口发送数据,用于测试使用,有两个参数:
- 参数一:host,主机名称,必须指定参数
- 参数二:port,端口号,必须指定参数
范例如下所示:
3.3 Console 接收器
将结果数据打印到控制台或者标准输出,通常用于测试或Bedug使用,三种输出模式OutputMode(Append、Update、Complete)都支持,两个参数可设置:
- 参数一:numRows,打印多少条数据,默认为20条;
- 参数二:truncate,如果某列值字符串太长是否截取,默认为true,截取字符串;
范例如下所示: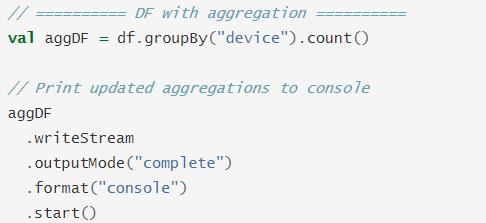
3.4 编程实现
可以认为Structured Streaming = SparkStreaming + SparkSQL,对流式数据处理使用SparkSQL数据结构,应用入口为SparkSession,对比SparkSQL与SparkStreaming编程:
- Spark Streaming:将流式数据按照时间间隔(BatchInterval)划分为很多Batch,每批次数据封装在RDD中,底层RDD数据,构建StreamingContext实时消费数据;
- Structured Streaming属于SparkSQL模块中一部分,对流式数据处理,构建SparkSession对象,
指定读取Stream数据和保存Streamn数据,具体语法格式:
- 加载数据Load:读取静态数据【spark.read】、读取流式数据【spark.readStream】
- 保存数据Save:保存静态数据【ds/df.write】、保存流式数据【ds/df.writeStrem】词频统计案例: 从TCP Socket实消费流式数据,进行词频统计,将结果打印在控制台Console 。
第一点、程序入口SparkSession,加载流式数据:spark.readStream
第二点、数据封装Dataset/DataFrame中,分析数据时,建议使用DSL编程,调用API,很少使用SQL方式
第三点、启动流式应用,设置Output结果相关信息、start方法启动应用
完整案例代码如下:
import org.apache.spark.sql.streaming.{OutputMode,StreamingQuery}
import org.apache.spark.sql.{DataFrame,SparkSession}
/**
* 使用Structured Streaming从TCP Socket实时读取数据,进行词频统计,将结果打印到控制台。
*/
object StructuredWordCount{
def main(args:Array[String]):Unit={
// TODO: 构建SparkSession实例对象
val spark:SparkSession=SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[2]")
.config("spark.sql.shuffle.partitions","2") // 设置Shuffle分区数目
.getOrCreate()
// 导入隐式转换和函数库
import spark.implicits._
import org.apache.spark.sql.functions._
// TODO: 1. 从TCP Socket 读取数据
val inputStreamDF:DataFrame=spark.readStream
.format("socket")
.option("host","node1.itcast.cn").option("port",9999)
.load()
/*
root
|-- value: string (nullable = true)
*/
//inputStreamDF.printSchema()
// TODO: 2. 业务分析:词频统计WordCount
val resultStreamDF:DataFrame=inputStreamDF
.as[String] // 将DataFrame转换为Dataset进行操作
// 过滤数据
.filter(line=>null!=line&&line.trim.length>0)
// 分割单词
.flatMap(line=>line.trim.split("\\\\s+"))
.groupBy($"value").count() // 按照单词分组,聚合
/*
root
|-- value: string (nullable = true)
|-- count: long (nullable = false)
*/
//resultStreamDF.printSchema()
// TODO: 3. 设置Streaming应用输出及启动
val query:StreamingQuery=resultStreamDF.writeStream
// TODO: 设置输出模式:Complete表示将ResultTable中所有结果数据输出
// .outputMode(OutputMode.Complete())
// TODO: 设置输出模式:Update表示将ResultTable中有更新结果数据输出
.outputMode(OutputMode.Update())
.format("console")
.option("numRows","10").option("truncate","false")
// 流式应用,需要启动start
.start()
// 流式查询等待流式应用终止
query.awaitTermination()
// 等待所有任务运行完成才停止运行
query.stop()
}
}
其中可以设置不同输出模式(OutputMode),当设置为Complete时,结果表ResultTable中
所有数据都输出;当设置为Update时,仅仅输出结果表ResultTable中更新的数据。
4 DataStreamReader 接口
从Spark 2.0至Spark 2.4版本,目前支持数据源有4种,其中Kafka 数据源使用作为广泛,其他数据源主要用于开发测试程序。
文档: http://spark.apache.org/docs/2.4.5/structured-streaming-programming-guide.html#input-sources

在Structured Streaming中使用SparkSession#readStream读取流式数据,返回DataStreamReader对象,指定读取数据源相关信息,声明如下:
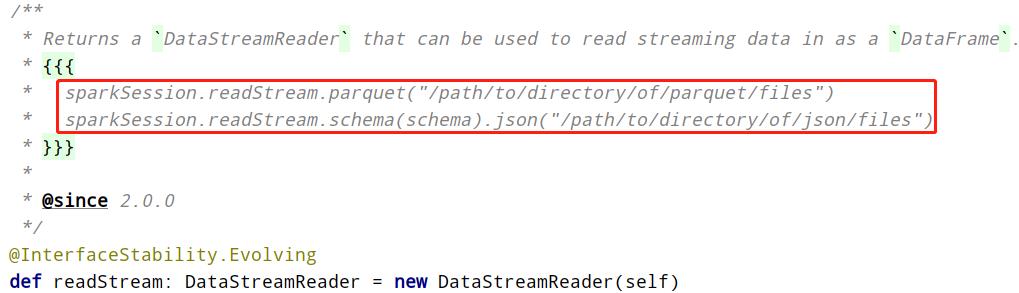
查看DataStreamReader中方法可以发现与DataFrameReader中基本一致,编码上更加方便加载流式数据。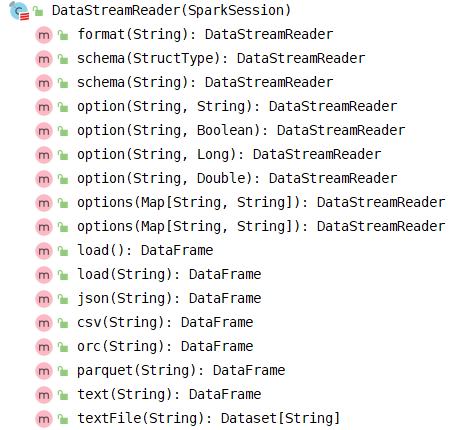
5 文件数据源
将目录中写入的文件作为数据流读取,支持的文件格式为:text、csv、json、orc、parquet,可以设置相关可选参数:

从文件数据源加载数据伪代码如下:
val streamDF = spark
.readStream
// Schema must be specified when creating a streaming source DataFrame.
.schema(schema)
// 每个trigger最大文件数量
.option("maxFilesPerTrigger",100)
// 是否首先计算最新的文件,默认为false
.option("latestFirst",value = true)
// 是否只检查名字,如果名字相同,则不视为更新,默认为false
.option("fileNameOnly",value = true)
.csv("*.csv")
演示范例:监听某一个目录,读取csv格式数据,统计年龄小于25岁的人群的爱好排行榜。
- 测试数据
jack;23;running
charles;32;basketball
tom;28;football
lili;24;running
bob;20;swimming
zhangsan;32;running
lisi;28;running
wangwu;24;running
zhaoliu;26;swimming
honghong;28;running`
- 业务实现代码,监控Windows系统目录【D:/datas】
import org.apache.spark.sql.streaming.{OutputMode,StreamingQuery}
import org.apache.spark.sql.types.{IntegerType,StringType,StructType}
import org.apache.spark.sql.{DataFrame,Dataset,Row,SparkSession}
/**
* 使用Structured Streaming从目录中读取文件数据:统计年龄小于25岁的人群的爱好排行榜
*/
object StructuredFileSource{
def main(args:Array[String]):Unit={
// 构建SparkSession实例对象
val spark:SparkSession=SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[2]")
// 设置Shuffle分区数目
.config("spark.sql.shuffle.partitions","2")
.getOrCreate()
// 导入隐式转换和函数库
import spark.implicits._
import org.apache.spark.sql.functions._
// TODO: 从文件系统,监控目录,读取CSV格式数据
// 数据样本 -> jack,23,running
val csvSchema:StructType=new StructType()
.add("name",StringType,nullable=true)
.add("age",IntegerType,nullable=true)
.add("hobby",StringType,nullable=true)
val inputStreamDF:DataFrame=spark.readStream
.option("sep",";")
.option("header","false")
// 指定schema信息
.schema(csvSchema)
.csv("file:///D:/datas/")
// 依据业务需求,分析数据:统计年龄小于25岁的人群的爱好排行榜
val resultStreamDF:Dataset[Row]=inputStreamDF
// 年龄小于25岁
.filter($"age"< 25)
// 按照爱好分组统计
.groupBy($"hobby").count()
// 按照词频降序排序
.orderBy($"count".desc)
// 设置Streaming应用输出及启动
val query:StreamingQuery=resultStreamDF.writeStream
// 对流式应用输出来说,设置输出模式
.outputMode(OutputMode.Complete())
.format("console")
.option("numRows","10")
.option("truncate","false")
// 流式应用,需要启动start
.start()
// 查询器等待流式应用终止
query.awaitTermination()
query.stop() // 等待所有任务运行完成才停止运行
}
}
6 Rate source
以每秒指定的行数生成数据,每个输出行包含2个字段:timestamp和value。其中timestamp是一个Timestamp含有信息分配的时间类型,并且value是Long(包含消息的计数从0开始作为第一行)类型。此源用于测试和基准测试,可选参数如下:

演示范例代码如下:
import org.apache.spark.sql.streaming.{OutputMode,StreamingQuery,Trigger}
import org.apache.spark.sql.{DataFrame,SparkSession}
/**
* 数据源:Rate Source,以每秒指定的行数生成数据,每个输出行包含一个timestamp和value。
*/
object StructuredRateSource{
def main(args:Array[String]):Unit={
// 构建SparkSession实例对象
val spark:SparkSession=SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[2]")
// 设置Shuffle分区数目
.config("spark.sql.shuffle.partitions","2")
.getOrCreate()
// 导入隐式转换和函数库
import spark.implicits._
import org.apache.spark.sql.functions._
// TODO:从Rate数据源实时消费数据
val rateStreamDF:DataFrame=spark.readStream
.format("rate")
.option("rowsPerSecond","10") // 每秒生成数据数目
.option("rampUpTime","0s") // 每条数据生成间隔时间
.option("numPartitions","2") // 分区数目
.load()
/*
root
|-- timestamp: timestamp (nullable = true)
|-- value: long (nullable = true)
*/
//rateStreamDF.printSchema()
// 3. 设置Streaming应用输出及启动
val query:StreamingQuery=rateStreamDF.writeStream
// 设置输出模式:Append表示新数据以追加方式输出
.outputMode(OutputMode.Append())
.format("console")
.option("numRows","10")
.option("truncate","false")
// 流式应用,需要启动start
.start()
// 流式查询等待流式应用终止
query.awaitTermination()
// 等待所有任务运行完成才停止运行
query.stop()
}
}
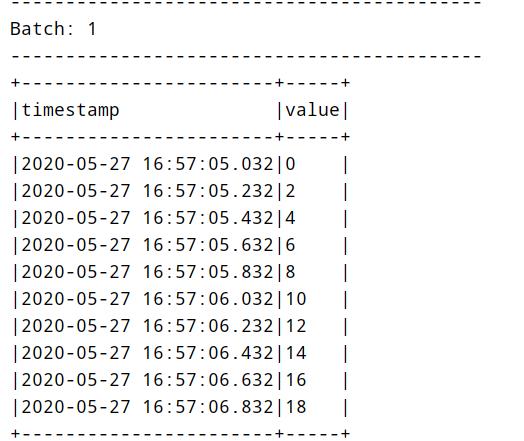
运行应用程序,随机生成的数据,截图如下:
以上是关于大数据Spark Structured Streaming的主要内容,如果未能解决你的问题,请参考以下文章
大数据Spark Structured Streaming集成 Kafka
Structured Streaming教程 —— 基本概念与使用
Structured Streaming系列-4集成 Kafka