第3版emWin教程第31章 emWin6.x的全字库的实现(GB2312编码,SPI Flash方案)
Posted Simon223
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第3版emWin教程第31章 emWin6.x的全字库的实现(GB2312编码,SPI Flash方案)相关的知识,希望对你有一定的参考价值。
教程不断更新中:http://www.armbbs.cn/forum.php?mod=viewthread&tid=98429
第31章 emWin6.x的全字库的实现(GB2312编码,SPI Flash方案)
本章节为大家讲解GB2312编码全字库的实现,对于习惯了GB2312编码的用户来说,使用本章节的方法非常合适。emWin本身是不支持GB2312编码字符显示的,本章节是新创建一种字体类型来实现GB2312编码字符的显示,所采用的方式是早期UCGUI3.98时期遗留下来,但对那种方法进行了修改,以适合高版本emWin6.xx的使用。
目录
31.5.3 文件GUI_Font12.c,GUI_Font16.c等
31.7 内部Flash和SPI Flash程序调试下载配置(重要必看)
31.1 初学者重要提示
- 对于不习惯前面章节讲解的XBF格式和SIF格式的Unicode编码全字库的用户来说,使用GB2312编码是很好的选择,很适合初学者,汉字操作方式与大家使用裸机代码(没有使用GUI)时是一样的。
- 下载本章节相关例子前,务必先添加好SPI Flash的下载算法。本章使用的方法支持内部Flash和外部SPI Flash可以同时下载。如此以来,大家可以方便的将字库,图库和主题存到外部SPI Flash,简单易用,大大方便大家项目实战。
- GB2312编码的全字库文件可以存到任何外部存储介质中。本章节配套例子是将其存储到SPI Flash里面了。
- 使用GB2312编码也是有缺点的,相比前面章节使用FontCvt生成的XBF格式和SIF格式全字库,GB2312编码全字库不支持抗锯齿效果,且仅支持等宽字体(仅支持等宽是因为当前新字体的创建方法不支持非等宽字体)。
31.2 下载算法存放位置(操作前必看)
(注:例子下载地址 http://www.armbbs.cn/forum.php?mod=viewthread&tid=86980 )
编译例子:V7-065_SPI Flash的MDK下载算法制作,生成的算法文件位于此路径下:
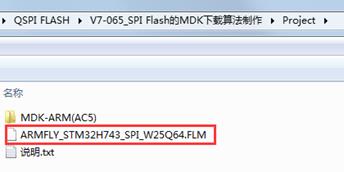
生成算法文件后,需要大家将其存到到MDK安装目录,有两个位置可以存放,任选其一,推荐第2种:
- 第1种:存放到MDK的STM32H7软包安装目录里面:\\Keil\\STM32H7xx_DFP\\2.6.0\\CMSIS\\Flash(软包版本不同,数值2.6.0不同)。
- 第2种:MDK的安装目录 \\ARM\\Flash里面。
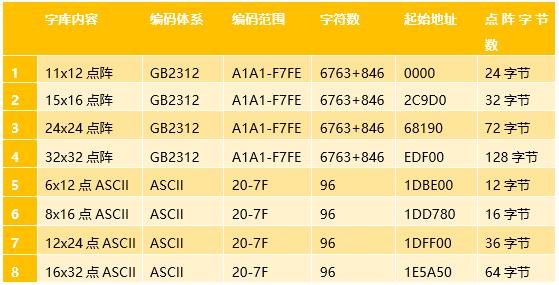
31.3 GB2312编码全字库说明
本章节配套例子使用的字库是从字库芯片提取出来的,下面是点阵字库相关信息,仅列出了要用到的点阵字符:
了解了点阵字体的相关信息后,剩下就是寻址算法了。
汉字点阵在汉字库中的地址计算:
汉字库种类繁多,但都是按照区位的顺序排列的。前一个字节为该汉字的区号,后一个字节为该字的位号,位号是该字在该区中的位置。GB2312编码区范围是A1A1到F7FE,一共F7-A1+1 = 87个区,每区有FE-A1+1=94个字符,因此GB2312可以表示87*94=8178个字符。
计算公式为:(94 * (区号 - 1) + 位号 - 1) * 一个汉字字模占用字节数
我们在计算机中常用的汉字编码为汉字内码,不是区位码,需要进行转换。因此最终的计算公式为:
ADDRESS = [(内码1 - 0xa1) * 94 + (内码2 - 0xa1)] *一个汉字字模占用字节数(内码1对应区号,内码2对应位号)
ASCII区,GB2312编码的全角字符区和汉字区的所有字符可以看下这个帖子:
http://bbs.armfly.com/read.php?tid=201 ,初学者务必看下,非常有必要。
下面对这8种点阵依次做下说明:
- 汉字点阵GB2312编码字库地址计算
GBCode表示汉字内码。
MSB 表示汉字内码GBCode的高8bits,
LSB 表示汉字内码GBCode的低8bits。
Address 表示汉字或ASCII字符点阵在芯片中的字节地址。
BaseAdd:说明点阵数据在字库中的起始地址。
11*12点阵计算方法:
BaseAdd=0x0;
if(MSB >=0xA1 && MSB <= 0Xa9 && LSB >=0xA1)
Address =( (MSB – 0xA1) * 94 + (LSB – 0xA1))*24+ BaseAdd;
else if(MSB >=0xB0 && MSB <= 0xF7 && LSB >=0xA1)
Address = ((MSB – 0xB0) * 94 + (LSB – 0xA1)+ 846)*24+ BaseAdd;
15*16点阵计算方法:
BaseAdd=0x2C9D0;
if(MSB >=0xA1 && MSB <= 0Xa9 && LSB >=0xA1)
Address =( (MSB - 0xA1) * 94 + (LSB - 0xA1))*32+ BaseAdd;
else if(MSB >=0xB0 && MSB <= 0xF7 && LSB >=0xA1)
Address = ((MSB - 0xB0) * 94 + (LSB - 0xA1)+ 846)*32+ BaseAdd;
24*24点阵计算方法:
BaseAdd=0x68190;
if(MSB >=0xA1 && MSB <= 0Xa9 && LSB >=0xA1)
Address =( (MSB - 0xA1) * 94 + (LSB - 0xA1))*72+ BaseAdd;
else if(MSB >=0xB0 && MSB <= 0xF7 && LSB >=0xA1)
Address = ((MSB - 0xB0) * 94 + (LSB - 0xA1)+ 846)*72+ BaseAdd;
32*32点阵计算方法:
BaseAdd=0XEDF00;
if(MSB >=0xA1 && MSB <= 0Xa9 && LSB >=0xA1)
Address =( (MSB - 0xA1) * 94 + (LSB - 0xA1))*128+ BaseAdd;
else if(MSB >=0xB0 && MSB <= 0xF7 && LSB >=0xA1)
Address = ((MSB - 0xB0) * 94 + (LSB - 0xA1)+ 846)*128+ BaseAdd;
这四种点阵字体除了每个点阵字符的字节数和起始地址不一样,其余都是一样的。其中第一个if条件语句是判断区号在0xA1到0xA8里面的全角字符区,共846个字符。第二个else if条件语句是判断区号在0xB0到0xF7里面的汉字区,共6763个汉字。
- ASCII字符地址计算
ASCIICode:表示 ASCII 码( 8bits)
BaseAdd:说明该套字库在芯片中的起始地址。
Address: ASCII 字符点阵在芯片中的字节地址。
6x12点阵ASCII计算方法:
BaseAdd=0x1DBE00
if (ASCIICode >= 0x20) and (ASCIICode <= 0x7E)
Address = (ASCIICode –0x20 ) * 12+BaseAdd
8x16点阵ASCII计算方法:
BaseAdd=0x1DD780
if (ASCIICode >= 0x20) and (ASCIICode <= 0x7E)
Address = (ASCIICode –0x20 ) * 16+BaseAdd
12x24点阵ASCII计算方法:
BaseAdd=0x1DFF00
if (ASCIICode >= 0x20) and (ASCIICode <= 0x7E)
Address = (ASCIICode –0x20 ) * 48+BaseAdd
16x32点阵ASCII计算方法:
BaseAdd=0x1E5A50
if (ASCIICode >= 0x20) and (ASCIICode <= 0x7E)
Address = (ASCIICode –0x20 ) * 64+BaseAdd
这四种点阵字体除了每个点阵字符的字节数和起始地址不一样,其余都是一样的。每个点阵都是只用到了0x20到0x7E,共96个字符。
---------------------------------------------------------------
讲解完编码地址的计算后,再说一个比较重要的知识点,初学者容易在这个问题上面犯迷糊。汉字内码在文件里面存储的时候就是按照高低字节依次存储的,比如汉字“我”的GB2312编码是0xced2,汉字“们”的编码是0xc3c7,现在我们在电脑端新建一个记事本文件,然后将“我们”这两个字写到电脑端的记事本里面,然后保存,文本编码类型选择ANSI即可。
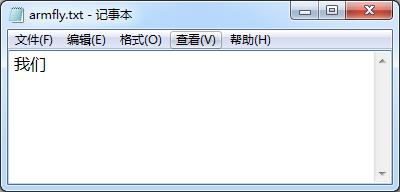
此时将这个文本文件用winhex打开,可以看到,编码数值如下:
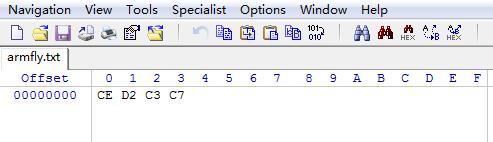
跟汉字的编码值对比后发现汉字的编码值存储就是高低字节依次存储的。那么问题来了,一般情况下,使用MCU微控制器的时候都是用的小端模式,即低地址存储低位数据,高地址存储高位数据。现在我们采用如下的程序做简单的测试:
char *ptr = {"我们"};
U16 c1, c2;
c1 = *(U16 *)ptr;
c2 = *(U16 *)(ptr + 2);
printf("c1 = %x, c2 = %x\\r\\n", c1, c2);
串口打印的输出结果就是 c1 = 0xd2ce , c2 = 0xc7c3。正好与汉字内码的高低字节反过来了,初学者在学习的时候务必要注意这个问题。
31.4 GB2312全字库的移植方法
这里用到的几个移植文件是早期UCGUI3.XX版本时代遗留下来的,但都进行了修改,更加适合emWin6.xx版本使用(由于早期UCGUI3.XX版本是有源码的,这种方式是在源码的基础上新创建的一种字体方式,适合国内用的GB编码)。
GUI_Font12.c,GUI_Font16.c,GUI_Font24.c和GUI_Font32.c都是相同的代码结构,仅仅是定义的点阵大小不同,用户要实现其它点阵大小的字体,只需根据这几个文件照葫芦画瓢即可。剩下的两个文件GUI_UC_EncondeNone.c和GUICharPEx.c是必须要包含的,用户需要根据字库的起始位置做修改(如何修改,看本章节的31.2小节,本章节配套的例子不用改,因为已经根据31.2小节的起始地址设置好了)。
接下来要做的移植工作比较简单,仅需两步即可完成:
1、第1步:将图31-1中的6个文件全部添加到工程中,IAR和MDK是一样的,下面以MDK为例进行说明。
上面的截图就是添加到MDK工程的效果。如果用户要移植这几个文件到自己的工程项目,直接从本章节配套例子的emWin文件夹下打开文件HanZi就看到这几个文件了,所以用户只需复制粘贴HanZi到自己的工程项目即可。
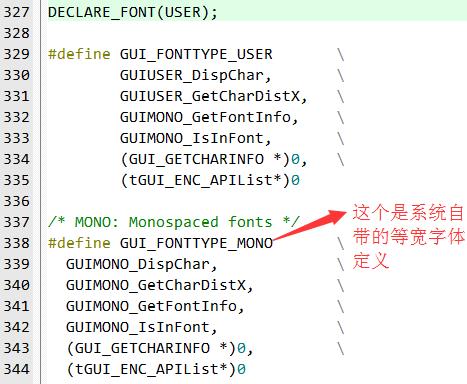
2、第2步:在GUI_Type.h文件添加一种新的字体类型定义
新添加的字体类型如下:
DECLARE_FONT(USER);
#define GUI_FONTTYPE_USER \\
GUIUSER_DispChar, \\
GUIUSER_GetCharDistX, \\
GUIMONO_GetFontInfo, \\
GUIMONO_IsInFont, \\
(GUI_GETCHARINFO *)0, \\
(tGUI_ENC_APIList*)0
此定义放在等宽字体定义的前面即可:
通过这两步就完成移植了,剩下就是如何使用了。不过第2步里面新添加的函数有必要简单的解释一下。
- 首先是函数DECLARE_FONT(USER),这个函数的原始定义如下:
#define DECLARE_FONT(Type) \\ void GUI##Type##_DispChar (U16P c); \\ int GUI##Type##_GetCharDistX(U16P c, int * pSizeX); \\ void GUI##Type##_GetFontInfo (const GUI_FONT * pFont, GUI_FONTINFO * pfi); \\ char GUI##Type##_IsInFont (const GUI_FONT * pFont, U16 c); \\ int GUI##Type##_GetCharInfo (U16P c, GUI_CHARINFO_EXT * pInfo)
##是预处理运算符,这种方式有效的对宏定义进行了扩展,DECLARE_FONT里面的参数是可以任意定义的,只要满足函数命名即可,比如用户调用了DECLARE_FONT(USER),就相当于一次声明了5个函数:
void GUIUSER_DispChar (U16P c); \\ int GUIUSER _GetCharDistX(U16P c, int * pSizeX); \\ void GUIUSER _GetFontInfo (const GUI_FONT * pFont, GUI_FONTINFO * pfi); \\ char GUIUSER _IsInFont (const GUI_FONT * pFont, U16 c); \\ int GUIUSER _GetCharInfo (U16P c, GUI_CHARINFO_EXT * pInfo)
也就是将Type前后的预处理运算符##去掉,并将Type用USER代替。在GUI_Type.h文件里面还有其它几种字体类型的定义,都是这个意思。
DECLARE_FONT(MONO); DECLARE_FONT(PROP); DECLARE_FONT(PROP_EXT); DECLARE_FONT(PROP_FRM); DECLARE_FONT(PROPAA); DECLARE_FONT(PROP_AA2); DECLARE_FONT(PROP_AA2_EXT); DECLARE_FONT(PROP_AA4); DECLARE_FONT(PROP_AA4_EXT); DECLARE_FONT(USER);
- 再说下宏定义#define GUI_FONTTYPE_USER
这种形式的宏定义也很少见,宏定义后面跟了好几个子函数。其实就是一种简单的替换,在程序代码遇到GUI_FONTTYPE_USER的地方,就用下面的代替
GUIUSER_DispChar, \\
GUIUSER_GetCharDistX, \\
GUIMONO_GetFontInfo, \\
GUIMONO_IsInFont, \\
(GUI_GETCHARINFO *)0, \\
(tGUI_ENC_APIList*)0
此宏定义是在文件GUI_Font12.c,GUI_Font16.c,GUI_Font24.c和GUI_Font32.c里面被调用。关于替代的这几个函数有必要再进一步的阐释下。
函数GUIUSER_DispChar和GUIUSER_GetCharDistX是要用户自己实现的,已经在GUICharPEx.c里面实现了。函数GUIUSER_GetFontInfo和GUIUSER_IsInFont没有实现,而是用emWin等宽字体的GUIMONO_GetFontInfo和GUIMONO_IsInFont实现的。剩下的两个函数(GUI_GETCHARINFO *)0和(tGUI_ENC_APIList*)0未做实现,使用emWin自带的方式来实现。讲解到这里,初学者会有疑问,为什么字体类型要定义这几种函数?其实这个是由emWin的字体类型变量决定的,定义如下:
struct GUI_FONT {
GUI_DISPCHAR * pfDispChar;
GUI_GETCHARDISTX * pfGetCharDistX;
GUI_GETFONTINFO * pfGetFontInfo;
GUI_ISINFONT * pfIsInFont;
GUI_GETCHARINFO * pfGetCharInfo;
const tGUI_ENC_APIList* pafEncode;
U8 YSize;
U8 YDist;
U8 XMag;
U8 YMag;
union {
const void * pFontData;
const GUI_FONT_MONO * pMono;
const GUI_FONT_PROP * pProp;
const GUI_FONT_PROP_EXT * pPropExt;
} p;
U8 Baseline;
U8 LHeight; /* Height of a small lower case character (a,x) */
U8 CHeight; /* Height of a small upper case character (A,X) */
};
结构体GUI_FONT前六个成员就是我们这里实现的,其余的几种字体类型全是如此:
DECLARE_FONT(MONO); DECLARE_FONT(PROP); DECLARE_FONT(PROP_EXT); DECLARE_FONT(PROP_FRM); DECLARE_FONT(PROPAA); DECLARE_FONT(PROP_AA2); DECLARE_FONT(PROP_AA2_EXT); DECLARE_FONT(PROP_AA4); DECLARE_FONT(PROP_AA4_EXT); /* MONO: Monospaced fonts */ #define GUI_FONTTYPE_MONO \\ GUIMONO_DispChar, \\ GUIMONO_GetCharDistX, \\ GUIMONO_GetFontInfo, \\ GUIMONO_IsInFont, \\ (GUI_GETCHARINFO *)0, \\ (tGUI_ENC_APIList*)0 /* PROP: Proportional fonts */ #define GUI_FONTTYPE_PROP \\ GUIPROP_DispChar, \\ GUIPROP_GetCharDistX, \\ GUIPROP_GetFontInfo, \\ GUIPROP_IsInFont, \\ (GUI_GETCHARINFO *)0, \\ (tGUI_ENC_APIList*)0 /* PROP_EXT: Extended proportional fonts */ #define GUI_FONTTYPE_PROP_EXT \\ GUIPROP_EXT_DispChar, \\ GUIPROP_EXT_GetCharDistX, \\ GUIPROP_EXT_GetFontInfo, \\ GUIPROP_EXT_IsInFont, \\ GUIPROP_EXT_GetCharInfo, \\ &GUI_ENC_APIList_EXT /* PROP_FRM: Extended proportional fonts, framed */ #define GUI_FONTTYPE_PROP_FRM \\ GUIPROP_FRM_DispChar, \\ GUIPROP_FRM_GetCharDistX, \\ GUIPROP_FRM_GetFontInfo, \\ GUIPROP_FRM_IsInFont, \\ (GUI_GETCHARINFO *)0, \\ (tGUI_ENC_APIList*)0 /* PROP: Proportional fonts SJIS */ #define GUI_FONTTYPE_PROP_SJIS \\ GUIPROP_DispChar, \\ GUIPROP_GetCharDistX, \\ GUIPROP_GetFontInfo, \\ GUIPROP_IsInFont, \\ (GUI_GETCHARINFO *)0, \\ &GUI_ENC_APIList_SJIS /* PROPAA: Proportional, antialiased fonts */ #define GUI_FONTTYPE_PROPAA \\ GUIPROPAA_DispChar, \\ GUIPROPAA_GetCharDistX, \\ GUIPROPAA_GetFontInfo, \\ GUIPROPAA_IsInFont, \\ (GUI_GETCHARINFO *)0, \\ (tGUI_ENC_APIList*)0 /* PROP_AA2: Proportional, antialiased fonts, 2bpp */ #define GUI_FONTTYPE_PROP_AA2 \\ GUIPROP_AA2_DispChar, \\ GUIPROP_AA2_GetCharDistX, \\ GUIPROP_AA2_GetFontInfo, \\ GUIPROP_AA2_IsInFont, \\ (GUI_GETCHARINFO *)0, \\ (tGUI_ENC_APIList*)0 /* PROP_AA2_EXT: Proportional, antialiased fonts, 2bpp, extended font information */ #define GUI_FONTTYPE_PROP_AA2_EXT \\ GUIPROP_AA2_EXT_DispChar, \\ GUIPROP_EXT_GetCharDistX, \\ GUIPROP_EXT_GetFontInfo, \\ GUIPROP_EXT_IsInFont, \\ GUIPROP_EXT_GetCharInfo, \\ &GUI_ENC_APIList_EXT /* PROP_AA2: Proportional, antialiased fonts, 2bpp, SJIS encoding */ #define GUI_FONTTYPE_PROP_AA2_SJIS \\ GUIPROP_AA2_DispChar, \\ GUIPROP_AA2_GetCharDistX, \\ GUIPROP_AA2_GetFontInfo, \\ GUIPROP_AA2_IsInFont, \\ (GUI_GETCHARINFO *)0, \\ &GUI_ENC_APIList_SJIS /* PROP_AA4: Proportional, antialiased fonts, 4bpp */ #define GUI_FONTTYPE_PROP_AA4 \\ GUIPROP_AA4_DispChar, \\ GUIPROP_AA4_GetCharDistX, \\ GUIPROP_AA4_GetFontInfo, \\ GUIPROP_AA4_IsInFont, \\ (GUI_GETCHARINFO *)0, \\ (tGUI_ENC_APIList*)0 /* PROP_AA4_EXT: Proportional, antialiased fonts, 4bpp, extended font information */ #define GUI_FONTTYPE_PROP_AA4_EXT \\ GUIPROP_AA4_EXT_DispChar, \\ GUIPROP_EXT_GetCharDistX, \\ GUIPROP_EXT_GetFontInfo, \\ GUIPROP_EXT_IsInFont, \\ GUIPROP_EXT_GetCharInfo, \\ &GUI_ENC_APIList_EXT /* PROP_AA4: Proportional, antialiased fonts, 4bpp, SJIS encoding */ #define GUI_FONTTYPE_PROP_AA4_SJIS \\ GUIPROP_AA4_DispChar, \\ GUIPROP_AA4_GetCharDistX, \\ GUIPROP_AA4_GetFontInfo, \\ GUIPROP_AA4_IsInFont, \\ (GUI_GETCHARINFO *)0, \\ &GUI_ENC_APIList_SJIS
关于移植部分就给大家讲解这么多,下面对这几个移植的文件简单的说说。
31.5 移植文件简易说明
31.5.1 文件GUICharPEx.c
此文件主要是实现了新定义字体里面的API函数GUIUSER_DispChar和GUIUSER_GetCharDistX,其实这两个函数是由UCGUI3.98源码里面的文件GUICharP.c修改而来。关于这两个函数暂不做讲解,用户使用的时候也不需要对这两个函数做修改,接下来重点看函数:
static void GUI_GetDataFromMemory(const GUI_FONT_PROP GUI_UNI_PTR *pProp, U16P c)
的实现,这个函数是需要用户去实现的,根据使用的外部存储器和汉字库地址实现点阵数据的读取。下面是根据31.2小节的说明,实现从SPI Flash里面读取点阵数据:
/* 点阵数据缓存, 必须大于等于单个字模需要的存储空间 */
#define BYTES_PER_FONT 512
static U8 GUI_FontDataBuf[BYTES_PER_FONT];
/*
*********************************************************************************************************
* 函 数 名: GUI_GetDataFromMemory
* 功能说明: 读取点阵数据
* 形 参: pProp GUI_FONT_PROP类型结构
* c 字符
* 返 回 值: 无
*********************************************************************************************************
*/
static void GUI_GetDataFromMemory(const GUI_FONT_PROP GUI_UNI_PTR *pProp, U16P c)
{
U16 BytesPerFont;
U32 oft = 0, BaseAdd;
U8 code1,code2;
char *font = (char *)pProp->paCharInfo->pData;
/* 每个字模的数据字节数 */
BytesPerFont = GUI_pContext->pAFont->YSize * pProp->paCharInfo->BytesPerLine;
if (BytesPerFont > BYTES_PER_FONT)
{
BytesPerFont = BYTES_PER_FONT;
}
/* 英文字符地址偏移计算 */
if (c < 0x80)
{
if(strncmp("A12", font, 3) == 0) /* 6*12 ASCII字符 */
{
BaseAdd = 0x1DBE00;
}
else if(strncmp("A16", font, 3) == 0) /* 8*16 ASCII字符 */
{
BaseAdd = 0x1DD780;
}
else if(strncmp("A24", font, 3) == 0) /* 12*24 ASCII字符 */
{
BaseAdd = 0x1DFF00;
}
else if(strncmp("A32", font, 3) == 0) /* 24*48 ASCII字符 */
{
BaseAdd = 0x1E5A50;
}
oft = (c-0x20) * BytesPerFont + BaseAdd;
}
/* 汉字和全角字符的偏移地址计算 */
else
{
if(strncmp("H12", font, 3) == 0) /* 12*12 字符 */
{
BaseAdd = 0x0;
}
else if(strncmp("H16", font, 3) == 0) /* 16*16 字符 */
{
BaseAdd = 0x2C9D0;
}
else if(strncmp("H24", font, 3) == 0) /* 24*24 字符 */
{
BaseAdd = 0x68190;
}
else if(strncmp("H32", font, 3) == 0) /* 32*32 字符 */
{
BaseAdd = 0XEDF00;
}
/* 根据汉字内码的计算公式锁定起始地址 */
code2 = c >> 8;
code1 = c & 0xFF;
if (code1 >=0xA1 && code1 <= 0xA9 && code2 >=0xA1)
{
oft = ((code1 - 0xA1) * 94 + (code2 - 0xA1)) * BytesPerFont + BaseAdd;
}
else if (code1 >=0xB0 && code1 <= 0xF7 && code2 >=0xA1)
{
oft = ((code1 - 0xB0) * 94 + (code2 - 0xA1) + 846) * BytesPerFont + BaseAdd;
}
}
/* 读取点阵数据 */
sf_ReadBuffer(GUI_FontDataBuf, oft, BytesPerFont);
}
汉字和ASCII点阵数据的起始地址计算公式就是前面31.2小节讲解的内容,只是都合并成一个公式来实现了。
31.5.2 文件GUI_UC_EncodeNone.c
这个文件就是来自UCGUI3.98源码,并对其进行了简单修改,以适合我们的GB2312编码,特别注意一点,在emWin的源码里面也是有一个此文件的,添加了这个文件,会把原有的文件覆盖掉。
#include "GUI_Private.h"
/*********************************************************************
*
* Static code
*
**********************************************************************
*/
/*********************************************************************
*
* _GetCharCode
*
* Purpose:
* Return the UNICODE character code of the current character.
*/
static U16 _GetCharCode(const char GUI_UNI_PTR * s) {
if((*s) > 0xA0) /* ASCII字符编码是00-7F,返回一个字节数据即可,GB2312编码是A1A1到FEFE,需要返回两个字节
数据,这里以第一个字节作为判断即可 */
{
return *(const U16 GUI_UNI_PTR *)s;
}
return *(const U8 GUI_UNI_PTR *)s;
}
/*********************************************************************
*
* _GetCharSize
*
* Purpose:
* Return the number of bytes of the current character.
*/
static int _GetCharSize(const char GUI_UNI_PTR * s) {
GUI_USE_PARA(s);
if((*s) > 0xA0) /* ASCII字符编码是00-7F,返回一个字节大小,GB2312编码是A1A1到FEFE,需要返回两个字节大小,
这里以第一个字节作为判断即可 */
{
return 2;
}
return 1;
}
/*********************************************************************
*
* _CalcSizeOfChar
*
* Purpose:
* Return the number of bytes needed for the given character.
*/
static int _CalcSizeOfChar(U16 Char) {
GUI_USE_PARA(Char);
if(Char > 0xA0A0) /* ASCII字符编码是00-7F,返回一个字节大小,GB2312编码是A1A1到FEFE,需要返回两个字节大
小,这里以A0A0作为判断*/
{
return 2;
}
return 1;
}
/*********************************************************************
*
* _Encode
*
* Purpose:
* Encode character into 1/2/3 bytes.
*/
static int _Encode(char *s, U16 Char) {
if(Char > 0xA0A0) /* ASCII字符编码是00-7F,返回一个字节大小,GB2312编码是A1A1到FEFE,需要返回两个字节大
小,这里以A0A0作为判断,并将编码中赋值给形参s */
{
*((U16 *)s) = (U16)(Char);
return 2;
}
*s = (U8)(Char);
return 1;
}
/*********************************************************************
*
* Static data
*
**********************************************************************
*/
/*********************************************************************
*
* _API_Table
*/
const GUI_UC_ENC_APILIST GUI__API_TableNone = {
_GetCharCode, /* return character code as U16 */
_GetCharSize, /* return size of character: 1 */
_CalcSizeOfChar, /* return size of character: 1 */
_Encode /* Encode character */
};
const GUI_UC_ENC_APILIST GUI_UC_None = {
_GetCharCode, /* return character code as U16 */
_GetCharSize, /* return size of character: 1 */
_CalcSizeOfChar, /* return size of character: 1 */
_Encode /* Encode character */
};
31.5.3 文件GUI_Font12.c,GUI_Font16.c等
这几个文件都是同一个架构,我们这里以GUI_Font16.c文件为例进行说明。
#include "GUI.h"
#include "GUI_Type.h"
GUI_CONST_STORAGE GUI_CHARINFO GUI_FontHZ16_CharInfo[2] = // ----------(1)
{
{ 8, 8, 1, (void *)"A16"},
{ 16, 16, 2, (void *)"H16"},
};
GUI_CONST_STORAGE GUI_FONT_PROP GUI_FontHZ16_PropHZ= { // ----------(2)
0xA1A1,
0xFEFE,
&GUI_FontHZ16_CharInfo[1],
(void *)0,
};
GUI_CONST_STORAGE GUI_FONT_PROP GUI_FontHZ16_PropASC= { // ----------(3)
0x0000,
0x007F,
&GUI_FontHZ16_CharInfo[0],
(void GUI_CONST_STORAGE *)&GUI_FontHZ16_PropHZ,
};
GUI_CONST_STORAGE GUI_FONT GUI_FontHZ16 = // ----------(4)
{
GUI_FONTTYPE_USER,
16,
16,
1,
1,
(void GUI_CONST_STORAGE *)&GUI_FontHZ16_PropASC,
};
GUI_CONST_STORAGE GUI_FONT GUI_FontHZ16x2 = // ----------(5)
{
GUI_FONTTYPE_USER,
16,
16,
2,
2,
(void GUI_CONST_STORAGE *)&GUI_FontHZ16_PropASC
};
1、第1个语句:GUI_CONST_STORAGE GUI_CHARINFO GUI_FontHZ16_CharInfo[2]
了解这个函数得了解GUI_CHARINFO的定义,定义如下:
typedef struct {
U8 XSize;
U8 XDist;
U8 BytesPerLine;
const unsigned char * pData;
} GUI_CHARINFO;
第1个成员U8 Xsize是点阵字符的X轴方向的长度。
第2个成员U8 XDist是实际显示时X轴方向的长度。
第3个成员 U8 BytesPerLine是每行点阵数据需要的字节数。
第4个成员const unsigned char *pData用来做一些字符标记。
认识这几个变量成员后,如下两个变量成员也就不难理解了:
{ 8, 8, 1, (void *)"A16"}
表示此点阵字符的X轴长度是8个像素点,实际显示也是8个像素点,显示一行需要1个字节就行,用字符A16作为识别标志,这一行的整体作用是用来识别16点阵ASCII。
{ 16, 16, 2, (void *)"H16"}
表示此点阵字符的X轴长度是16个像素点,实际显示也是16个像素点,显示一行需要2个字节就行,用字符H16作为识别标志,这一行的整体作用是用来识别16点阵汉字。
2、第2个语句:GUI_CONST_STORAGE GUI_FONT_PROP GUI_FontHZ16_PropHZ
了解这个函数得了解GUI_FONT_PROP的定义,定义如下:
typedef struct GUI_FONT_PROP {
U16P First; /* First character */
U16P Last; /* Last character */
const GUI_CHARINFO * paCharInfo; /* Address of first character */
const struct GUI_FONT_PROP * pNext; /* Pointer to next */
} GUI_FONT_PROP;
第1个成员U16P First是第一个字符的编码值。
第2个成员U16P First是最后一个字符的编码值。
第3个成员 const GUI_CHARINFO * paCharInfo记录了第一个字符的存储位置。
第4个成员const struct GUI_FONT_PROP * pNext用来指向下一个GUI_FONT_PROP定义的字符区间。
对结构体GUI_FONT_PROP的定义了解后,这里定义的如下四个参数:
0xA1A1,
0xFEFE,
&GUI_FontHZ16_CharInfo[1],
(void *)0,
表示此编码区的字符是从0XA1A1开始到0XFEFE。字符的位置由GUI_FontHZ16_CharInfo[1]记录,没有指向下一个编码范围。这里的编码就是GB2312的编码范围。
3、第3个语句:GUI_CONST_STORAGE GUI_FONT_PROP GUI_FontHZ16_PropASC
有了上面第二句的解释,第三句也比较好理解了。
这里表示此编码区的字符是从0x0000开始到0x007F。字符的位置由GUI_FontHZ16_CharInfo[0]记录,指向下一个编码范围就是第二句的GB2312编码区。这里的编码就是ASCII的编码范围。
4、第4个语句:GUI_CONST_STORAGE GUI_FONT GUI_FontHZ16
此句就是根据前面25.3小节末尾新创建字体类型所定义的一个16点阵字体。
GUI_CONST_STORAGE GUI_FONT GUI_FontHZ16 =
{
GUI_FONTTYPE_USER, /* 表示新定义的字体类型 */
16, /* 字体Y轴方向的点阵高度 */
16, /* 字体Y轴方向的实际显示点阵高度 */
1, /* 字体X轴方向放大到1倍,就是原始大小 */
1, /* 字体Y轴方向放大到1倍 ,就是原始大小 */
(void GUI_CONST_STORAGE*)&GUI_FontHZ16_PropASC,/* 此字体类型从GUI_FontHZ16_PropASC */
};
5、第5个语句:GUI_CONST_STORAGE GUI_FONT GUI_FontHZ16x2
跟第4句一样,区别的地方就是将字体放大了1倍。
GUI_CONST_STORAGE GUI_FONT GUI_FontHZ16 =
{
GUI_FONTTYPE_USER, /* 表示新定义的字体类型 */
16, /* 字体Y轴方向的点阵高度 */
16, /* 字体Y轴方向的实际显示点阵高度 */
2, /* 字体X轴方向放大到2倍 */
2, /* 字体Y轴方向放大到2倍 */
(void GUI_CONST_STORAGE*)&GUI_FontHZ16_PropASC,/* 此字体类型从GUI_FontHZ16_PropASC */
};
关于这个几个移植文件就跟大家讲解这么多。这个就是GUI_Font16.C的讲解,其它的GUI_Font12.c, GUI_Font24.c和GUI_Font32.c是一样的。
31.6 GB2312字库使用方法
移植好之后,使用就比较容易了,下面分两步进行说明
第1步:声明12点阵,16点阵,24点阵和32点阵的字体,放在了MainTask.h文件里面,方便调用,程序代码中只需包含这个头文件就可以了。
/* ********************************************************************************************************* * 字体声明 ********************************************************************************************************* */ extern GUI_CONST_STORAGE GUI_FONT GUI_FontHZ32; extern GUI_CONST_STORAGE GUI_FONT GUI_FontHZ24; extern GUI_CONST_STORAGE GUI_FONT GUI_FontHZ16; extern GUI_CONST_STORAGE GUI_FONT GUI_FontHZ12;
有几种点阵字库就通过extern声明几个,方便外部文件调用。
第2步:使用方法。
比如设置按钮的字体使用16点阵,调用如下设置函数即可。
BUTTON_SetFont(hWin, &GUI_FontHZ16); /* hWin是按钮的句柄 */
设置其它控件是一样的。另外注意,使用GB编码没有烦人的文件编码设置问题了,从这一点来说,比使用前面章节讲的XBF格式和SIF格式的Unicode编码方便很多了。
31.7 内部Flash和SPI Flash程序调试下载配置(重要必看)
将下面两个地方配置后,就可以像使用内部Flash一样使用SPI Flash进行调试了。并且这种方式可以方便的调试程序,内部Flash和外部Flash都做调试。
31.7.1 将字库文件转换为C数组格式文件
为了方便将bin文件添加到MDK工程中,我们这里使用小软件B2C.exe将其转换为C格式文件(此软件已经放到本章配套例子V7-538_emWin6.x实验_全字库实现,GB2312编码(SPI Flash RTOS)的Doc文件里面。
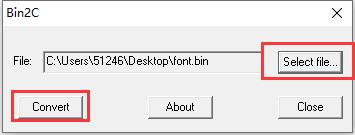
转换后生成的文件命名为gb2312.c :
const unsigned char _acgb2312[2097152UL + 1] = {
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x10, 0x00, 0x08, 0x00,
0x0C, 0x00, 0x04, 0x00, 0x00, 0x00, 0x00, 0x00 省略未写
}
31.7.2 设置字库文件到外部SPI Flash。
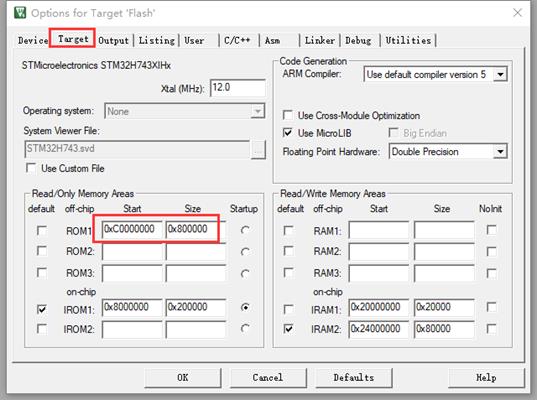
下面将流位图文件下载到SPI Flash,需要大家先在这里添加SPI Flash地址范围:
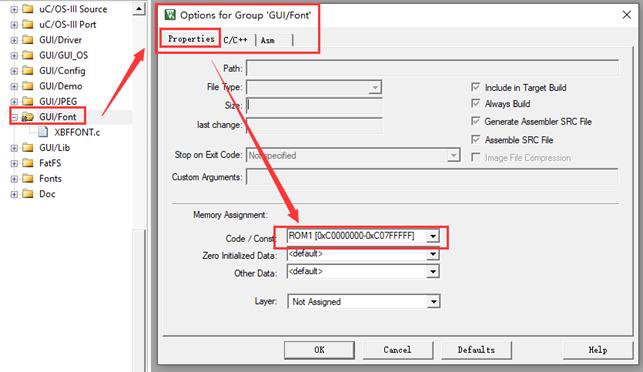
然后设置资源文件到外部SPI Flash:鼠标右击文件分组GUI/Font,选择Options。
31.7.3 下载配置
注意这里一定要够大,否则会提示算法文件无法加载:
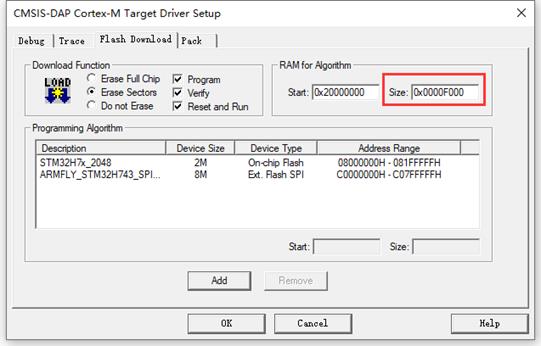
我们这里是将其加到DTCM中,即首地址为0x20000000,大家也可以存储到任意其它RAM地址,只要空间还够加载算法文件即可。推荐使用AXI SRAM(地址0x24000000),因为这块RAM空间足够大。
如果要下载程序到内部Flash和外部SPI Flash里面,需要做如下配置,两个下载算法都要添加进来:
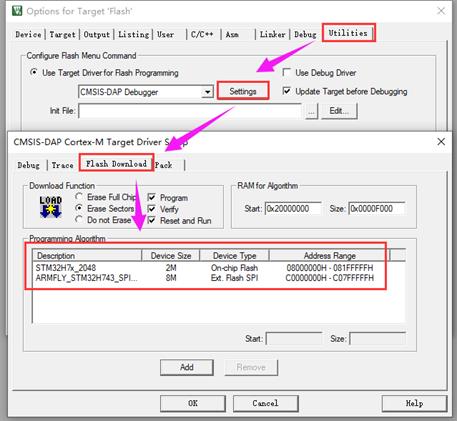
31.8 实验例程说明(RTOS)
配套例子:
V7-538_emWin6.x实验_全字库实现,GB2312编码(SPI Flash RTOS)
实验目的:
- 学习emWin的GB2312编码全字库的使用方法。
- emWin功能的实现在MainTask.c文件里面。
实验内容:
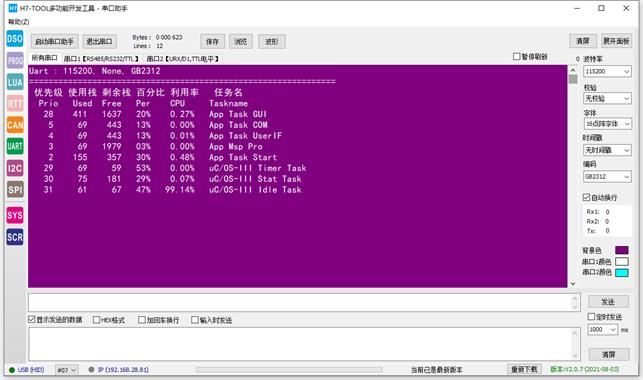
1、K1按键按下,串口或者RTT打印任务执行情况(串口波特率115200,数据位8,奇偶校验位无,停止位1)。
2、(1) 凡是用到printf函数的全部通过函数App_Printf实现。
(2) App_Printf函数做了信号量的互斥操作,解决资源共享问题。
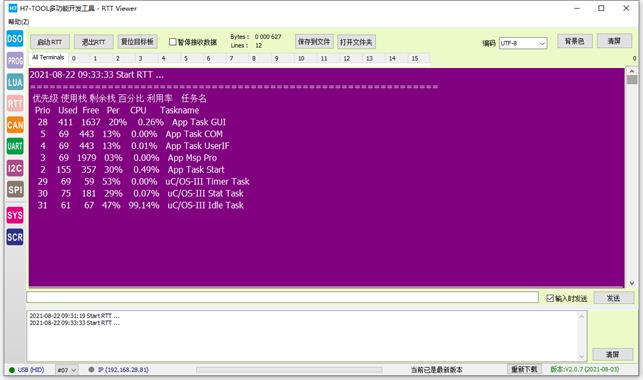
3、默认上电是通过串口打印信息,如果使用RTT打印信息:
MDK AC5,MDK AC6或IAR通过使能bsp.h文件中的宏定义为1即可
#define Enable_RTTViewer 1
4、各个任务实现的功能如下:
App Task Start 任务 :启动任务,这里用作BSP驱动包处理。
App Task MspPro任务 :消息处理,这里用作LED闪烁。
App Task UserIF 任务 :按键消息处理。
App Task COM 任务 :暂未使用。
App Task GUI 任务 :GUI任务。
μCOS-III任务调试信息(按K1按键,串口打印):
RTT 打印信息方式:
程序设计:
任务栈大小分配:
μCOS-III任务栈大小在app_cfg.h文件中配置:
#define APP_CFG_TASK_START_STK_SIZE 512u
#define APP_CFG_TASK_MsgPro_STK_SIZE 2048u
#define APP_CFG_TASK_COM_STK_SIZE 512u
#define APP_CFG_TASK_USER_IF_STK_SIZE 512u
#define APP_CFG_TASK_GUI_STK_SIZE 2048u
任务栈大小的单位是4字节,那么每个任务的栈大小如下:
App Task Start 任务 :2048字节。
App Task MspPro任务 :8192字节。
App Task UserIF 任务 :2048字节。
App Task COM 任务 :2048字节。
App Task GUI 任务 :8192字节。
系统栈大小分配:
μCOS-III的系统栈大小在os_cfg_app.h文件中配置:
#define OS_CFG_ISR_STK_SIZE 512u
系统栈大小的单位是4字节,那么这里就是配置系统栈大小为2KB
emWin动态内存配置:
GUIConf.c文件中的配置如下:
#define EX_SRAM 1/*1 used extern sram, 0 used internal sram */ #if EX_SRAM #define GUI_NUMBYTES (1024*1024*24) #else #define GUI_NUMBYTES (100*1024) #endif
通过宏定义来配置使用内部SRAM还是外部的SDRAM做为emWin的动态内存,当配置:
#define EX_SRAM 1 表示使用外部SDRAM作为emWin动态内存,大小24MB。
#define EX_SRAM 0 表示使用内部SRAM作为emWin动态内存,大小100KB。
默认情况下,本教程配套的所有emWin例子都是用外部SDRAM作为emWin动态内存。
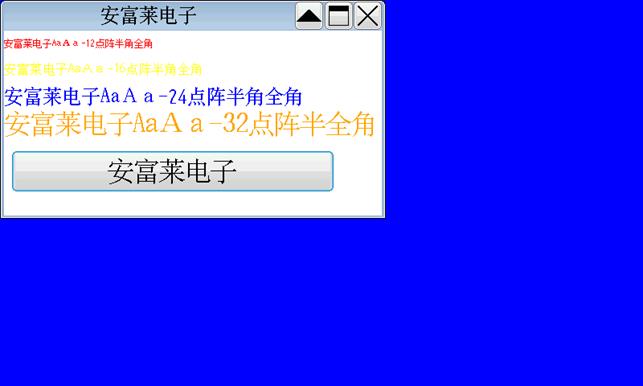
emWin界面显示效果:
800*480分辨率界面效果。
31.9 实验例程说明(裸机)
配套例子:
V7-537_emWin6.x实验_全字库实现,GB2312编码(SPI Flash裸机)
实验目的:
- 学习emWin的的SIF格式全字库的生成和使用方法,Unicode编码
- emWin功能的实现在MainTask.c文件里面。
emWin界面显示效果:
800*480分辨率界面效果。
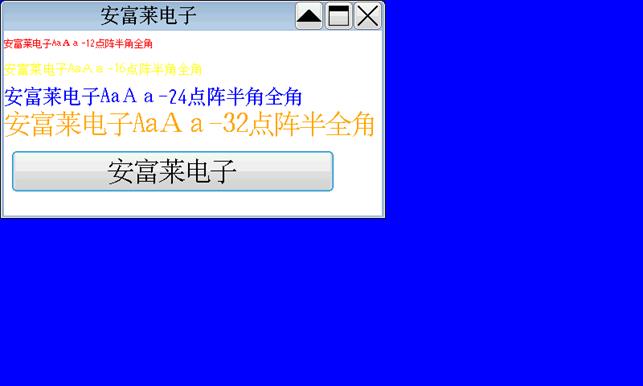
emWin动态内存配置:
GUIConf.c文件中的配置如下:
#define EX_SRAM 1/*1 used extern sram, 0 used internal sram */ #if EX_SRAM #define GUI_NUMBYTES (1024*1024*24) #else #define GUI_NUMBYTES (100*1024) #endif
通过宏定义来配置使用内部SRAM还是外部的SDRAM做为emWin的动态内存,当配置:
#define EX_SRAM 1 表示使用外部SDRAM作为emWin动态内存,大小24MB。
#define EX_SRAM 0 表示使用内部SRAM作为emWin动态内存,大小100KB。
默认情况下,本教程配套的所有emWin例子都是用外部SDRAM作为emWin动态内存。
31.10 总结
本章节为大家讲解的GB2312编码格式字体是可以用于项目实战的,对于习惯了GB2312编码的用户来说是个很好的选择。这种方式的字体可以存储到任何外部存储介质中。
以上是关于第3版emWin教程第31章 emWin6.x的全字库的实现(GB2312编码,SPI Flash方案)的主要内容,如果未能解决你的问题,请参考以下文章
第3版emWin教程第35章 emWin6.x的AppWizard中文实现方法