openmmlab 语义分割算法基础
Posted 临街的小孩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了openmmlab 语义分割算法基础相关的知识,希望对你有一定的参考价值。
本文是openmmlab AI实战营的第六次课程的笔记,以下是我比较关注的部分。
简要介绍语义分割
:如下图,左边原图,右边语义分割图,对每个像数进行分类

应用
语义分割在个各种场景下都非常重要,特别是在自动驾驶和医疗领域,

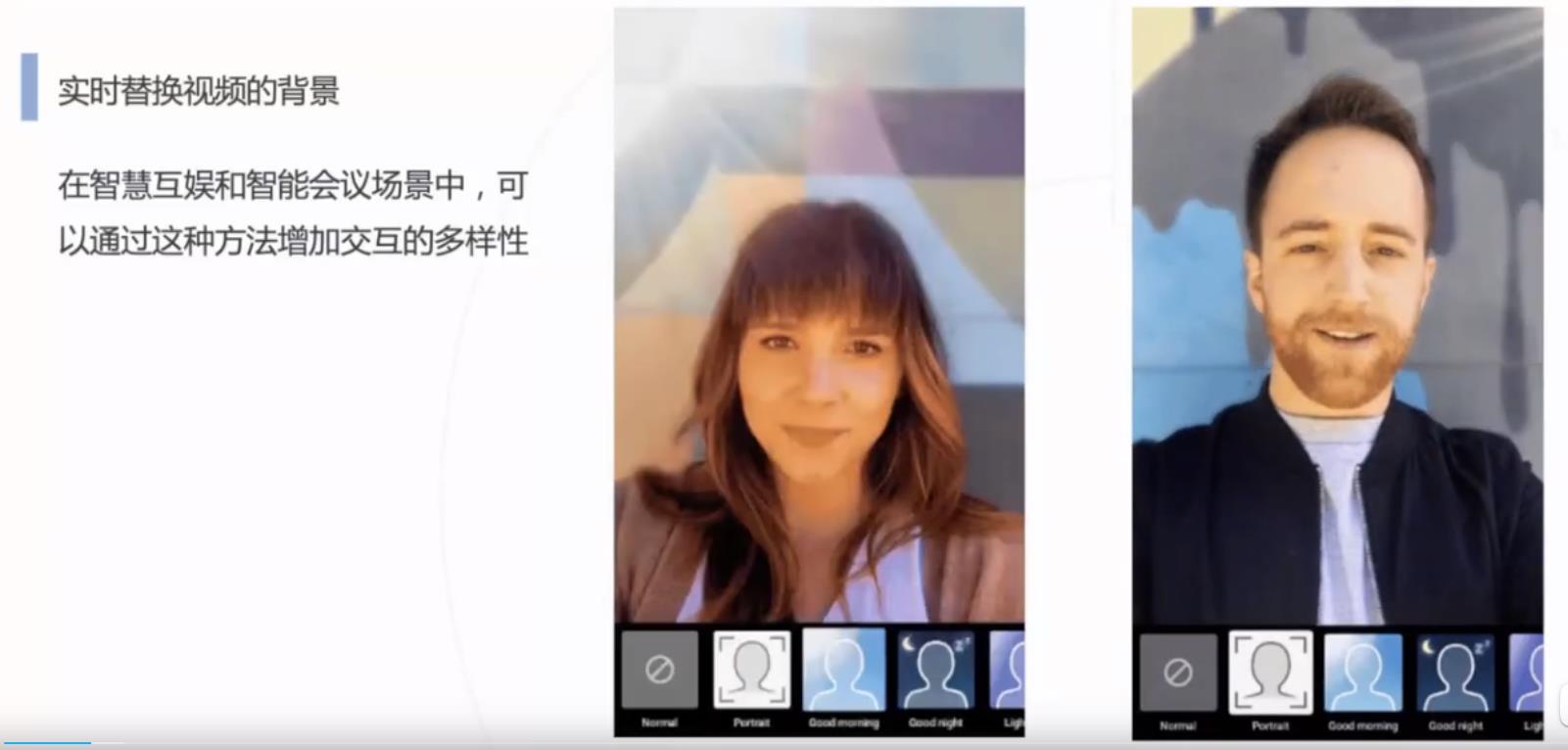
实时切换人物背景
智能摇杆

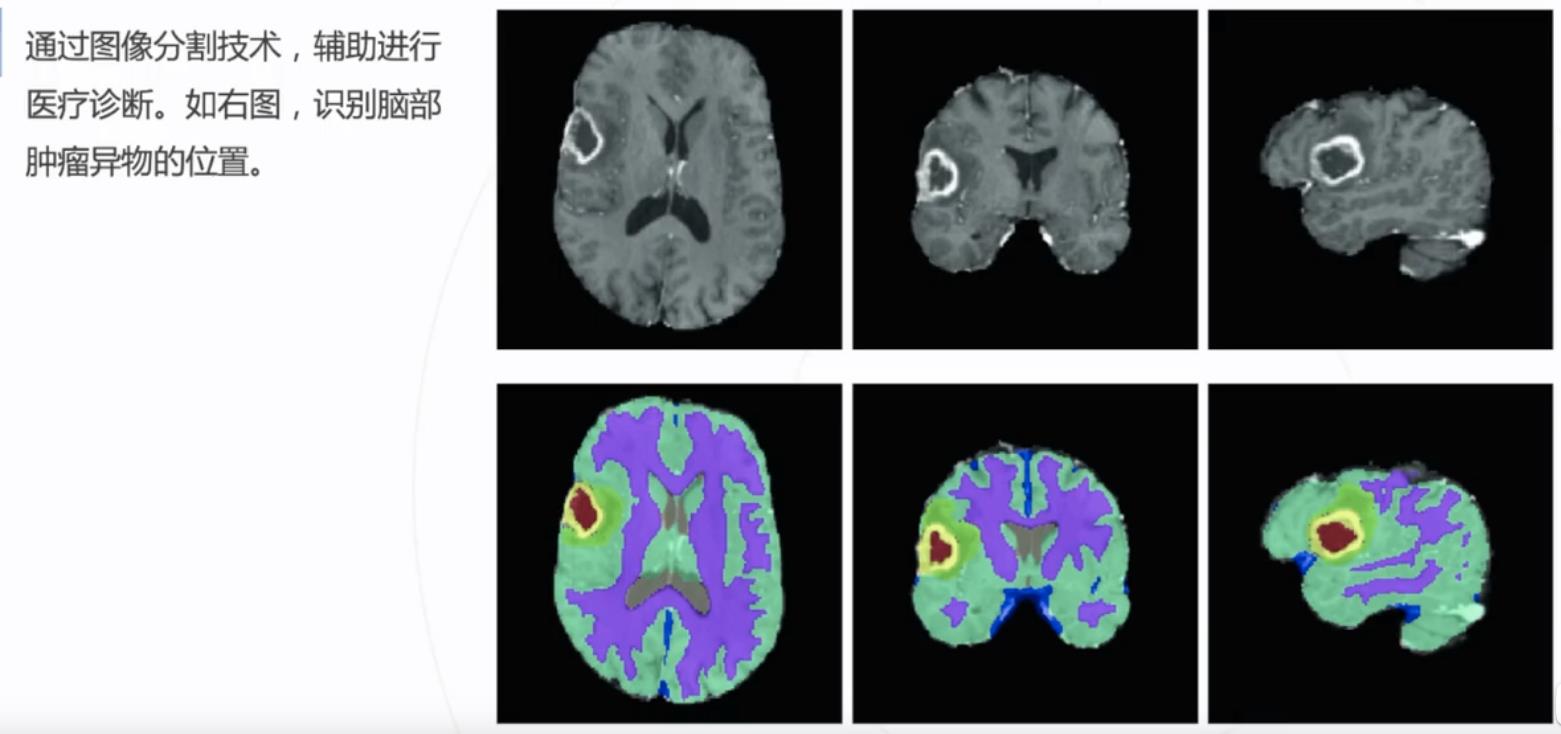
医疗影像分析
语义分割的基本思路
1.按颜色分割
最早期的语义分割就是按照颜色分割,一个块就是一个物体。按照不同的分层,我们可以获得层次的这种颜色分割图。只按照颜色分割效果很差,先验知识不完全准确。我们需要额外的手段确定物体类别,所以这是一种最朴素最初级的方法。
2.逐像素分类
后来有了卷积神经网络,开始按照像素分类。我们把某个像素周围的这个小窗口当成是一张图像,我们把这张图像输入到分类模型里面,给出一个类别作为这个滑窗的这个窗口中间像素的类别结果。只有我们就是实现了像素分类,这种方式称之为滑动窗口。我们用不同尺寸不同大小不同长宽,然后在图像上滑动窗口,每滑动一次就输入到卷积神经网络里面去进行一次类别预测,于是将每一个像素都划一遍就获得了每一个像素的分类结果。滑动窗口无法复用,效率低下。
3.改进:复用卷积计算
把全图输入到卷积神经网络里面,在全图得到的feature map上再运行滑窗,这样至少能让所有的滑窗都共享这个feature map,很好的降低了计算。
4.再改进:全连接层的卷积化
(1)全卷积网络 Fully Convolutional Network 2015
可以兼容任意尺寸的图像输入,最终可以得到某一个类别的特征图,代表这个类别的语义分割结果,我们就把分类网络转成了分割网络。
(2)预测图的升采样
问题: 图像分类模型使用降采样层(步长卷积或池化)获得高层次特征,导致全卷积网络输出尺寸小于原图,而分割要求同尺寸输出。
解决方法: 对预测的分割图升采样,恢复原图分辨率,升采样方案:
双线性插值
转置卷积:可学习的升采样层
全卷积网络的预测与训练
(3)基于多层级特征的上采样
问题:基于顶层特征预测,再升采样 32 倍得到的预测图较为粗糙。
分析:高层特征经过多次降采样,细节丢失严重。
解决思路:结合低层次和高层次特征图。
解决方案 FCN: 基于低层次和高层次特征图分别产生类别预测,升采样到原图大小,再平均得到最终结果。
解决方案 UNet: 逐级融合高低层次特征。
上下文信息
1.上下文的重要性
有歧义的区域:如何肯定图像里的物体到底是什么?
图像周围的内容(也称上下文)可以帮助我们做出更准确的判断。
2.获取上下文信息
方案:增加感受野更大的网络分支, 将上下文信息导入局部预测中。
3.PSPNet 2016
对特征图进行不同尺度的池化,得到不同尺度的上下文特征
上下文特征经过通道压缩和空间上采样之后拼接回原特征图 → 同时包含局部和上下文特征
基于融合的特征产生预测图
四、空洞卷积与 DeepLab 系列算法
1.DeepLab 系列
DeepLab 是语义分割的又一系列工作,其主要贡献为:
使用空洞卷积解决网络中的下采样问题
使用条件随机场 CRF 作为后处理手段,精细化分割图
使用多尺度的空洞卷积(ASPP 模块)捕捉上下文信息
DeepLab v1 发表于 2014 年,后于 2016、2017、2018 年提出 v2、v3、v3+ 版本。
2.空洞卷积解决下采样问题
图像分类模型中的下采样层使输出尺寸变小。
如果将池化层和卷积中的步长去掉:
可以减少下采样的次数;
特征图就会变大,需要对应增大卷积核,以维持相同的感受野,但会增加大量参数
使用空洞卷积(Dilated Convolution/Atrous Convolution),在不增加参数的情况下增大感受野
空洞卷积和下采样
3.DeepLab 模型
DeepLab 在图像分类网络的基础上做了修改:
去除分类模型中的后半部分的下采样层
后续的卷积层改为膨胀卷积,并且逐步增加rate来维持原网络的感受野
4.条件随机场 Conditional Random Field, CRF
模型直接输出的分割图较为粗糙,尤其在物体边界处不能产生很好的分割结果。
DeepLab v1&v2 使用条件随机场 (CRF) 作为后处理手段,结合原图颜色信息和神经网络预测的类别得到精细化分割结果。
CRF 是一种概率模型。DeepLab 使用 CRF 对分割结果进行建模,用能量函数用来表示分割结果优劣,通过最小化能量函数获得更好的分割结果。
能量函数的意义
5.空间金字塔池化 Atrous Spatial Pyramid Pooling ASPP
PSPNet 使用不同尺度的池化来获取不同尺度的上下文信息。
DeepLab v2 & v3 使用不同尺度的空洞卷积达到类似的效果。
6.DeepLab v3+
DeepLab v2 / v3 模型使用 ASPP 捕捉上下文特征
Encoder / Decoder 结构(如 UNet) 在上采样过程中融入低层次的特征图,以获得更精细的分割图
DeepLab v3+ 将两种思路融合,在原有模型结构上增加了一个简单的 decoder 结构
7.语义分割算法总结
语义分割模型的评估
1.比较预测与真值
2.基于交并集的评估指标
六、语义分割工具包 MMSegmentation
代码库: https://github.com/open-mmlab/mmsegmentation
文档: https://mmsegmentation.readthedocs.io/en/latest/
MMSegmentation算法丰富,20+ 算法、370+ 预训练模型,统一超参,全面的性能标定。
1.项目结构
2.分割模型的模块化设计
MMSegmentation 将分割模型统一拆解为如下模块,方便用户根据自己的需求进行组装和扩展。
(1)分割模型的配置文件
model = dict(
type='EncoderDecoder' OR 'CascadeEncoderDecoder',
pretrained='open-mmlab://resnet50_v1c',
backbone=dict(
type='ResNetV1c',
# ... more options),
neck = None,
decode_head=dict(
type='PSPHead',
# ... more options
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
auxiliary_head=dict(
type='FCNHead',
# ... more options
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
train_cfg=dict(...),
test_cfg=dict(...))
(2)主干网络的配置。主干网络输入图像,输出多层次的特征图。
backbone=dict(
type='ResNetV1c',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
dilations=(1, 1, 2, 4),
strides=(1, 2, 1, 1),
norm_cfg= dict(type='SyncBN', requires_grad=True),
norm_eval=False,
style='pytorch',
contract_dilation=True)
3.ResNet v1c
ResNet 50 层以上的模型在 BottleNeck 模块以及 stem 部分(即网络前几层)有一些变形:
(1)主解码头的配置。主解码头从特征图预测分割图。
decode_head=dict(
type='PSPHead',
in_channels=2048,
in_index=3,
channels=512,
pool_scales=(1, 2, 3, 6),
dropout_ratio=0.1,
num_classes=19,
norm_cfg= dict(type='SyncBN', requires_grad=True),
align_corners=False,
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
(2)辅助解码头的配置
(3)数据集配置
(4)数据处理流水线
(5)常用训练策略
以上是关于openmmlab 语义分割算法基础的主要内容,如果未能解决你的问题,请参考以下文章