笔记分享 -- 弱网下的极限实时视频通信
Posted 声网Agora
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了笔记分享 -- 弱网下的极限实时视频通信相关的知识,希望对你有一定的参考价值。

今天给大家分享一下 InfoQ 平台公开课——弱网下的极限实时视频通信,关于实时视频通信的极限探索,主讲人是南京大学的马展教授。
一、课题背景
首先说下课题的背景,平时手机、电脑等网络设备接收信息的准确性和及时性都与实时通信有关,以实时视频通信为例,我们不可能一直保证网络的全时稳定,此时,弱网环境的存在会对提高传输质量起到重要的作用。
引用官方的解释就是:弱网环境长期存在,特别在很多关乎到生活、生产乃至生命的关键时刻,通信网络往往受到极大的物理条件限制,如海事作业、应急救灾、高并发场景等。因此我们更加需要探索新理论新方法来有效的分析、精准的建模、准确的预判,以期实现弱网极限环境下(如极低带宽 <50kbps, 极不稳定网络抖动,极大时延等)的高质量实时视频通信。
马教授先介绍了一下他自己关于视频处理方向研究了大概十七年左右,目前主要在做两个方面的工作,一方面是关于信息采集的,另一方面是利用类似人脸识别、车流识别、智能交通等技术进行视频处理,面向人的这样的一个重建。
二、弱网下极限视频通信是什么?
引入弱网
弱网和常规的互联网不一样,常规的互联网从目前极限的角度来看,已经是相当的不错。而比如说无论是直播也好还是点播也好,不管从信号处理的角度、视频压缩的角度还是从网络的角度,网络的设备已经能够满足高清超高清,甚至更多。但是遇到大规模泥石流等情况,基站无法使用;如果是在海事上,只能用的是通信卫星。但是我们又需要实时的、及时的、准确的掌握线上环境,此时研究一种极限视频框架就显得十分重要,也就是弱网。
三、极限通信的架构设计和优势
三个方面
一、 从最基本的这样的一些工程设计的角度出发,能够真正全部走向数据移动。
利用原来的方法进行数据驱动,类似于阿尔法狗-围棋,它里面用了强化学习。把强化学习用到去控制网络带宽,去控制我们复杂的像视频编解码器这样的一些参数。相对应来说,这些网络的这些参数和编辑码参数都是数字。所以如果我们通过经验性的去设计他这个,心里可能永远是有一个瓶颈的。
二、那第二个就是经验型的设计,从数据驱动更进一步走到智能化。
马教授在这里取了个标题,叫从阿尔法 go 到阿尔法 zero。说到阿尔法狗在设计的时候,他会为了很多这样的做一个简单的起步,但是到阿尔法 zero 他就会根据自己的这样的模式从最初始的状态,然后慢慢学习。所以也提出了对于端到端的视频通讯,利用在线学习,能够学到整个网络互联当中不同的状态。然后提供一个最新的在线学习的模型或者决策,要实现对单一用户的个性化学习。
三、利用视频中心以及数据通信的形式。结合视频内容或者图像的内容,让通信信息本身在这个用户的这个理解上,或者我们叫语义层面的这样的一个内容理解上,真正从数据能走向人工智能。相当于在感知中,即使视频丢了一帧或者图像有一些像素的丢失,甚至有一些大块的丢失,都可以通过一些补偿的方法把它获取回来。
四、智能视频编码
在视频信号处理方面,我们怎么样通过有脑视觉启发的这样的一个神经网络的视频压缩视频编码处理或者这样的一个更低码率的信号处理?
视频压缩它其实是一个非常类似于之前流水线结构的一个过程。从像素然后到编码端,从像素到这个安置流,解码呢从二进制流到像素,它其实是一个信息化的流程。那么这个信息化流程下我们有一些新理论和新方法应该要发掘,应该继续去探索的。
其中提到两大系统,从人的角度来看的话,我们从视网膜然后到中间的这样的。叫 optical nerve。然后再到这样的一个外侧膝双层,最后到我们的大脑,我们叫初级视觉皮层。那么这也是信息的逐步的提取和感知理解。
在另一个角度下提出了要用这个生物视觉或者老视觉来启发,利用最基本的信息流,从人眼感 3D 世界中进行网络成像。这样的称之为叫 for the pass way 到中间就是外侧吸取底层,然后再通过不同的细胞到我们的初级皮层,再到里面这个 aerial,然后这里面每个部分它都有很多这样的一个功能性。目前除了理论上的探索,我们称为叫这个刺激性实验,还有很多灵长类动物的这样的一个解剖实验。所以也从侧面证明了这样的信息是怎么样的一个传递过程。
技术上的挑战-复杂度
对于之前的一些视频图像的处理,其中有一个很关注的就是它的复杂度。它复杂度也是芯片设计到底能否实现的一个很重要的环节。
解决方案
提出了一个新的一种方法,就是我们能否把这个基于这样一个脑视觉的这样的一个模式能够跟现在的传统的这样的一个视频压缩能够结合起来。这个主要有两个原因,一般是从性能上的。在性能上的话,虽然说我们现在的图像压缩已经超过了最新的国际标准。但是在视频聊天的时候,还有一定的路要走,同时的话就是目前应该有数十亿的设备。已有的这样的一个超大数量存在。所以最有效的方法就是我们能否在这些已有的这样的设备上能够通过一些简单的改造能够让一些陈旧的数据得到启发,在视频处理上能够实实在在的用起来。
五、网络自适应传输
基于强化学习的视频码率自适应
问题描述及难点
网络的时延抖动会造成可用带宽的实时变化。现有算法主要为 VoD 场最/启发式设计.实时场景中无法获得未来视频信息且不容忍较大缓冲
解决思路
1.设计高效鲁棒的码率自适应算法预测带宽并动态调整视频编码和发送码率
2.实时码率自适应策略系统框架,通过历史的视频流化经验自动学习实时码率自适应算法
后期根据学习国际化先进经验,把这个用到了真正的实时系统里面。然后用这个实时系在互联网上的一个 any game 上进行了一个分布式学习。所以在这里面我们提出了就是说离线的这样的一个 adaptive time streaming。采集了很多这样的一个网络垂直,也包括像欧洲,像其他实验室给出来的,然后提出了一个网络反馈信号的标准,其中进行了一个演化。
基于强化学习的视频码率自适应一演进
存在问题
1.离线训练过程样本受限
2.模拟环填与实际环境可能不符
3.考虑模型模型泛化性能带来的性能损失
解决思路
1.网络状况聚类和分类
2.视频内容服类和分类
3.针对网络状况、视频分别训练离线模型
4.在线模型调优进一步覆盖未考虑到的环境状况
六、端到端极限视频通信演示平台
做的两个 demo。首先第一个就是跟 any game 做的就是目前整个的这样的一个状态,网络的感知以及这样的一个云游戏。
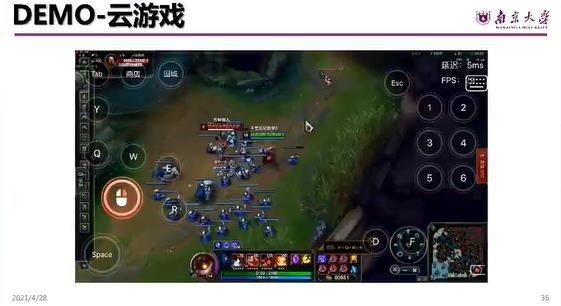
DEMO-云游戏
另一个就是在用这样的一个称为叫云中行,然后其实也是通过视频的形式把这样的一个桌面能够传递回来。
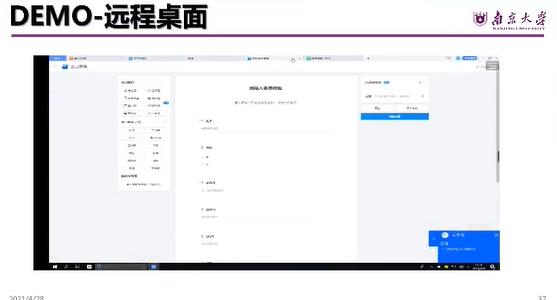
DEMO-远程桌面
以上,就是本次笔记分享的全部内容,本次分享对应的视频内容,可以点击“这里”进行观看。
以上是关于笔记分享 -- 弱网下的极限实时视频通信的主要内容,如果未能解决你的问题,请参考以下文章