使用KNN算法对鸢尾花种类预测
Posted 神的孩子都在歌唱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用KNN算法对鸢尾花种类预测相关的知识,希望对你有一定的参考价值。
使用KNN算法对鸢尾花种类预测
悄悄介绍自己:
作者:神的孩子在跳舞
本人是快升大四的小白,在山西上学,学习的是python方面的知识,希望能找到一个适合自己的实习公司,哪位大佬看上我的可以留下联系方式我去找您,或者加我微信chenyunzhiLBP
kNN算法定义:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。具体可以查看这篇文章K近邻算法简单介绍——机器学习
一. 数据集介绍
返回值的属性:
data:特征数据数组
target:标签(目标)数组
DESCR:数据描述
feature_names:特征名,
target_names:标签(目标值)名
#加载鸢尾花数据集
from sklearn.datasets import load_iris
保存在C:\\Users\\用户名\\scikit_learn_data
1.1 小数据集获取 load_*
# 获取鸢尾花数据集
iris = load_iris()
#数据集属性描述
print("鸢尾花数据集的返回值:\\n", iris)
# 返回值是一个继承自字典的Bench
print("鸢尾花的特征值:\\n", iris["data"])
print("鸢尾花的目标值:\\n", iris.target)
print("鸢尾花特征的名字:\\n", iris.feature_names)
print("鸢尾花目标值的名字:\\n", iris.target_names)
print("鸢尾花的描述:\\n", iris.DESCR)
#还有对应的feature_names
部分输出情况
鸢尾花数据集的返回值:
{'data': array([[5.1, 3.5, 1.4, 0.2],
[4.9, 3. , 1.4, 0.2],
....
[5.9, 3. , 5.1, 1.8]]),
'target': array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
...
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2]), 'frame': None, 'target_names':
鸢尾花的特征值:
[[5.1 3.5 1.4 0.2]
...
[5.9 3. 5.1 1.8]]
鸢尾花的目标值:
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
鸢尾花特征的名字:
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
鸢尾花目标值的名字:
['setosa' 'versicolor' 'virginica']
鸢尾花的描述:
.. _iris_dataset:
1.2 大数据集获取 fetch_*
#加载鸢尾花数据集
from sklearn.datasets import fetch_20newsgroups
news=fetch_20newsgroups()
print(news["data"][0:5])
部分输出

1.3 查看数据分布 seaborn画图的
seaborn.lmplot() 是一个非常有用的方法,它会在绘制二维散点图时,自动完成回归拟合
sns.lmplot() 里的 x, y 分别代表横纵坐标的列名,
data= 是关联到数据集,
hue=*代表按照 species即花的类别分类显示,
fit_reg=是否进行线性拟合。
#用的版本老可能画图显示不出来,所以要加上%matplotlib inline
%matplotlib inline
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
#数据用dataframe存储,根据特征值的名字命名
iris_data=pd.DataFrame(data=iris.data, columns = ['Sepal_Length', 'Sepal_Width', 'Petal_Length', 'Petal_Width'])
print(iris_data)
输出
Sepal_Length Sepal_Width Petal_Length Petal_Width
0 5.1 3.5 1.4 0.2
1 4.9 3.0 1.4 0.2
2 4.7 3.2 1.3 0.2
3 4.6 3.1 1.5 0.2
4 5.0 3.6 1.4 0.2
.. ... ... ... ...
145 6.7 3.0 5.2 2.3
146 6.3 2.5 5.0 1.9
147 6.5 3.0 5.2 2.0
148 6.2 3.4 5.4 2.3
149 5.9 3.0 5.1 1.8
[150 rows x 4 columns]
#添加目标值(自变量)
iris_data["target"]=iris.target
iris_data
输出:
| Sepal_Length | Sepal_Width | Petal_Length | Petal_Width | target | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | 0 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | 0 |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | 0 |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | 0 |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | 0 |
| ... | ... | ... | ... | ... | ... |
| 145 | 6.7 | 3.0 | 5.2 | 2.3 | 2 |
| 146 | 6.3 | 2.5 | 5.0 | 1.9 | 2 |
| 147 | 6.5 | 3.0 | 5.2 | 2.0 | 2 |
| 148 | 6.2 | 3.4 | 5.4 | 2.3 | 2 |
| 149 | 5.9 | 3.0 | 5.1 | 1.8 | 2 |
150 rows × 5 columns
#定义画图函数
def iris_plot(data,col1,col2):
sns.lmplot(x=col1,y=col2,data=data)
plt.show()
iris_plot(iris_data,"Sepal_Length","Petal_Length")
上面图形存在问题:有线,并且图形颜色都一样
那是因为我们没有传入目标的类别target,和fit_reg=False表示不要线
#定义画图函数
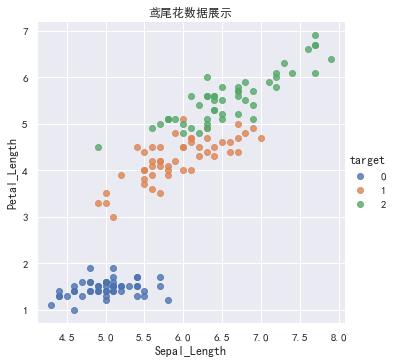
def iris_plot(data,col1,col2):
sns.lmplot(x=col1,y=col2,data=data,hue="target",fit_reg=False)
plt.title("鸢尾花数据展示")
plt.xlabel(col1)
plt.ylabel(col2)
plt.show()
iris_plot(iris_data,"Sepal_Length","Petal_Length")
如果出现中文显示问题
from matplotlib.font_manager import FontProperties
myfont=FontProperties(fname=r'C:\\Windows\\Fonts\\simhei.ttf',size=14)
sns.set(font=myfont.get_name())
iris_plot(iris_data,"Sepal_Length","Petal_Length")
多试几种
iris_plot(iris_data,"Sepal_Width","Petal_Length")

总结:
1. import seaborn
2. seaborn.lmplot()
3. 参数
二. 数据集的划分
数据集返回值是什么:训练集的特征值,测试集的特征值,训练集的目标值,测试集的目标值 顺序一定要对
from sklearn.model_selection import train_test_split
api
x 数据集的特征值
y 数据集的标签值
test_size 测试集的大小,一般为float
random_state 随机数种子,不同的种子会造成不同的随机采样结果。相同的种子采样结果相同。
return 测试集特征训练集特征值值,训练标签,测试标签(默认随机取)
还是拿鸢尾花数据测试
#会返回四个值iris.data拆分成特征值,iris.target拆分成目标值
x_train,x_test,y_train,y_test=train_test_split(iris.data,iris.target)
print('训练集的特征值{}\\n测试集的特征值{}\\n训练集的目标值{}\\n测试集的目标值{}'
.format(x_train.shape,x_test.shape,y_train.shape,y_test.shape))
输出
训练集的特征值(112, 4)
测试集的特征值(38, 4)
训练集的目标值(112,)
测试集的目标值(38,)
可以在里面加上不同的api,比如test_size和random_state
#随机数种子,我们这里传入2
x_train,x_test,y_train,y_test=train_test_split(iris.data,iris.target,test_size=0.2,random_state=2)
print('测试集的目标值\\n',y_test)
#随机数种子,我们这里传入22
x_train1,x_test1,y_train1,y_test1=train_test_split(iris.data,iris.target,test_size=0.2,random_state=22)
print('测试集的目标值\\n',y_test1)
x_train2,x_test2,y_train2,y_test2=train_test_split(iris.data,iris.target,test_size=0.2,random_state=22)
print('测试集的目标值\\n',y_test2)
输出
测试集的目标值
[0 0 2 0 0 2 0 2 2 0 0 0 0 0 1 1 0 1 2 1 1 1 2 1 1 0 0 2 0 2]
测试集的目标值
[0 2 1 2 1 1 1 2 1 0 2 1 2 2 0 2 1 1 2 1 0 2 0 1 2 0 2 2 2 2]
测试集的目标值
[0 2 1 2 1 1 1 2 1 0 2 1 2 2 0 2 1 1 2 1 0 2 0 1 2 0 2 2 2 2]
三. 特征工程
特征预处理
1. 定义: 通过一些转换函数将特征数据转换成更加适合算法模型的特征数据过程
2.包含内容:归一化和标准化
3.api:sklearn.preprocessing
4.归一化
定义:
对原始数据进行变换把数据映射到(默认为[0,1])之间
api:
sklearn.preprocessing.MinMaxScaler (feature_range=(0,1) )
参数:
feature_range -- 自己指定范围,默认0-1
总结:
鲁棒性比较差(容易受到异常点的影响)
只适合传统精确小数据场景(以后不会用你了)
5.标准化
定义:
对原始数据进行变换把数据变换到均值为0,标准差为1范围内
api:
sklearn.preprocessing.StandardScaler( )
总结:
异常值对我影响小
适合现代嘈杂大数据场景(以后就是用你了)
3.1 归一化处理MinMaxScaler
#coding:utf-8
from sklearn.preprocessing import MinMaxScaler
#读取数据
import pandas as pd
data=pd.read_csv("./data/dating.txt")
data
| milage | Liters | Consumtime | target | |
|---|---|---|---|---|
| 0 | 40920 | 8.326976 | 0.953952 | 3 |
| 1 | 14488 | 7.153469 | 1.673904 | 2 |
| 2 | 26052 | 1.441871 | 0.805124 | 1 |
| 3 | 75136 | 13.147394 | 0.428964 | 1 |
| 4 | 38344 | 1.669788 | 0.134296 | 1 |
| ... | ... | ... | ... | ... |
| 995 | 11145 | 3.410627 | 0.631838 | 2 |
| 996 | 68846 | 9.974715 | 0.669787 | 1 |
| 997 | 26575 | 10.650102 | 0.866627 | 3 |
| 998 | 48111 | 9.134528 | 0.728045 | 3 |
| 999 | 43757 | 7.882601 | 1.332446 | 3 |
1000 rows × 4 columns
#实例化一个转换器
transfer=MinMaxScaler(feature_range=(0,1))
#调用fit_transform方法
minmax_data=transfer.fit_transform(data[['milage','Liters','Consumtime']])
print("结果归一化处理之后的数据:\\n",minmax_data)
结果归一化处理之后的数据:
[[0.44832535 0.39805139 0.56233353]
[0.15873259 0.34195467 0.98724416]
[0.28542943 0.06892523 0.47449629]
...
[0.29115949 0.50910294 0.51079493]
[0.52711097 0.43665451 0.4290048 ]
[0.47940793 0.3768091 0.78571804]]
归一化缺点:容易收到异常点影响
3.2 标准化 StandardScaler
#coding:utf-8
from sklearn.preprocessing import StandardScaler
#实例化一个转换器
transfer=StandardScaler()##变成均值为0,标准差为1的范围
#调用fit_transform方法
minmax_data=transfer.fit_transform(data[['milage','Liters','Consumtime']])
print("结果标准化处理之后的数据:\\n",minmax_data)
结果标准化处理之后的数据:
[[ 0.33193158 0.41660188 0.24523407]
[-0.87247784 0.13992897 1.69385734]
[-0.34554872 -1.20667094 -0.05422437]
...
[-0.32171752 0.96431572 0.06952649]
[ 0.65959911 0.60699509 -0.20931587]
[ 0.46120328 0.31183342 1.00680598]]
四. 流程实现
1.获取数据集
2.数据基本处理
3.特征工程
4.机器学习(模型训练)
5.模型评估
4.1 导包
#coding:utf-8
from sklearn.datasets import load_iris#获取数据集
from sklearn.model_selection import train_test_split#数据分割
from sklearn.preprocessing import StandardScaler#标准化
from sklearn.neighbors import KNeighborsClassifier#模型KNN算法
4.2获取数据集
iris=load_iris()
4.3 数据基本处理
#数据分割
x_train,x_test,y_train,y_test=train_test_split(iris.data,iris.target,test_size=0.2,random_state=22)
print(x_train)
print(y_test)
[[-1.17760298 0.08972731 -1.14053941 -1.22920387]
...
[ 2.34912539 1.65995518 1.71664486 1.37688208]]
[0 2 1 2 1 1 1 2 1 0 2 1 2 2 0 2 1 1 2 1 0 2 0 1 2 0 2 2 2 2]
4.4 特征工程
#实例化一个转换器,标准化
transfer=StandardScaler()
#调用fit_transform方法
x_train=transfer.fit_transform(x_train)
x_test=transfer.fit_transform(x_test)
4.5 机器学习KNN算法进行模型训练
#实例化一个估计器
estimator=KNeighborsClassifier(n_neighbors=5)#默认auto选择最优的
#模型训练
estimator.fit(x_train,y_train)
KNeighborsClassifier()
4.6 模型评估
#输出预测值
y_pre=estimator.predict(x_test)
print("预测值:\\n",y_pre)
print("预测值和真实值t:\\n",y_pre == y_test)
#准确率
ret=estimator.score(x_test,y_test)
print("准确率是:",ret)#增加准确率可以去除random_state=22,或者调整n_neighbors
预测值:
[0 2 1 1 1 1 1 1 1 0 2 1 2 2 0 2 1 1 1 1 0 2 0 1 1 0 1 1 2 1]
预测值和真实值t:
[ True True True False True True True False True True True True
True True True True True True False True True True True True
False True False False True False]
准确率是: 0.7666666666666667
五. KNN算法总结
优点:
1.简单有效
2.重新训练代价底
3.适合类域交叉样本
4.适合大样本自动分类
缺点:
1.惰性学习
2.类别评分不是规格化
3.输出可解释性不强
4.对不均衡的样本不擅长
样本不均衡:收集到的数据每个类别占比严重失衡(解决:重新采集样本)
5.计算量较大
本人博客:https://blog.csdn.net/weixin_46654114
本人b站求关注:https://space.bilibili.com/391105864
转载说明:跟我说明,务必注明来源,附带本人博客连接。
请给我点个赞鼓励我吧

以上是关于使用KNN算法对鸢尾花种类预测的主要内容,如果未能解决你的问题,请参考以下文章