AI编译优化谈谈 tvm ansor
Posted 极智视界
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AI编译优化谈谈 tvm ansor相关的知识,希望对你有一定的参考价值。
本文主要讨论一下 tvm ansor。
参考论文:

参考代码:
文章目录
1、深度学习系统堆栈
深度学习系统堆栈,前端是各种 AI 框架(pytorch、tf、mxnet、caffe … ),后端是各种硬件(NVGPU、ARMCPU、X86CPU、NPU … )
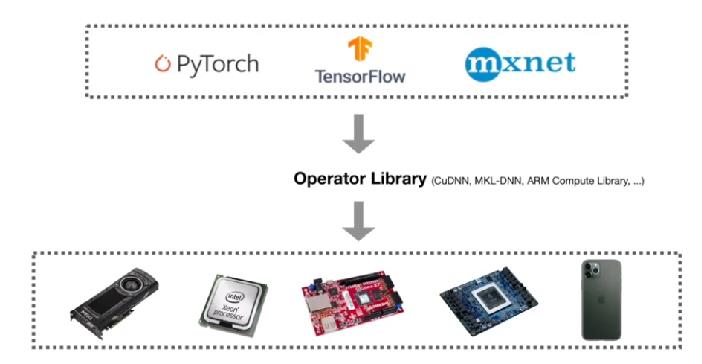
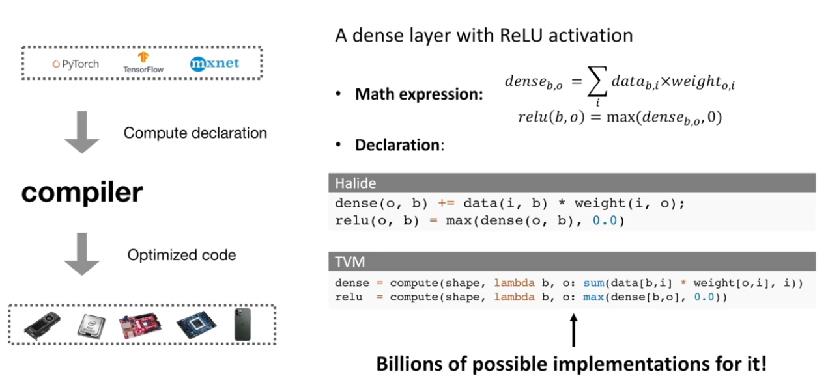
对于深度学习编译器来说,就是把前端 AI 框架出来的网络 / 算子 code_gen / compiler 成对应 target 硬件后端高性能的机器码,而 tvm / halide 把这个compiler 的过程拆成计算(compute)和调度(optimized code)两个过程,理由很简单,这样解耦后只需要关注调度优化,因为调度是和硬件强相关的,而不用担心调度影响了精度。拿 dense_layer + relu 这个 subgraph 来说,halide 和 tvm 的计算表达可能是这样的:
# halide
dense(o, b) += data(i, b) * weight(i, o)
relu(o, b) = max(dense(o, b), 0.0)
# tvm
dense = compute(shape, lambda b, o: sum(data[b, i] * weight[o, i], i))
relu = compute(shape, lambda b, o: max(dense[b, o], 0.0))
2、相关的高性能张量生成工作
2.1 auto tvm
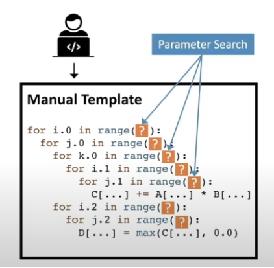
做法是使用 template-guided 进行搜索,对于每个 op 使用 templates 去定义搜索空间。
缺点是:
(1)没有做到全自动:还需要大量的手动工作;
(2)受限的搜索空间:不能达到更加好的优化性能;
2.2 halide auto-scheduler
做法是基于 sequential construction 进行搜索,使用 beam search 算法搜索顺序生成。说一下 beam search 算法,beam search 是所谓的 束搜索,是对 greedy search(贪心搜索)的一个改进算,相对 greedy search 扩大了搜索空间,但远远不及穷举搜索指数级的搜索空间,是二者的一个折中方案。
halide auto-scheduler 的缺点是:
(1)因为它是顺序生成的,对于中间的算子优化来说是不连续不完整的,因此 cost model 没办法进行准确的预测,导致了错误的累积;
(2)和 auto tvm 一样,搜索空间也是受限的;
通过对以上两个调度搜索算法的讨论,得到三个痛点:(1)怎么样能够自动的获取一个很大的搜索空间;(2)如何让搜索更加的高效;(3)对于这么多的搜索任务我们怎么样去分配资源。对于这三个痛点,ansor 的解法是:对于(1)采用 hierarchical search space;对于(2)采用 sample complete programs and fine-tune them;对于(3)采用 task scheduler 程序对重要任务进行优先排序。
3、tvm ansor 原理
先来看一下 tvm ansor 的逻辑栈,下面对主要的操作展开谈谈。
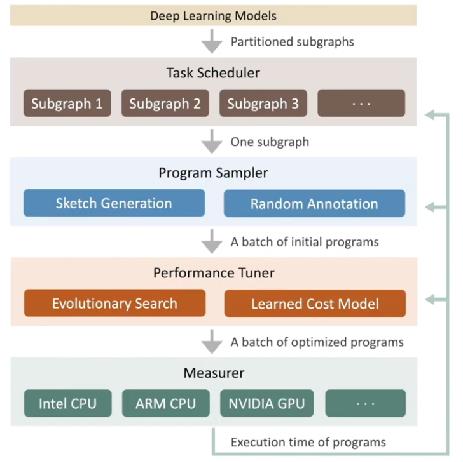
前端接的还是 AI框架出来的 models,然后切分成很多 subgraphs 子图,对于每个 subgraph 都会进行如下的调度优化。
3.1 program sampling
program sampling 的目标是自动地构建一个连续的大的搜索空间。这里要理解这个搜索空间到底是用于搜索个啥,我的理解是搜索计算的姿势或者说计算的调度方式,而不是计算本身。方法是使用 sketch generation 和 random annotation。其中 sketch 是 a few good high-level structures,annotaion 是 billions of low-level details,通俗一点理解 sketch 进行高层抽象,annotaion 进行底层映射,通过这两步操作就能构建了一个很大的搜索空间。
这个用于解决痛点(1)搜索空间大小问题。

3.1.1 sketch generation
先贴一些论文里的描述:

做法大致流程是这样:先出数学表达 -> 再出程序表达 -> 根据程序表达和数学表达出有向无环图描述计算节点和计算逻辑 -> 根据设计好的 sketch gen rules 来生成 sketch 表达(比如对于CPU,有 “SSRSRS”的循环展开结构)。所以 sketch 的整个流程可以用如下这个 dense_layer + relu 的例子展示,可以看到最后生成的 sketch 草图里有很多类似 TILE_I0 的参数,这些是超参,是需要调优搜索的值,也是 random annotation 的工作之一,所以最后生成的 sketch 草图不止一个,往往是一个草图列表。

还有这个例子也是一样:

3.1.2 random annotation
annotaion 是获得 sketch 草图的后续动作,annotaion 操作是 randomly 选择一个sketch,randomly 填充 tile sizes,randomly parallelize 外部循环,randomly vectorize 内部循环,randomly change 计算节点位置以对 tile stucture 做微调等。还是接着上面的 dense_layer + relu 的例子展示:

3.2 performance fine-tuning
接着 program sampling 后的操作就到了 performance tuner 了。这里这要包含搜索算法设计和代价评估模型的设计,使 ansor 能够更加高效的进行搜索和收敛。
这个用于解决痛点(2)搜索效率问题。
3.2.1 evolutionary search
random annotation 的随机生成/抽样不能保证性能,ansor 采用类似遗传算法的进化搜索算法来进一步对 annotation 抽样程序进行进化搜索。主要涉及 基因突变和基因交叉。
(1)突变:随机改变 tile size;随机改变 parallel/unroll/vectorize 因子和粒度;随机改变 computation location;
(2)交叉:从算子计算有向无环图的角度解释,如下:

3.2.2 learned cost model
预测每个 non-loop innermost statement 的得分,可能比较抽象,上一些论文里的解释

再上个例子进行说明,如下,statement B 和 statement C 就是所谓的 non-loop innermost statement 了,这个比较直观一点。

每个 non-loop innermost statement 提取的特征包括:使用的 cache lines、使用的 memory、reuse distance、arithmetic intensity 等
3.3 task scheduler
ansor 中的 task scheduler 会对重要任务进行优先排序。
这个是用于解决痛点(3)多任务调度资源分配问题。
我们拿 resnet50 来说,在 ansor 中会把它切成 29 个独立的 subgraphs。如果按照传统的任务调度方式,一般会顺序地对这些 subgraphs 进行调度,就像这样。

ansor 中的 task scheduler 会将时间进行切片并对重要的子图优先排序,就像这样,这种优化很像推理里的 pipeline 优化。

4、性能数据
下面给出一些测试的性能数据,论文里也有:
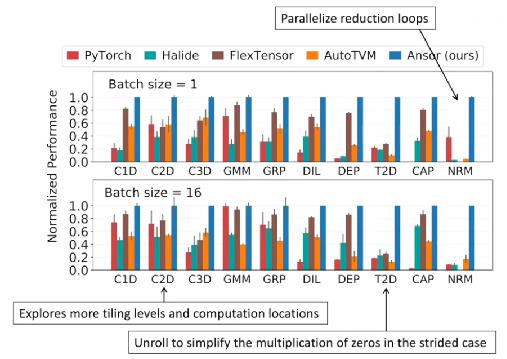
(1) 单算子
测试平台是 Intel-Platinum 8124M (18 cores):

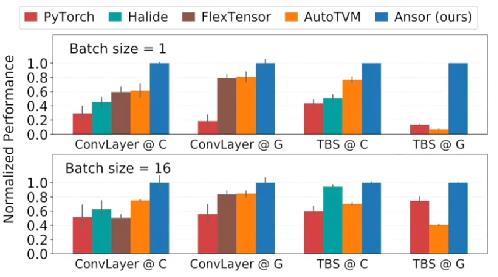
(2) subgraph
测试平台是 ‘’@C’’ for Inter CPU (8124M)、’’@G’’ for NVIDIA (V100)。
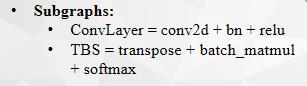
(3) 整网
测试平台是 Intel CPU (8124M)、NVIDIA GPU (V100)、ARM CPU (A53)。


从上面给出的数据可以看出,不管是单算子、subgraph、整网来说,ansor 的表现都很棒。
以上讨论了我目前对 tvm ansor 的理解。
收工~
扫描下方二维码即可关注我的微信公众号【极智视界】,获取更多AI经验分享,让我们用极致+极客的心态来迎接AI !

以上是关于AI编译优化谈谈 tvm ansor的主要内容,如果未能解决你的问题,请参考以下文章