极智AI | 谈谈昇腾 auto tune
Posted 极智视界
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了极智AI | 谈谈昇腾 auto tune相关的知识,希望对你有一定的参考价值。
欢迎关注我的公众号 [极智视界],获取我的更多笔记分享
大家好,我是极智视界,本文介绍一下 谈谈昇腾 auto tune。
auto tune 也即 自动调优,在 AI 芯片国产化适配的过程中,你会发现有好几家是基于 tvm 的拓展。这里昇腾也不例外,所以昇腾的 auto tune,一切源于TVM。tvm 会有几个关键词:自动优化、深度学习编译器、适配多种硬件后端,这里昇腾的 auto tune 最关注的应该就是 自动优化。所以,可能会蹦出:为什么需要自动优化呢?总结来说主要有几下几点:
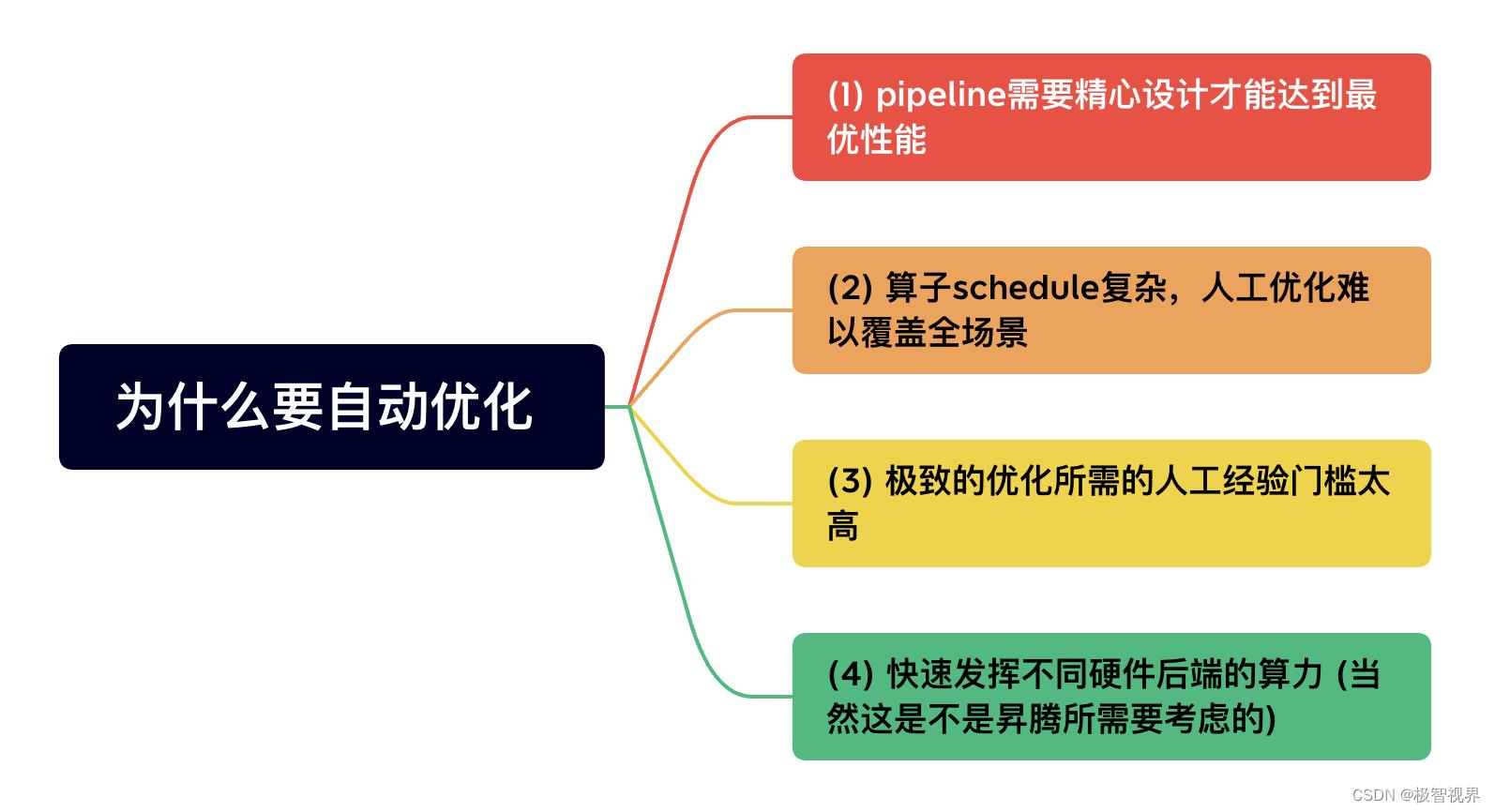
首先是 AI芯片在计算过程中需要精心的排布才能充分发挥算力 (pipeline 优化):AI 芯片通常由计算单元 (如昇腾的就有 矩阵计算单元、向量计算单元 和 标量计算单元等多个计算单元)、控制单元、存储单元 (on-chip、global memory等) 模块组成,运行在上面的算子,耗时或者吞吐量无法简单的通过计算量和算力获得,更要看各个组件之间的协同情况。即使相同的计算任务部署在相同的卡上,用不同的 pipeline 排布 效率也会差别十分的大,而看似相似的计算输入可能要求的计算 pipeline 流水线排布也是相差巨大。算子的理论最大性能是其瓶颈负载 (计算、数据传输等) 除以对应处理单元的效率。然而,在现代 AI 卡上 (比如昇腾卡),一次计算任务通常会被切分成多片进行处理,这样就会产生计算或传输冗余,所以实际负载往往要大于理论负载。咱们通常需要把冗余较小的方案或者冗余转移到非瓶颈组件上。这就是 pipeline 优化,如果都要靠人工一点点去排布,工作量巨大。
其次是算子schedule的优化:这是怎么回事呢?我们一般理解的算子实现其实只有 算子计算实现,而像 tvm 这类编译优化的框架中还有个概念是 算子调度实现 (你也可以发现,在写昇腾TBE算子 或者 是写TVM算子的时候,需要实现两个部分:compute 和 schedule)。可以说算子的计算实现优化是有限的,但是算子调度优化却是有千千万,拿 tvm 里的算子调度优化就包括:sketch generation、random annotation、突变、交叉等 (我有一篇文章专门写了 tvm 的 auto-tune,有兴趣的同学可以移步查阅 《极智AI | 谈谈 tvm ansor》)。如果这些算子调度优化,都需要人工一点点去抠,一点点去优化,一方面要求的人工经验门槛太高,另一方面人工优化难以覆盖全场景。有了 auto tune,可以说刚毕业的学生,甚至在校的同学也能够通过 简单的配置 获得不错的性能。
最后是 能够快速发挥不同硬件后端的算力:当然这并不是昇腾所需要考虑的,因为昇腾的 auto tune 只需要针对昇腾的卡 (特定的芯片、特定的架构) 进行极致的优化就可以了,而不要考虑适配其他家的芯片。但 TVM 不一样,TVM 的提出本身就是为了解决 前端训练框架太多、后端硬件太多,部署难、慢、重复造轮子 的问题,所以 auto-tune (tvm ansor) 有个很重要的使命是 能够快速发挥不同硬件后端的最大算力。

经过上述讨论,应该很容易得出结论:昇腾 auto tune 模块的作用是 快速、充分、低门槛地利用 Ascend 硬件资源进行算子的自动优化。昇腾的 auto tune 模块集成在 ATC 工具中,所以是在做模型转换的时候去做 auto tune。
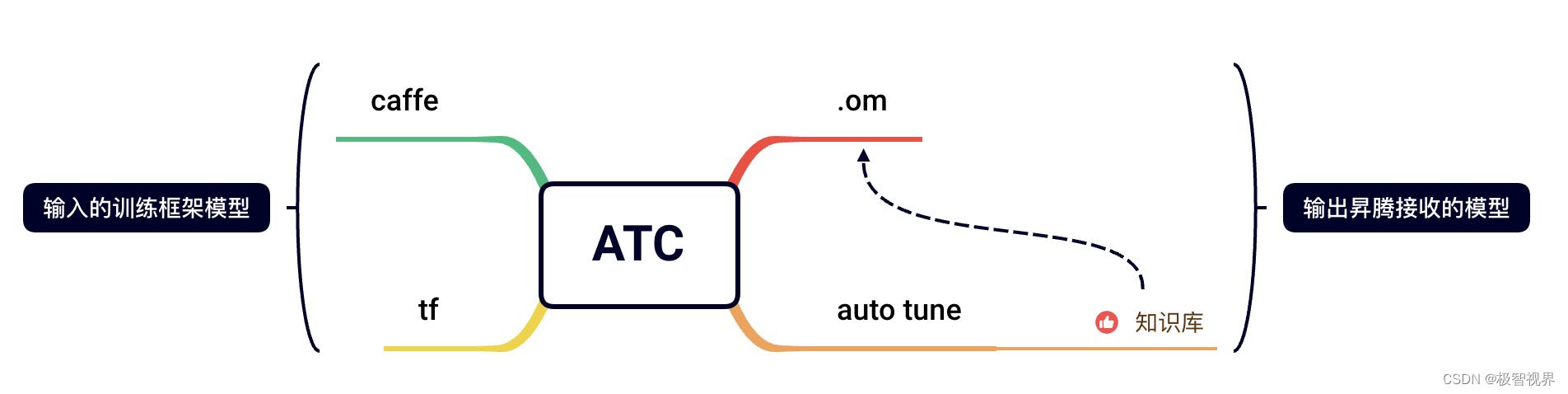
具体的下篇再说吧。
好了,以上分享了 谈谈昇腾 auto tune,希望我的分享能对你的学习有一点帮助。
【极智视界】

搜索关注我的微信公众号【极智视界】,获取我的更多经验分享,让我们用极致+极客的心态来迎接AI !
以上是关于极智AI | 谈谈昇腾 auto tune的主要内容,如果未能解决你的问题,请参考以下文章