极智AI | 再谈昇腾 auto tune
Posted 极智视界
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了极智AI | 再谈昇腾 auto tune相关的知识,希望对你有一定的参考价值。
欢迎关注我的公众号 [极智视界],获取我的更多笔记分享
大家好,我是极智视界,本文 再来谈谈昇腾 auto tune。
写这篇主要是为了填这篇《谈谈昇腾 auto tune》自己留的坑,上篇其实大篇幅在说昇腾 auto tune 的一些 由来,以及与 深度学习编译器 tvm 的一些联系,感兴趣的同学可以去瞧瞧~
这篇主要写昇腾 auto tune 的原理。
上篇说到,auto tune 的作用其实就是充分发挥硬件资源进行算子的自动调优。而具体到昇腾里,把 auto tune 功能集成在 atc模型转换工具 里面,在使用 atc 生成 om 模型的时候,打开 --auto_tune_mode 开关就能够方便的使用 auto tune 功能了,调优的结果会放在自定义路径 / 默认路径的知识库中,然后生成模型的时候就可以享用调优的知识库,生成性能更加好的模型。
昇腾里的 auto tune 包含两种调优模式:RL 和 GA,而搜索算法在 tvm 里会更加丰富一些,包括:Random、GridSearch、GA、XGBoost。如下:
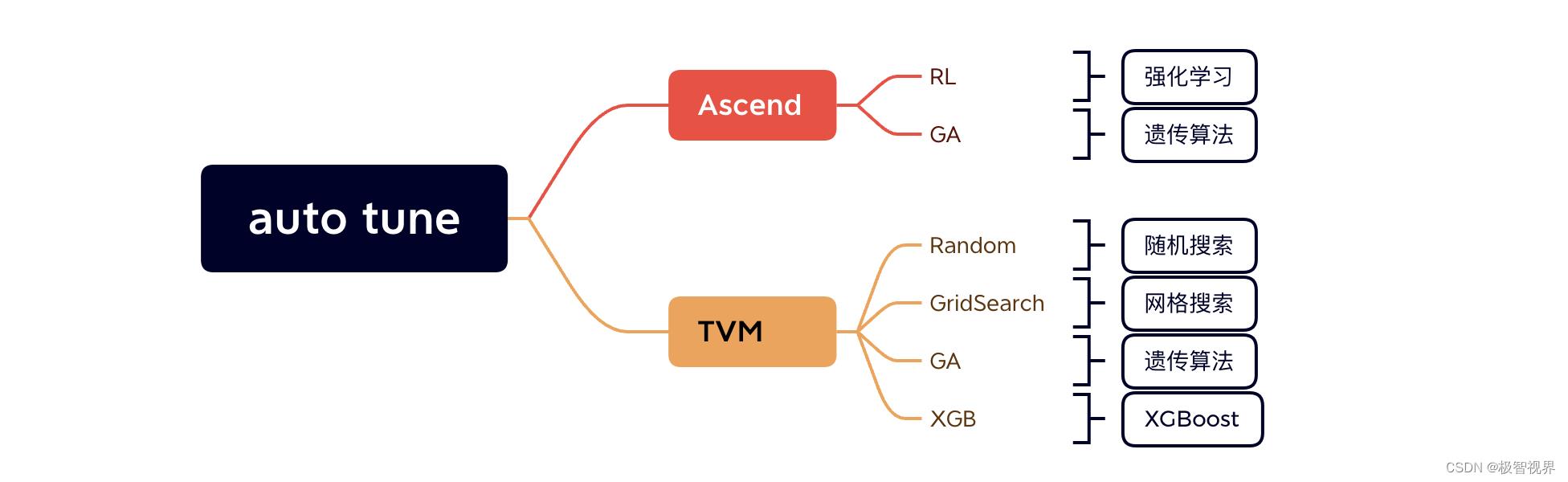
主要来说说昇腾的两种调优模式:
- RL Mode:Reinforcement Larning 即强化学习,原理为 将schedule调度过程抽象为基于蒙特卡洛树搜索的决策链 (
蒙特卡洛树搜索又称随机抽样或统计试验方法,阿尔法狗在下棋的时候,做决策的不是策略网络和价值网络,而是蒙特卡洛树搜索),然后使用神经网络指导决策,其中的神经网络是基于强化学习训练而成的。昇腾的 RL Mode 主要支持elewise、broadcast、reduce类算子; - GA Mode:这个思想和 tvm 的一样,主要通过遗传算法 (GA) 进行多轮的参数寻优,从而获得最优的策略。采用多级组合优化生成调优空间,加入人工经验进行剪枝、压缩、重排,以提高搜索效率。昇腾的 GA Mode 主要支持
cube类算子 (所谓cube类算子 就是指 矩阵乘之类的算子,因为cube就是指昇腾的矩阵运算单元),如Conv2D、GEMM、MatMul、FullyConnection等;
介绍到这里其实还是比较笼统,下面再深入来讲解两种模式的原理。
RL Mode 原理
首先来说说 RL Mode,RL Mode 由 RL Tune 和 RL知识库 两部分组成,其中 RL Tune 主要负责算子调优,而 RL知识库 则用来存储调优后的策略。
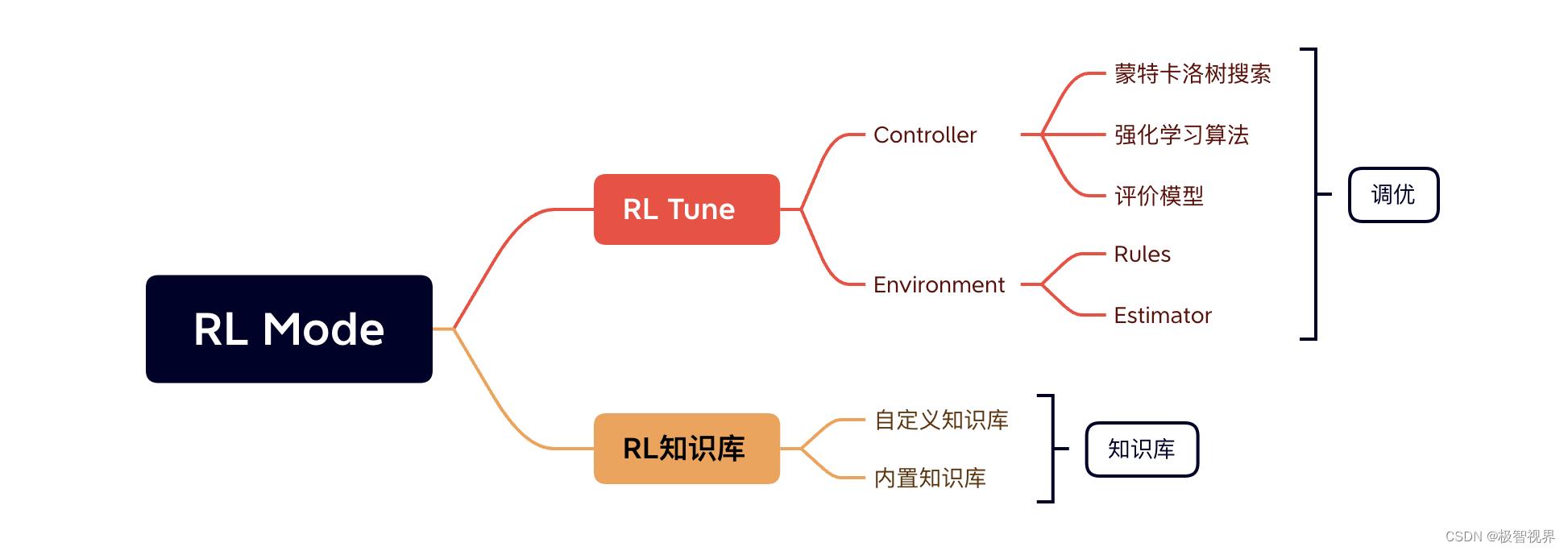
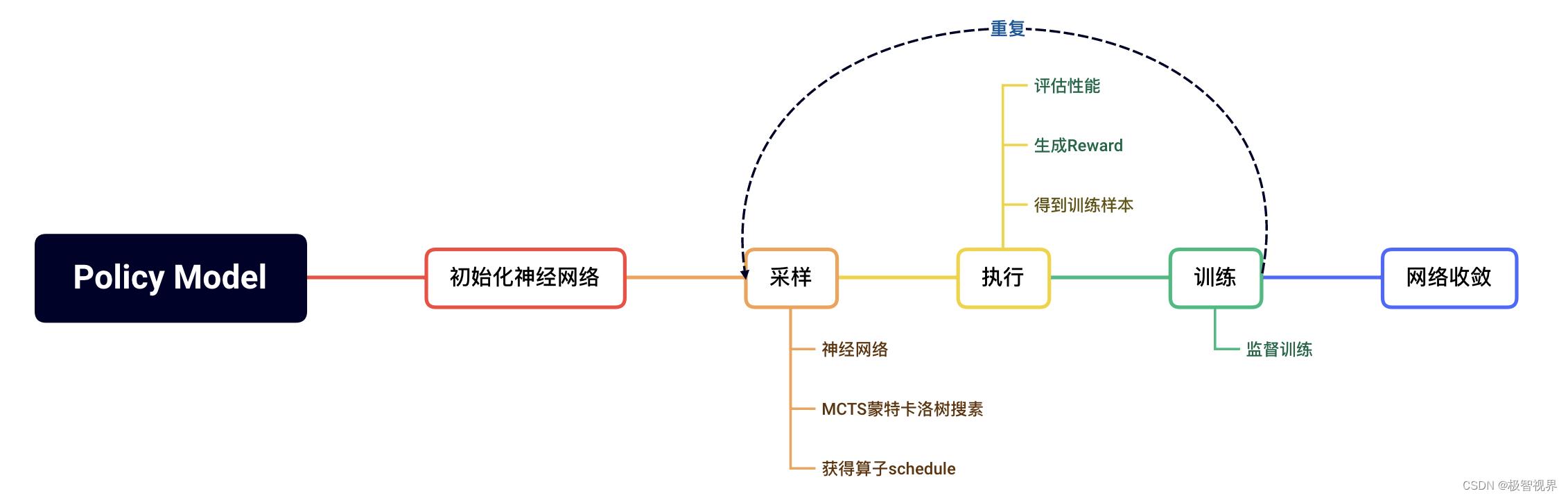
RL Tune 中会使用强化学习训练出一个策略评价模型 Policy Model,训练的原理如下:
RL知识库包括 内置知识库 与 自定义知识库。内置知识库顾名思义就是内置好的了,是预置的针对常见算子不同 shape 的调优后的策略 (知识库),存储路径为 cann_install_path/opp/data/rl/<soc_version>/built-in。而自定义知识库 是用户使用 RL Mode 调优后生成的性能优于内置知识库的调优策略 (所以这里在调优的过程中会去和内置知识库进行一个性能比较),默认存储在 cann_install_path/opp/data/rl/<soc_version>/custom,也可自行指定存储路径。
GA Mode 原理
GA Mode 首先会进行调优空间的分析,然后利用遗传算法进行搜索,评估出最优调优策略后存入知识库中。
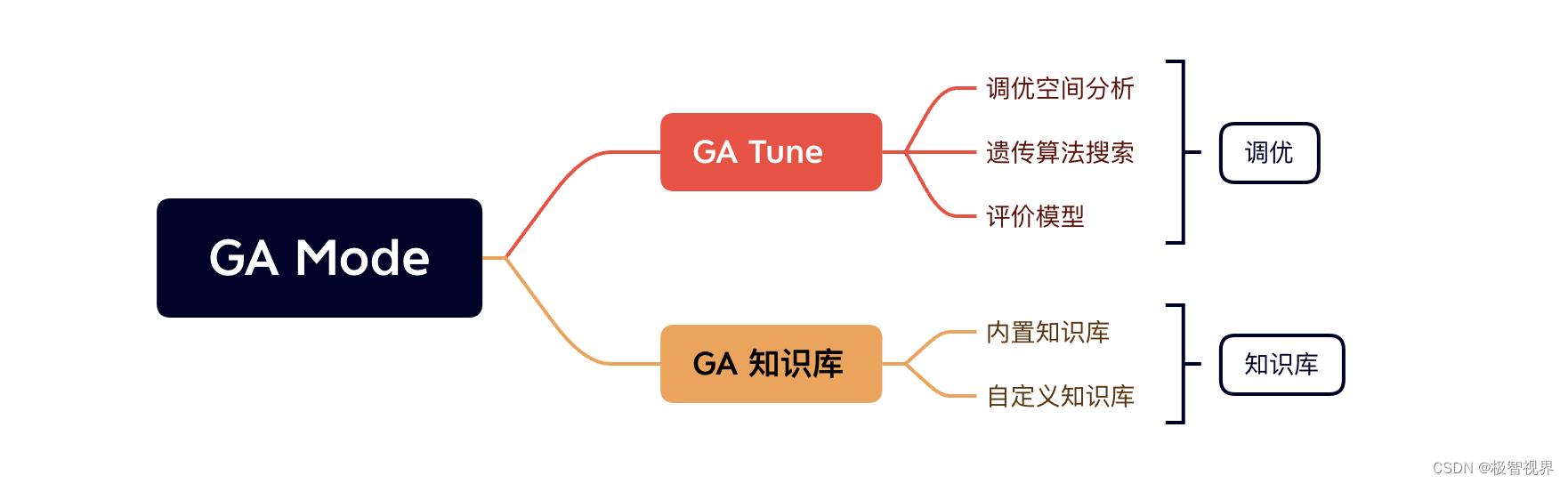
GA Mode 中调优空间分析主要是指 tiling组合分析,生成调优空间后 (tiling参数空间),再利用遗传算法进行调优搜索,最后返回最优的 tiling参数。整个过程如下:
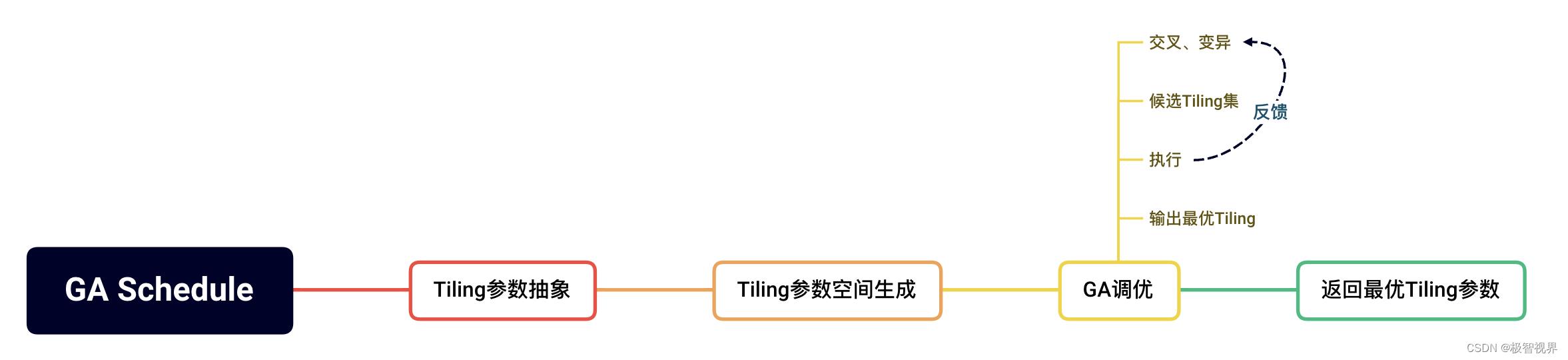
同样,GA 知识库包括 内置知识库 与 自定义知识库。内置知识库存储路径为 cann_install_path/opp/data/tiling/<soc_version>/built-in。而自定义知识库默认存储在 cann_install_path/opp/data/tiling/<soc_version>/custom,同样也可自行指定存储路径。
再留个坑吧,具体用法咱们下篇再说。
好了,以上分享了 再谈昇腾 auto tune,希望我的分享能对你的学习有一点帮助。
【极智视界】

搜索关注我的微信公众号【极智视界】,获取我的更多经验分享,让我们用极致+极客的心态来迎接AI !
以上是关于极智AI | 再谈昇腾 auto tune的主要内容,如果未能解决你的问题,请参考以下文章