组队学习李宏毅的深度学习-1
Posted Mia2019
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了组队学习李宏毅的深度学习-1相关的知识,希望对你有一定的参考价值。
一、学习总任务

二、完成任务1
Task01——机器学习介绍
Part1:任务综述
本任务主要是需要掌握机器学习的基本内容,包括简要历史、相关概念、主要相关技术的介绍。
Part2:主要内容笔记
1.人工智慧,机器学习,深度学习的关系
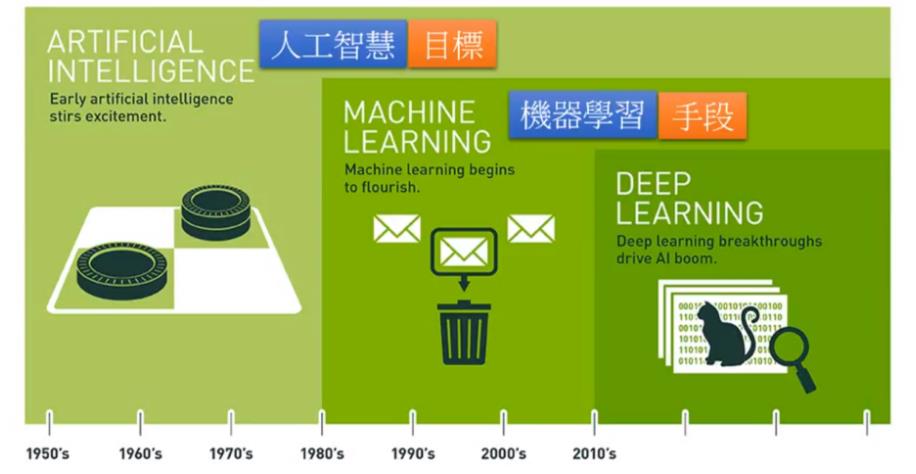
人工智慧是我们想要达成的目标,而机器学习是想要达成目标的手段,深度学习就是机器学习的其中一种方法。
若想机器具备人工智慧,那么根据生物智慧的性质,有那种方式,一是让机器具备本能,二是通过后天学习的手段让机器表现的很有智慧。由于是机器,机器的本能性是人类提前灌输给它的内容,称为规则。它根据人类设定好的规则进行各种行为。那么人类想不到东西,就没办法写规则,没有写规则,机器就不知道要怎么办。如此,就必须给以派给成千上万的工程师,用血汗的方式来建出数以万计的规则,然后让他的机器看起来好像很聪明。机器的学习性主要体现在不需要非常大量的人来帮你想各式各样的规则,只要手上有data,你可以让机器通过自身反复学习来帮你做这件事情。
2.机器学习的基本框架
a、确定function集合;b、找到评价标准;c、找到最好的function

3.基于Learning Map介绍相关技术

a.监督学习(supervised learning)
监督学习是一种传统的机器学习方式。是告诉机器function的input和output,机器通过我们提供给它的training data而学习后得到output.
其中,Regression是一种machine learning的task,它的输出是一个scalar。
Regression和Classification的差别是机器输出类型不一样。在Regression中机器输出的是一个数值,在Classification里面机器输出的是类别。假设Classification问题分成两种,一种叫做二分类输出的是是或否(Yes or No);另一类叫做多分类(Multi-class)。
我们知道,机器在解任务的过程中第一步就是要选择function set,选不同的function set就是选不同的model。Model有很多种,有线性模型和非线性模型。在非线性的模型中最耳熟能详的就是Deep learning。(注意:除了deep learning 以外还有很多machine learning的model也是非线性的模型)
b.半监督学习(Semi-Supervised Learning,SSL)
半监督学习使用大量的未标记数据,以及同时使用标记数据,来进行模式识别工作。(means:监督学习的训练数据都是有标签的)
c.迁移学习(Transfer learning)
迁移学习就是把为任务 A 开发的模型作为初始点,重新使用在为任务 B 开发模型的过程中。这个学习有些像让机器学会举一反三。
d.无监督学习(Unsupervised Learning)
通过监督学习的对比来理解无监督学习:
- 监督学习是一种目的明确的训练方式,你知道得到的是什么;而无监督学习则是没有明确目的的训练方式,你无法提前知道结果是什么。
- 监督学习需要给数据打标签;而无监督学习不需要给数据打标签。
- 监督学习由于目标明确,所以可以衡量效果;而无监督学习几乎无法量化效果如何。
d.强化学习(Reinforcement Learning, RL)
这种学习方法是不断语环境的交互、试错,最终得到特定目的。
以上是关于组队学习李宏毅的深度学习-1的主要内容,如果未能解决你的问题,请参考以下文章