深度学习的三个主要步骤!
Posted AI科技大本营
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习的三个主要步骤!相关的知识,希望对你有一定的参考价值。


作者:屈太国
来源:Datawhale

说明
本文来自李宏毅机器学习笔记(LeeML-Notes)组队学习,详细介绍了使用深度学习技术的三大主要步骤。
教程地址:
https://github.com/datawhalechina/leeml-notes
深度学习的三个步骤:
Step1:神经网络(Neural network)Step2:模型评估(Goodness of function)Step3:选择最优函数(Pick best function)
Step1:神经网络
01

神经网络是由很多单元连接而成,这些单元称为神经元。
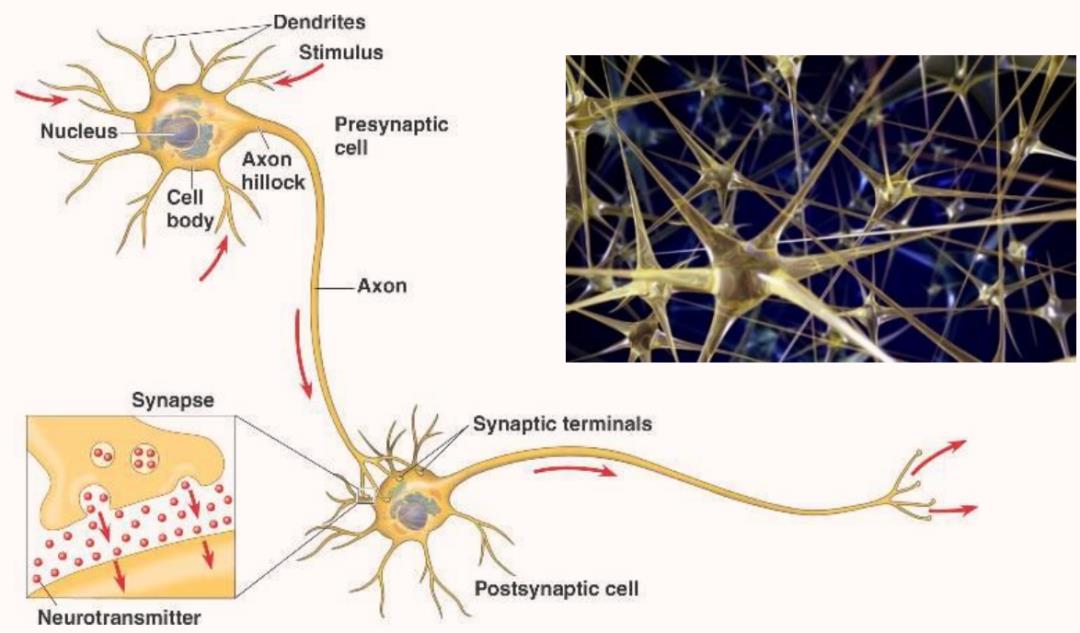
神经网络类似于人类的神经细胞,电信号在神经元上传递,类似于数值在神经网络中传递的过程。
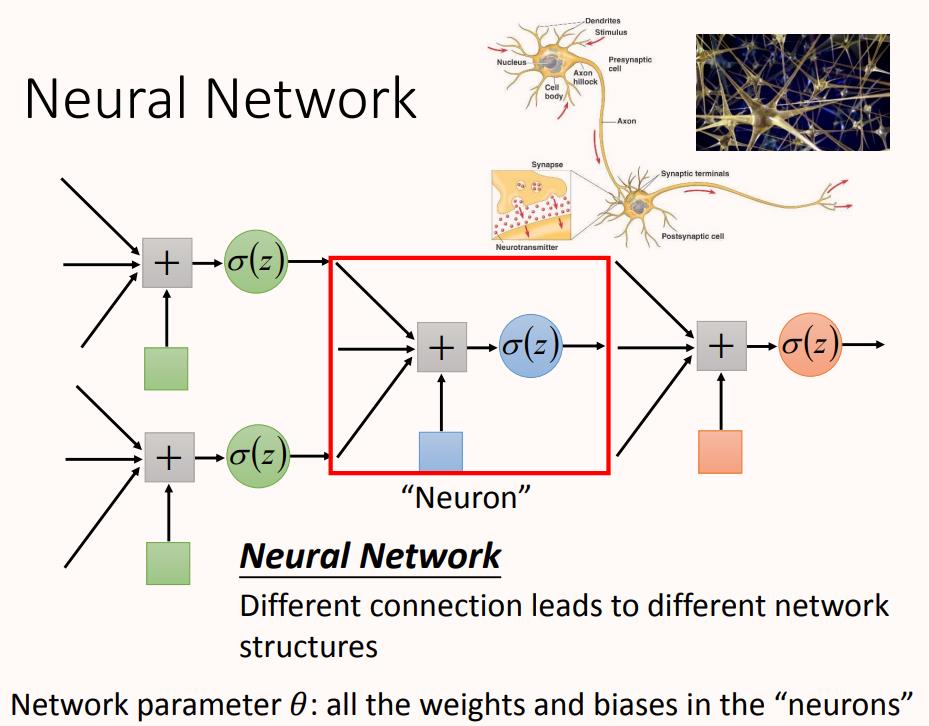
在这个神经网络里面,一个神经元就相当于一个逻辑回归函数,所以上图中有很多逻辑回归函数,其中每个逻辑回归都有自己的权重和自己的偏差,这些权重和偏差就是参数。
图中红框表示的就是神经元,多个神经元以不同的方式进行连接,就会构成不同结构神经网络。神经元的连接方式是由人工设计的。
神经元:神经元的结构如图所示
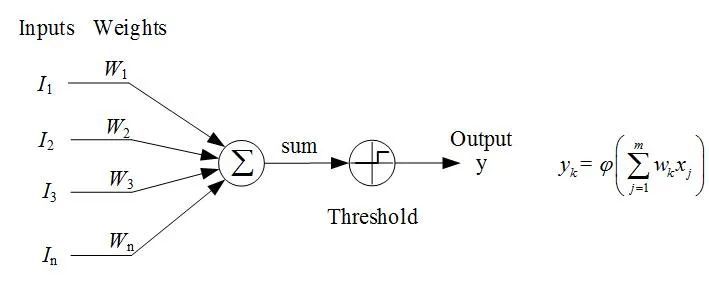
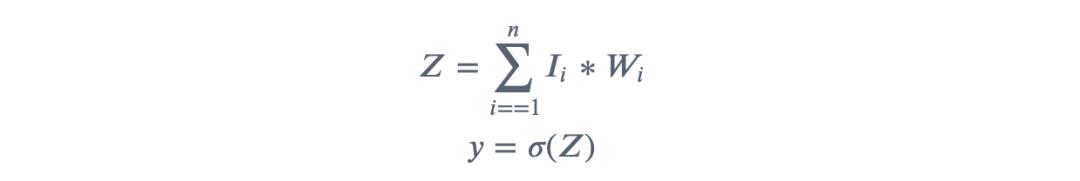
每个输入乘以其对应的权重,将结果求和,得到;
将和代入激活函数,得到结果。

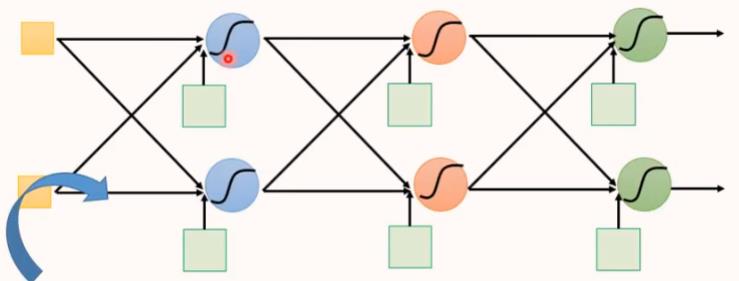
全连接前馈神经网络
全连接:每一个神经元的输出都连接到下一层神经元的每一个神经元,每一个神经元的输入都来自上一层的每一个神经元。
前馈:前馈(feedforward)也可以称为前向,从信号流向来理解就是输入信号进入网络后,信号流动是单向的,即信号从前一层流向后一层,一直到输出层,其中任意两层之间的连接并没有反馈(feedback),亦即信号没有从后一层又返回到前一层。
全连接前馈神经网络示例:
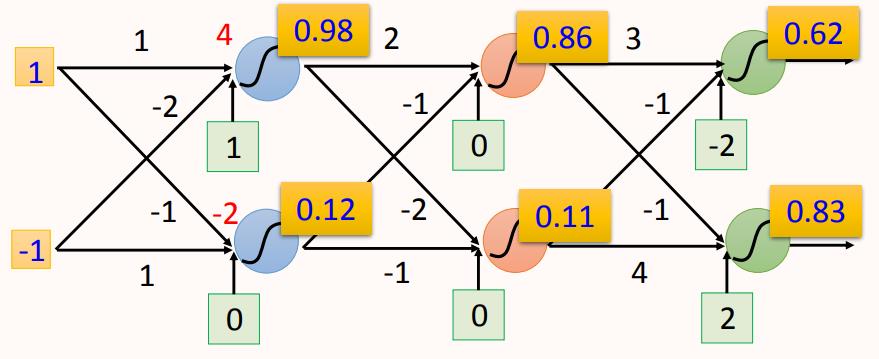
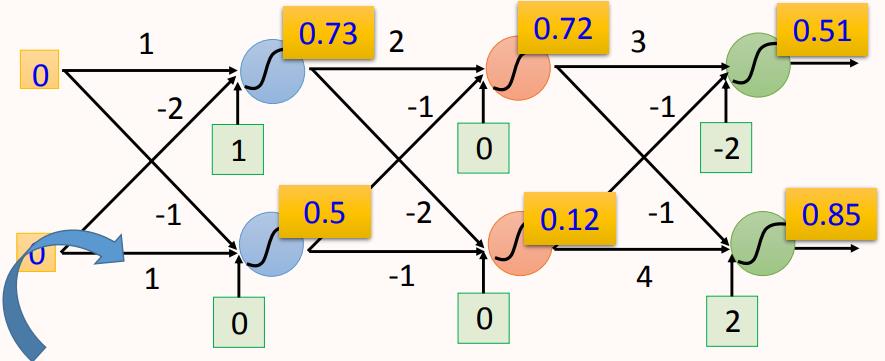
如图所示,这是一个4层的全连接神经网络,每一层有两个神经元,每个神经元的激活函数都是sigmoid。
网络输入为(1, -1),激活函数为sigmoid:
网络输入为(0, 0),激活函数为sigmoid:
神经网络结构:
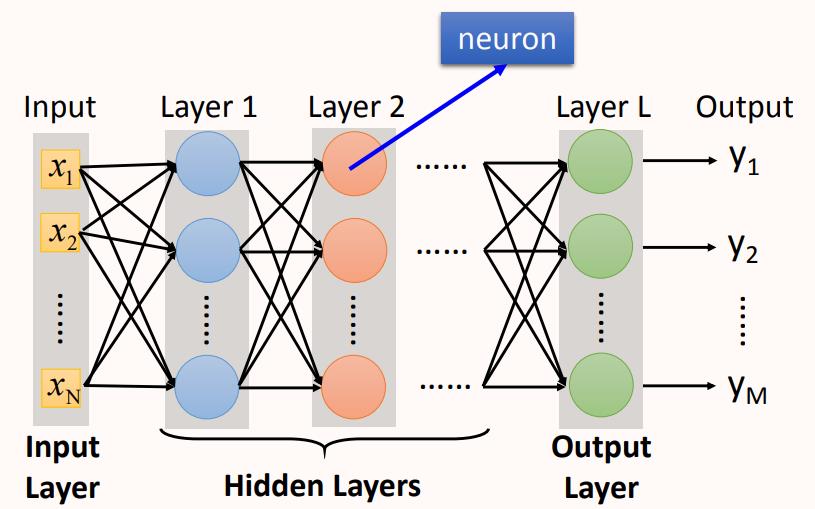
Input Layer:网络的输入层,Layer的size和真实输入大小匹配。
Hidden Layers:处于输入层和输出层之间的网络层。
Output Layer:网络的最后一层,神经元计算产生的结果直接输出,作为模型的输出。

一些疑惑
为什么叫「全连接」?
因为网络中相邻的两层神经元,前一层的每一个神经元和后一层的每一个神经元都有连接,所以叫做全连接;
为什么叫「前馈」?
因为值在网络中传递的方向是由前往后传(输入层传向输出层),所以叫做Feedforward。
Deep Learning,“Deep”体现在哪里?
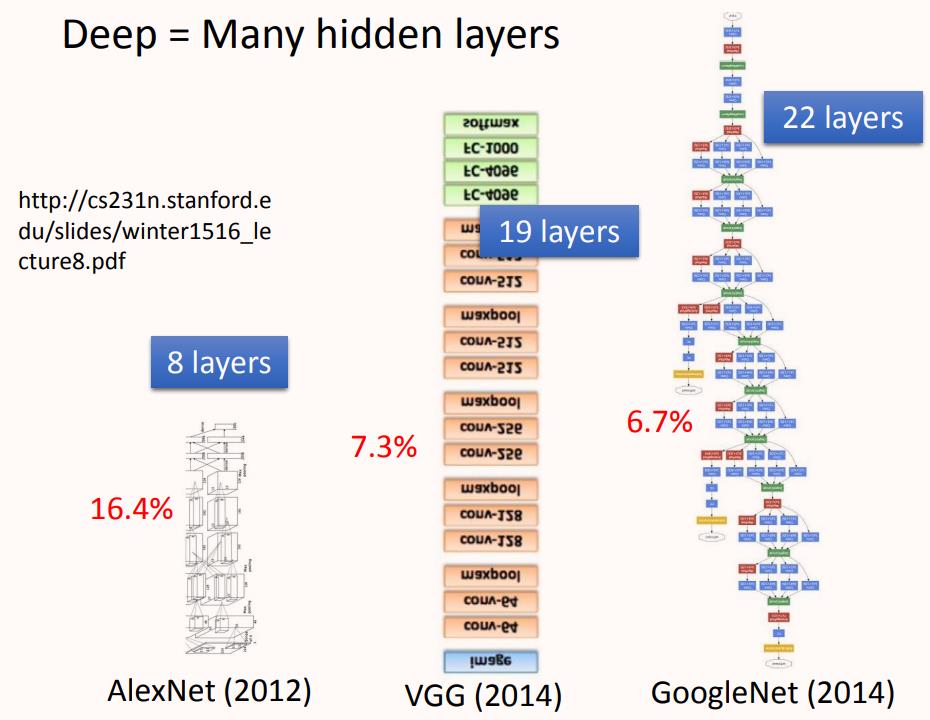
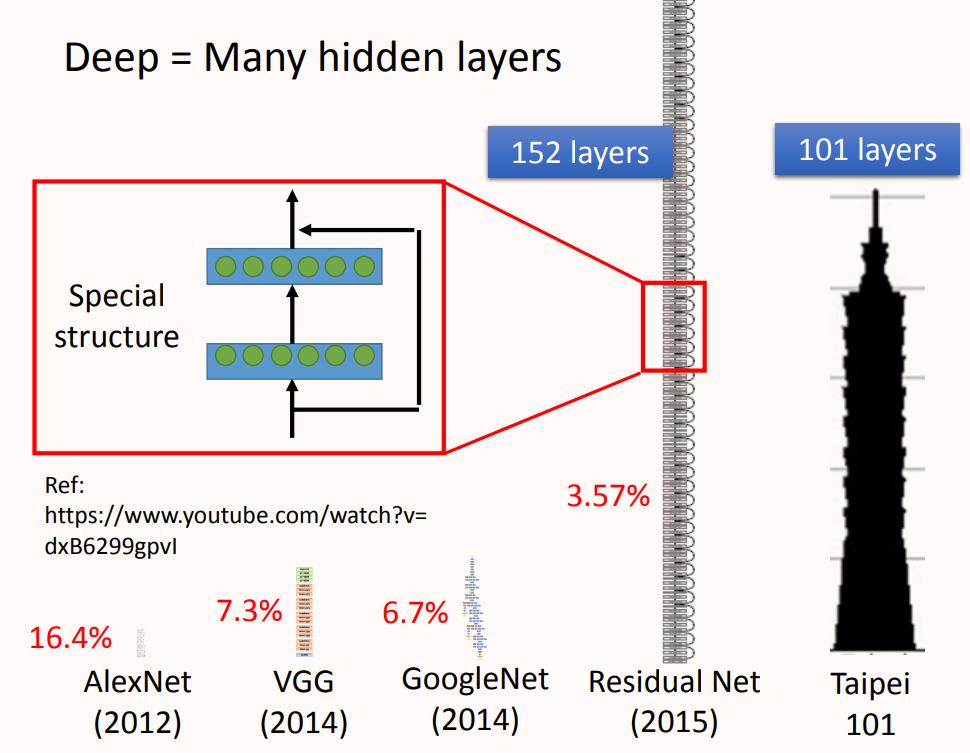
神经网络的连接方式由人工设计,所以可以堆叠很多层神经元构成很“深”网络,如上图所示2015年提出的ResNet就达到了152层的深度。

深度神经需要特殊的训练技巧
随着层数变多,网络参数增多,随之运算量增大,通常都是超过亿万级的计算。对于这样复杂的结构,我们一定不会一个一个的计算,对于亿万级的计算,使用loop循环效率很低。
网络的运算过程如图所示:
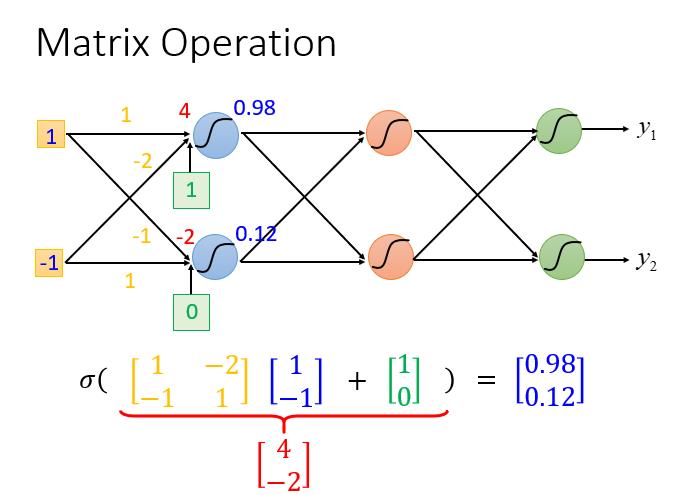
上图中,网络的运算过程可看作是矩阵的运算。
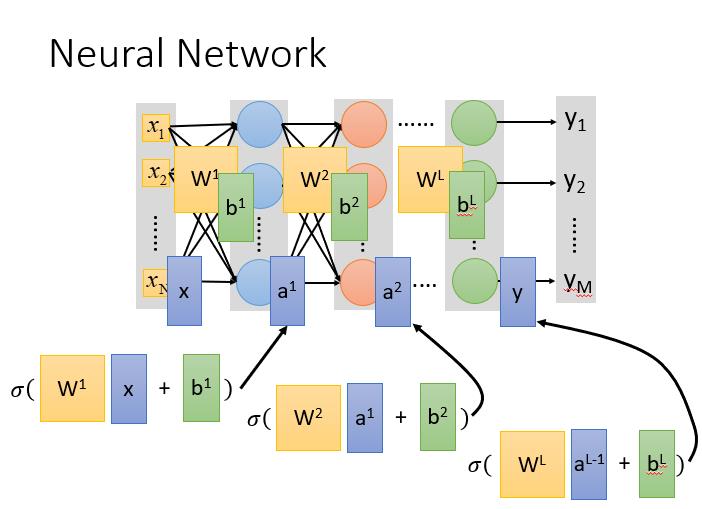
网络的计算方法就像是嵌套,所以整个神经网络运算就相当于一连串的矩阵运算。

从结构上看每一层的计算都是一样的,也就是用计算机进行并行矩阵运算。这样写成矩阵运算的好处是,你可以使用GPU加速,GPU核心多,可以并行做大量的矩阵运算。

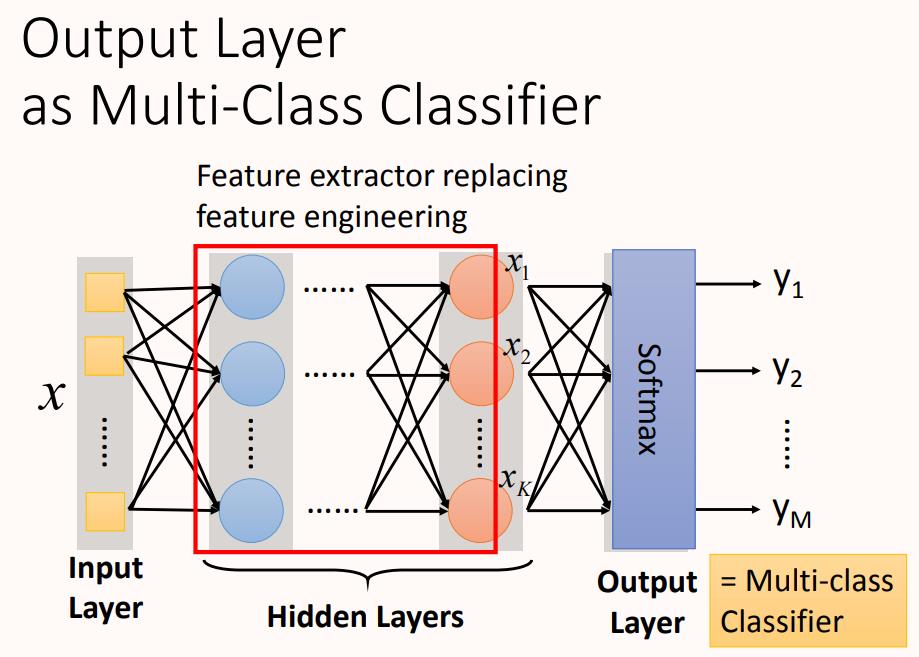
神经网络的本质:通过隐藏层进行特征转换
隐藏层可以看作是对网络输入层输入特征进行特征处理,在最后一层隐藏层进行输出,这时的输出可以看作一组全新的特征,将其输出给输出层,输出层对这组全新的特征进行分类。
举例:手写数字识别
举一个手写数字体识别的例子:
输入:一个16*16=256维的向量,每个pixel对应一个dimension,有颜色用(ink)用1表示,没有颜色(no ink)用0表示,将图片展平为一个256维的向量作为网络输入。
输出:10个维度,每个维度代表一个数字的置信度(可理解为是该数字的概率有多大)
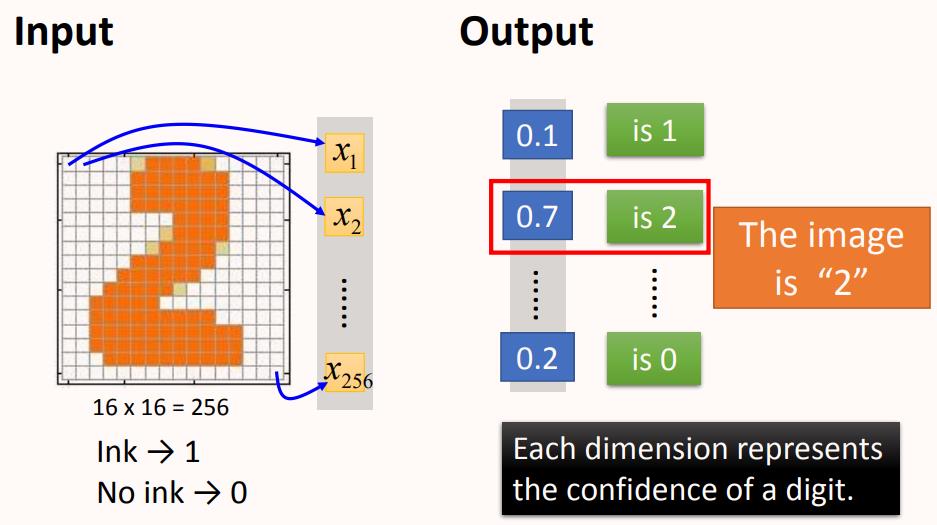
从输出结果来看,每一个维度对应输出一个数字,代表模型输出为当前分类数字的概率。说明这张图片是2的可能性就是最大的。
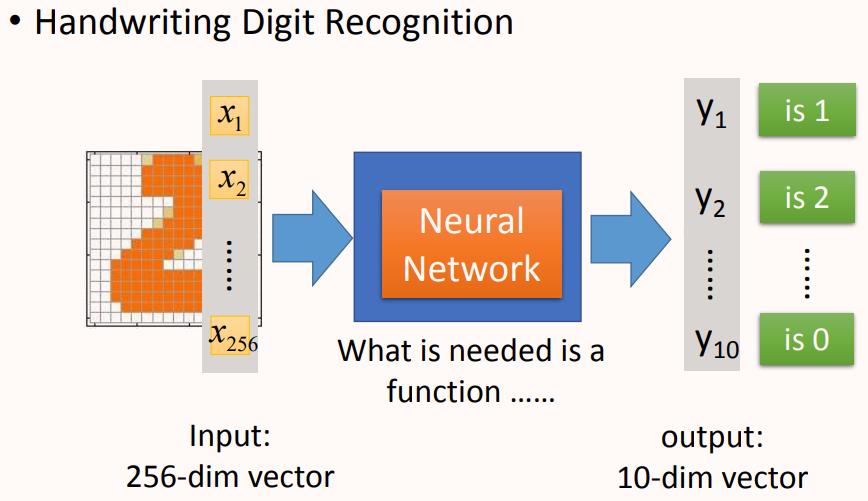
在这个问题中,唯一确定的就是,输入是256维的向量,输出是10维的向量,我们所需要找的函数就是输入和输出之间的神经网络这个函数。

从上图看神经网络的结构决定了函数集(function set),通常来讲函数集中的函数越多越复杂,网络的表达空间就越大,越能handle复杂的模式,所以说网络结构(network structured)很关键。
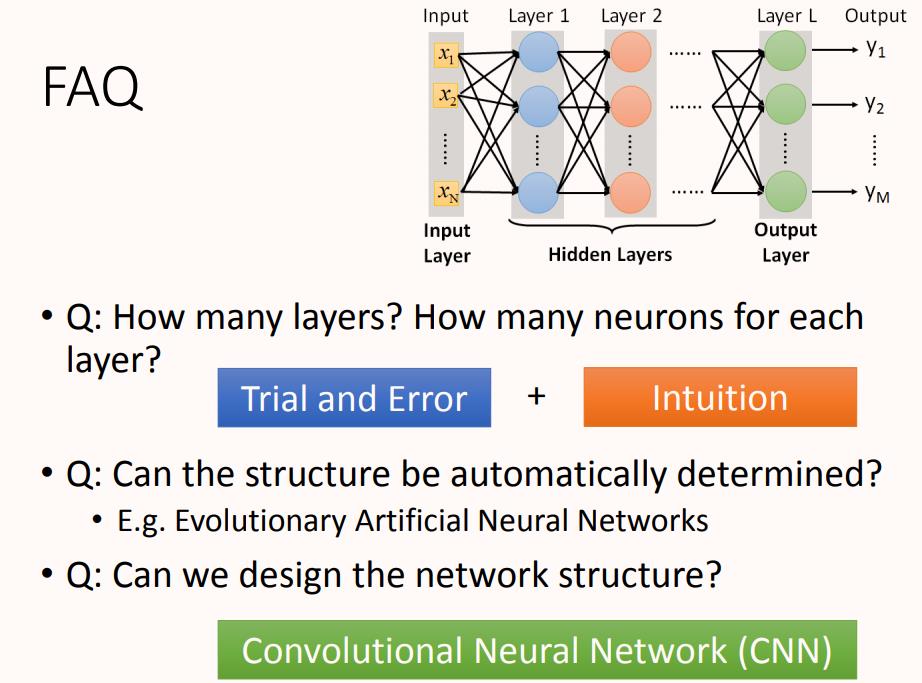
接下来有几个问题:
多少层?每层有多少神经元?这个问我们需要用尝试加上直觉的方法来进行调试。对于有些机器学习相关的问题,我们一般用特征工程来提取特征,但是对于深度学习,我们只需要设计神经网络模型来进行就可以了。对于语音识别和影像识别,深度学习是个好的方法,因为特征工程提取特征并不容易。
结构可以自动确定吗?有很多设计方法可以让机器自动找到神经网络的结构的,比如进化人工神经网络(Evolutionary Artificial Neural Networks)但是这些方法并不是很普及 。
我们可以设计网络结构吗?可以的,比如 CNN卷积神经网络(Convolutional Neural Network )
Step2:模型评估
02

损失示例
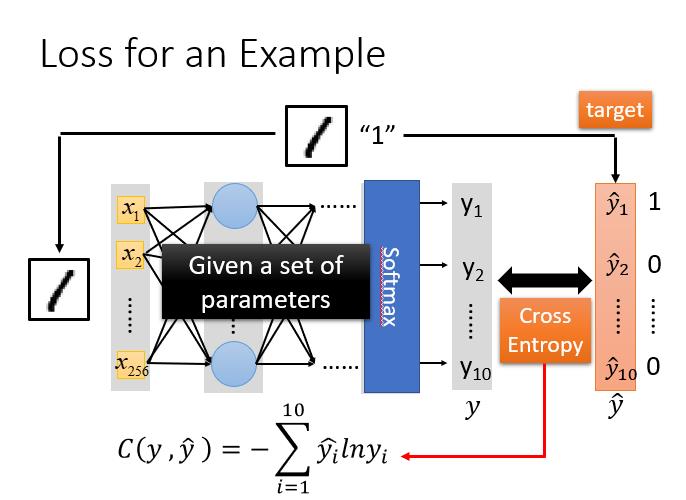
对于模型的评估,我们一般采用损失函数来反应模型的优劣,所以对于神经网络来说,我们可以采用交叉熵(cross entropy)函数来对 ???? 和 ????̂ 的损失进行计算,接下来我们就通过调整参数,让交叉熵越小越好。
总体损失
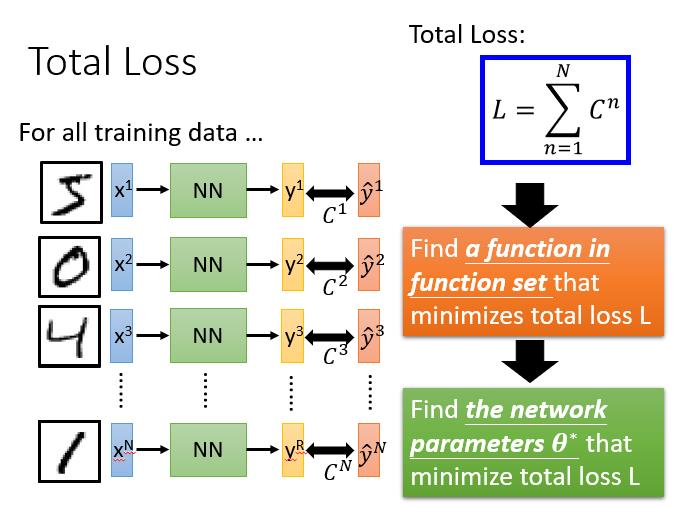
对于损失,我们不单单要计算一笔数据的,而是要计算整体所有训练数据的损失,然后把所有的训练数据的损失都加起来,得到一个总体损失????。接下来就是在functon set里面找到一组函数能最小化这个总体损失????,或者是找一组神经网络的参数????,来最小化总体损失。
Step3:选择最优函数
03

如何找到最优的函数和最好的一组参数?
——使用梯度下降。具体流程:????是一组包含权重和偏差的参数集合,随机找一个初始值,接下来计算一下每个参数对应的偏微分,得到的一个偏微分的集合∇????就是梯度,有了这些偏微分,我们就可以更新梯度得到新的参数,这样不断反复进行,就能得到一组参数使得损失函数的值最小。


反向传播
在神经网络训练中,我们需要将计算得到的损失向前传递,以计算各个神经元连接的权重对损失的影响大小,这里用到的方法就是反向传播。我们可以用很多框架来进行计算损失,比如说TensorFlow,Pytorch,theano等。

思考题
为什么要用深度学习,深层架构带来哪些好处?那是不是隐藏层越多越好?
隐藏层越多越好?
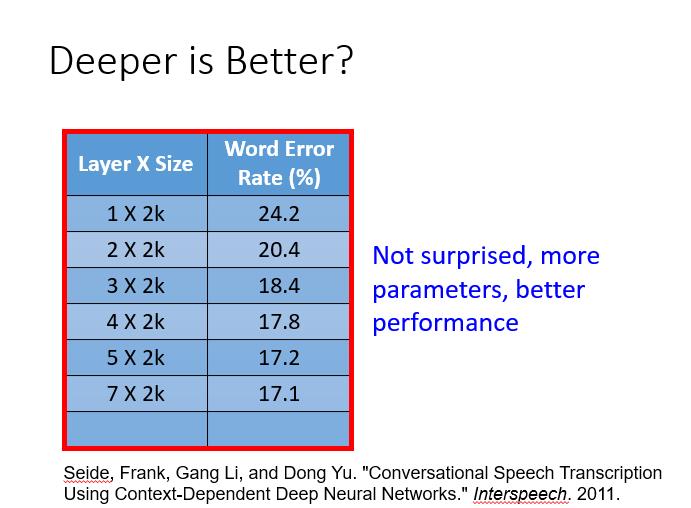
从图中展示的结果看,毫无疑问,理论上网络的层次越深效果越好,但现实中是这样吗?
普遍性定理

参数更多的模型拟合数据效果更好是很正常的。
有一个通用的理论:对于任何一个连续的函数,都可以用足够多的神经元来表示。那为什么我们还需要深度(Deep)神经网络结构呢,是不是直接用一层包含很多神经元的网络(Fat)来表示就可以了?
以上所有配图都为李宏毅机器学习视频截图


往
期
回
顾
新闻
大赛
技术
新闻

分享

点收藏

点点赞

点在看
以上是关于深度学习的三个主要步骤!的主要内容,如果未能解决你的问题,请参考以下文章