毕设--基于深度学习的人脸识别(详细步骤+代码)
Posted S-Tatum
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了毕设--基于深度学习的人脸识别(详细步骤+代码)相关的知识,希望对你有一定的参考价值。
最近闲来无事,想写一个本人毕设基于深度学习的人脸识别文章。我主要利用两个不同的神经网络进行实现,分别是一个简单三层的卷积神经网络和结构复杂的VGG16神经网络,并比对了两种网络训练出的模型的识别效果。从最终的结果来看,与预想的一样结构更复杂的VGG16的效果更胜一筹。下面我就来具体介绍一下其实现过程。
(鉴于很多小伙伴私聊我对这个项目感兴趣,我将代码链接附在评论区了,有需要的小伙伴请自取,觉得有用的话记得点赞哦,栓Q~~~)
接下来我将从以下的顺序来进行讲解:
环境配置
人脸检测部分
训练模型部分
人脸识别部分
1. 环境配置
①Python3.6 (尽管现在的 python 以经更新到了 3.9 版本了,但是由于 tensorflow 框架和 Anaconda 的需求这里还是选择 3.6 版本) ②opencv (opencv_python-4.4.0-cp36-cp36m-win_amd64,这里面版本号没有具体限制, 但是必须要支持 python3.6) ③scipy1.2.0(这个一定要注意呀,使用pip install scipy安装这个包的时候,一般都会安装1.3+的版本,在我这个程序里面就会报错了,因为我是使用了1.2版本里面的方法,在1.3版本里面该方法舍弃了) ④tensorflow1.9 ⑤keras2.2.0 ⑥sklearn(scikit_learn-0.24.1 版本) ⑦tkinder(没有具体要求,此设计使用的最新版)对了还有就是在安装这些库的时候,如果是使用pip install的方法,建议就都使用这个方法,不然使用不同方法安装到时就会报错(一条来自踩坑者的忠告哈哈),配置大概是这些了,可能有的没写出来,可能就需要大家踩一些坑配置了(此处是不是要啪啪打脸了啊)
2. 人脸检测
此部分主要采用的是opencv来调用摄像头并进行图像处理,然后使用基于级联分类器+haar特征的方法进行人脸检测。opencv使用起来非常方便,这里使用到的函数很少,也就普通的读取图片,灰度转换,显示图像,简单的编辑图像罢了。
1)读取图片
只需要给出待操作的图片的路径即可。
import cv2
image = cv2.imread(imagepath)
2)灰度转换
灰度转换的作用就是:转换成灰度的图片的计算强度得以降低。因为现在的彩色图片都是三通道的数据,不做任何处理,数据量会很大,对于我们学生用的机子来说hold不住。
import cv2
gray = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
灰色图片大概就是这样的。
3)画图
opencv 的强大之处的一个体现就是其可以对图片进行任意编辑,处理。
下面的这个函数最后一个参数指定的就是画笔的大小。其实就是要把检测到的人脸边框给描出来。
import cv2
cv2.rectangle(image,(x,y),(x+w,y+w),(0,255,0),2)4)显示图像
编辑完的图像要么直接的被显示出来,要么就保存到物理的存储介质。
import cv2
cv2.imshow("Image Title",image)
5)获取人脸识别训练数据
看似复杂,其实就是对于人脸特征的一些描述,这样opencv在读取完数据后很据训练中的样品数据,就可以感知读取到的图片上的特征,进而对图片进行人脸识别。
import cv2
face_cascade = cv2.CascadeClassifier(r'./haarcascade_frontalface_default.xml')
里面的xml文件非常关键,可以说是这个模型的核心了,就是靠它才能获取到人脸数据的。它是opencv在GitHub上共享出来的具有普适的训练好的数据。我们可以直接的拿来使用。
6)探测人脸
说白了,就是根据训练的数据来对新图片进行识别的过程。
import cv2
# 探测图片中的人脸
faces = face_cascade.detectMultiScale(
gray,
scaleFactor = 1.15,
minNeighbors = 5,
minSize = (5,5),
flags = cv2.cv.CV_HAAR_SCALE_IMAGE
)
我们可以随意的指定里面参数的值,来达到不同精度下的识别。返回值就是opencv对图片的探测结果的体现。
处理人脸探测的结果
结束了刚才的人脸探测,我们就可以拿到返回值来做进一步的处理了。但这也不是说会多么的复杂,无非添加点特征值罢了。
import cv2
print "发现0个人脸!".format(len(faces))
for(x,y,w,h) in faces:
cv2.rectangle(image,(x,y),(x+w,y+w),(0,255,0),2)
以上就介绍完了一些必备函数,包括人脸检测的函数。那我们就是要来讲这个模型了,讲模型其实很好讲,首先获取训练数据,然后写好模型训练,最后检测效果即可。按照这个顺序来,我们先讲讲如何来收集人脸数据。
我们只要收集两个人的图片即可,考虑到大家的笔记本电脑配置,每个人只要收集几百张图片即可。文件名记为get_face.py,代码如下:
def CatchPICFromVideo(window_name, camera_idx, catch_pic_num, path_name):
cv2.namedWindow(window_name)
# 视频来源,可以来自一段已存好的视频,也可以直接来自USB摄像头
cap = cv2.VideoCapture(camera_idx)
# 告诉OpenCV使用人脸识别分类器
data_path = "haarcascade_frontalface_default.xml"
classfier = cv2.CascadeClassifier(data_path)
# 识别出人脸后要画的边框的颜色,RGB格式
color = (0, 255, 0)
num = 0
while cap.isOpened():
ok, frame = cap.read() # 读取一帧数据
if not ok:
break
grey = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # 将当前桢图像转换成灰度图像
# 人脸检测,1.2和2分别为图片缩放比例和需要检测的有效点数
faceRects = classfier.detectMultiScale(grey, scaleFactor=1.2, minNeighbors=3, minSize=(32, 32))
if len(faceRects) > 0: # 大于0则检测到人脸
for faceRect in faceRects: # 单独框出每一张人脸
x, y, w, h = faceRect
# 将当前帧保存为图片
img_name = '%s/%d.jpg ' %(path_name, num)
image = frame[y - 10: y + h + 10, x - 10: x + w + 10]
cv2.imwrite(img_name, image)
num += 1
if num > catch_pic_num: # 如果超过指定最大保存数量退出循环
break
# 画出矩形框
cv2.rectangle(frame, (x - 10, y - 10), (x + w + 10, y + h + 10), color, 2)
# 显示当前捕捉到了多少人脸图片
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(frame ,'num:%d' % (num) ,(x + 30, y + 30), font, 1, (255 ,0 ,255) ,4)
# 超过指定最大保存数量结束程序
if num > catch_pic_num:
break
# 显示图像
cv2.imshow(window_name, frame)
c = cv2.waitKey(10)
if c & 0xFF == ord('q'):
break
# 释放摄像头并销毁所有窗口
cap.release()
cv2.destroyAllWindows()
3. 训练模型
数据拿到了,接下来就是要写模型训练了,我分别用了两个模型。下面的模型是采用了3个卷积操作+1个全连接操作实现的,如果是VGG16的话只需换以下部分即可,其它部分代码一样。
模型代码如下:
def build_model(self, dataset, nb_classes=2):
# 构建一个空的网络模型,它是一个线性堆叠模型,各神经网络层会被顺序添加,专业名称为序贯模型或线性堆叠模型
self.model = Sequential()
# 以下代码将顺序添加CNN网络需要的各层,一个add就是一个网络层
self.model.add(Convolution2D(32, 3, 3, border_mode='same',
input_shape=dataset.input_shape)) # 1 2维卷积层
self.model.add(Activation('relu')) # 2 激活函数层
self.model.add(MaxPooling2D(pool_size=(2, 2))) # 5 池化层
self.model.add(Dropout(0.25)) # 6 Dropout层
self.model.add(Convolution2D(64, 3, 3, border_mode='same')) # 7 2维卷积层
self.model.add(Activation('relu')) # 8 激活函数层
self.model.add(MaxPooling2D(pool_size=(2, 2))) # 11 池化层
self.model.add(Dropout(0.25)) # 12 Dropout层
self.model.add(Flatten()) # 13 Flatten层
self.model.add(Dense(512)) # 14 Dense层,又被称作全连接层
self.model.add(Activation('relu')) # 15 激活函数层
self.model.add(Dropout(0.5)) # 16 Dropout层
self.model.add(Dense(nb_classes)) # 17 Dense层
self.model.add(Activation('softmax')) # 18 分类层,输出最终结果
# 输出模型概况
self.model.summary()
因为是用keras写的,所以看起来比较简洁。
训练模型的函数也很简洁
sgd = SGD(lr=0.01, decay=1e-6,
momentum=0.9, nesterov=True) # 采用SGD+momentum的优化器进行训练,首先生成一个优化器对象
self.model.compile(loss='categorical_crossentropy',
optimizer=sgd,
metrics=['accuracy']) # 完成实际的模型配置工作
这儿再说一点,我们知道如果要判别两个人是谁,训练的时候肯定是要给两个人的照片分类的,比如A标记为0,B标记为1。此模型也是如此来训练的,在load_face.py中的load_dataset()函数里有一行代码就是如此,代码如下:
# 标注数据,'LDY'文件夹下都是我的脸部图像,全部指定为0,另外一个文件夹下是同学的,全部指定为1
labels = np.array([0 if label.endswith('LDY') else 1 for label in labels])
此文件的该处地方也是需要大家修改的,即把“LDY”改为自己文件夹的名称。
如果你要做多人识别的话,也是在这处地方做手脚的,我这儿就标记了0和1,所以大家很自然的知道我是做两人识别的,如果你要多识别一些人,就多做一些标记就行了。
最后还有一处地方需要修改,就是train.py文件的主函数部分:
# 此处文件地址是你收集的图片的文件夹地址
dataset = Dataset('D:\\PyCharm-Community\\Workplace\\Face_Recognition\\\\face_data')
dataset.load()
model = Model()
model.build_model(dataset)
model.train(dataset)
# 此处地址是你保存训练好模型的地址
model.save_model(file_path='D:\\PyCharm-Community\\Workplace\\Face_Recognition\\\\face_data\\model\\ldy_face_model.h5')
model.evaluate(dataset)
4. 人脸识别
模型训练好了,最后就可以拿照片来测试了。
文件名叫:Face_recognition.py,代码如下:
if __name__ == '__main__':
if len(sys.argv) != 1:
print("Usage:%s camera_id\\r\\n" % (sys.argv[0]))
sys.exit(0)
# 加载模型
model = Model()
model.load_model(file_path='D:\\PyCharm-Community\\Workplace\\Face_Recognition\\model\\jianxin_face_model.h5')
# 框住人脸的矩形边框颜色
color = (0, 255, 0)
# 捕获指定摄像头的实时视频流
cap = cv2.VideoCapture(0)
# 人脸识别分类器本地存储路径
cascade_path = "D:\\opencv\\\\build\\etc\\haarcascades\\haarcascade_frontalface_default.xml"
# 循环检测识别人脸
while True:
ret, frame = cap.read() # 读取一帧视频
if ret is True:
# 图像灰化,降低计算复杂度
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
else:
continue
# 使用人脸识别分类器,读入分类器
cascade = cv2.CascadeClassifier(cascade_path)
# 利用分类器识别出哪个区域为人脸
faceRects = cascade.detectMultiScale(frame_gray, scaleFactor=1.2, minNeighbors=3, minSize=(32, 32))
if len(faceRects) > 0:
for faceRect in faceRects:
x, y, w, h = faceRect
# 截取脸部图像提交给模型识别这是谁
image = frame[y - 10: y + h + 10, x - 10: x + w + 10]
faceID = model.face_predict(image)
print("faceID", faceID)
# 如果是“我”
if faceID == 0:
cv2.rectangle(frame, (x - 10, y - 10), (x + w + 10, y + h + 10), color, thickness=2)
# 文字提示是谁
cv2.putText(frame, 'Chengjianxin',
(x + 30, y + 30), # 坐标
cv2.FONT_HERSHEY_SIMPLEX, # 字体
1, # 字号
(255, 0, 255), # 颜色
2) # 字的线宽
else:
cv2.rectangle(frame, (x - 10, y - 10), (x + w + 10, y + h + 10), color, thickness=2)
cv2.putText(frame, 'Nobody',
(x + 30, y + 30), # 坐标
cv2.FONT_HERSHEY_SIMPLEX, # 字体
2, # 字号
(255, 0, 0), # 颜色
2) # 字的线宽
pass
cv2.imshow("Face Recognition", frame)
# 等待10毫秒看是否有按键输入
k = cv2.waitKey(10)
# 如果输入q则退出循环
if k & 0xFF == ord('q'):
break
# 释放摄像头并销毁所有窗口
cap.release()
cv2.destroyAllWindows()
其中有3处地方需要修改
# 加载模型
model = Model()
model.load_model(file_path='D:\\PyCharm-Community\\Workplace\\Face_Recognition\\model\\jianxin_face_model.h5')
模型地址改成你自己的。
# 人脸识别分类器本地存储路径
cascade_path = "D:\\opencv\\\\build\\etc\\haarcascades\\haarcascade_frontalface_default.xml"
这个xml文件地址也改成你自己的,前面的get_face.py也是这样。
# 如果是“我”
if faceID == 0:
cv2.rectangle(frame, (x - 10, y - 10), (x + w + 10, y + h + 10), color, thickness=2)
# 文字提示是谁
cv2.putText(frame, 'Chengjianxin',
(x + 30, y + 30), # 坐标
cv2.FONT_HERSHEY_SIMPLEX, # 字体
1, # 字号
(255, 0, 255), # 颜色
2) # 字的线宽
else:
cv2.rectangle(frame, (x - 10, y - 10), (x + w + 10, y + h + 10), color, thickness=2)
cv2.putText(frame, 'Nobody',
(x + 30, y + 30), # 坐标
cv2.FONT_HERSHEY_SIMPLEX, # 字体
2, # 字号
(255, 0, 0), # 颜色
2) # 字的线宽
这里面的文字提示改成你自己的就行了。
毕业设计-基于深度学习的人脸识别方法
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导: https://blog.csdn.net/qq_37340229/article/details/128243277
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯毕业设计-基于深度学习的人脸识别方法
课题背景和意义
人脸识别与虹膜识别、指纹识别、步态识别等其它生物特征识别技术相比,具有自然、便捷、用户体验友好等独特优势,因而受到了学术界和工业界的广泛关注.近年来,在深度学习技术的驱动下,人脸识别技术取得了突破性进展,在面对表情、姿态、光照、遮挡等外在干扰因素时,仍表现出较好的鲁棒性。特别地,基于深度学习的人脸识别技术已广泛应用于安防、金融、教育、交通、新零售等应用领域。人脸识别是一种依据人脸图像进行身份识别的生物特征识别技术。人脸识别 的研究始于 20 世纪 60 年代,与虹膜识别、指纹识别、步态识别等生物特征识别技术相比,人脸识别因其便捷、高效、易普及的优点成为最受关注的研究问题之一。通常,其难点在于人脸结构相似性导致不同个体之间差异不显著,而同一个体在不同表情、姿态、年龄、光照、遮挡、妆饰等干扰因素下变化显著。因而人脸识别技术需要在类内变化干扰的情况下尽可能增大类间差距以区分不同个体,其关键在于从人脸图像中提取有利于识别的特征。实现技术思路
一、人脸识别介绍
早期基于人脸几何特征的识别方法[2–4] 使用眼睛、鼻子、嘴巴等关键部位之间的关系 (如角度、距离) 构建人脸描述子,此类方法忽略了人脸纹理、外观包含的有用信息,因此,识别效果一般.基于子空间学习的识别方法如 Eigenfaces、Fisherfaces,将原始数据整体映射到低维人脸子空间,这类方法很大程度上推动了人脸识别技术的发展.
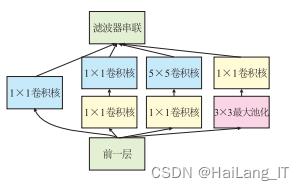
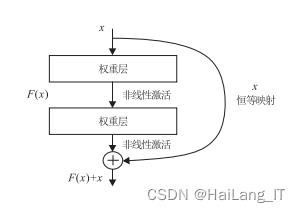
二、基于深度学习的人脸识别方法
基于深度学习的人脸识别流程主要包括人脸预处理 ( 检测、对齐、标准化、数据增强等) 、特征学习、特征比对等步骤,其中特征学习是人脸识别的关键,如何提取强判别性、强鲁棒性的特征是人脸识别的研究重点.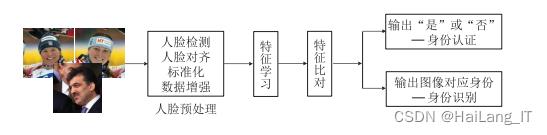

人脸识别损失函数
损失函数可以指导神经网络将人脸图像映射到不同的特征空间,选择合适的损失函数有利于在特征空间将不同类别的人脸图像区分开,提升人脸识别的精度. 1) Softmax loss Softmax loss 是一种常用于人脸图像多分类问题的损失函数. Softmax 激活函数的作用是将模型预测结果进行归一化操作,使输出结果为 [0 , 1] 区间内的概率值.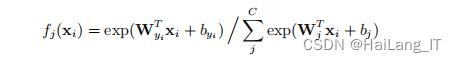

下图为两种不同损失函数对应的深度特征可视化:

特征比对
在损失函数的指导下利用海量有标记的人脸图像样本对网络参数进行有监督训练.测试阶段,将待测试的人脸图像输入训练好的神经网络提取人脸深度特征,使用最近邻分类器通过比较深度特征之间的距离进行身份识别或认证。假设人脸图像 xi 和 xj 的特征分别为 f(xi) 和 f(xj ),当特征之间的距离在预先设定的阈值 τ 范围内时,即

则认为这两幅图像来自同一个人。
人脸数据集 基于深度学习的人脸识别方法需要大量训练数据,数据集的发展也反映了人脸识别技术的发展.与早期实验室环境下采集获得的人脸数据不同,2007 年公开的 LFW数据集开启了无约束场景下人脸识别研究的新阶段,有力地推动了无约束人脸识别的发展.随后不断有更大、更多样化的人脸数据集被发布。 评级标准 1)身份认证 一般使用 ROC 曲线作为人脸识别方法的评价指标, ROC 曲线由两项指标确定,分别是接受率 (Ture Alarm Rate, TAR) ,误识率 (False Alarm Rate, FAR) 2) 身份识别 一般使用身份识别精度作为识别方法的评价指标,计算方式简单明了,与认证准确度类似,计算识别正确的比例即可.比较特别的是,在大规模分类问题中常使用 K 次命中率作为评价的标准,即真实标签出现在预测结果前 K 名之内,则认为预测正确。 3) 基于深度学习人脸识别方法比较 随着深度卷积神经网络的发展,目前人脸识别方法一般只使用单个网络,并且采用的网络结构以 ResNet 为主,例如 DeepVisage 、 SphereFace 、 CosFace 等.研究热点也从网络结构设计转移至损失函数的设计,例如 L-Softmax 、 NormFace 、 ArcFace 等方法将度量学习的思想引入 Softmax loss 并提升了人脸识别模型的性能。各种方法的精度比较: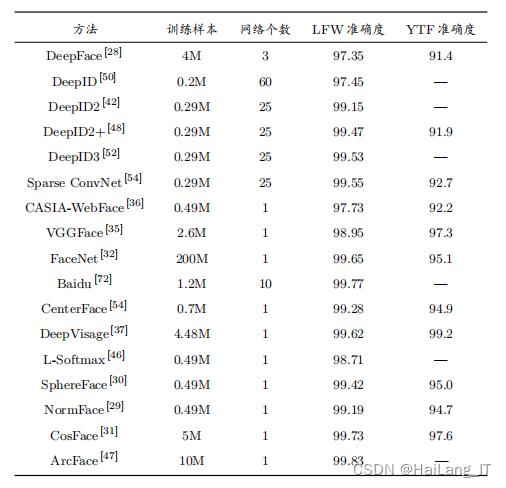
实现效果图样例
基于深度学习的人脸识别:
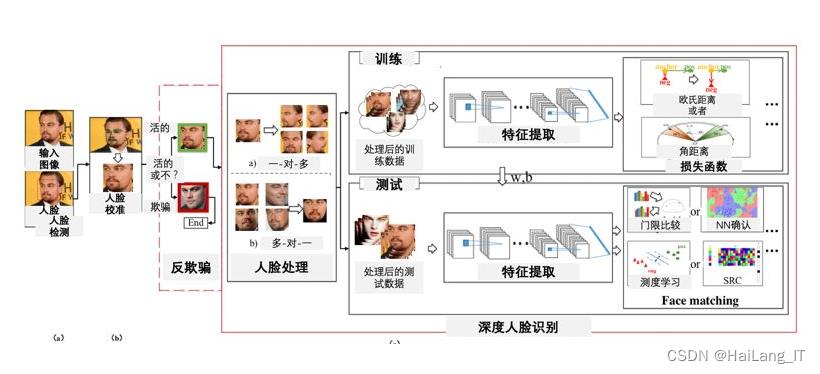 人脸识别之身份认证:
人脸识别之身份认证:

我是海浪学长,创作不易,欢迎点赞、关注、收藏、留言。
毕设帮助,疑难解答,欢迎打扰!
最后
以上是关于毕设--基于深度学习的人脸识别(详细步骤+代码)的主要内容,如果未能解决你的问题,请参考以下文章