HDFS伪分布式环境搭建
Posted JavaEdge.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS伪分布式环境搭建相关的知识,希望对你有一定的参考价值。
1 HDFS概述及设计目标
1.1 什么是HDFS:
- Hadoop实现的一个分布式文件系统(Hadoop Distributed File System),简称HDFS
- 源自于Google的GFS论文
- 论文发表于2003年,HDFS是GFS的克隆版
1.2 HDFS的设计目标:
- 非常巨大的分布式文件系统
- 运行在普通廉价的硬件上
- 易扩展、为用户提供性能不错的文件存储服务
HDFS官方文档地址
2 HDFS架构
HDFS是主/从式的架构。一个HDFS集群会有一个NameNode(简称NN),也就是命名节点,该节点作为主服务器存在(master server).
- NameNode用于管理文件系统的命名空间以及调节客户访问文件
- 此外,还会有多个DataNode(简称DN),也就是数据节点,数据节点作为从节点存在(slave server)
- 通常每一个集群中的DataNode,都会被NameNode所管理,DataNode用于存储数据。
HDFS公开了文件系统名称空间,允许用户将数据存储在文件中,就好比我们平时使用操作系统中的文件系统一样,用户无需关心底层是如何存储数据的
而在底层,一个文件会被分成一个或多个数据块,这些数据库块会被存储在一组数据节点中。在CDH中数据块的默认大小是128M,这个大小我们可以通过配置文件进行调节
在NameNode上我们可以执行文件系统的命名空间操作,如打开,关闭,重命名文件等。这也决定了数据块到数据节点的映射。
我们可以来看看HDFS的架构图
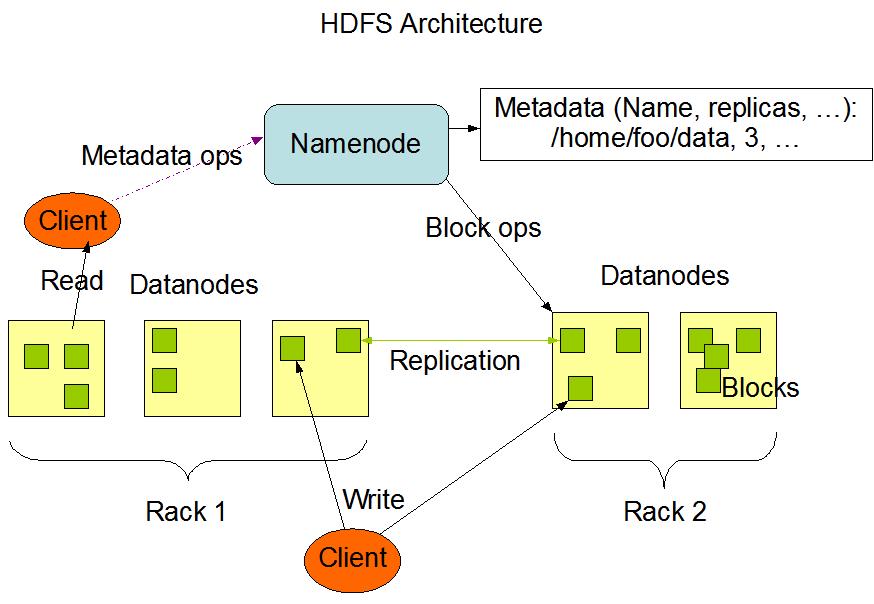
HDFS被设计为可以运行在普通的廉价机器上,而这些机器通常运行着一个Linux操作系统。HDFS是使用Java语言编写的,任何支持Java的机器都可以运行HDFS
使用高度可移植的Java语言编写的HDFS,意味着可以部署在广泛的机器上
一个典型的HDFS集群部署会有一个专门的机器只能运行NameNode,而其他集群中的机器各自运行一个DataNode实例。虽然一台机器上也可以运行多个节点,但是并不建议这么做,除非是学习环境。
总结
- HDFS是主/从式的架构,一个HDFS集群会有一个NameNode以及多个DataNode
- 一个文件会被拆分为多个数据块进行存储,默认数据块大小是128M
- 即便一个数据块大小为130M,也会被拆分为2个Block,一个大小为128M,一个大小为2M
- HDFS是使用Java编写的,使得其可以运行在安装了JDK的操作系统之上
NN
- 负责客户端请求的响应
- 负责元数据(文件的名称、副本系数、Block存放的DN)的管理
DN
- 存储用户的文件对应的数据块(Block)
- 会定期向NN发送心跳信息,汇报本身及其所有的block信息和健康状况
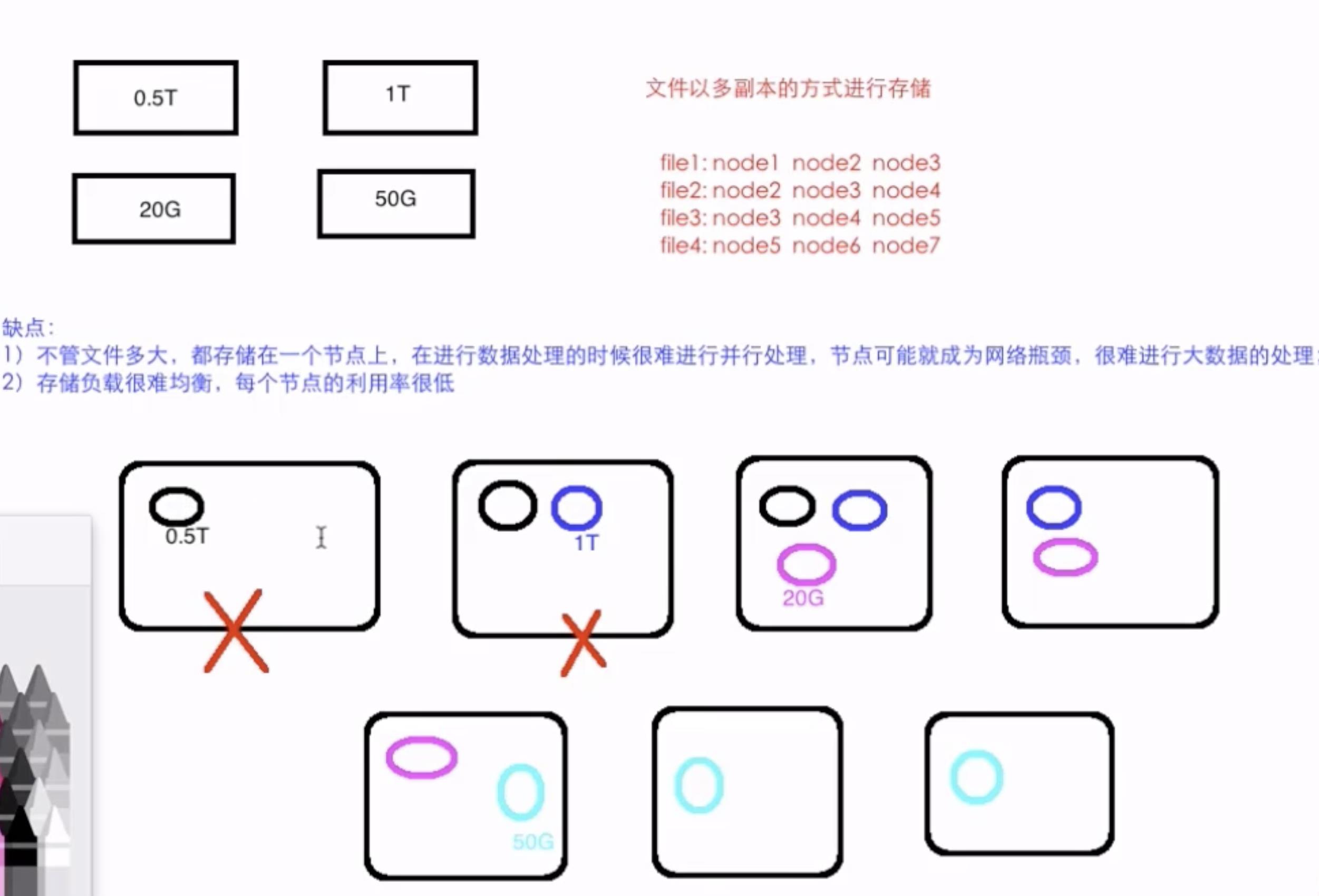
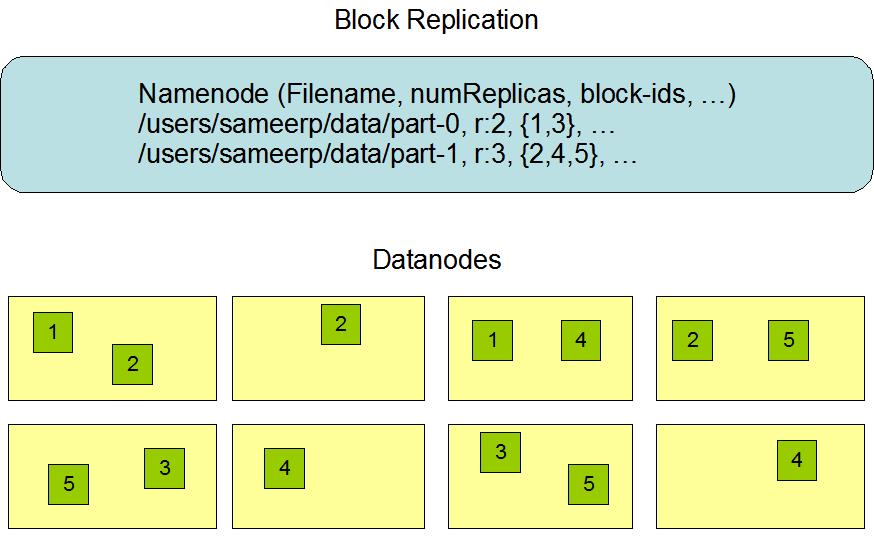
3 HDFS副本机制
在HDFS中,一个文件会被拆分为一个或多个数据块
默认情况下,每个数据块都会有三个副本
每个副本都会被存放在不同的机器上,而且每一个副本都有自己唯一的编号
- 如下图
4 HDFS 副本存放策略
NameNode节点选择一个DataNode节点去存储block副本得过程就叫做副本存放,这个过程的策略其实就是在可靠性和读写带宽间得权衡。
《Hadoop权威指南》中的默认方式:
- 第一个副本会随机选择,但是不会选择存储过满的节点。
- 第二个副本放在和第一个副本不同且随机选择的机架上。
- 第三个和第二个放在同一个机架上的不同节点上。
- 剩余的副本就完全随机节点了
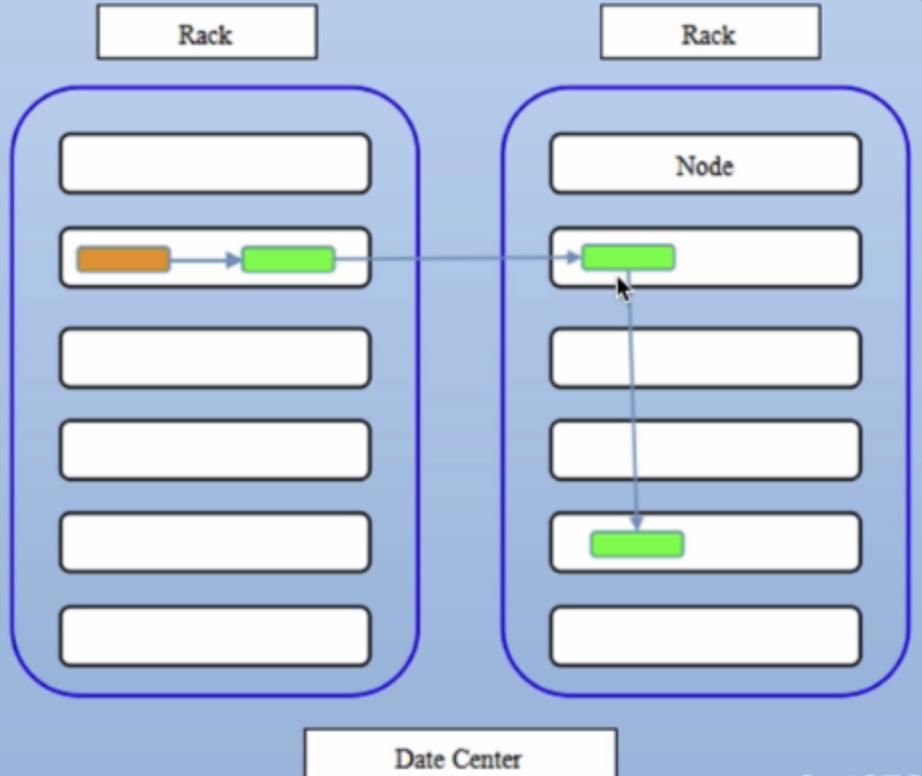
可以看出这个方案比较合理
- 可靠性:block存储在两个机架上
- 写带宽:写操作仅仅穿过一个网络交换机
- 读操作:选择其中得一个机架去读
- block分布在整个集群上
5 HDFS伪分布式环境搭建
5.1 官方安装文档地址
5.2 环境参数
- Mac OS 10.14.4
- JDK1.8
- Hadoop 2.6.0-cdh5.7.0
- ssh
- rsync
下载Hadoop 2.6.0-cdh5.7.0的tar.gz包并解压:
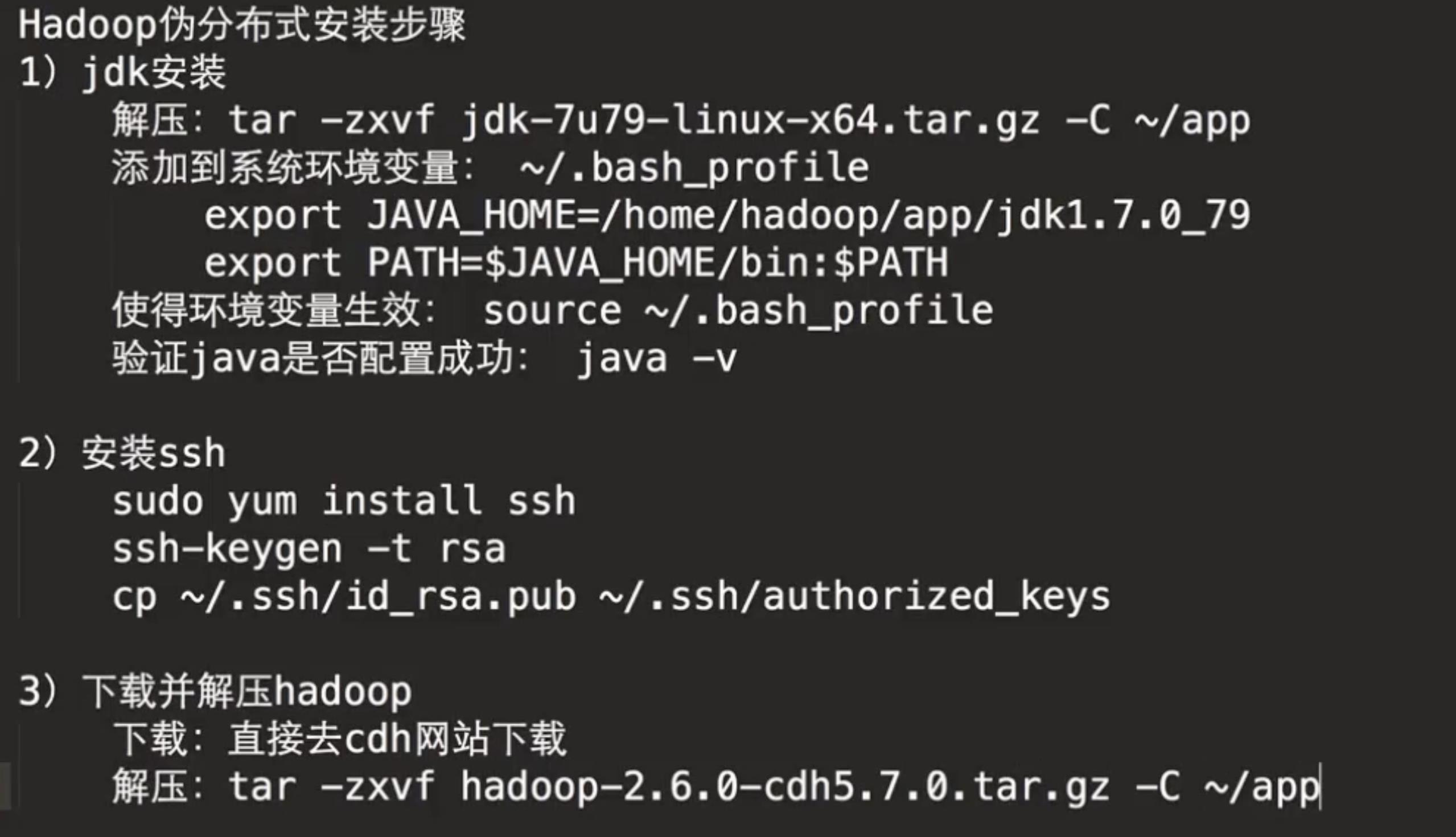
MacOS安装环境



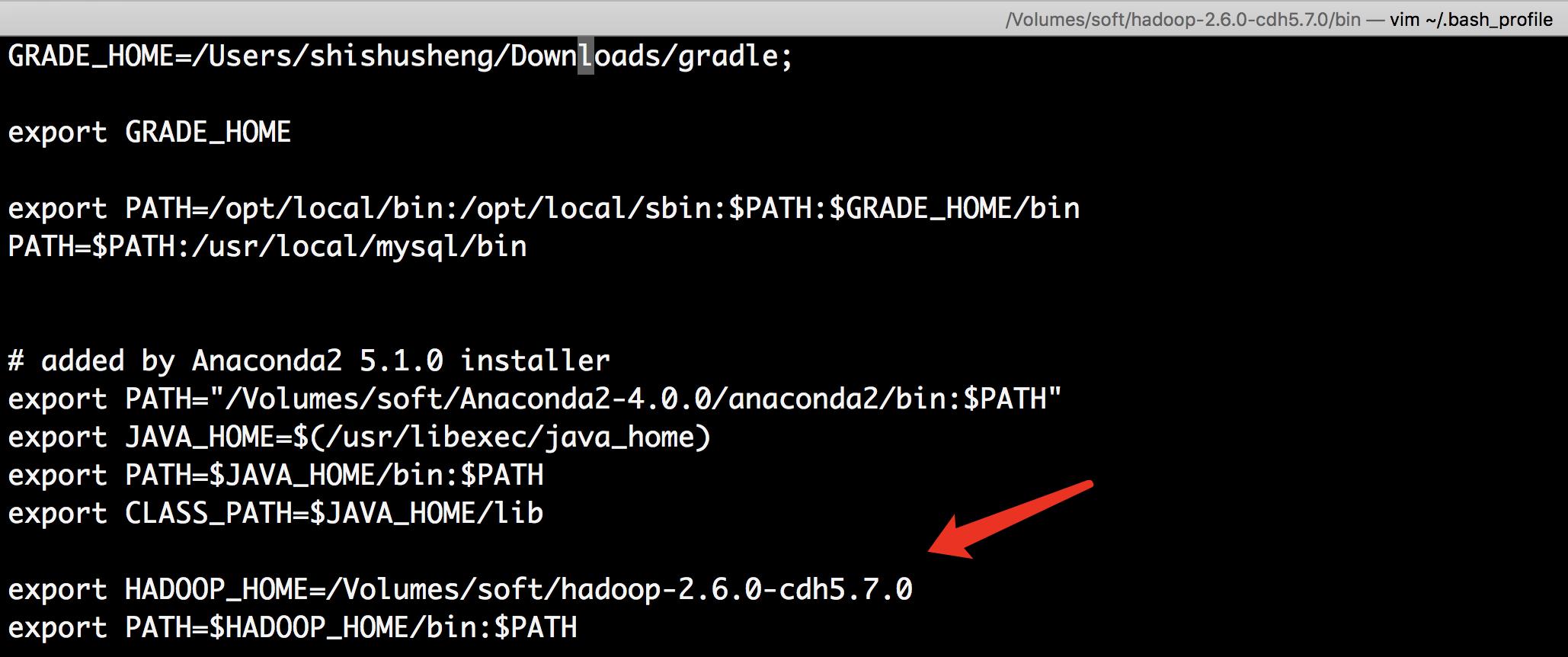
设置 JAVA_HOME
- 添加java_home到.bash_profile文件中
export JAVA_HOME=$(/usr/libexec/java_home)
export PATH=$JAVA_HOME/bin:$PATH
export CLASS_PATH=$JAVA_HOME/lib
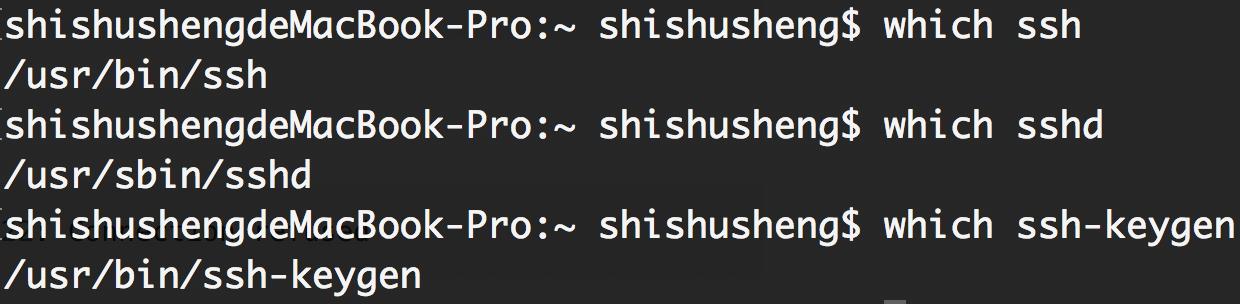
-
输入命令ssh localhost,可能遇到如下问题

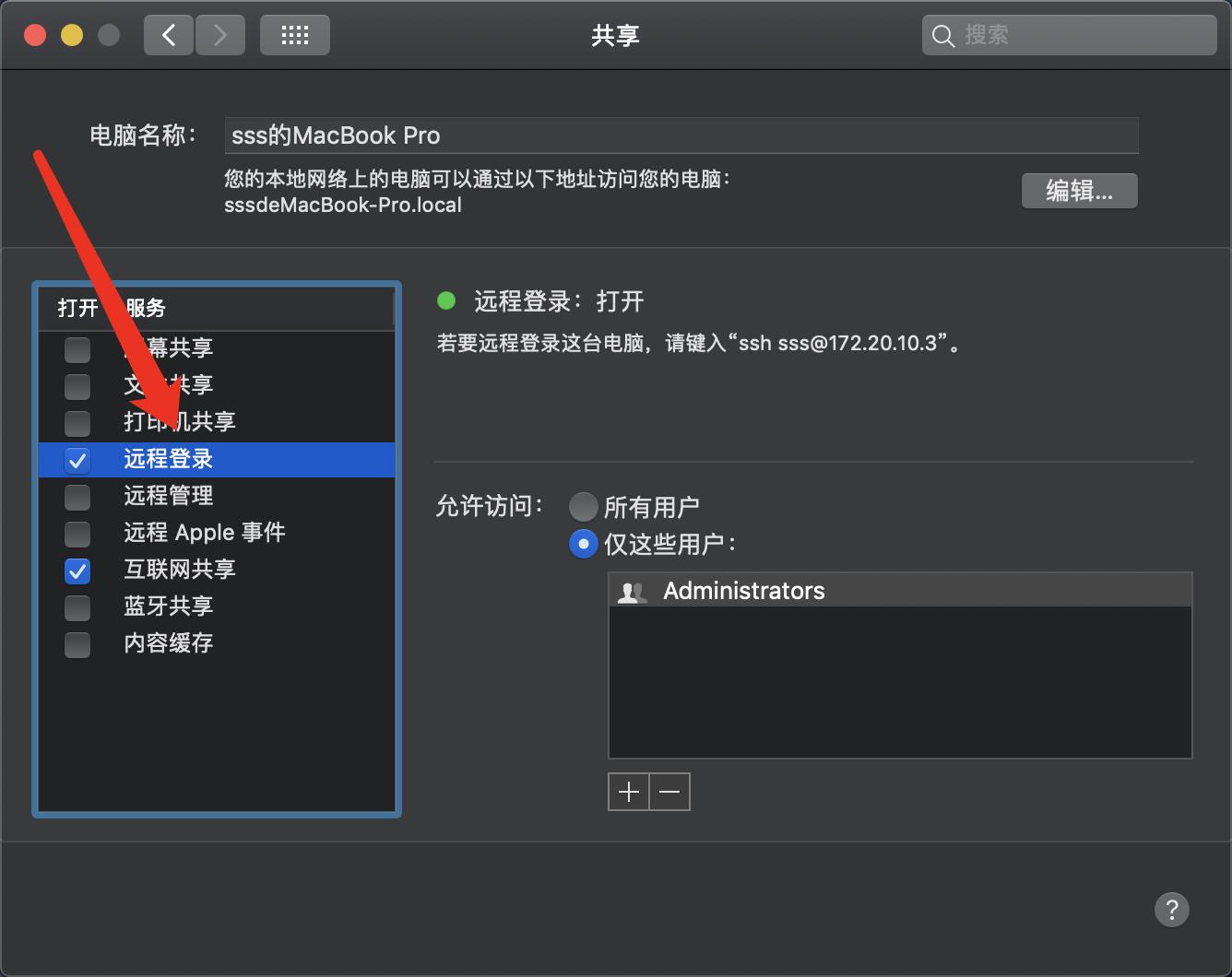
-
原因是没打开远程登录,进入系统设置->共享->远程登录打开就好
这时你再ssh localhost一下
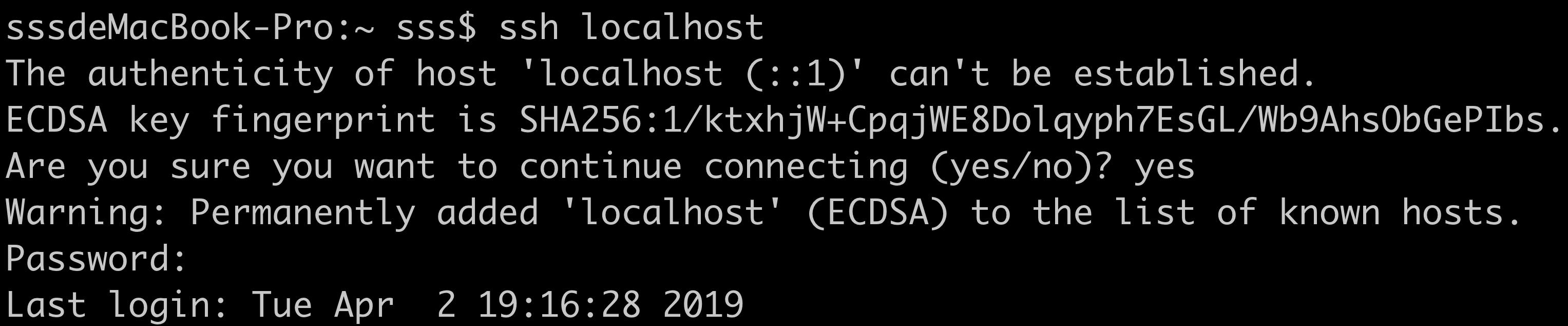
5.3 下载 Hadoop
tar -zxvf hadoop-2.6.0-cdh5.7.0.tar.gz
- 解压到doc目录,解压完后,进入到解压后的目录下,可以看到hadoop的目录结构如下
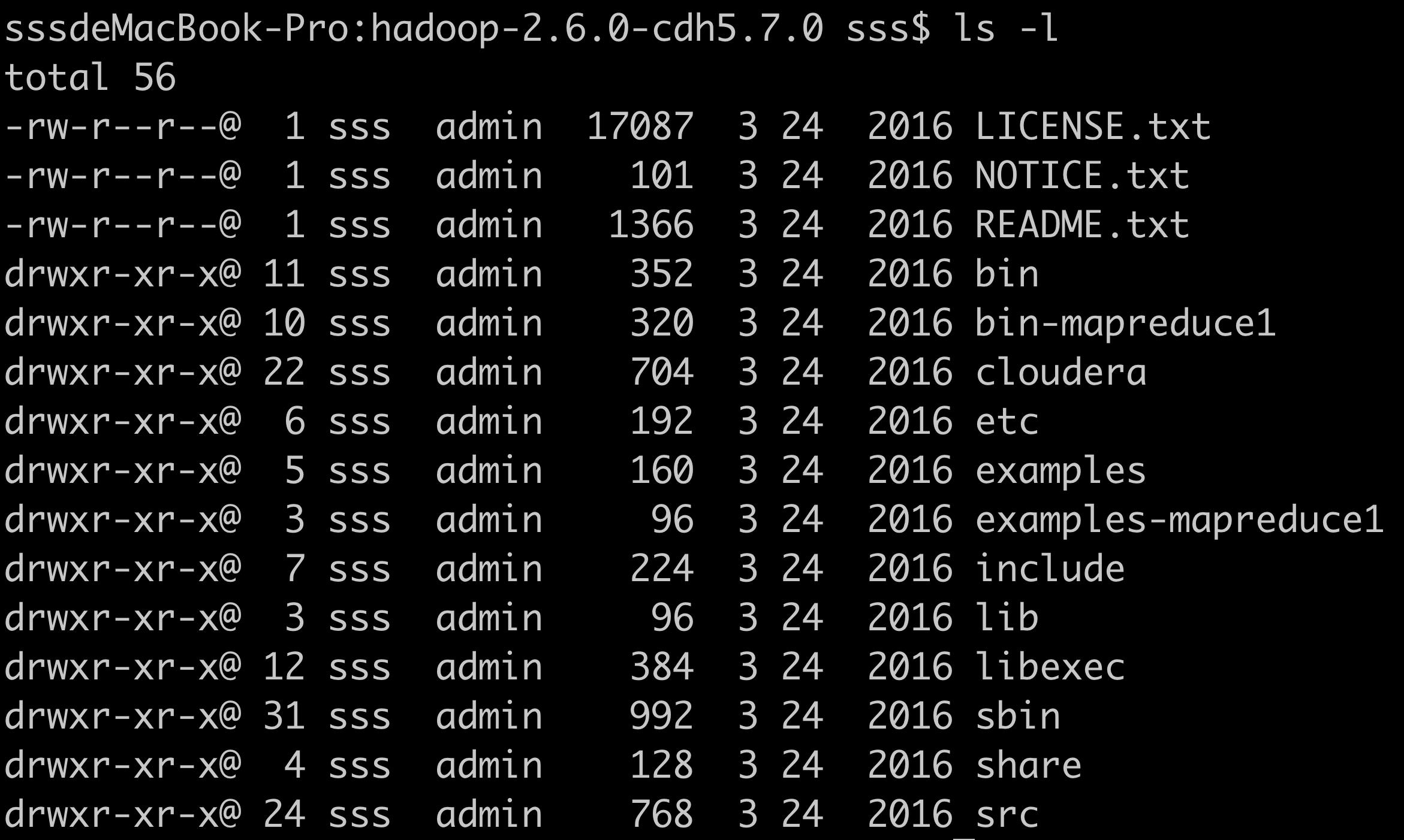
- bin目录存放可执行文件
- etc目录存放配置文件
- sbin目录下存放服务的启动命令
- share目录下存放jar包与文档
以上就算是把hadoop给安装好了,接下来就是编辑配置文件,把JAVA_HOME配置一下
cd etc/
cd hadoop
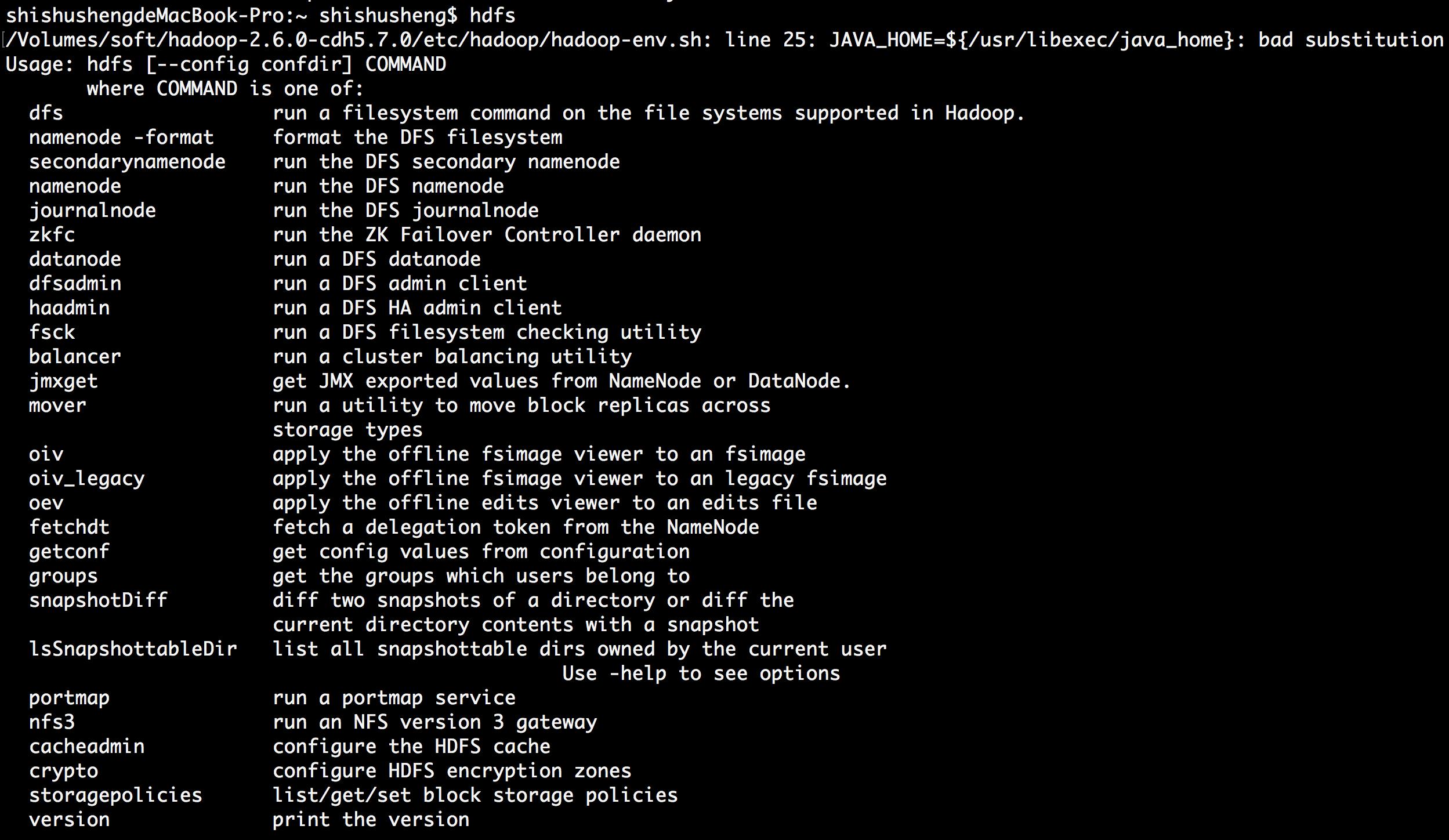
vim hadoop-env.sh
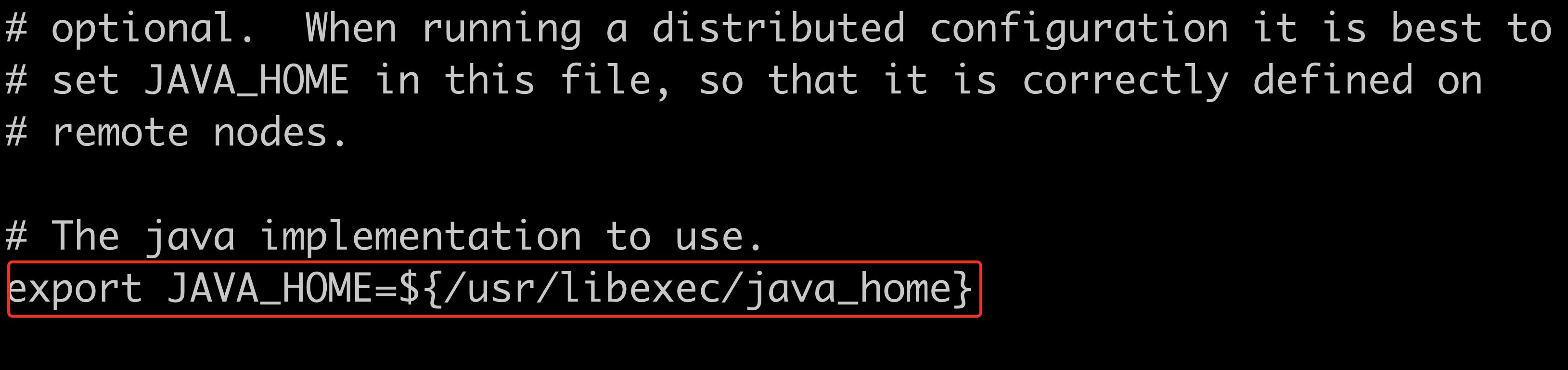
export JAVA_HOME=/usr/local/jdk1.8/ # 根据你的环境变量进行修改

- 编辑 hadoop-env.sh 文件
export JAVA_HOME=${/usr/libexec/java_home}

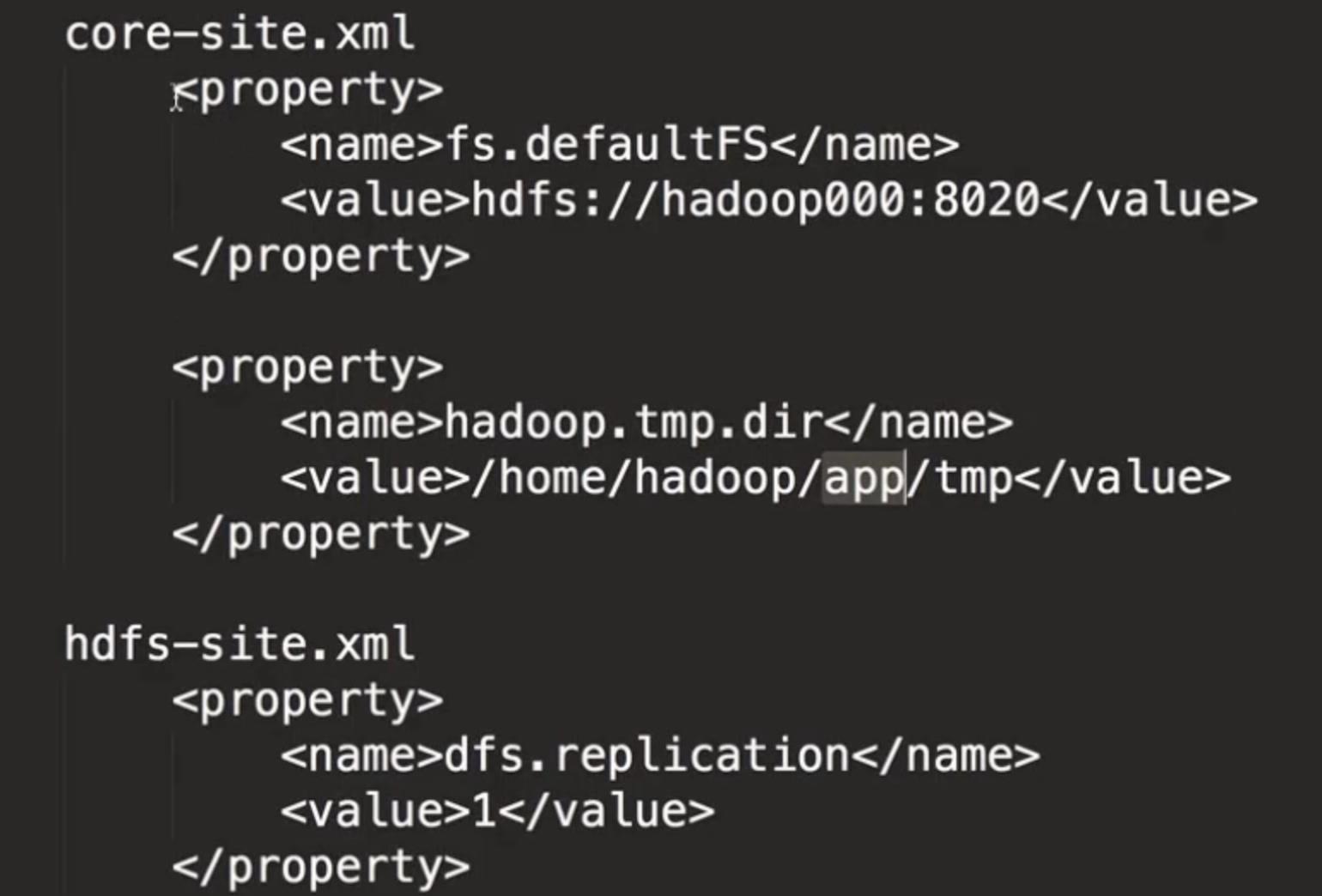
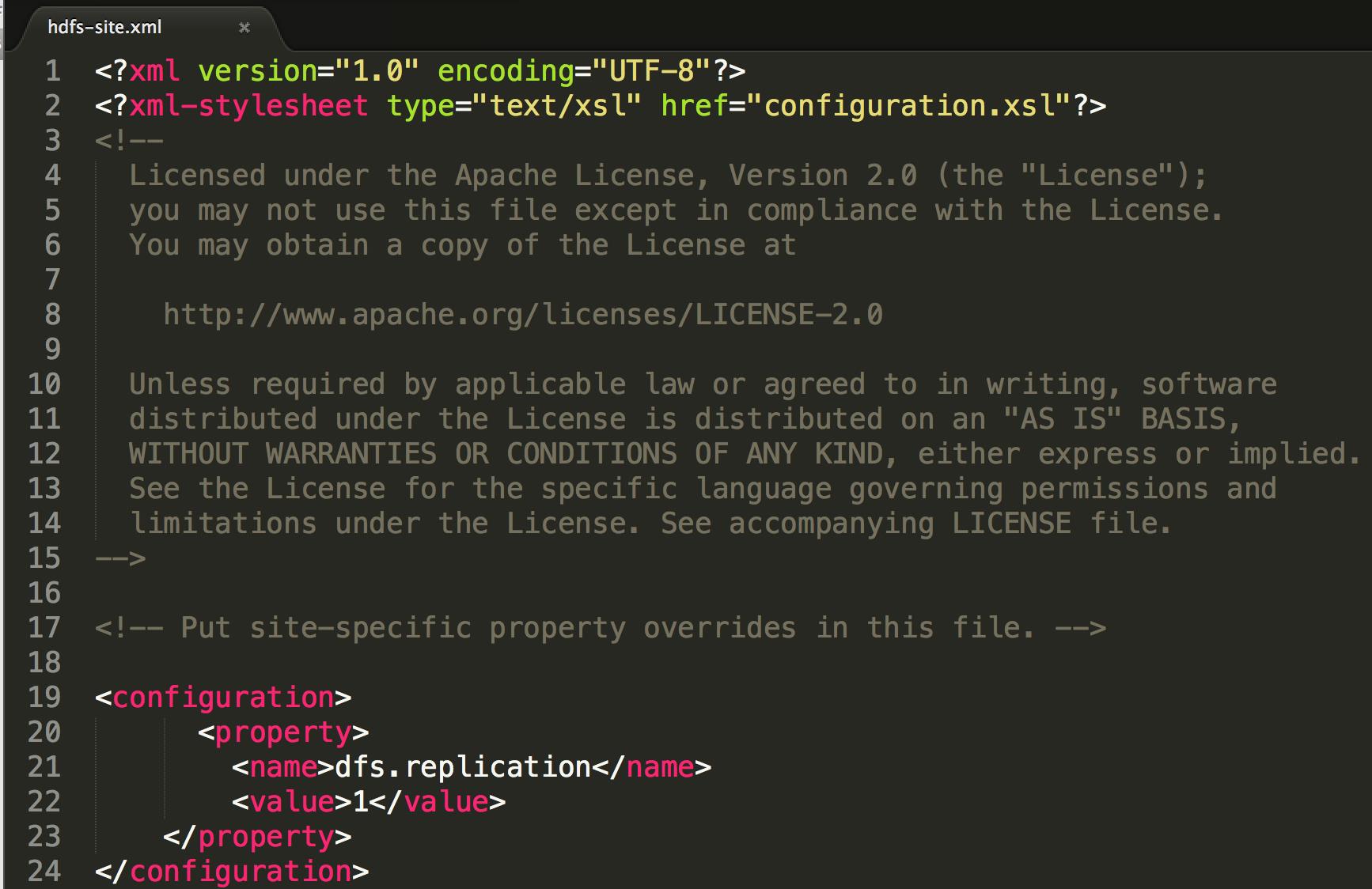
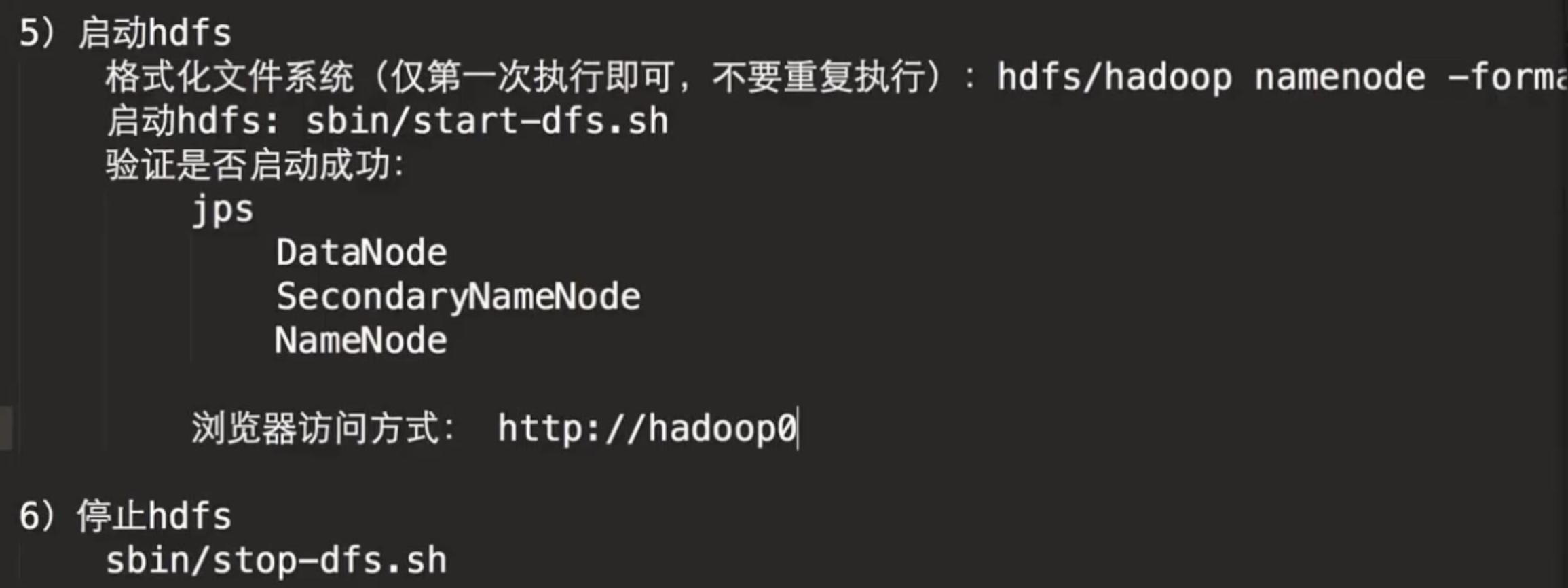
由于我们要进行的是单节点伪分布式环境的搭建,所以还需要配置两个配置文件,分别是core-site.xml以及hdfs-site.xml
Hadoop也可以在伪分布模式下的单节点上运行,其中每个Hadoop守护进程都在单独的Java进程中运行


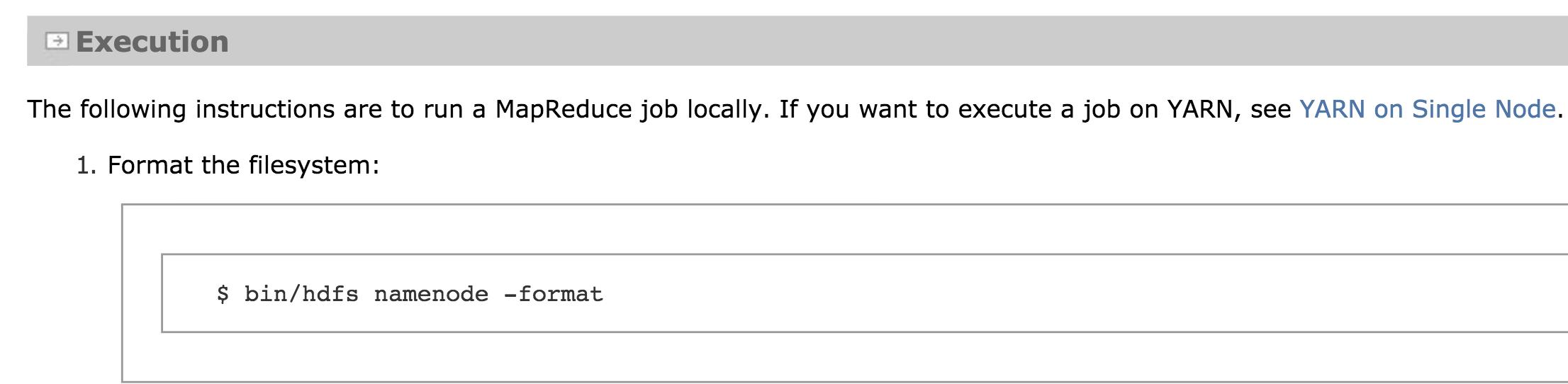
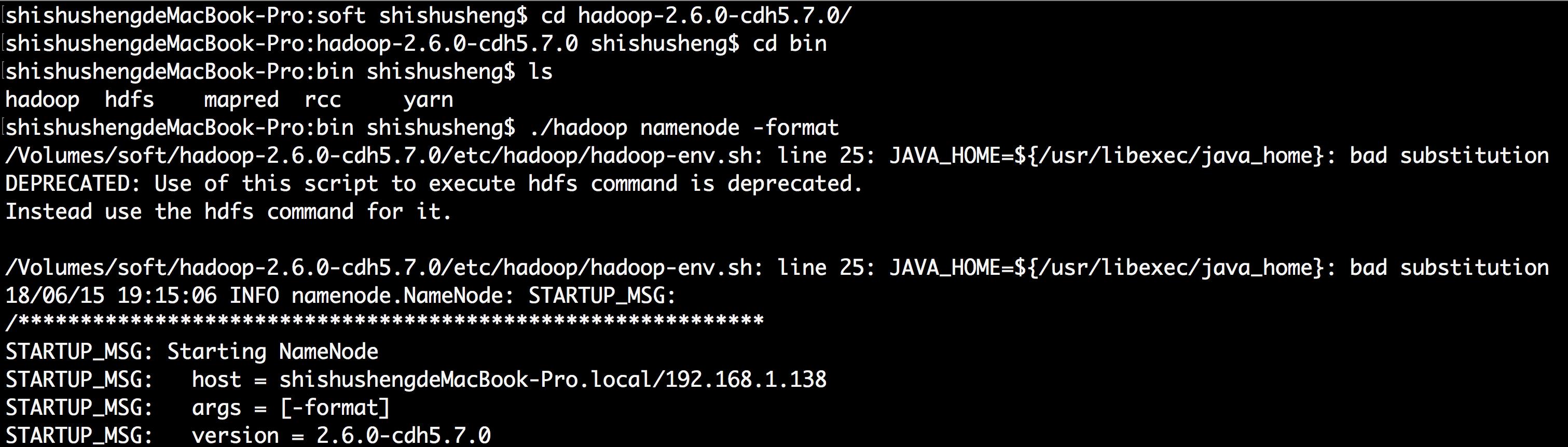
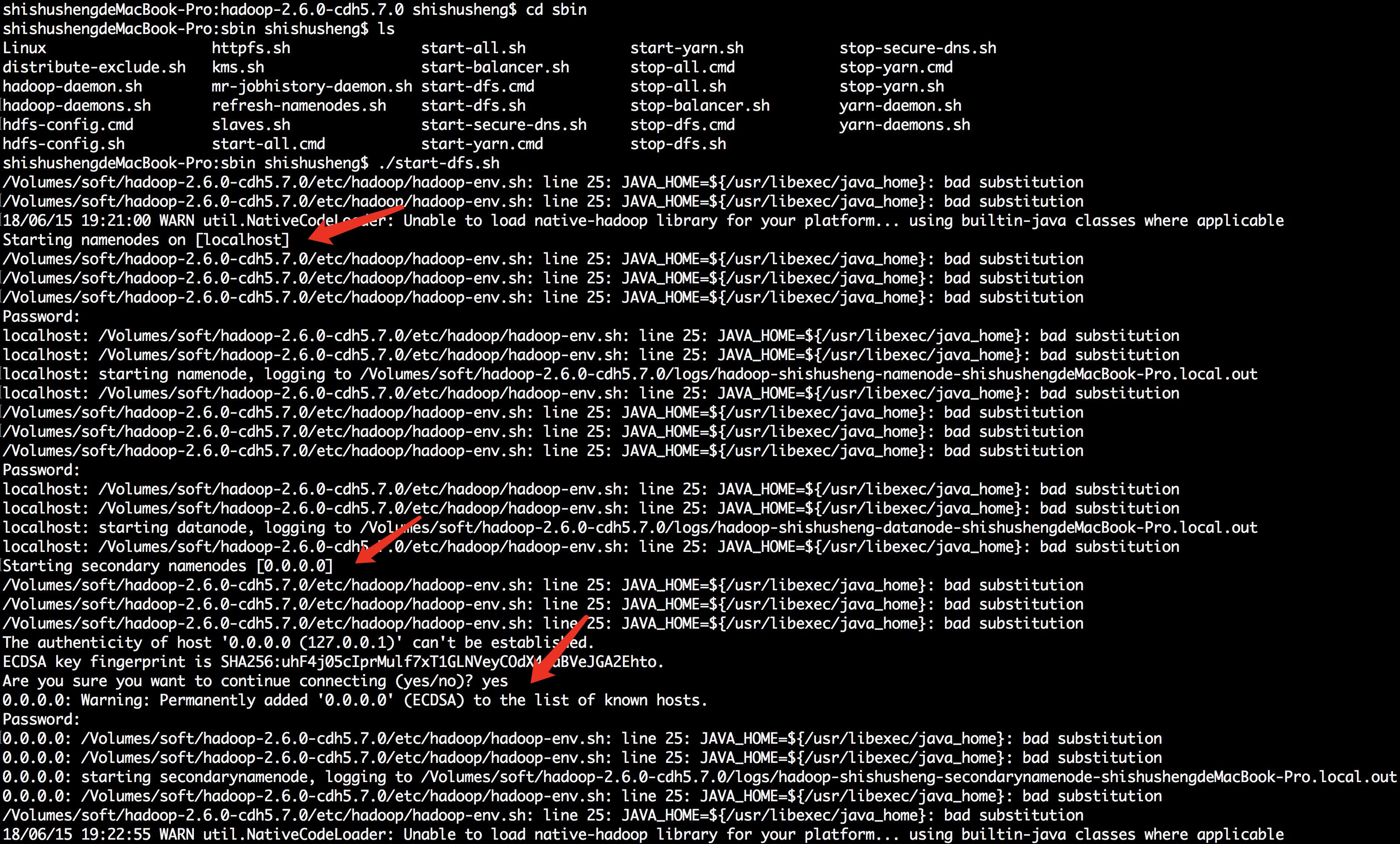
启动 hdfs


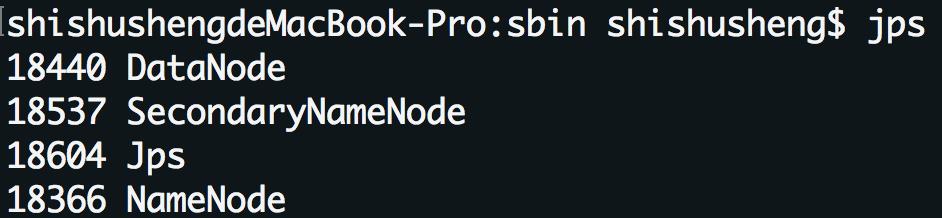
查看进程
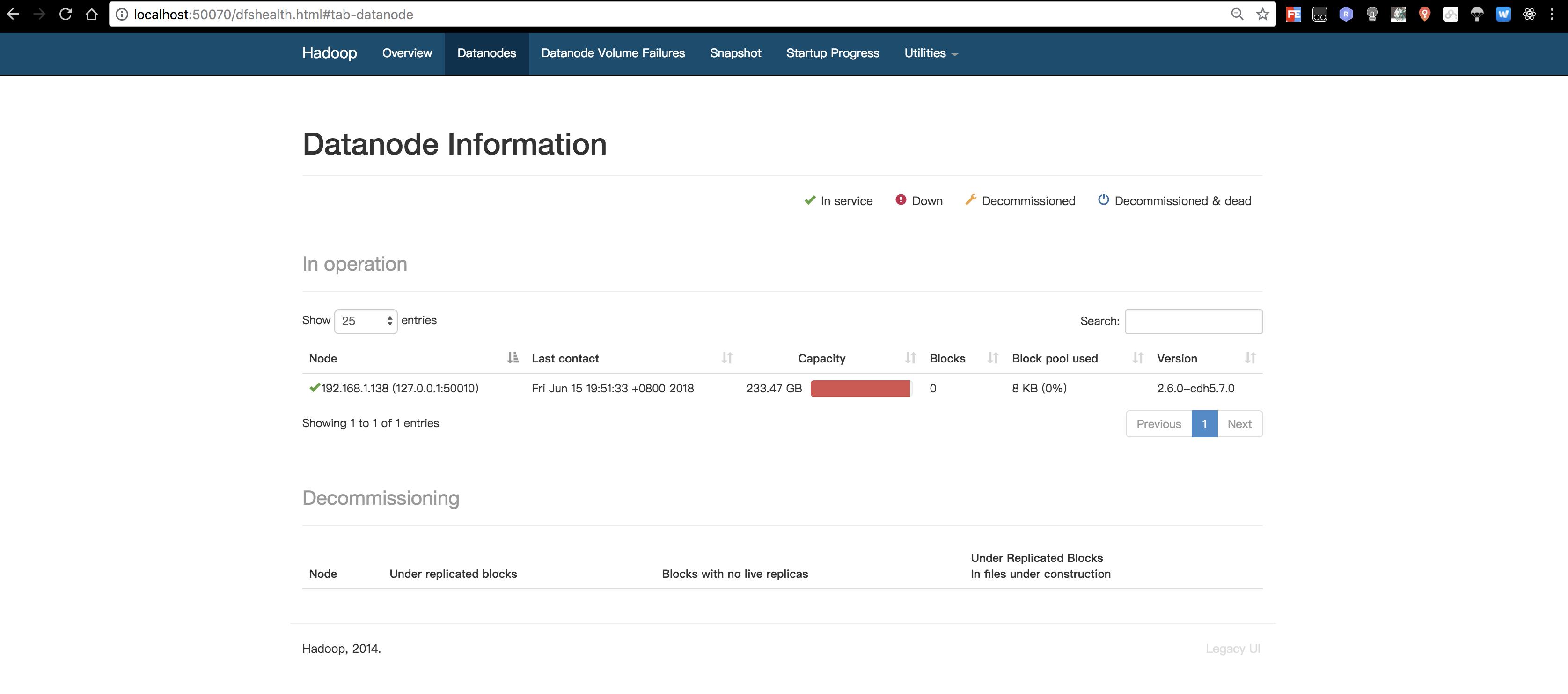
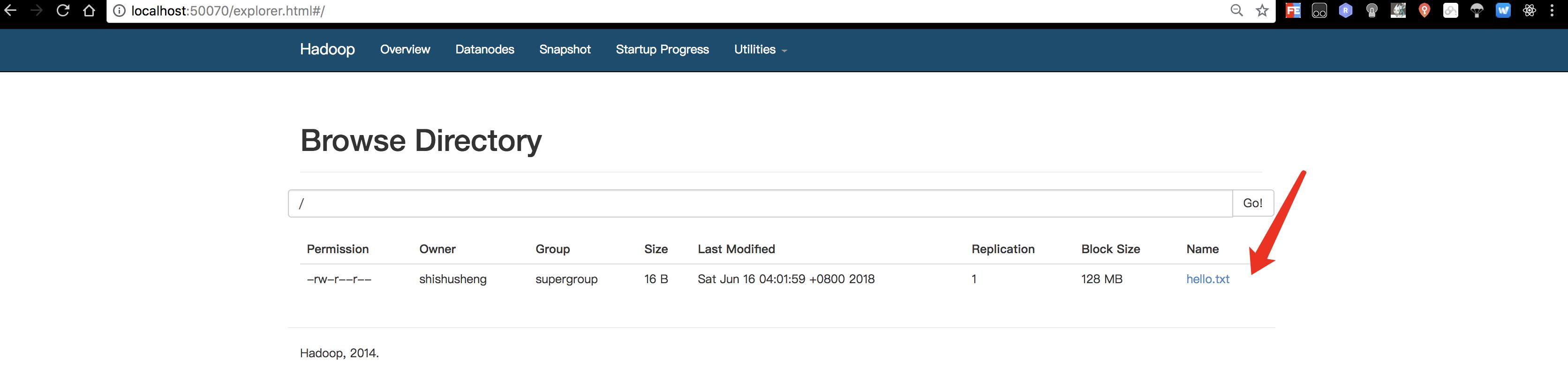
访问http://localhost:50070/
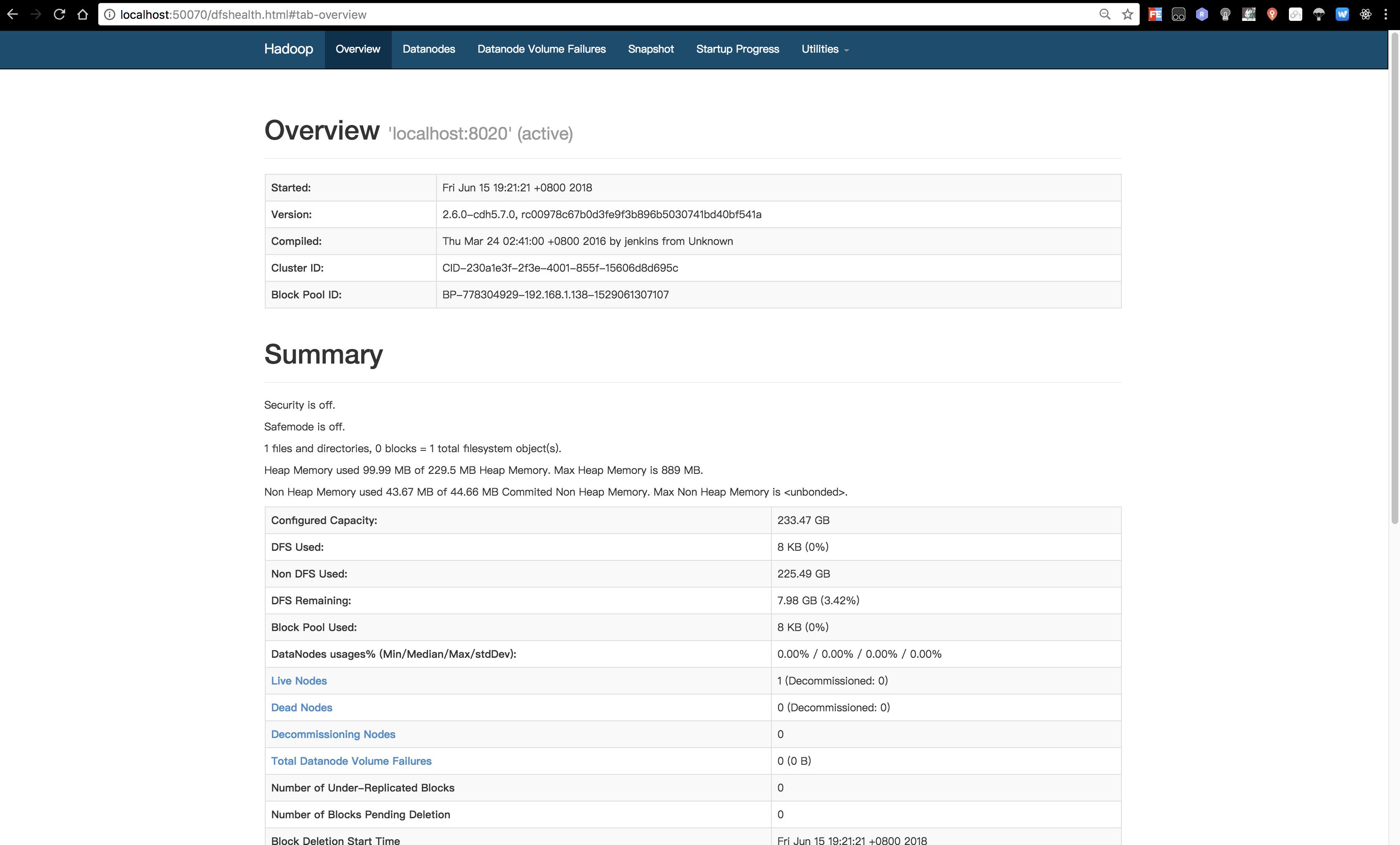
表示HDFS已经安装成功
步骤小结
关闭
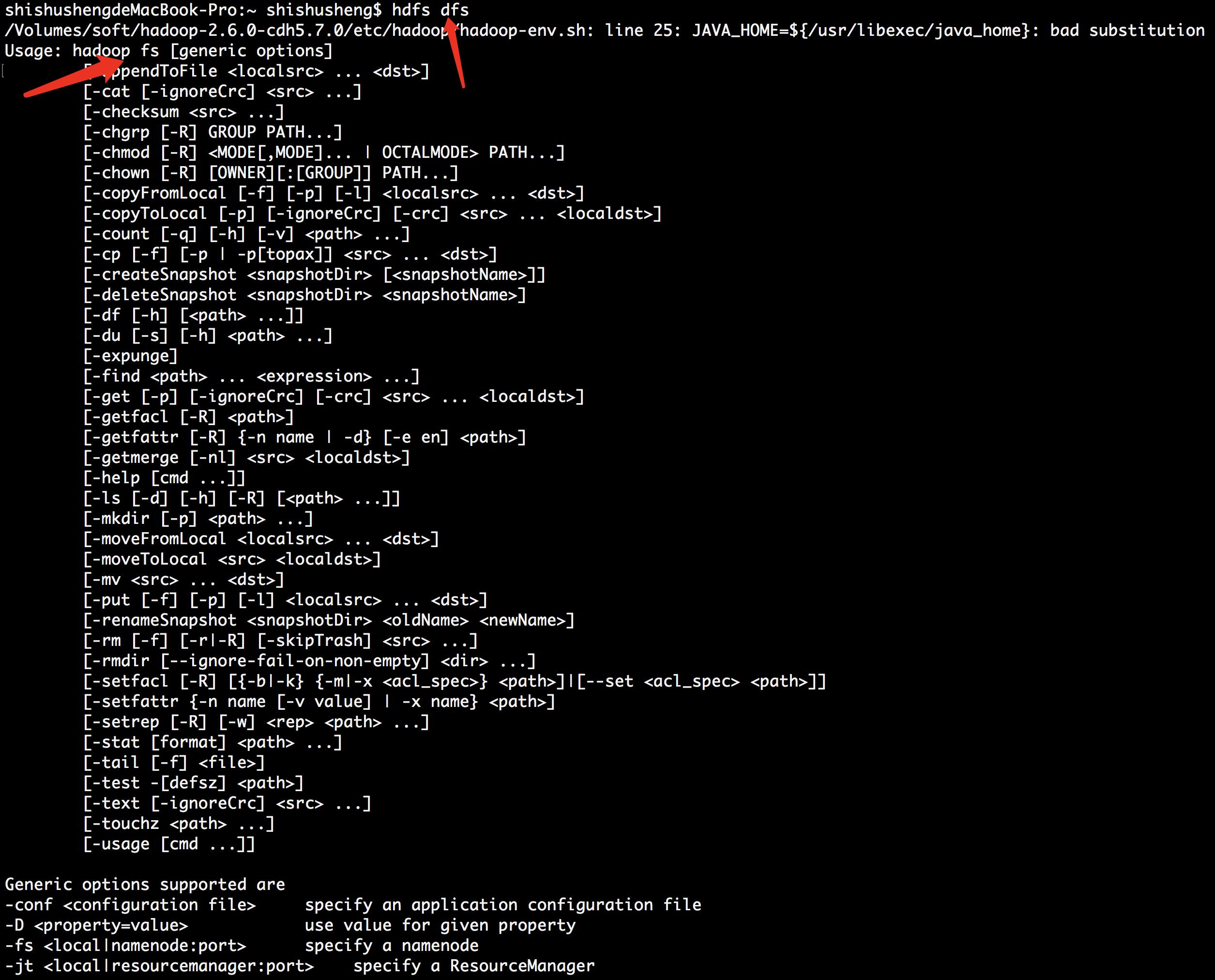
HDFS Shell 操作

官网指南
先启动 HDFS

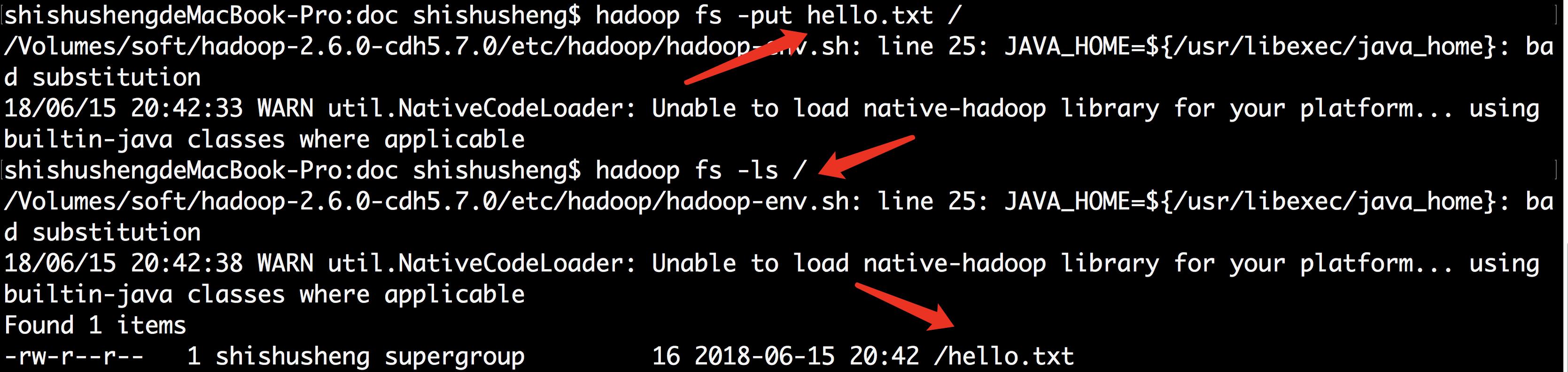

创建文件夹

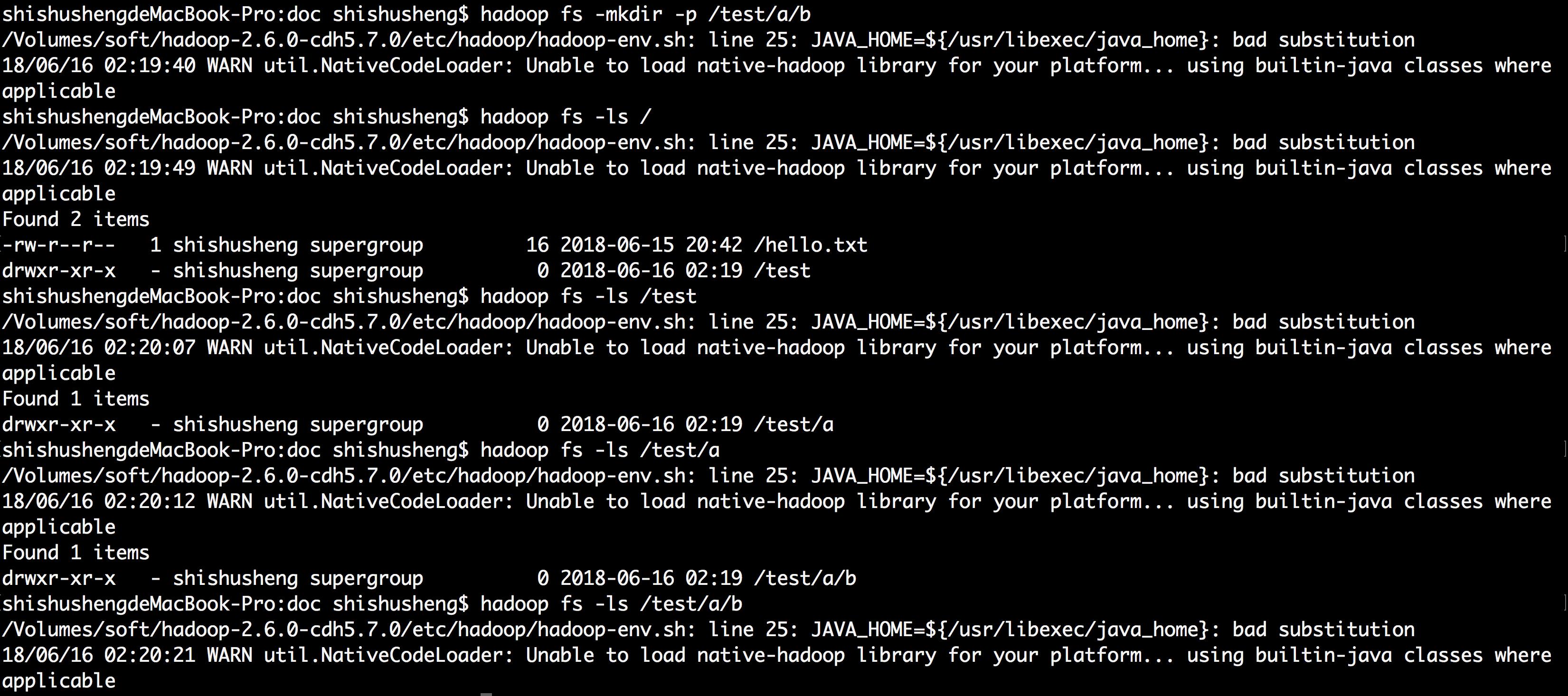
多层次文件夹
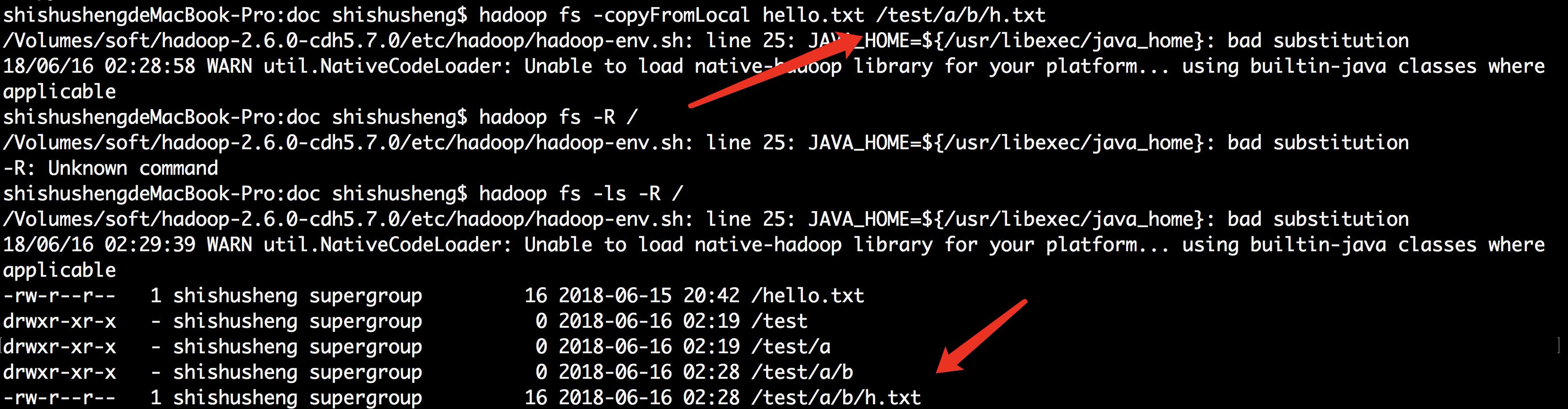
遍历所有文件夹



删除文件/文件夹


Java 操作 HDFS 开发环境搭建

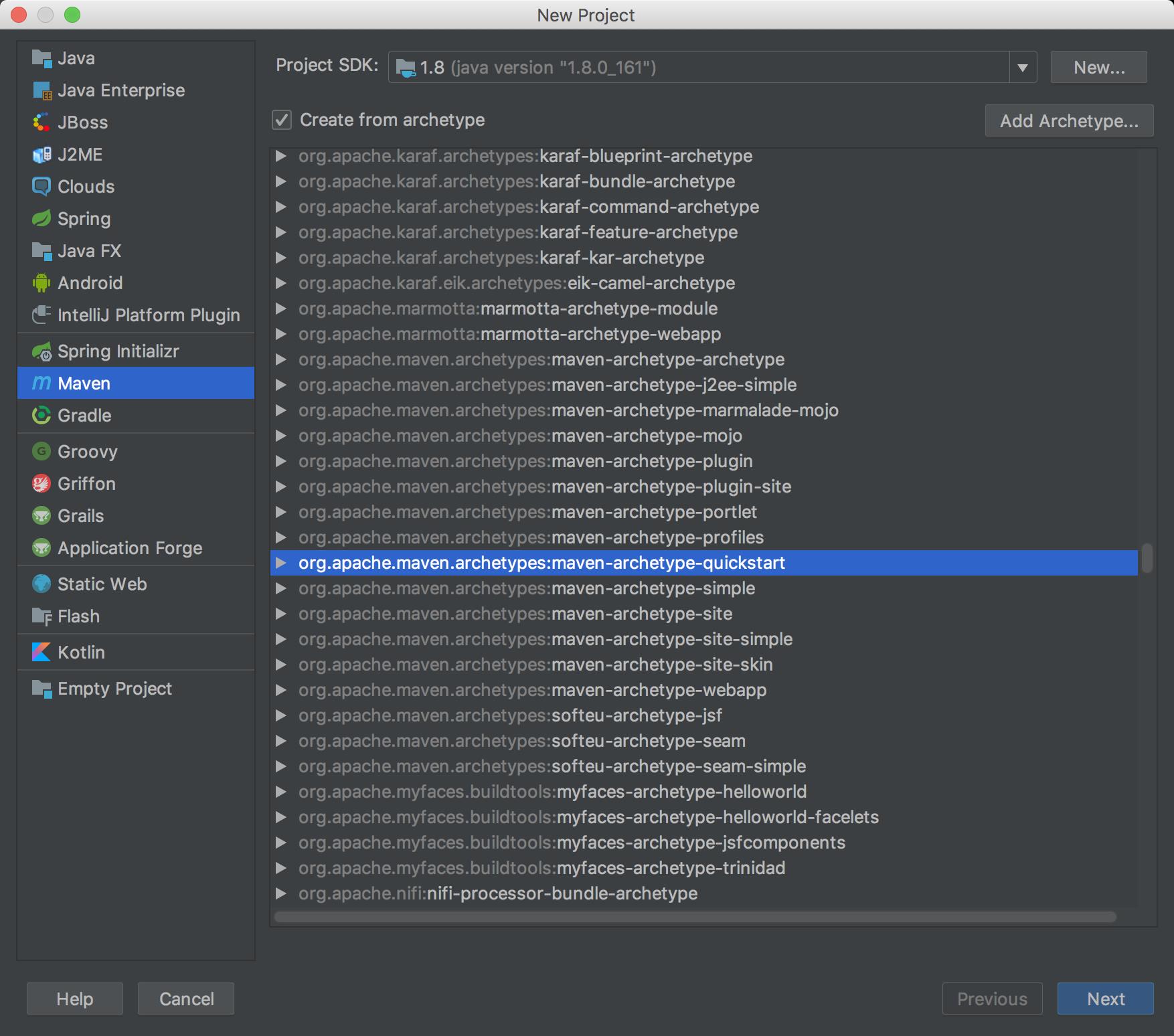
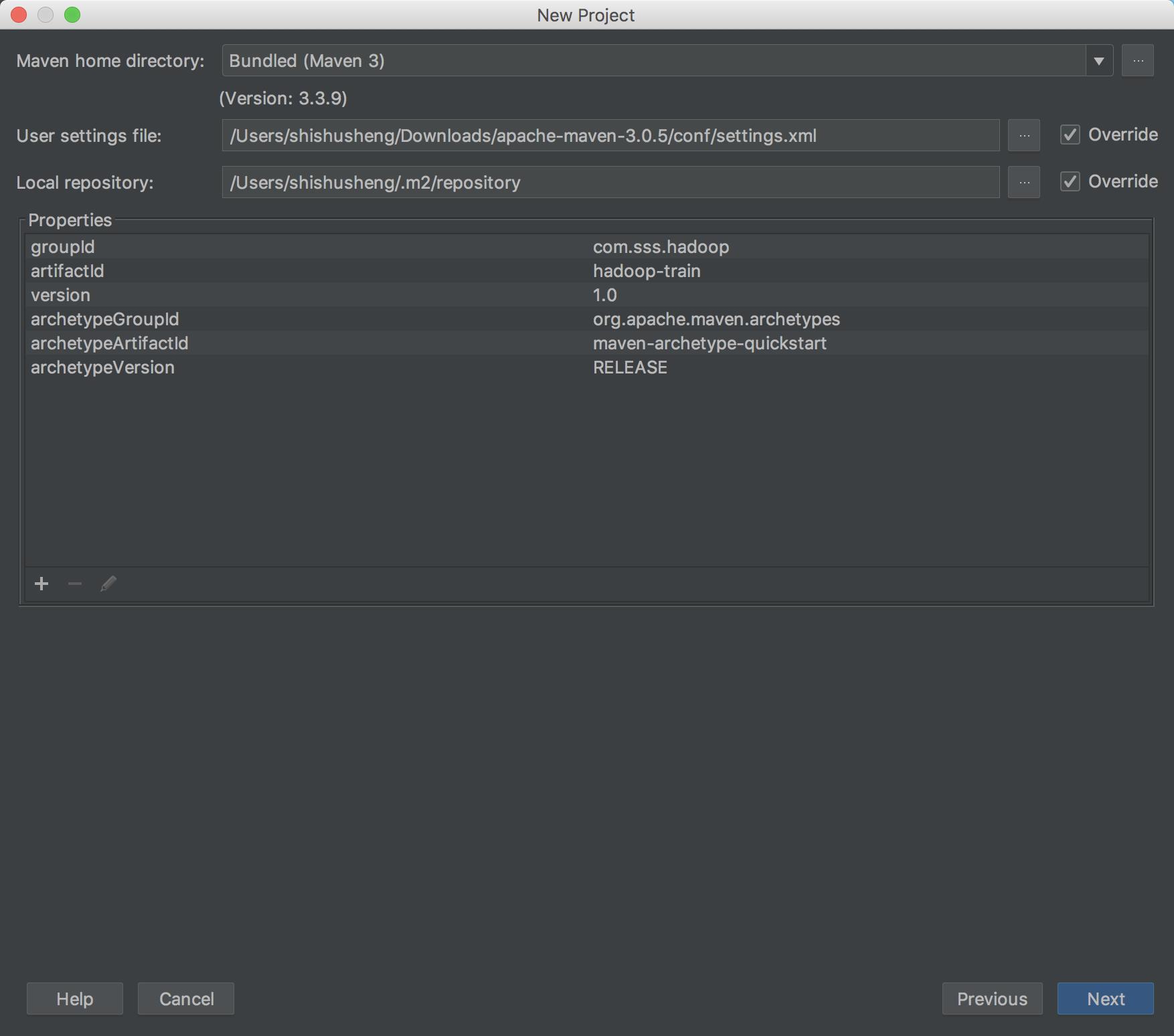
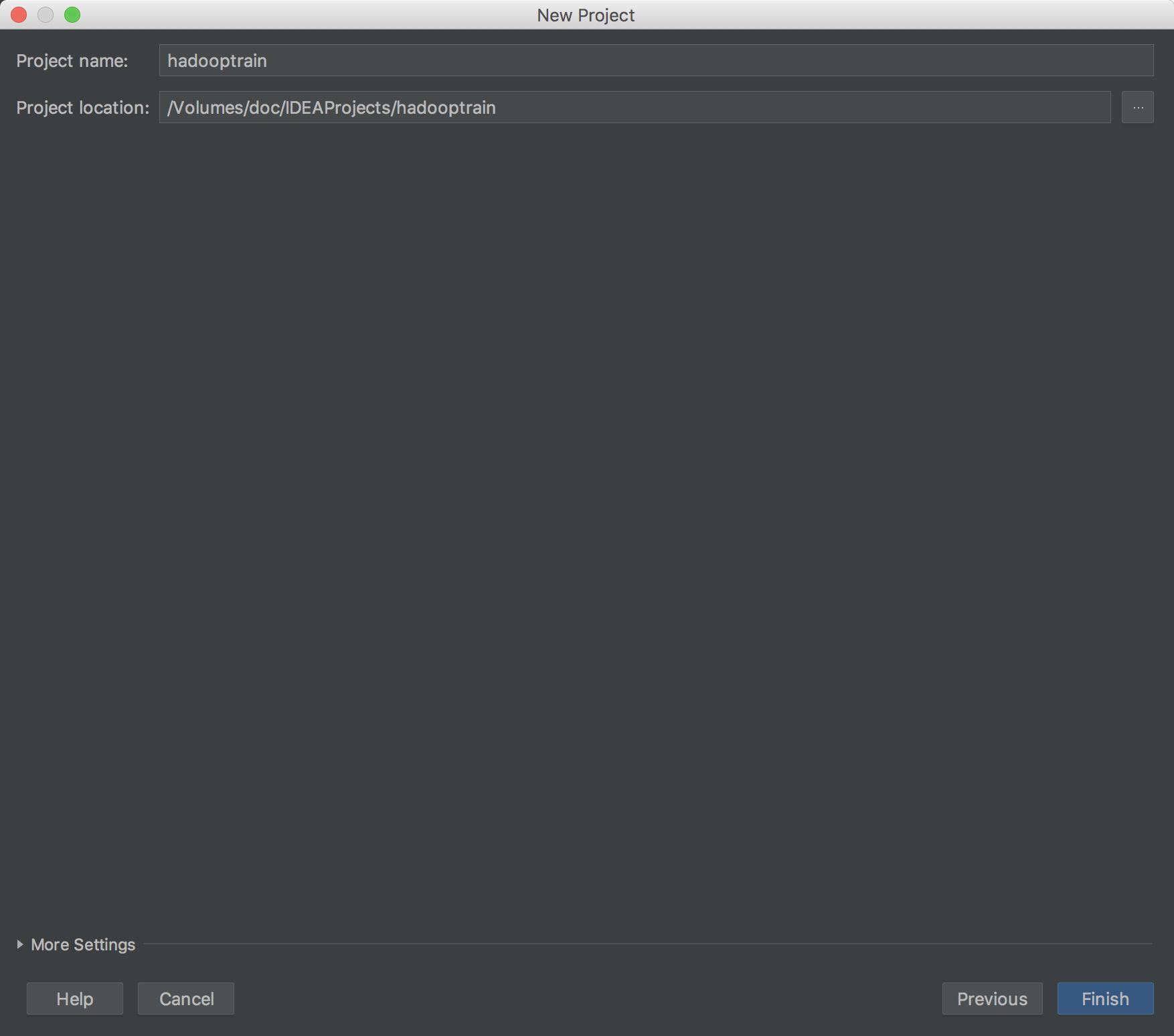
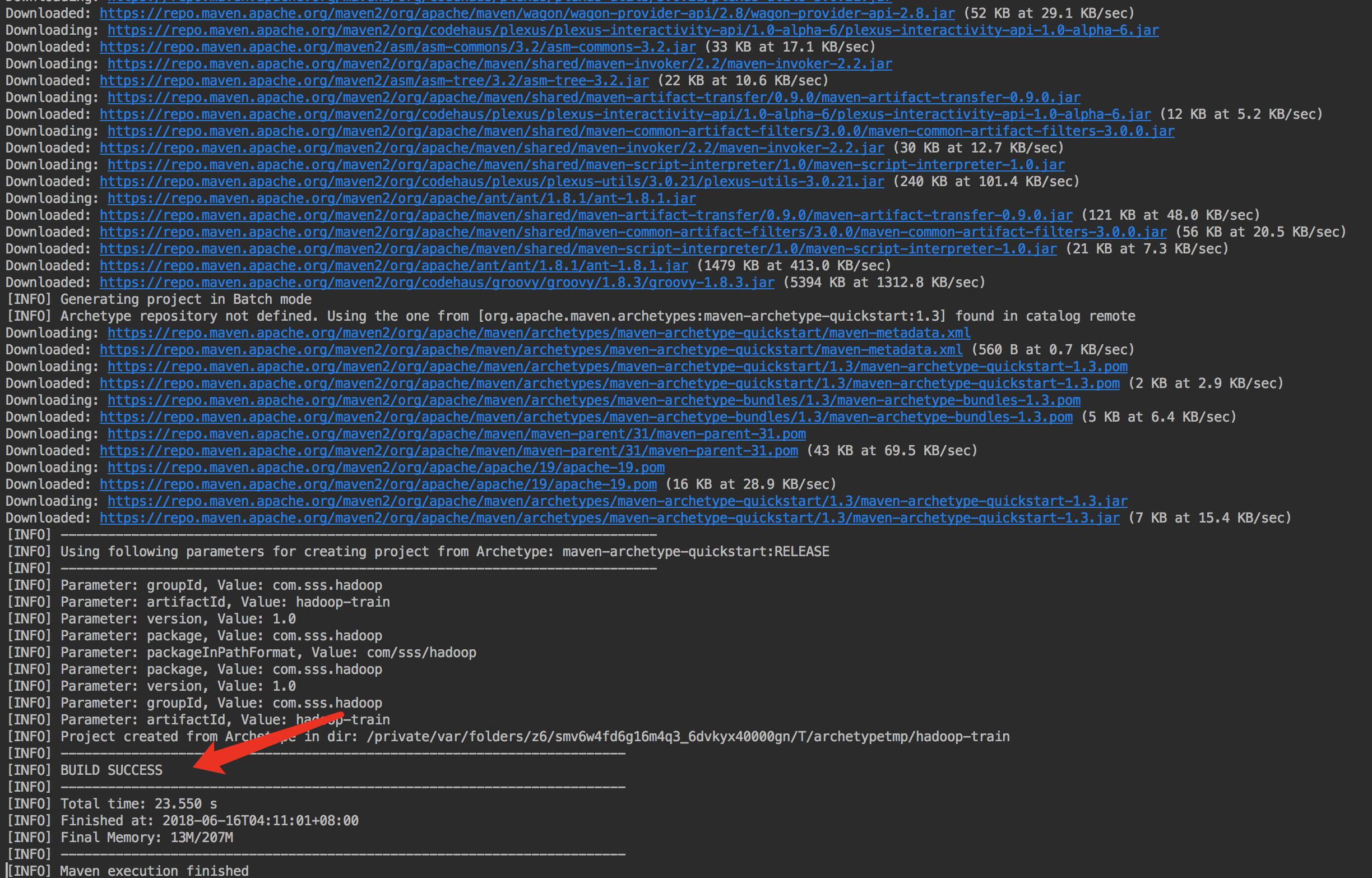
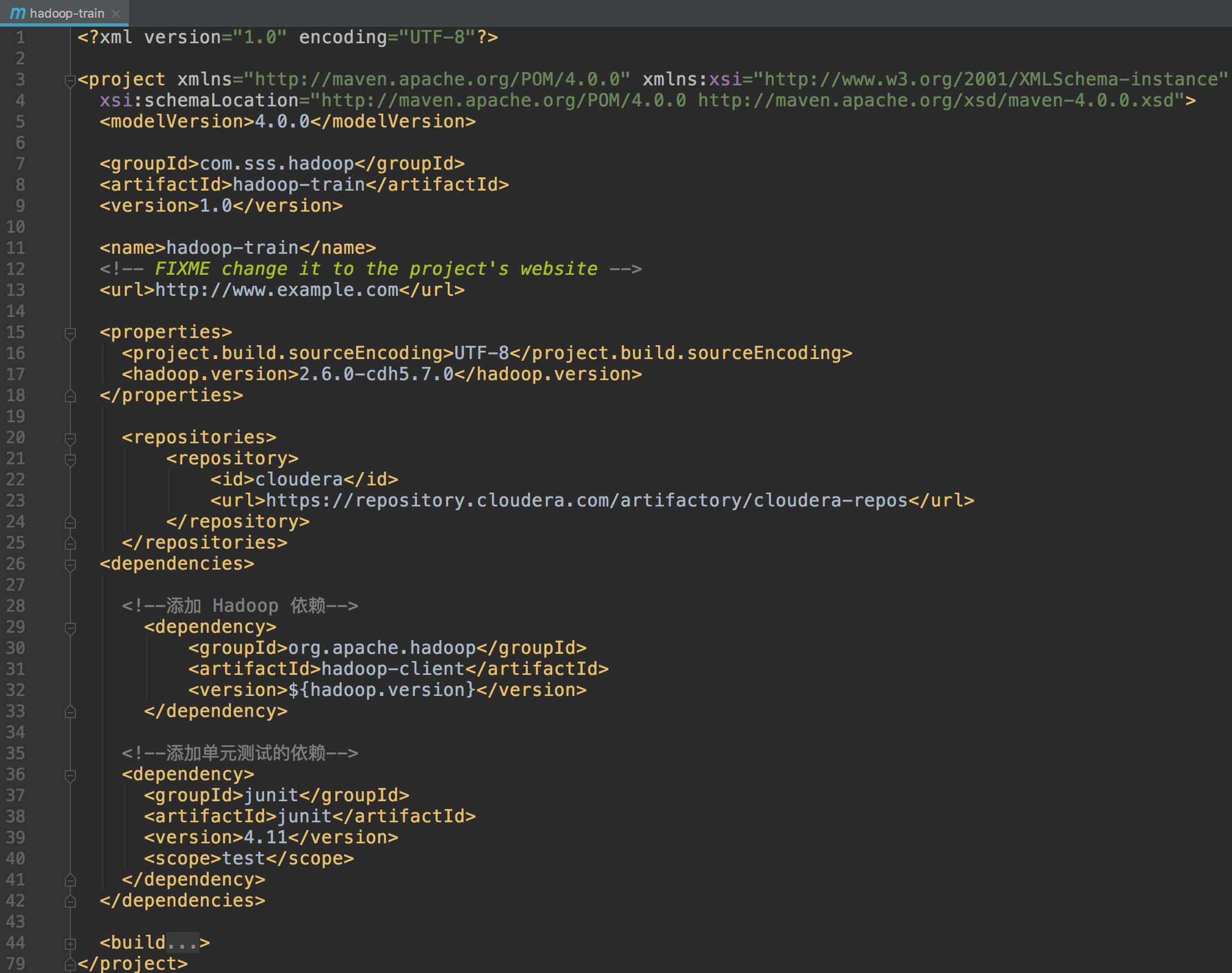
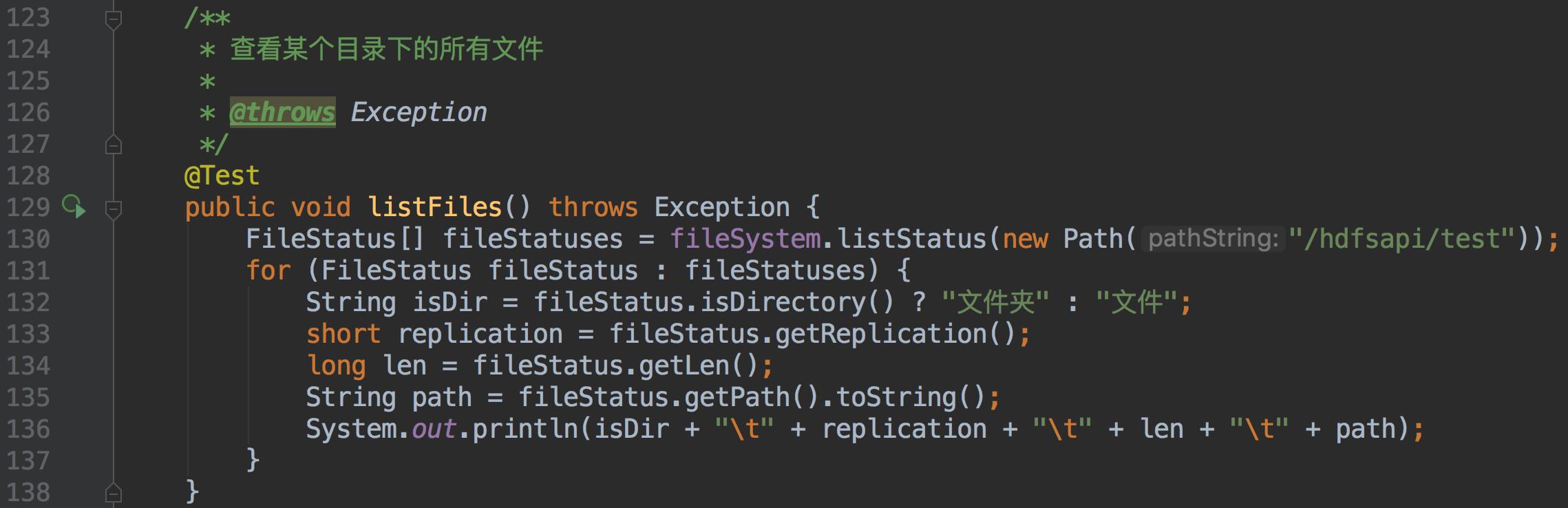
JavaAPI 操作 HDFS文件系统
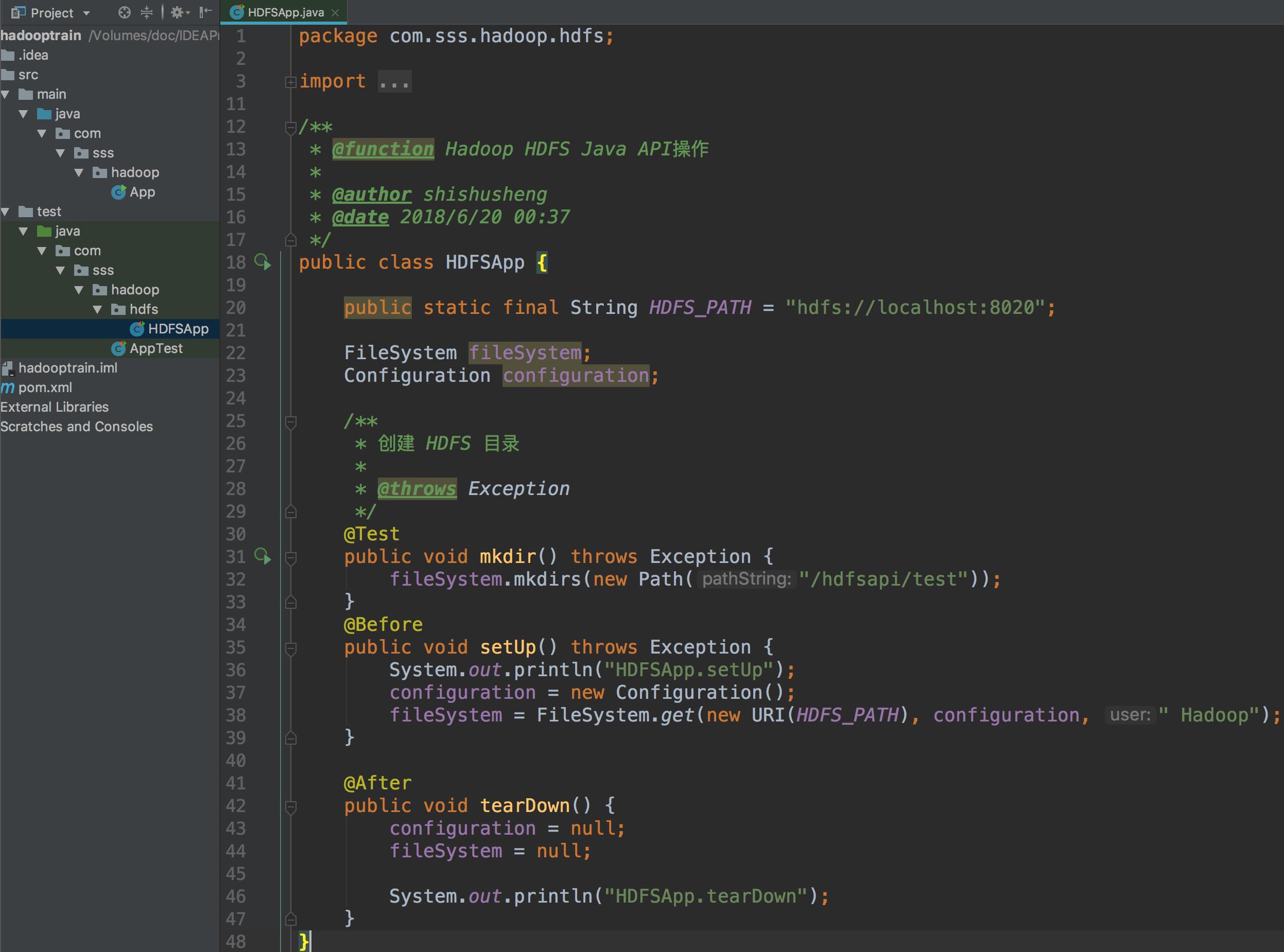

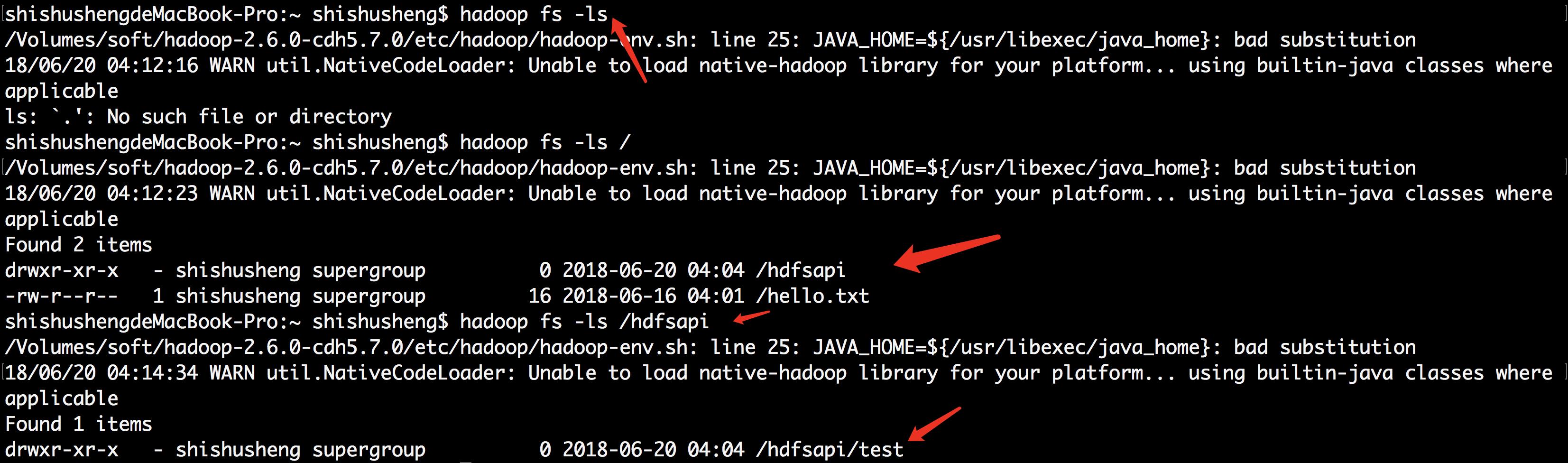
- 测试创建文件方法
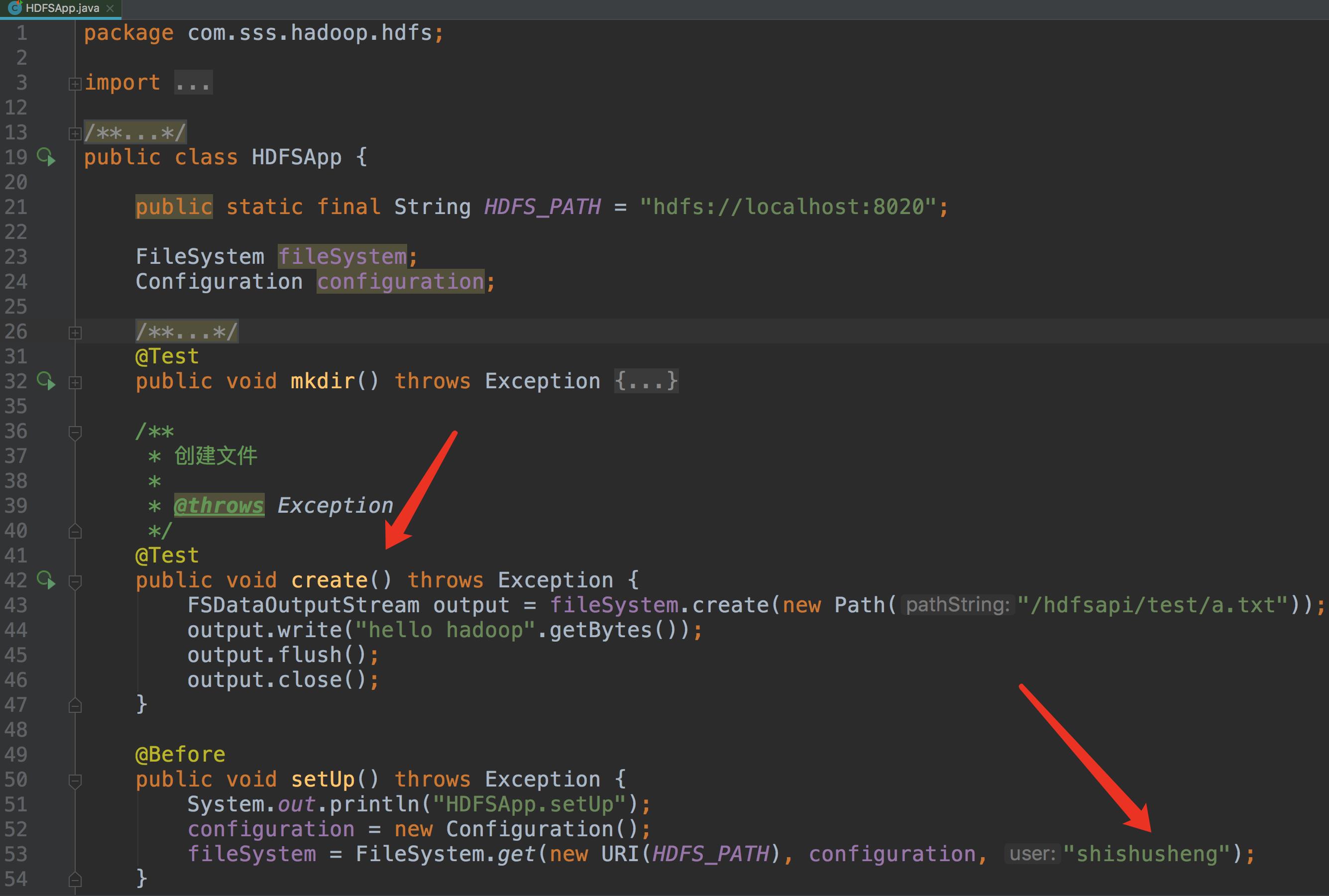

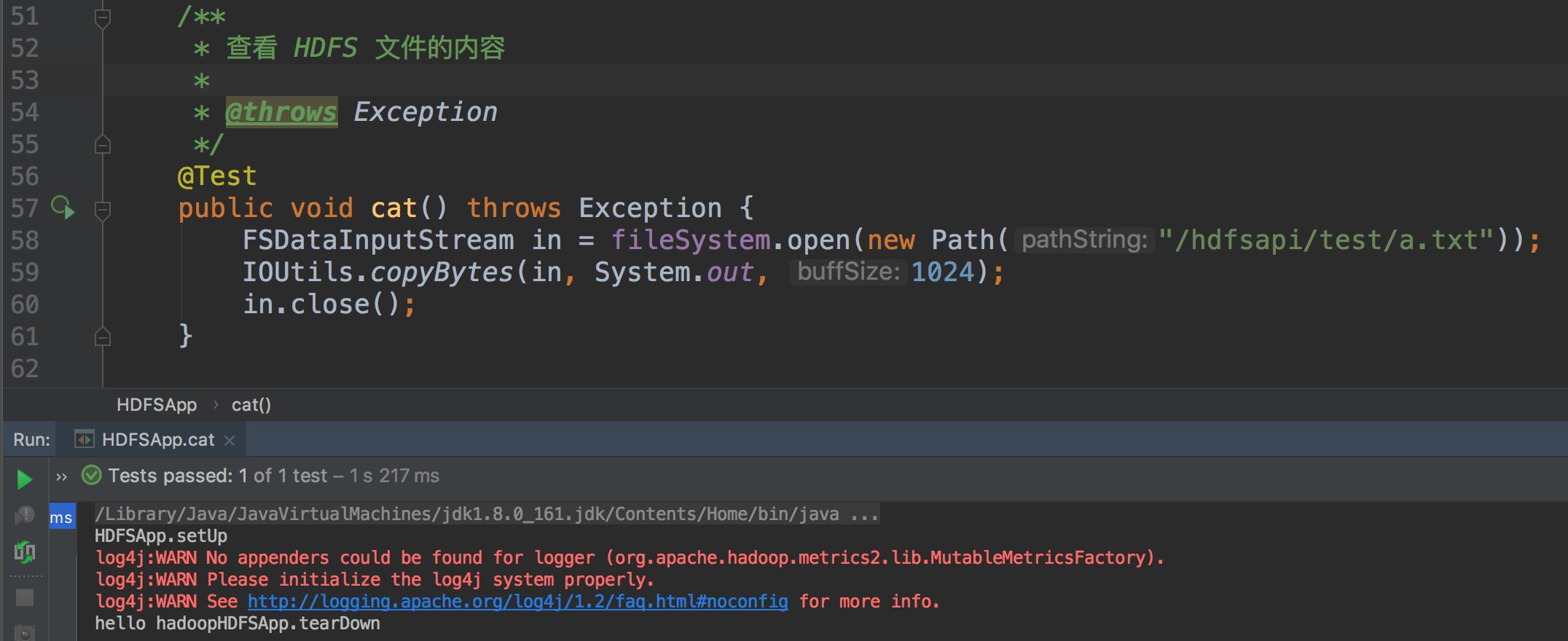
- 查看 HDFS 文件的内容
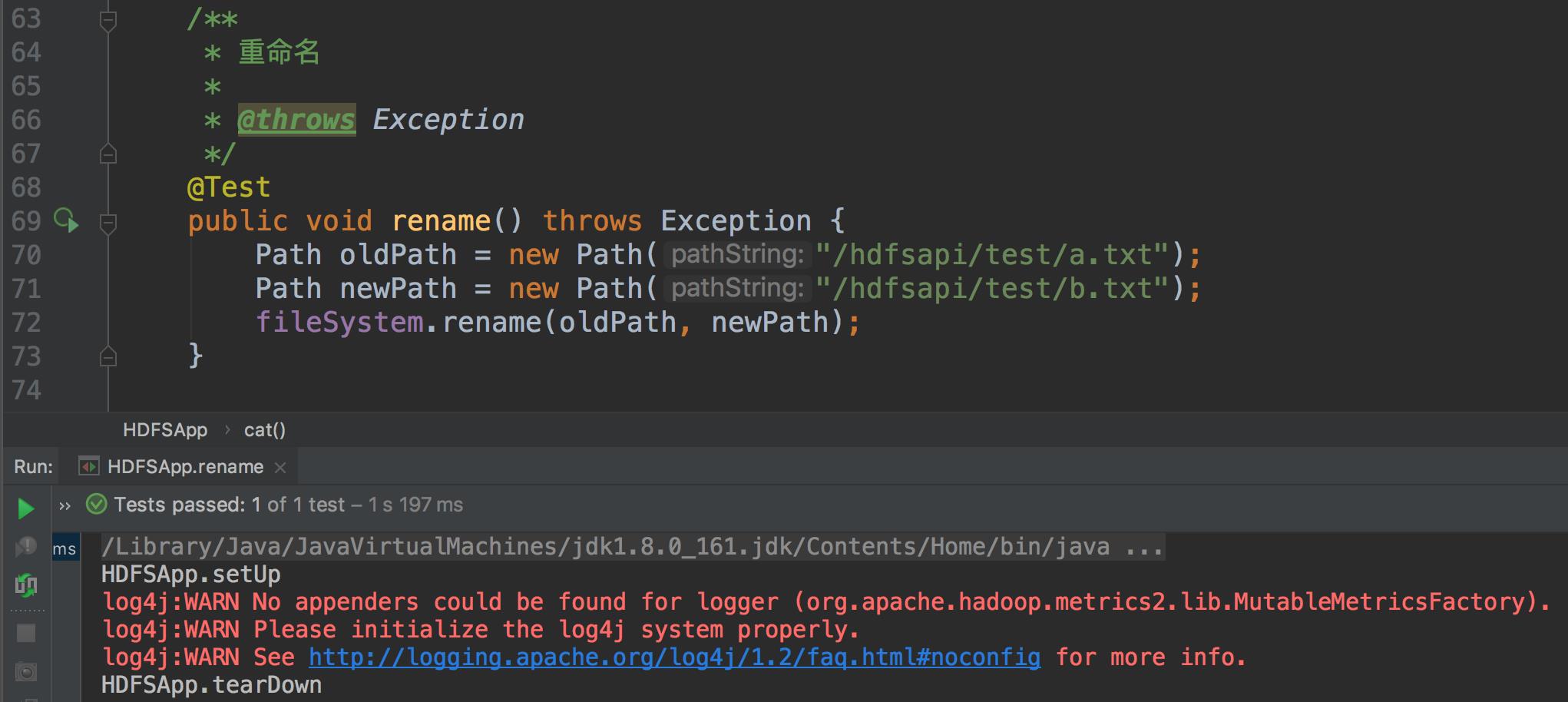
- 上传文件到 HDFS

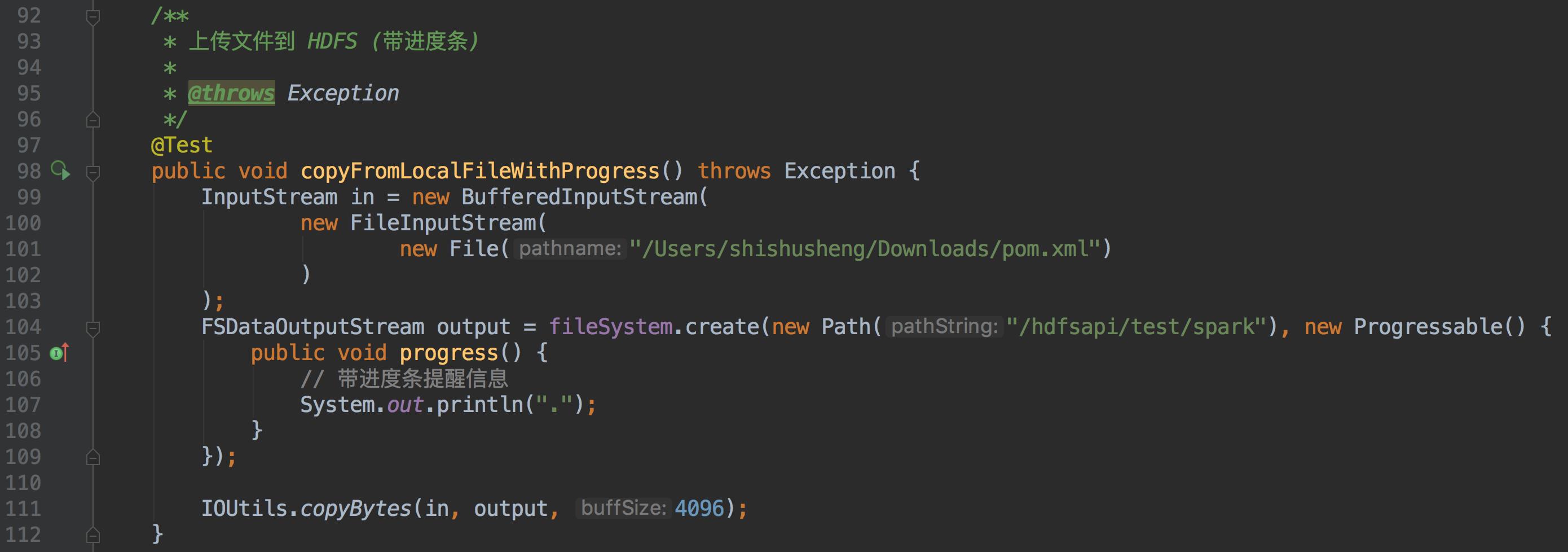
- 上传文件到 HDFS(带进度条)


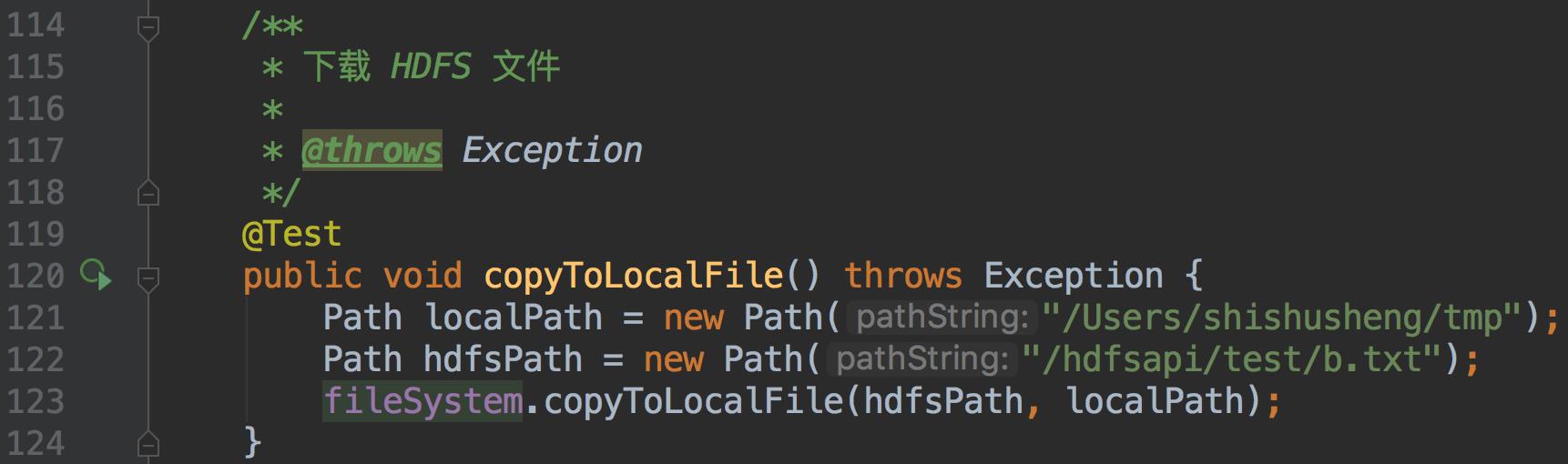
- 下载文件到本地

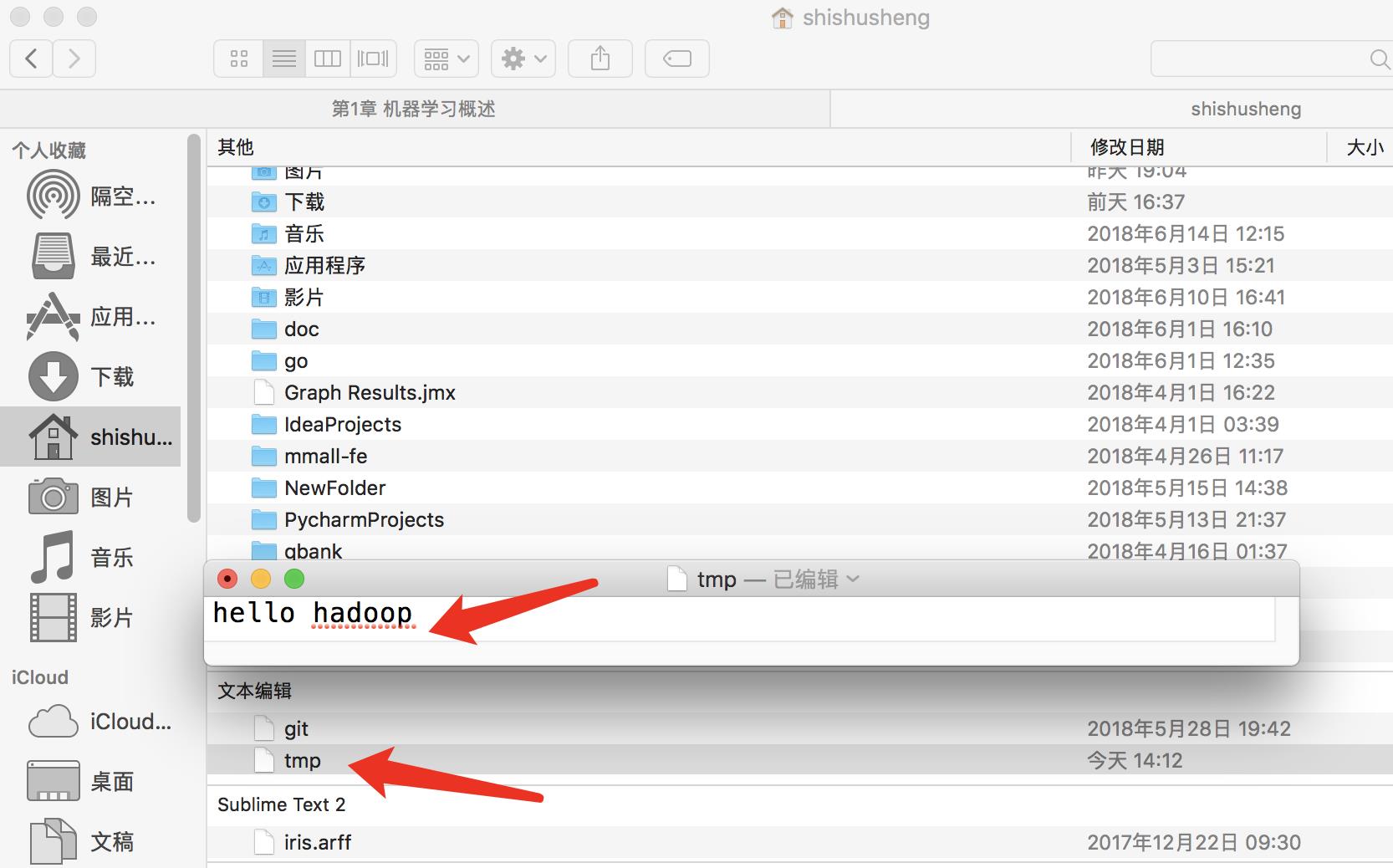
- 查看某个目录下的所有文件

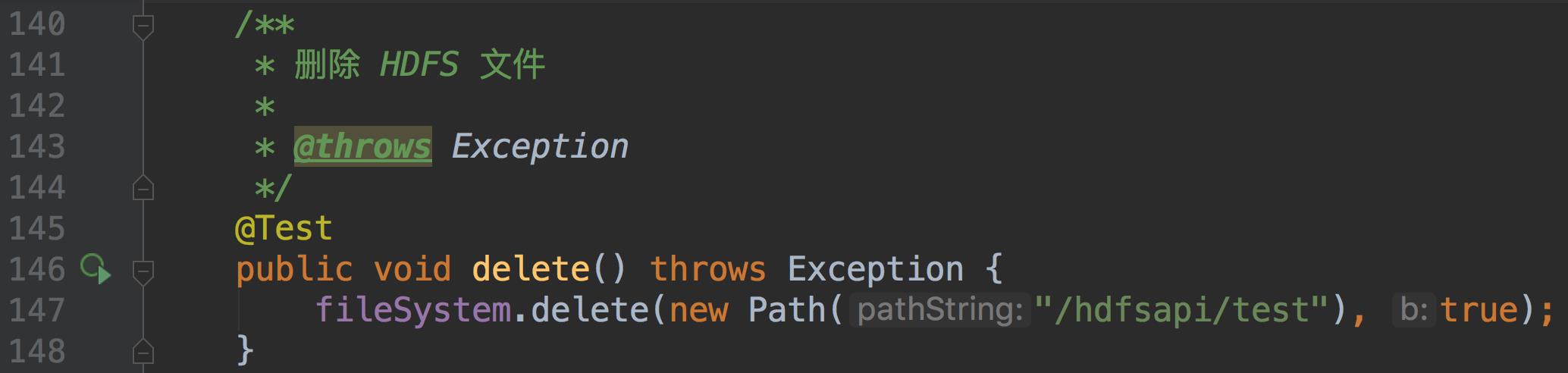
- 删除文件/文件夹


以上是关于HDFS伪分布式环境搭建的主要内容,如果未能解决你的问题,请参考以下文章