Hadoop伪分布式集群搭建
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop伪分布式集群搭建相关的知识,希望对你有一定的参考价值。
一、HDFS伪分布式环境搭建
Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统。它和现有的分布式文件系统有很多共同点。但同时,它和其他的分布式文件系统的区别也是很明显的。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。HDFS放宽了一部分POSIX约束,来实现流式读取文件系统数据的目的。HDFS在最开始是作为Apache Nutch搜索引擎项目的基础架构而开发的。HDFS是Apache Hadoop Core项目的一部分Hadoop的三种运行模式(启动模式)
1.1单机模式(独立模式)
-默认情况下Hadoop即为该模式,用于开发和调试
-不对配置文件进行修改
-使用本地的文件系统,而不是分布式的文件系统。
-Hadoop不会启动NameNode(名称节点)、DataNode(用于存储数据)JobTracker、TaskTracker等守护进程、Map和Redu()任务作为同一个进程的不同部分来执行的。
-用于对Map程序的逻辑进行调试,确保程序的正确。
1.2.伪分布式模式(Pseudo-Distrubuted Mode)
-Hadoop的守护进程运行在本机机器上,模拟一个小规模的集群
-Hadoop启动NameNode、DataNode、JobTracker、TaskTracker这些守护进程都在同一台机器上运行,是互相独立的JAVA进程。
-在这种模式下,Hadoop使用的是分布式文件系统,各个作业也是由JobTraker服务,来管理的独立进程。在单机模式之上增加了代码调试功能,允许检查内存使用情况,HDFS输入输出,
以及其他的守护进程交互。类似于完全分布式模式,因此,这种模式常用来开发测试Hadoop程序的执行是否正确。
-修改3个配置文件:core-site.xml(Hadoop集群的特性,作用于全部进程及客户端)、hdfs-site.xml(配置HDFS集群的工作属性)、mapred-site.xml(配置MapReduce集群的属性)
-格式化文件系统
1.3全分布式集群模式
-Hadoop的守护进程运行在一个集群上
-Hadoop的守护进程运行在有多台主机搭建的集群上,是真正的生产环境。
-在所有的主机上安装JDK和Hadoop,组成相互连接通的网络。
-在主机间设置ssh免登陆,把个从节点生产的公钥添加到主节点的新人列表。
-修改3个配置文件:core-site.xml、hdfs-site.xml、mapred-site.xml,指定NameNode和JobTraker的位置和端口,设置文件的副本等参数 -格式化文件系统
2.2HDFS分布式架构
HDFS是主/从式的架构。一个HDFS集群会有一个NameNode(简称NN),也就是命名节点,该节点作为主服务器存在(master server)。NameNode用于管理文件系统的命名空间以及调节客户访问文件。此外,还会有多个DataNode(简称DN),也就是数据节点,数据节点作为从节点存在(slave server)。通常每一个集群中的DataNode,都会被NameNode所管理,DataNode用于存储数据。HDFS公开了文件系统名称空间,允许用户将数据存储在文件中,就好比我们平时使用操作系统中的文件系统一样,用户无需关心底层是如何存储数据的。而在底层,一个文件会被分成一个或多个数据块,这些数据库块会被存储在一组数据节点中。在CDH中数据块的默认大小是128M,这个大小我们可以通过配置文件进行调节。在NameNode上我们可以执行文件系统的命名空间操作,如打开,关闭,重命名文件等。这也决定了数据块到数据节点的映射。
我们可以来看看HDFS的架构图:
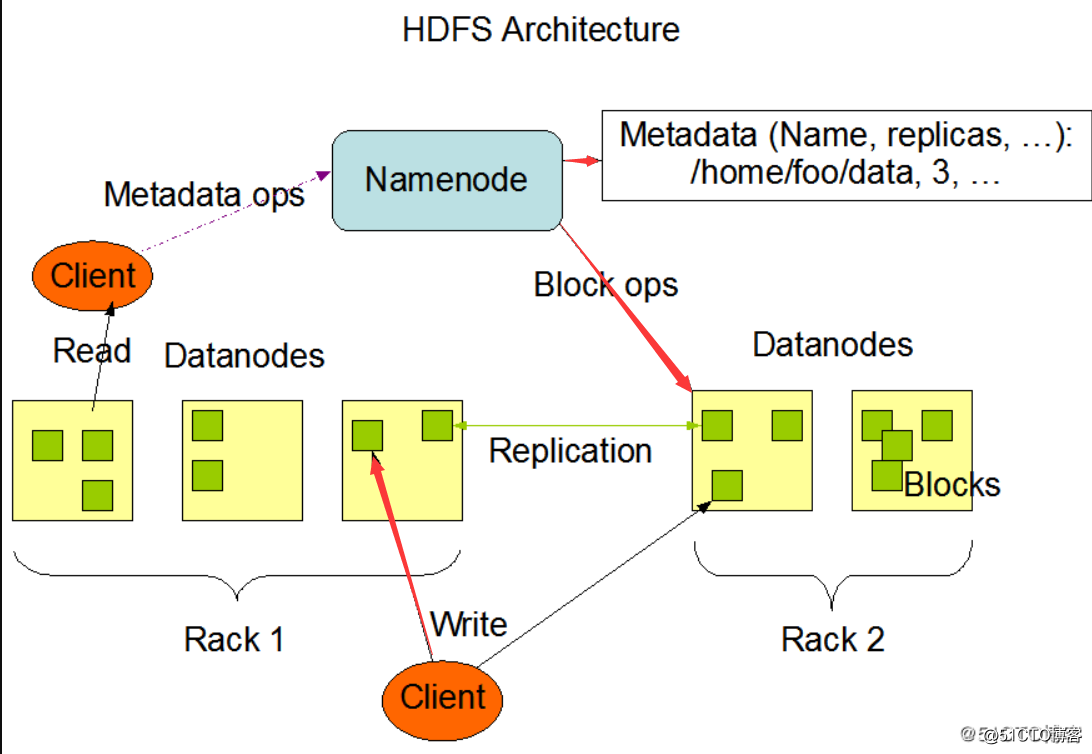
HDFS被设计为可以运行在普通的廉价机器上,而这些机器通常运行着一个Linux操作系统。HDFS是使用java语言编写的,任何支持java的机器都可以运行HDFS。使用高度可移植的java语言编写的HDFS,意味着可以部署在广泛的机器上。一个典型的HDFS集群部署会有一个专门的机器只能运行NameNode,而其他集群中的机器各自运行一个DataNode实例。虽然一台机器上也可以运行多个节点,但是并不建议这么做,除非是学习环境。
总结:
HDFS是主/从式的架构,一个HDFS集群会有一个NameNode以及多个DataNode
一个文件会被拆分为多个数据块进行存储,默认数据块大小是128M
即便一个数据块大小为130M,也会被拆分为2个Block,一个大小为128M,一个大小为2M
HDFS是使用Java编写的,使得其可以运行在安装了JDK的操作系统之上
NN:
负责客户端请求的响应
负责元数据(文件的名称、副本系数、Block存放的DN)的管理
DN:
存储用户的文件对应的数据块(Block)
会定期向NN发送心跳信息,汇报本身及其所有的block信息和健康状况
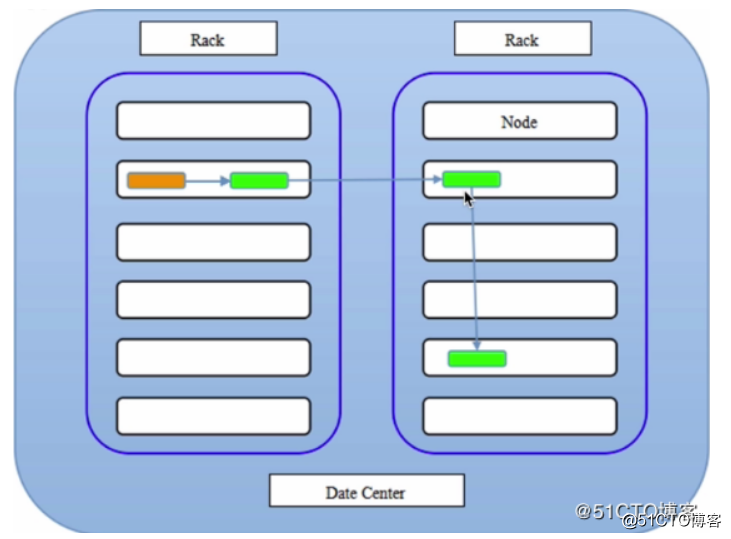
HDFS副本存放策略
NameNode节点选择一个DataNode节点去存储block副本得过程就叫做副本存放,这个过程的策略其实就是在可靠性和读写带宽间得权衡。
《Hadoop权威指南》中的默认方式:
第一个副本会随机选择,但是不会选择存储过满的节点。
第二个副本放在和第一个副本不同且随机选择的机架上。
第三个和第二个放在同一个机架上的不同节点上。
剩余的副本就完全随机节点了。
二、搭建伪分布式集群的前提条件
安装环境要求:
Centos7
Centos6
JDK
Hadoop
下载Hadoop 2.6.0-cdh5.7.0的tar.gz包并解压:[[email protected] hadoop]# cd /usr/local/src/
[[email protected] src]# ls
hadoop-2.6.0-cdh5.7.0 hadoop-2.6.0-cdh5.7.0.tar.gz
[[email protected] src]# wget http://archive.cloudera.com/cdh5/cdh/5/hadoop-2.6.0-cdh5.7.0.tar.gz(软件包较大可以利用win下载上传)
解压完后,进入到解压后的目录下,可以看到hadoop的目录结构如下:
简单说明一下其中几个目录存放的东西:
- bin目录存放可执行文件
- etc目录存放配置文件
- sbin目录下存放服务的启动命令
-
share目录下存放jar包与文档
以上就算是把hadoop给安装好了,接下来就是编辑配置文件,把JAVA_HOME配置一下:
[[email protected] hadoop-2.6.0-cdh5.7.0]# cd etc/
[[email protected] etc]# cd hadoop
[[email protected] hadoop]# vim hadoop-env.sh
 # 根据你的环境变量进行修改
# 根据你的环境变量进行修改
由于我们要进行的是单节点伪分布式环境的搭建,所以还需要配置两个配置文件,分别是core-site.xml以及hdfs-site.xml,如下:
[[email protected] hadoop]# vim core-site.xml
[[email protected] hadoop]# pwd
/usr/local/src/hadoop-2.6.0-cdh5.7.0/etc/hadoop
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://10.0.0.8:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name> # 指定临时文件所存放的目录
<value>/data/tmp/</value>
</property>
</configuration>
[[email protected] /usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop]# mkdir /data/tmp/
[[email protected] /usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop]# vim hdfs-site.xml # 增加如下内容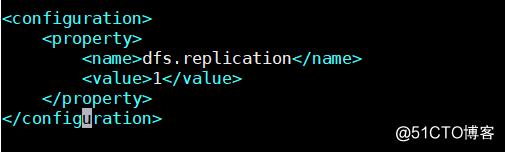
<configuration>
<property>
<name>dfs.replication</name> # 指定只产生一个副本
<value>1</value>
</property>
</configuration>
然后配置一下密钥对,设置本地免密登录,搭建伪分布式的话这一步是必须的:
[[email protected] ~]# ssh-keygen -t dsa -P ‘‘ -f ~/.ssh/id_dsa
Generating public/private dsa key pair.
Your identification has been saved in /root/.ssh/id_dsa.
Your public key has been saved in /root/.ssh/id_dsa.pub.
The key fingerprint is:
c2:41:89:65:bd:04:9e:3e:3f:f9:a7:51:cd:e9:cf:1e [email protected]
The key‘s randomart image is:
+--[ DSA 1024]----+
| o=+ |
| .+..o |
| +. . |
| o .. o . |
| = S . + |
| + . . . |
| + . .E |
| o .. o.|
| oo .+|
+-----------------+
[[email protected] ~]# cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
[[email protected] ~]# ssh localhost
ssh_exchange_identification: read: Connection reset by peer
[[email protected] ~]#
如上,测试本地免密登录的时候报了个ssh_exchange_identification: read: Connection reset by peer错误,于是着手排查错误,发现是/etc/hosts.allow文件里限制了IP,于是修改一下该配置文件即可,如下:
[[email protected] ~]# vim /etc/hosts.allow # 修改为 sshd: ALL
[[email protected] ~]# service sshd restart
[[email protected] ~]# ssh localhost # 测试登录成功
Last login: Sat Mar 24 21:56:38 2018 from localhost
[[email protected] ~]# logout
Connection to localhost closed.
[[email protected] ~]#
接下来就可以启动HDFS了,不过在启动之前需要先格式化文件系统:
[[email protected] ~]# /usr/local/hadoop-2.6.0-cdh5.7.0/bin/hdfs namenode -format(namenode -format注意)
注:只有第一次启动才需要格式化
使用服务启动脚本启动服务:
[[email protected] ~]# /usr/local/hadoop-2.6.0-cdh5.7.0/sbin/start-dfs.sh
18/03/24 21:59:03 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting namenodes on [192.168.77.130]
192.168.77.130: namenode running as process 8928. Stop it first.
localhost: starting datanode, logging to /usr/local/hadoop-2.6.0-cdh5.7.0/logs/hadoop-root-datanode-localhost.out
Starting secondary namenodes [0.0.0.0]
The authenticity of host ‘0.0.0.0 (0.0.0.0)‘ can‘t be established.
ECDSA key fingerprint is 63:74:14:e8:15:4c:45:13:9e:16:56:92:6a:8c:1a:84.
Are you sure you want to continue connecting (yes/no)? yes # 第一次启动会询问是否连接节点
0.0.0.0: Warning: Permanently added ‘0.0.0.0‘ (ECDSA) to the list of known hosts.
0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop-2.6.0-cdh5.7.0/logs/hadoop-root-secondarynamenode-localhost.out
18/03/24 21:59:22 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[[email protected] ~]# jps # 检查是否有以下几个进程,如果少了一个都是不成功的
8928 NameNode
9875 Jps
9578 DataNode
9757 SecondaryNameNode
[[email protected] ~]# netstat -lntp |grep java # 检查端口
tcp 0 0 0.0.0.0:50090 0.0.0.0: LISTEN 9757/java
tcp 0 0 192.168.77.130:8020 0.0.0.0: LISTEN 8928/java
tcp 0 0 0.0.0.0:50070 0.0.0.0: LISTEN 8928/java
tcp 0 0 0.0.0.0:50010 0.0.0.0: LISTEN 9578/java
tcp 0 0 0.0.0.0:50075 0.0.0.0: LISTEN 9578/java
tcp 0 0 0.0.0.0:50020 0.0.0.0: LISTEN 9578/java
tcp 0 0 127.0.0.1:53703 0.0.0.0:* LISTEN 9578/java
[[email protected] ~]#
然后将Hadoop的安装目录配置到环境变量中,方便之后使用它的命令:
[[email protected] hadoop]# vim ~/.bash_profile

确认服务启动成功后,使用浏览器访问10.0.0.8:50070,会访问到如下页面: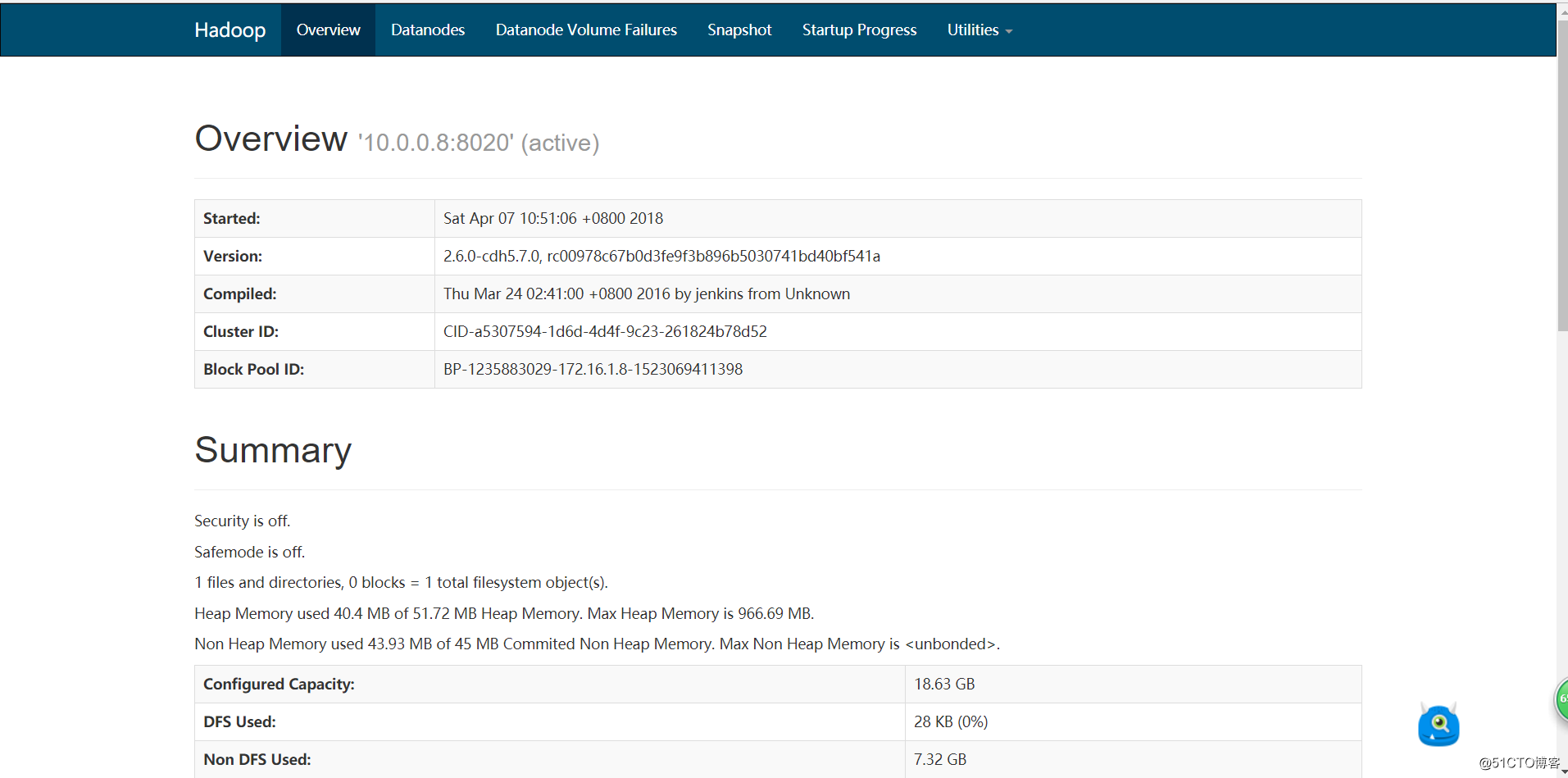
点击Live Nodes查看活着的节点:
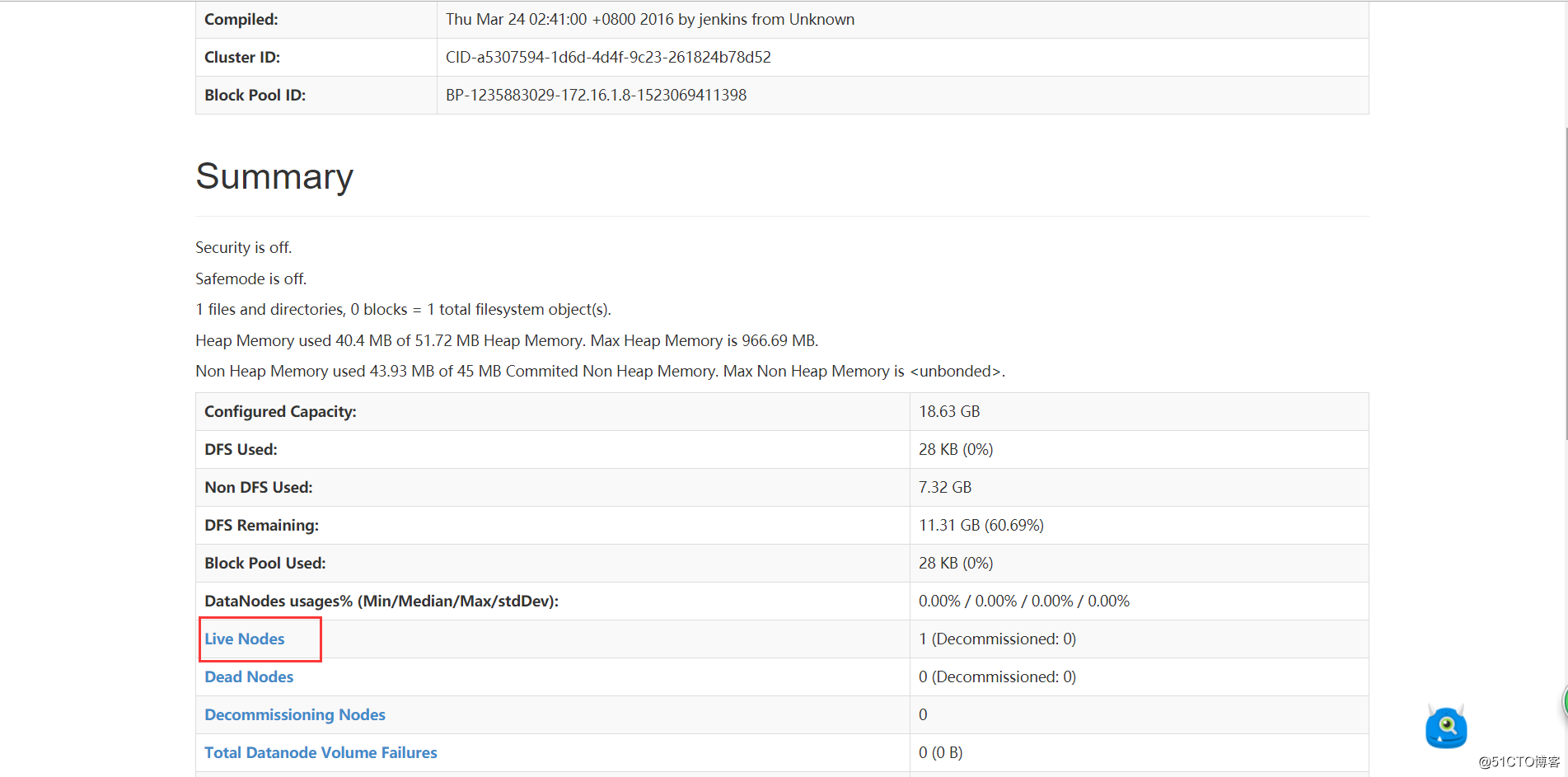
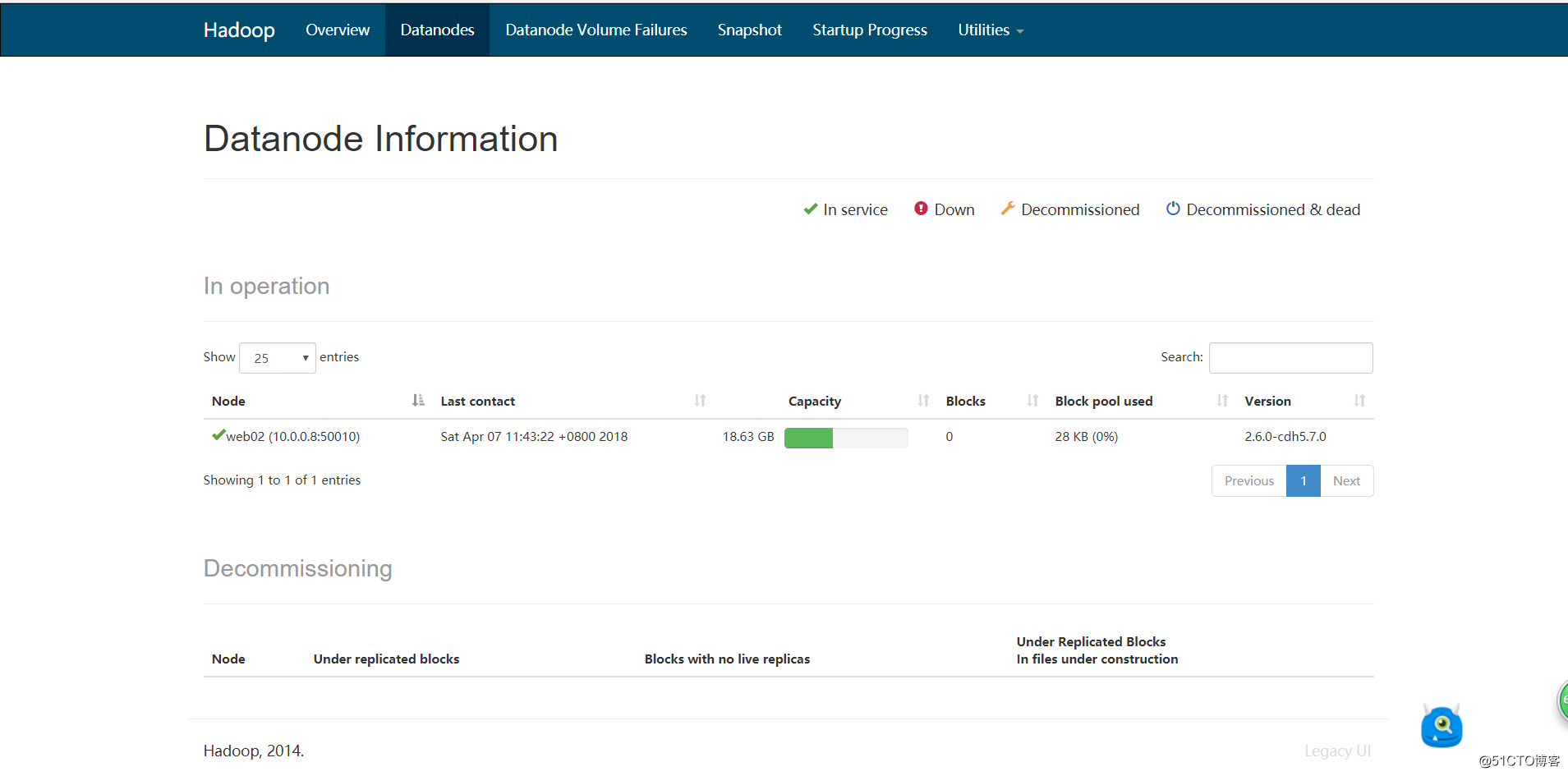
如上,可以看到节点的信息。到此,我们伪分布式的hadoop集群就搭建完成了
以上是关于Hadoop伪分布式集群搭建的主要内容,如果未能解决你的问题,请参考以下文章