Hadoop伪分布集群搭建(Hadoop)
Posted 木头㉿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop伪分布集群搭建(Hadoop)相关的知识,希望对你有一定的参考价值。
Hadoop伪分布集群搭建

1.安装vmware workstation软件(版本15或16,12也可),配置centos 7镜像文件。需注意如下:
(1)centos安装后无法打开,一般是虚拟化的问题,在bios界面将其打开。网上有千篇一律的说法,结合自身电脑进行尝试。
(2)安装centos7推荐安装桌面版,“软件选择”——“GNOME桌面”,操作较为直观,可以清楚的展现文件部署。
(3)安装时可自定义ip地址、用户名和主机名。
(4)本次实例为单节点。
配置中若是遇到问题,滴滴vx:mutou88848
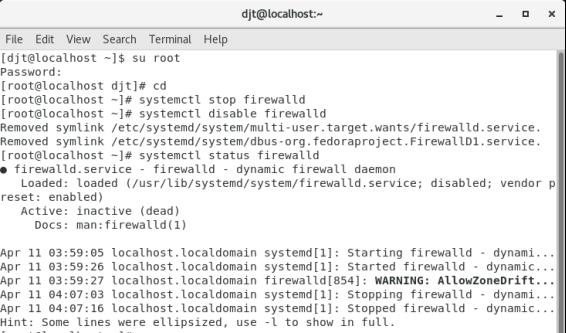
2.关闭防火墙(切换到root用户下进行)
命令:su root
systemctl stop firewalld
systemctl disable firewalld
systemctl status firewalld(出现inactive dead即可)
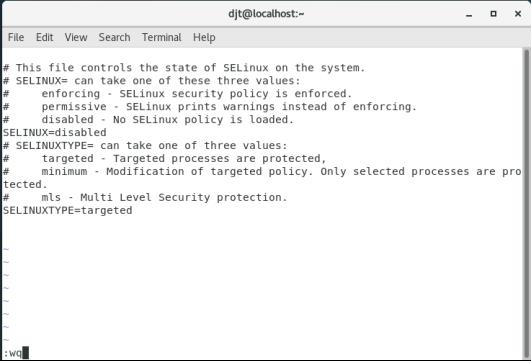
3.禁用selinux
vi /etc/selinux/config
#修改: SELINUX=disabled
进入配置文件,按“i”键,下方出现“INSERT”,此时上下左右移动光标到SELINUX=enforcing处,删除enforcing,改为disabled,此时,按esc键,此时“INSERT”消失,输入“:wq”保存并退出即可
重启reboot生效
4.网络配置IP
(1)查看虚拟机ip,子网掩码,网关信息等
方法1:在开始装镜像文件时,网络配置信息可查看,如下图
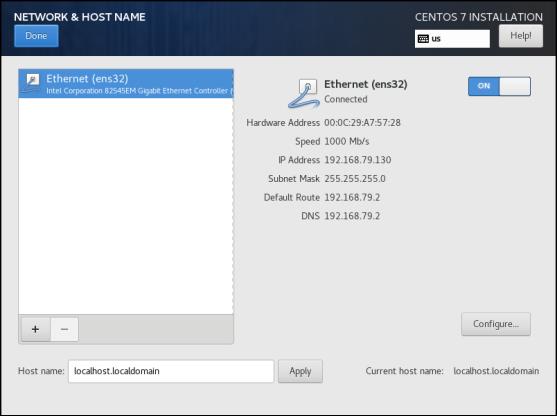
可以得到,网关(192.168.79.2),子网掩码(255.255.255.0)和ip地址(192.168.79.130)
方法二:点击VMware栏的编辑>>网络编辑器,切换显示VMnet8的信息.一般子网IP是安装VMware时随机分配的
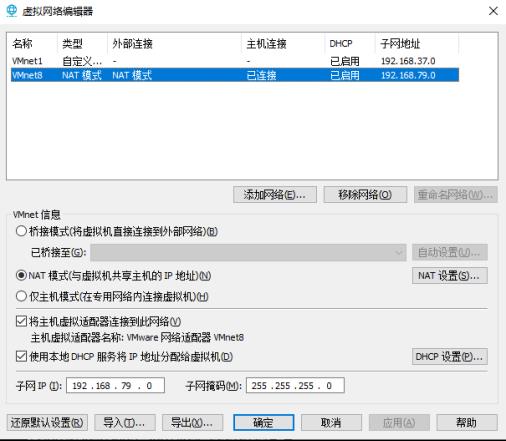
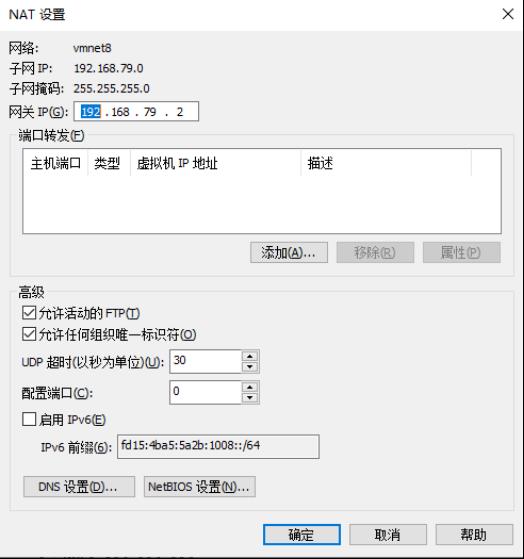
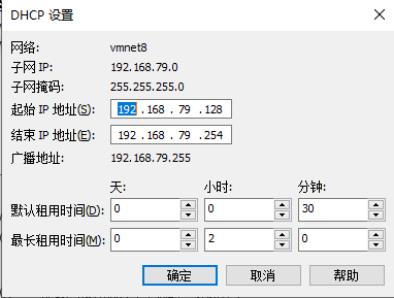
点击NAT设置和DHCP设置,可以得到,网关(192.168.79.2),子网掩码(255.255.255.0)和ip地址(dhcp设置中,ip地址是一个范围,这里设置为192.168.79.130)
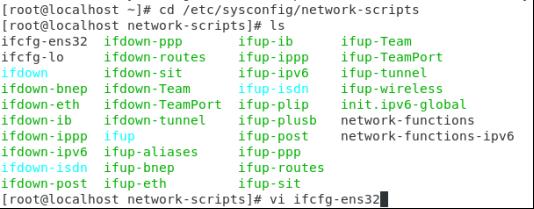
(2)在/etc/sysconfig/network-scripts/中,找到ifcfg-ens32或者ifcfg-ens33配置文件,修改BOOTPROTO=static,ONBOOT=yes,添加如下信息
IPADDR=192.168.79.130
NETMASK=255.255.255.0
GATEWAY=192.168.79.2
DNS1=114.114.114
DNS2=8.8.8.8
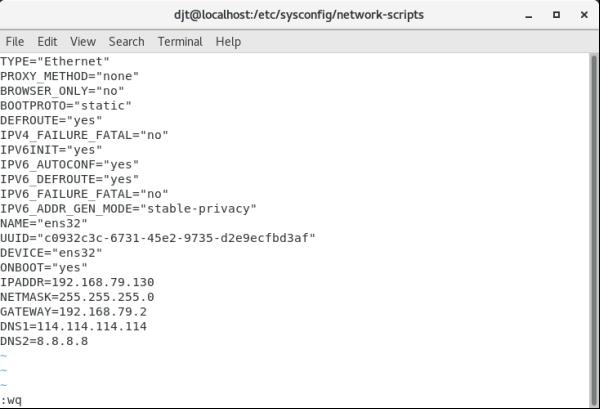
(3)设置resolv.conf文件
编辑resolve.conf文件,输入vi /etc/resolv.conf,添加之前设置的DNS,用于解析地址
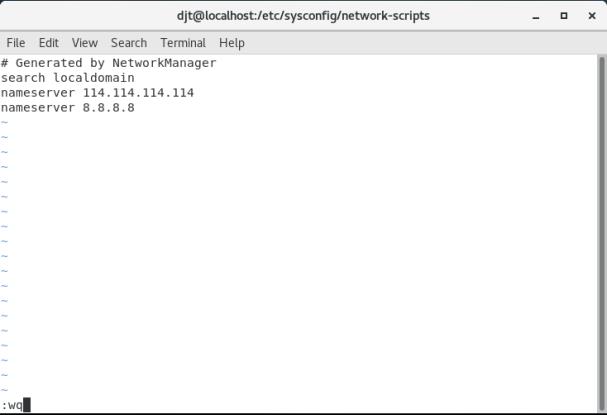
(4)输入systemctl restart network重启网络服务
(5)测试ping 百度(ctrl+c可停止)
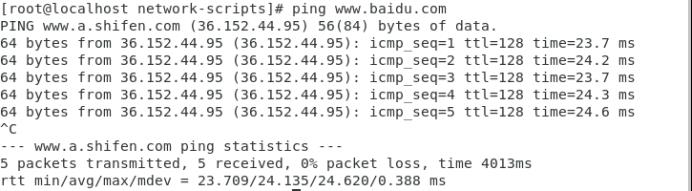
(6)在主机的系统命令行中ping虚拟机的IP地址,输入ping 虚拟机IP,如下图所示则表示ping通了
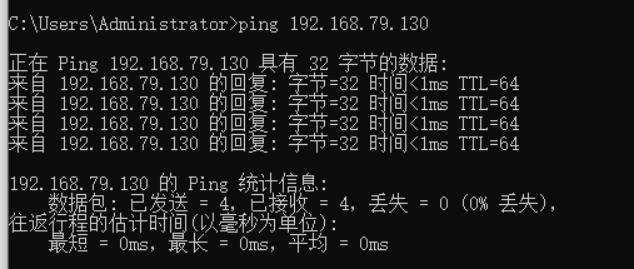
5.修改主机名,做主机映射
hostnamectl set-hostname djt
reboot

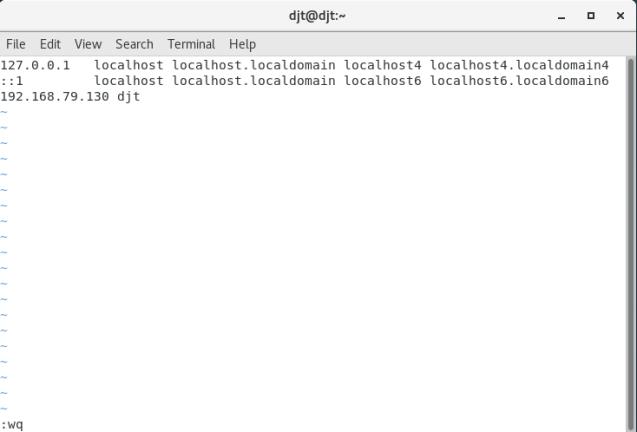
修改配置文件vi /etc/hosts
6.创建用户hadoop
useradd -m hadoop

7.为hadoop用户设置SSH免密码登录
(1)切换到hadoop用户,创建.ssh目录

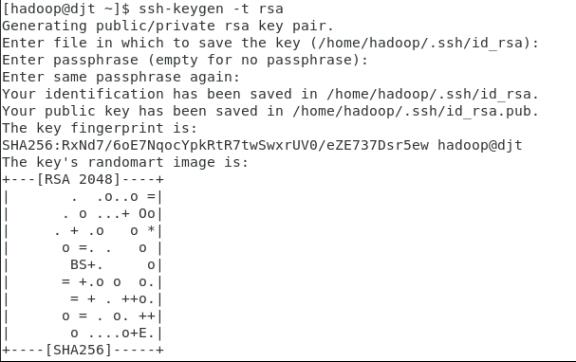
(2)生成密钥对
ssh-keygen -t rsa
(3)公钥文件复制到相同目录下的authorized文件中
cat id_rsa.pub >> authorized_keys
cat authorized_keys

(4)切换到hadoop用户根目录为.ssh目录及文件赋予相应的权限

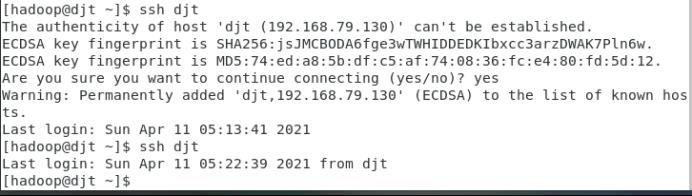
(5)使用ssh命令登录djt,第一次需要输入yes,后边则不用输入,此时设置成功
8.jdk安装
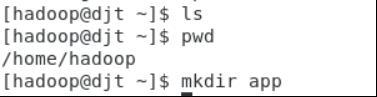
(1)创建jdk安装目录/home/hadoop/app
(2)将jdk安装包从windows拖到虚拟机中的/home/hadoop/app下(拖拽和复制粘贴的方式都试试,有时会没有反应,多复制几次,直到jdk在相应目录下)
(3)解压
tar -zxvf jdk-8u281-linux-x64.tar.gz


(4)创建软连接
ln -s jdk1.8.0_281 jdk

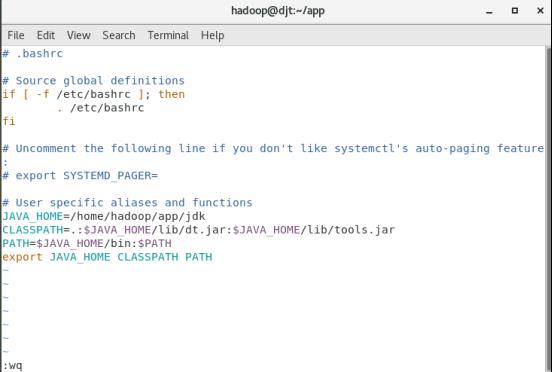
(5)配置环境变量
vi ~/.bashrc
添加:
JAVA_HOME=/home/hadoop/app/jdk
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME CLASSPATH PATH
(6)生效配置文件,并测试
source ~/.bashrc
java -version

9.安装hadoop
(1)将hadoop从windows拖拽或复制到虚拟机 home/hadoop/app目录下
(2)解压
tar -zxvf hadoop-2.10.1.tar.gz


(3)创建软连接
ln -s hadoop-2.10.1 hadoop

(4)配置hadoop环境变量
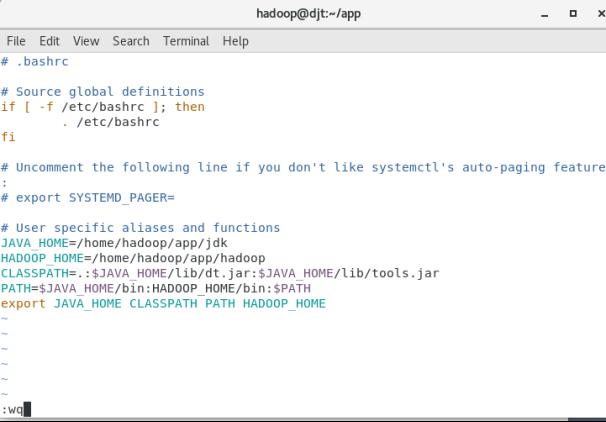
vi ~/.bashrc
JAVA_HOME=/home/hadoop/app/jdk
HADOOP_HOME=/home/hadoop/app/hadoop
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:HADOOP_HOME/bin:$PATH
export JAVA_HOME CLASSPATH PATH HADOOP_HOME
(5)配置生效
source ~/.bashrc
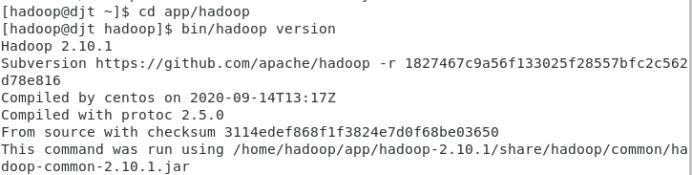
(6)查看hadoop版本号
bin/hadoop version
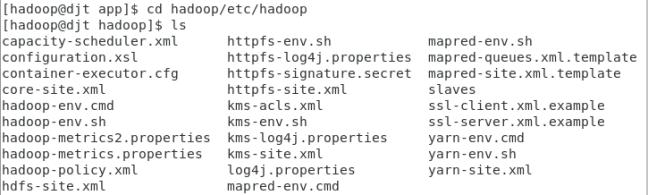
10.修改hadoop配置文件
(1)进入hadoop/etc/hadoop,查看相关配置文件
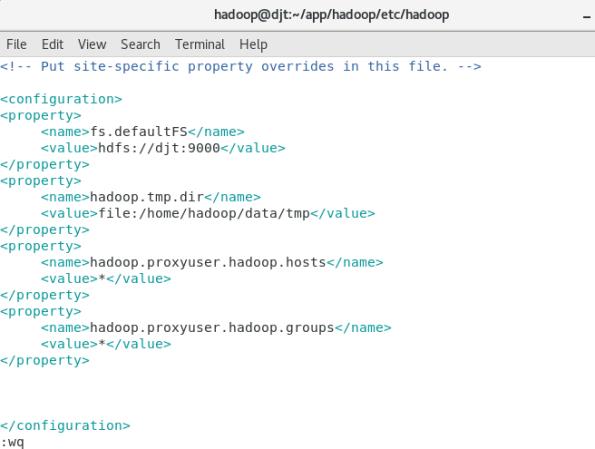
(2)修改 core-site.xml 配置文件
vi core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://djt:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/data/tmp</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
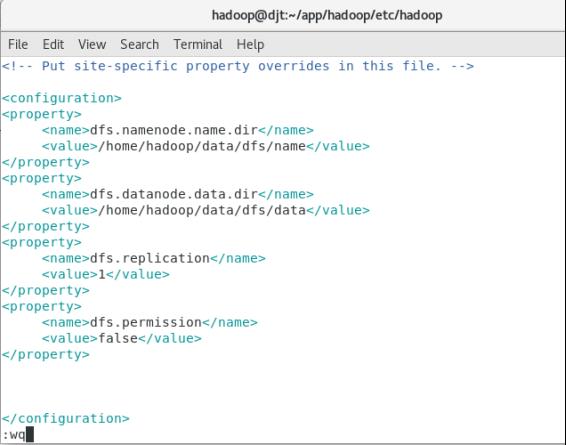
(3)修改hdfs-site.xml配置文件
vi hdfs-site.xml
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/data/dfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/data/dfs/data</value>
<final>true</final>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permission</name>
<value>false</value>
</property>
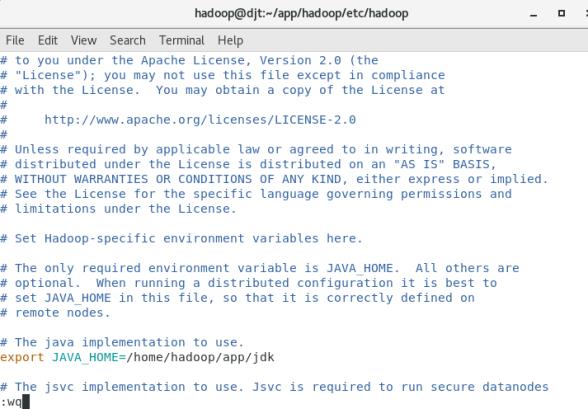
(4)修改hadoop-env.sh配置文件
export JAVA_HOME=/home/hadoop/app/jdk
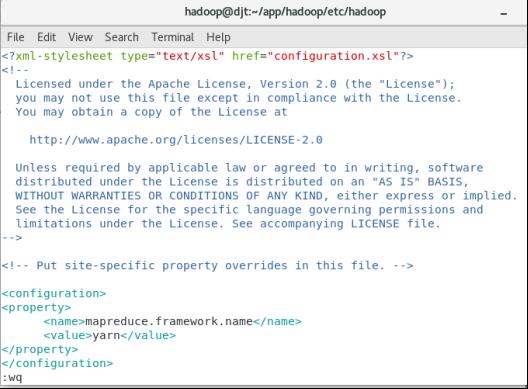
(5)修改mapred-site.xml配置文件
cp ./mapred-site.xml.template ./mapred-site.xml
vi mapred–site.xml

<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
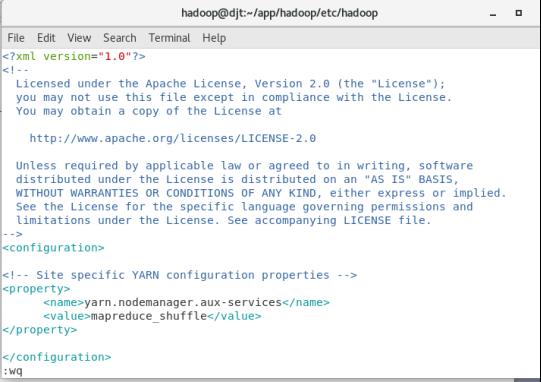
(6)配置yarn-site.xml配置文件
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
(7)修改slaves配置文件
vi slaves
11.创建hadoop相关数据目录,格式化HDFS的namenode

格式化:bin/hadoop namenode -format

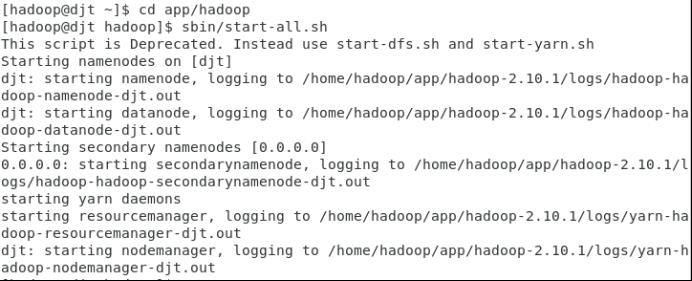
12.启动hadoop
sbin/start-all.sh
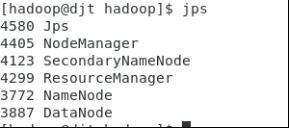
jps查看进程,出现下图即可
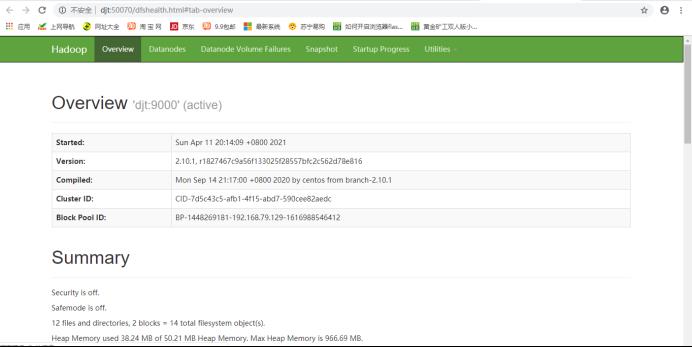
13.页面测试
(1)修改配置文件,在地址c://windows/system32/drivers/etc,找到hosts文件,用记事本打开

(2)添加ip hostname(这里我的是192.168.79.130 djt)

(3)在谷歌浏览器分别输入ip:50070,hostname:50070,ip:8088和hostname:8088进行验证(这里我的ip是192.168.79.130,hostname是djt,要根据自己实际情况测试)
以上是关于Hadoop伪分布集群搭建(Hadoop)的主要内容,如果未能解决你的问题,请参考以下文章