LR(逻辑回归)算法实现
Posted 土味儿大谢
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LR(逻辑回归)算法实现相关的知识,希望对你有一定的参考价值。
现在做的不是做预测某个人未来信用卡支出多少钱这类的预测工作,而是通过对过去的数据去分析哪些因素是信用卡支出的显著影响因素
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
import numpy as np
import pandas as pd
import os
os.getcwd() # 查看工作目录
os.chdir(r"F:\\\\Anaconda3\\\\LR") # 改变工作目录,数据文件要放在这个工作目录里是最简单导入数据的方法
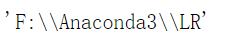
# 导入数据集
data_raw = pd.read_excel("LR_practice.xlsx")#要见名知意的起名,raw data为原始数据
data_raw.info()#查看数据情况

data_raw


# 删除无用变量
data_raw.drop(["id", "Acc", "edad2"], axis = 1, inplace = True)#按列操作axis = 1;inplace=True确定真的要删
筛选哪一列没用哪一列有用,要根据数据字典去筛选
 开始数据清洗的操作(缺失值、异常值、重复值、哑变量)
开始数据清洗的操作(缺失值、异常值、重复值、哑变量)
# 处理重复值
data_raw = data_raw.drop_duplicates()
# 缺失值
data_raw.isnull().mean()#查看缺失值占比

#处理缺失值,推荐用fillna()
data_raw["avg_exp"] = data_raw["avg_exp"].fillna(data_raw["avg_exp"].mean())#用均值去填补缺失值,然后再次运行上面代码,会发现该列缺失值没了

把非数值类型的变为数值类型就是数据编码

# 数据编码 .map(用于向量series)/.apply(用于dataframe)
data_raw["gender"] = data_raw["gender"].map({"Male": 1, "Female": 0})#.map(用于向量series)/.apply(用于dataframe)

label = data_raw["edu_class"].unique().tolist()#unique返回所有元素,tolist转换为列表
data_raw["edu_class"] = data_raw["edu_class"].apply(lambda x: label.index(x))#index返回列表内元素的下标。lambda x: label.index(x):apply前面的元素会传入x,然后用index看传进来的这个元素是在上面的list里面的第几个
#只要我一想到我要对某个变量内每个元素做一个什么对应操作,第一反应就是用apply搭配lambda,因为apply配lambda的作用就是把apply前面的对象里面的每一个元素都拿出来传到lambda函数里,然后告诉这个lambda函数,我要对这些元素做什么操作

# 异常值
#只处理明显异常的值
#处理步骤1、画图;2、通过计算去算三倍标准差看有没有需要处理的异常值
import seaborn
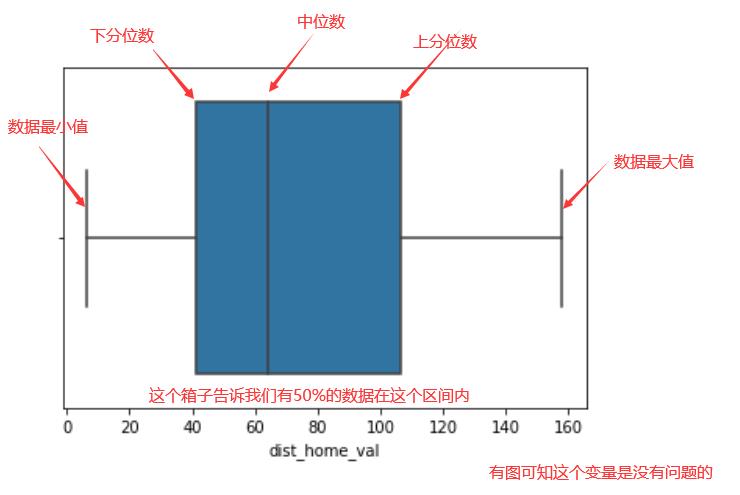
seaborn.boxplot(x = data_raw["dist_home_val"]);#识别异常值的图
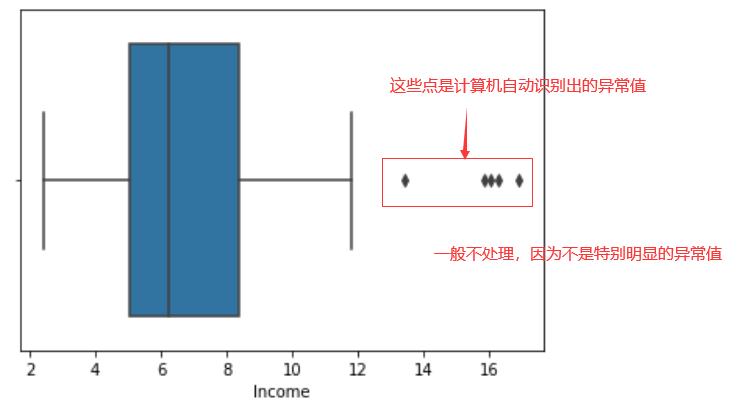
seaborn.boxplot(x = data_raw["Income"]);
seaborn.boxplot(x = data_raw["Age"]);
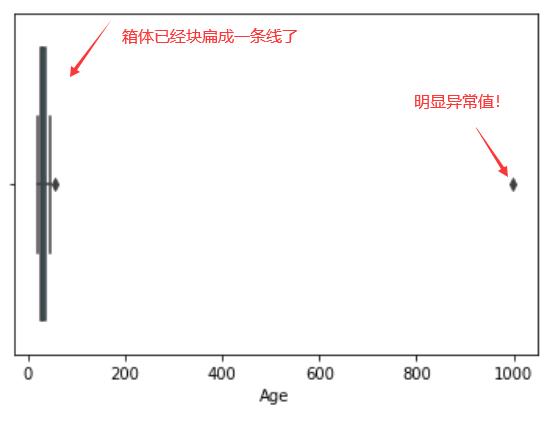
# 筛出3倍标准差以外的值,通常只做一到两次
from scipy import stats#统计学的包
z = np.abs(stats.zscore(data_raw["Age"]))#zscore对谁标准化就把谁放进去。abs取绝对值大于3的就是异常值
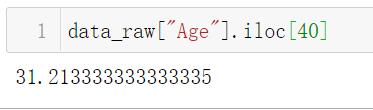
(z > 3).tolist().index(1)#得到True的位置,也就是异常值的位置

data_raw["Age"].iloc[40]

#明显异常值的处理,把异常值替换为均值
data_raw["Age"].iloc[40]=data_raw["Age"].drop(index=40).mean()#把明显异常值去掉算均值,一般情况下只做一次或两次筛选异常值
# 处理哑变量get_dummies
# 为了等下的相关分析,哑变量转换后要生成新的Dataframe,不要覆盖原始数据
dummy = pd.get_dummies(data_raw["edu_class"], prefix = "edu_class").iloc[ : , 1: ]#可以进行哑变量的转换,缺陷是列名没改,prefix可以解决这个缺陷(会根据下标自动命名)。注意要删除一列,除了null那列不能删

data_drop = data_raw.drop("edu_class", axis = 1)#删除edu_class列原始数据后赋值给新的表data_drop
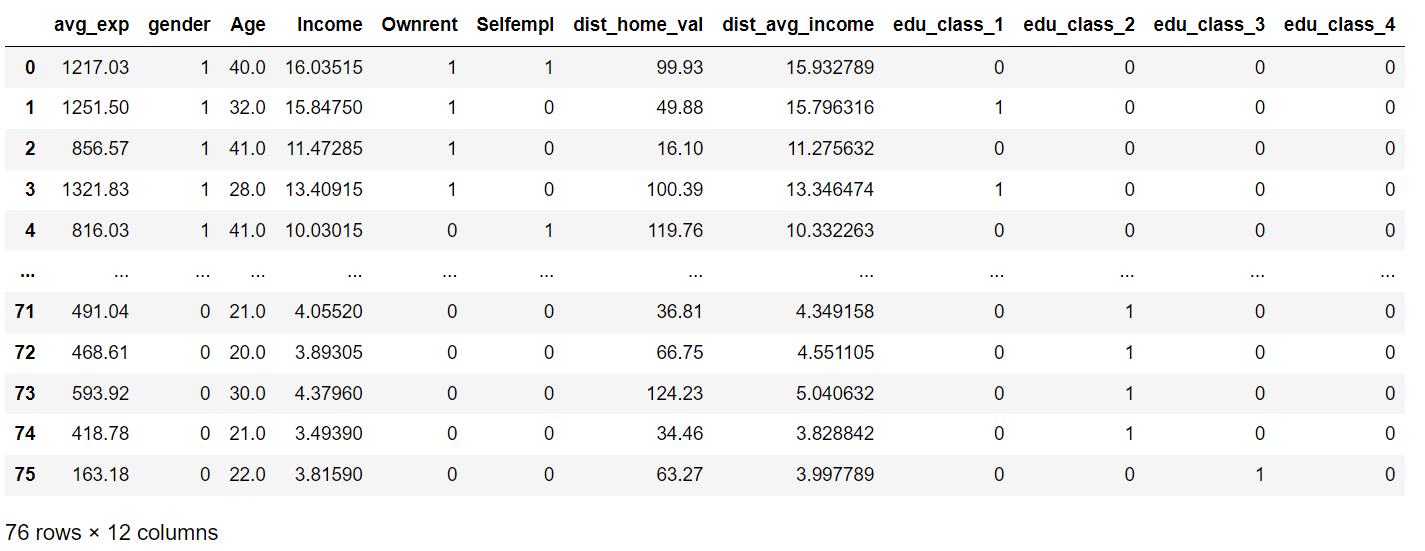
data = pd.concat([data_drop, dummy], axis = 1)#用pd.concat拼接两张表
data#跑回归的时候就用这个表了
 相关分析
相关分析
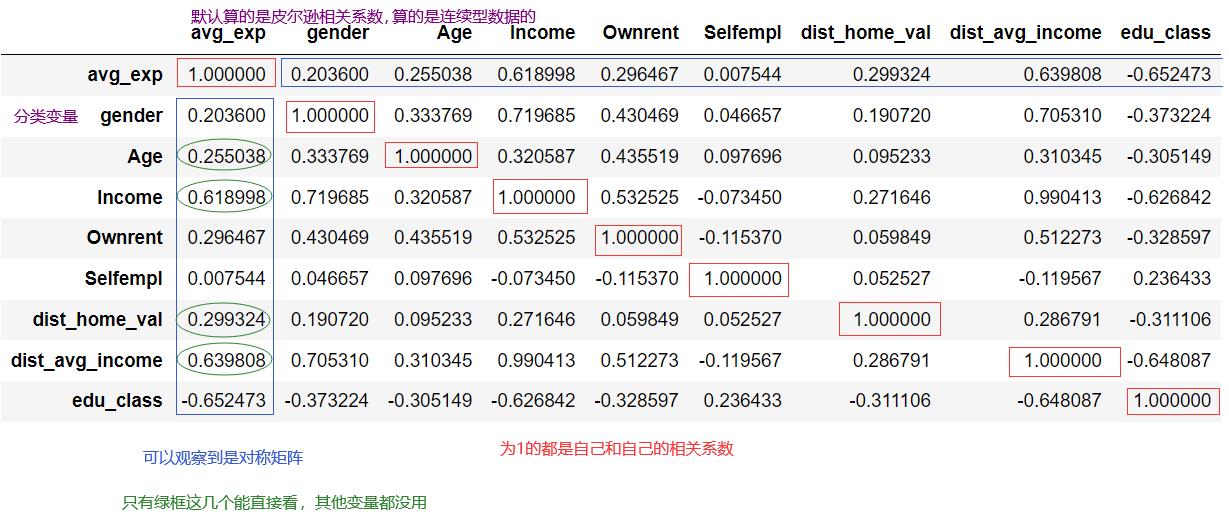
data_raw[["avg_exp", "gender", "Ownrent", "Selfempl", "edu_class"]].corr(method= "kendall")#只显示出所有分类型数据用Kendall相关系数来算
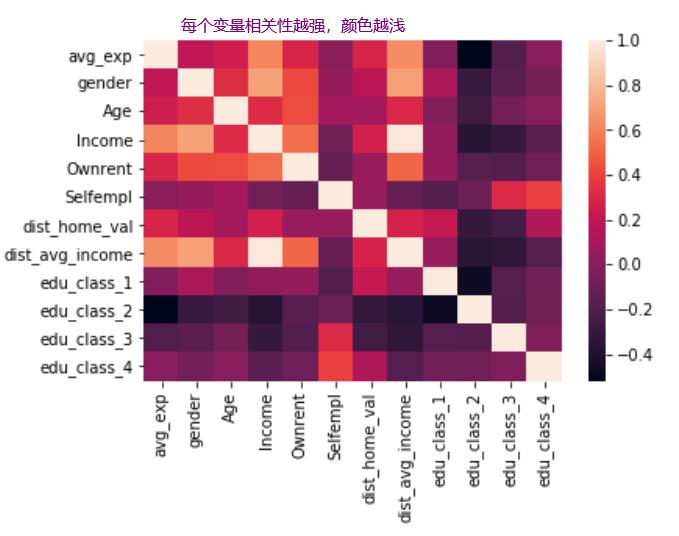
# 热力图 可视化看相关性
seaborn.heatmap(data.corr());
# 散点图scatter
import matplotlib.pyplot as plt
plt.scatter(data["avg_exp"], data["Age"]);#看是否有曲线相关性存在

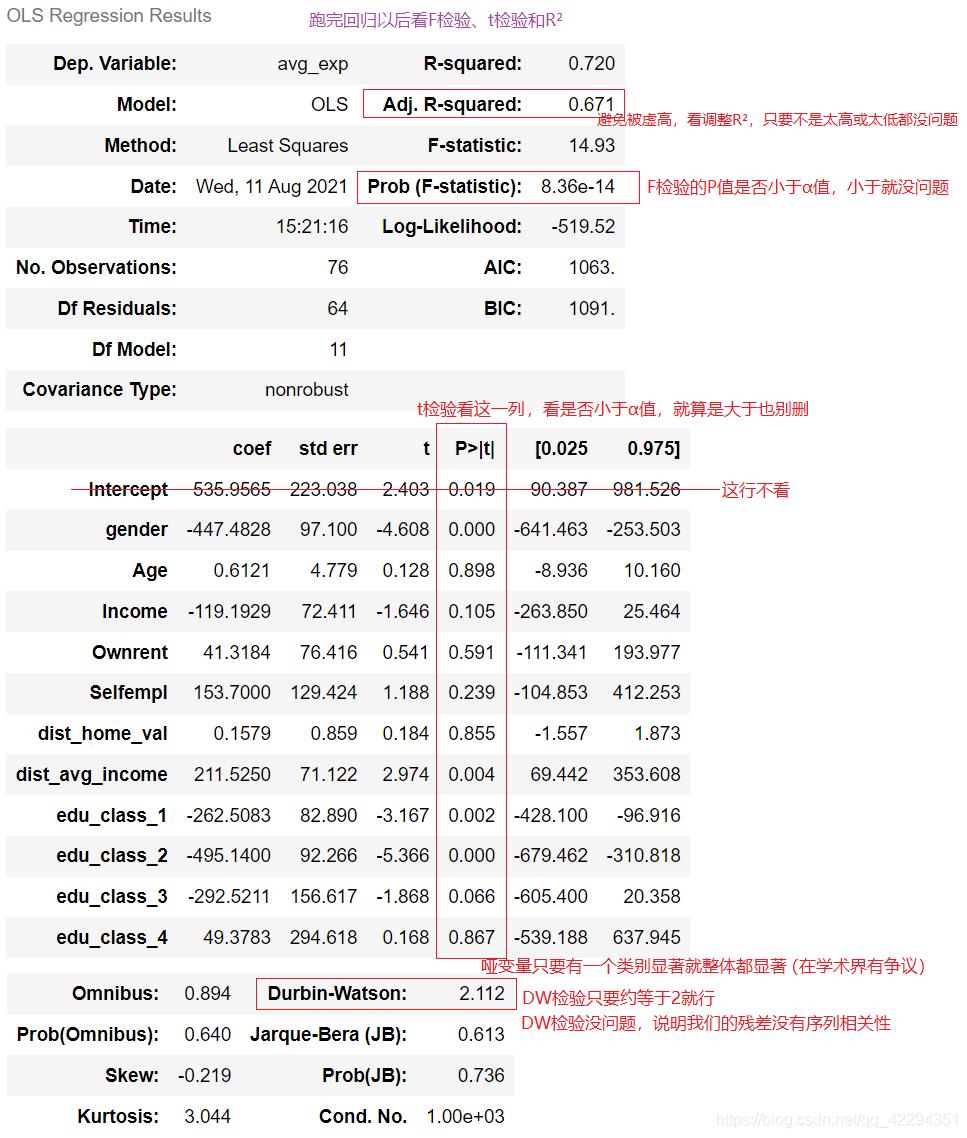
# 回归
from statsmodels.formula.api import ols#ols经典线性回归,dir(ols)可以看这个包里面有什么
#~是等号
LR = "avg_exp ~ gender+Age+Income+Ownrent+Selfempl+dist_home_val+dist_avg_income+edu_class_1+edu_class_2+edu_class_3+edu_class_4"
#做的所有模型只要是用python在做,包括决策树、聚类等,只要调包做模型的时候一定是分成以下三步
model = ols(LR, data) # 第一步:实例化 ols(做谁的回归模型, 数据集)
model = model.fit() # 第二步:拟合数据 所有模型统一用.fit()
model.summary() # 第三步:查看模型结果
# 查看残差
model.resid

# 共线性VIF
from statsmodels.stats.outliers_influence import variance_inflation_factor as vif
data_vif = data.iloc[:, 1:] # 去掉因变量
data_vif["inter"] = 1 # python计算vif值的时候,需要手动添加常数列
data_vif

for i in range(0, data_vif.shape[1]):#.shape(1)返回总列数
print(data_vif.columns[i], "\\t", vif(data_vif.values, i))#vif(数据集,前面数据集的第几列的下标序号)

#重新跑模型,不需要动原始数据,只需要把dist_avg_income从下面式子中剔除出去
LR = "avg_exp ~ gender+Age+Income+Ownrent+Selfempl+dist_home_val+edu_class_1+edu_class_2+edu_class_3+edu_class_4"
model = ols(LR, data) # 实例化
model = model.fit() # 拟合数据
model.summary() # 查看模型结果
#跑完后还是要先看F检验,然后看R²,t检验

# 同方差
# 残差散点图,纵轴是残差,横轴是因变量的拟合值
plt.scatter(model.predict(data), model.resid);#没有喇叭状那些样子所以可以判断同方差没问题;.predict做预测算出拟合值,.resid算残差

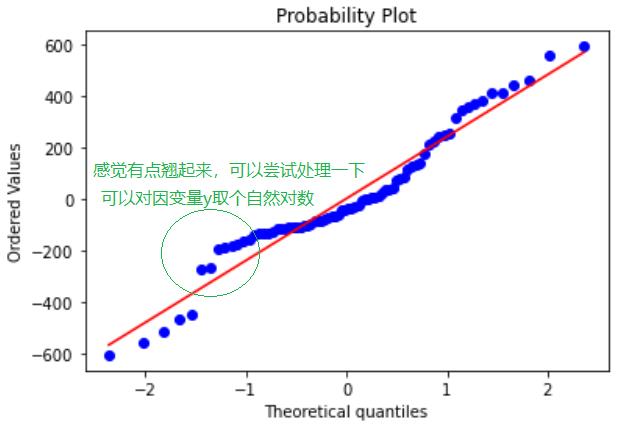
# 正态性 画残差的正态概率图讨论正态性
from scipy import stats#这个包帮助我们去画残差的正态概率图
fig = plt.figure()#实例化一个模型
res = stats.probplot(model.resid, plot = plt)#数据的拟合stats.probplot(数据集, plot = plt)
plt.show()#输出模型
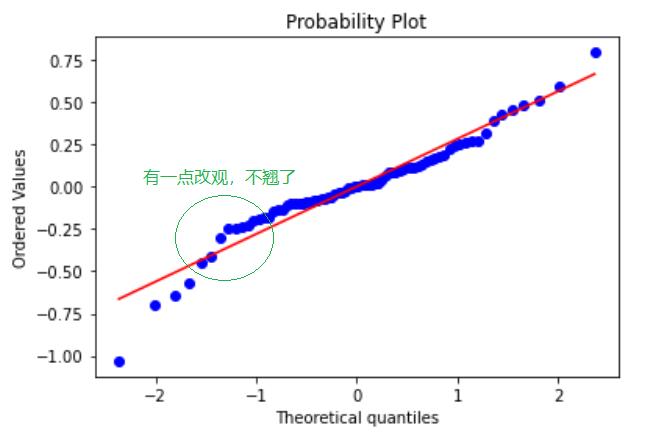
data["ln_avg_exp"] = np.log(data["avg_exp"])#把取过对数的y单独放进一列里
LR = "ln_avg_exp ~ gender+Age+Income+Ownrent+Selfempl+dist_home_val+edu_class_1+edu_class_2+edu_class_3+edu_class_4"
model_ln = ols(LR, data) # 实例化
model_ln = model_ln.fit() # 拟合数据
fig = plt.figure()
res = stats.probplot(model_ln.resid, plot = plt)
plt.show()
高次项
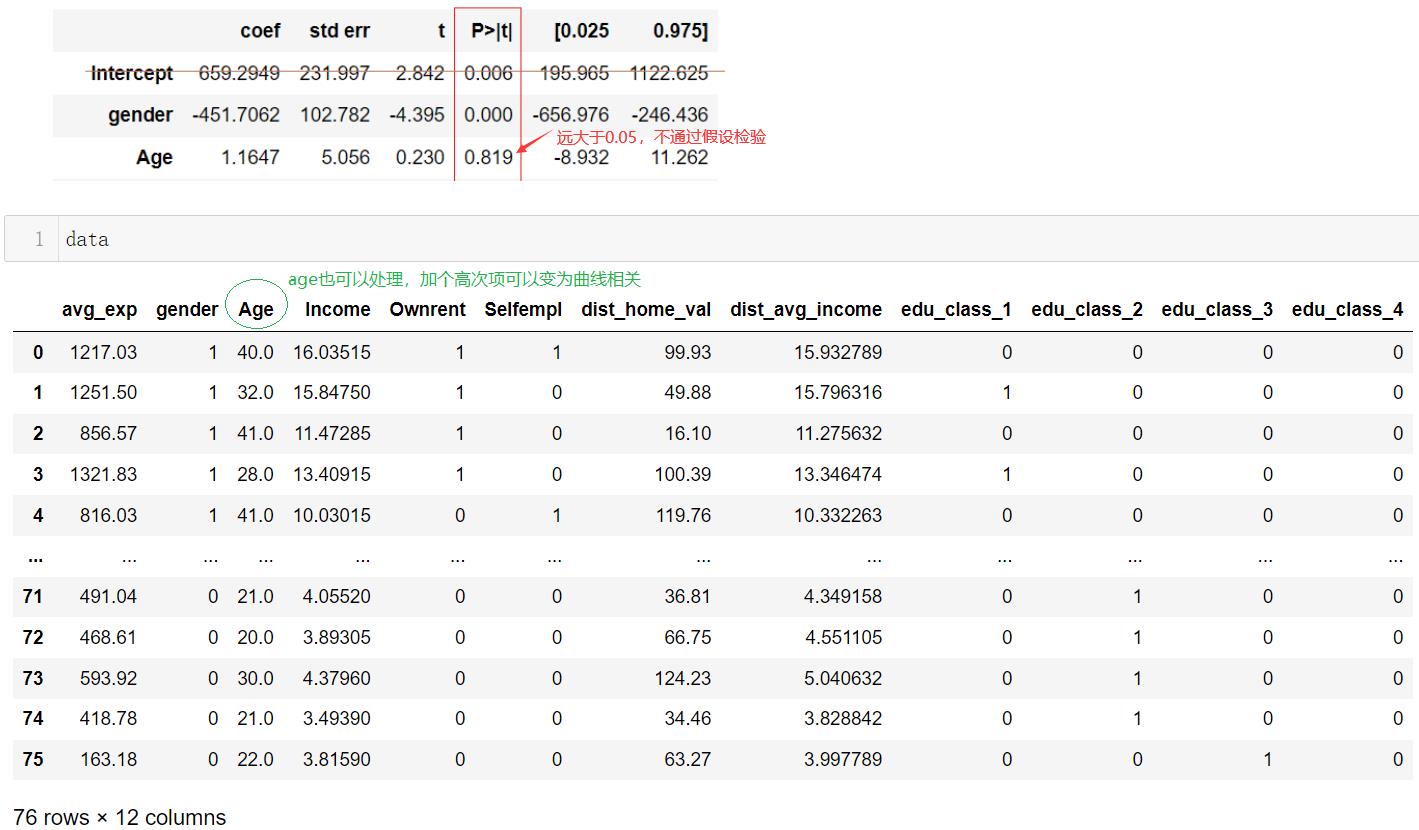
# 高次项
data["Age_sq"]= data["Age"] ** 2
LR = "avg_exp ~ gender+Age+Age_sq+Income+Ownrent+Selfempl+dist_home_val+edu_class_1+edu_class_2+edu_class_3+edu_class_4"
model = ols(LR, data) # 实例化
model = model.fit() # 拟合数据
model.summary() # 查看模型结果

# 交互项(若只做识别,不是必须加入) 如果需要看变量(偏回归系数)的数值大小,这个时候就要考虑是否有交互项
data["AgeGender"] = data["Age"] * data["gender"]
LR = "avg_exp ~ gender+AgeGender+Age+Age_sq+Income+Ownrent+Selfempl+dist_home_val+edu_class_1+edu_class_2+edu_class_3+edu_class_4"
model = ols(LR, data) # 实例化
model = model.fit() # 拟合数据
model.summary() # 查看模型结果
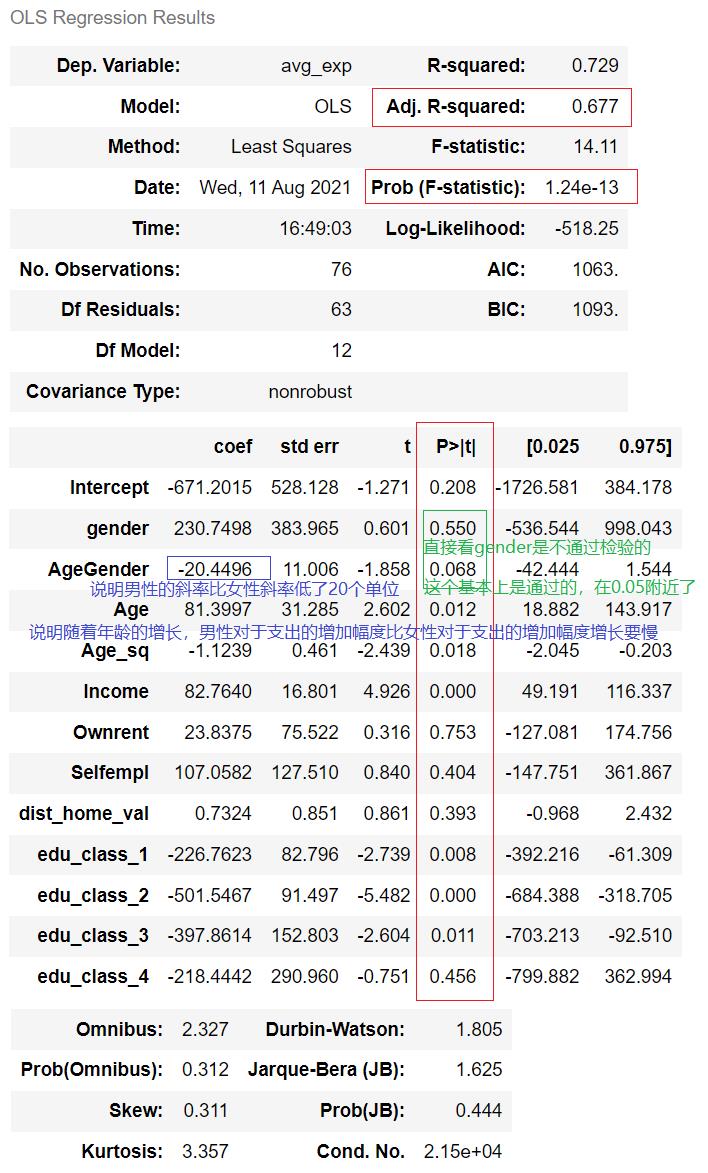
补充:
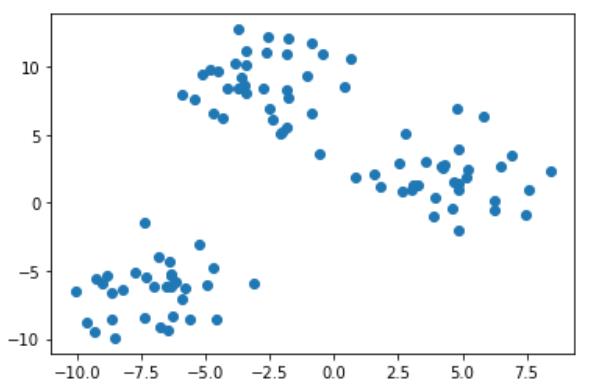
from sklearn.datasets import make_blobs#生成测试类数据的包
import sklearn.datasets#如果想查看,得加载整个库本身
dir(sklearn.datasets)#查看datasets这个库

X, Y = make_blobs(n_features= 2, cluster_std= 2, random_state= 991)#比如生成一个凸的数据集。
#告诉计算机我们现在要生成一个X和一个Y,n_features要生成多少维的数据,cluster_std设置标准差可以让数据更分散,random_state设置随机种子
Z = pd.DataFrame(X)
plt.scatter(Z.iloc[:, 0], Z.iloc[:, 1]);#观察散点图
不分享Excel表数据
以上是关于LR(逻辑回归)算法实现的主要内容,如果未能解决你的问题,请参考以下文章