逻辑回归LR算法LR优缺点LR推导LR损失函数
Posted 小葵花幼儿园园长
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了逻辑回归LR算法LR优缺点LR推导LR损失函数相关的知识,希望对你有一定的参考价值。
逻辑回归
LR–逻辑回归
LR作用?
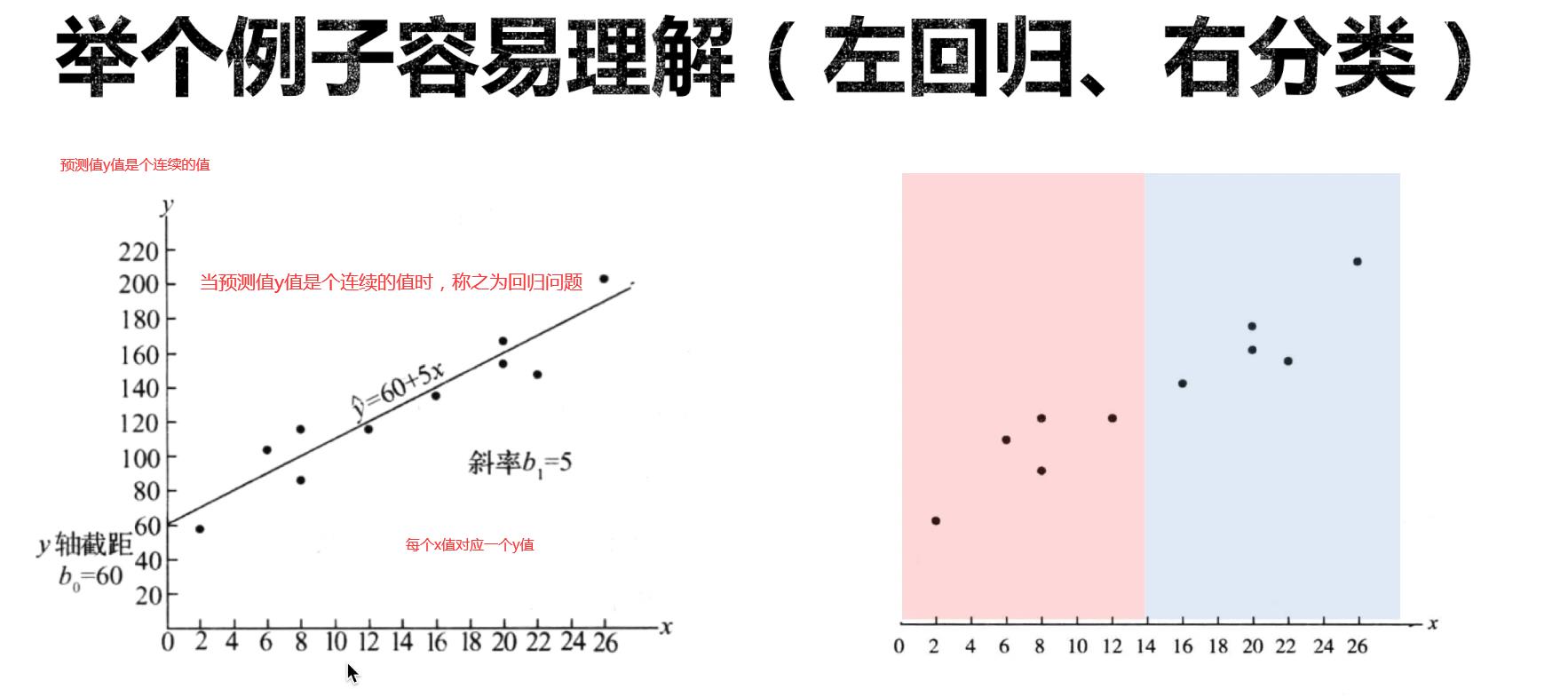
- 常用的处理二分类问题的线性模型
二分类:分类目标只有两种
判断是猪吗-----是、不是
回归和分类的区别?
- 回归模型的输出是连续的
- 分类模型的输出是离散的
逻辑回归函数?
逻辑回归=线性回归+sigmoid函数
线性回归就是用一条直线来拟合自变量和因变量之间的关系
把回归变成分类?
- sigmoid函数
参考:sigmoid
将y压缩为0-1,y小于0–变成[0,0.5],y大于0–变成[0.5,1]

- 逻辑回归:把线性函数的输出z,当做sigmoid函数的输入,最后得到y。当
y
∈
[
0
,
0.5
]
y\\in[0,0.5]
y∈[0,0.5]
否,当 y ∈ [ 0 , 1 ] y\\in[0,1] y∈[0,1]是 - 逻辑回归函数:
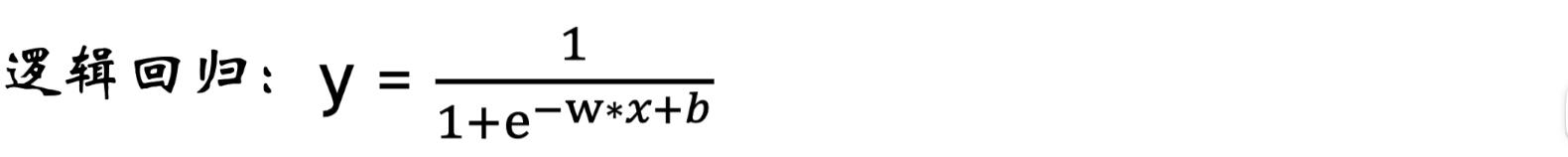
如何去求解出好的参数? - 利用到好的损失函数
逻辑回归损失函数?
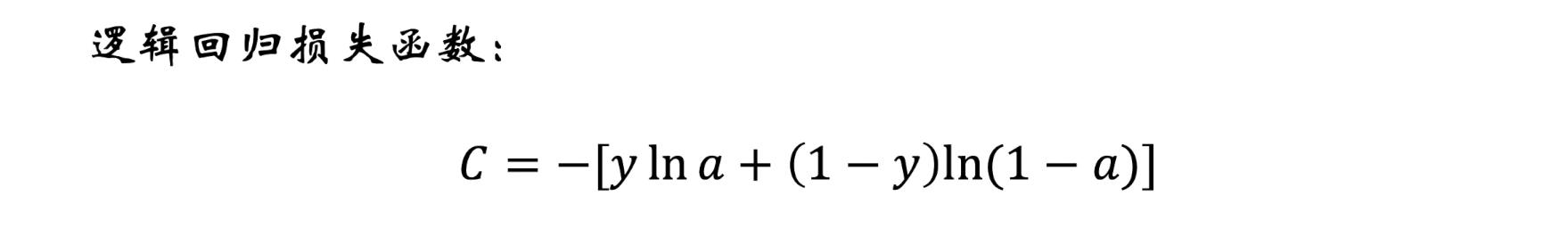
- 损失函数是体现“预测值”与“实际值”相似程度的函数
- 损失函数越小,模型越好
解读损失函数
- 其中y表示样本的真实标签,(0或1)
- a表示预测的结果是0或者1的概率,a的取值范围为[0,1]
- 对于上述损失函数,分开讨论两种预测结果—(正|反)
- 正:y=1,loss=-yIna,当a越接近1时,yIna越大,loss越小
- 负同理
LR的推导?
我们采用𝑦 ∈ 0, 1 以符合Logistic 回归的描述习惯.
为了解决连续的线性函数不适合进行分类的问题,我们引入非线性函数
𝑔
∶
R
𝐷
→
(
0
,
1
)
𝑔 ∶ℝ^𝐷 → (0, 1)
g∶RD→(0,1)来预测类别标签的后验概率𝑝(𝑦 = 1|𝒙).
𝑝
(
𝑦
=
1
∣
𝒙
)
=
𝑔
(
𝑓
(
𝒙
;
𝒘
)
)
𝑝(𝑦 = 1|𝒙) = 𝑔(𝑓(𝒙; 𝒘))
p(y=1∣x)=g(f(x;w))
其中𝑔(⋅) 通常称为激活函数(Activation Function),其作用是把线性函数的值域从实数区间“挤压”到了(0, 1) 之间,可以用来表示概率.
在Logistic 回归中,我们使用Logistic 函数来作为激活函数.标签𝑦 = 1 的后验概率为
𝑝(𝑦 = 1|𝒙)=𝜎(𝒘T𝒙) ≜
1
1
+
e
x
p
(
−
𝒘
T
𝒙
)
\\frac11 + exp(−𝒘^T𝒙)
1+exp(−wTx)1
为简单起见,这里
𝒙
=
[
𝑥
1
,
⋯
,
𝑥
𝐷
,
1
]
T
𝒙 = [𝑥_1, ⋯ , 𝑥_𝐷, 1]^T
x=[x1,⋯,xD,1]T和
𝒘
=
[
𝑤
1
,
⋯
,
𝑤
𝐷
,
𝑏
]
T
𝒘 = [𝑤_1, ⋯ , 𝑤_𝐷, 𝑏]^T
w=[w1,⋯,wD,b]T分别为𝐷 + 1 维的增广特征向量和增广权重向量.
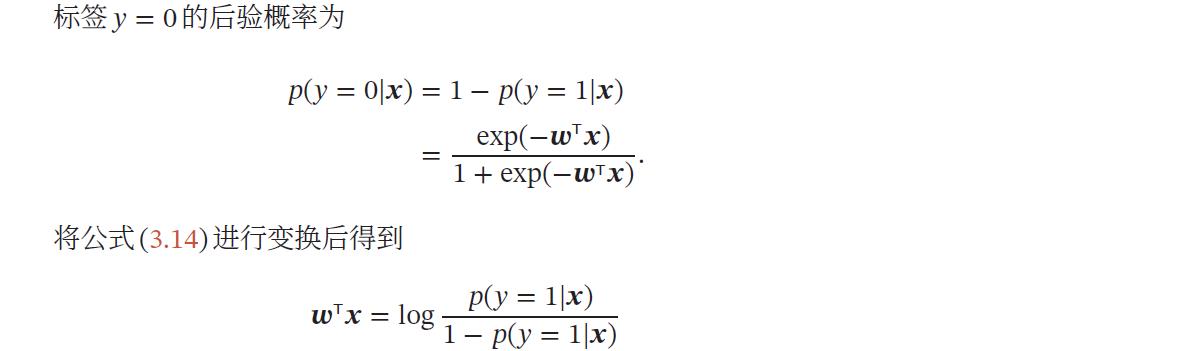
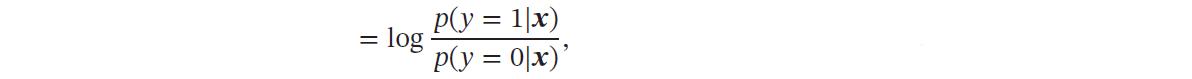
LR和线性回归的区别
- 逻辑回归=线性回归+sigmoid函数
线性回归是用一条直线来拟合自变量和因变量之间的关系(做预测)逻辑回归是来解决二分类问题的(做分类)
逻辑回归怎么实现多分类?
One-Vs-All
- 思想:
把一个多分类问题变成多个二分类问题。 - 思路:选择其中一个类别为正类(Positive),使其他所有类别为负类(Negative)。然后一个接一个
- 缺点:训练集样本数量不平衡
One-Vs-One
- 思想:
One-Vs-One是一种相对稳健的扩展方法。对于同样的三分类问题,我们像举行车轮作战一样让不同类别的数据两两组合训练分类器,可以得到 3 个二元分类器。 - 缺点:训练出更多的 Classifier,会影响预测时间。
Softmax
- 逻辑回归使用sigmoid激活函数,映射到【0,1】之间的数值上
- 使用
Softmax让一个样本映射到多个【0,1】之间的数值上 Softmax使得所有概率之和为1,对概率分布归一化
优缺点
优点:
对数据中小噪声的鲁棒性好;
LR 算法已被广泛应用于工业问题中;
多重共线性并不是问题,它可结合正则化来解决。
LR算法的缺点:
对于非线性特征,需要转换
当特征空间很大时,LR的性能并不是太好
以上是关于逻辑回归LR算法LR优缺点LR推导LR损失函数的主要内容,如果未能解决你的问题,请参考以下文章