全国大学生大数据技能竞赛(Hadoop集群搭建)
Posted 鈴音.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了全国大学生大数据技能竞赛(Hadoop集群搭建)相关的知识,希望对你有一定的参考价值。
文章目录
前言
本篇博客将根据往年全国大学生大数据技能竞赛的资料和今年的培训来Hadoop搭建,每一个步骤都有相应的执行的截图。以下博客仅作为个人搭建Hadoop过程的记录~如有不足之处欢迎指出,共同学习进步。附上资料链接。
资料链接
第四届全国大学生大数据技能竞赛中关于搭建Hadoop集群的培训链接:
https://www.qingjiaoclass.com/market/detail/4486
所有环境工具百度网盘链接:
https://pan.baidu.com/s/1oOW7WqHK4fiqv4Xja5f7gQ
提取码:vvi7
在自己练习搭建Hadoop集群时尽量每一步都拍快照,防止出现错误解决不了然后不得不重新搭建,非常麻烦
用VMware练习配置前准备三台虚拟机并修改网络为桥接
1.暂时关闭防火墙和selinux
systemctl stop firewalld
setenforce 0
2.永久关闭
systemctl disable firewalld
vi /etc/sysconfig/selinux

2.配置网络桥接模式修改静态ip地址
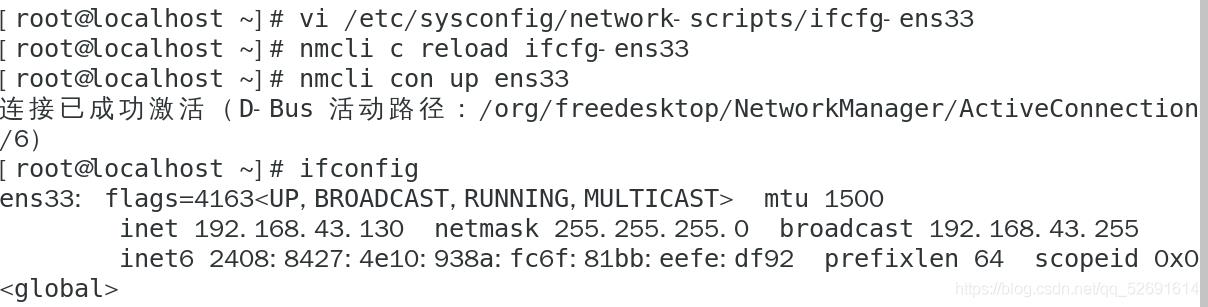
vi /etc/sysconfig/network-scripts/ifcfg-ens33
nmcli c reload ifcfg-ens33
nmcli con up ens33
ifconfig

3.克隆两台虚拟机,并修改IP地址
克隆虚拟机
修改克隆的两台虚拟机ip分别为
192.168.43.140,192.168.43.150
打开SecureCRT,远程登录三台虚拟机
01本地源YUM


02基础环境配置
1.防火墙
systemctl stop firewalld
systemctl status firewalld
2.主机名与映射
2.1修改主机名
本次集群搭建共有三个节点,包括一个主节点master,和两个从节点slave1和slave2。需要把三个节点的主机名分别修改。
1.以主机点master为例,首次切换到root用户:su
2.修改主机名为master:
hostnamectl set-hostname master
3.立即生效:
bash

4.若要永久修改主机名,编辑/etc/sysconfig/network文件
vi /etc/sysconfig/network
内容如下:
NETWORKING=yes
HOSTNAME=master

保存该文件,重启计算机:reboot
查看是否生效:hostname
2.2添加映射
使各个节点能使用对应的节点主机名连接对应的地址。
hosts文件主要用于确定每个结点的IP地址,方便后续各结点能快速查到并访问。在上述3个虚机结点上均需要配置此文件。
vi /etc/hosts

3.时间同步
3.1时区
1.查看自己机器时间:
date
2.选择时区:
tzselect

3.2时间同步协议NTP
1.3台机器安装ntp:
yum install -y ntp

2.master作为ntp服务器,修改ntp配置文件。(master上执行)
vi /etc/ntp.conf
找到第58行,也就是最后一行
添加
server 127.127.1.0
fudge 127.127.1.0 stratum 10

3.重启ntp服务。
/bin/systemctl restart ntpd.service

4.其他机器同步(slave1,slave2)
等待大概五分钟,再到其他机上同步该机器时间。
ntpdate master


4.定时任务crontab
4.1描述
- 星号(*):代表所有可能的值,例如month字段如果是星号,则表示在满足其它字段的制约条件后每月都执行该命令操作。
- 逗号(,):可以用逗号隔开的值指定一个列表范围,例如,“1,2,5,7,8,9”
- 中杠(-):可以用整数之间的中杠表示一个整数范围,例如“2-6”表示“2,3,4,5,6”
- 正斜线(/):可以用正斜线指定时间的间隔频率,例如“0-23/2”表示每两小时执行一次。
- 同时正斜线可以和星号一起使用,例如*/10,如果用在minute字段,表示每十分钟执行一次

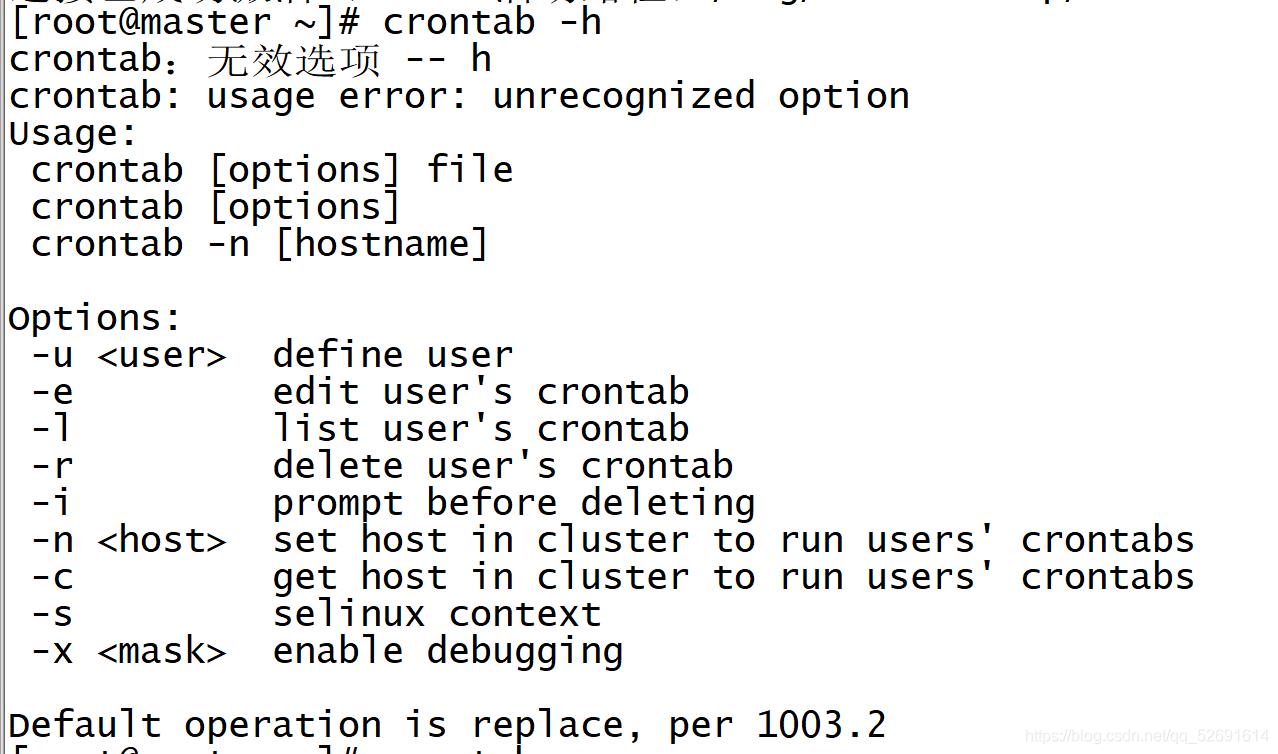
输入
crontab -h
可查看命令相关操作
4.2案例:定时任务
要求:每10min执行一次
写一个定时任务:
crontab -e
键入 i ,进入编辑模式
输入内容:
*/10 * * * * usr/sbin/ntpdate master

查看定时任务列表:
crontab -l

03远程登录ssh
为了让主结点master能通过SSH免密码登录两个子结点slave。
1.三台机器分别执行
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa

2.只在master节点执行
cd .ssh/
ls
id_dsa.pub为公钥,id_dsa为私钥

3.将公钥文件复制成authorized_keys文件:(仅master)
cat id_dsa.pub >> authorized_keys
验证ssh内回环
ssh master
输入yes
exit
ssh master#这一次不用输入yes验证

4.在master节点执行以下命令:
scp ./authorized_keys root@slave1:~/.ssh/
scp ./authorized_keys root@slave2:~/.ssh/

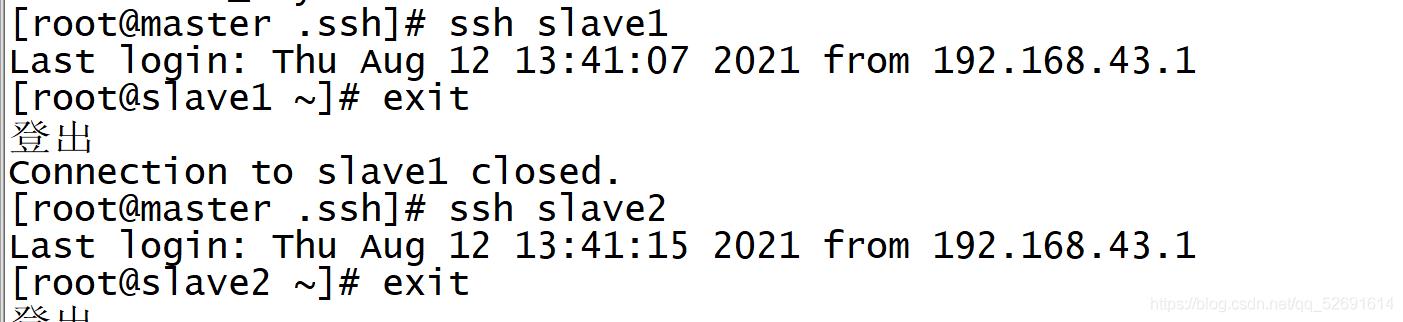
5.验证ssh免密登录
ssh slave1
exit
04语言环境–Java
4.1安装JDK
三台虚拟机都需安装
1.建立工作路径
mkdir -p /usr/java
2.把文件传输到本地根目录(我用的secureCRT)
到Windows下先复制jdk的安装包,点击箭头所指的那个,然后右键粘贴,等待文件传输完成。

3.解压缩
tar -zxvf jdk-8u171-linux-x64.tar.gz -C /usr/java/
4.修改环境变量
vi /etc/profile
在文件第55行添加以下内容
export JAVA_HOME=/usr/java/jdk1.8.0_171
export PATH=$PATH:$JAVA_HOME/bin

生效文件和查看jdk版本
source /etc/profile
java -version

安装的jdk版本和自己安装的一样,安装成功!
4.2安装完jdk后jdk版本和自己安装的不一样
请看这篇博文,相信你能解决问题!
安装完jdk后jdk版本和自己安装的不一样怎么办?
05协调服务zookeeper安装
注意:第1步在三台虚拟机进行,2~10步在master虚拟机进行,11步在 slave1,slave2虚拟机进行,12步在三台虚拟机进行
1.修改主机名称到ip地址映射配置(三台虚拟机)
vi /etc/hosts
192.168.43.130 master master.root
192.168.43.140 slave1 slave1.root
192.168.43.150 slave2 slave2.root

2.上传zookeeper安装包到虚拟机根目录
3.新建目录
mkdir -p /usr/zookeeper

4.解压缩
tar -zxvf zookeeper-3.4.10.tar.gz -C /usr/zookeeper/
5.修改/etc/profile文件,配置zookeeper环境变量。
vi /etc/profile
在第58行添加
export ZOOKEEPER_HOME=/usr/zookeeper/zookeeper-3.4.10
PATH=$PATH:$ZOOKEEPER_HOME/bin

6.进入zookeeper配置文件夹conf,将zoo_sample.cfg文件拷贝一份命名为zoo.cfg
cd /usr/zookeeper/zookeeper-3.4.10/conf/
cp -p zoo_sample.cfg zoo.cfg

7. 配置文件zoo.cfg
vi zoo.cfg
修改第12行为
dataDir=/usr/zookeeper/zookeeper-3.4.10/zkdata

在第29行,也就是文件末尾,添加以下内容
dataLogDir=/usr/zookeeper/zookeeper-3.4.10/zkdatalog
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888

8.在zookeeper的目录中,创建配置中所需的zkdata和zkdatalog两个文件夹。
mkdir zkdata
mkdir zkdatalog

9.进入zkdata文件夹,创建文件myid,用于表示是几号服务器。master主机中,设置服务器id为1。
cd zkdata
vi myid

10.以上已经在主节点master上配置完成ZooKeeper,现在可以将该配置好的安装文件远程拷贝到集群
中的各个结点对应的目录下(这时候子节点):
scp -r /usr/zookeeper root@slave1:/usr/
scp -r /usr/zookeeper root@slave2:/usr/
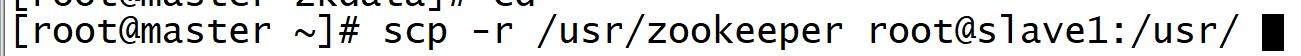
11.配置文件myid文件,slave1为2,slave2为3
cd /usr/zookeeper/zookeeper-3.4.10/zkdata
vi myid


12.启动zookeeper集群
每台虚拟机要先进入zookeeper目录下
cd /usr/zookeeper/zookeeper-3.4.10/
再分别执行
bin/zkServer.sh start
bin/zkServer.sh status
一个节点是leader,其余节点是follower,就安装成功啦~



06.Hadoop安装
6.1解压安装包,配置环境变量
1.把Hadoop安装包拷贝到根目录,创建工作目录,解压Hadoop安装包
mkdir –p /usr/hadoop
tar -zxvf hadoop-2.7.3.tar.gz -C /usr/hadoop/
2.配置环境变量,修改/etc/profile文件
vi /etc/profile
在第60行添加
#HADOOP
export HADOOP_HOME=/usr/hadoop/hadoop-2.7.3
export CLASSPATH=$CLASSPATH:$HADOOP_HOME/lib
export PATH=$PATH:$HADOOP_HOME/bin

3.生效配置文件
source /etc/profile
6.2配置Hadoop各组件

1.进入Hadoop的/etc/hadoop目录
cd /usr/hadoop/hadoop-2.7.3/etc/hadoop

2.编辑hadoop-env.sh文件
vi /hadoop-env.sh
在第28行添加以下内容
export JAVA_HOME=/usr/java/jdk1.8.0_171

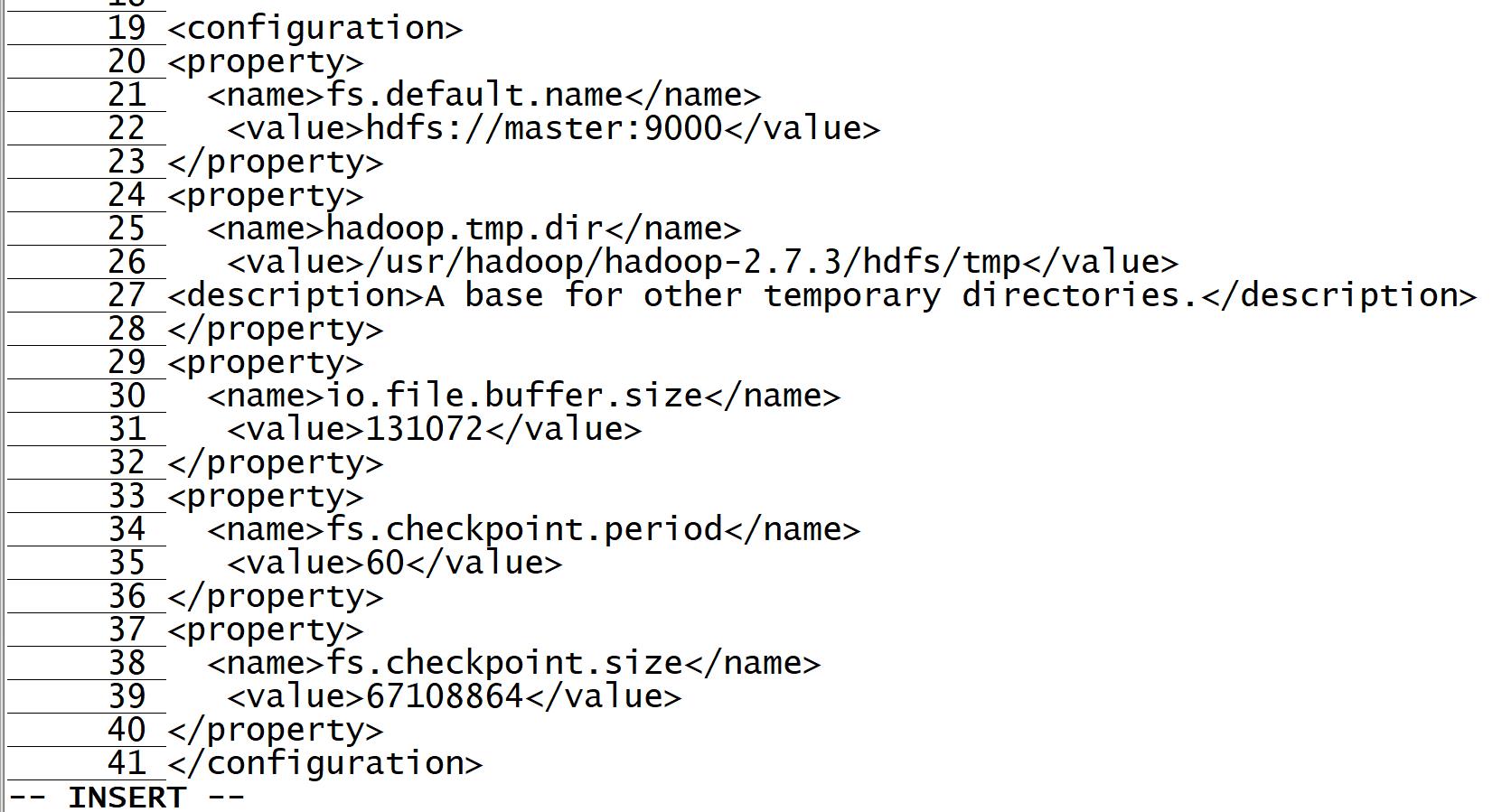
3.编辑core-site.xml
vi core-site.xml
添加以下内容
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/hadoop-2.7.3/hdfs/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>fs.checkpoint.period</name>
<value>60</value>
</property>
<property>
<name>fs.checkpoint.size</name>
<value>67108864</value>
</property>
</configuration>
4.编辑yarn -site.xml
vi yarn-site.xml
<property>
<name>yarn.resourcemanager.address</name>
<value>master:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name> <value>master:18030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:18088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<property>
<name>yarn.resourcemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.shuffleHandler</value>
</property>

5.编辑hdfs-site.xml
vi hdfs-site.xml
添加以下内容
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/hadoop/hadoop-2.7.3.hdfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/hadoop/hadoop-2.7.3/hdfs/data</value>
<final>true</final>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>

6.编辑mapred-site.xml
hadoop是没有这个文件的,需要将mapred-site.xml.template复制为mapredsite.xml。
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml

添加以下内容
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>

7.设置节点文件
vi slaves

vi master

8.分发hadoop
scp -r /usr/hadoop root@slave1:/usr/
scp -r /usr/hadoop root@slave2:/usr/
9.hdfs格式化(master虚拟机执行)
hadoop namenode -format
出现下面这句话时,恭喜你~格式化成功!

6.3开启集群
仅在master主机上开启操作命令。它会带起从节点的启动。
开启集群:
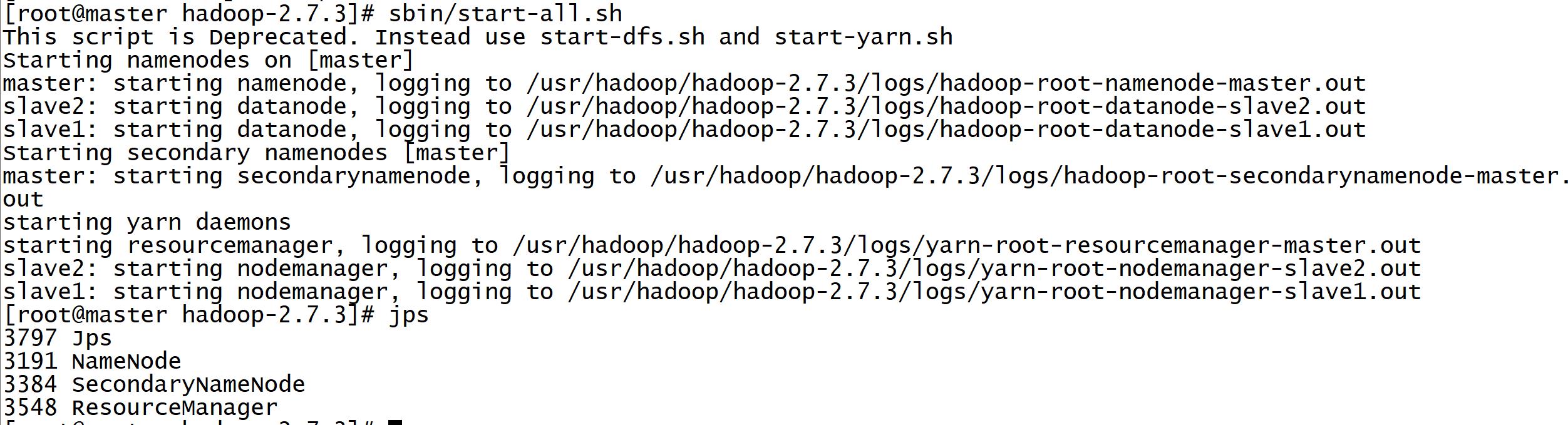
进入到Hadoop目录下执行:
sbin/start-all.sh
或者
start-all.sh start
查看进程:
jsp
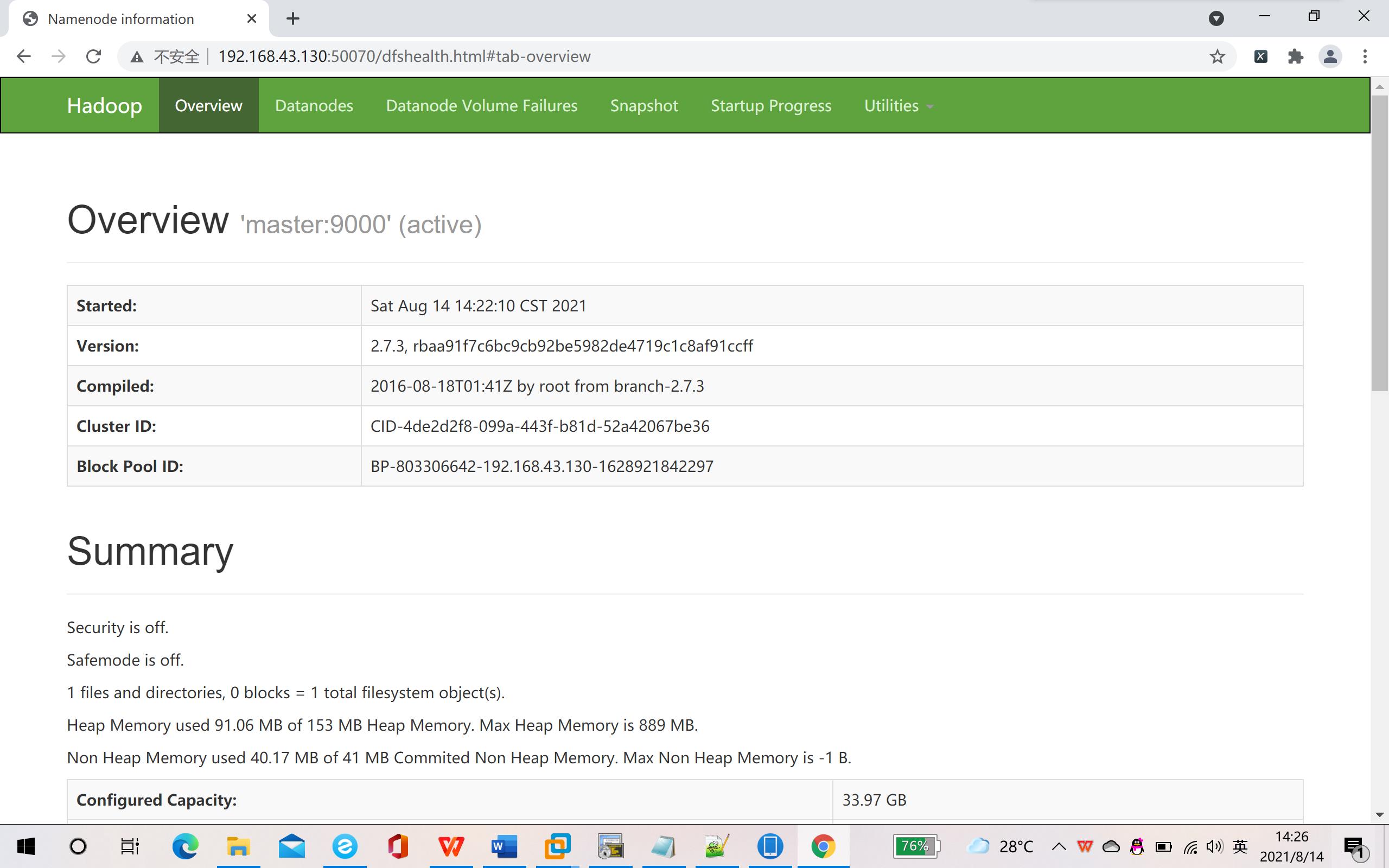
11.浏览器访问:masterIP:50070
出现以下页面表面搭建成功~~
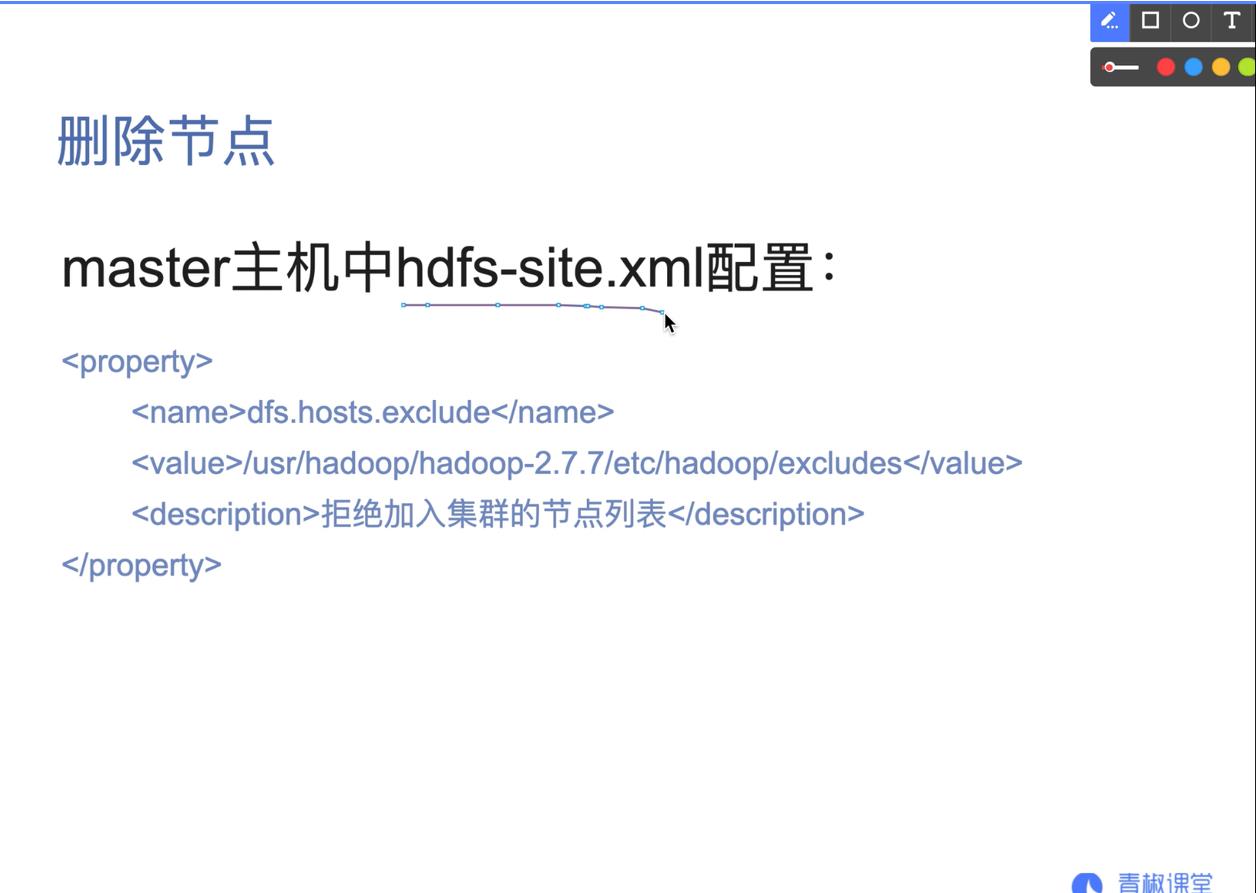
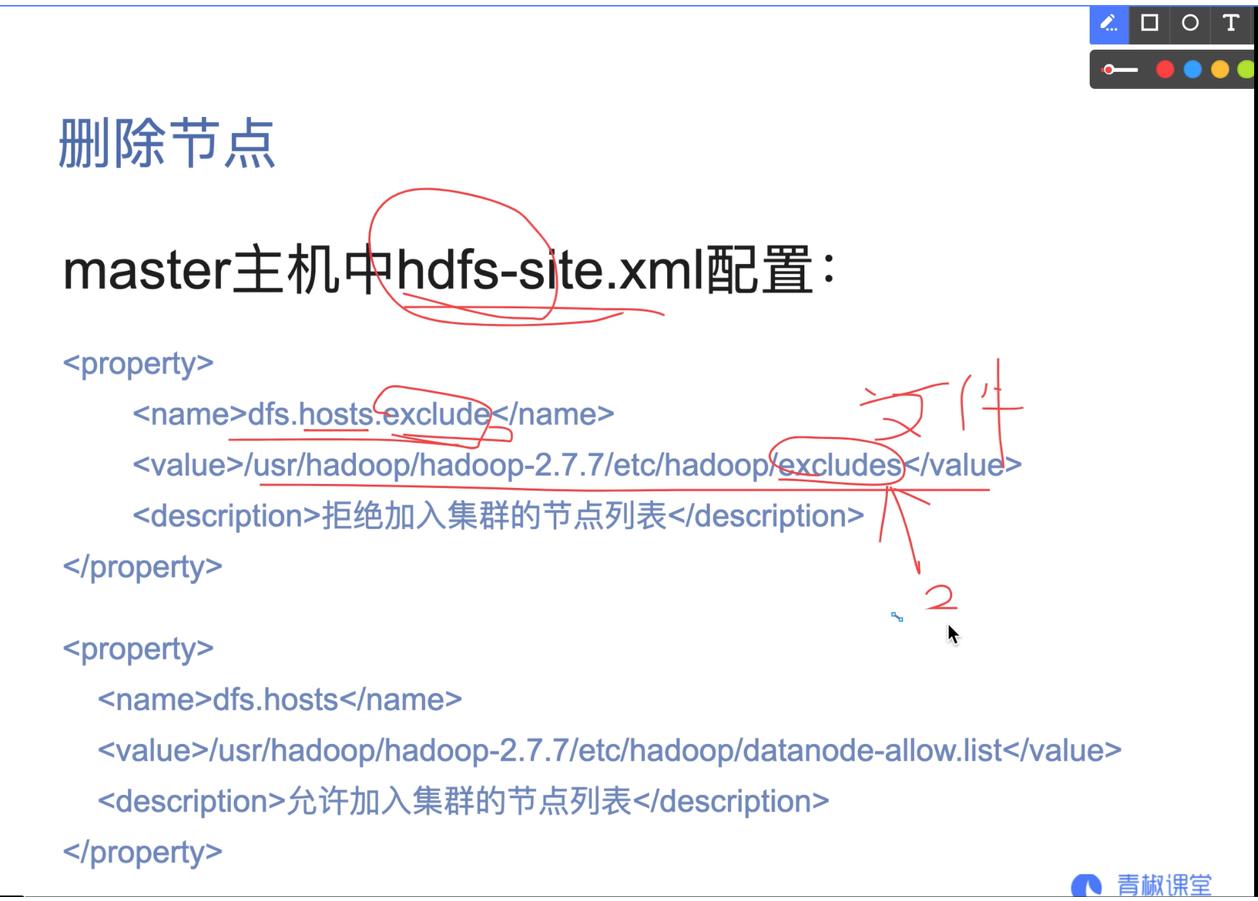
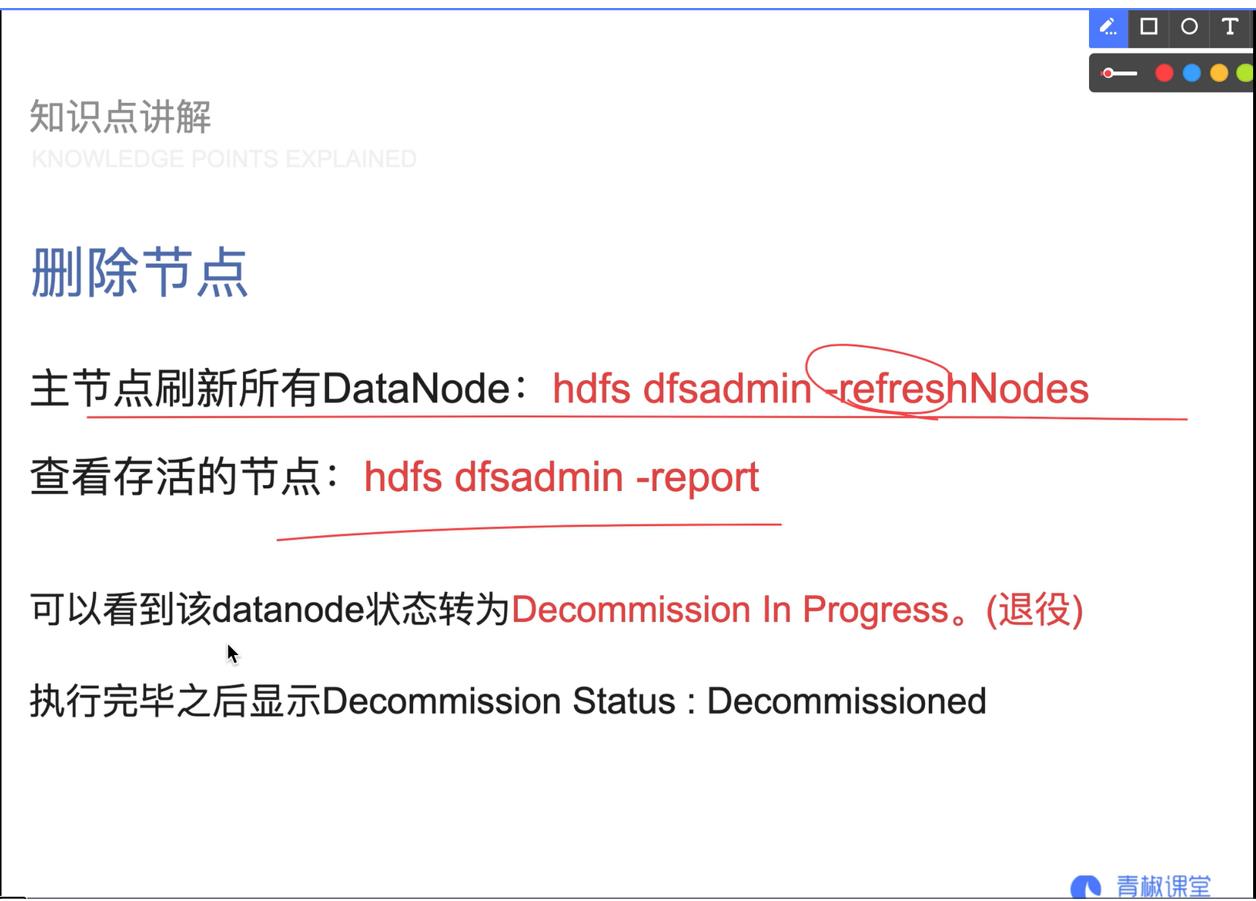
07.添加删除节点






以上是关于全国大学生大数据技能竞赛(Hadoop集群搭建)的主要内容,如果未能解决你的问题,请参考以下文章