大数据分析师实操练习(Hadoop完全分布式集群搭建)
Posted TianCMCC
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据分析师实操练习(Hadoop完全分布式集群搭建)相关的知识,希望对你有一定的参考价值。
练习内容:
- 安装并配置Hadoop相关环境;
- 相关配置文件,并确定master为namenode,slave1和slave2为datanode;
- 配置Yarn运行环境;
- 设置Yarn核心参数;
- 格式化HDFS,开启Hadoop完全分布式集群。
1. 将对应软件包解压到指定路径/usr/hadoop:
在master、slave1、slave2上操作以下三个步骤:
- 创建 /usr/hadoop 目录:
mkdir /usr/hadoop - 切换至hadoop安装包所在目录:
cd /usr/package/ - 解压缩至指定路径:
tar -zxvf hadoop-2.7.3.tar.gz -C /usr/hadoop
2. 配置Hadoop环境变量
在master、slave1、slave2上操作:
vim /etc/profile
=== 添加以下内容 ===
#HADOOP_HOME
export HADOOP_HOME=/usr/hadoop/hadoop-2.7.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
使文件生效:source /etc/profile
3. 配置Hadoop运行环境hadoop-env.sh
在master、slave1、slave2上操作:
- 切换至Hadoop环境目录:
cd /usr/hadoop/hadoop-2.7.3/etc/hadoop - 修改hadoop-env.sh内容:
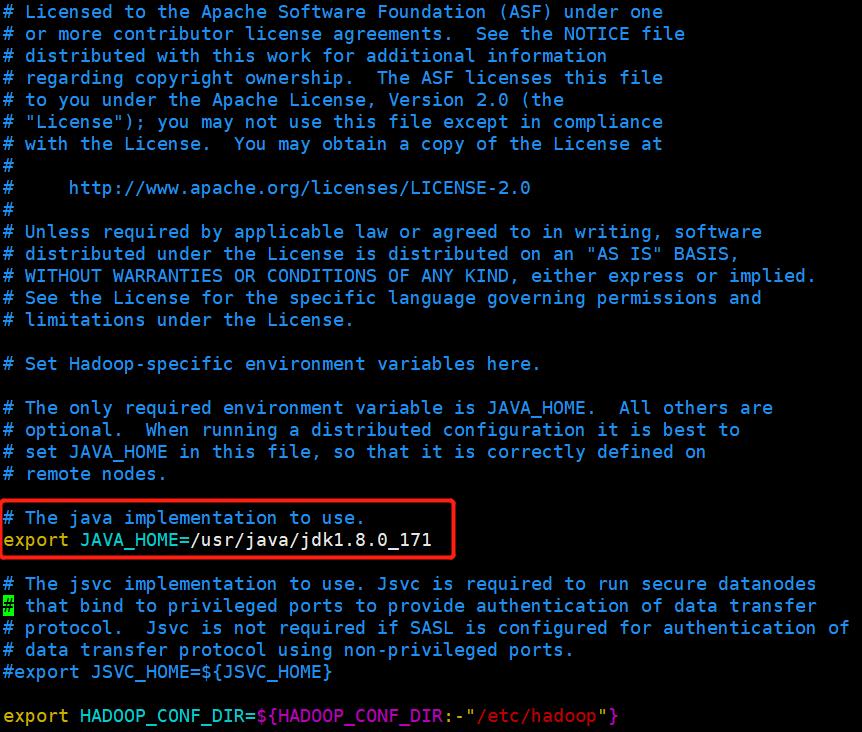
vim hadoop-env.sh - 将第25行处修改为当前的JAVA_HOME路径(集群基础配置中JAVA_HOME路径):
export JAVA_HOME=/usr/java/jdk1.8.0_171
4. 设置全局参数,指定NN(NameNode)的IP为master(映射名),端口为9000:
在master、slave1、slave2上操作:
修改 core-site.xml 文件(还是在 /usr/hadoop/hadoop-2.7.3/etc/hadoop 路径下)
vim core-site.xml
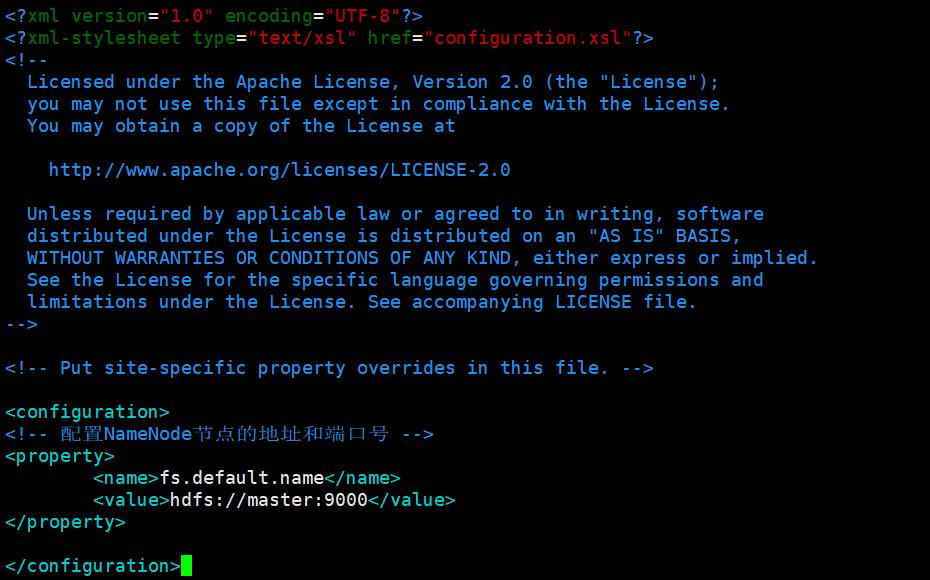
在<configuration></configuration>中添加如下内容
<!-- 配置NameNode节点的地址和端口号 -->
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
5. 指定存放临时数据的目录为hadoop安装目录下/hdfs/tmp(绝对路径):
在master、slave1、slave2上操作:
还是修改 core-site.xml 文件。
vim core-site.xml
(hadoop安装目录: /usr/hadoop/hadoop-2.7.3)
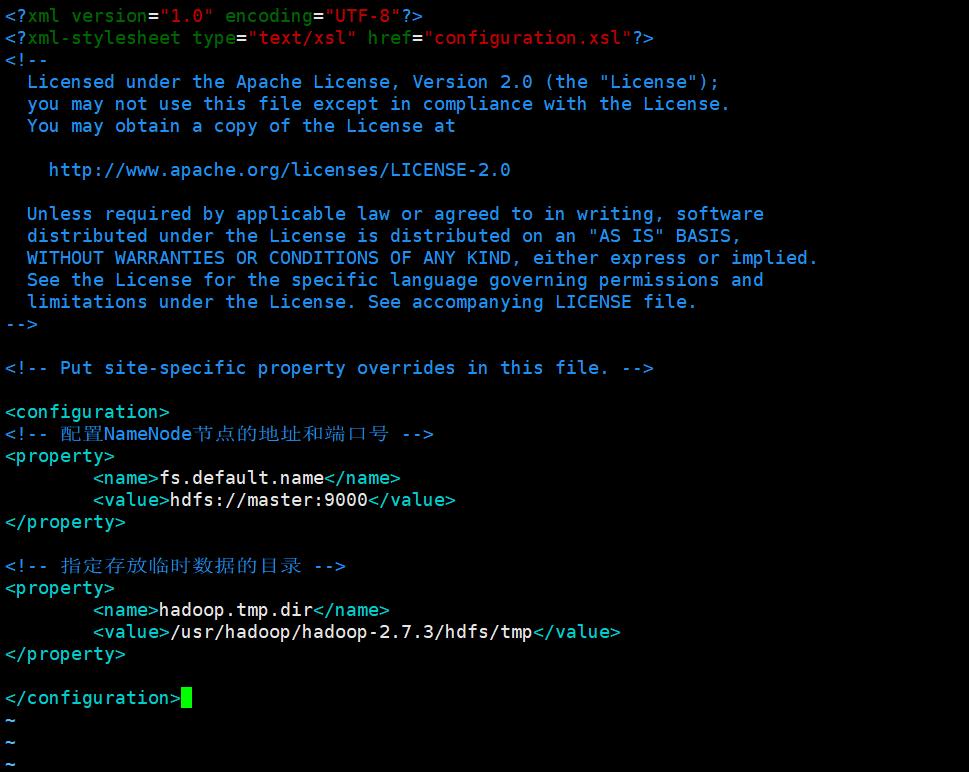
在<configuration></configuration>中添加如下内容 :
<!-- 指定存放临时数据的目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/hadoop-2.7.3/hdfs/tmp</value>
</property>
6. 设置HDFS参数:
在master、slave1、slave2上操作:
修改 hdfs-site.xml 文件以设置HDFS参数:
vim hdfs-site.xml
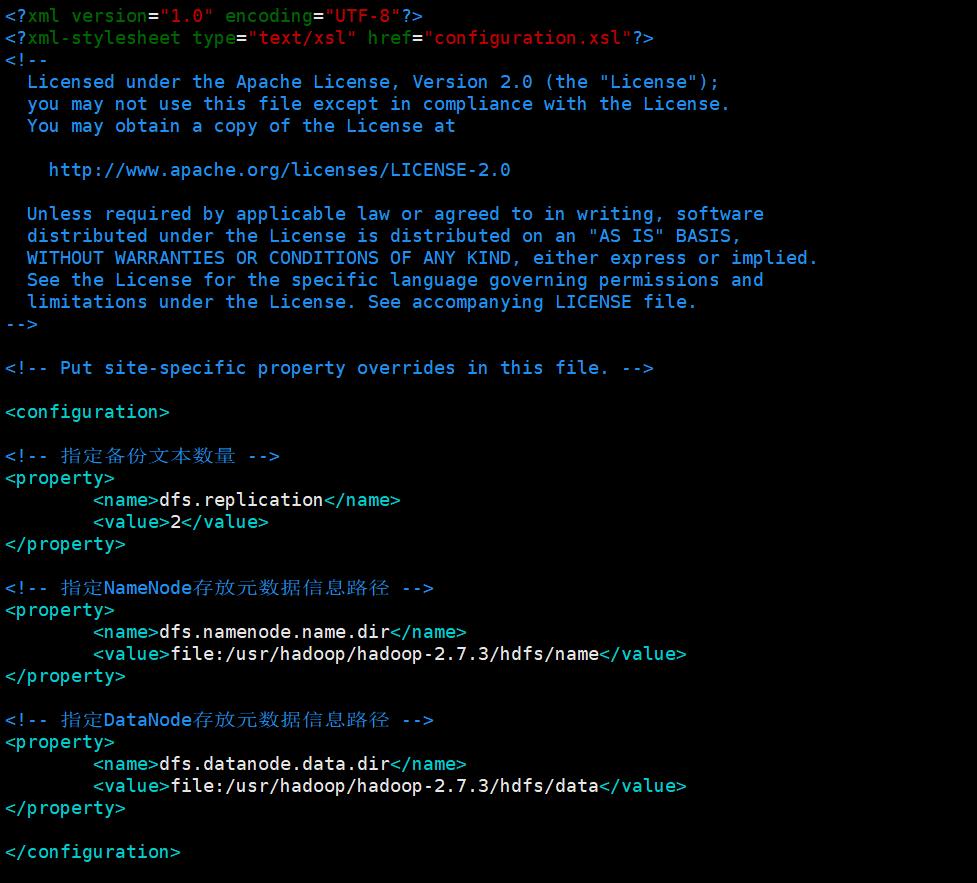
- 指定备份文本数量为2:
<!-- 指定备份文本数量 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
- 指定NameNode存放元数据信息路径为hadoop目录下/hdfs/name:
<!-- 指定NameNode存放元数据信息路径 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/hadoop/hadoop-2.7.3/hdfs/name</value>
</property>
- 指定DataNode存放元数据信息路径为hadoop安装目录下/hdfs/data:
<!-- 指定DataNode存放元数据信息路径 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/hadoop/hadoop-2.7.3/hdfs/data</value>
</property>
7. 设置YARN运行环境:
在master、slave1、slave2上操作:
vim yarn-env.sh
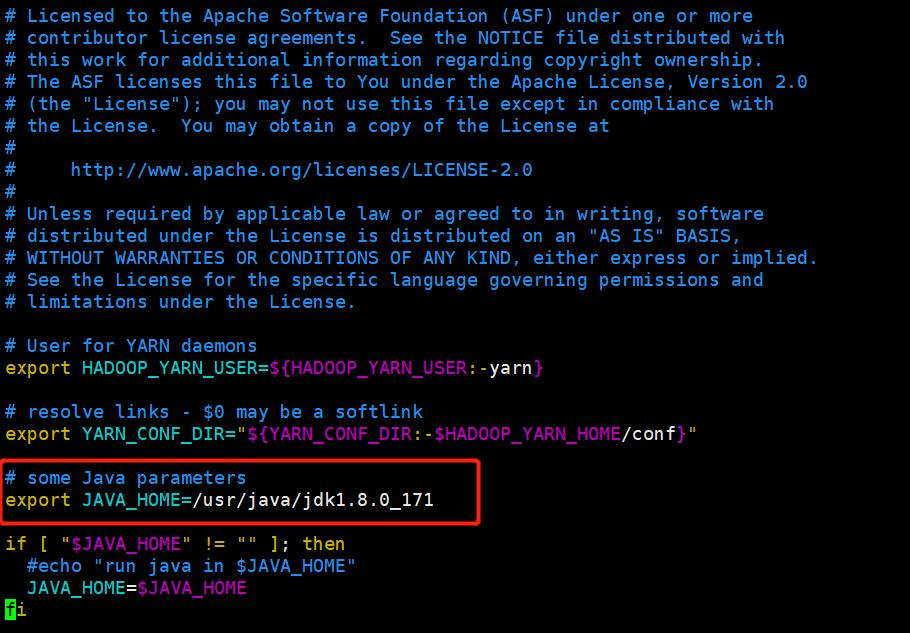
修改yarn-env.sh中的第23行为JAVA_HOME路径:
export JAVA_HOME=/usr/java/jdk1.8.0_171
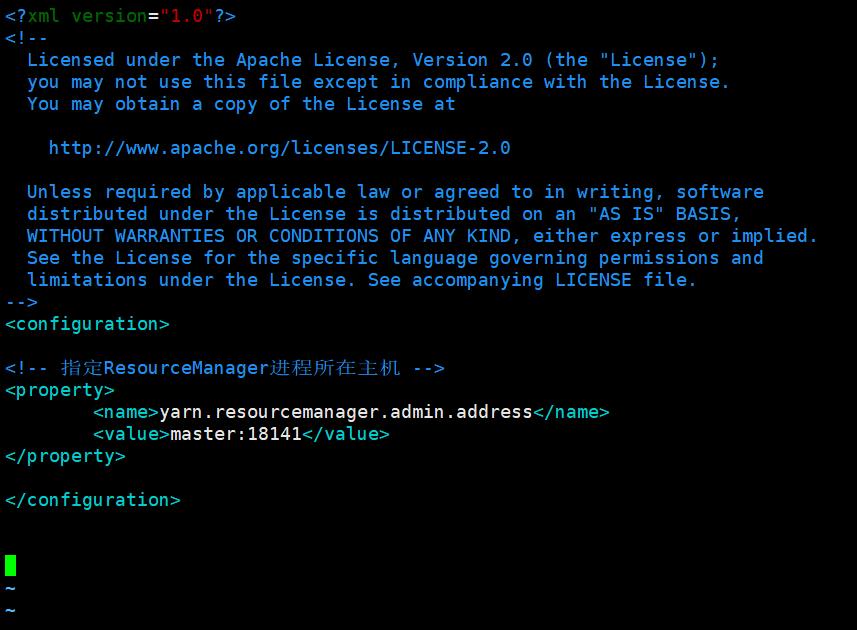
8. 设置YARN核心参数,指定ResourceManager进程所在主机为master,端口为18141:
在master、slave1、slave2上操作:
vim yarn-site.xml
在<configuration></configuration>中添加如下内容 :
<!-- 指定ResourceManager进程所在主机 -->
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
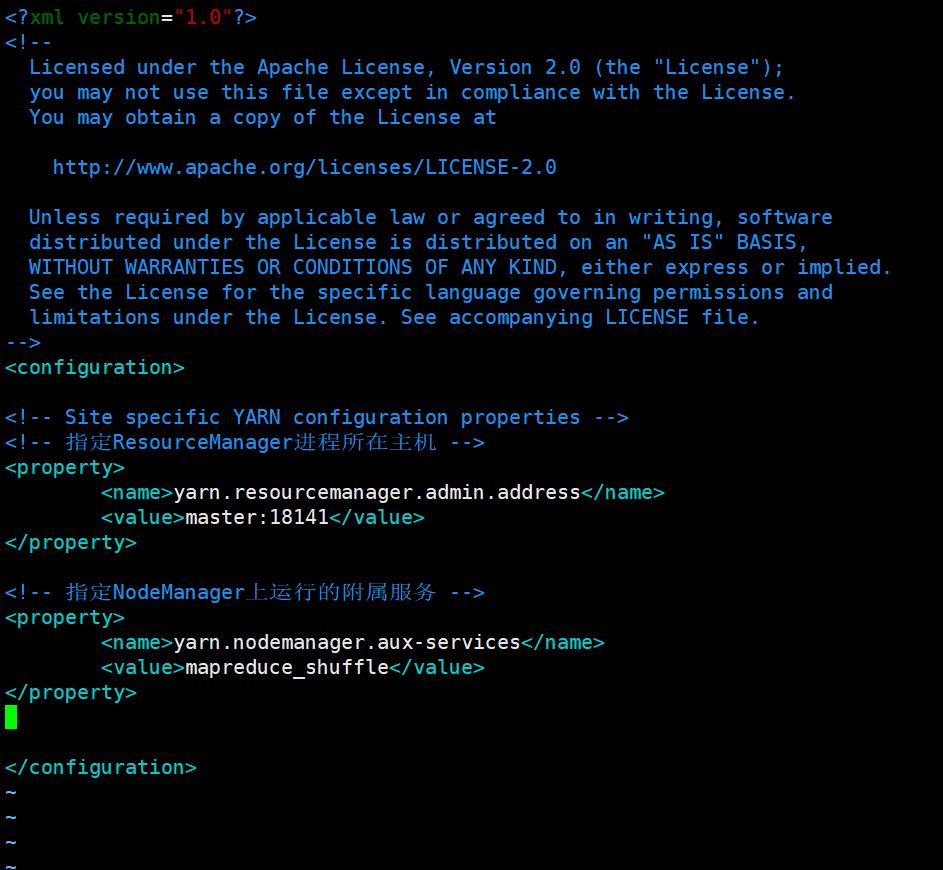
9. 设置YARN核心参数,指定NodeManager上运行的附属服务为shuffle:
在master、slave1、slave2上操作:
vim yarn-site.xml
在<configuration></configuration>中添加如下内容 :
<!-- 指定NodeManager上运行的附属服务 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
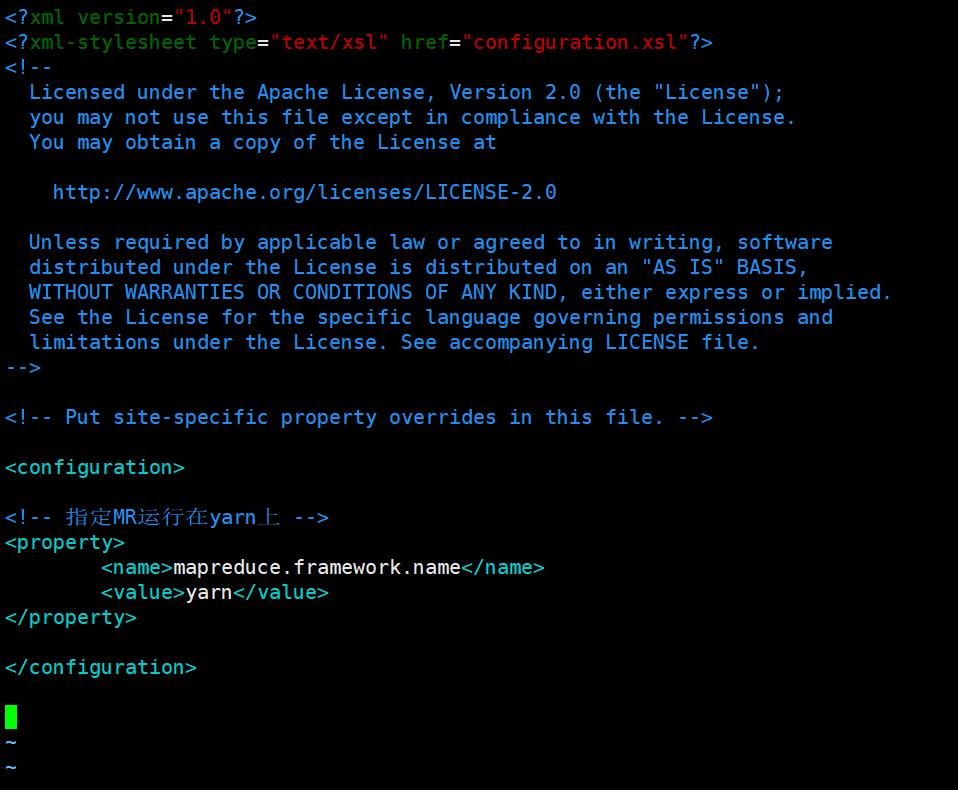
10. 设置计算框架参数,指定MR运行在yarn上:
在master、slave1、slave2上操作:
Hadoop集群中没有mapred-site.xml这个文件,因此需要把mapred-site.xml.template复制为mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
在<configuration></configuration>中添加如下内容 :
<!-- 指定MR运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
11. 设置节点文件,要求master为主节点; slave1、slave2为子节点:
在master、slave1、slave2上操作:
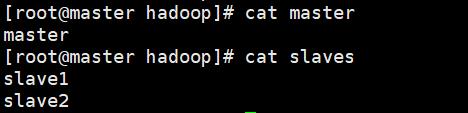
还是在 /usr/hadoop/hadoop-2.7.3/etc/hadoop 路径下,修改master、slaves文件:
vim master
=== 写入 ===
master
vim slaves
=== 写入 ===
slave1
slave2
12. 文件系统格式化:
在master上操作:
hadoop namenode -format
出现以下界面即代表格式化成功:

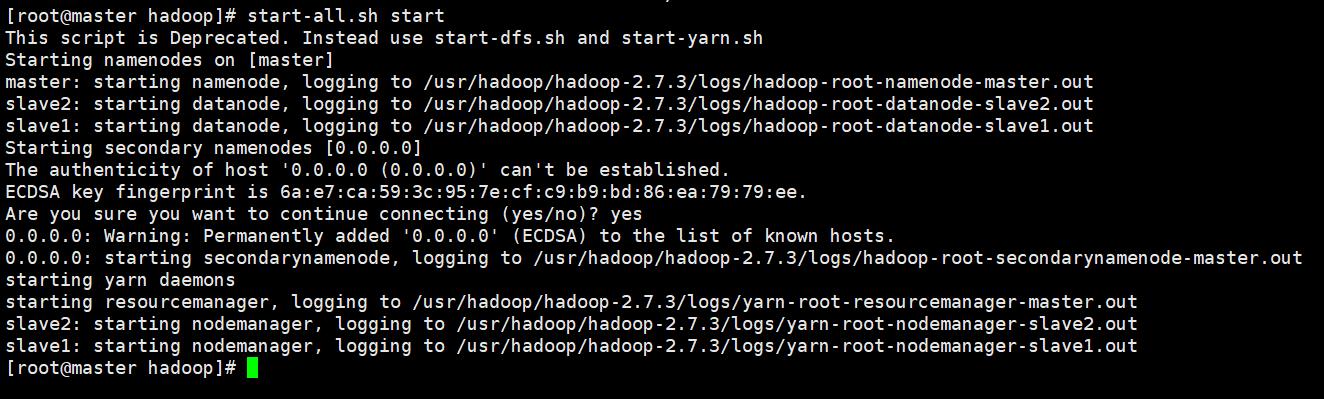
13. 启动Hadoop集群:
在master上操作:
start-all.sh start
然后输入 yes 即可启动:
以上是关于大数据分析师实操练习(Hadoop完全分布式集群搭建)的主要内容,如果未能解决你的问题,请参考以下文章