2021年全国行业职业技能竞赛暨第四届全国大学生大数据技能竞赛——职教学生组线上选拔赛
Posted 慕铭yikm
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2021年全国行业职业技能竞赛暨第四届全国大学生大数据技能竞赛——职教学生组线上选拔赛相关的知识,希望对你有一定的参考价值。
2021年全国行业职业技能竞赛暨第四届全国大学生大数据技能竞赛——职教学生组线上选拔赛
目录
2021年全国行业职业技能竞赛暨第四届全国大学生大数据技能竞赛——职教学生组线上选拔赛
前言
根据2021年全国行业职业技能竞赛暨第四届全国大学生大数据技能竞赛——职教学生组线上选拔赛赛题整理,附上资料链接,如果有错误指出请提出改正,谢谢
资料
链接:https://pan.baidu.com/s/1Q2Z-roUoGSMkXNf1I4dThA
提取码:yikm
前提条件
由于比赛中已经安装有ntp和mysql服务,我们现在虚拟机中安装配置。
ntp在三台机器上安装(master,slave1,slave2)
MySQL可以只在slave2中安装,将slave2作为数据库存储数据,使用client/thrift server的连接方式进行访问。
安装ntp:
yum install -y ntp
安装完成: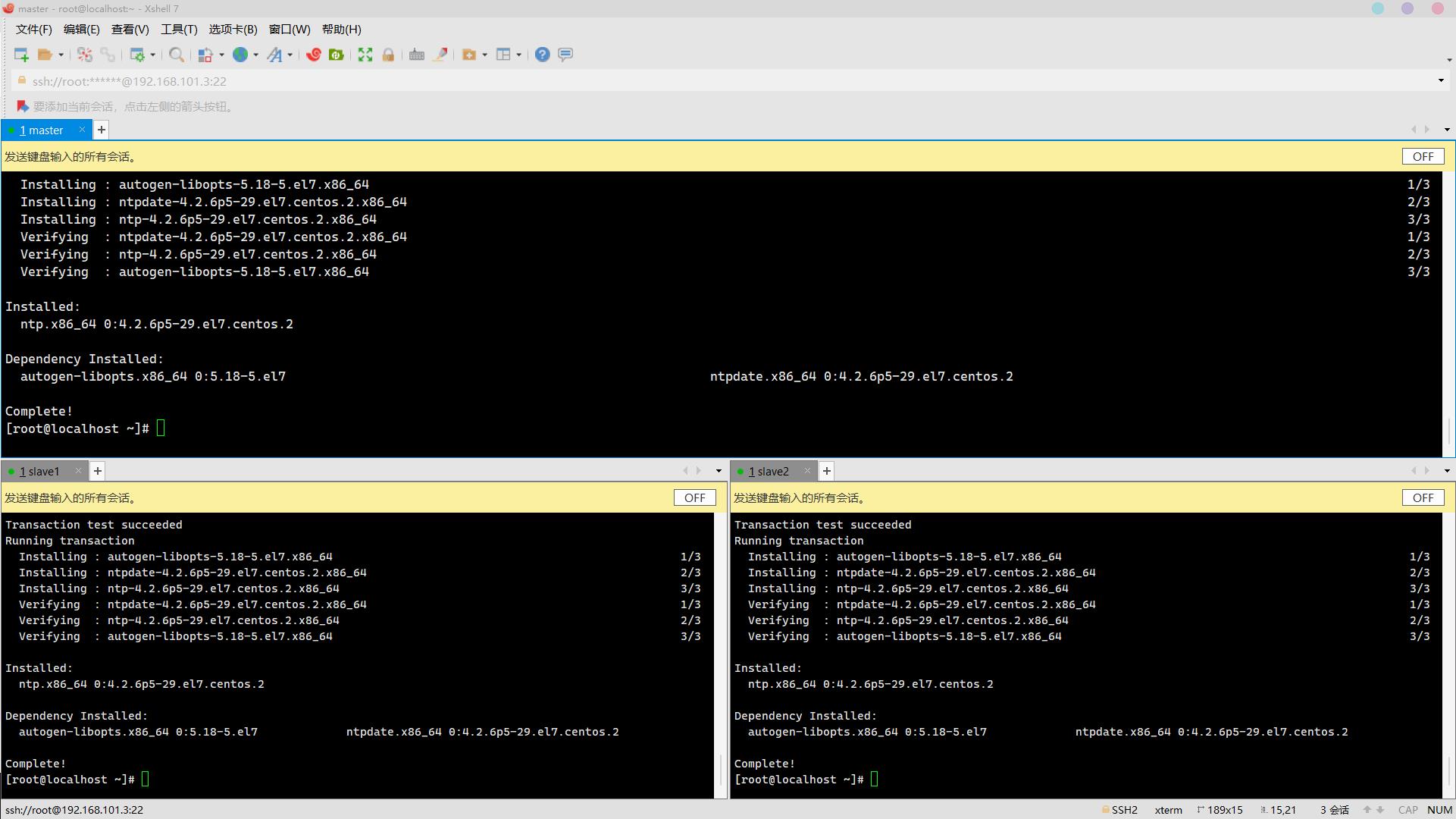
安装MySQL数据库:
卸载系统自带的Mariadb
rpm -qa|grep mariadb
rpm -e mariadb-libs-5.5.68-1.el7.x86_64 --nodeps
rpm -qa|grep mariadb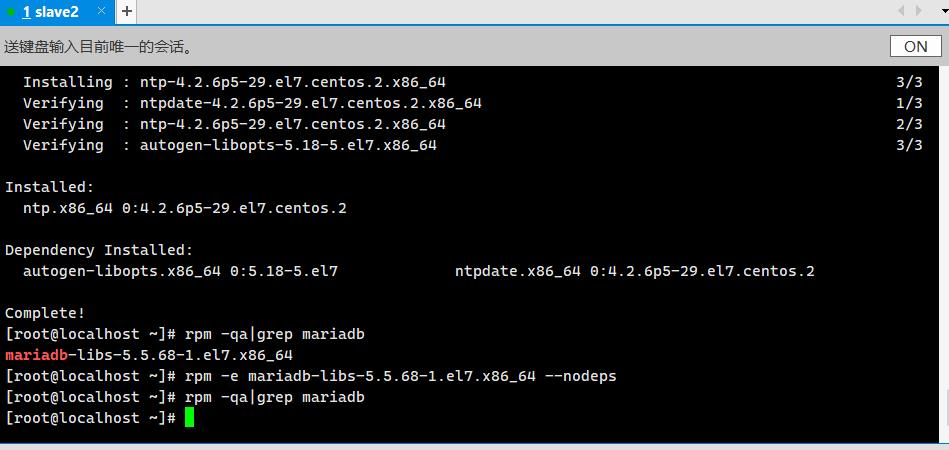
安装MySQL:
解压:
tar -xvf /usr/package277/mysql-5.7.25-1.el7.x86_64.rpm-bundle.tar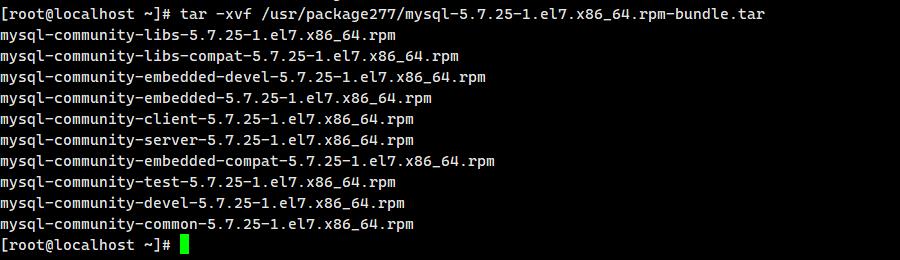 安装:
安装:
rpm -ivh mysql-community-common-5.7.25-1.el7.x86_64.rpm mysql-community-libs-5.7.25-1.el7.x86_64.rpm mysql-community-libs-compat-5.7.25-1.el7.x86_64.rpm mysql-community-client-5.7.25-1.el7.x86_64.rpm mysql-community-server-5.7.25-1.el7.x86_64.rpm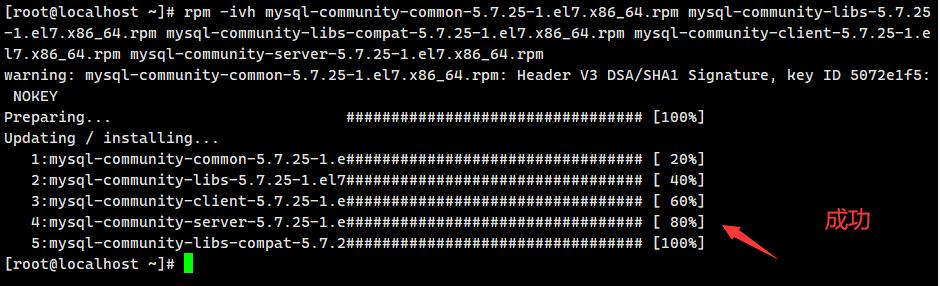
配置完毕!
题目一、基础配置(30分)
1.比赛框架
本次比赛为分布式集群搭建,共三台节点,其中master作为主节点,slave1、slave2为从节点;
2.比赛内容
- 基础配置:修改主机名、主机映射、时区修改、时间同步、定时任务、免密访问;
- JDK安装:环境变量;
- Zookeeper部署:环境变量、配置文件zoo.cfg、myid;
- Hadoop部署:环境变量、配置文件修改、设置节点文件、格式化、开启集群;
- Hive部署:Mysql数据库配置、服务器端配置、客户端配置。
3.版本说明
| 内置安装/依赖包(/usr/package277) | 已安装服务 | 系统版本 |
| hadoop-2.7.7.tar.gz | ntp | CentOS Linux release 7.3.1611 (Core) |
| zookeeper-3.4.14.tar.gz | mysql-community-server | |
| apache-hive-2.3.4-bin.tar.gz | ||
| jdk-8u211-linux-x64.tar.gz | ||
| mysql-connector-java-5.1.47-bin.jar |
core-site.xml参数配置详情
官方文档:http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/core-default.xml
core-default.xml与core-site.xml的功能是一样的,如果在core-site.xml里没有配置的属性,则会自动会获取core-default.xml里的相同属性的值
| 属性 | 值 | 说明 |
| fs.default.name | hdfs://???? | 定义master的URI和端口 |
| hadoop.tmp.dir | /???? | 临时文件夹,指定后需将使用到的所有子级文件夹都要手动创建出来,否则无法正常启动服务。 |
hdfs-site.xml参数配置详情
| 属性 | 值 | 说明 |
| dfs.replication | ??? | hdfs数据块的复制份数,默认3,理论上份数越多跑数速度越快,但是需要的存储空间也更多。 |
| dfs.namenode.name.dir | file:/usr/hadoop/hadoop-2.7.3/hdfs/???? | NN所使用的元数据保存 |
| dfs.datanode.data.dir | file:/usr/hadoop/hadoop-2.7.3/hdfs/???? | 真正的datanode数据保存路径,可以写多块硬盘,逗号分隔 |
yarn-site.xml参数配置详情
| 属性 | 值 | 说明 |
| yarn.resourcemanager.admin.address | ${yarn.resourcemanager.hostname}:18141 | ResourceManager 对管理员暴露的访问地址。管理员通过该地址向RM发送管理命令等。 |
| yarn.nodemanager.aux-services | mapreduce_shuffle | NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序 |
mapred-site.xml参数配置详情
| 属性 | 值 | 说明 |
| mapreduce.framework.name | yarn | 指定MR运行框架,默认为local |
基础环境配置
前提说明
- 相关安装包已经存放至环境/usr/package277/中
- 对应ntp和mysql已安装,可直接对其进行操作和配置
1.修改主机名,便于识别节点;
2.工具包已保存在环境中;
3.修改hosts文件,添加集群节点映射,按照给出的节点IP和对应的主机名进行设置;
4.要求各节点时区修改为中国时区( 中国标准时间CST+8)
5.安装ntp服务,要求主节点master为本地时钟源,从节点设置定时任务同步本地时间;
6.集群中数据传输需要节点之间免密访问,要求设置主节点之间到从节点的免密访问;
7.Hadoop技术基于Java语言,要求本地源下载对应安装包进行安装配置,注意安装路径要求,无需更改文件名,注意添加环境变量。
本环境用于为基础设置部分,用于后续的集群搭建。
考核条件如下:
1. 按照左侧虚拟机名称修改对应主机名(分别为master、slave1、slave2,使用hostnamectl命令)(2分)
操作环境: master、slave1、slave2
hostnamectl set-hostname master
hostnamectl set-hostname slave1
hostnamectl set-hostname slave2
bash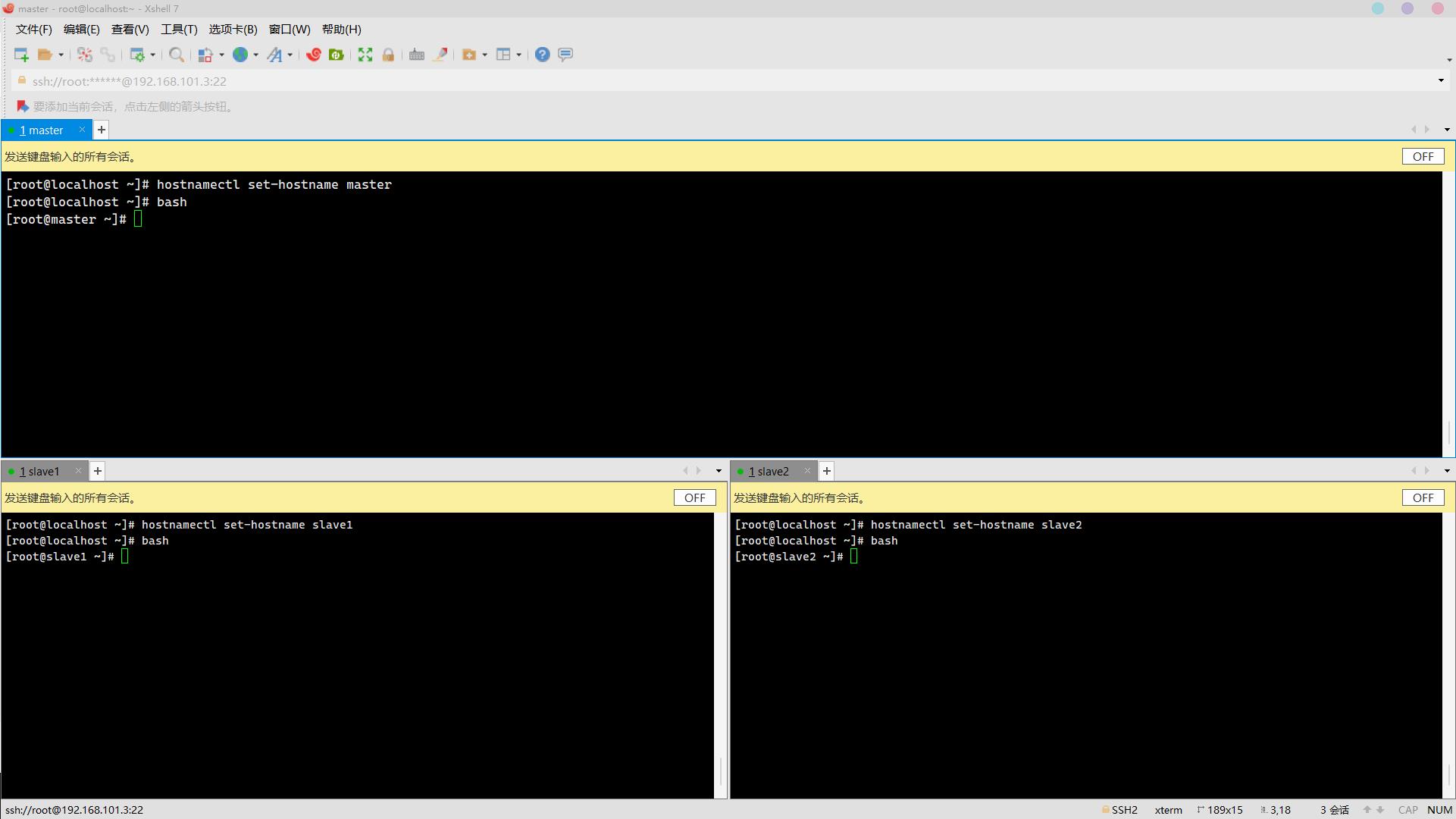
2. 修改云主机host文件添加左侧master、slave1、slave2三个节点IP与主机名映射(使用内网IP)(2分)
操作环境: master、slave1、slave2
vim /etc/hosts
添加ip+主机名:

:wq保存退出
ping测试:(ctrl+c停止)
ping slave1
ping slave2
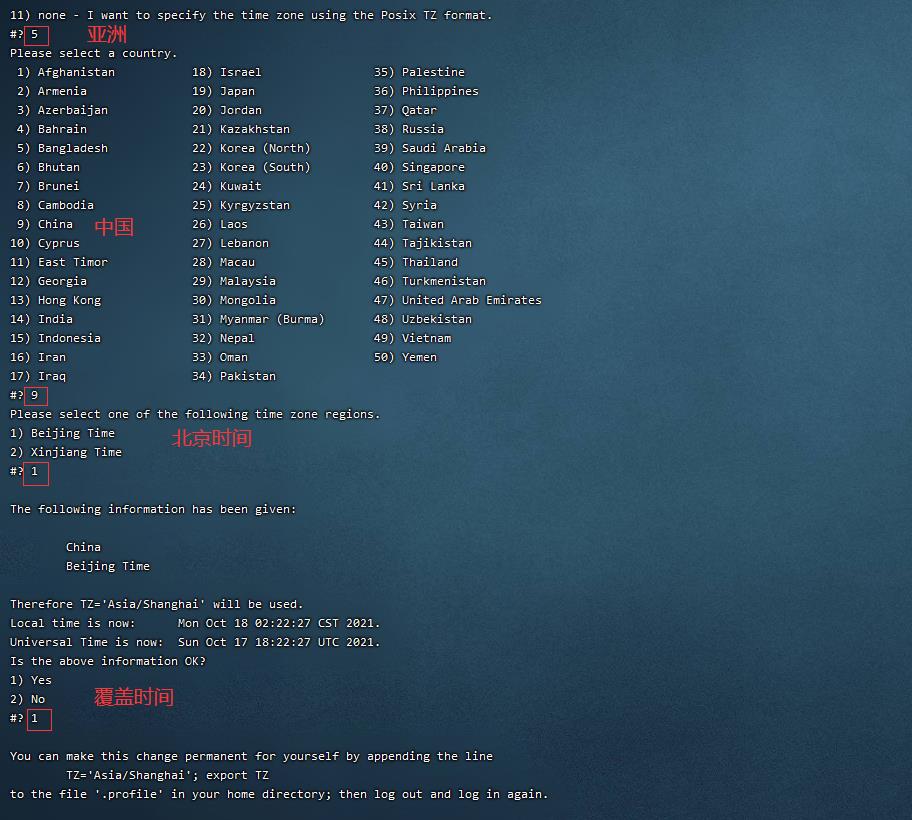
3. 时区更改为上海时间(CST+0800时区)(2分)
操作环境: master、slave1、slave2
tzselect
依次输入
5
9
1
1
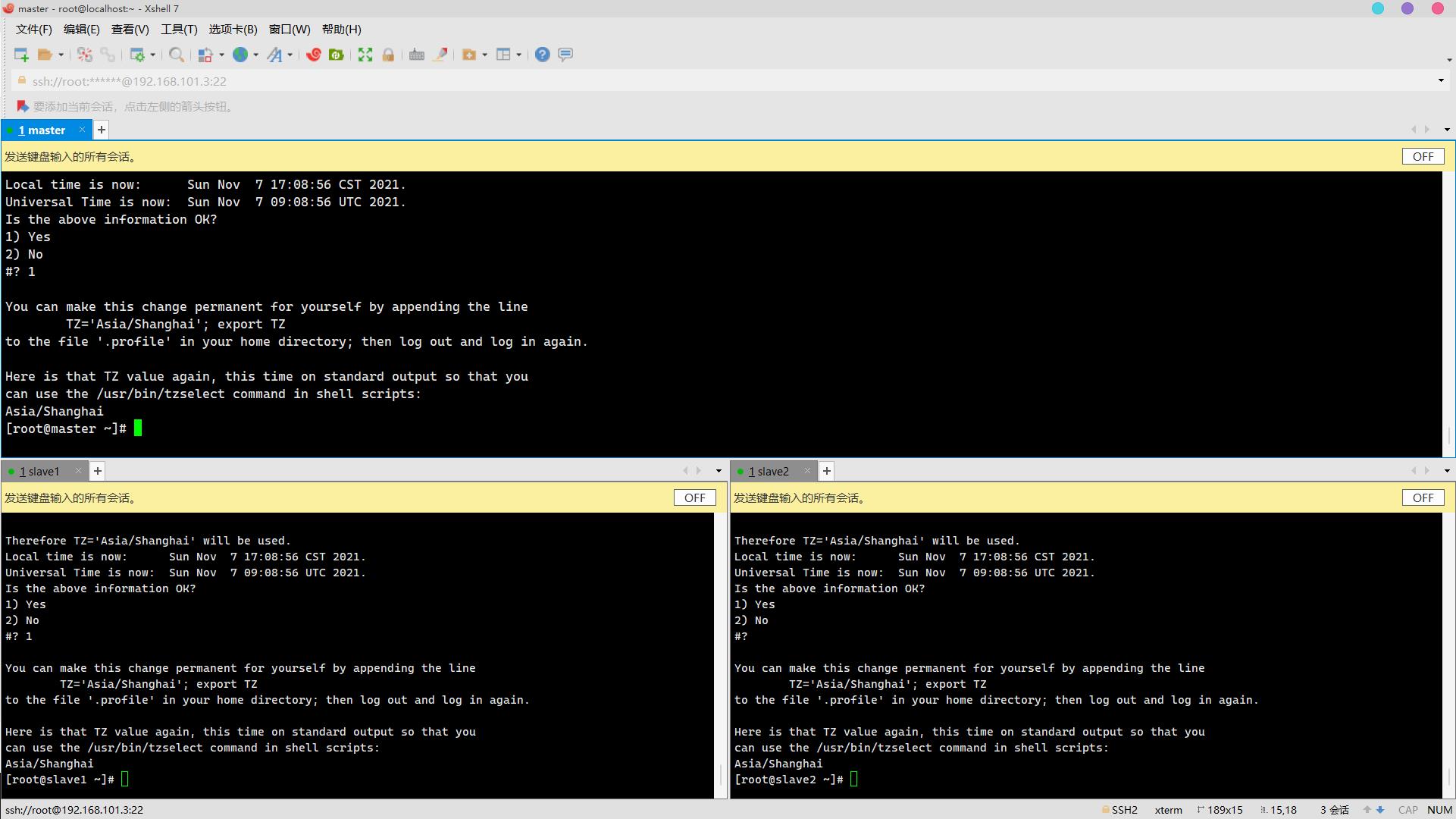
修改环境变量:
vim /etc/profile加入:
TZ='Asia/Shanghai'; export TZ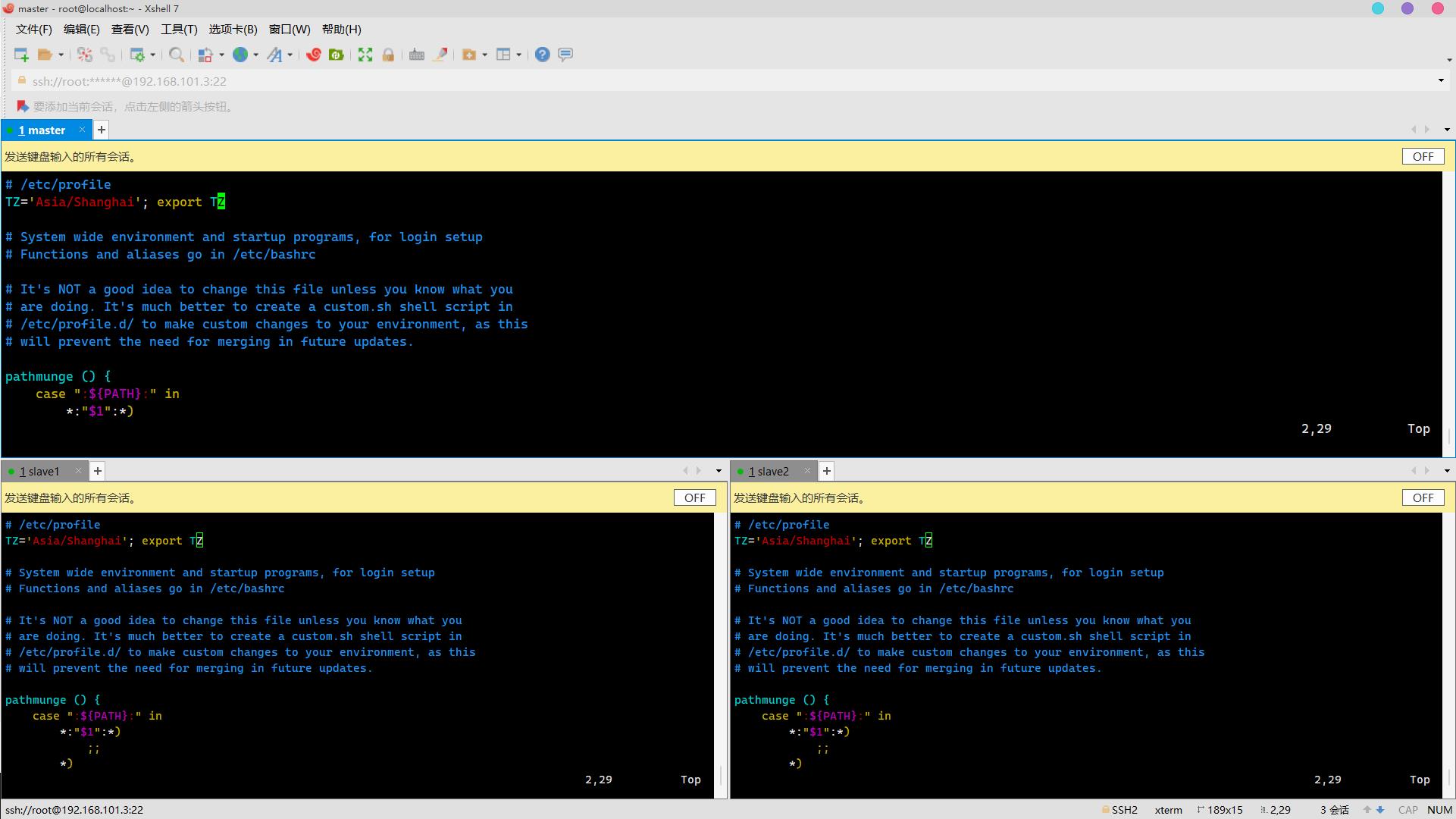
生效环境变量:
source /etc/profile查看时间:
date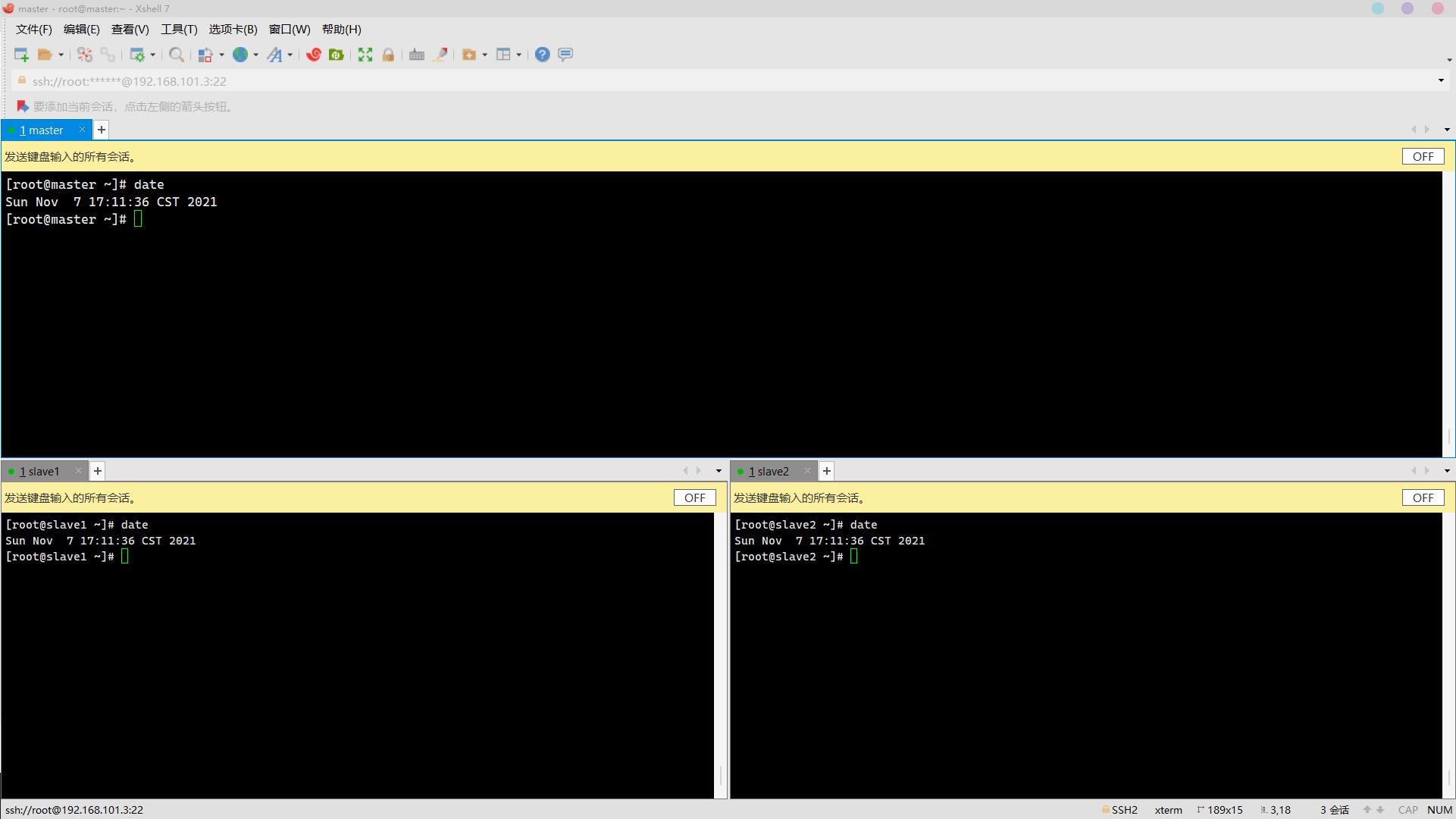
在ntp同步之前关闭防火墙和selinux安全机制
操作环境: master、slave1、slave2
关闭防火墙:
systemctl stop firewalld
systemctl status firewalld
systemctl disable firewalld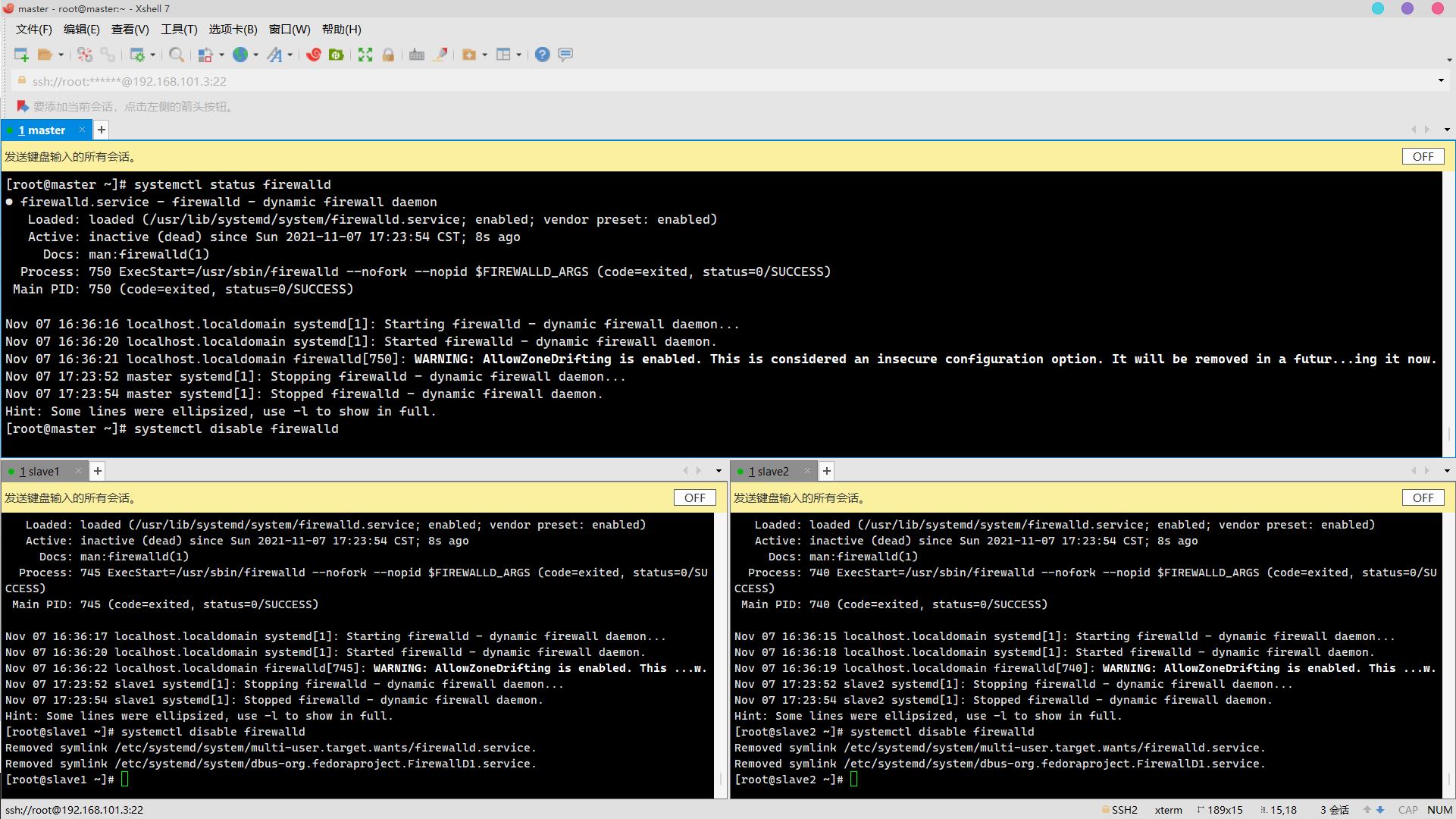
关闭selinux安全机制:
vim /etc/sysconfig/selinux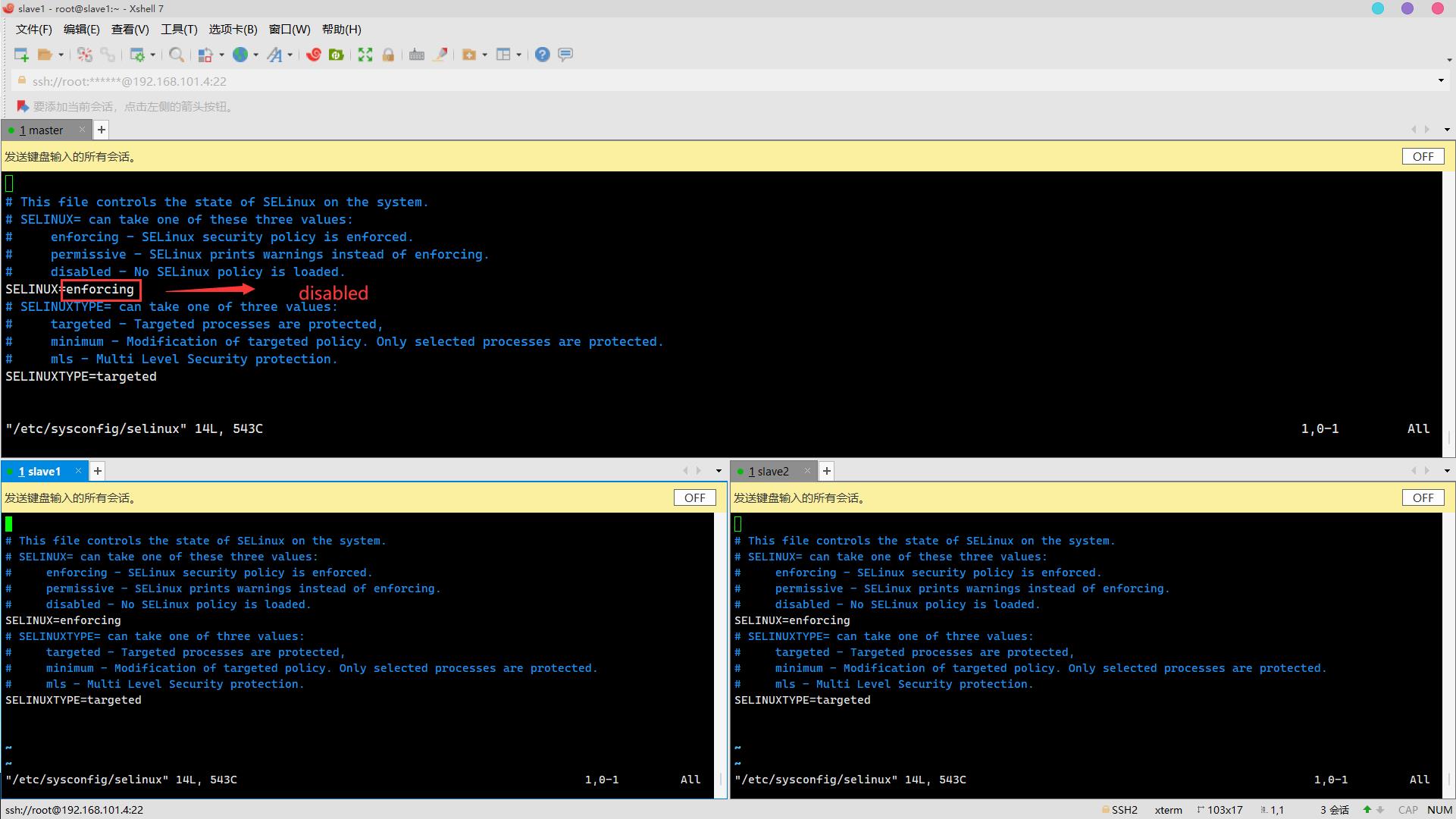

4. 环境已经安装NTP,修改master节点NTP配置,设置master为本地时间服务器,屏蔽默认server,服务器层级设为10(2分)
操作环境: master
echo "server 127.127.1.0
fudge 127.127.1.0 stratum 10" >> /etc/ntp.conf 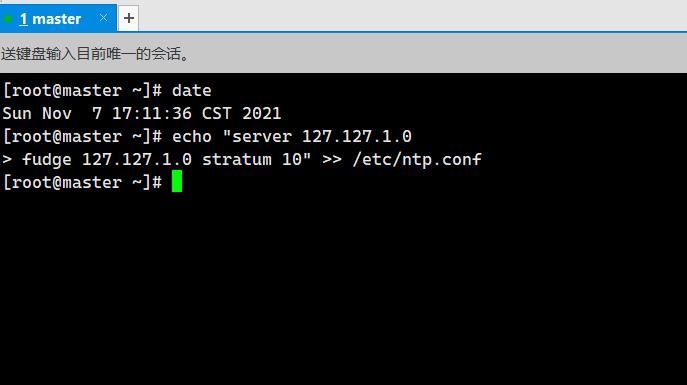
5. 开启NTP服务(2分)
操作环境: master
/bin/systemctl restart ntpd.service 
6. 添加定时任务--在早十-晚五时间段内每隔半个小时同步一次本地服务器时间(24小时制、使用用户root任务调度crontab,服务器地址使用主机名)(2分)
操作环境: slave1、slave2
ntp同步master
ntpdate master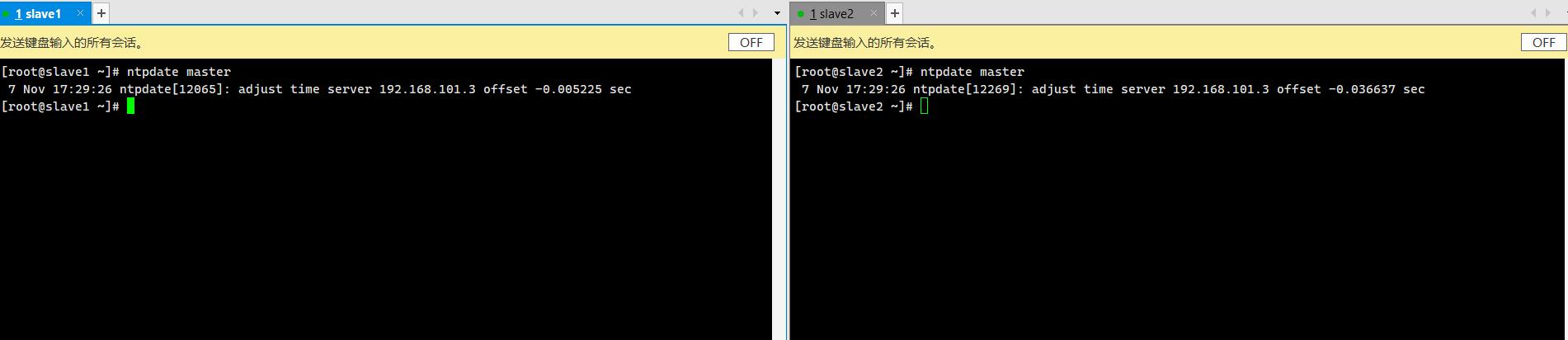
crontab -e
*/30 10-17 * * * usr/sbin/ntpdate master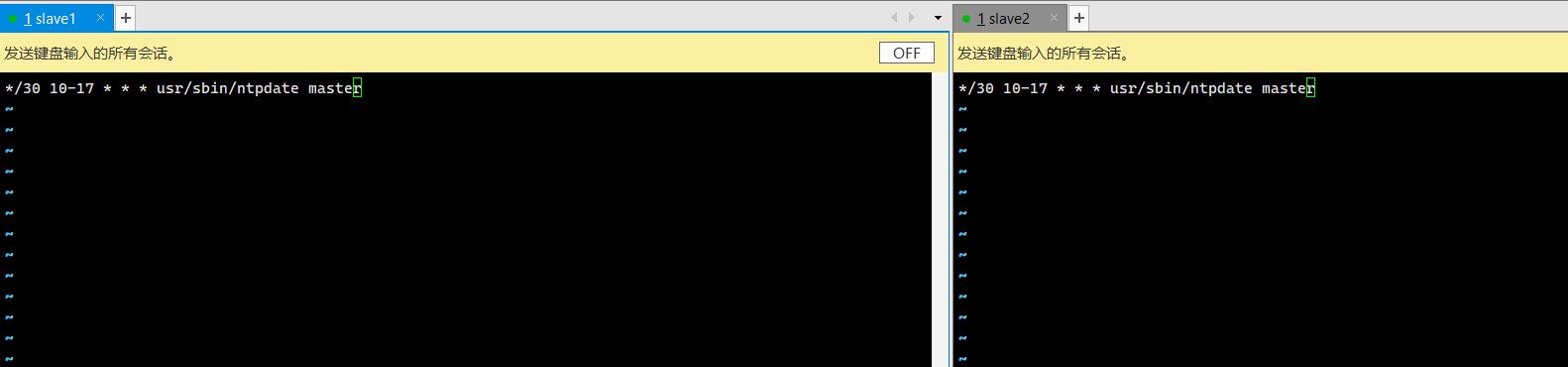 查看任务:
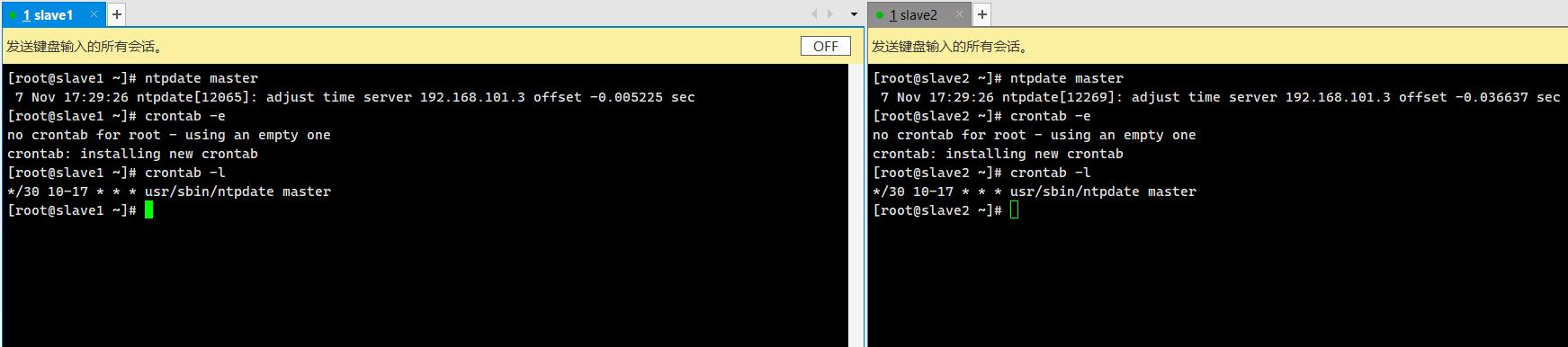
查看任务:
crontab -l
7. master节点生成公钥文件id_rsa.pub(数字签名RSA,用户root,主机名master)(2分)
操作环境: master
ssh-keygen
三次回车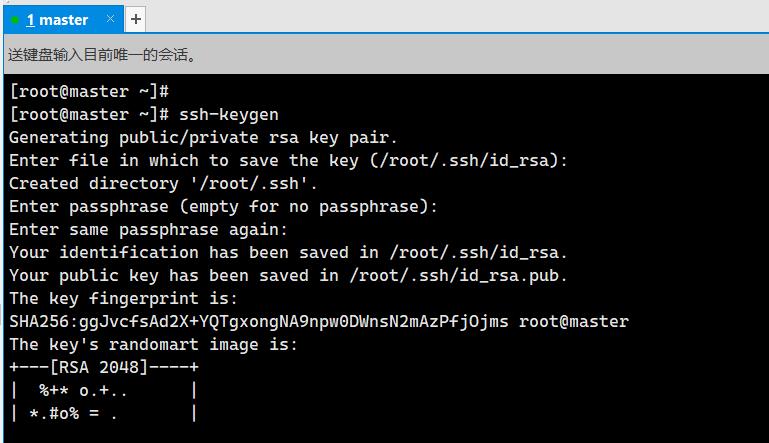
8. 建⽴master⾃身使⽤root⽤户ssh访问localhost免密登录(2分)
操作环境: master
ssh-copy-id localhost输入yes和密码
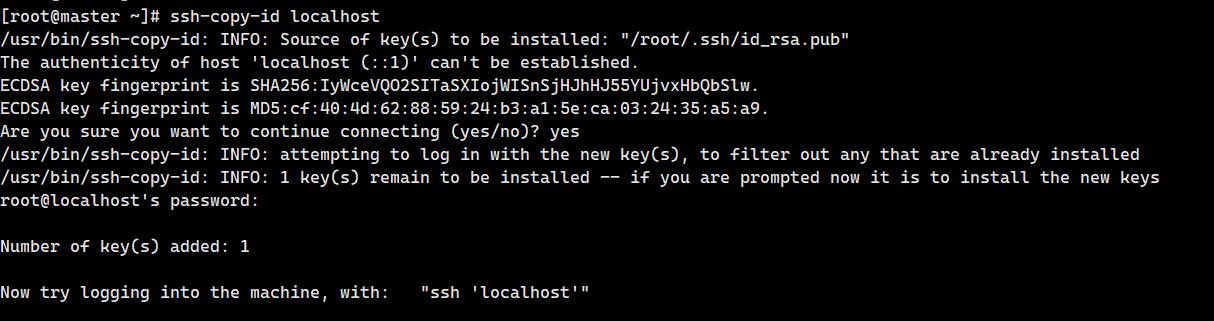
9. 建⽴master使⽤root⽤户到slave1的ssh免密登录访问(2分)
操作环境: master
ssh-copy-id slave1输入yes和密码:
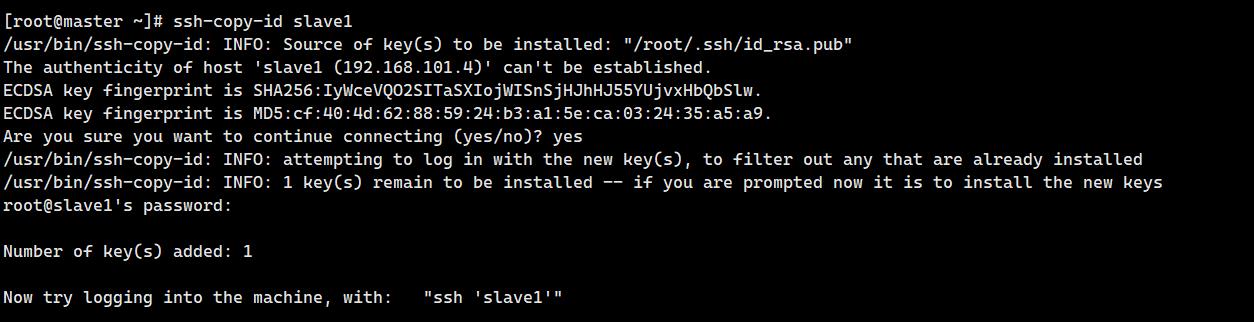
10. 建⽴master使⽤root⽤户到slave2的ssh免密登录访问(2分)
操作环境: master
ssh-copy-id slave2输入yes和密码:
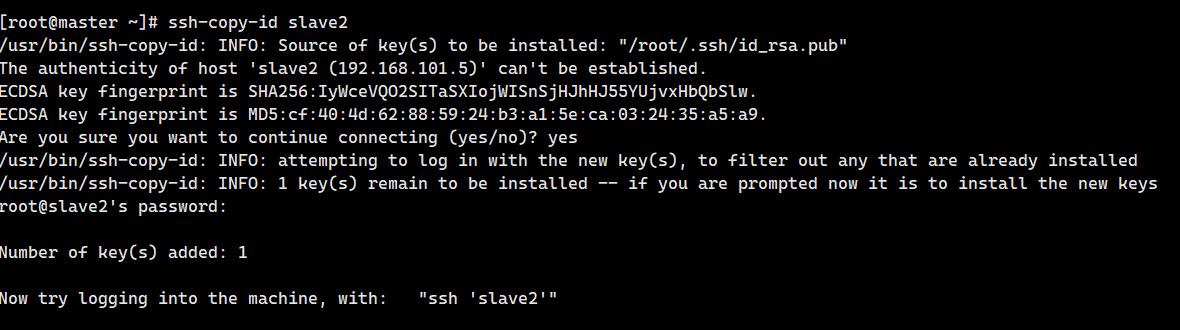
ssh测试:
ssh slave1
exit
ssh slave2
exit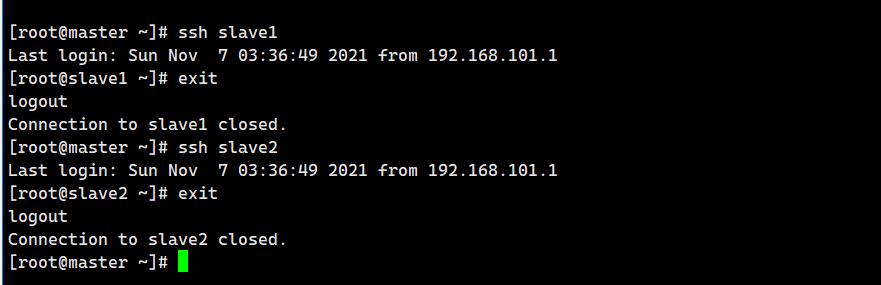
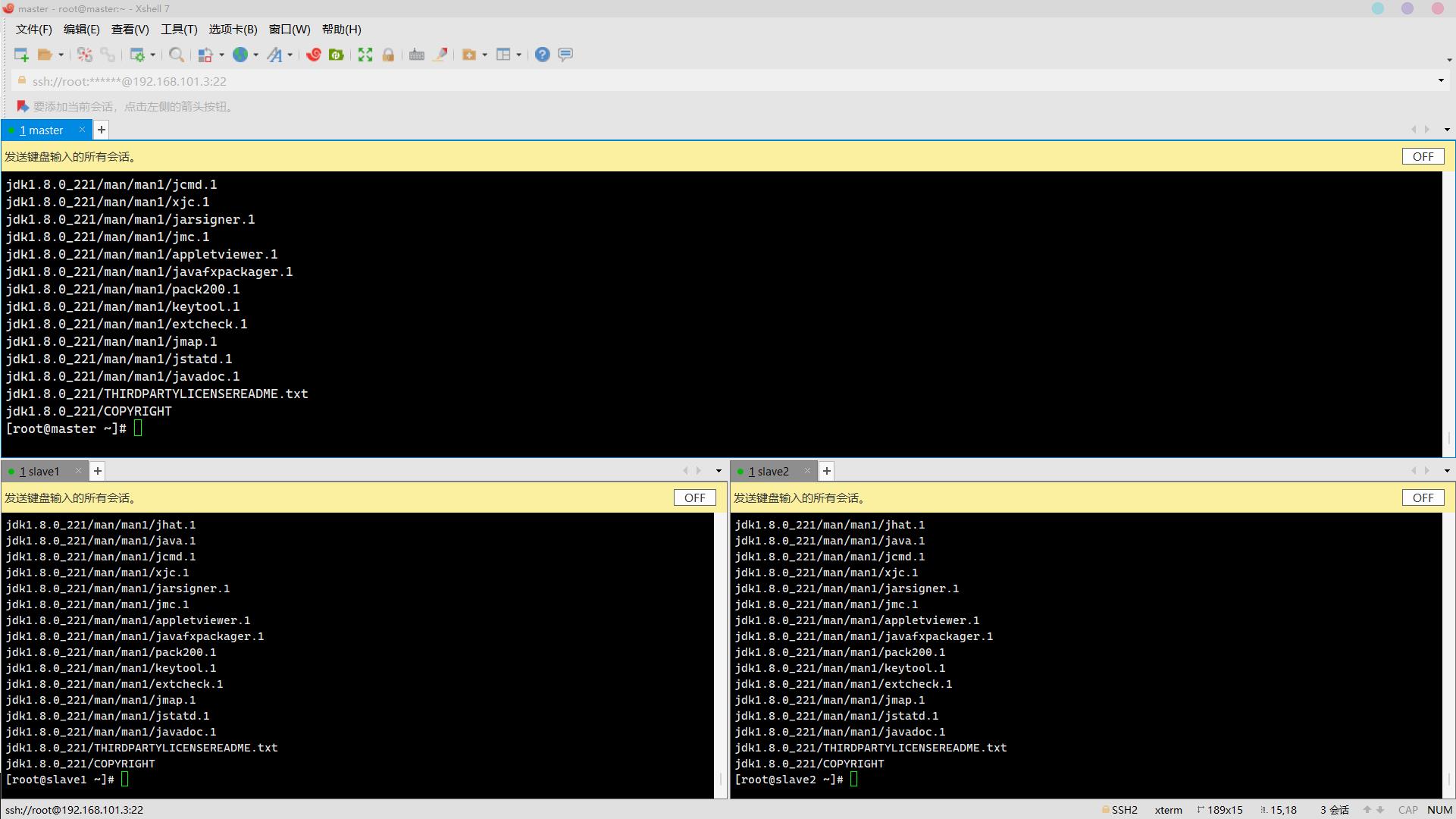
11. 将jdk安装包解压到/usr/java目录(安装包存放于/usr/package277/,路径自行创建,解压后文件夹为默认名称,其他安装同理)(5分)
操作环境: master、slave1、slave2
mkdir /usr/java
tar -zxvf /usr/package277/jdk-8u221-linux-x64.tar.gz -C /usr/java/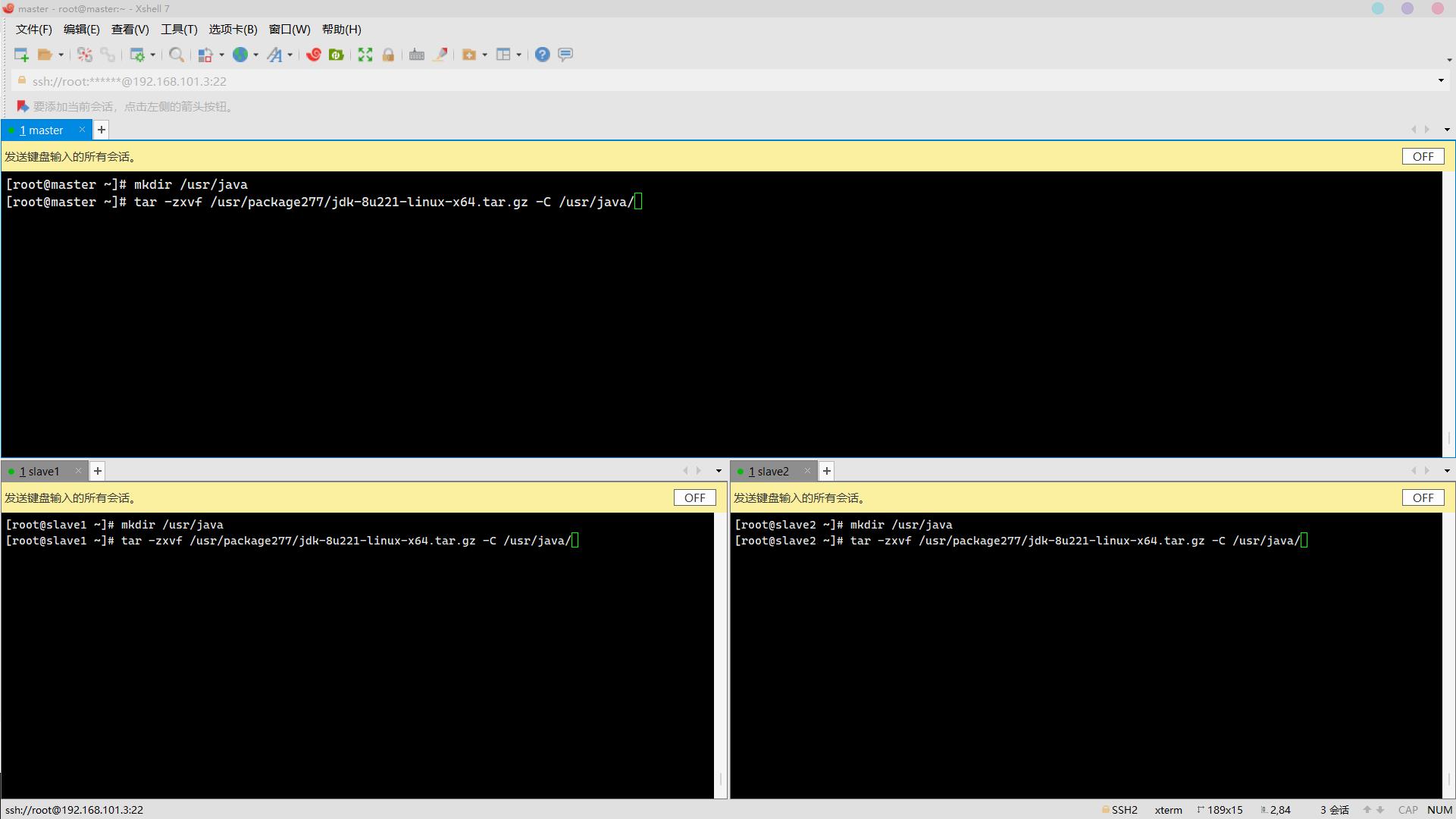 解压完毕:
解压完毕:
12. 文件/etc/profile中配置系统环境变量JAVA_HOME,同时将JDK安装路径中bin目录加入PATH系统变量,注意生效变量,查看JDK版本(5分)
操作环境: master、slave1、slave2
vim /etc/profile添加以下内容:
#java
export JAVA_HOME=/usr/java/jdk1.8.0_221
export PATH=$PATH:$JAVA_HOME/bin
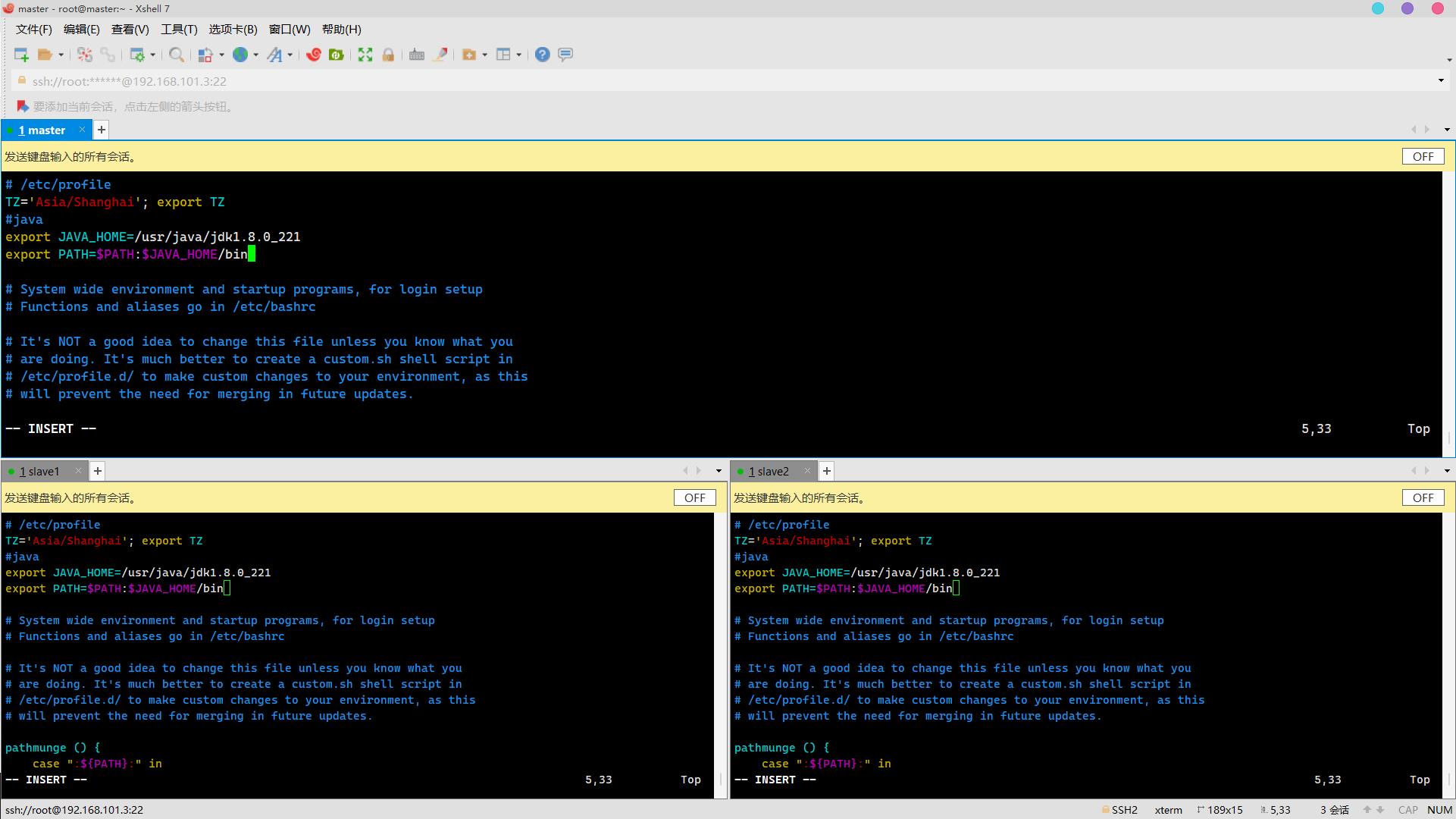
生效环境变量:
source /etc/profile查看版本:
java -version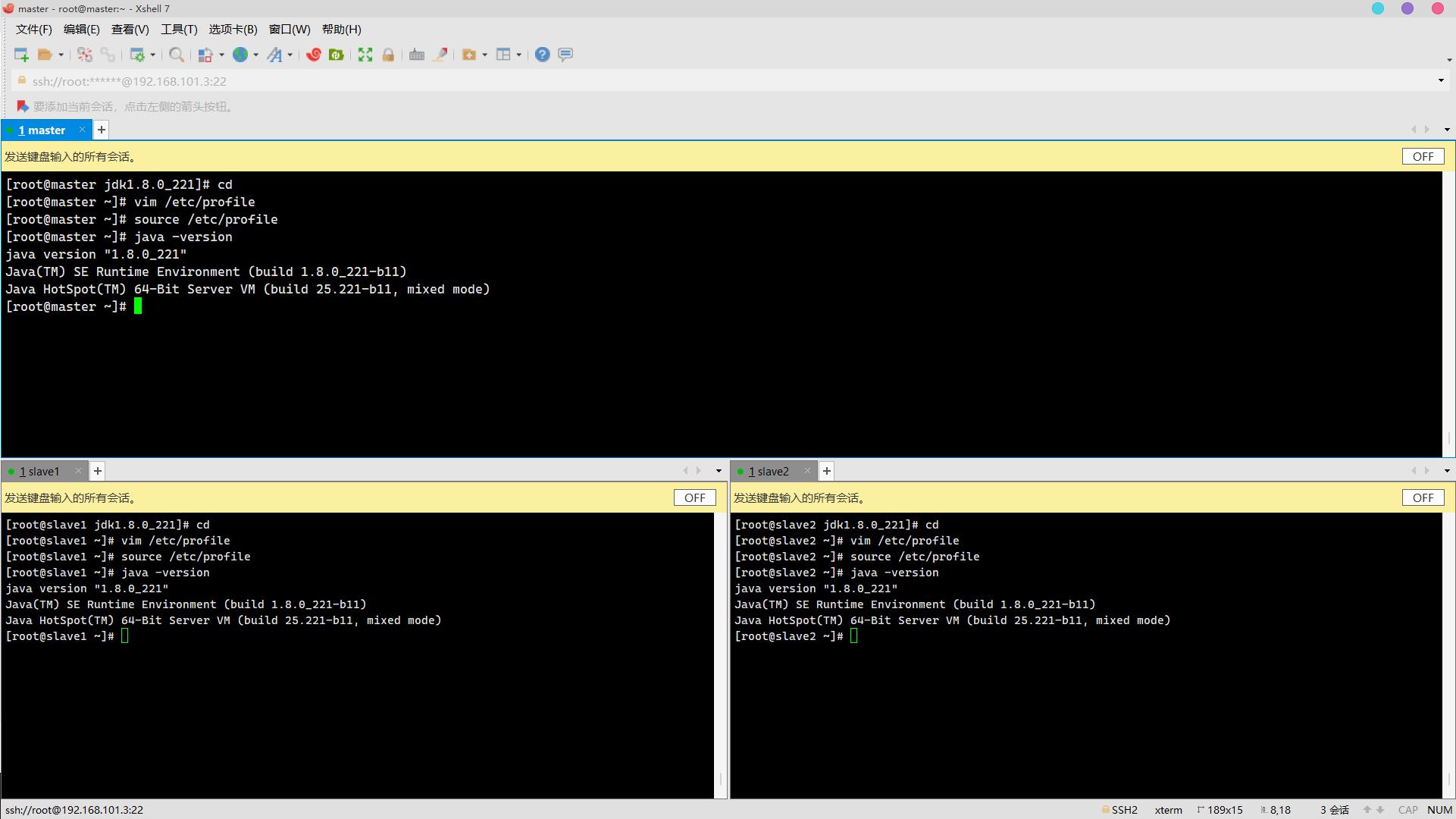
版本不同解决方案:
(铃音大佬整理)
题目二、Zookeeper搭建(30分)
Zookeeper是一个分布式服务框架,是Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。
预装的配置文件zoo_sample.cfg下面默认有五个属性,分别是:
1.tickTime
心跳间隔,单位是毫秒,系统默认是2000毫秒,也就是间隔两秒心跳一次。
tickTime的意义:客户端与服务器或者服务器与服务器之间维持心跳,也就是每个tickTime时间就会发送一次心跳。通过心跳不仅能够用来监听机器的工作状态,还可以通过心跳来控制Flower跟Leader的通信时间,默认情况下FL的会话时常是心跳间隔的两倍。
2.initLimit
集群中的follower服务器(F)与leader服务器(L)之间初始连接时能容忍的最多心跳数(tickTime的数量)。
3.syncLimit
集群中flower服务器(F)跟leader(L)服务器之间的请求和答应最多能容忍的心跳数。
4.clientPort
客户端连接的接口,客户端连接zookeeper服务器的端口,zookeeper会监听这个端口,接收客户端的请求访问,端口默认是2181。
5.dataDir
该属性对应的目录是用来存放myid信息跟一些版本,日志,跟服务器唯一的ID信息等。
在集群Zookeeper服务在启动的时候,会回去读取zoo.cfg这个文件,从这个文件中找到这个属性然后获取它的值也就是dataDir 的路径,它会从这个路径下面读取myid这个文件,从这个文件中获取要启动的当前服务器的地址。
集群信息的配置:
在配置文件中,配置集群信息是存在一定的格式:service.N =YYY: A:B
N:代表服务器编号(准确对应对应服务器中myid里面的值)
YYY:服务器地址
A:表示 Flower 跟 Leader的通信端口,简称服务端内部通信的端口(默认2888)
B:表示是选举端口(默认是3888)
例如:server.1=master:2888:3888
配置文件参考
tickTime=2000
initLimit=10
syncLimit=5
clientPort=2181
# 配置数据存储路径
????
# 配置日志文件路径
????
# 配置集群列表
server.1=????
server.2=????
server.3=????Zookeeper集群环境搭建(30分)
Zookeeper是一个分布式服务框架,是Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。
预装的配置文件zoo_sample.cfg下面默认有五个属性,分别是:
1.tickTime
心跳间隔,单位是毫秒,系统默认是2000毫秒,也就是间隔两秒心跳一次。
tickTime的意义:客户端与服务器或者服务器与服务器之间维持心跳,也就是每个tickTime时间就会发送一次心跳。通过心跳不仅能够用来监听机器的工作状态,还可以通过心跳来控制Flower跟Leader的通信时间,默认情况下FL的会话时常是心跳间隔的两倍。
2.initLimit
集群中的follower服务器(F)与leader服务器(L)之间初始连接时能容忍的最多心跳数(tickTime的数量)。
3.syncLimit
集群中flower服务器(F)跟leader(L)服务器之间的请求和答应最多能容忍的心跳数。
4.clientPort
客户端连接的接口,客户端连接zookeeper服务器的端口,zookeeper会监听这个端口,接收客户端的请求访问,端口默认是2181。
5.dataDir
该属性对应的目录是用来存放myid信息跟一些版本,日志,跟服务器唯一的ID信息等。
在集群Zookeeper服务在启动的时候,会回去读取zoo.cfg这个文件,从这个文件中找到这个属性然后获取它的值也就是dataDir 的路径,它会从这个路径下面读取myid这个文件,从这个文件中获取要启动的当前服务器的地址。
集群信息的配置:
在配置文件中,配置集群信息是存在一定的格式:service.N =YYY: A:B
N:代表服务器编号(准确对应对应服务器中myid里面的值)
YYY:服务器地址
A:表示 Flower 跟 Leader的通信端口,简称服务端内部通信的端口(默认2888)
B:表示是选举端口(默认是3888)
例如:server.1=master:2888:3888
配置文件参考
tickTime=2000
initLimit=10
syncLimit=5
clientPort=2181
# 配置数据存储路径
????
# 配置日志文件路径
????
# 配置集群列表
server.1=????
server.2=????
server.3=????考核条件如下:
1. 将zookeeper安装包解压到指定路径/usr/zookeeper(安装包存放于/usr/package277/)(3分)
操作环境: master、slave1、slave2
mkdir /usr/zookeeper
tar -zxvf /usr/package277/zookeeper-3.4.14.tar.gz -C /usr/zookeeper/ 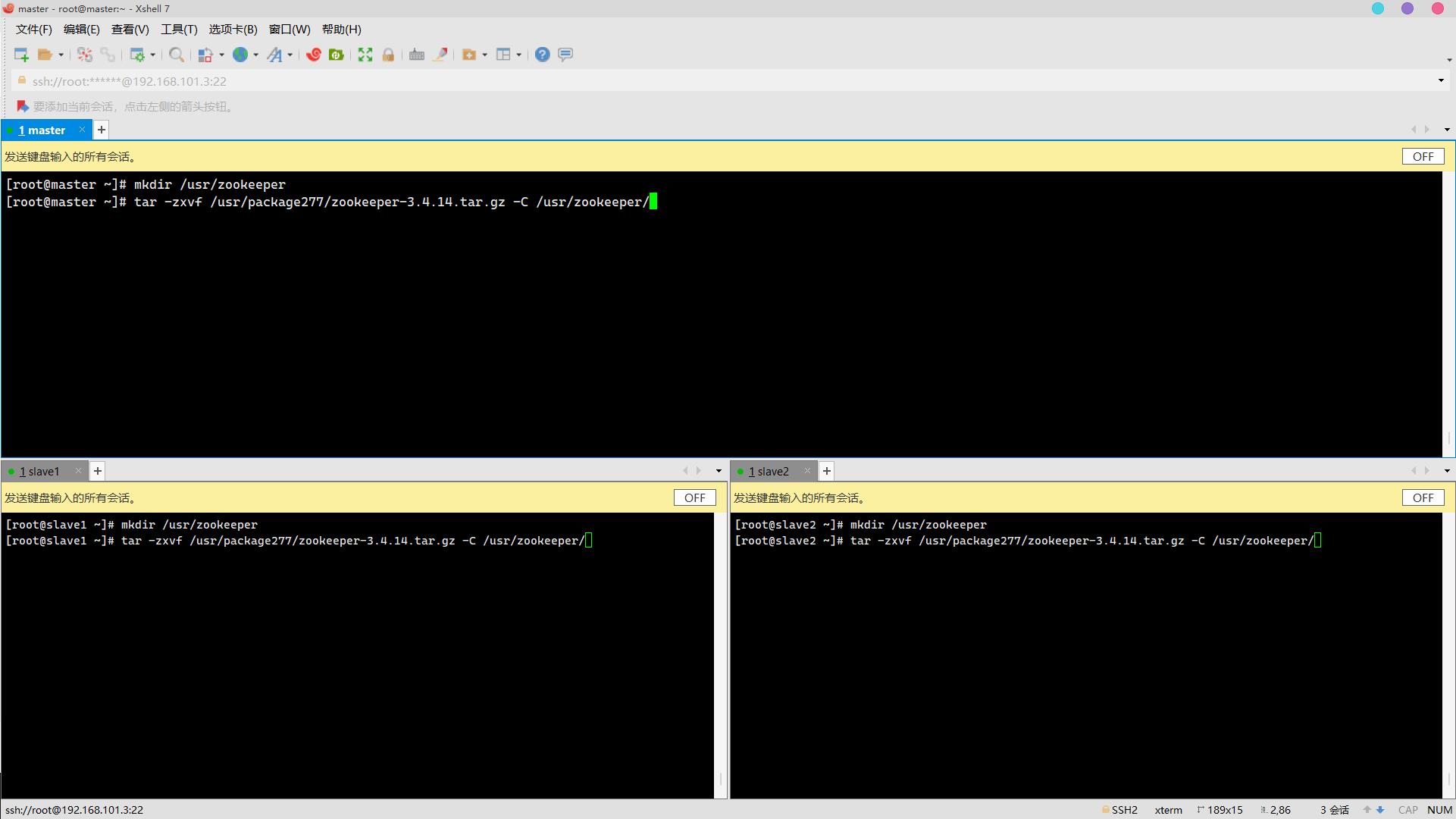
2. 文件/etc/profile中配置系统变量ZOOKEEPER_HOME,同时将Zookeeper安装路径中bin目录加入PATH系统变量,注意生效变量(3分)
操作环境: master、slave1、slave2
vim /etc/profile
加入:
#zookeeper
export ZOOKEEPER_HOME=/usr/zookeeper/zookeeper-3.4.14
export PATH=$PATH:$ZOOKEEPER_HOME/bin
source /etc/profile 
3. Zookeeper的默认配置文件为Zookeeper安装路径下conf/zoo_sample.cfg,将其修改为zoo.cfg(3分)
操作环境: master、slave1、slave2
cd /usr/zookeeper/zookeeper-3.4.14/conf/
ll
mv zoo_sample.cfg zoo.cfg
ll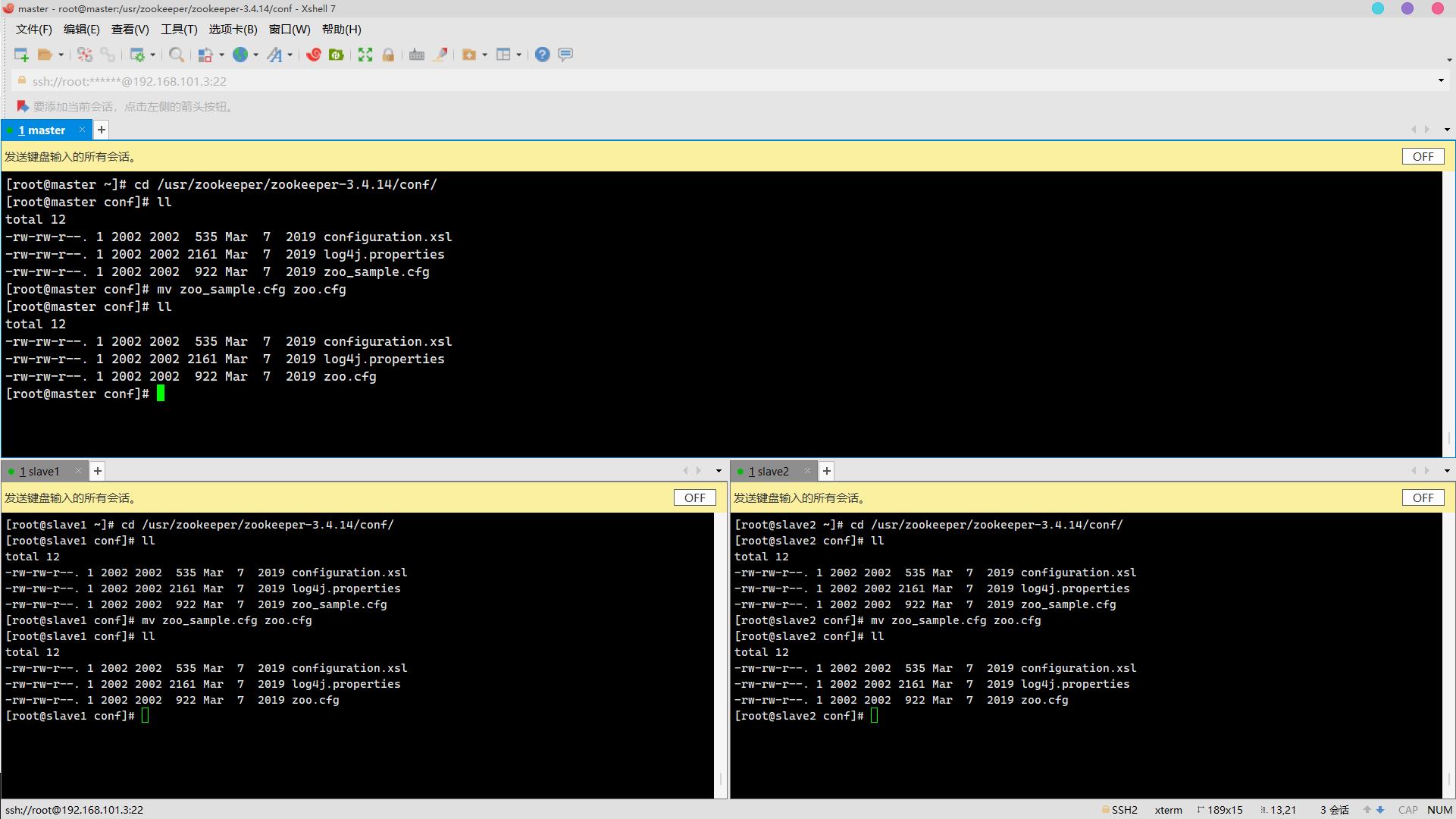 4. 设置数据存储路径(dataDir)为/usr/zookeeper/zookeeper-3.4.14/zkdata(3分)
4. 设置数据存储路径(dataDir)为/usr/zookeeper/zookeeper-3.4.14/zkdata(3分)
操作环境: master、slave1、slave2
5. 设置日志文件路径(dataLogDir)为/usr/zookeeper/zookeeper-3.4.14/zkdatalog(3分)
操作环境: master、slave1、slave2
6. 设置集群列表(要求master为1号服务器,slave1为2号服务器,slave2为3号服务器)(3分)
操作环境: master、slave1、slave2
4,5,6:
vim /etc/profile
修改:
dataDir=/usr/zookeeper/zookeeper-3.4.14/zkdata
加入:
dataLogDir=/usr/zookeeper/zookeeper-3.4.14/zkdatalog
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888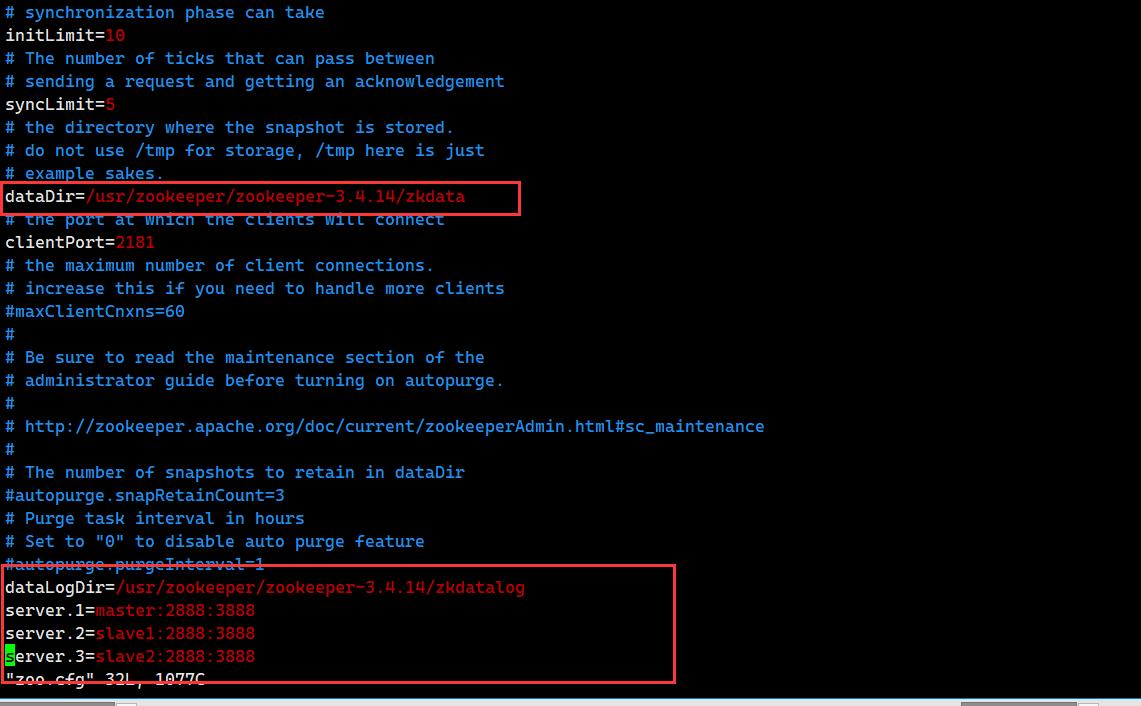 7. 创建所需数据存储文件夹、日志存储文件夹(3分)
7. 创建所需数据存储文件夹、日志存储文件夹(3分)
操作环境: master、slave1、slave2
cd /usr/zookeeper/zookeeper-3.4.14/
mkdir zkdata zkdatalog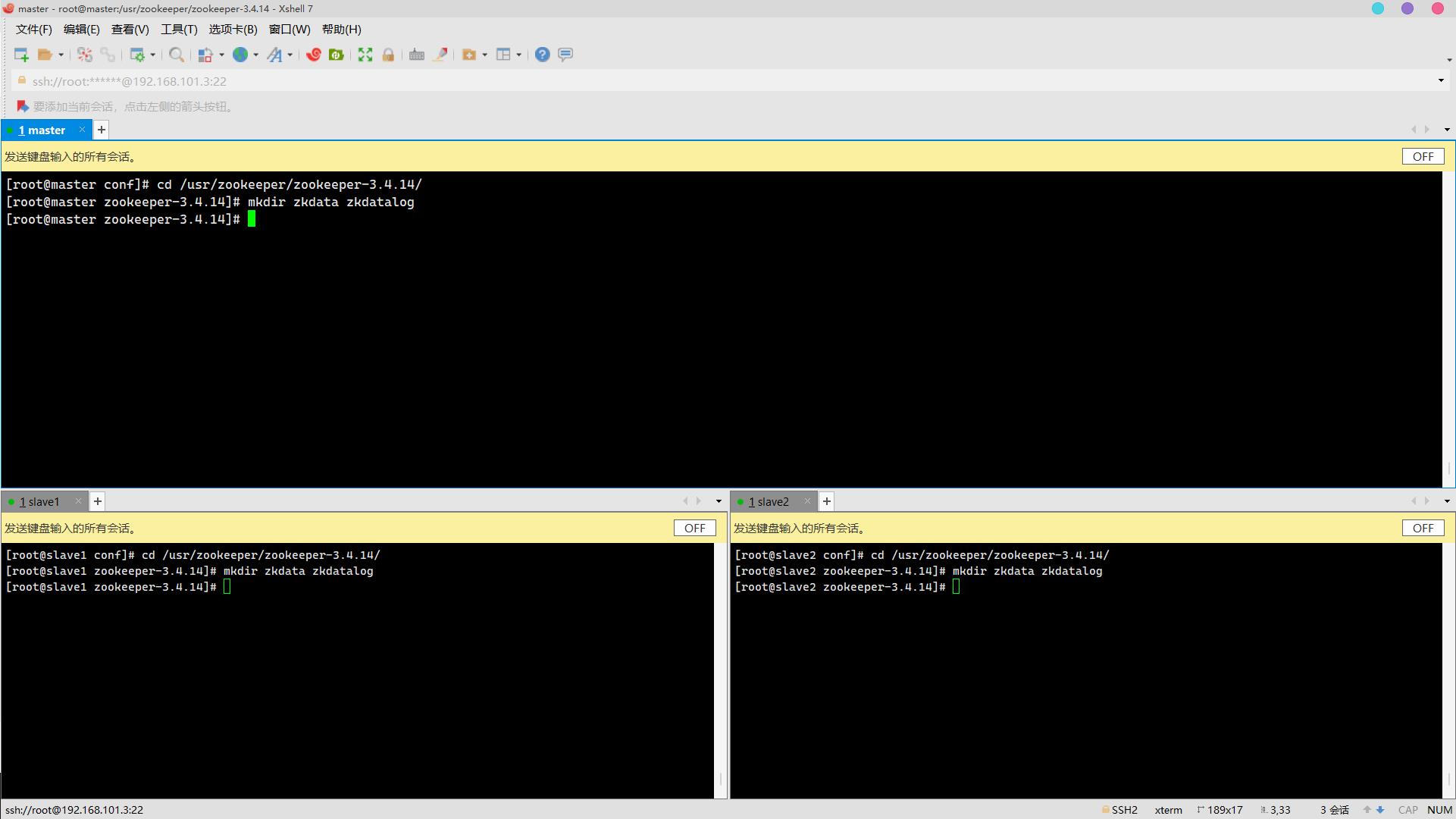 8. 数据存储路径下创建myid,写入对应的标识主机服务器序号(3分)
8. 数据存储路径下创建myid,写入对应的标识主机服务器序号(3分)
操作环境: master、slave1、slave2
cd zkdata
echo "1" >>myid (master上)
echo "2" >>myid (slave1上)
echo "3" >>myid (slave2上)
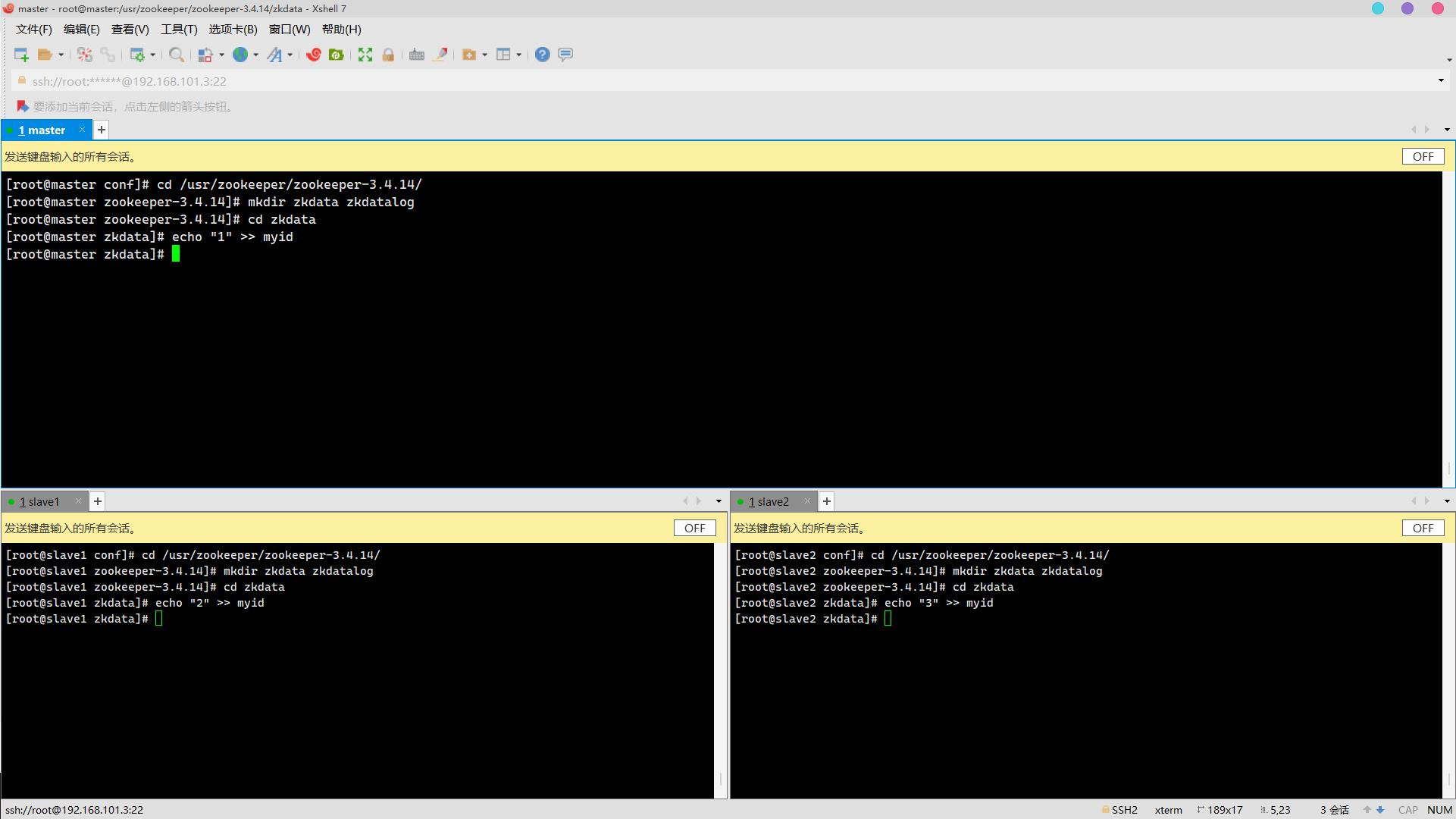
9. 启动服务,查看进程QuorumPeerMain是否存在(3分)
操作环境: master、slave1、slave2
cd ..
bin/zkServer.sh start
jps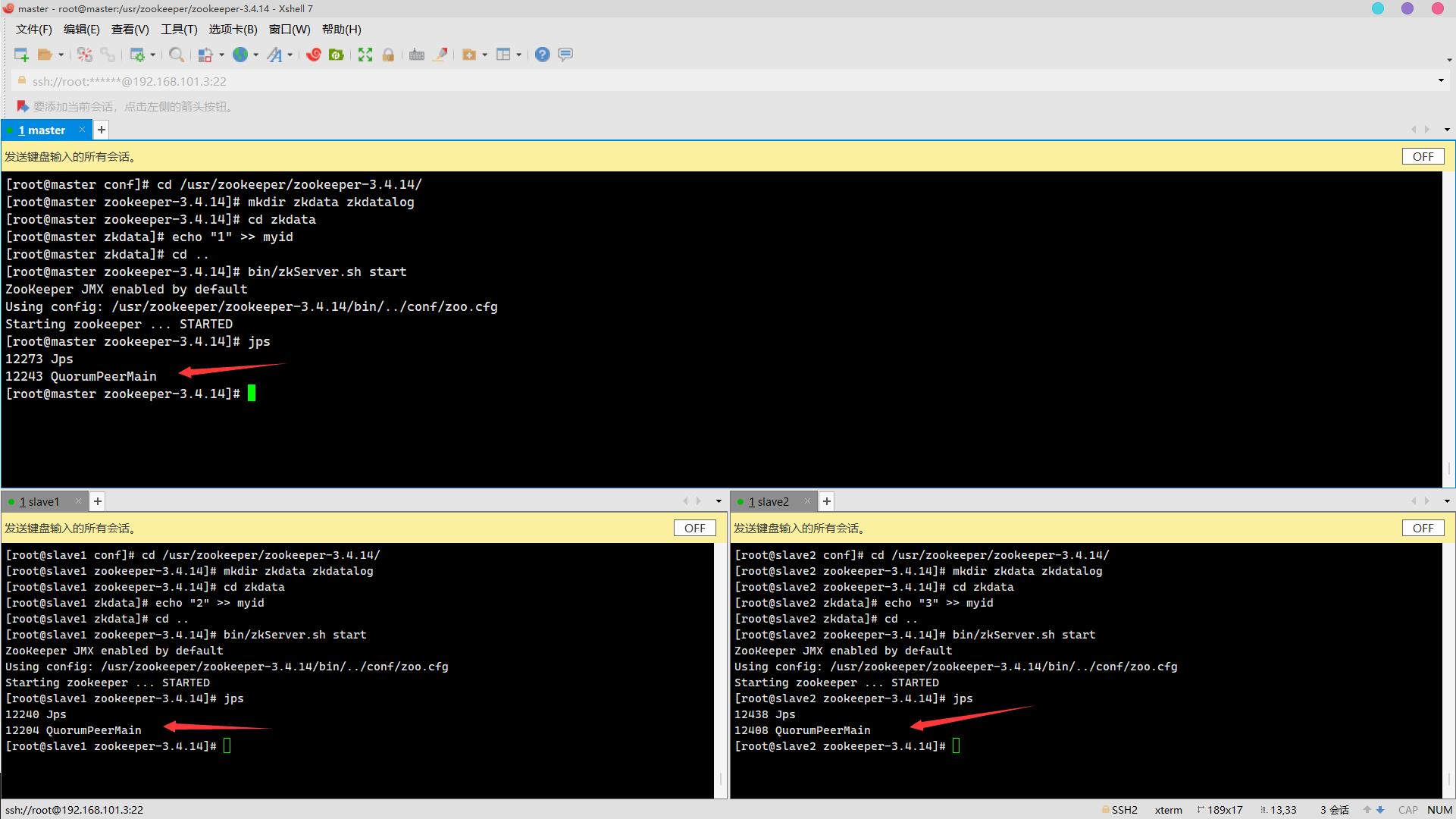 10. 查看各节点服务器角色是否正常(leader/follower)(3分)
10. 查看各节点服务器角色是否正常(leader/follower)(3分)
操作环境: master、slave1、slave2
bin/zkServer.sh status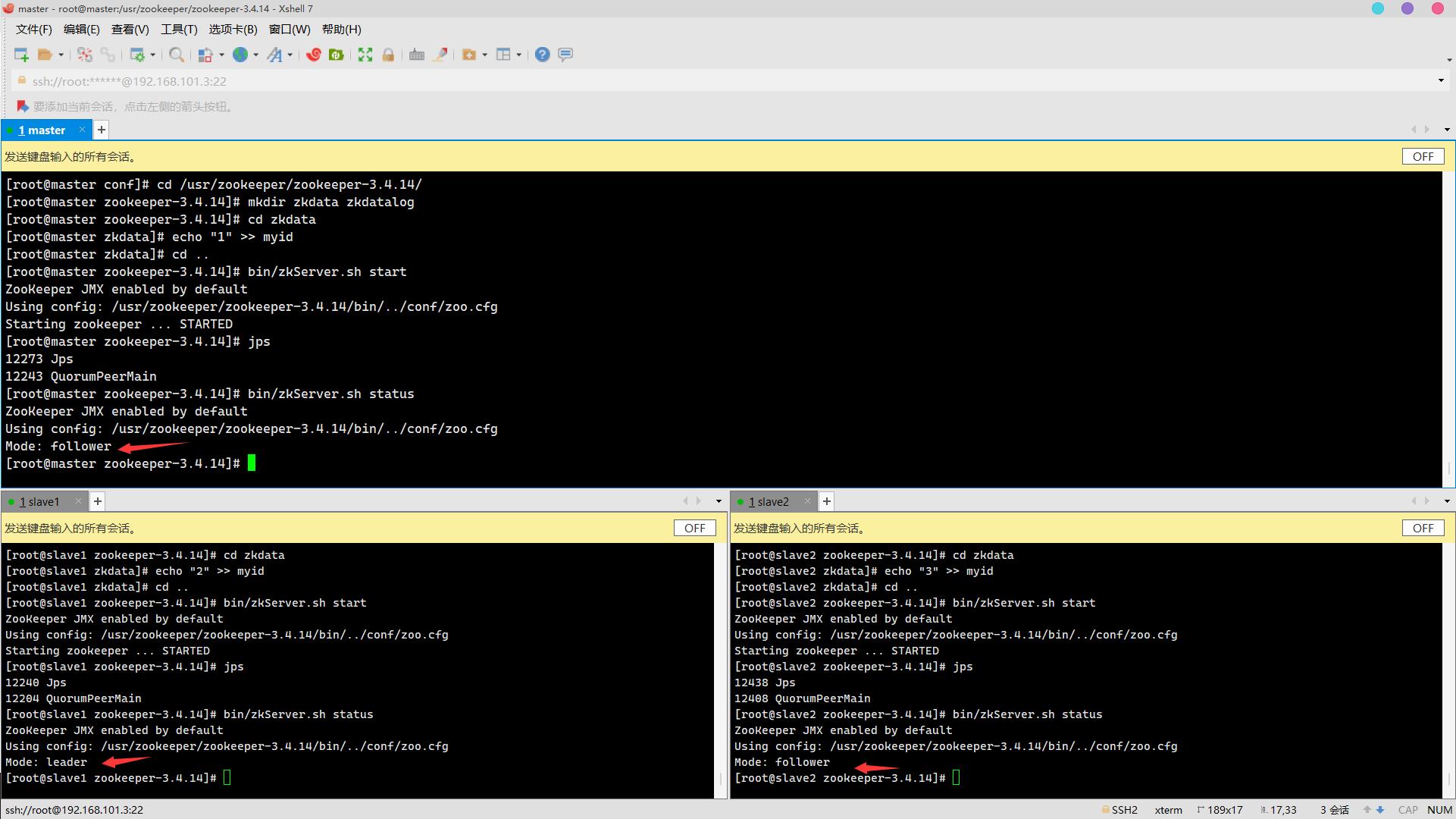
题目三、Hadoop集群搭建( 80分)
Hadoop是由Java语言编写的,在分布式服务器集群上存储海量数据并运行分布式分析应用的开源框架,其核心部件是HDFS与MapReduce。
- HDFS是一个分布式文件系统:引入存放文件元数据信息的服务器Namenode和实际存放数据的服务器Datanode,对数据进行分布式储存和读取。
- MapReduce是一个计算框架:MapReduce的核心思想是把计算任务分配给集群内的服务器里执行。通过对计算任务的拆分(Map计算/Reduce计算)再根据任务调度器(JobTracker)对任务进行分布式计算。
| 配置文件 | 配置对象 | 主要内容 |
| hadoop-env.sh | hadoop运行环境 | 用来定义Hadoop运行环境相关的配置信息; |
| core-site.xml | 集群全局参数 | 定义系统级别的参数,包括HDFS URL、Hadoop临时目录等; |
| hdfs-site.xml | HDFS参数 | 定义名称节点、数据节点的存放位置、文本副本的个数、文件读取权限等; |
| mapred-site.xml | MapReduce参数 | 包括JobHistory Server 和应用程序参数两部分,如reduce任务的默认个数、任务所能够使用内存的默认上下限等; |
| yarn-site.xml | 集群资源管理系统参数 | 配置ResourceManager ,nodeManager的通信端口,web监控端口等; |
Hadoop的配置类是由资源指定的,资源可以由一个String或Path来指定,资源以XML形式的数据表示,由一系列的键值对组成。资源可以用String或path命名(示例如下),
- String:指示hadoop在classpath中查找该资源;
- Path:指示hadoop在本地文件系统中查找该资源。
<configuration>
<property>
<name>fs.default.name</name>
<value>????</value>
</property>
</configuration>常用属性解析:
1.core-site.xml参数
| 配置参数 | 说明 |
| fs.default.name | 用于指定NameNode的地址 |
| hadoop.tmp.dir | Hadoop运行时产生文件的临时存储目录 |
2.hdfs-site.xml
| 配置参数 | 说明 |
| dfs.replication | 用于指定NameNode的地址 |
| dfs.namenode.name.dir | NameNode在本地文件系统中持久存储命名空间和事务日志的路径 |
| dfs.datanode.data.dir | DataNode在本地文件系统中存放块的路径 |
| dfs.permissions | 集群权限系统校验 |
| dfs.datanode.use.datanode.hostname | datanode之间通过域名方式通信 |
注意:外域机器通信需要用外网IP,未配置hostname访问会访问异常。可以在Java api客户端使用conf.set("fs.client.use.datanode.hostname","true");。
3.mapreduce-site.xml
| 配置参数 | 说明 |
| mapreduce.framework.name | 指定执行MapReduce作业的运行时框架。属性值可以是local,classic或yarn。 |
4.yarn-site.xml
| 配置参数 | 说明 |
| yarn.resourcemanager.admin.address | 用于指定RM管理界面的地址(主机:端口) |
| yarn.nodemanager.aux-services | mapreduce 获取数据的方式,指定在进行mapreduce作业时,yarn使用mapreduce_shuffle混洗技术。这个混洗技术是hadoop的一个核心技术,非常重要。 |
| yarn.nodemanager.auxservices.mapreduce.shuffle.class | 用于指定混洗技术对应的字节码文件,值为org.apache.hadoop.mapred.ShuffleHandler |
Hadoop完全分布式集群搭建(80分)
Hadoop是由Java语言编写的,在分布式服务器集群上存储海量数据并运行分布式分析应用的开源框架,其核心部件是HDFS与MapReduce。
- HDFS是一个分布式文件系统:引入存放文件元数据信息的服务器Namenode和实际存放数据的服务器Datanode,对数据进行分布式储存和读取。
- MapReduce是一个计算框架:MapReduce的核心思想是把计算任务分配给集群内的服务器里执行。通过对计算任务的拆分(Map计算/Reduce计算)再根据任务调度器(JobTracker)对任务进行分布式计算。
| 配置文件 | 配置对象 | 主要内容 |
| hadoop-env.sh | hadoop运行环境 | 用来定义Hadoop运行环境相关的配置信息; |
| core-site.xml | 集群全局参数 | 定义系统级别的参数,包括HDFS URL、Hadoop临时目录等; |
| hdfs-site.xml | HDFS参数 | 定义名称节点、数据节点的存放位置、文本副本的个数、文件读取权限等; |
| mapred-site.xml | MapReduce参数 | 包括JobHistory Server 和应用程序参数两部分,如reduce任务的默认个数、任务所能够使用内存的默认上下限等; |
| yarn-site.xml | 集群资源管理系统参数 | 配置ResourceManager ,nodeManager的通信端口,web监控端口等; |
Hadoop的配置类是由资源指定的,资源可以由一个String或Path来指定,资源以XML形式的数据表示,由一系列的键值对组成。资源可以用String或path命名(示例如下),
- String:指示hadoop在classpath中查找该资源;
- Path:指示hadoop在本地文件系统中查找该资源。
<configuration>
<property>
<name>fs.default.name</name>
<value>????</value>
</property>
</configuration>常用属性解析:
1.core-site.xml参数
| 配置参数 | 说明 |
| fs.default.name | 用于指定NameNode的地址 |
| hadoop.tmp.dir | Hadoop运行时产生文件的临时存储目录 |
2.hdfs-site.xml
| 配置参数 | 说明 |
| dfs.replication | 用于指定NameNode的地址 |
| dfs.namenode.name.dir |