送你两个神器,关系数据库数据入湖轻松应对
Posted 华为云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了送你两个神器,关系数据库数据入湖轻松应对相关的知识,希望对你有一定的参考价值。
摘要:关系数据库的数据入湖,有多种场景、多种工具、多种入湖时效要求等,本文梳理相关场景,以及对应的建议方案。
本文分享自华为云社区《关系数据库数据入湖的场景及方案总结》,作者:HisonHuang 。
关系数据库的数据入湖,有多种场景、多种工具、多种入湖时效要求等,本文梳理相关场景,以及对应的建议方案。
首先介绍下两种入湖工具:批量数据迁移工具(如CDM)和实时数据接入工具(如CDL)。
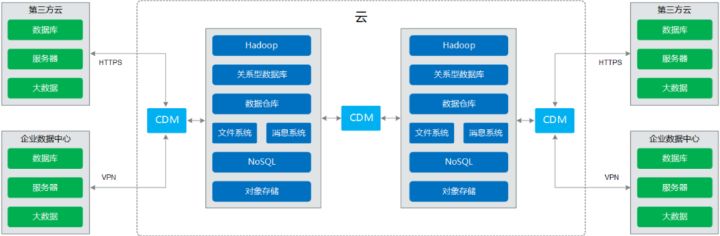
批量数据迁移工具,可以一次全量、一次全量+批次增量的方式将数据从关系数据库的数据迁移到数据湖,往往入湖时效性(从数据产生到数据进入数据湖贴源层)在10多分钟或更长,如15分钟左右,取决于批次增量迁移任务的时间间隔。以下是批量数据迁移工具(CDM)的功能架构图:
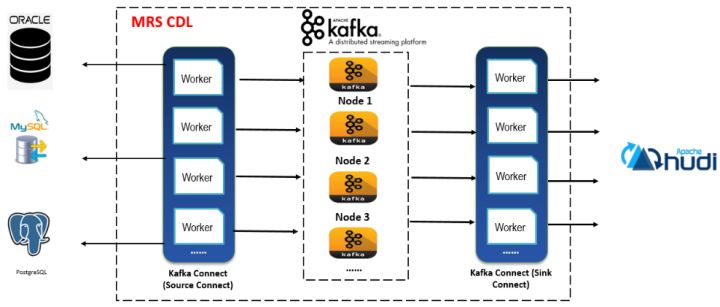
实时数据接入工具(如CDL),可以实时捕获关系数据库的binlog日志,保存在消息队列如Kafka,并支持实时解析binlog日志生成增删改命令来操作数据湖的数据记录,实现关系数据库的数据实时入湖,入湖时效性在秒级或分钟级,一般小于15分钟。以下是实时数据接入工具(CDL)的功能架构图:
场景1:关系数据库有存量历史数据,无实时产生的新数据
方案:
1、入湖工具:批量数据迁移工具(如CDM)
2、入湖方式:整表迁移,示意如下:

3、入湖流程:
3.1、使用入湖工具,配置关系数据库作为源端,配置HDFS/Hive的目录作为目的端;
3.2、用入湖工具启动入湖作业,关系数据库-》HDFS目录(数据湖贴源层)。
场景2:关系数据库初始无数据,在建立入湖流程后,关系数据库才开放数据写入
方案:
前置条件:关系数据库打开binlog日志开关。
1、入湖工具:实时数据接入工具(如CDL)
2、入湖方式:实时增量数据入湖,示意如下:

3、入湖流程:
3.1、使用入湖工具,配置关系数据库作为源端,配置Hudi文件的目录作为目的端;
3.2、启动入湖工具运行;
3.3、关系数据库的实时增量数据入湖;
3.3.1、数据记录插入、修改、删除到关系数据库;
3.3.2、关系数据库的数据变化日志被实时捕获到入湖工具;
3.3.3、入湖工具解析日志,调用Hudi接口插入、修改、删除数据记录到Hudi文件的目录(数据湖贴源层)。
场景3:关系数据库有存量历史数据,且实时产生新数据,数据记录有时间标识字段
方案1:
1、入湖工具:批量数据迁移工具(如CDM)
2、入湖方式:首次存量历史数据入湖+持续批次增量数据入湖
3、入湖时效:近实时(取决于批次调度周期)
4、入湖流程:
4.1、假设关系数据库实时产生稳定数量的新数据;
4.2、使用入湖工具,配置关系数据库作为源端,配置HDFS/Hive的目录作为目的端;
4.3、用入湖工具,启动存量数据入湖作业,其中Where过滤条件的时间标识字段从初始时间截止到当前时间;
注:存量数据入湖作业运行时间较久,视存量历史数据量、网络带宽、入湖作业吞吐量等因素决定。在此期间,关系数据库由于不断接受新写入,累积较大量的新数据。
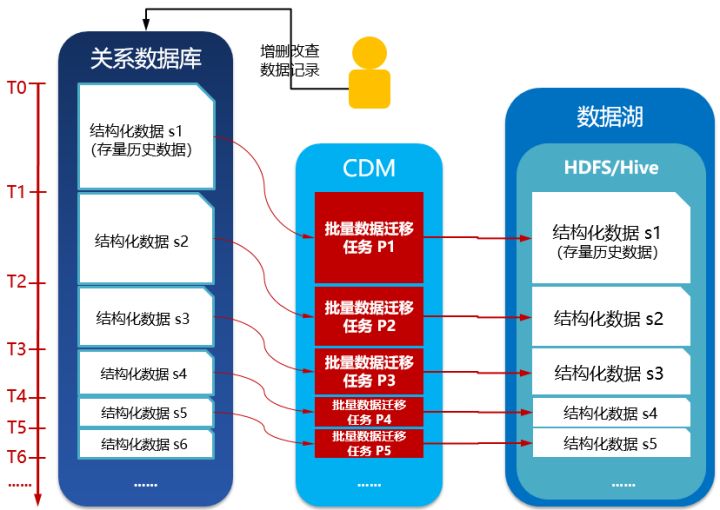
4.4、持续批次启动增量数据入湖作业,其中Where过滤条件的时间标识字段从上一批次作业的截止时间到到当前时间;每批次迁移数据量逐步减少,批次之间的时间间隔逐步减小并趋向稳定,每批次作业所占用的计算资源也逐步减小并趋向稳定。示意如下:
方案2:
前置条件:关系数据库打开binlog日志开关。
1、入湖工具:批量数据迁移工具(如CDM)+ 实时数据接入工具(如CDL)
2、入湖方式:首次存量历史数据入湖+持续批次增量数据入湖+实时增量数据入湖
3、入湖时效:前两个阶段非实时,最后阶段进入实时
4、入湖流程:
4.1、假设关系数据库实时产生稳定数量的新数据;
4.2、使用批量数据迁移工具,配置关系数据库作为源端,配置HDFS/Hive的目录作为目的端(表A,文件格式可能是CSV);
4.3、用批量数据迁移工具,启动存量数据入湖作业,其中Where过滤条件的时间标识字段从初始时间截止到当前时间;
注:存量数据入湖作业运行时间较久,视存量历史数据量、网络带宽、入湖作业吞吐量等因素决定。在此期间,关系数据库由于不断接受新写入,累积较大量的新数据。
4.4、持续批次启动增量数据入湖作业,其中Where过滤条件的时间标识字段从上一批次作业的截止时间到到当前时间;每批次迁移数据量逐步减少,批次之间的时间间隔逐步减小并趋向稳定,每批次作业所占用的计算资源也逐步减小并趋向稳定;
4.5、某时间点Ts暂停关系数据库的数据写入,确保Ts之前的数据全部由批次作业迁移到了HDFS目录(数据湖贴源层);
4.6、停止批量数据迁移工具的批次作业。
4.7、使用实时数据接入工具,配置关系数据库作为源端,配置Hudi文件的目录作为目的端(表B,文件格式是Hudi);
4.8、启动实时数据接入工具运行;
4.9、此时Te关系数据库开放数据写入;
4.10、关系数据库的实时增量数据入湖;
4.10.1、关系数据库的数据变化日志被实时捕获到实时数据接入工具;
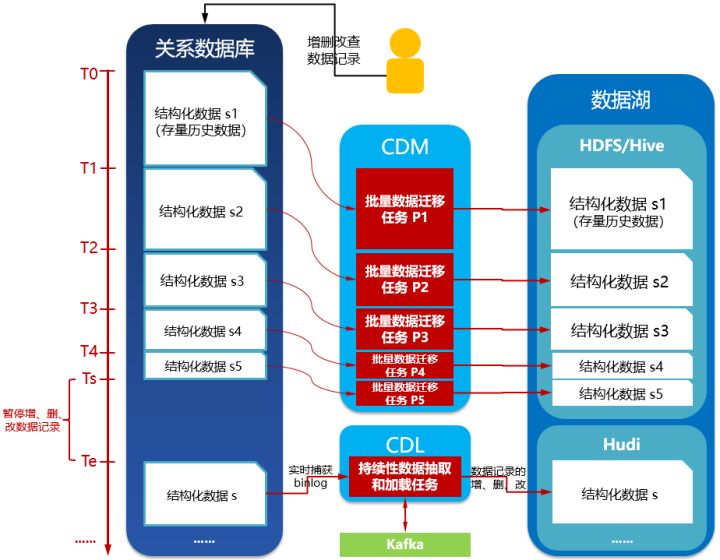
4.10.2、实时数据接入工具解析日志,调用Hudi接口插入、修改、删除数据记录到Hudi文件的目录(数据湖贴源层)。示意如下:
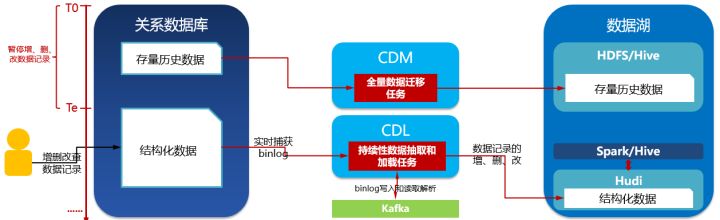
场景4:关系数据库有存量历史数据,且实时产生新数据,数据记录无时间标识字段
方案:
前置条件:关系数据库打开binlog日志开关。
1、入湖工具:批量数据迁移工具(如CDM)+ 实时数据接入工具(如CDL)
2、入湖方式:整表迁移+实时增量数据入湖
3、入湖时效:最后阶段进入实时
4、入湖流程:
4.1、暂停关系数据库的数据写入;
4.2、使用批量数据迁移工具,配置关系数据库作为源端,配置HDFS/Hive的目录作为目的端(表A,文件格式可能是CSV);
4.3、用批量数据迁移工具批量数据迁移工具启动入湖作业,关系数据库-》HDFS目录(数据湖贴源层);
4.4、以上存量数据迁移完成后,停止批量数据迁移工具的批次作业;
4.5、使用实时数据接入工具,配置关系数据库作为源端,配置Hudi文件的目录作为目的端(表B,文件格式是Hudi);
4.6、启动实时数据接入工具运行;
4.7、此时Te关系数据库开放数据写入;
4.8、关系数据库的实时增量数据入湖;
4.8.1、关系数据库的数据变化日志被实时捕获到实时数据接入工具;
4.8.2、实时数据接入工具解析日志,调用Hudi接口插入、修改、删除数据记录到Hudi文件的目录(数据湖贴源层)。示意如下:
以上是关于送你两个神器,关系数据库数据入湖轻松应对的主要内容,如果未能解决你的问题,请参考以下文章