NLP注意力机制在神经网络中的应用
Posted HL Lee
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NLP注意力机制在神经网络中的应用相关的知识,希望对你有一定的参考价值。
注意力机制在神经网络中的应用
0. 前言
这篇是我在一门专业选修课上的结课论文,当时的认识还是太过浅薄。
最近开始系统学习NLP相关知识,先将这篇小论文发出来,之后会写关于2017年谷歌发布的《Attention Is All You Need》的笔记,还有Transformer的代码实现。鼓励自己学习,欢迎大家批评指正。
1. 相关认知神经科学的实验结果
注意力视觉同认识神经科学的联系是在视觉方面,我们经常说的注意力不集中都是体现在我们使用眼睛去看的过程。对于注意力机制的研究,早在上世纪九十年代就有人研究,但是在本世纪才出现了对于注意力机制在视觉领域和自然语言处理方面的应用。
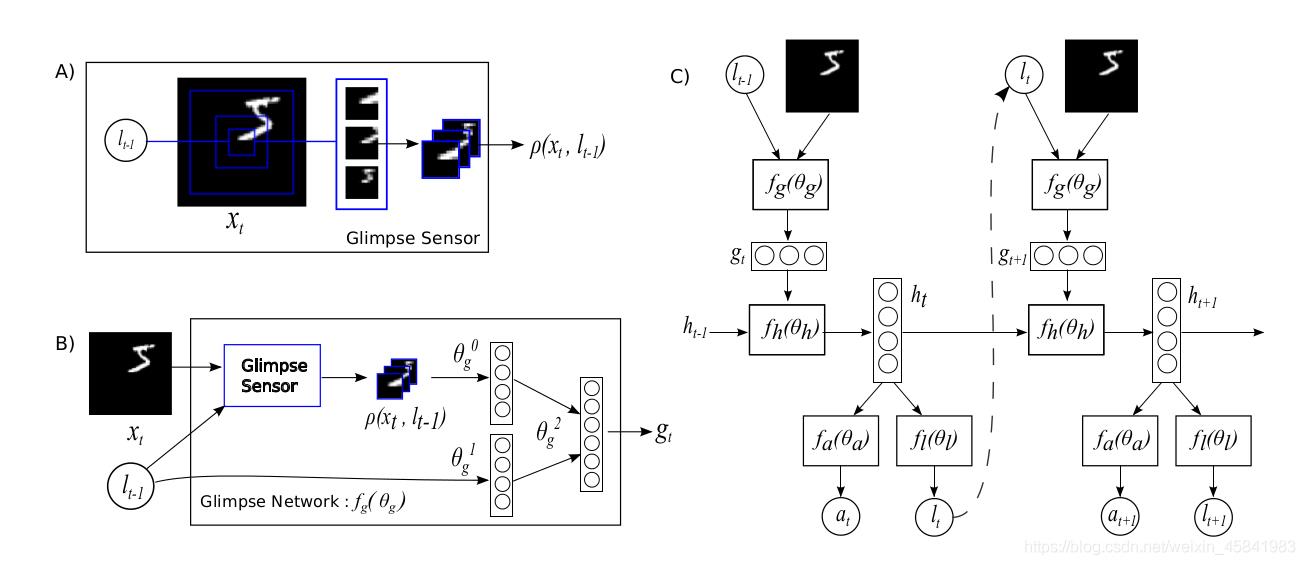
2014年,Google Deep Mind发表了题为《Recurrent Models of Visual
Attention》的论文,第一次将注意力机制应用在计算机视觉领域,该研究组织将注意力机制引入到RNN模型当中,提出了RAM(The
Recurrent Attention
Model)模型按照时间顺序处理输入,一次在一张图像中处理不同位置,结合信息以建立一个同环境相关的动态间隔表示,该模型可以基于过去的信息和任务需要选择下一个位置进行处理,可以摆脱源文件的大小约束。
同年,Bahdanau[1]等人发表论文《Neural Machine Translation by Jointly Learning to Align and Translate》,在这篇文章中,将类似注意力机制应用在了NLP(Neural Language Processing,自然语言处理)领域,其采用Seq2Seq+Attention模型来进行机器翻译,效果得到显著提升,之后,基于Attention的RNN模型被广泛应用到各种NLP任务中。
2015年,Minh-Thang Luong[2]发表论文《Effective Approaches to Attention-based Neural Machine Translation》,本篇论文极大促进了后续各种基于attention机制的模型在NLP领域的应用,在该篇文章中,提出了全局注意力机制和局部注意力机制。
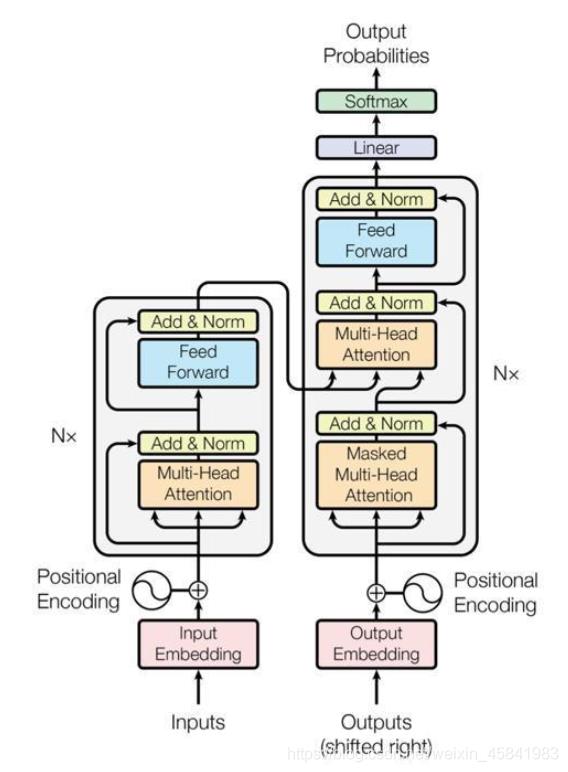
Attention机制的研究重要节点是2017年,Google的机器翻译团队在NIPS
2017发表《Attention is All You Need》[3],该研究中,完全摆脱了RNN和CNN等现有网络结构的束缚,仅仅采用了Attention机制来完成机器翻译任务,提出了Transformer网络结构,Transformer在NLP、CV(Computer Vision, 计算机视觉)领域都得到充分应用。
2018年,Google进一步发展Transformer网络,发布《Pre-training of Deep
Bidirectional Transformers for Language
Understanding》[4],BERT模型是基于Transformer发展而来,对Attention机制的应用更加充分,成功在11项NLP任务中取得优秀成果,在自然语言处理领域得到不少赞声。
2. 算法的基本原理
人工智能这个学科的出现,便是人们对机器拟人态的追求,Attention机制便是对人的感知方式和注意力原理的应用。
人类视觉领域的注意力机制是人类视觉特有的信号处理机制,人大脑视觉领域可以通过快速扫描图像局部,获取需要重点关注的目标区域,集中注意力。对于判断为无关的区域,将给予极少的和注意力,这样的视觉原理使得人类可以利用有限的注意力资源从大量信息中筛选得到高价值的信息,极大提高了人类视觉处理信息的效率,同时保证了准确性,下图很好的表示了人类对于注意力的合理安排。

人类将更多的注意力分配到人脸、文字等具有极高辨识度的区域,而对文章中的空白背景等不具有特征的部分则不会倾注太多注意力[7]。
注意力机制便是将该原理应用到机器学习中,计算机视觉领域就是使机器训练识别关注点,从而忽略其他不重要的部分,在机器中的操作是使其模糊化。而在自然语言处理领域,则是采取提取关键字的方式来集中机器注意力。
对于Attention机制原理的阐述离不开encoder-decoder模型,最初注意力机制便是在这个模型中得到使用,而且目前大多数注意力模型也都是依赖于encoder-decoder框架下。
该框架可以看作是一种研究模式,抽象框架中,我们是先将源语言输入encoder中进行编码,得到语义编码c传递给decoder中进行解码,从而实现语言间的翻译。
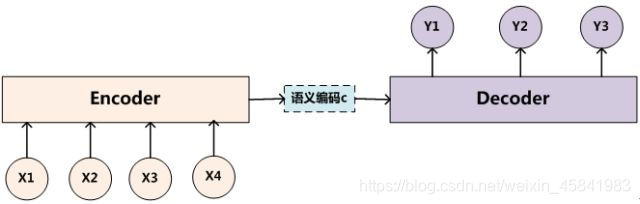
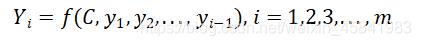
这种传统的encoder-decoder框架是没有体现出注意力的重要性的,它属于注意力不集中的分心模型,在这样的框架下的翻译,对每个词翻译时,其他单词都对翻译产生一样的影响,而实际上我们在翻译特定词时,这个单词本身应该占有很大的权重,这样才能在翻译长句子时也保证准确性。
在分配了不同的权重之后,encoder-decoder框架中间的予以编码C换成根据当前翻译单词基于注意力模型来调整得到的变化的Ci变量[7]。
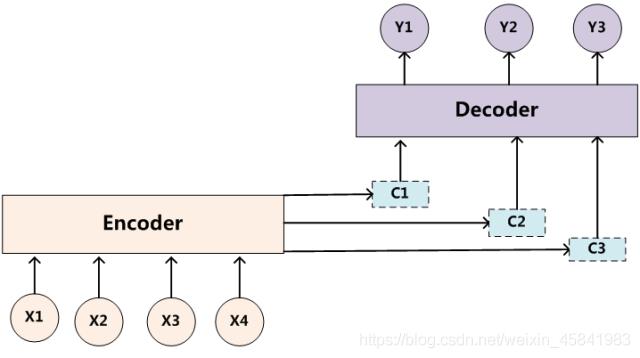
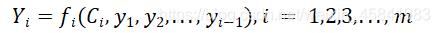
公式中,针对不同的待翻译元素,Ci取到不同的值,同时,语义编码的过程中还要考虑到其他元素对于翻译产生的影响。在不同权重比的影响下,机器对单词的翻译的准确度得到提高,短句对齐效果更好。
基于上面对于encoder-decoder框架的解释,我们下面介绍Attention机制的本质思想。我们可以将源语言中的词汇想象成是由一系列键值对<Key,
Value>构成,譬如在英语中,dance这样的实义动词和yeah这样的语气词会具有不同的Value,然后我们给定目标语言中某个元素Query,然后进行如下三步操作。
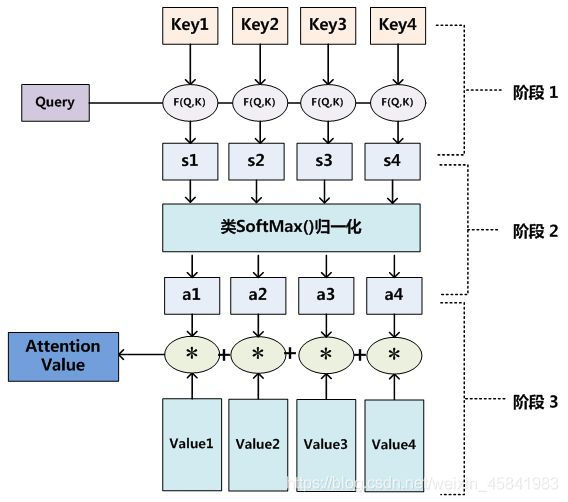
第一步是要先计算Q和K的相似程度,公式如下:
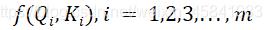
第二步是将得到的相似度进行Softmax操作,实现归一化。
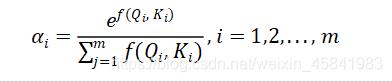
最后一步是需要将得到的归一化权重,同键值对中的Value计算加权和,得到我们需要的Attention向量。
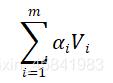
由Attention向量的计算过程,我们可以体会到注意力机制的核心思想,即将有限的注意力放到少量重要信息上,忽略大部分不重要的信息,而重要性的判断则是依靠Value值,Value值越大代表其带给我们的信息越重要。
这种Attention类型称之为Soft Attention[6],软性注意力机制的关注相对发散,实际应用中将元素归一化为0~1之间的元素。与之相对性的Hard
Attention在实际应用中只输出一个0或1二元变量。
举一个简单的NLP例子,我们将一句“我爱中国。”,翻译的结果应该是“I love
China.”如果采用硬性注意力机制,翻译“我”,归一化结果为[1,0,…],即在当前时刻,模型只关注于当前单词的翻译,而完全忽略其他单词。按照语言的一般化规律,我们无法对这样的强模型进行优化。
而使用Soft Attention,便不会忽略其他元素对翻译的影响,在翻译“我”的时候,归一化得到的权重可能为[0.6,0,1,0.3],当前时刻,对“我”的翻译,它便占了大权重,而下一时刻模型翻译“爱”时,权重可能更新为[0.2,0.7,0.1],这样的一个变化,使得我们在关注到当前翻译元素的同时,也不会完全忽略其他词带来的信息影响。
3. 算法的应用领域和效果
注意力机制的应用主要是NLP自然语言处理和CV计算机视觉两个领域。
3.1 注意力机制在NLP领域的应用
Attention机制在NLP领域的典型代表是在《Neural Machine Translation by Jointly Learning to Align and Translate》[1]论文中,这篇论文是第一次在NLP领域使用attention机制。
论文中以NLP中机器翻译来举例子,图4中是经典的神经网络机器翻译encoder-decoder模型[5]。
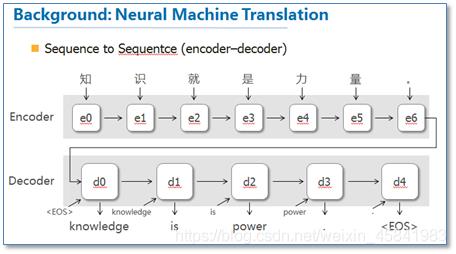
传统的NMT模型使用两个RNN神经网络,第一个RNN模型对源语言进行编码,将源语言编码到一个固定的维度的中间向量,然后使用另一个RNN模型进行解码翻译,翻译成目标语言。而图5中添加了Attention机制的NMT模型,它把源语言端的每个词的表达都学到,然后和预测翻译的词建立联系,这种联系的可靠性就是依靠Attention机制提供保证,训练完毕后,根据得到的attention矩阵,我们就可以实现源语言和目标语言的对齐。
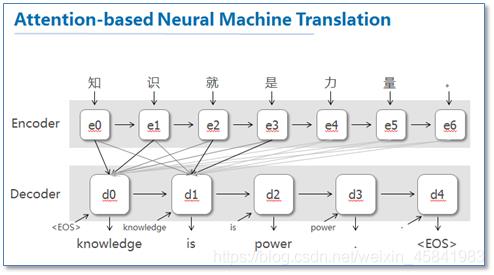
《Effective Approaches to Attention-based Neural Machine Translation》[2]中,Global类型的attention同上一篇论文中的机器翻译模型思路相差不多,都是对源语言所有词进行处理,只不过在这篇论文中,作者提出了几种计算attention矩阵的简单扩展版本。
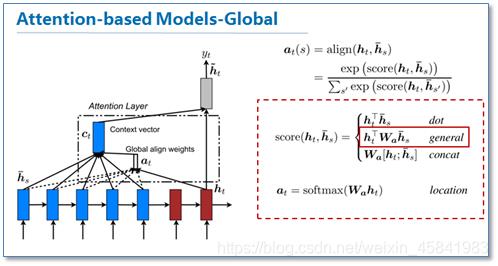
在NLP领域具有重要意义的是作者在这篇论文中提到的local类型的attention模型,这个类型的主要思路是为减少attention计算耗费,在计算attention矩阵时,并不是考虑到源语言端的所有元素,而是根据一个预测函数,确定一个大致的范围,论文中提出local-m和local-p两种方式。
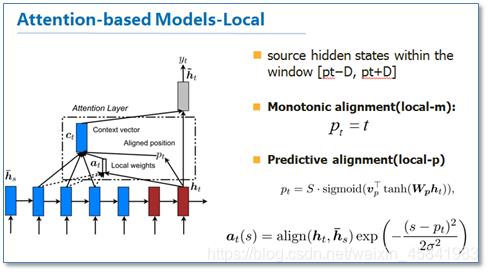
这篇论文启示了大家如何在自然语言处理领域应用attention机制,如何进行相对应的扩展,还有就是引入了局部attention方法。
Attention机制引入NLP领域实际上是起到了短句对齐的一个功能,传统的短句对齐准确度不高,翻译效果不好。2016年,Google部署了他们基于神经网络的机器翻译系统,在这个系统,引入了Attention机制,相比传统模型翻译效果有大幅提升,翻译错误率下降了60%,效果十分可观。
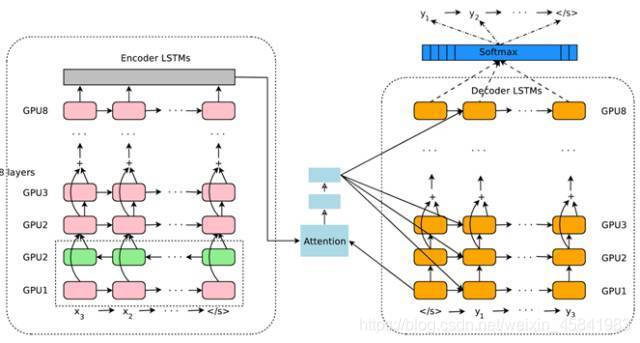
目前Attention在NLP中已经有广泛的应用。它有一个很大的优点就是可以可视化attention矩阵来告诉大家神经网络在进行任务时关注了哪些部分。不过在NLP中的attention机制和人类的attention机制还是有所区别,它基本还是需要计算所有要处理的对象,并额外用一个矩阵去存储其权重,其实增加了开销。而不是像人类一样可以忽略不想关注的部分,只去处理关注的部分。
3.2 注意力机制在CV领域的应用
计算机视觉中一种经典的应用就是图片描述,即我们输入一幅图画,模型通过不同的注意力集中机制,根据图片中的不同元素,输出一句描述当前图片的语句,是实现图文结合的经典实例,类似于我们在英语或语文学习中做过的看图说话。
图片描述任务依然需要用到encoder-decoder框架,此时encoder编码器需要输入一张图片,而decoder解码器需要输出一句描述语句。在encoder处选用CNN神经网络对图片进行特征提取,在解码器部分需要使用RNN或者LSTM等NLP任务经典的模型输出描述语句。
在注意力机制加入后的翻译过程可以用带有MASK的模糊图来展示这一过程。

最终我们根据图片得到的描述语句为“A person is standing on a beach with a
surfboard”。
注意力机制的短句对齐优势体现在,如果我们选择语句中的一个单词,它可以确定该单词表述的大致图片范围是哪里,这也为我们做该问题的逆问题——语句与图片的匹配提供的思路,具体表现在下面的四个例子中体现出来。

4. 算法的优点和缺点讨论
Attention机制的引入,主要是处于Attention机制的三个优点
4.1 算法优点分析
-
参数少。引入Attention之后的模型复杂度同CNN、RNN等经典模型相比,复杂度更小,参数也更少。模型对于计算机的算力要求也就更小。
-
速度快。RNN模型中,不能进行并行计算,而Attention机制每一步计算都不依赖于上一步的计算结果,因此Attention机制可以实现和CNN一样的并行处理操作。
-
效果好。Attention机制引入之前,研究人员面临一个令人烦恼的问题:长距离的信息会被弱化,就好比记忆能力弱的人对于过去较为久远的记不太起来。 而Attention机制是模型挑重点,在处理长文本的时候,Attention机制可以从中间抓住重点,避免重要信息丢失。
4.2 算法缺点分析
算法应用至今,对其缺点的描述不是很多。如果分析注意力机制的缺点,那可能是由于发展不充分导致的。
注意力机制选择区域并不能完全模仿人的视觉机制进行,模仿人的视觉原理可能是算法的最终目标。但就目前来看,尽管提出了Soft Attention和Self Attention去拟人化,但是本质上还是给图画分配权重。这方面可能还需要认识神经科学领域的研究进一步加深。
5. 参考文献
- Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. ICLR, 2015. Neural Machine Translation by Jointly Learning to Align and Translate.
- Minh-Thang Luong, Hieu Pham, and Christopher D Manning. EMNLP, 2015.Effective approaches to attention-based neural machine translation.
- Ashish Vaswani, et al. NIPS, 2017. Attention Is All You Need.
- Devlin J , Chang M W , Lee K , et al. BERT: Pre-training of Deep
Bidirectional Transformers for Language Understanding[J]. 2018.- Robert_ai.注意力机制(Attention Mechanism)在自然语言处理中的应用.https://www.cnblogs.com/robert-dlut/p/5952032.html
- super灬睿.注意力机制(Attention Mechanism)浅谈.https://zhuanlan.zhihu.com/p/364819787
- 张俊林.深度学习中的注意力机制(2017版).https://blog.csdn.net/malefactor/article/details/78767781
以上是关于NLP注意力机制在神经网络中的应用的主要内容,如果未能解决你的问题,请参考以下文章