注意力机制
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了注意力机制相关的知识,希望对你有一定的参考价值。
参考技术A 本文大部分的内容来自于 深度学习中的注意力机制意力机制借鉴了人类注意力的说法,比如我们在阅读过程中,会把注意集中在重要的信息上。在训练过程中,输入的权重也都是不同的,注意力机制就是学习到这些权重。最开始attention机制在CV领域被提出来,但后面广泛应用在NLP领域。
需要注意的是,注意力机制是一种通用的思想和技术,不依赖于任何模型,换句话说,注意力机制可以用于任何模型。只是我们介绍注意力机制的时候更多会用encoder-decoder框架做介绍。
Encoder-Decoder 框架可以看作是一种深度学习领域的研究模式,应用场景异常广泛。下图是文本处理领域里Encoder-Decoder 框架最抽象的一种表示。
在NLP领域,可以把Encoder-Decoder框架看作是:将一个句子(篇章)转换成另一个句子(篇章)。最直观的例子就是机器翻译,将一种语言的表达翻译成另一种语言。对于句子对<source,target>,将给定输入句子
source,通过Encoder-Decoder框架生成目标句子target。其中,source和target都是一组单词序列:
Encoder是对source进行编码,转换成中间语义 :
对于解码器Decoder,其任务是根据中间语义C和当前已经生成的历史信息来生成下一时刻要生成的单词:
我们从最常见的Soft Attention模型开始介绍attention的基本思路。
在上一节介绍的Encoder-Decoder框架是没有体现出“注意力模型”的,为什么这么说呢?我们可以看下target的生成过程:
其中, 是Decoder的非线性变换函数。从上面式子中可以看出,在生成目标句子的单词时,不论生成哪个单词,它们使用的输入句子source的语义编码 都是一样的,没有任何区别。而语义编码 又是通过对source经过Encoder编码产生的,因此对于target中的任何一个单词,source中任意单词对某个目标单词 来说影响力都是相同的,这就是为什么说图1中的模型没有体现注意力的原因。
下面从一个例子入手,具体说明下注意力机制是怎么做的。
比如机器翻译任务,输入source是英文句子:Tom chase Jerry;输出target想得到中文:汤姆 追逐 杰瑞。在翻译“Jerry”这个单词的时候,在普通Encoder-Decoder模型中,source里的每个单词对“杰瑞”的贡献是相同的,很明显这样不太合理,因为“Jerry”对于翻译成“杰瑞”更重要。如果引入Attention模型,在生成“杰瑞”的时候,应该体现出英文单词对于翻译当前中文单词不同的影响程度,比如给出类似下面一个概率分布值:
每个英文单词的概率代表了翻译当前单词“杰瑞”时注意力分配模型分配给不同英文单词的注意力大小。同理,对于target中任意一个单词都应该有对应的source中的单词的注意力分配概率,可以把所有的注意力概率看作 ,其中 表示source长度, 表示target长度。而且,由于注意力模型的加入,原来在生成target单词时候的中间语义 就不再是固定的,而是会根据注意力概率变化的 ,加入了注意力模型的Encoder-Decoder框架就变成了如图2所示。
根据图2,生成target的过程就变成了下面形式:
因为每个 可能对应着不同的注意力分配概率分布,比如对于上面的英汉翻译来说,其对应的信息可能如下:
其中, 表示Encoder对输入英文单词的某种变换函数,比如如果Encoder是用RNN模型的话,这个 函数的结果往往是某个时刻输入 后隐层节点的状态值;g代表Encoder根据单词的中间表示合成整个句子中间语义表示的变换函数,一般的做法中,g函数就是对构成元素加权求和,即:
其中, 代表输入句子Source的长度, 代表在Target输出第 个单词时Source输入句子第 个单词的注意力分配系数,而 则是Source输入句子中第 个单词的语义编码。假设下标 就是上面例子所说的“汤姆”生成如下图:
那另一个问题来了:注意力概率分布是怎么得到的呢?为了便于说明,我们假设图1的Encoder-Decoder框架中,Encoder和Decoder都采用RNN模型,那么图1变成下图4:
那么注意力分配概率分布值的通用计算过程如图5:
上面就是经典的soft Attention模型的基本思想,区别只是函数 会有所不同。
从我的角度看,其实Attention机制可以看作,Target中每个单词是对Source每个单词的加权求和,而权重是Source中每个单词对Target中每个单词的重要程度。因此,Attention的本质思想会表示成下图6:
将Source中的构成元素看作是一系列的<Key, Value>数据对,给定Target中的某个元素Query,通过计算Query和各个Key的相似性或者相关性,即权重系数;然后对Value进行加权求和,并得到最终的Attention数值。将本质思想表示成公式如下:
其中, 表示Source的长度。
深度学习中的注意力机制 中提到:
因此,Attention机制的具体计算过程实际上分成了3个阶段,如图7:
第一阶段可以引入不同的函数和计算机制,根据Query和某个 ,计算两者的相似性或者相关性,最常见的方法包括:求两者的向量点积、求两者的向量cosine相似性或者引入额外的神经网络来求值,如下:
第二阶段引入类似SoftMax的计算方式,对第一阶段的得分进行数值转换,一方面可以进行归一化,将原始计算分值整理成所有元素权重之和为1的概率分布;另一方面也可以通过SoftMax的内在机制更加突出重要元素的权重。即一般采用的公式如下:
第三阶段的计算结果 即为 对应的权重系数,然后进行加权求和即可得到Attention数值:
通过如上三个阶段的计算,就可以求出针对Query的Attention数值。
上面介绍的是soft Attention,hard Attention的区别在于soft Attention中 是概率分布,而hard Attention取值为0/1。Hard Attention在图像上有使用,具体可见 引入attention机制 。
这里的global attention其实就是soft Attention,global attention需要考虑encoder中所有的 ;而local Attention直观上理解是只考虑局部的 。
Self-attention是Google在transformer模型中提出的,上面介绍的都是一般情况下Attention发生在Target元素Query和Source中所有元素之间。而Self Attention,指的是Source内部元素之间或者Target内部元素之间发生的Attention机制,也可以理解为Target=Source这种特殊情况下的注意力机制。当然,具体的计算过程仍然是一样的,只是计算对象发生了变化而已。
上面内容也有说到,一般情况下Attention本质上是Target和Source之间的一种单词对齐机制。那么如果是Self Attention机制,到底学的是哪些规律或者抽取了哪些特征呢?或者说引入Self Attention有什么增益或者好处呢?仍然以机器翻译为例来说明,如图8和图9:
具体做法是点乘 和 ,然后除以 ,并经过Softmax,以此得到 的权重。也就是说Attention计算过程如下式,其中 是scaled factor:
注意力的计算一般有两种:加性注意力(additive attention)、乘法(点积)注意力(multiplicative attention)。(这里可以和第3部分计算相似度对应)
加性注意力是最经典的注意力机制,它使用了有一个隐藏层的前馈网络(全连接)来计算注意力; 乘法注意力就是Transformer用的方式。这两种注意力在复杂度上是相似的,但是乘法注意力在实践中要更快速、具有高效的存储,因为它可以使用矩阵操作更高效地实现。
Transformer原文:
Multi-Head Attention是用不同的 得到不同的Attention,最后将这些Attention拼接起来作为输出。公式如下:
其中, ;在Transformer模型中, 。
Scaled Dot-Product Attention和Multi-Attention如下图所示:
面向CV的注意力机制——通道注意力空间注意力自注意力等
前言
本文介绍注意力机制的概念和基本原理,并站在计算机视觉CV角度,进一步介绍通道注意力、空间注意力、混合注意力、自注意力等。
目录
一、注意力机制
我们可以通过眼睛看到各种各样的事物,感知世界上的大量信息;可以让自己免受海量信息的干扰,是因为人的选择能力,可以选择重要的信息,而忽视不重要信息。
举个例子,下面有一张图片,当我们看到这张图片的时候会下意识把注意力集中到熊猫的身上,而忽略背景。

即:在观看这幅图像的时候,并非能够对图片的所有信息给予相同的关注度,而是将注意力着重放在某个局部区域。
同样,希望网络也具有这种能力,从而在网络中引入了注意力机制。注意力机制,是对输入进行加权再输出,希望网络关注到的地方给较大的权重,不希望网络注意的地方给较小的权重。
再举个例子,在自然语言处理领域,在分析一句话的时候,并不是所有的词的信息都需要被关注,可以选择重要的词分析,即可理解句子所传达的语义。
1.1 注意力机制原理
注意力机制在语义分割和图像描述生成方面被广泛使用。使用注意力处理任务时,不同信息的重要程度由权值来体现。
注意力机制对不同信息关注度的区分体现在权值分配,注意力机制可以视为查询矩阵、键以及加权平均值构成了多层感知机(Multilayer Perceptron, MLP)。
注意力的思想,类似于寻址。给定 Query,去 Source 中计算 Query和不同 Key 的相关性,即计算 Source 中不同 Value 值的权重系数;Value 的加权平均结果可以作为注意力值。
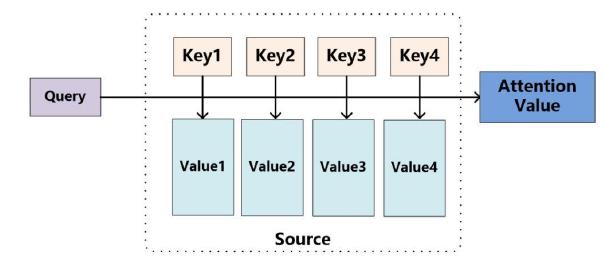
注意力的计算公式如下: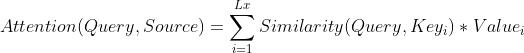
其中,Lx代表Source的长度。
1.2 注意力机制计算过程
大多数方法采用的注意力机制计算过程可以细化为如下三个阶段。
三阶段的注意力机制计算流程:
- 第一阶段是计算 Query和不同 Key 的相关性,即计算不同 Value 值的权重系数;
- 第二阶段对上一阶段的输出进行归一化处理,将数值的范围映射到 0 和 1 之间。
- 第三阶段,对值和每个值对应的权重相乘的结果做累加操作,从而获得注意力数值。
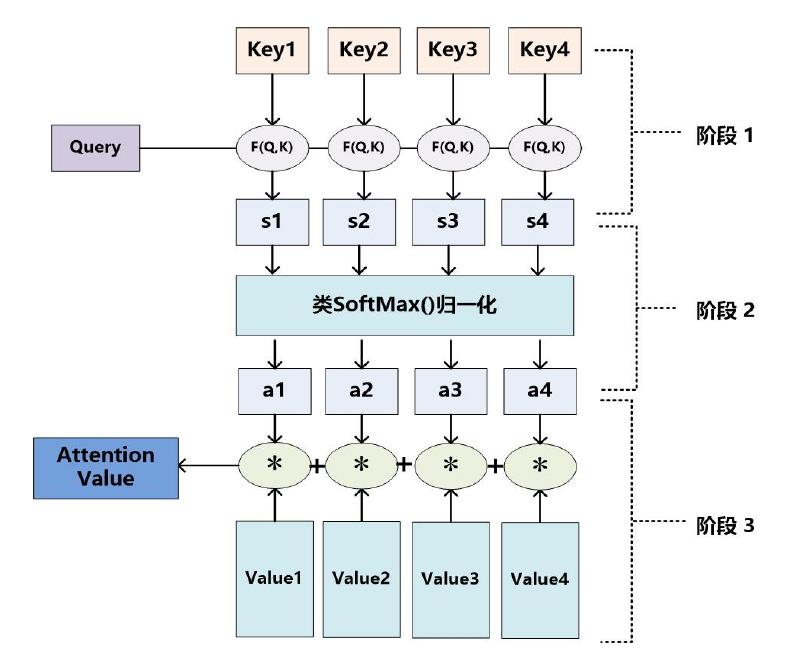
公式化表示:
第一阶段是计算 Query和不同 Key 的相关性,即计算不同 Value 值的权重系数;相关性计算主要包括点积、余弦相似性或者引入神经网络这三种方法。计算方式分别如下:
第二阶段对上一阶段的输出进行归一化处理,将数值的范围映射到 0 和 1 之间。其中,ai表第 i 个值被分为的权重值。
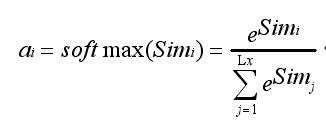
第三阶段,对值和每个值对应的权重相乘的结果做累加操作,从而获得注意力数值。
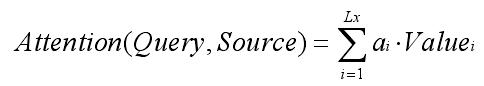
二、通道注意力机制
通道注意力机制的代表模型是:压缩和激励网络(Squeeze-and-Excitation Networks,SENet)。SENet 分为压缩和激励两个部分,其中压缩部分的目的是对全局空间信息进行压缩,然后在通道维度进行特征学习,形成各个通对道的重要性,最后通过激励部分对各个通道进行分配不同权重的。
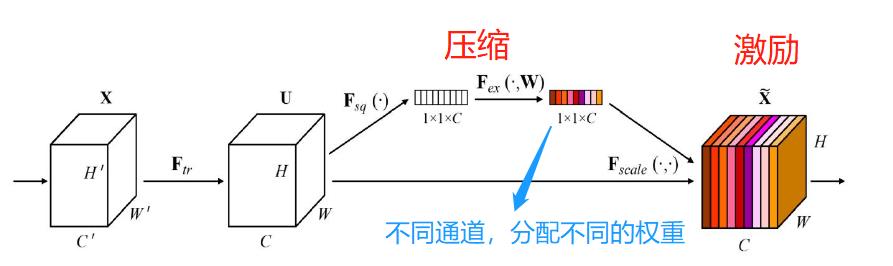
上图是SE模块的结构, 在压缩部分,输入的元素特征图的维度是 H×W×C,H、W 和 C 分别代表高度、宽度和通道数。压缩部分的功能是将维数从 H×W×C 压缩至1×1×C,即把 H×W 压缩为 1×1 维,这个过程由全局平均池化实现。
在激励部分,需要将压缩部分得到的 1×1×C 的维度融入全连接层,预测各个通道的重要程度,然后再激励到前面特征图对应通道上进行操作。采用简单的门控机制与Sigmoid 激活函数。
小结:在通道注意力机制,学习各个通道的重要性时,是先对特征图的空间进行压缩,然后在通道维度进行学习,得到各个通道的重要性。
三、空间注意力机制
空间注意力机制的代表模型是:空间变换神经网络(Spatial Transformer Networks,STN),STN 能够对各种形变数据在空间中进行转换并自动捕获重要区域特征。它能够保证图像在经过裁剪、平移或者旋转等操作后,依然可以获得和操作前的原始图像相同的结果。
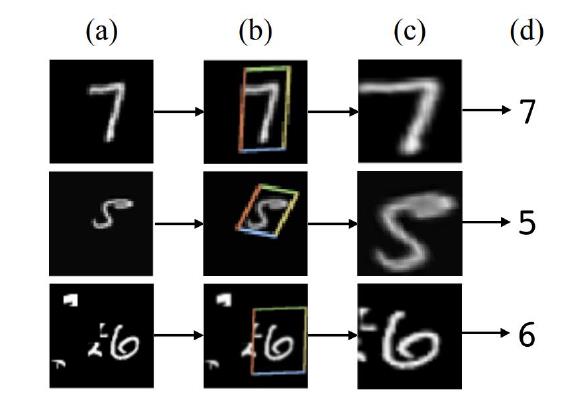
举个例子,在MNIST 数字分类的中应用STN,该分类过程一共包含 4 个步骤:
- MNIST中的数字,是经过随机平移、缩放和旋转处理;把它们输入到STN网络中;
- 通过STN网络,预测前面输入数字的变换(是平移了?还是缩放了?或是旋转了?)
- STN网络预测出“变换前的数字”,即没经过变换的数字是怎样的
- 最终进行分类预测
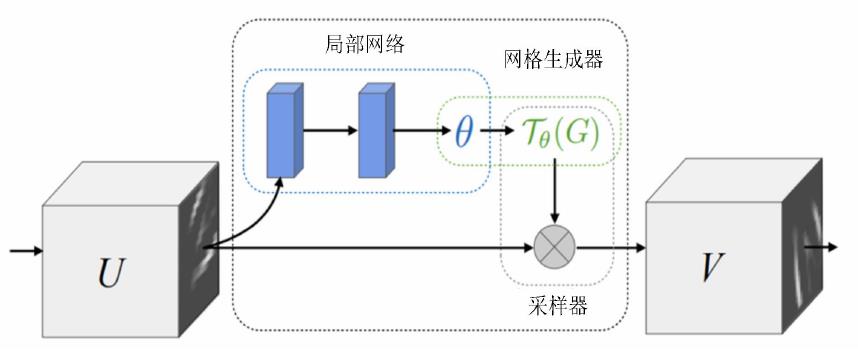
STN 网络包括局部网络、参数化网络采样(网络生成器)和差分图像采样。
局部网络:预测输入数字的变换(是平移了?还是缩放了?或是旋转了?)
网络生成器:获得输出特征图坐标点在输入特征图中坐标点的对应位置。
四、混合注意力机制
在混合注意力机制中,通道注意力和空间注意力可以通过串联、或者并联的方式进行组合。
混合注意力机制的代表模型是:卷积注意力模块(Convolutional Block Attention Module,CBAM),它包括通道注意力模块CAM、和空间注意力模块SAM。
CBAM的模型结构如下,它对输入的特征图,首先进行通道注意力模块处理;得到的结果,再经过空间注意力模块处理,最后得到调整后特征。
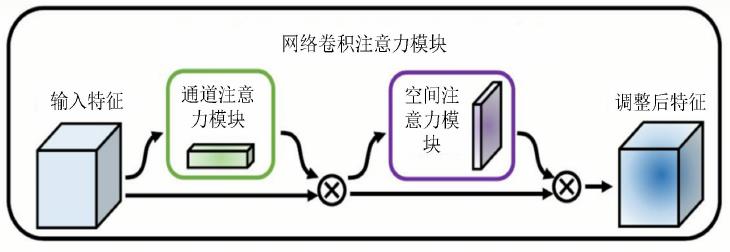
通道注意力模块CAM
CAM的输入是特征图,维度设为HxWxC;其中H是指特征图的高度,W是指宽度,C是指通道数。
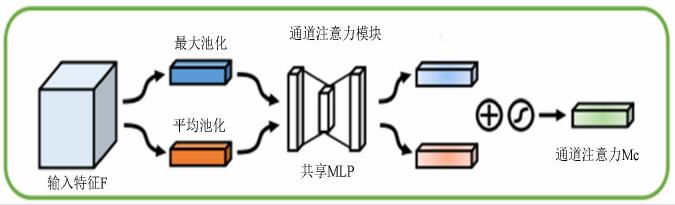
它的思路流程是:
- 首先对输入的特征图,进行全局池化和平均池化;(在空间维度进行池化,压缩空间尺寸;便于后面学习通道的特征)
- 然后将得到全局和评价池化的结果,送入到多层感知机中MLP学习;(基于MLP学习通道维度的特征,和各个通道的重要性)
- 最后将MLP输出额结果,进行“加”操作,接着经过Sigmoid函数的映射处理,得到最终的“通道注意力值”。
计算公式如下:
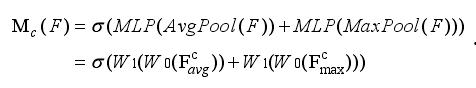
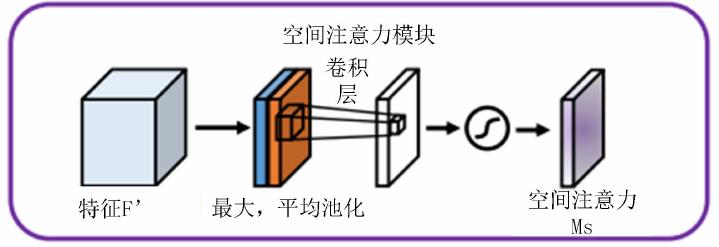
空间注意力模块SAM
SAM的输入是CAM输出的特征图。
它的思路流程是:
- 首先对输入的特征图,进行全局池化和平均池化;(在通道维度进行池化,压缩通道大小;便于后面学习空间的特征)
- 然后将全局池化和平均池化的结果,按照通道拼接;得到特征图维度是HxWx2,
- 最后对拼接的结果,进行卷积操作,得到特征图维度是HxWx1;接着通过激活函数处理。
计算公式如下:
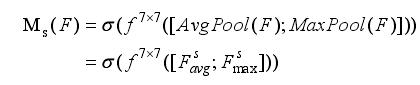
五、自注意力机制
背景
在注意力机制引入计算机视觉前,主要是靠叠加卷积层与池化层来进行特征提取,并扩大感受野。举个例子,在语义分割中,Deeplab系列提出的带有多尺度空洞卷积的 ASPP 模块:
- ASPP对输入的特征图,采用不同dilation rate 的空洞卷积进行卷积操作,以多个不同比例获取图像的上下文信息。
- ASPP模块只能利用空洞卷积从像素点周围的少数点去获取上下文信息,而不能形成密集的全局上下文信息。
为了获得密集的全局上下文信息,从而建立像素两两之间的依赖关系,引入“自注意力机制”。
参考文献
[1] 谢雨杉. 基于深度神经网络的图像语义分割技术研究[D].成都:电子科技大学,2022.
[2] 冀芒来. 基于注意力机制的道路驾驶场景实时语义分割[D].吉林:吉林大学,2022.
本文只是简单介绍了注意力机制中的通道注意力、空间注意力、自注意力,后续文章会分别详细介绍,其中的模型包括:SK-Net、ResNeSt、DANet、PFANet、SOCA、ECA-Net等等
以上是关于注意力机制的主要内容,如果未能解决你的问题,请参考以下文章