这一部分主要对注意力机制(Attention Mechanism)做一个概述,整合一下之前学习的内容,免得遗忘。
来源
注意力机制的设计,或者说命名,是借鉴了人类的注意力机制。人类的注意力机制属于生物的天性之一,无论是视觉还是听觉,都可以让我们在大量信息中筛选并关注高价值信息,获取更多所需要关注目标的细节信息,而抑制其他无用信息,极大地提高了信息处理的效率与准确性。
Encoder-Decoder(Seq2seq)
要了解注意力机制,就需要先理解Seq2seq问题,Seq2Seq是一种语言建模方法,可以使用Encoder-Decoder框架来实现的端到端的模型。它的目标是将输入序列转换为目标序列,并且两个序列的长度都可以是任意的。转换任务的例子包括文本或音频的翻译、问答、对话生成等等。
Encoder-Decoder框架的结构如下面一个文本翻译图所示:
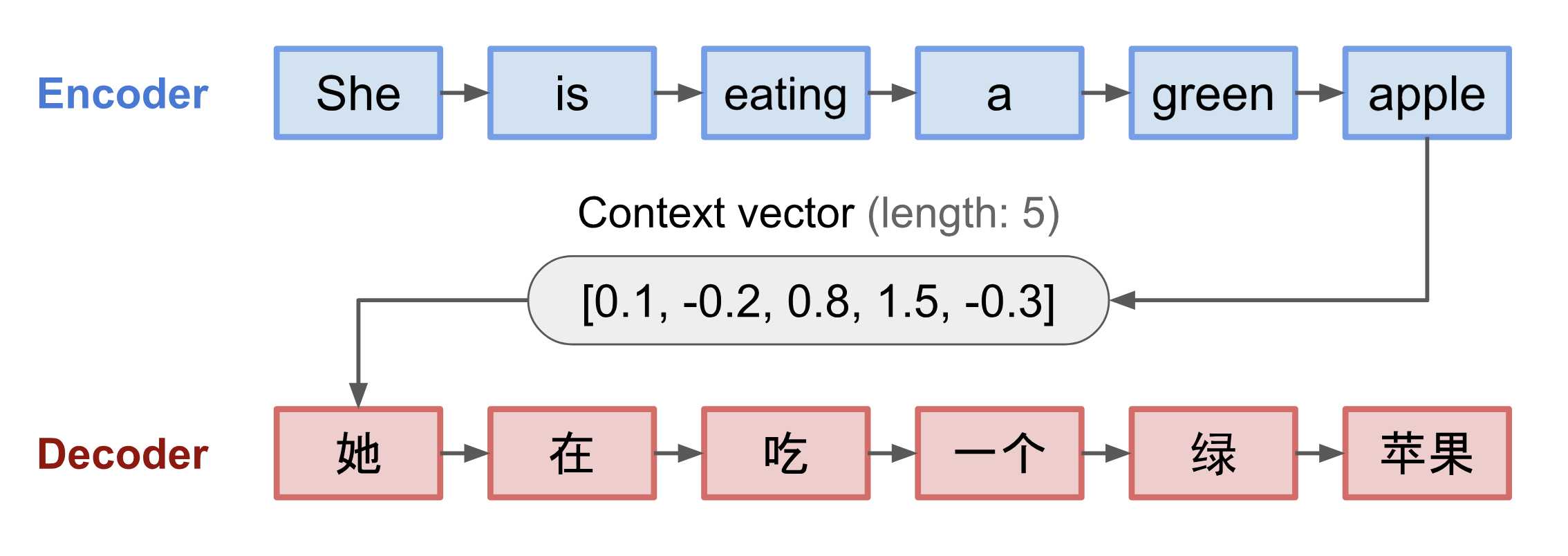
Encoder(编码器):负责处理输入序列,并将信息压缩成固定长度的上下文向量(Context Vector),上下文向量的目的是概括整个源序列的含义。
Decoder(解码器):使用上下文向量和之前生成的历史信息生成下一个单词,一直到目标文本生成完毕。
其中,编码器和解码器可以使用任何模型,CNN/RNN/LSTM/GRU/Transformer均可。
但是,由于编码和解码阶段一直使用一个定长的上下文向量,也造成了一些问题,其中最严重的是下面两个问题:
- 信息表示困难:编码器要将整个序列的信息压缩进一个固定长度的上下文向量,使得语义向量无法完全表示整个序列的信息
- 无法记住长句:对于长序列输入,最开始输入的序列容易被后输入的序列给覆盖掉,从而丢失许多细节信息
注意力机制就是为了解决这些问题而诞生的。
注意力机制(Attention)
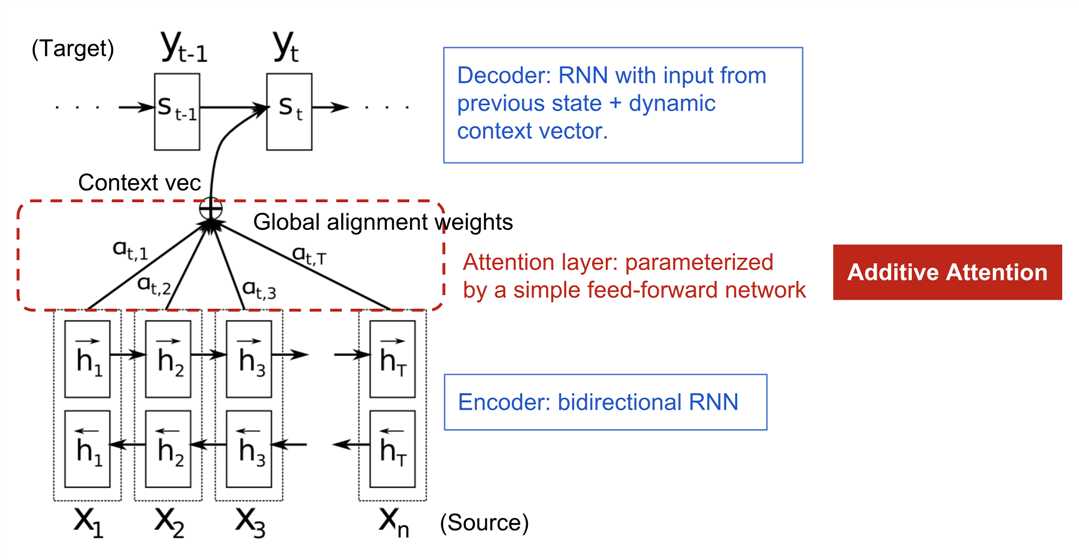
Attention机制在NLP领域第一次应用是Bahdanau et al., 2015的论文,应用于神经机器翻译(NMT)中,协助记忆长源句信息,其构建单个上下文向量的方式与Encoder不同,Encoder仅在最后一个隐藏状态构建上下文向量,而Attention在上下文向量和所有输入之间创建链接权重,供输出元素使用。
因为上下文向量可以访问整个输入序列,所以无需担心序列过长导致的信息遗忘问题。
下图是Bahdanau论文提出的具有附加注意机制的编码器-解码器模型。
Attention的类型
下面是几个常用的Attention和对应函数的汇总表:

^注意:scale-dot product添加了一个缩放系数,避免当输入很大时,softmax函数可能由于梯度过小,难以有效学习的问题。
下面是对更广泛的注意机制类别的总结:

其中:
Self-Attention:使用自适应方式获取特征信息,详见Transformer。
Soft Attention:通过加权求和的方式来选取特征信息。
Hard Attention:通过随机采样或最大采样的方式来选取特征信息,使得其无法使用反向传播算法进行训练。
Global Attention:关注的是整个序列的输入信息,相对来说需要更大的计算量。
Local Attention:关注限定窗口范围内的序列信息,但窗口的限定使得中心词容易忽视不在窗口范围内的信息,因此窗口的大小设定十分重要。
Thanks:
https://lilianweng.github.io/lil-log/2018/06/24/attention-attention.html
https://www.zhihu.com/question/68482809/answer/264632289
