Linux内核分析第六周作业
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux内核分析第六周作业相关的知识,希望对你有一定的参考价值。
分析Linux内核创建一个新进程的过程
首先更新MenuOS的代码,加入调用fork的命令。吐槽一句,实验楼免费用户无法连网。还好只要去github复制一段代码即可
先观察一下fork命令的实现
1 int Fork(int argc, char *argv[]) 2 { 3 int pid; 4 /* fork another process */ 5 pid = fork(); 6 if (pid<0) 7 { 8 /* error occurred */ 9 fprintf(stderr,"Fork Failed!"); 10 exit(-1); 11 } 12 else if (pid==0) 13 { 14 /* child process */ 15 printf("This is Child Process!\\n"); 16 } 17 else 18 { 19 /* parent process */ 20 printf("This is Parent Process!\\n"); 21 /* parent will wait for the child to complete*/ 22 wait(NULL); 23 printf("Child Complete!\\n"); 24 } 25 }
根据fork系统调用的返回值,可以区分出当前是父进程还是子进程,或者调用失败。然后父进程通过wait系统调用等待子进程结束,再输出"Child Complete"
因此,为了能退出进程,为quit命令添加一行代码
1 int Quit(int argc, char *argv[]) 2 { 3 exit(0); 4 }
编译以后运行一下
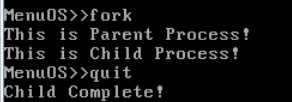
可以看到结果是符合预期的。
吃个饭回来发现实验楼的虚拟机到时间了 (╯°Д°)╯︵ ┻━┻。。。。启动vmware继续
下面开始具体分析进程创建的过程。
Linux有三个系统调用可以创建进程:clone/vfork/fork,网上有许多这三个函数区别的总结,基本上就是父进程和子进程共享资源的区别。
从代码上看,三个系统调用都是通过do_fork实现的,只不过参数不同。而do_fork又主要是由copy_process实现的
于是用gdb直接在copy_process入口处设置断点,进行跟踪。
一上来先是检查参数
然后调用dup_task_struct,创建了当前进程task_struct和thread_info结构体的副本。
但是创建的只是结构体的浅复制,结构体内的指针指向的都是同样的地址。于是接下来的一系列copy函数对各个模块进行深度复制

这些copy函数根据do_fork的参数进行复制,如果不复制,就等于共享了父进程的资源。并且复制也不是单纯的直接复制,而是根据情况进行一定的修改。
以copy_thread为例
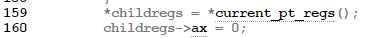
子进程复制了父进程的用户态寄存器,并且把eax设置为0。这样子进程从系统调用返回的时候,返回值就是0。所以用户态程序根据这一点来区别是哪个进程。
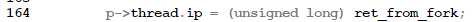
这一行把子进程的起始地址设置为ret_from_fork。当前进程作为父进程,还有后续很多工作要做,而当各种工作完成以后,子进程一开始就可以从ret_from_fork处运行

ret_from_fork代码很简单,基本就是直接从系统调用返回用户态,因此并不需要很多堆栈信息,只要保存基本的用户态寄存器等信息用于从系统调用顺利返回即可。
除了起始IP和堆栈,还有其他一些要修改的信息,包括使用alloc_pid分配一个新的PID,设置parent指针,明确父子关系等等
最后父进程返回do_fork,调用wake_up_new_task设置子进程的运行状态,子进程就可以被内核调度起来。父进程按照系统调用的正常返回流程返回,并不走ret_from_fork。
通过在ret_from_fork设置断点也可以证明这一点,

断点只触发了1次。
总结
Linux的进程创建方式是通过对父进程的复制实现的。通过这种方式,进程与线程的模型可以统一。而且引入了cow以后,创建新进程的开销极小,是Linux的优势之一。
王岩
原创作品转载请注明出处
《Linux内核分析》MOOC课程http://mooc.study.163.com/course/USTC-1000029000
以上是关于Linux内核分析第六周作业的主要内容,如果未能解决你的问题,请参考以下文章