《Linux内核与分析》第六周
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《Linux内核与分析》第六周相关的知识,希望对你有一定的参考价值。
20135130王川东
1、操作系统的三大管理功能包括:进程管理,内存管理,文件系统。
2、 Linux内核通过唯一的进程标识PID来区别每个进程。为了管理进程,内核必须对每个进程进行清晰的描述,进程描述符提供了内核所需了解的进程信息。每个进程的所有信息记录在了进程描述符(task_struct)中。struct task_struct数据结构很庞大,包括进程状态、进程内核堆栈、进程打开的文件、进程优先级以及进程调度相关信息等等。这是一个包含了很多信息的结构体,也被称之为进程控制块(PCB)。
3、Linux中,PCB task_struct中不包含进程包含的线程列表信息。
4、Linux进程的状态与操作系统原理中的描述的进程状态似乎有所不同,比如就绪状态和运行状态都是TASK_RUNNING。这是因为在Linux中,所谓区别一个进程的状态是就绪还是运行,在于它是否得到了CPU的控制权。也就是说,这个进程是否在CPU上实际的执行,如果有实际执行,那就是运行,如果没有,哪怕目前是可以运行,也还只是就绪状态。
注意,PCB task_struct中 存有进程链表,这是讲所有进程存在一个双向链表结构中。struct list_head tasks。
5、程序创建的进程具有父子关系,在编程时往往需要引用这样的父子关系。进程描述符中有几个域用来表示这样的关系。
6、Linux为每个进程分配一个8KB大小的内存区域,用于存放该进程两个不同的数据结构:Thread_info和进程的内核堆栈。进程处于内核态时使用, 不同于用户态堆栈,即PCB中指定了内核栈。内核控制路径所用的堆栈 很少,因此对栈和Thread_info 来说,8KB足够了
7、创建一个新进程在内核中的执行过程:fork、vfork和clone三个系统调用都可以创建一个新进程,而且都是通过调用do_fork来实现进程的创建;Linux通过复制父进程来创建一个新进程。从用户态的代码看fork();函数返回了两次,即在父子进程中各返回一次,父进程从系统调用中返回比较容易理解,子进程从系统调用中返回,那它在系统调用处理过程中的哪里开始执行的呢?Linux中,fork()系统调用产生的子进程在系统调用处理过程中从ret_from_fork处开始执行。
实验过程:
通过在myKernel中添加fork的功能,分析Linux内核创建一个新进程的过程。
添加后重新生成menu,并运行。
通过gdb调试,设置断点在sys_clone, do_fork, dup_task_struct, copy_process, copy_thread, ret_from_fork。运行menuOS中的fork,继续调试,查看断点处的代码情况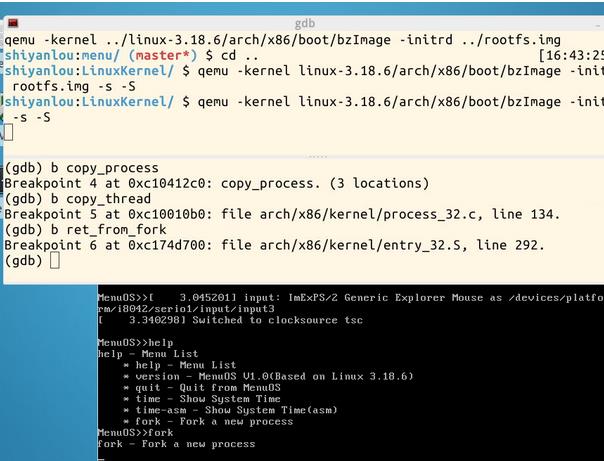 。
。
创建新进程的过程分析:
创建的新进程是从哪里开始执行的:ret_from_fork
*childregs = *current_pt_regs(); 复制内核堆栈(复制的pt_regs,是SAVE_ALL中系统调用压栈的那一部分。)
childregs->ax = 0; 子进程的fork返回0
p->thread.sp = (unsigned long) childregs; 调度到子进程时的内核栈顶
p->thread.ip = (unsigned long) ret_from_fork; 调度到子进程时的第一条指令地址ip指向的是ret_from_fork,所以是从这里开始执行的。
Linux操作系统通过start_kernel,在调用的时候执行得到cpu_idle进程,后来通过kernel_init和kthreadd生成了0号进程和1号进程,分别作为最初的内核进程和用户进程。这里的进程最初是通过程序员具体在代码中设置的结构啊,信息啊之类的,而之后的进程则是复制之前的进程,这里可以看做是父进程,生成了新的进程,也就是子进程,当然,子进程的信息会有修改,它并不是跟父进程完全一样。
程序调用状态可以表示为:
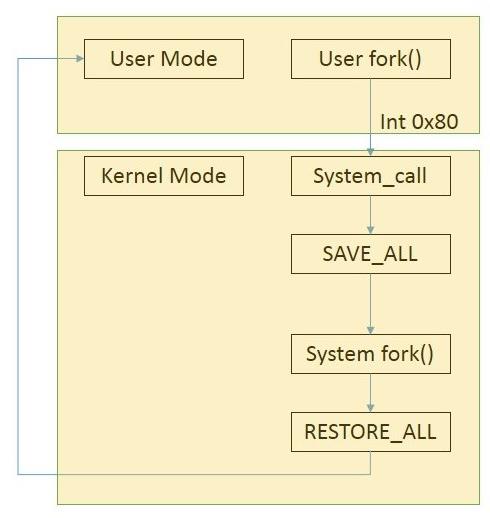
fork具体工作过程:
1. 调用sys_clone
2. 执行do_fork(), fork、vfork和clone三个系统调用都可以创建一个新进程,而且都是通过调用do_fork来实现进程的创建。do_fork()负责进程的复制。
3. 执行copy_process
4 dup_task_struct,复制父进程的task_struct信息到新的task_struct里
fork会产生父子进程,在父进程中,返回值是子进程的进程号;在子进程中,返回值为0。因此可通过返回值来判断当前进程是父进程还是子进程。使用fork函数得到的子进程是父进程的一个复制品,它从父进程处复制了整个进程的地址空间,包括进程上下文,进程堆栈,内存信息,打开的文件描述符,信号控制设定,进程优先级,进程组号,当前工作目录,根目录,资源限制,控制终端等。
5.copy_thread
6.ret_from_fork
进程的用户栈的起始地址存储在task_struct结构的stack_start成员中,新进程是从ret_from_fork处开始执行的。对于fork执行处理过程来说,父子进程共享同一段代码空间,”一次调用,两次返回“,其实对于调用fork的父进程来说,如果fork出来的子进程没有得到调度,那么父进程从fork系统调用返回。再看fork出来的子进程,由 copy_process函数可以看出,子进程的返回地址为ret_from_fork(和父进程在同一个代码点上返回),返回值直接置为0。所以当子进 程得到调度的时候,也从fork返回,返回值为0。ret_from_fork()调用schedule_tail()函数,用存放在栈中的值再装入所有寄存器,并强迫CPU返回到用户态。这样,eax寄存器就装过两个值,一个是子进程的值0,一个是父进程的值——子进程的PID。然后在fork()、vfork()或clone()返回时,新进程将开始执行。在不同的进程中返回不同的值。
以上是关于《Linux内核与分析》第六周的主要内容,如果未能解决你的问题,请参考以下文章