《Linux内核分析》第六周学习总结
Posted 20135223何伟钦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《Linux内核分析》第六周学习总结相关的知识,希望对你有一定的参考价值。
学习内容:分析Linux内核创建一个新进程的过程
-
分析fork函数对应的内核处理过程sys_clone,理解创建一个新进程如何创建和修改task_struct数据结构;
-
使用gdb跟踪分析一个fork系统调用内核处理函数sys_clone ,验证对Linux系统创建一个新进程的理解,
-
特别关注新进程是从哪里开始执行的?为什么从哪里能顺利执行下去?即执行起点与内核堆栈如何保证一致。
一.进程分析
(一)进程控制块PCB——task_struct
对于一个进程来说,PCB就好像是他的记账先生,当一个进程被创建时PCB就被分配,然后有关进程的所有信息就全都存储在PCB中,例如,打开的文件,页表基址寄存器,进程号等等。在linux中PCB是用结构task_struct来表示的,我们首先来看一下task_struct的组成(代码位于linux/include/linux/Sched.h)
代码如下:
struct task_struct {
long state; //表示进程的状态,-1表示不可执行,0表示可执行,>0表示停止
long counter;/* 运行时间片,以jiffs递减计数 */
long priority; /* 运行优先数,开始时,counter = priority,值越大,表示优先数越高,等待时间越长. */
long signal;/* 信号.是一组位图,每一个bit代表一种信号. */
struct sigaction sigaction[32]; /* 信号响应的数据结构, 对应信号要执行的操作和标志信息 */
long blocked; /* 进程信号屏蔽码(对应信号位图) */
/* various fields */
int exit_code; /* 任务执行停止的退出码,其父进程会取 */
unsigned long start_code,end_code,end_data,brk,start_stack;/* start_code代码段地址,end_code代码长度(byte),
end_data代码长度+数据长度(byte),brk总长度(byte),start_stack堆栈段地址 */
long pid,father,pgrp,session,leader;/* 进程号,父进程号 ,父进程组号,会话号,会话头(发起者)*/
unsigned short uid,euid,suid;/* 用户id 号,有效用户 id 号,保存用户 id 号*/
unsigned short gid,egid,sgid;/* 组标记号 (组id),有效组 id,保存的组id */
long alarm;/* 报警定时值 (jiffs数) */
long utime,stime,cutime,cstime,start_time;/* 用户态运行时间 (jiffs数),
系统态运行时间 (jiffs数),子进程用户态运行时间,子进程系统态运行时间,进程开始运行时刻 */
unsigned short used_math;/* 是否使用了协处理器 */
/* file system info */
int tty; /* 进程使用tty的子设备号. -1表示设有使用 */
unsigned short umask; /* 文件创建属性屏蔽位 */
struct m_inode * pwd; /* 当前工作目录 i节点结构 */
struct m_inode * root; /* 根目录i节点结构 */
struct m_inode * executable;/* 执行文件i节点结构 */
unsigned long close_on_exec; /* 执行时关闭文件句柄位图标志. */
struct file * filp[NR_OPEN];
/* 文件结构指针表,最多32项. 表项号即是文件描述符的值 */
struct desc_struct ldt[3];
/* 任务局部描述符表.0-空,1-cs段,2-Ds和Ss段 */
struct tss_struct tss; /* 进程的任务状态段信息结构 */
};
PCB task_struct中包含
进程状态进程打开的文件进程优先级信息
理解这一个过程可以用一个想象的框架:Linux通过复制父进程来创建一个新进程,复制一个PCB——task_struct
err = arch_dup_task_struct(tsk, orig);
要给新进程分配一个新的内核堆栈
ti = alloc_thread_info_node(tsk, node); tsk->stack = ti; setup_thread_stack(tsk, orig); //这里只是复制thread_info,而非复制内核堆栈
创建一个新进程在内核中的执行过程:fork、vfork和clone三个系统调用都可以创建一个新进程,而且都是通过调用do_fork来实现进程的创建;
1. fork,创建子进程
2. vfork,与fork类似,但是父子进程共享地址空间,而且子进程先于父进程运行。
3. clone,主要用于创建线程
这三个代码分别是:
SYSCALL_DEFINE0(fork)
{
return do_fork(SIGCHLD, 0, 0, NULL, NULL);
}
#endif
SYSCALL_DEFINE0(vfork)
{
return do_fork(CLONE_VFORK | CLONE_VM | SIGCHLD, 0,
0, NULL, NULL);
}
SYSCALL_DEFINE5(clone, unsigned long, clone_flags, unsigned long, newsp,
int __user *, parent_tidptr,
int __user *, child_tidptr,
int, tls_val)
{
return do_fork(clone_flags, newsp, 0, parent_tidptr, child_tidptr);
}
do_fork的代码:
long do_fork(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr)
{
struct task_struct *p;
int trace = 0;
long nr;// 复制进程描述符,返回创建的task_struct的指针
p = copy_process(clone_flags, stack_start, stack_size,
child_tidptr, NULL, trace);
if (!IS_ERR(p)) {
struct completion vfork;
struct pid *pid;
trace_sched_process_fork(current, p);
// 取出task结构体内的pid
pid = get_task_pid(p, PIDTYPE_PID);
nr = pid_vnr(pid);
if (clone_flags & CLONE_PARENT_SETTID)
put_user(nr, parent_tidptr);
// 如果使用的是vfork,那么必须采用某种完成机制,确保父进程后运行
if (clone_flags & CLONE_VFORK) {
p->vfork_done = &vfork;
init_completion(&vfork);
get_task_struct(p);
}
// 将子进程添加到调度器的队列,使得子进程有机会获得CPU
wake_up_new_task(p);// 如果设置了 CLONE_VFORK 则将父进程插入等待队列,并挂起父进程直到子进程释放自己的内存空间
// 保证子进程优先于父进程运行
if (clone_flags & CLONE_VFORK) {
if (!wait_for_vfork_done(p, &vfork))
ptrace_event_pid(PTRACE_EVENT_VFORK_DONE, pid);
}
put_pid(pid);
} else {
nr = PTR_ERR(p);
}
return nr;
}
do_fork的事情:
1. 调用copy_process,将当期进程复制一份出来为子进程,并且为子进程设置相应地上下文信息。
2. 初始化vfork的完成处理信息(如果是vfork调用)
3. 调用wake_up_new_task,将子进程放入调度器的队列中,此时的子进程就可以被调度进程选中,得以运行。
4. 如果是vfork调用,需要阻塞父进程,知道子进程执行exec。
理解这一个过程提供一个想象的框架:Linux通过复制父进程来创建一个新进程,复制一个PCB——task_struct
err = arch_dup_task_struct(tsk, orig);
要给新进程分配一个新的内核堆栈
ti = alloc_thread_info_node(tsk, node); tsk->stack = ti; setup_thread_stack(tsk, orig); //这里只是复制thread_info,而非复制内核堆栈
从用户态的代码看fork();函数返回了两次,即在父子进程中各返回一次,父进程从系统调用中返回比较容易理解,子进程从系统调用中返回,那它在系统调用处理过程中的哪里开始执行的呢?这就涉及子进程的内核堆栈数据状态和task_struct中thread记录的sp和ip的一致性问题,这是在哪里设定的?copy_thread in copy_process
*childregs = *current_pt_regs(); //复制内核堆栈
childregs->ax = 0; //为什么子进程的fork返回0,这里就是原因!
p->thread.sp = (unsigned long) childregs; //调度到子进程时的内核栈顶
p->thread.ip = (unsigned long) ret_from_fork; //调度到子进程时的第一条指令地址
(二)进程创建的关键
(1)copy_process函数:在进程创建的do_fork函数中调用,主要完成进程数据结构,各种资源的初始化。初始化方式可以重新分配,也可以共享父进程资源,
大体流程:
1. 检查各种标志位
2. 调用dup_task_struct复制一份task_struct结构体,作为子进程的进程描述符。
3. 检查进程的数量限制。
4. 初始化定时器、信号和自旋锁。
5. 初始化与调度有关的数据结构,调用了sched_fork,这里将子进程的state设置为TASK_RUNNING。
6. 复制所有的进程信息,包括fs、信号处理函数、信号、内存空间(包括写时复制)等。
7. 调用copy_thread,这又是关键的一步,这里设置了子进程的堆栈信息。
8. 为子进程分配一个pid
9. 设置子进程与其他进程的关系,以及pid、tgid等
关键地方:tsk = alloc_task_struct_node(node);//为task_struct开辟内存
ti = alloc_thread_info_node(tsk, node);//ti指向thread_info的首地址,同时也是系统为新进程分配的两个连续页面的首地址。
err = arch_dup_task_struct(tsk, orig);//复制父进程的task_struct信息到新的task_struct里, (dst = src;)
tsk->stack = ti;task的对应栈
setup_thread_stack(tsk, orig);//初始化thread info结构
set_task_stack_end_magic(tsk);//栈结束的地址设置数据为栈结束标示(for overflow detection)
代码如下:
/*
创建进程描述符以及子进程所需要的其他所有数据结构
为子进程准备运行环境
*/
static struct task_struct *copy_process(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *child_tidptr,
struct pid *pid,
int trace)
{
int retval;
struct task_struct *p;
// 分配一个新的task_struct,此时的p与当前进程的task,仅仅是stack地址不同
p = dup_task_struct(current);
// 检查该用户的进程数是否超过限制
if (atomic_read(&p->real_cred->user->processes) >=
task_rlimit(p, RLIMIT_NPROC)) {
// 检查该用户是否具有相关权限,不一定是root
if (p->real_cred->user != INIT_USER &&
!capable(CAP_SYS_RESOURCE) && !capable(CAP_SYS_ADMIN))
goto bad_fork_free;
}
retval = -EAGAIN;
// 检查进程数量是否超过 max_threads,后者取决于内存的大小
if (nr_threads >= max_threads)
goto bad_fork_cleanup_count;
// 初始化自旋锁
// 初始化挂起信号
// 初始化定时器
// 完成对新进程调度程序数据结构的初始化,并把新进程的状态设置为TASK_RUNNING
retval = sched_fork(clone_flags, p);
// .....
// 复制所有的进程信息
// copy_xyz
// 初始化子进程的内核栈
retval = copy_thread(clone_flags, stack_start, stack_size, p);
if (retval)
goto bad_fork_cleanup_io;
if (pid != &init_struct_pid) {
retval = -ENOMEM;
// 这里为子进程分配了新的pid号
pid = alloc_pid(p->nsproxy->pid_ns_for_children);
if (!pid)
goto bad_fork_cleanup_io;
}
/* ok, now we should be set up.. */
// 设置子进程的pid
p->pid = pid_nr(pid);
// 如果是创建线程
if (clone_flags & CLONE_THREAD) {
p->exit_signal = -1;
// 线程组的leader设置为当前线程的leader
p->group_leader = current->group_leader;
// tgid是当前线程组的id,也就是main进程的pid
p->tgid = current->tgid;
} else {
if (clone_flags & CLONE_PARENT)
p->exit_signal = current->group_leader->exit_signal;
else
p->exit_signal = (clone_flags & CSIGNAL);
// 创建的是进程,自己是一个单独的线程组
p->group_leader = p;
// tgid和pid相同
p->tgid = p->pid;
}
if (clone_flags & (CLONE_PARENT|CLONE_THREAD)) {
// 如果是创建线程,那么同一线程组内的所有线程、进程共享parent
p->real_parent = current->real_parent;
p->parent_exec_id = current->parent_exec_id;
} else {
// 如果是创建进程,当前进程就是子进程的parent
p->real_parent = current;
p->parent_exec_id = current->self_exec_id;
}
// 将pid加入PIDTYPE_PID这个散列表
attach_pid(p, PIDTYPE_PID);
// 递增 nr_threads的值
nr_threads++;
// 返回被创建的task结构体指针
return p;
}
(2)copy_thread函数:为子进程准备了上下文堆栈信息
copy_thread的流程如下:
1. 获取子进程寄存器信息的存放位置
2. 对子进程的thread.sp赋值,将来子进程运行,这就是子进程的esp寄存器的值。
3. 如果是创建内核线程,那么它的运行位置是ret_from_kernel_thread,将这段代码的地址赋给thread.ip,之后准备其他寄存器信息,退出。
4. 将父进程的寄存器信息复制给子进程。
5. 将子进程的eax寄存器值设置为0,所以fork调用在子进程中的返回值为0。
6. 子进程从ret_from_fork开始执行,所以它的地址赋给thread.ip,也就是将来的eip寄存器。// 初始化子进程的内核栈
int copy_thread(unsigned long clone_flags, unsigned long sp,
unsigned long arg, struct task_struct *p)
{
// 获取寄存器信息
struct pt_regs *childregs = task_pt_regs(p);
struct task_struct *tsk;
int err;
// 栈顶 空栈
p->thread.sp = (unsigned long) childregs;
p->thread.sp0 = (unsigned long) (childregs+1);
memset(p->thread.ptrace_bps, 0, sizeof(p->thread.ptrace_bps));
// 如果是创建的内核线程
if (unlikely(p->flags & PF_KTHREAD)) {
/* kernel thread */
memset(childregs, 0, sizeof(struct pt_regs));
// 内核线程开始执行的位置
p->thread.ip = (unsigned long) ret_from_kernel_thread;
task_user_gs(p) = __KERNEL_STACK_CANARY;
childregs->ds = __USER_DS;
childregs->es = __USER_DS;
childregs->fs = __KERNEL_PERCPU;
childregs->bx = sp; /* function */
childregs->bp = arg;
childregs->orig_ax = -1;
childregs->cs = __KERNEL_CS | get_kernel_rpl();
childregs->flags = X86_EFLAGS_IF | X86_EFLAGS_FIXED;
p->thread.io_bitmap_ptr = NULL;
return 0;
}
// 将当前进程的寄存器信息复制给子进程
*childregs = *current_pt_regs();
// 子进程的eax置为0,所以fork的子进程返回值为0
childregs->ax = 0;
if (sp)
childregs->sp = sp;
// 子进程从ret_from_fork开始执行
p->thread.ip = (unsigned long) ret_from_fork;
task_user_gs(p) = get_user_gs(current_pt_regs());
return err;
}
从流程中看出,子进程复制了父进程的上下文信息,仅仅对某些地方做了改动,运行逻辑和父进程完全一致。
子进程从ret_from_fork处开始执行。
(3)dup_ task_ struct函数
流程如下:
1.先调用alloc_task_struct_node分配一个task_struct结构体。
2.调用alloc_thread_info_node,分配了一个union。这里分配了一个thread_info结构体,还分配了一个stack数组。返回值为ti,实际上就是栈底。
3.tsk->stack = ti将栈底的地址赋给task的stack变量。4.最后为子进程分配了内核栈空间。
5.执行完dup_task_struct之后,子进程和父进程的task结构体,除了stack指针之外,完全相同。
(三)新进程的执行
新进程从ret_from_fork处开始执行,子进程的运行是由这几处保证的:
1. dup_task_struct中为其分配了新的堆栈
2. copy_process中调用了sched_fork,将其置为TASK_RUNNING
3. copy_thread中将父进程的寄存器上下文复制给子进程,这是非常关键的一步,这里保证了父子进程的堆栈信息是一致的。
4. 将ret_from_fork的地址设置为eip寄存器的值,这是子进程的第一条指令。
(四)子进程系统调用处理过程*childregs = *current_pt_regs(); //复制内核堆栈
childregs->ax = 0; //子进程的fork返回0的原因
p->thread.sp = (unsigned long) childregs; //调度到子进程时的内核栈顶
p->thread.ip = (unsigned long) ret_from_fork; //调度到子进程时的第一条指令地址
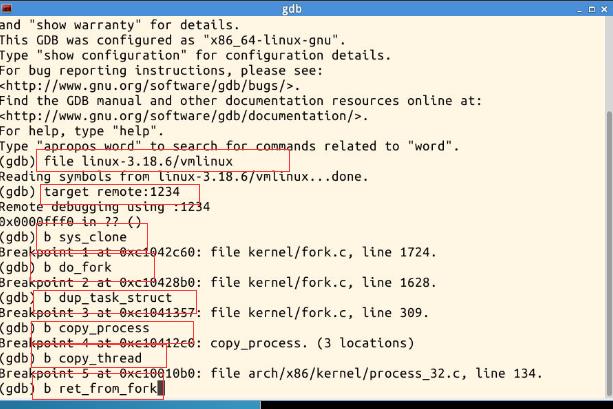
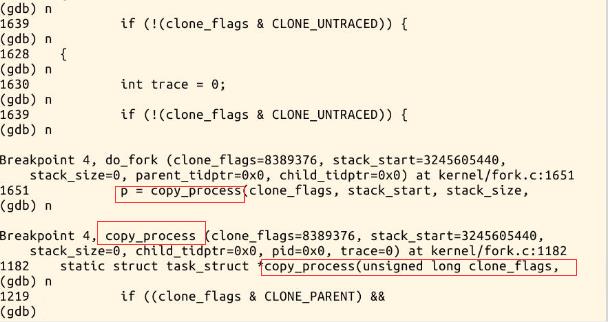
实践:使用gdb跟踪分析一个fork系统调用内核处理函数sys_clone
启动MenuOS和gdb调试
cd LinuxKernel
rm menu -rf
git clone https://github.com/mengning/menu.git
cd menu
mv test_fork.c test.c
make rootfs
qemu -kernel linux-3.18.6/arch/x86/boot/bzImage -initrd rootfs.img -s -S
在新窗口中启动调试
gdb
file linux-3.18.6/vmlinux
target remote:1234
实验截图如下:
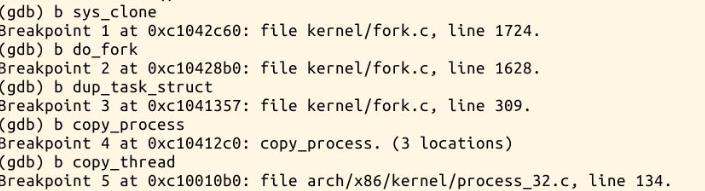
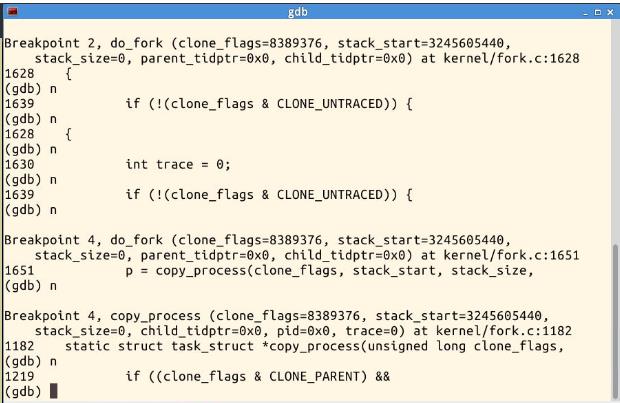
四、总结
可以将上面繁琐的进程创建过程总结为一下的几步:
1、调用fork()函数引发0x80中断
2、调用sys_fork
3、通过find_empty_process为新进程分配一个进程号
4、通过copy_process函数使子进程复制父进程的资源,并进行一些个性化设置后,返回进程号。
以上是关于《Linux内核分析》第六周学习总结的主要内容,如果未能解决你的问题,请参考以下文章