flinkFlink 1.12.2 源码浅析 :Task数据输出
Posted 九师兄
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了flinkFlink 1.12.2 源码浅析 :Task数据输出相关的知识,希望对你有一定的参考价值。

1.概述
转载:Flink 1.12.2 源码浅析 :Task数据输出
Stream的计算模型采用的是PUSH模式, 上游主动向下游推送数据, 上下游之间采用生产者-消费者模式, 下游收到数据触发计算, 没有数据则进入等待状态。 PUSH模式的数据处理过程也叫作Pipeline, 提到Pipeline或者流水线的时候, 一般是指PUSH模式的数据处理过程。
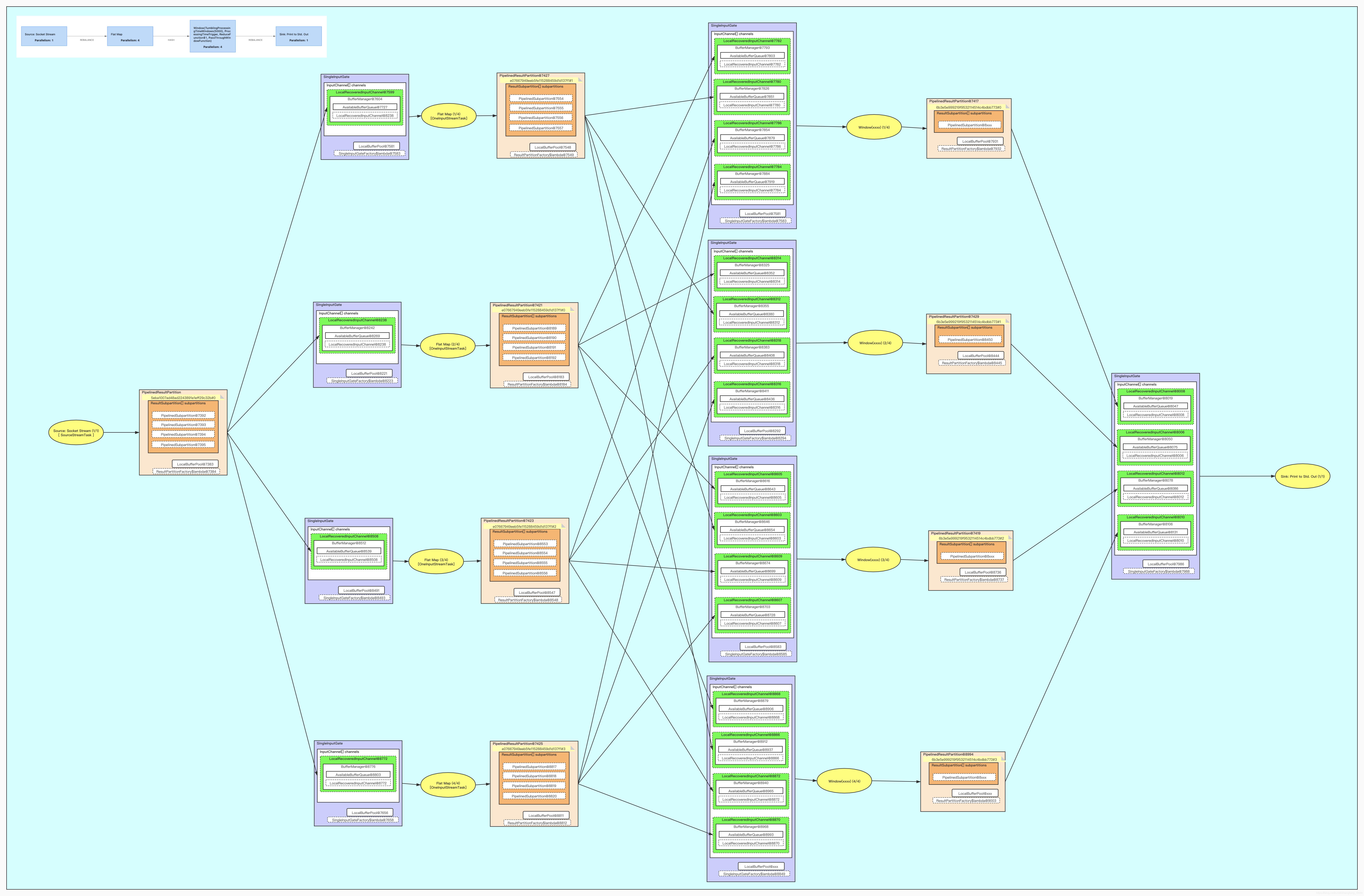
Task之间数据交换从本质上来说就是一个典型的生产者-消费者模型,上游算子生产数据到 ResultPartition 中,下游算子通过 InputGate 消费数据。由于不同的 Task 可能在同一个 TaskManager 中运行,也可能在不同的 TaskManager 中运行:对于前者,不同的 Task 其实就是同一个 TaskManager 进程中的不同的线程,它们的数据交换就是在本地不同线程间进行的;对于后者,必须要通过网络进行通信。
二 .几个基本概念
2.1. IntermediateDataset
IntermediateDataset是在 JobGraph 中对中间结果的抽象。我们知道,JobGraph 是对 StreamGraph 进一步进行优化后得到的逻辑图,它尽量把可以 chain 到一起 operator 合并为一个 JobVertex,而 IntermediateDataset 就表示一个 JobVertex 的输出结果。JobVertex 的输入是 JobEdge,而 JobEdge 可以看作是 IntermediateDataset 的消费者。一个 JobVertex 也可能产生多个 IntermediateDataset。需要说明的一点是,目前一个 IntermediateDataset 实际上只会有一个 JobEdge 作为消费者,也就是说,一个 JobVertex 的下游有多少 JobVertex 需要依赖当前节点的数据,那么当前节点就有对应数量的 IntermediateDataset。
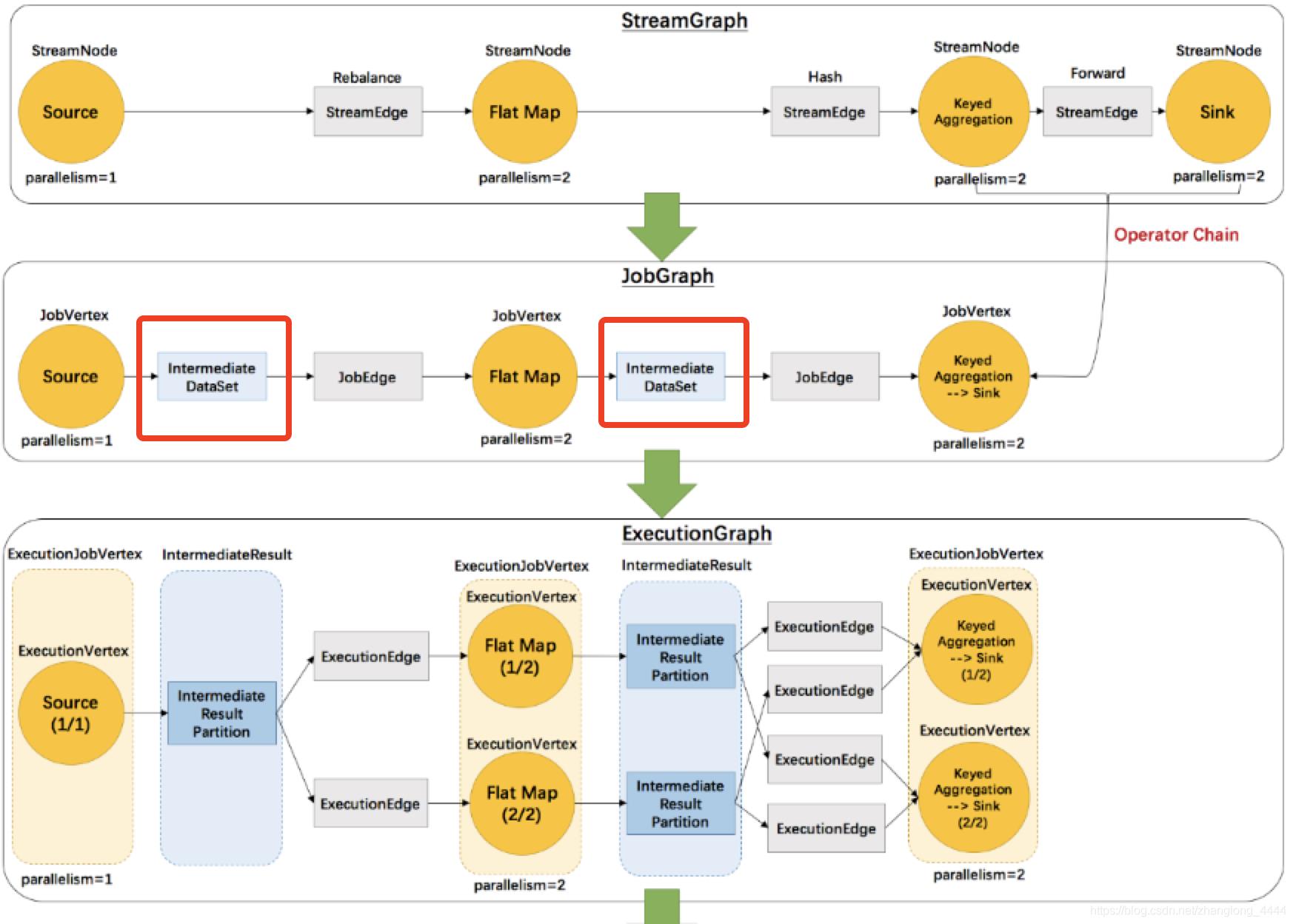
2.2. IntermediateResult 和 IntermediateResultpartition
在 JobManager 中,JobGraph 被进一步转换成可以被调度的并行化版本的执行图,即 ExecutionGraph。在 ExecutionGraph 中,和 JobVertex 对应的节点是 ExecutionJobVertex,和 IntermediateDataset 对应的则是 IntermediataResult。由于一个节点在实际运行时可能有多个并行子任务同时运行,所以 ExecutionJobVertex 按照并行度的设置被拆分为多个 ExecutionVertex,每一个表示一个并行的子任务。同样的,一个 IntermediataResult 也会被拆分为多个 IntermediateResultPartition,IntermediateResultPartition 对应 ExecutionVertex 的输出结果。
一个 IntermediateDataset 只有一个消费者,那么一个 IntermediataResult 也只会有一个消费者;
但是到了 IntermediateResultPartition 这里,由于节点被拆分成了并行化的节点,所以一个 IntermediateResultPartition 可能会有多个 ExecutionEdge 作为消费者。
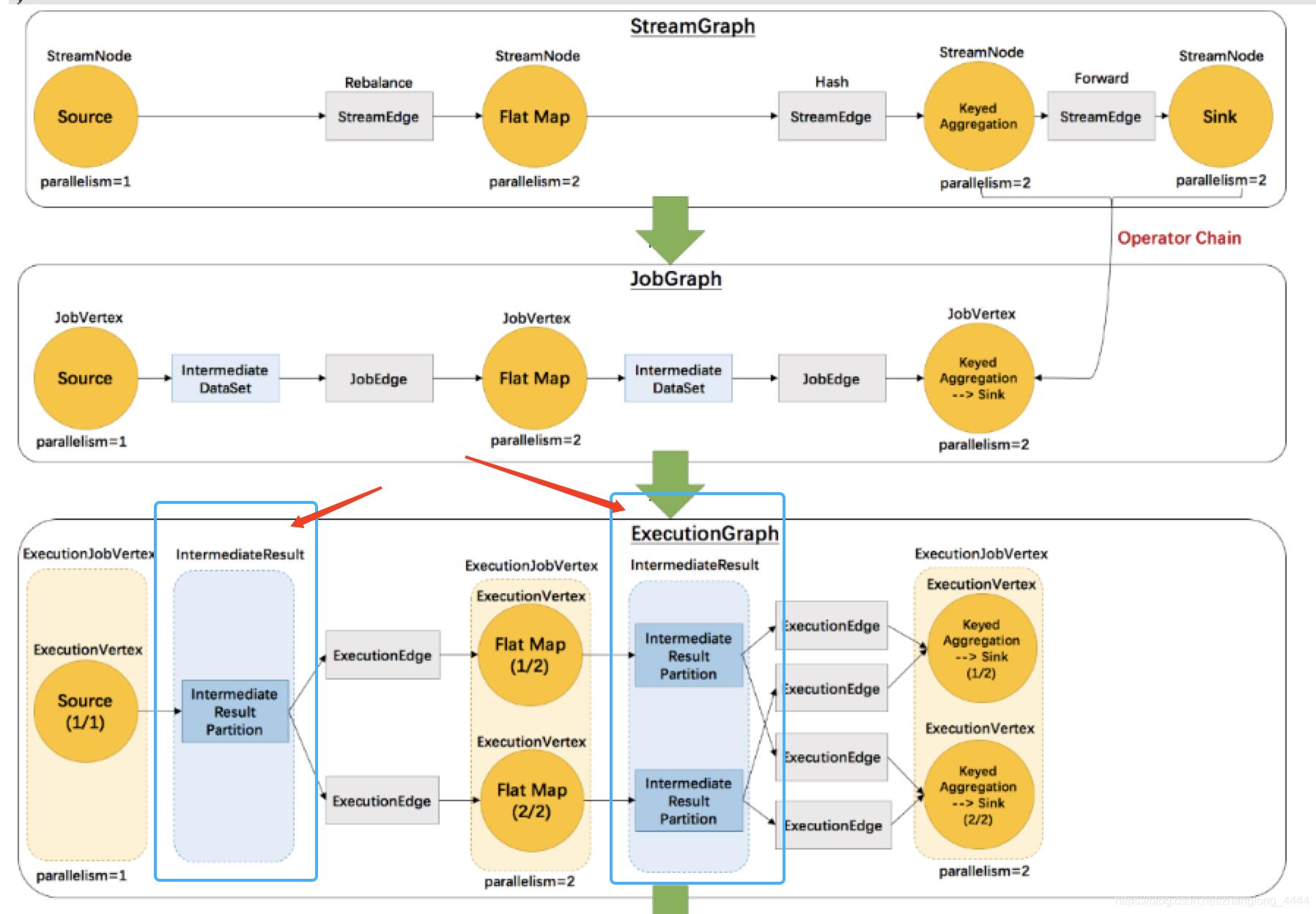
2.3. ResultPartition 和 ResultSubpartition
ExecutionGraph 还是 JobManager 中用于描述作业拓扑的一种逻辑上的数据结构,其中表示并行子任务的 ExecutionVertex 会被调度到 TaskManager 中执行,一个 Task 对应一个 ExecutionVertex。同 ExecutionVertex 的输出结果 IntermediateResultPartition 相对应的则是 ResultPartition。**IntermediateResultPartition 可能会有多个 ExecutionEdge 作为消费者,**那么在 Task 这里,ResultPartition 就会被拆分为多个 ResultSubpartition,下游每一个需要从当前 ResultPartition 消费数据的 Task 都会有一个专属的 ResultSubpartition。
ResultPartitionType 指定了 ResultPartition 的不同属性,这些属性包括是否流水线模式、是否会产生反压以及是否限制使用的 Network buffer 的数量。ResultPartitionType 有三个枚举值:
- BLOCKING:非流水线模式,无反压,不限制使用的网络缓冲的数量
- PIPELINED:流水线模式,有反压,不限制使用的网络缓冲的数量
- PIPELINED_BOUNDED:流水线模式,有反压,限制使用的网络缓冲的数量
其中是否PIPELINED模式这个属性会对消费行为产生很大的影响:
如果是流水线模式,那么在 ResultPartition 接收到第一个 Buffer 时,消费者任务就可以进行准备消费;而如果非流水线模式,那么消费者将等到生产端任务生产完数据之后才进行消费。目前在 Stream 模式下使用的类型是 PIPELINED_BOUNDED
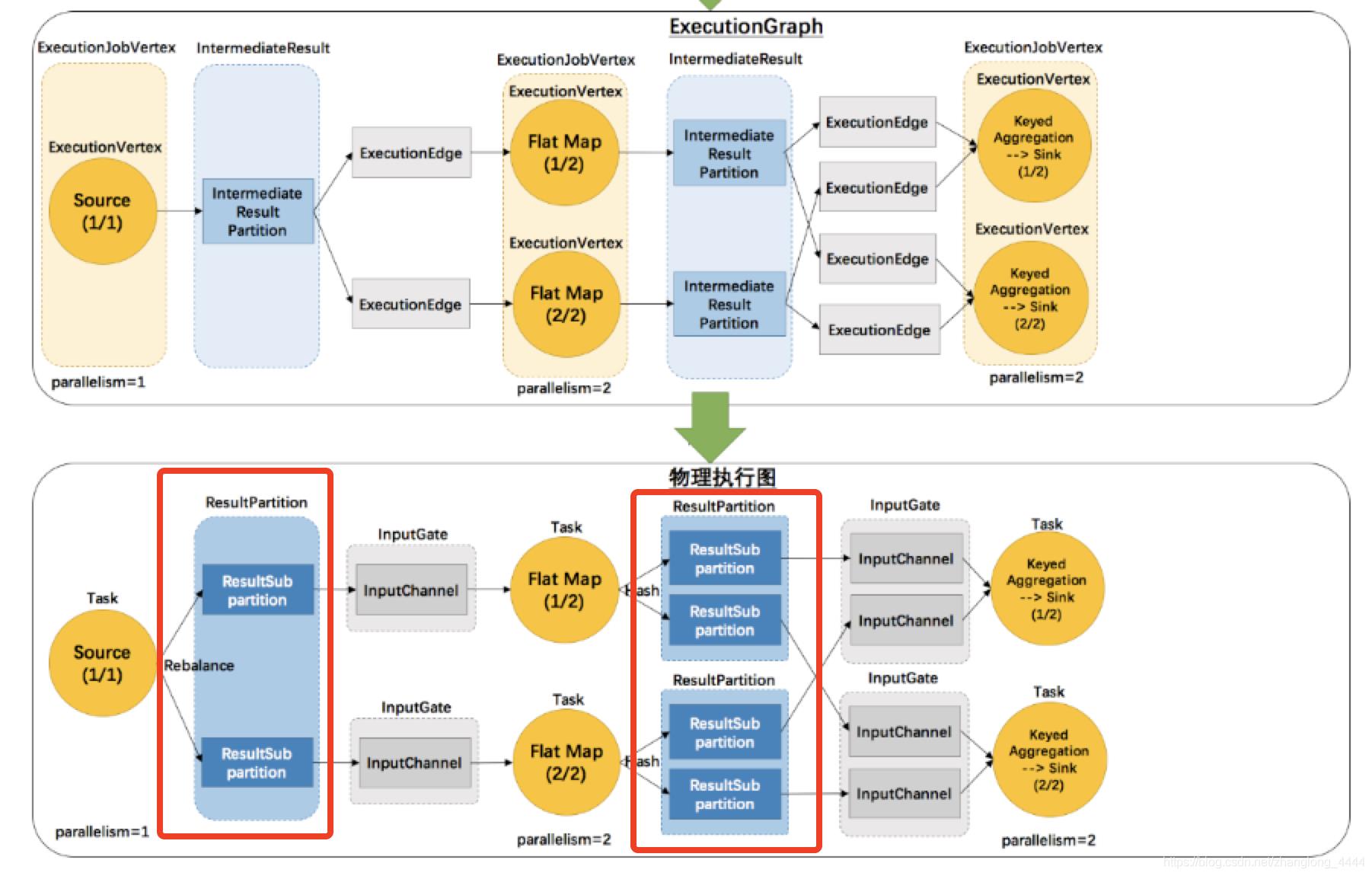
2.4. InputGate 和 InputChannel
在 Task 中,InputGate 是对输入的封装,InputGate 是和 JobGraph 中 JobEdge 一一对应的。也就是说,InputGate 实际上对应的是该 Task 依赖的上游算子(包含多个并行子任务),每个 InputGate 消费了一个或多个 ResultPartition。InputGate 由 InputChannel 构成。
三 .相关Class梳理
Task 产出的每一个 ResultPartition 都有一个关联的 ResultPartitionWriter,同时也都有一个独立的 LocalBufferPool 负责提供写入数据所需的 buffer。
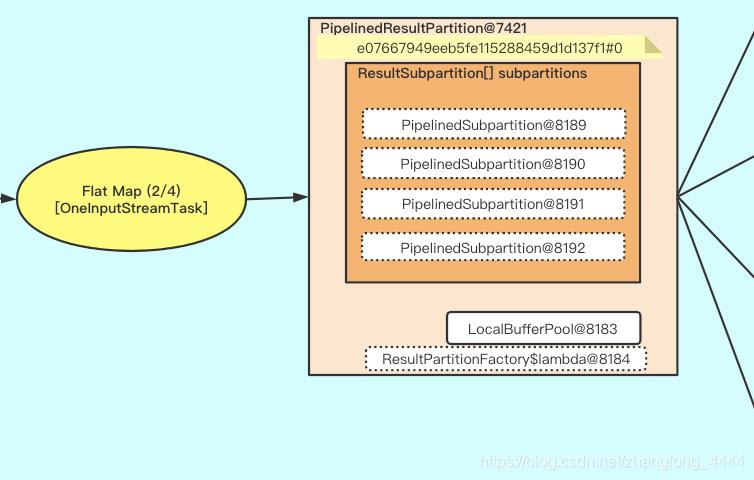
如上图 Flat Map 算子的输出就是PipelinedResultPartition , 我们看一下PipelinedResultPartition的相关Class
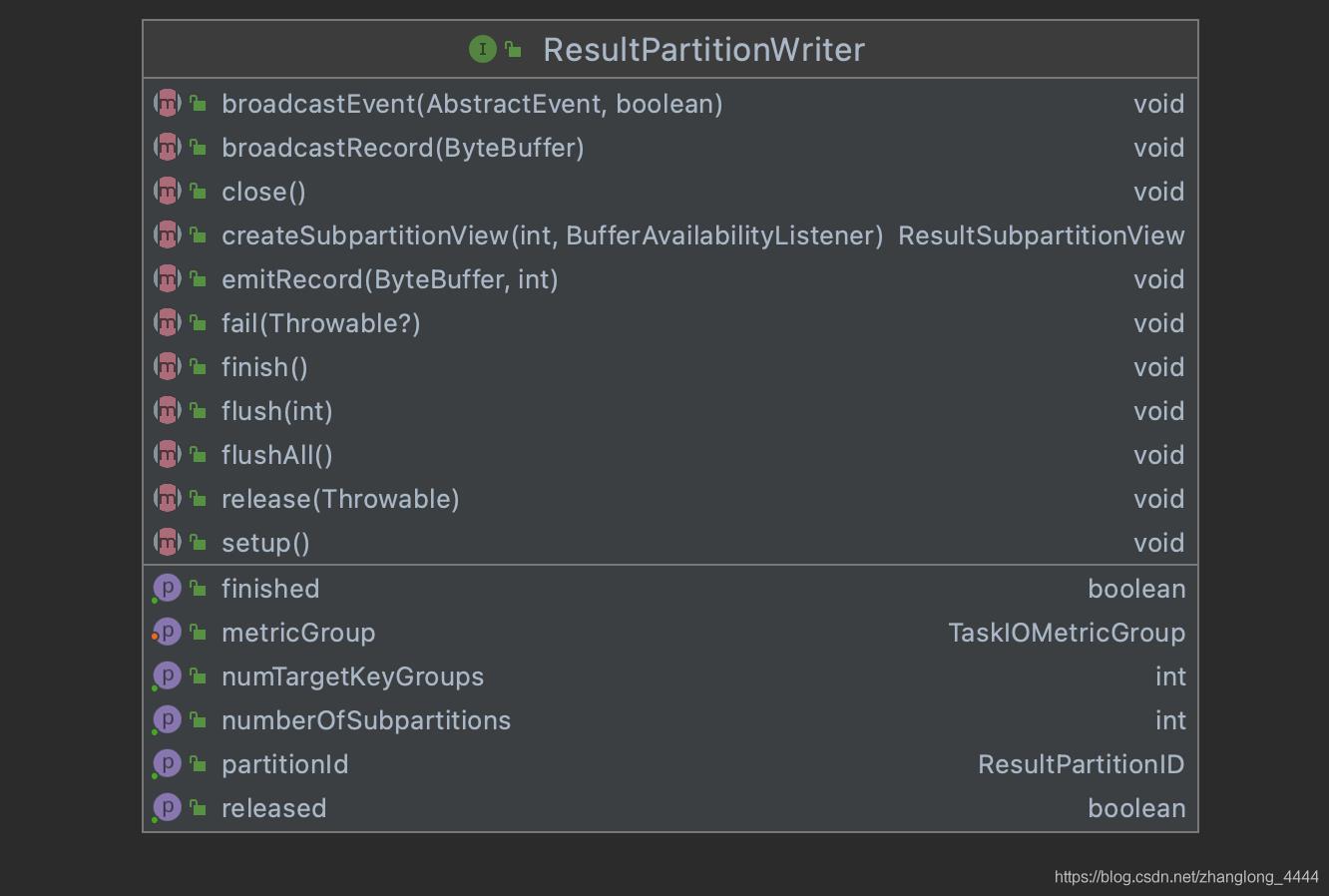
3.1. ResultPartitionWriter
Task 产出的每一个 ResultPartition 都有一个关联的 ResultPartitionWriter,同时也都有一个独立的 LocalBufferPool 负责提供写入数据所需的 buffer。
ResultPartitionWriter 是一个接口类, 定义了一系列的方法.
| 名称 | 描述 |
|---|---|
| void setup() throws IOException; | 初始化相关 |
| ResultPartitionID getPartitionId(); | 获取ResultPartitionID |
| int getNumberOfSubpartitions(); | 获取子分区的数量 |
| int getNumTargetKeyGroups(); | xxx |
| void emitRecord(ByteBuffer record, int targetSubpartition) throws IOException; | 将数据发送到制定的子分区 |
| void broadcastRecord(ByteBuffer record) throws IOException; | 广播数据 |
| void broadcastEvent(AbstractEvent event, boolean isPriorityEvent) | 广播事件 |
| void setMetricGroup(TaskIOMetricGroup metrics); | 设置metric相关 |
| ResultSubpartitionView createSubpartitionView( int index, BufferAvailabilityListener availabilityListener) | 构建SubpartitionView,用于读取子分区数据 |
| void flushAll(); | flush所有分区的数据 |
| void flush(int subpartitionIndex); | flush某一个分区的数据 |
| void fail(@Nullable Throwable throwable); | 异常相关 |
| void finish() throws IOException; | 执行设置分区状态为成功 |
| boolean isFinished(); | 是否成功 |
| void release(Throwable cause); | 执行释放资源 |
| boolean isReleased(); | 资源是否释放成功 |
| void close() throws Exception; | 执行分区关闭 |
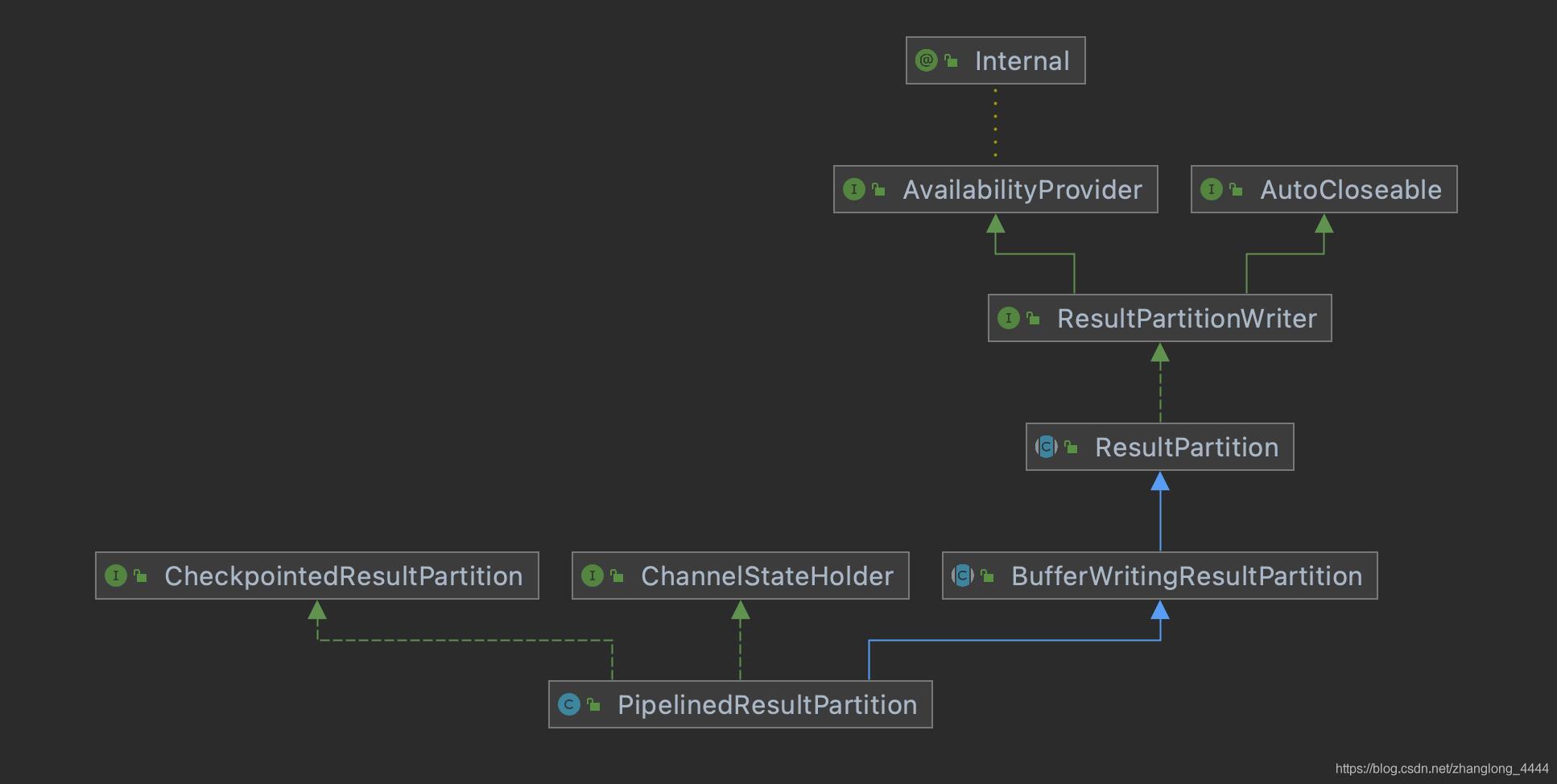
3.2. ResultPartition
ResultPartition 是一个抽象类 , 实现了ResultPartitionWriter 接口…
一个数据处理流程(Task)对应着一个ResultPartition,
ResultPartition的数据需要发送数据到多个下游Channel(对应着下游多个Task),
ResultPartition中的数据专门为下游不同的接收者做了分组,这个分组叫做ResultSubpartition。
对应JobGraph中的IntermediateResultPartition .
3.2.1. 属性相关
| 名称 | 描述 |
|---|---|
| String owningTaskName | 任务名称: “Flat Map (1/4)#0 (b2490d6207a4eaa9f285fb307bd31782)” |
| int partitionIndex | 0 |
| ResultPartitionID partitionId | 分区ID |
| ResultPartitionType partitionType | “PIPELINED_BOUNDED” |
| ResultPartitionManager partitionManager | ResultPartitionManager 管理当前 TaskManager 所有的 ResultPartition |
| int numTargetKeyGroups | 128 |
| -------------------------------------- | -------------------------------------- |
| Runtime state 相关 | |
| AtomicBoolean isReleased | 是否释放资源 |
| BufferPool bufferPool | LocalBufferPool |
| boolean isFinished | 是否成功 |
| SupplierWithException<BufferPool, IOException> bufferPoolFactory | ResultPartitionFactory$lambda@6982 |
| Throwable cause | 异常信息 |
| BufferCompressor bufferCompressor; | Buffer压缩器 |
| Counter numBytesOut | 处理数据的大小bytes |
| Counter numBuffersOut | 处理数据的数量 |
数据样例
releaseLock = {Object@6973}
consumedSubpartitions = {boolean[4]@6974} [false, false, false, false]
numUnconsumedSubpartitions = 4
subpartitions = {ResultSubpartition[4]@6975}
unicastBufferBuilders = {BufferBuilder[4]@6976}
broadcastBufferBuilder = null
idleTimeMsPerSecond = {MeterView@6977}
owningTaskName = "Flat Map (1/4)#0 (b2490d6207a4eaa9f285fb307bd31782)"
partitionIndex = 0
partitionId = {ResultPartitionID@6979} "3abe615ae9be22f64d8e5af582df91ed#0@b2490d6207a4eaa9f285fb307bd31782"
partitionType = {ResultPartitionType@6929} "PIPELINED_BOUNDED"
partitionManager = {ResultPartitionManager@6930}
numSubpartitions = 4
numTargetKeyGroups = 128
isReleased = {AtomicBoolean@6980} "false"
bufferPool = {LocalBufferPool@6981} "[size: 16, required: 5, requested: 1, available: 1, max: 16, listeners: 0,subpartitions: 4, maxBuffersPerChannel: 10, destroyed: false]"
isFinished = false
cause = null
bufferPoolFactory = {ResultPartitionFactory$lambda@6982}
bufferCompressor = null
numBytesOut = {SimpleCounter@6983}
numBuffersOut = {SimpleCounter@6984}
3.2.2. 构造方法
只是简单地 赋值操作, 没做任何变化…
public ResultPartition(
String owningTaskName,
int partitionIndex,
ResultPartitionID partitionId,
ResultPartitionType partitionType,
int numSubpartitions,
int numTargetKeyGroups,
ResultPartitionManager partitionManager,
@Nullable BufferCompressor bufferCompressor,
SupplierWithException<BufferPool, IOException> bufferPoolFactory) {
this.owningTaskName = checkNotNull(owningTaskName);
Preconditions.checkArgument(0 <= partitionIndex, "The partition index must be positive.");
this.partitionIndex = partitionIndex;
this.partitionId = checkNotNull(partitionId);
this.partitionType = checkNotNull(partitionType);
this.numSubpartitions = numSubpartitions;
this.numTargetKeyGroups = numTargetKeyGroups;
this.partitionManager = checkNotNull(partitionManager);
this.bufferCompressor = bufferCompressor;
this.bufferPoolFactory = bufferPoolFactory;
}
3.2.3. 方法相关
ResultPartition 是一个抽象类 , 实现了ResultPartitionWriter 接口… 所以要实现ResultPartitionWriter的方法.
| 名称 | 描述 |
|---|---|
| void setup() throws IOException; | 初始化相关 |
| ResultPartitionID getPartitionId(); | 获取ResultPartitionID |
| int getNumberOfSubpartitions(); | 获取子分区的数量 |
| int getNumTargetKeyGroups(); | xxx |
| void emitRecord(ByteBuffer record, int targetSubpartition) throws IOException; | 将数据发送到制定的子分区 |
| void broadcastRecord(ByteBuffer record) throws IOException; | 广播数据 |
| void broadcastEvent(AbstractEvent event, boolean isPriorityEvent) | 广播事件 |
| void setMetricGroup(TaskIOMetricGroup metrics); | 设置metric相关 |
| ResultSubpartitionView createSubpartitionView( int index, BufferAvailabilityListener availabilityListener) | 构建SubpartitionView,用于读取子分区数据 |
| void flushAll(); | flush所有分区的数据 |
| void flush(int subpartitionIndex); | flush某一个分区的数据 |
| void fail(@Nullable Throwable throwable); | 异常相关 |
| void finish() throws IOException; | 执行设置分区状态为成功 |
| boolean isFinished(); | 是否成功 |
| void release(Throwable cause); | 执行释放资源 |
| boolean isReleased(); | 资源是否释放成功 |
| void close() throws Exception; | 执行分区关闭 |
setup 初始化
/**
* Registers a buffer pool with this result partition.
*
* <p>There is one pool for each result partition, which is shared by all its sub partitions.
*
* <p>The pool is registered with the partition *after* it as been constructed in order to
* conform to the life-cycle of task registrations in the {@link TaskExecutor}.
*/
@Override
public void setup() throws IOException {
checkState(
this.bufferPool == null,
"Bug in result partition setup logic: Already registered buffer pool.");
// bufferPool = {LocalBufferPool@6981} "[
// size: 16,
// required: 5,
// requested: 1,
// available: 1,
// max: 16,
// listeners: 0,
// subpartitions: 4,
// maxBuffersPerChannel: 10,
// destroyed: false
// ]"
this.bufferPool = checkNotNull(bufferPoolFactory.get());
// 将这个分区注册到partitionManager
partitionManager.registerResultPartition(this);
}
其他的没啥特殊的就是状态的转换…
3.3. BufferWritingResultPartition
BufferWritingResultPartition 也是一个抽象类, 继承了ResultPartition .
3.3.1. 属性
一共有四个属性:
| 名称 | 描述 |
|---|---|
| ResultSubpartition[] subpartitions | 子分区 |
| BufferBuilder[] unicastBufferBuilders | 对于非广播模式,每个子分区都维护一个单独的BufferBuilder,该BufferBuilder可能为空 |
| BufferBuilder broadcastBufferBuilder | 广播变量的BufferBuilders |
| Meter idleTimeMsPerSecond = new MeterView(new SimpleCounter()) | 计数相关 |
3.3.2. 构造方法
构造方法就是赋值操作, 区别是 根据分区的数量构建了对应的 BufferBuilder[] unicastBufferBuilders .
public BufferWritingResultPartition(
String owningTaskName,
int partitionIndex,
ResultPartitionID partitionId,
ResultPartitionType partitionType,
ResultSubpartition[] subpartitions,
int numTargetKeyGroups,
ResultPartitionManager partitionManager,
@Nullable BufferCompressor bufferCompressor,
SupplierWithException<BufferPool, IOException> bufferPoolFactory) {
super(
owningTaskName,
partitionIndex,
partitionId,
partitionType,
subpartitions.length,
numTargetKeyGroups,
partitionManager,
bufferCompressor,
bufferPoolFactory);
this.subpartitions = checkNotNull(subpartitions);
// 根据子分区的数量构建
this.unicastBufferBuilders = new BufferBuilder[subpartitions.length];
}
3.3.3. 方法相关
BufferWritingResultPartition 也是一个抽象类, 继承了ResultPartition , 所以会重写 ResultPartition 的方法.
| 名称 | 描述 |
|---|---|
| void setup() throws IOException; | 初始化相关 |
| int getNumberOfQueuedBuffers(int targetSubpartition) | 获取所有子分区队列中buffer的数量 |
| void flushSubpartition(int targetSubpartition, boolean finishProducers) | flush指定分区 |
| void flushAllSubpartitions(boolean finishProducers) | flush所有分区 |
| void emitRecord(ByteBuffer record, int targetSubpartition) | 将序列化结果写入buffer |
| BufferBuilder appendUnicastDataForNewRecord( final ByteBuffer record, final int targetSubpartition) | 将数据写入指定分区 |
| BufferBuilder requestNewUnicastBufferBuilder(int targetSubpartition) | 请求分区 |
| void finishUnicastBufferBuilder(int targetSubpartition) | BufferBuilder数据写满操作. |
| BufferBuilder appendUnicastDataForRecordContinuation( final ByteBuffer remainingRecordBytes, final int targetSubpartition) | 追加剩余数据 |
| void broadcastRecord(ByteBuffer record) | 广播数据 |
| broadcastEvent(AbstractEvent event, boolean isPriorityEvent) | 广播事件 |
| ResultSubpartitionView createSubpartitionView( int subpartitionIndex, BufferAvailabilityListener availabilityListener) | 创建子分区视图 |
| BufferBuilder appendBroadcastDataForNewRecord(final ByteBuffer record) | 追加广播数据 |
| BufferBuilder appendBroadcastDataForRecordContinuation( final ByteBuffer remainingRecordBytes) | 最加剩余的广播数据 |
| void createBroadcastBufferConsumers(BufferBuilder buffer, int partialRecordBytes) | 创建广播Buffer消费者 |
| BufferBuilder requestNewBroadcastBufferBuilder() | 请求新的广播buffer |
| requestNewBufferBuilderFromPool(int targetSubpartition) | 为某分区请求新的BufferBuilder |
| void finishUnicastBufferBuilders() | 将所有分区的数据设置为finish |
| void finishBroadcastBufferBuilder() | 将所有的广播buffer设置为finish |
3.4. BufferBuilder
不是线程安全类,用于填充{@link MemorySegment}的内容。
要访问写入的数据,请使用{@link BufferConsumer},它允许从写入的数据构建{@link Buffer}实例。
3.4.1. 属性
一共有四个属性
| 名称 | 描述 |
|---|---|
| MemorySegment memorySegment; | 内存片段 |
| BufferRecycler recycler; | buffer回收器 |
| SettablePositionMarker positionMarker = new SettablePositionMarker(); | 指针对象,用于记录MemorySegmentx写入的位置等指针信息 |
| boolean bufferConsumerCreated = false; | 是否构建Consumer |
3.4.2. 构造方法
构造方法只是赋值操作, 给MemorySegment和BufferRecycler赋值…
public BufferBuilder(MemorySegment memorySegment, BufferRecycler recycler) {
this.memorySegment = checkNotNull(memorySegment);
this.recycler = checkNotNull(recycler);
}
3.4.3. 构造BufferConsumer相关方法
此方法始终从当前writer offset 开始创建{@link BufferConsumer}。
在创建{@link BufferConsumer}之前写入{@link BufferBuilder}的数据对于该{@link BufferConsumer}将不可见。
// 从指定的offset位置, 构建BufferConsumer .
private BufferConsumer createBufferConsumer(int currentReaderPosition) {
checkState(
!bufferConsumerCreated, "Two BufferConsumer shouldn't exist for one BufferBuilder");
// 设置bufferConsumerCreated 为true
bufferConsumerCreated = true;
// 构建BufferConsumer
return new BufferConsumer(memorySegment, recycler, positionMarker, currentReaderPosition);
}
3.4.3. MemorySegment内存操作相关方法
appendAndCommit & append
将数据写入到memorySegment .
/** Same as {@link #append(ByteBuffer)} but additionally {@link #commit()} the appending. */
public int appendAndCommit(ByteBuffer source) {
int writtenBytes = append(source);
commit();
return writtenBytes;
}
/**
* Append as many data as possible from {@code source}. Not everything might be copied if there
* is not enough space in the underlying {@link MemorySegment}
*
* @return number of copied bytes
*/
public int append(ByteBuffer source) {
checkState(!isFinished());
int needed = source.remaining();
int available = getMaxCapacity() - positionMarker.getCached();
int toCopy = Math.min(needed, available);
memorySegment.put(positionMarker.getCached(), source, toCopy);
positionMarker.move(toCopy);
return toCopy;
}
commit
更新指针的位置
/**
* Make the change visible to the readers. This is costly operation (volatile access) thus in
* case of bulk writes it's better to commit them all together instead one by one.
*/
public void commit() {
positionMarker.commit();
}
3.4.3. 资源回收
recycle
public void recycle() {
recycler.recycle(memorySegment);
}
3.5. BufferConsumer
BufferBuilder类中的createBufferConsumer方法, 会从MemorySegment的指定offset构建BufferConsumer .
new BufferConsumer(memorySegment, recycler, positionMarker, currentReaderPosition)
3.5.1. 属性
BufferConsumer 有三个属性一个是Buffer buffer , 所有的memorySegment都会封装成NetworkBuffer .
剩下的CachedPositionMarker writerPosition 和 int currentReaderPosition 分别是写入的位置和当前读取位置的指针.
private final Buffer buffer;
private final CachedPositionMarker writerPosition;
private int currentReaderPosition;
3.5.2. 构造方法
BufferConsumer的构造方法中会将传入的MemorySegment封装成NetworkBuffer.
NetworkBuffer是一个MemorySegment的封装, 创建的时候需要指定他们的回收器recycler。
Recycler需要实现BufferRecycler接口, 该接口仅有一个方法recycle, 存放了MemorySegment的回收逻辑。
BufferBuilder.PositionMarker封装成CachedPositionMarker .
/** Constructs {@link BufferConsumer} instance with the initial reader position. */
public BufferConsumer(
MemorySegment memorySegment,
BufferRecycler recycler,
PositionMarker currentWriterPosition,
int currentReaderPosition) {
this(
new NetworkBuffer(checkNotNull(memorySegment), checkNotNull(recycler)),
currentWriterPosition,
currentReaderPosition);
}
3.5.3. 操作方法
| 名称 | 描述 |
|---|---|
| Buffer build() | 构建根据信息构建新的NetworkBuffer |
| skip(int bytesToSkip) | 读取指针跳到指定位置 |
| BufferConsumer copy() | 复制一个新的BufferConsumer |
| close() | 回收操作… |
3.6. ResultSubpartitionView
ResultSubpartitionView 是一个接口, 用于消费 {@link ResultSubpartition}实例的视图
| 名称 | 描述 |
|---|---|
| BufferAndBacklog getNextBuffer() | 从队列中获取下一个{@link Buffer}的实例 |
| void notifyDataAvailable(); | 通知 ResultSubpartition 的数据可供消费 |
| void notifyPriorityEvent(int priorityBufferNumber) | 已经完成对 ResultSubpartition 的Event消费 |
| void releaseAllResources() | 释放所有资源 |
| boolean isReleased(); | 是否释放 |
| void resumeConsumption() | 恢复消费数据 |
| Throwable getFailureCause() | 获取失败原因 |
| boolean isAvailable(int numCreditsAvailable) | 是否可用(比如信用额度) |
| int unsynchronizedGetNumberOfQueuedBuffers() | 获取队列中尚未消费的BufferConsumer |
3.7. 实现类PipelinedSubpartitionView
PipelinedSubpartitionView 是ResultSubpartitionView 的实现类.
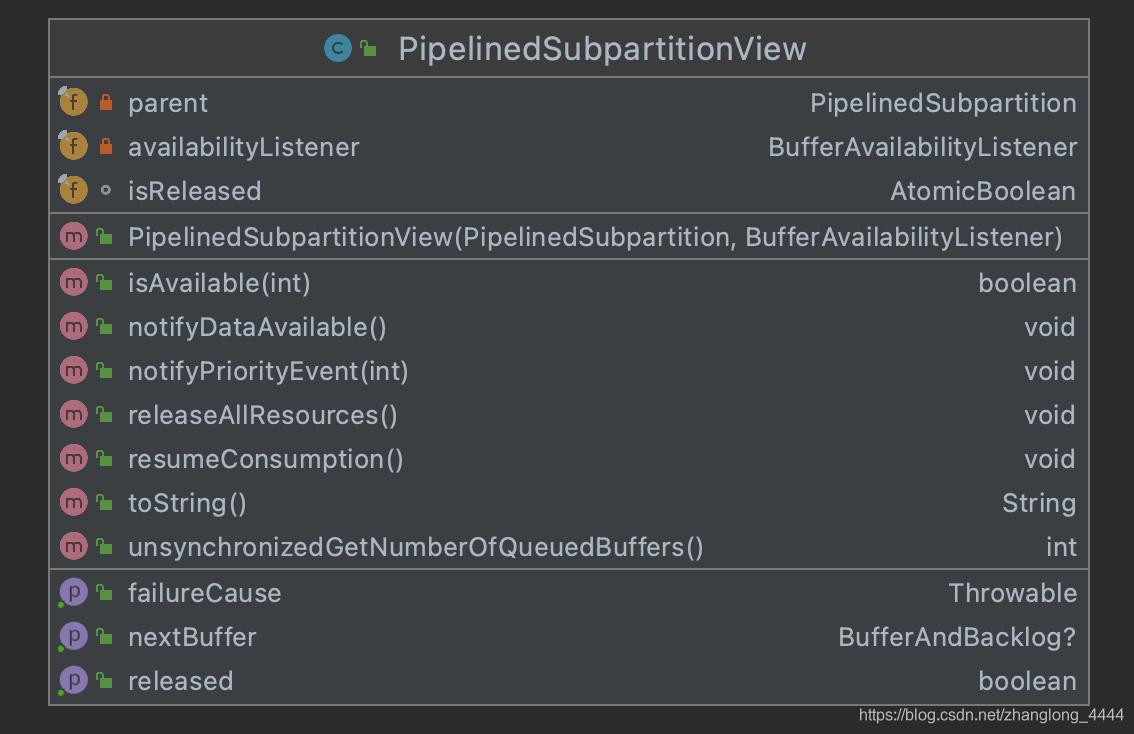
3.7.1. 属性
/**
* 标识这个视图归属于哪个 PipelinedSubpartition
* The subpartition this view belongs to.
* */
private final PipelinedSubpartition parent;
/**
* 当有数据的时候通过BufferAvailabilityListener的实现通知
* LocalInputChannel
* 或者
* CreditBasedSequenceNumberingViewReader(RemoteInputChannel)有数据到来,可以消费数据
*/
private final BufferAvailabilityListener availabilityListener;
/**
* 这个视图是否被释放
* Flag indicating whether this view has been released. */
final AtomicBoolean isReleased;
3.7.2. 构造方法
public PipelinedSubpartitionView(
PipelinedSubpartition parent, BufferAvailabilityListener listener) {
this.parent = checkNotNull(parent);
this.availabilityListener = checkNotNull(listener);
// 原子类, 资源是否释放.
this.isReleased = new AtomicBoolean();
}
3.7.3. 方法相关
PipelinedSubpartitionView 是ResultSubpartitionView接口的实现类. 所以要实现ResultSubpartitionView接口的所有方法.
| 名称 | 描述 |
|---|---|
| BufferAndBacklog getNextBuffer() | 从队列中获取下一个{@link Buffer}的实例 |
| void notifyDataAvailable(); | 通知 ResultSubpartition 的数据可供消费 |
| void notifyPriorityEvent(int priorityBufferNumber) | 已经完成对 ResultSubpartition 的Event消费 |
| void releaseAllResources() | 释放所有资源 |
| boolean isReleased(); | 是否释放 |
| void resumeConsumption() | 恢复消费数据 |
| Throwable getFailureCause() | 获取失败原因 |
| boolean isAvailable(int numCreditsAvailable) | 是否可用(比如信用额度) |
| int unsynchronizedGetNumberOfQueuedBuffers() | 获取队列中尚未消费的BufferConsumer |
其实大部分的方法都是直接调用该 该PipelinedSubpartitionView 所属 PipelinedSubpartition的方法.
notifyDataAvailable
这个方法重点说一下吧, 当有数据到来的时候,会通知inputchannel有数据到了,进而inputchannel的实现就可以进行消费了.
availabilityListener的实现就两个 一个是LocalInputChannel 另一个是 CreditBasedSequenceNumberingViewReader(针对RemoteInputChannel)有数据到来,可以消费数据 .
@Override
public void notifyDataAvailable() {
//回调接口,通知inputchannel有数据到来
availabilityListener.notifyDataAvailable();
}
3.8. PipelinedResultPartition
PipelinedResultPartition是抽象类BufferWritingResultPartition 的实现类
一个任务的结果输出,通过pipelined (streamed) 传输到接收器。
这个结果分区实现同时用于批处理和流处理。
对于流式传输,它支持低延迟传输(确保数据在100毫秒内发送)或无限制传输,而对于批处理,它仅在缓冲区已满时传输。
此外,对于流式使用,这通常会限制缓冲区积压的长度,以避免有太多的数据在传输中,而对于批处理,我们不限制这一点。
3.8.1. 属性
就三个属性, 一个锁, 以及一个数组用于标识子分区是否可以用于消费和另一个暂停消费的子分区的数量 .
/**
* The lock that guard release operations (which can be asynchronously propagated from the
* networks threads.
*/
private final Object releaseLock = new Object();
/**
* A flag for each subpartition indicating whether it was already consumed or not, to make
* releases idempotent.
*/
@GuardedBy("releaseLock")
private final boolean[] consumedSubpartitions;
/**
* The total number of references to subpartitions of this result. The result partition can be
* safely released, iff the reference count is zero.
*/
@GuardedBy("releaseLock")
private int numUnconsumedSubpartitions;
3.8.2 构造方法
public PipelinedResultPartition(
String owningTaskName,
int partitionIndex,
ResultPartitionID partitionId,
ResultPartitionType partitionType,
ResultSubpartition[] subpartitions,
int numTargetKeyGroups,
ResultPartitionManager partitionManager,
@Nullable BufferCompressor bufferCompressor,
SupplierWithException<BufferPool, IOException> bufferPoolFactory) {
super(
owningTaskName,
partitionIndex,
partitionId,
checkResultPartitionType(partitionType),
subpartitions,
numTargetKeyGroups,
partitionManager,
bufferCompressor,
bufferPoolFactory);
this.consumedSubpartitions = new boolean[subpartitions.length];
this.numUnconsumedSubpartitions = subpartitions.length;
}
3.8.3 方法相关
onConsumedSubpartition
/**
* 一旦释放了所有子分区读取器,pipelined分区就会自动释放。
*
* 这是因为pipelined分区不能被多次使用或重新连接。
*
* The pipelined partition releases automatically once all subpartition readers are released.
* That is because pipelined partitions cannot be consumed multiple times, or reconnect.
*/
@Override
void onConsumedSubpartition(int subpartitionIndex) {
// 如果资源已被释放, 则直接return
if (isReleased()) {
return;
}
final int remainingUnconsumed;
// we synchronize only the bookkeeping section, to avoid holding the lock during any
// calls into other components
//加锁
synchronized (releaseLock) {
// 如果该子分区已经处于可消费的状态,直接返回
if (consumedSubpartitions[subpartitionIndex]) {
// repeated call - ignore
return;
}
// 设置该子分区处于可消费的状态
以上是关于flinkFlink 1.12.2 源码浅析 :Task数据输出的主要内容,如果未能解决你的问题,请参考以下文章
flinkFlink 1.12.2 源码浅析 : Task 浅析
flinkFlink 1.12.2 源码浅析 : Task数据输入
flinkFlink 1.12.2 源码浅析 :Task数据输出
flinkFlink 1.12.2 源码浅析 : yarn-per-job模式解析 TaskMasger 启动
flinkFlink 1.12.2 源码浅析 : yarn-per-job模式解析 yarn 提交过程解析
flinkFlink 1.12.2 源码浅析 : yarn-per-job模式解析 JobMasger启动 YarnJobClusterEntrypoint