flinkFlink 1.12.2 源码浅析 : yarn-per-job模式解析 yarn 提交过程解析
Posted 九师兄
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了flinkFlink 1.12.2 源码浅析 : yarn-per-job模式解析 yarn 提交过程解析相关的知识,希望对你有一定的参考价值。

1.概述
转载:Flink 1.12.2 源码浅析 : yarn-per-job模式解析 [二] 请大家看原文去。
接上文Flink 1.12.2 源码分析 : yarn-per-job模式浅析 [一] .
CliFrontend类最终会调用我们自己写的代码,入口类是main方法.
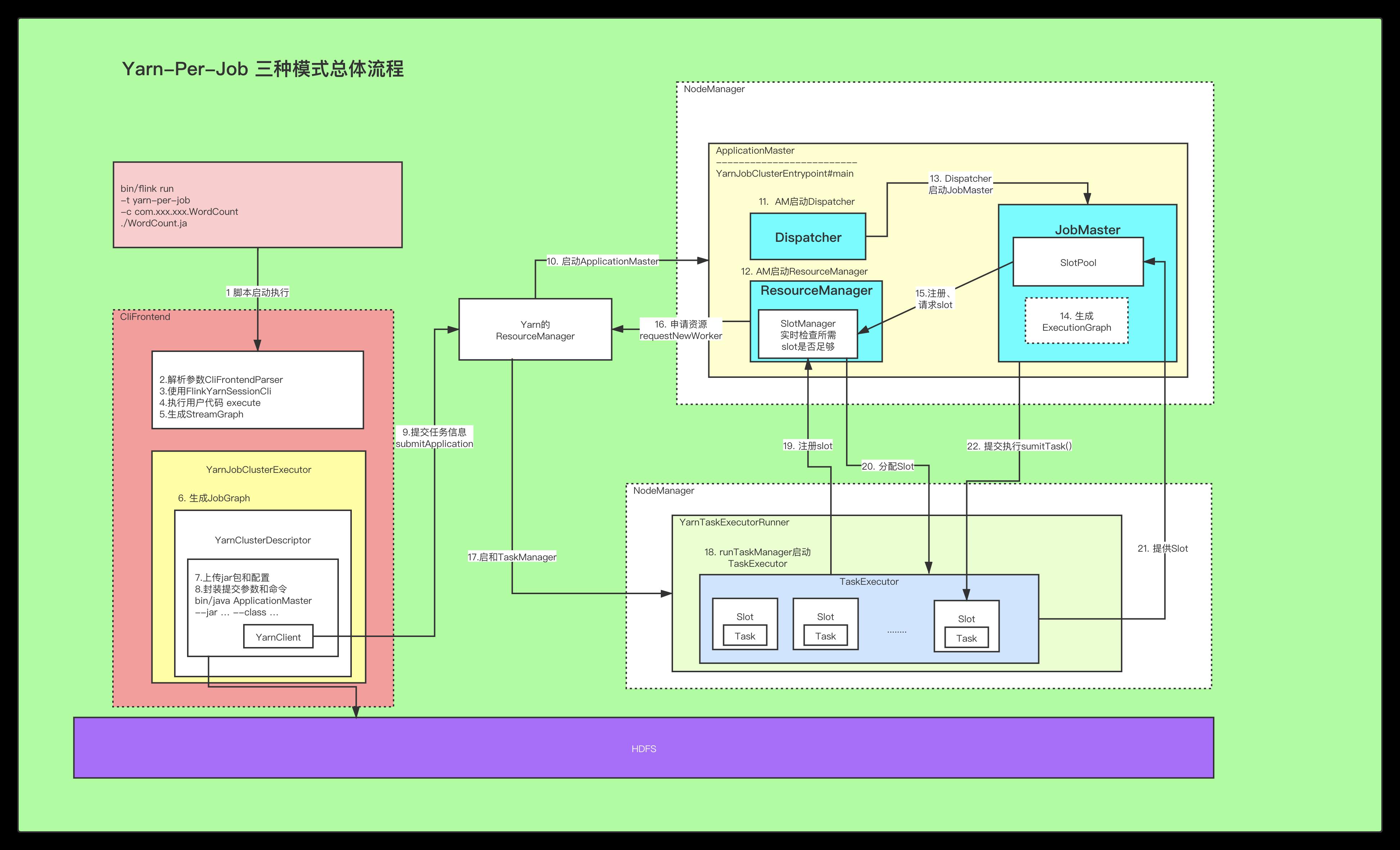
整体流程图
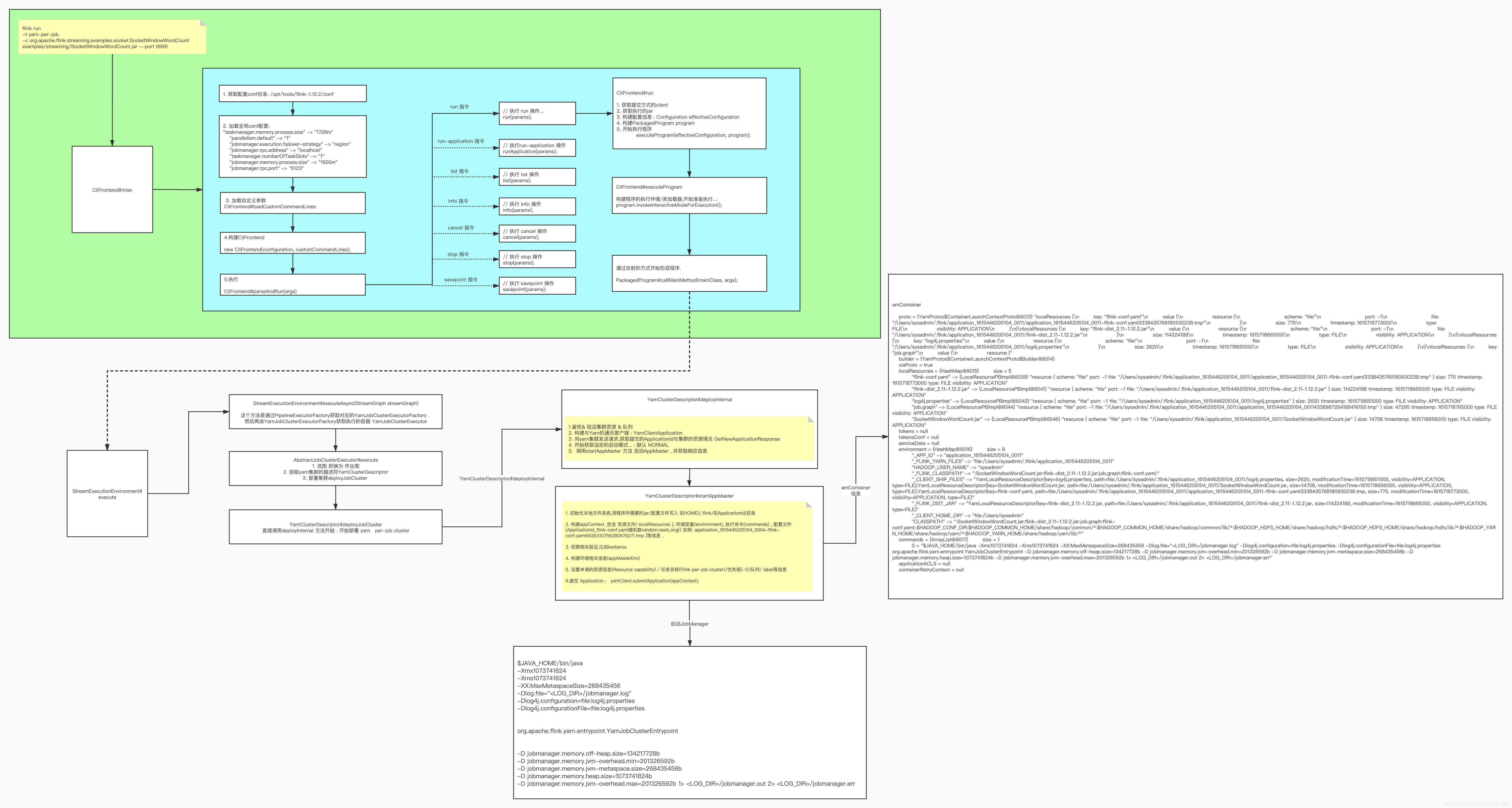
细节图
整体代码如下:
package org.apache.flink.streaming.examples.socket;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
/**
* Implements a streaming windowed version of the "WordCount" program.
*
* <p>This program connects to a server socket and reads strings from the socket. The easiest way to
* try this out is to open a text server (at port 12345) using the <i>netcat</i> tool via
*
* <pre>
* nc -l 12345 on Linux or nc -l -p 12345 on Windows
* </pre>
*
* <p>and run this example with the hostname and the port as arguments.
*/
@SuppressWarnings("serial")
public class SocketWindowWordCount {
public static void main(String[] args) throws Exception {
// the host and the port to connect to
final String hostname;
final int port;
try {
final ParameterTool params = ParameterTool.fromArgs(args);
hostname = params.has("hostname") ? params.get("hostname") : "localhost";
port = params.getInt("port");
} catch (Exception e) {
System.err.println(
"No port specified. Please run 'SocketWindowWordCount "
+ "--hostname <hostname> --port <port>', where hostname (localhost by default) "
+ "and port is the address of the text server");
System.err.println(
"To start a simple text server, run 'netcat -l <port>' and "
+ "type the input text into the command line");
return;
}
// get the execution environment
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// get input data by connecting to the socket
DataStream<String> text = env.socketTextStream(hostname, port, "\\n");
// parse the data, group it, window it, and aggregate the counts
DataStream<WordWithCount> windowCounts =
text.flatMap(
new FlatMapFunction<String, WordWithCount>() {
@Override
public void flatMap(
String value, Collector<WordWithCount> out) {
for (String word : value.split("\\\\s")) {
out.collect(new WordWithCount(word, 1L));
}
}
})
.keyBy(value -> value.word)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.reduce(
new ReduceFunction<WordWithCount>() {
@Override
public WordWithCount reduce(WordWithCount a, WordWithCount b) {
return new WordWithCount(a.word, a.count + b.count);
}
});
// print the results with a single thread, rather than in parallel
windowCounts.print().setParallelism(1);
env.execute("Socket Window WordCount");
}
// ------------------------------------------------------------------------
/** Data type for words with count. */
public static class WordWithCount {
public String word;
public long count;
public WordWithCount() {}
public WordWithCount(String word, long count) {
this.word = word;
this.count = count;
}
@Override
public String toString() {
return word + " : " + count;
}
}
}
二 .启动解析
2.1. StreamExecutionEnvironment#execute
在查看SocketWindowWordCount类的时候, 可以知道,这就是一个每5秒统计一次单词数量的类.
我们都知道, Flink代码最终执行的入口是env.execute, 所以我们从这里开始看.
2.1.1 StreamExecutionEnvironment#execute
在这里我们看到首先通过getStreamGraph(jobName) 生成StreamGraph , 然后交由execute(StreamGraph streamGraph) 开始执行
/**
* Triggers the program execution. The environment will execute all parts of the program that
* have resulted in a "sink" operation. Sink operations are for example printing results or
* forwarding them to a message queue.
*
* <p>The program execution will be logged and displayed with the provided name
*
* @param jobName Desired name of the job
* @return The result of the job execution, containing elapsed time and accumulators.
* @throws Exception which occurs during job execution.
*/
public JobExecutionResult execute(String jobName) throws Exception {
Preconditions.checkNotNull(jobName, "Streaming Job name should not be null.");
// 获取 getStreamGraph 继续执行...
return execute(getStreamGraph(jobName));
}
/**
* Triggers the program execution. The environment will execute all parts of the program that
* have resulted in a "sink" operation. Sink operations are for example printing results or
* forwarding them to a message queue.
*
* @param streamGraph the stream graph representing the transformations
* @return The result of the job execution, containing elapsed time and accumulators.
* @throws Exception which occurs during job execution.
*/
@Internal
public JobExecutionResult execute(StreamGraph streamGraph) throws Exception {
// ----------------------
// 提交代码的streamGraph
// ----------------------
final JobClient jobClient = executeAsync(streamGraph);
try {
final JobExecutionResult jobExecutionResult;
if (configuration.getBoolean(DeploymentOptions.ATTACHED)) {
jobExecutionResult = jobClient.getJobExecutionResult().get();
} else {
jobExecutionResult = new DetachedJobExecutionResult(jobClient.getJobID());
}
jobListeners.forEach(
jobListener -> jobListener.onJobExecuted(jobExecutionResult, null));
return jobExecutionResult;
} catch (Throwable t) {
// get() on the JobExecutionResult Future will throw an ExecutionException. This
// behaviour was largely not there in Flink versions before the PipelineExecutor
// refactoring so we should strip that exception.
Throwable strippedException = ExceptionUtils.stripExecutionException(t);
jobListeners.forEach(
jobListener -> {
jobListener.onJobExecuted(null, strippedException);
});
ExceptionUtils.rethrowException(strippedException);
// never reached, only make javac happy
return null;
}
}
在接下来我们就看到 executeAsync(streamGraph);
2.2. StreamExecutionEnvironment#executeAsync
这个方法是通过PipelineExecutorFactory获取对应的YarnJobClusterExecutorFactory .
然后再由YarnJobClusterExecutorFactory获取执行的容器 YarnJobClusterExecutor
@Override
public CompletableFuture<JobClient> execute(
@Nonnull final Pipeline pipeline,
@Nonnull final Configuration configuration,
@Nonnull final ClassLoader userCodeClassloader)
throws Exception {
// 流图 抓换为 作业图
// JobGraph(jobId: 536af83b56ddfc2ef4ffda8b43a21e15)
final JobGraph jobGraph = PipelineExecutorUtils.getJobGraph(pipeline, configuration);
// 获取yarn集群的描述符
try (final ClusterDescriptor<ClusterID> clusterDescriptor =
clusterClientFactory.createClusterDescriptor(configuration)) {
// {
// taskmanager.memory.process.size=1728m,
// jobmanager.execution.failover-strategy=region,
// jobmanager.rpc.address=localhost,
// execution.target=yarn-per-job,
// jobmanager.memory.process.size=1600m,
// jobmanager.rpc.port=6123,
// execution.savepoint.ignore-unclaimed-state=false,
// execution.attached=true,
// execution.shutdown-on-attached-exit=false,
// pipeline.jars=[file:/opt/tools/flink-1.12.2/examples/streaming/SocketWindowWordCount.jar],
// parallelism.default=1,
// taskmanager.numberOfTaskSlots=1,
// pipeline.classpaths=[],
// $internal.deployment.config-dir=/opt/tools/flink-1.12.2/conf,
// $internal.yarn.log-config-file=/opt/tools/flink-1.12.2/conf/log4j.properties
// }
final ExecutionConfigAccessor configAccessor =
ExecutionConfigAccessor.fromConfiguration(configuration);
// 获取指定资源的描述
// masterMemoryMB = 1600
// taskManagerMemoryMB = 1728
// slotsPerTaskManager = 1
final ClusterSpecification clusterSpecification =
clusterClientFactory.getClusterSpecification(configuration);
// 部署集群....
final ClusterClientProvider<ClusterID> clusterClientProvider =
clusterDescriptor.deployJobCluster(
clusterSpecification, jobGraph, configAccessor.getDetachedMode());
LOG.info("Job has been submitted with JobID " + jobGraph.getJobID());
return CompletableFuture.completedFuture(
new ClusterClientJobClientAdapter<>(
clusterClientProvider, jobGraph.getJobID(), userCodeClassloader));
}
}
2.3. YarnClusterDescriptor#deployJobCluster
直接调用deployInternal 方法开始 : 开始部署 yarn per-job cluster
@Override
public ClusterClientProvider<ApplicationId> deployJobCluster(
ClusterSpecification clusterSpecification, JobGraph jobGraph, boolean detached)
throws ClusterDeploymentException {
try {
// 开始部署 yarn per-job cluster
return deployInternal(
clusterSpecification,
"Flink per-job cluster",
// 这个数yarn集群入口的名字 !!!!!!
getYarnJobClusterEntrypoint(),
jobGraph,
detached);
} catch (Exception e) {
throw new ClusterDeploymentException("Could not deploy Yarn job cluster.", e);
}
}
2.4. YarnClusterDescriptor#deployInternal [核心]
/**
* This method will block until the ApplicationMaster/JobManager have been deployed on YARN.
*
* @param clusterSpecification Initial cluster specification for the Flink cluster to be
* deployed
* @param applicationName name of the Yarn application to start
* @param yarnClusterEntrypoint Class name of the Yarn cluster entry point.
* @param jobGraph A job graph which is deployed with the Flink cluster, {@code null} if none
* @param detached True if the cluster should be started in detached mode
*/
private ClusterClientProvider<ApplicationId> deployInternal(
ClusterSpecification clusterSpecification,
String applicationName,
String yarnClusterEntrypoint,
@Nullable JobGraph jobGraph,
boolean detached)
throws Exception {
// 安心配置信息相关.....
// currentUser: sysadmin (auth:SIMPLE)
final UserGroupInformation currentUser = UserGroupInformation.getCurrentUser();
if (HadoopUtils.isKerberosSecurityEnabled(currentUser)) {
boolean useTicketCache =
flinkConfiguration.getBoolean(SecurityOptions.KERBEROS_LOGIN_USETICKETCACHE);
if (!HadoopUtils.areKerberosCredentialsValid(currentUser, useTicketCache)) {
throw new RuntimeException(
"Hadoop security with Kerberos is enabled but the login user "
+ "does not have Kerberos credentials or delegation tokens!");
}
}
// 开启一系列检测, 是否有足够的资源启动集群 (jar , conf , yarn core)
isReadyForDeployment(clusterSpecification);
// ------------------ Check if the specified queue exists --------------------
// 检测队列是否存在...
checkYarnQueues(yarnClient);
// ------------------ Check if the YARN ClusterClient has the requested resources
// --------------
// 构建 application 的 客户端
// Create application via yarnClient
final YarnClientApplication yarnApplication = yarnClient.createApplication();
// 获取响应信息.
// application_id {
// id: 10
// cluster_timestamp: 1615446205104
// }
// maximumCapability {
// memory: 8192
// virtual_cores: 4
// resource_value_map {
// key: "memory-mb"
// value: 8192
// units: "Mi"
// type: COUNTABLE
// }
// resource_value_map {
// key: "vcores"
// value: 4
// units: ""
// type: COUNTABLE
// }
// }
final GetNewApplicationResponse appResponse = yarnApplication.getNewApplicationResponse();
// 获取yarn集群资源的最大值...
// <memory:8192, vCores:4>
Resource maxRes = appResponse.getMaximumResourceCapability();
final ClusterResourceDescription freeClusterMem;
try {
// 获取空间内存大小....
// freeClusterMem :
// totalFreeMemory = 104857600
// containerLimit = 104857600
// nodeManagersFree = {int[1]@4603}
freeClusterMem = getCurrentFreeClusterResources(yarnClient);
} catch (YarnException | IOException e) {
failSessionDuringDeployment(yarnClient, yarnApplication);
throw new YarnDeploymentException(
"Could not retrieve information about free cluster resources.", e);
}
// 获取yarn最小分配的内存大小, 默认 1024MB
final int yarnMinAllocationMB =
yarnConfiguration.getInt(
YarnConfiguration.RM_SCHEDULER_MINIMUM_ALLOCATION_MB,
YarnConfiguration.DEFAULT_RM_SCHEDULER_MINIMUM_ALLOCATION_MB);
// 如果最小分配的内存资源 < 0 , 抛出异常....
if (yarnMinAllocationMB <= 0) {
throw new YarnDeploymentException(
"The minimum allocation memory "
+ "("
+ yarnMinAllocationMB
+ " MB) configured via '"
+ YarnConfiguration.RM_SCHEDULER_MINIMUM_ALLOCATION_MB
+ "' should be greater than 0.");
}
final ClusterSpecification validClusterSpecification;
try {
// 开启验证, 验证资源是否满足需求...
validClusterSpecification =
validateClusterResources(
clusterSpecification, yarnMinAllocationMB, maxRes, freeClusterMem);
} catch (YarnDeploymentException yde) {
failSessionDuringDeployment(yarnClient, yarnApplication);
throw yde;
}
LOG.info("Cluster specification: {}", validClusterSpecification);
// 开始获取设定的启动模式... : NORMAL
final ClusterEntrypoint.ExecutionMode executionMode =
detached
? ClusterEntrypoint.ExecutionMode.DETACHED
: ClusterEntrypoint.ExecutionMode.NORMAL;
// 设置启动模式 : internal.cluster.execution-mode =>
flinkConfiguration.setString(ClusterEntrypoint.EXECUTION_MODE, executionMode.toString());
// 开始启动AppMaster, 获取响应信息
ApplicationReport report =
startAppMaster(
flinkConfiguration,
applicationName,
yarnClusterEntrypoint,
jobGraph,
yarnClient,
yarnApplication,
validClusterSpecification);
// 输出application id, 主要用去取消任务...
// print the application id for user to cancel themselves.
if (detached) {
final ApplicationId yarnApplicationId = report.getApplicationId();
logDetachedClusterInformation(yarnApplicationId, LOG);
}
// 设置集群配置...
setClusterEntrypointInfoToConfig(report);
return () -> {
try {
// 构建反馈的集群客户端...
return new RestClusterClient<>(flinkConfiguration, report.getApplicationId());
} catch (Exception e) {
throw new RuntimeException("Error while creating RestClusterClient.", e);
}
};
}
2.5. StreamExecutionEnvironment#startAppMaster
提交任务, 启动AppMaster .
private ApplicationReport startAppMaster(
Configuration configuration,
String applicationName,
String yarnClusterEntrypoint,
JobGraph jobGraph,
YarnClient yarnClient,
YarnClientApplication yarnApplication,
ClusterSpecification clusterSpecification)
throws Exception {
// ------------------ Initialize the file systems -------------------------
// 初始化文件系统
org.apache.flink.core.fs.FileSystem.initialize(
configuration, PluginUtils.createPluginManagerFromRootFolder(configuration));
// 获取文件系统: LocalFileSystem
final FileSystem fs = FileSystem.get(yarnConfiguration);
// 硬编码检查GoogleHadoopFileSystem, 因为他没有复写getScheme 方法
// hard coded check for the GoogleHDFS client because its not overriding the getScheme() method.
if (!fs.getClass