一文搞明白Python并发编程和并行编程
Posted 思源湖的鱼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文搞明白Python并发编程和并行编程相关的知识,希望对你有一定的参考价值。
目录
前言
出于需要,有多任务场景,但之前对并发和并行的了解像是一团浆糊,除了知道多进程、多线程、协程这么几个词,不知道他们的准确解释,不知道相关基础知识,不知道应用场景,不知道该用哪个库。故在此做番学习了解。
一、基础知识
1、并行和并发
在学习的时候,发现并行和并发在好些地方搞混了,这是两个概念,得先明确下
(1)定义
Erlang 之父 Joe Armstrong 画了一张很可爱的图来解释这两个概念:
- 并发是两个队列交替使用一台咖啡机
- 并行是两个队列同时使用两台咖啡机
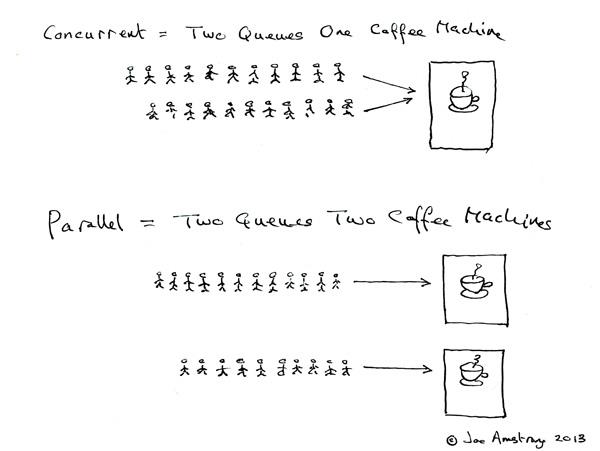
两个词很好的说明了并发和并行的区别:
- Parallel Computing:并行计算
- Concurrent programming:并发编程
(2)联系
那么并发并行和多进程多线程的关系呢?
- 多核cpu,多个进程可以并行在多个cpu中计算,当然也会存在进程切换;单核cpu,多个进程在这个单核cpu中是并发运行,根据时间片读取上下文+执行程序+保存上下文。同一个进程同一时间段只能在一个cpu中运行,如果进程数小于cpu数,那么未使用的cpu将会空闲
- 多核cpu,进程中的多线程并行执行;单核cpu,多线程在单核cpu中并发执行,根据时间片切换线程。同一个线程同一时间段只能在一个cpu内核中运行,如果线程数小于cpu内核数,那么将有多余的内核空闲
场景:
- 多核CPU——计算密集型任务:尽量使用并行计算,可以提高任务执行效率。计算密集型任务会持续地将CPU占满,此时有越多CPU来分担任务,计算速度就会越快,这是并行的用武之地
- 单核CPU——计算密集型任务:此时的任务已经把CPU资源100%消耗了,就没必要使用并行计算,毕竟硬件障碍摆在那里
- 单核CPU——I/O密集型任务:I/O密集型任务在任务执行时需要经常调用磁盘、屏幕、键盘等外设,由于调用外设时CPU会空闲,所以CPU的利用率并不高,此时使用多线程程序,只是便于人机交互。计算效率提升不大。
- 多核CPU——I/O密集型任务:同单核CPU——I/O密集型任务
总结下:
- 并行从代码层次上强依赖于多进程/多线程代码,从硬件角度上则依赖于多核CPU
- 并发是一种现象:同时运行多个程序或多个任务需要被处理的现象,这些任务可能是并行执行的,也可能是串行执行的,和CPU核心数无关,是操作系统进程调度和CPU上下文切换达到的结果
2、进程、线程和协程
(1)定义
1、进程
- 进程是程序的一次执行过程,是一个动态概念,是程序在执行过程中分配和管理资源的基本单位
- 在面向线程设计的系统(如当代多数操作系统、Linux 2.6及更新的版本)中,进程本身不是基本运行单位,而是线程的容器
- 进程拥有自己独立的内存空间,所属线程可以访问进程的空间
- 程序本身只是指令、数据及其组织形式的描述,进程才是程序的真正运行实例
2、线程
- 线程是CPU调度和分派的基本单位,它可与同属一个进程的其他的线程共享进程所拥有的全部资源
- 当前的操作系统是面向线程的,即以线程为基本运行单位,并按线程分配CPU
3、协程
-
又称微线程,纤程,英文名Coroutine。协程的作用是在执行函数A时可以随时中断去执行函数B,然后中断函数B继续执行函数A(可以自由切换)。但这一过程并不是函数调用,是线程里的并发
-
拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方(非CPU),在切回来的时候,恢复先前保存的寄存器上下文和栈。因此:协程能保留上一次调用时的状态(即所有局部状态的一个特定组合),每次过程重入时,就相当于进入上一次调用的状态,CPU感觉不到协程的存在,协程是用户自己控制的
-
优点:
无需线程上下文切换的开销
无需数据操作锁定及同步的开销
方便切换控制流,简化编程模型
高并发+高扩展性+低成本:一个CPU支持上万的协程都不是问题。所以很适合用于高并发处理 -
缺点:
无法利用多核资源:协程的本质是个单线程,它不能同时将单个CPU 的多个核用上,协程需要和进程配合才能运行在多CPU上,协程如果要使用多核CPU的话,那么就需要先启多个进程,在每个进程下启一个线程,然后在线程下在启协程。
日常所编写的绝大部分应用都没有这个必要,除非是cpu密集型应用
(2)联系
线程是进程的一部分,一个线程只能属于一个进程,而一个进程可以有多个线程,且至少有一个线程。而协程则包含在线程中
可以看个图
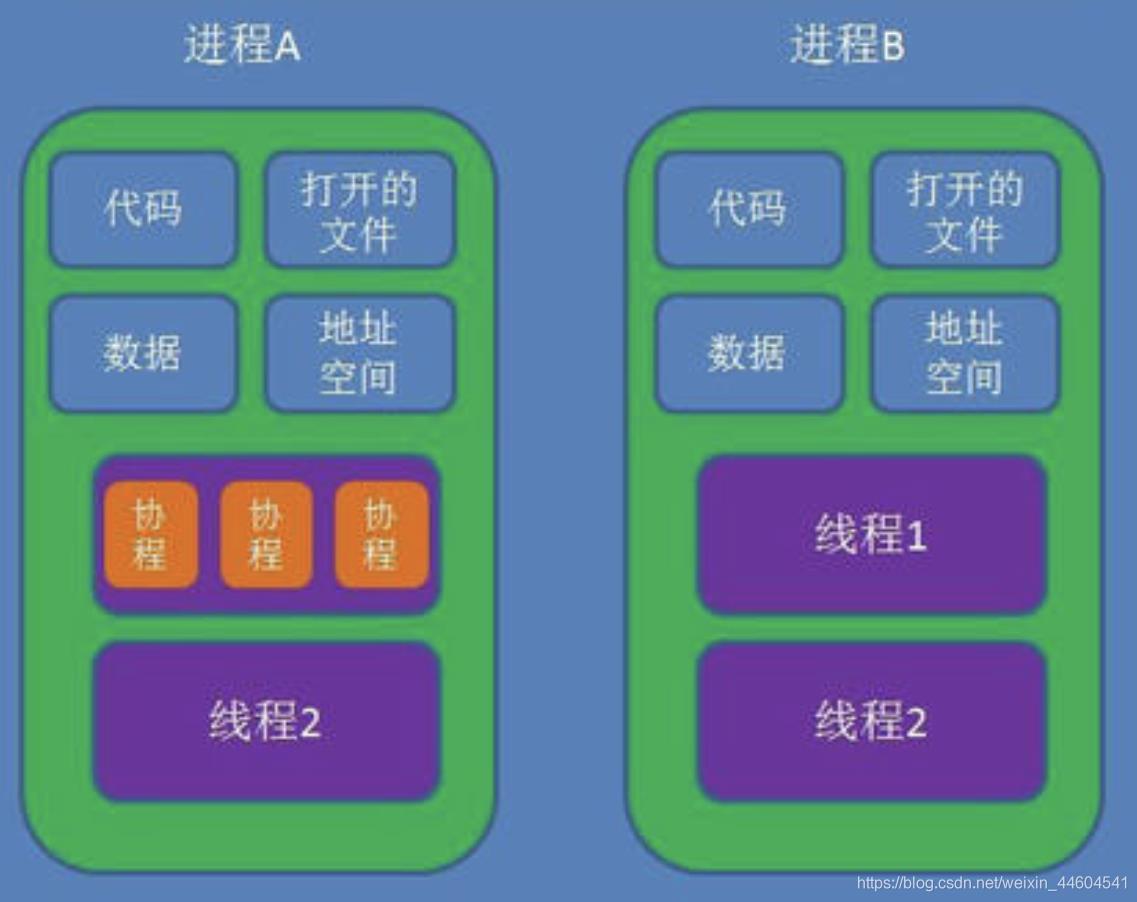
区别:理解它们的差别,从资源使用的角度出发。(所谓的资源就是计算机里的中央处理器,内存,文件,网络等等)
-
根本区别:进程是操作系统资源分配的基本单位,而线程是任务调度和执行的基本单位
-
在开销方面:每个进程都有独立的代码和数据空间(程序上下文),程序之间的切换会有较大的开销;线程共享代码和数据空间,每个线程都有自己独立的运行栈和程序计数器(PC),线程之间切换的开销小
-
所处环境:在操作系统中能同时运行多个进程(程序);而在同一个进程(程序)中有多个线程同时执行(通过CPU调度,在每个时间片中只有一个线程执行)
-
内存分配方面:系统在运行的时候会为每个进程分配不同的内存空间;而对线程而言,除了CPU外,系统不会为线程分配内存(线程所使用的资源来自其所属进程的资源),线程组之间只能共享资源
包含关系:
- 没有线程的进程可以看做是单线程的,如果一个进程内有多个线程,则执行过程不是一条线的,而是多条线(线程)共同完成的
- 线程是进程的一部分,所以线程也被称为轻量级进程
- 协程是线程的一部分,被称为微型线程
3、生成器
一切还是得从生成器说起,因为asyncio或者大多数协程库内部也是通过生成器实现的
生成器是一次生成一个值的特殊类型函数,可以将其视为可恢复函数,这里就不探究其内部实现原理了
(1)yield
简单例子如下
def gen_func():
yield 1
yield 2
yield 3
if __name__ == '__main__':
gen = gen_func()
for i in gen:
print(i)
output:
1
2
3
上面的例子没有什么稀奇的不是吗?yield像一个特殊的关键字,将函数变成了一个类似于迭代器的对象,可以使用for循环取值。
(2)send, next
协程自然不会这么简单,python协程的目标是星辰大海,从上面的例之所以get不到它的野心,是因为你没有试过send, next两个函数。
首先说next
def gen_func():
yield 1
yield 2
yield 3
if __name__ == '__main__':
gen = gen_func()
print(next(gen))
print(next(gen))
print(next(gen))
output:
1
2
3
next的操作有点像for循环,每调用一次next,就会从中取出一个yield出来的值,其实还是没啥特别的,感觉还没有for循环好用。
不过,不知道你有没有想过,如果你只需要一个值,你next一次就可以了,然后你可以去做其他事情,等到需要的时候才回来再次next取值。
就这一部分而言,你也许知道为啥说生成器是可以暂停的了,不过,这似乎也没什么用,那是因为你不知到时,生成器除了可以抛出值,还能将值传递进去。
接下来我们看send的例子。
def gen_func():
a = yield 1
print("a: ", a)
b = yield 2
print("b: ", b)
c = yield 3
print("c: ", c)
return "finish"
if __name__ == '__main__':
gen = gen_func()
for i in range(4):
if i == 0:
print(gen.send(None))
else:
# 因为gen生成器里面只有三个yield,那么只能循环三次。
# 第四次循环的时候,生成器会抛出StopIteration异常,并且return语句里面内容放在StopIteration异常里面
try:
print(gen.send(i))
except StopIteration as e:
print("e: ", e)
output:
1
a: 1
2
b: 2
3
c: 3
e: finish
send有着next差不多的功能,不过send在传递一个值给生成器的同时,还能获取到生成器yield抛出的值,在上面的代码中,send分别将None,1,2,3四个值传递给了生成器,之所以第一需要传递None给生成器,是因为规定,之所以规定,因为第一次传递过去的值没有特定的变量或者说对象能接收,所以规定只能传递None, 如果你传递一个非None的值进去,会抛出一下错误
TypeError: can't send non-None value to a just-started generator
从上面的例子我们也发现,生成器里面的变量a,b,c获得了send函数发送来的1, 2, 3.
如果你有事件循环或者说多路复用的经验,你也许能够隐隐察觉到微妙的感觉。
这个微妙的感觉是,是否可以将IO操作yield出来?由事件循环调度, 如果你能get到这个微妙的感觉,那么你已经知道协程高并发的秘密了.
(3)yield from
下面是yield from的例子
def gen_func():
a = yield 1
print("a: ", a)
b = yield 2
print("b: ", b)
c = yield 3
print("c: ", c)
return 4
def middle():
gen = gen_func()
ret = yield from gen
print("ret: ", ret)
return "middle Exception"
def main():
mid = middle()
for i in range(4):
if i == 0:
print(mid.send(None))
else:
try:
print(mid.send(i))
except StopIteration as e:
print("e: ", e)
if __name__ == '__main__':
main()
output:
1
a: 1
2
b: 2
3
c: 3
ret: 4
e: middle Exception
从上面的代码我们发现,main函数调用的middle函数的send,但是gen_func函数却能接收到main函数传递的值.有一种透传的感觉,这就是yield from的作用, 这很关键。
而yield from最终传递出来的值是StopIteration异常,异常里面的内容是最终接收生成器(本示例是gen_func)return出来的值,所以ret获得了gen_func函数return的4.但是ret将异常里面的值取出之后会继续将接收到的异常往上抛,所以main函数里面需要使用try语句捕获异常。而gen_func抛出的异常里面的值已经被middle函数接收,所以middle函数会将抛出的异常里面的值设为自身return的值
4、IO模型
linux有5种IO模型
(1)同步IO
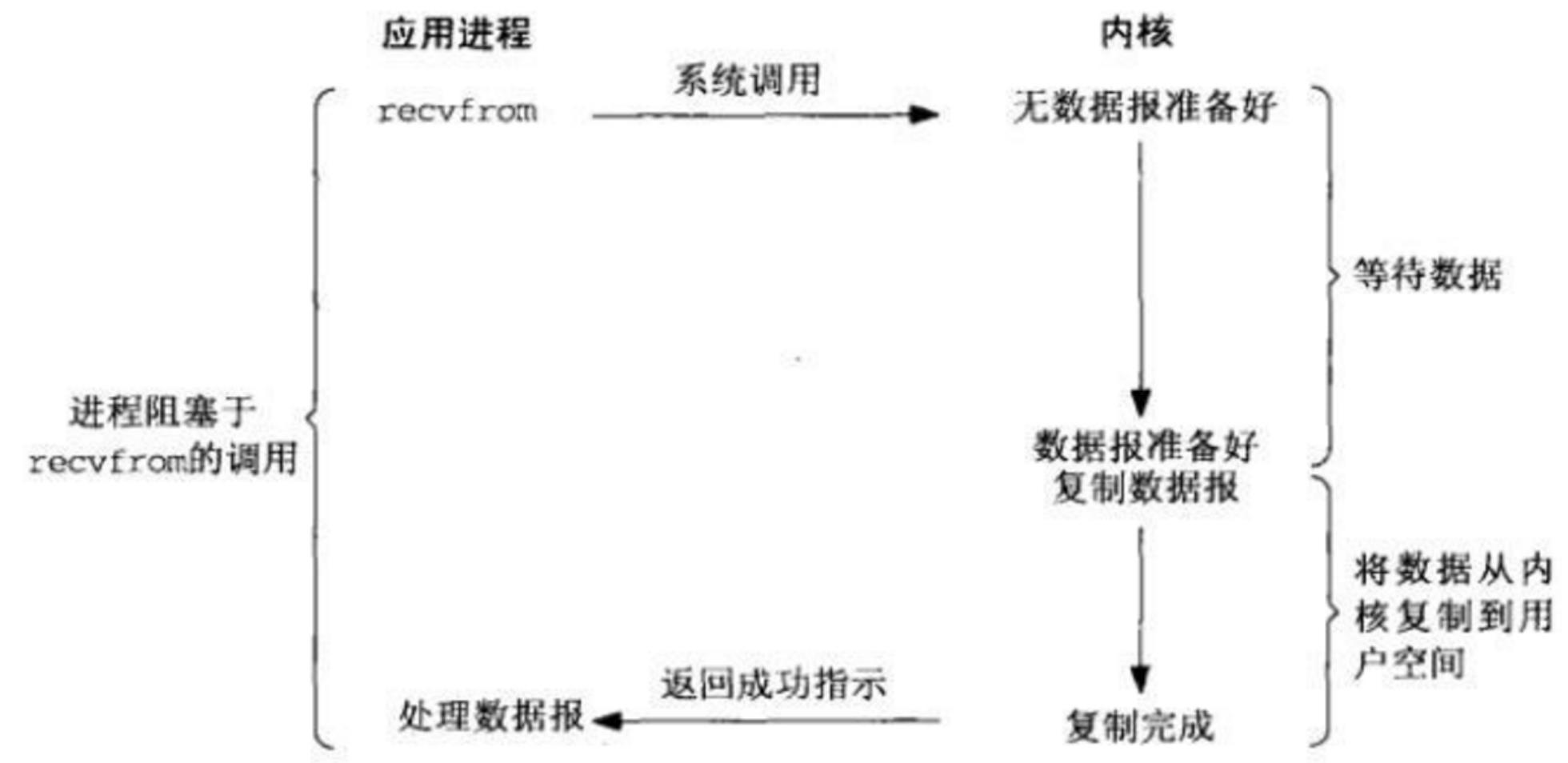
同步模型自然是效率最低的模型了,每次只能处理完一个连接才能处理下一个,如果只有一个线程的话, 如果有一个连接一直占用,那么后来者只能傻傻的等了。所以不适合高并发,不过最简单,符合惯性思维
(2)非阻塞式IO
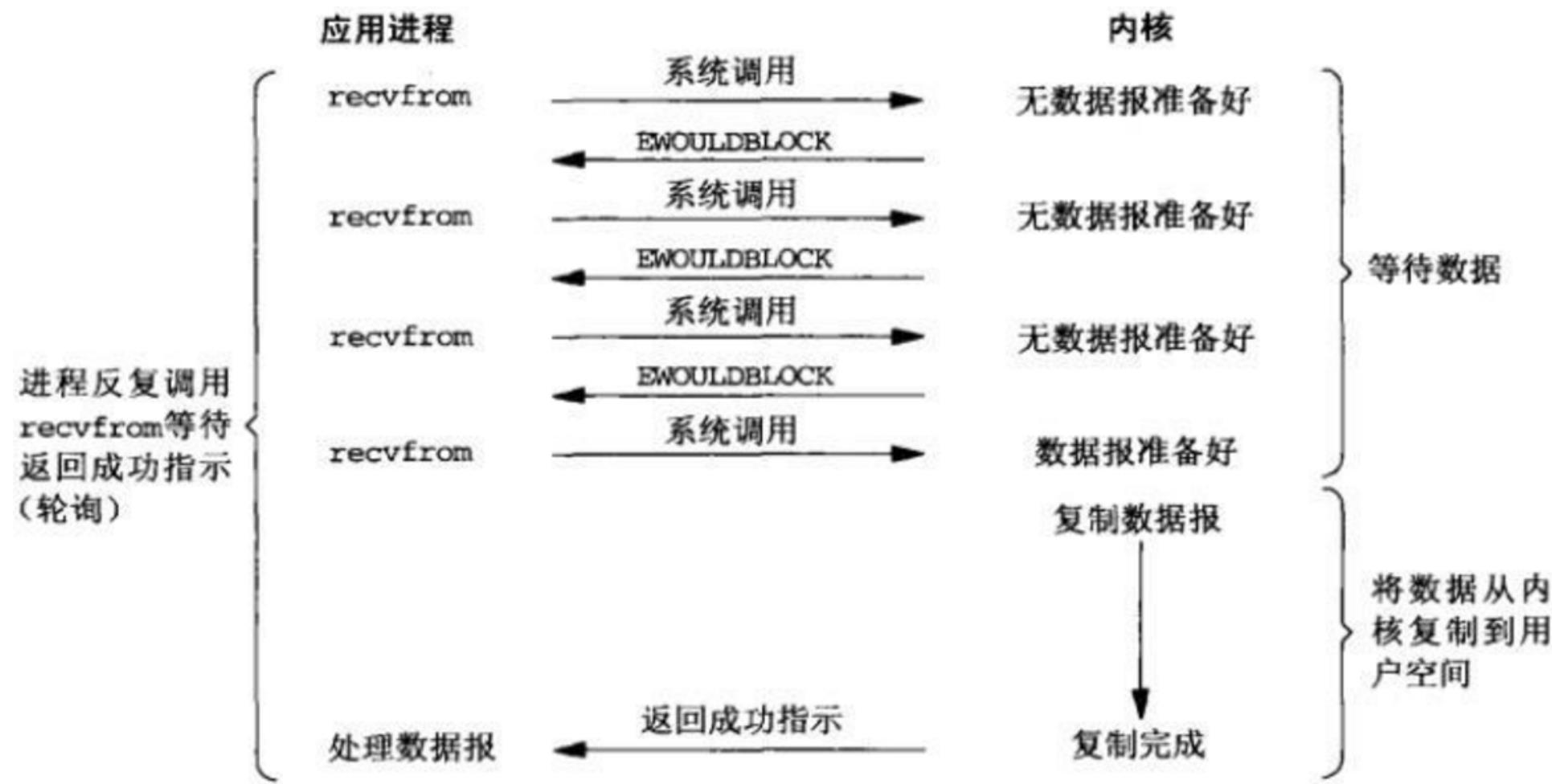
不会阻塞后面的代码,但是需要不停的显式询问内核数据是否准备好,一般通过while循环,而while循环会耗费大量的CPU。所以也不适合高并发。
(3)多路复用IO
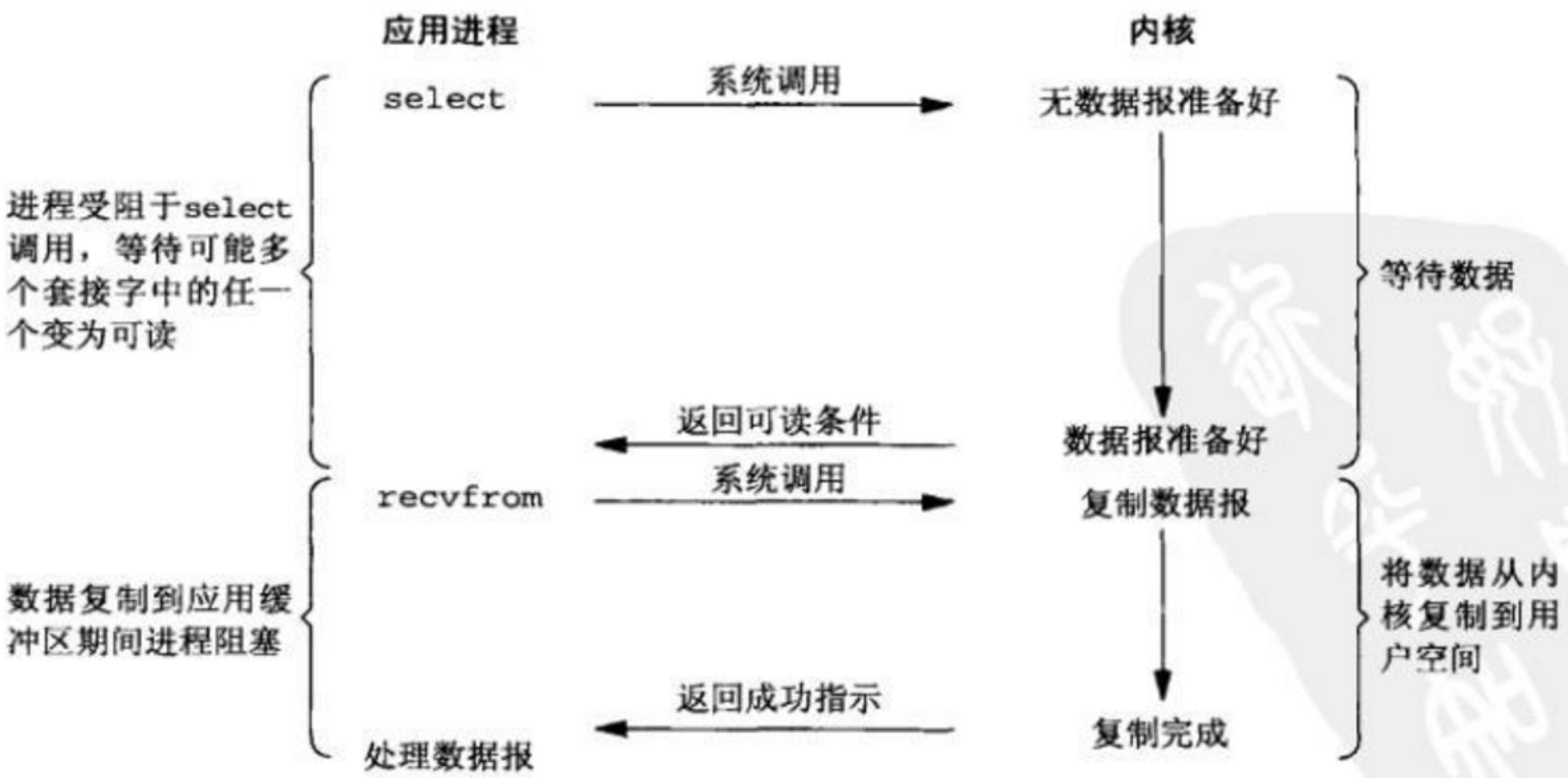
当前最流行,使用最广泛的高并发方案。
而多路复用又有三种实现方式, 分别是select, poll, epoll:
-
select,poll由于设计的问题,当处理连接过多会造成性能线性下降,而epoll是在前人的经验上做过改进的解决方案。不会有此问题。
-
不过select, poll并不是一无是处,假设场景是连接数不多,并且每个连接非常活跃,select,poll是要性能高于epoll的。
可参考:select、poll、epoll之间的区别总结[整理]
(4)信号驱动式IO
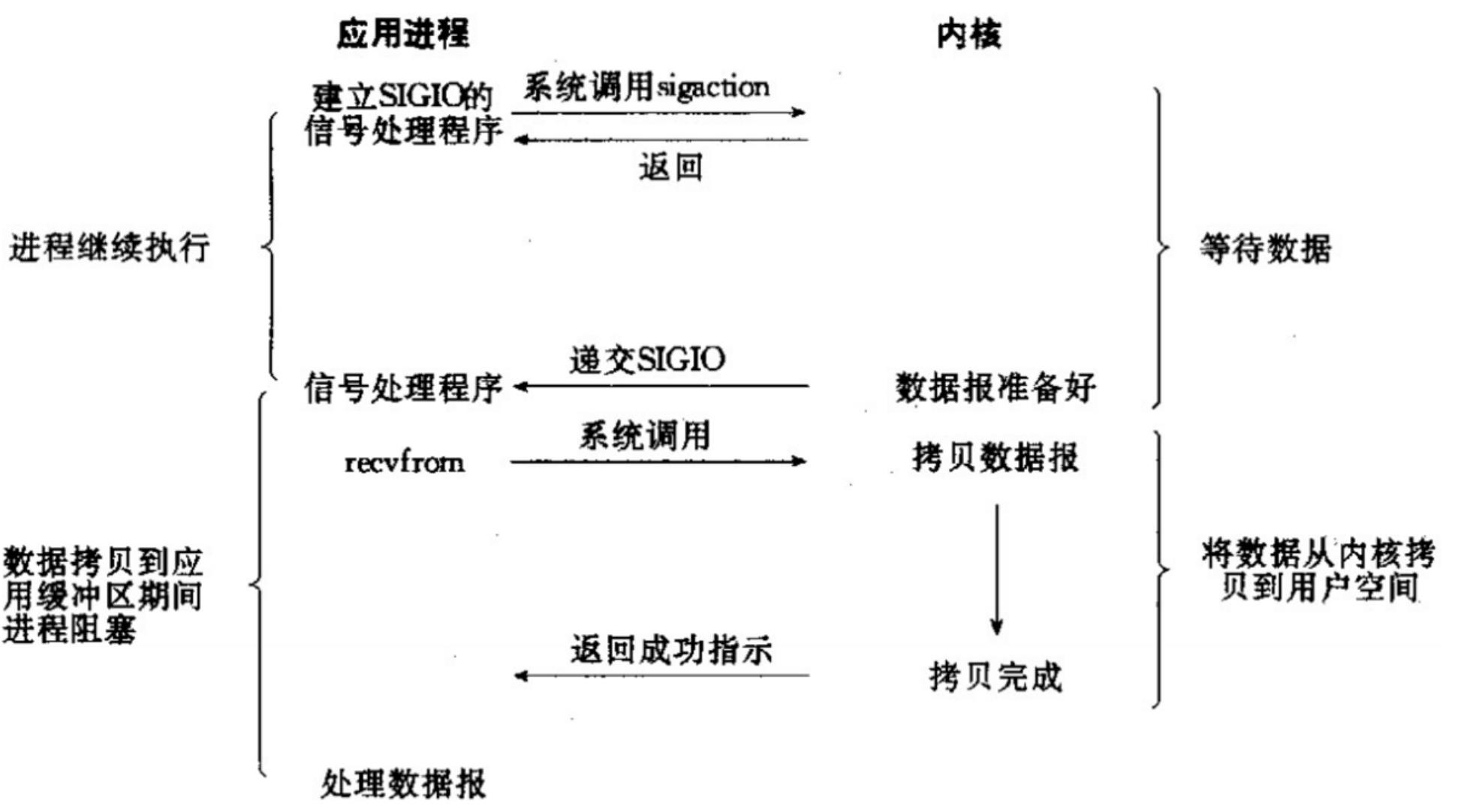
没见过
(5)异步非阻塞IO
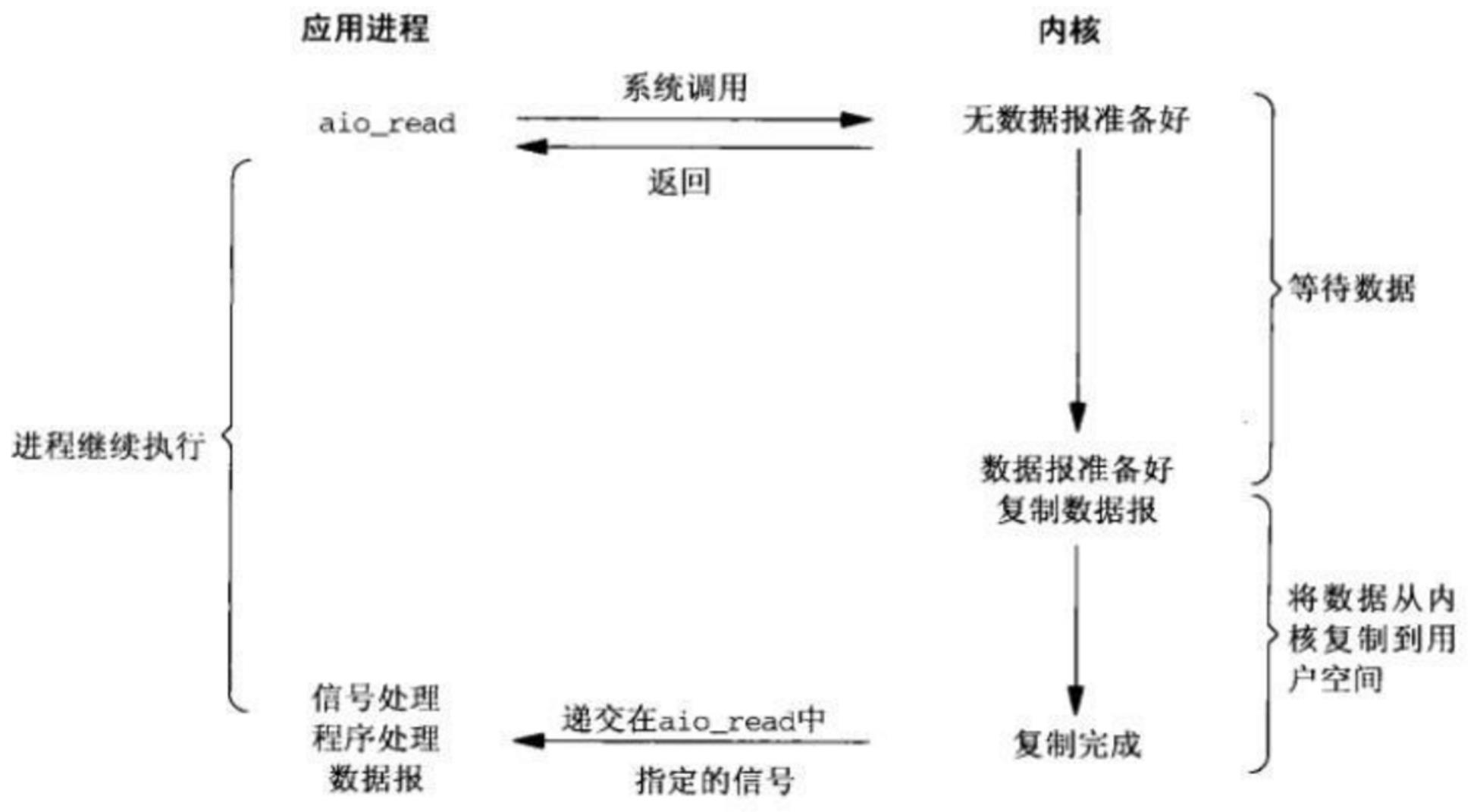
理论上比多路复用更快,因为少了一次调用,但是实际使用并没有比多路复用快非常多
5、事件循环
IO模型能够解决IO的效率问题,但是实际使用起来需要一个事件循环驱动协程去处理IO。
简单实现
下面引用官方的一个简单例子:
import selectors
import socket
# 创建一个selctor对象
# 在不同的平台会使用不同的IO模型,比如Linux使用epoll, windows使用select(不确定)
# 使用select调度IO
sel = selectors.DefaultSelector()
# 回调函数,用于接收新连接
def accept(sock, mask):
conn, addr = sock.accept() # Should be ready
print('accepted', conn, 'from', addr)
conn.setblocking(False)
sel.register(conn, selectors.EVENT_READ, read)
# 回调函数,用户读取client用户数据
def read(conn, mask):
data = conn.recv(1000) # Should be ready
if data:
print('echoing', repr(data), 'to', conn)
conn.send(data) # Hope it won't block
else:
print('closing', conn)
sel.unregister(conn)
conn.close()
# 创建一个非堵塞的socket
sock = socket.socket()
sock.bind(('localhost', 1234))
sock.listen(100)
sock.setblocking(False)
sel.register(sock, selectors.EVENT_READ, accept)
# 一个事件循环,用于IO调度
# 当IO可读或者可写的时候, 执行事件所对应的回调函数
def loop():
while True:
events = sel.select()
for key, mask in events:
callback = key.data
callback(key.fileobj, mask)
if __name__ == '__main__':
loop()
上面代码中loop函数对应事件循环,它要做的就是一遍一遍的等待IO,然后调用事件的回调函数.
二、实现
1、多进程、多线程、协程
实现就有多进程、多线程、协程三种方法,具体参见:
关键看场景:
- IO密集型并发用协程
- CPU密集型并发用多进程
- 并行用多进程
- 多线程在python里不咋推荐
- 一个任务拿不准是CPU密集还是I/O密集型,且没有其它不能选择多进程方式的因素,都统一直接上多进程模式,下面两个哪个快就哪个:
from multiprocessing import Pool
from multiprocessing.dummy import Pool
2、concurrent.futures库
从 Python3.2 开始一个叫做 concurrent.futures 被纳入了标准库,这个模块中有 2 个类:ThreadPoolExecutor 和 ProcessPoolExecutor,也就是对 threading 和 multiprocessing 的进行了高级别的抽象, 暴露出统一的接口,帮助开发者非常方便的实现异步调用
使用方法可以参见:
3、性能对比
结语
并发:多进程、多线程、协程
并行:多核CPU,多进程
参考:
以上是关于一文搞明白Python并发编程和并行编程的主要内容,如果未能解决你的问题,请参考以下文章
一文搞明白Python多进程编程:multiprocessing库