一文搞明白Python多线程编程:threading库
Posted 思源湖的鱼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文搞明白Python多线程编程:threading库相关的知识,希望对你有一定的参考价值。
目录
前言
本文试图搞明白Python多线程编程
这是几个姊妹篇:
一、基础知识
1、并行和并发
在学习的时候,发现并行和并发在好些地方搞混了,这是两个概念,得先明确下
(1)定义
Erlang 之父 Joe Armstrong 画了一张很可爱的图来解释这两个概念:
- 并发是两个队列交替使用一台咖啡机
- 并行是两个队列同时使用两台咖啡机
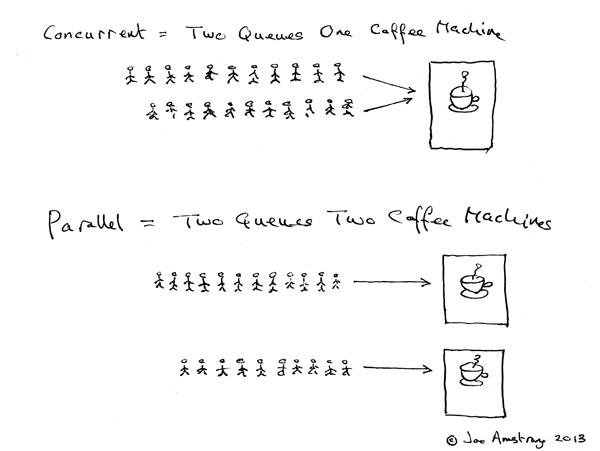
两个词很好的说明了并发和并行的区别:
- Parallel Computing:并行计算
- Concurrent programming:并发编程
(2)联系
那么并发并行和多进程多线程的关系呢?
- 多核cpu,多个进程可以并行在多个cpu中计算,当然也会存在进程切换;单核cpu,多个进程在这个单核cpu中是并发运行,根据时间片读取上下文+执行程序+保存上下文。同一个进程同一时间段只能在一个cpu中运行,如果进程数小于cpu数,那么未使用的cpu将会空闲
- 多核cpu,进程中的多线程并行执行;单核cpu,多线程在单核cpu中并发执行,根据时间片切换线程。同一个线程同一时间段只能在一个cpu内核中运行,如果线程数小于cpu内核数,那么将有多余的内核空闲
场景:
- 多核CPU——计算密集型任务:尽量使用并行计算,可以提高任务执行效率。计算密集型任务会持续地将CPU占满,此时有越多CPU来分担任务,计算速度就会越快,这是并行的用武之地
- 单核CPU——计算密集型任务:此时的任务已经把CPU资源100%消耗了,就没必要使用并行计算,毕竟硬件障碍摆在那里
- 单核CPU——I/O密集型任务:I/O密集型任务在任务执行时需要经常调用磁盘、屏幕、键盘等外设,由于调用外设时CPU会空闲,所以CPU的利用率并不高,此时使用多线程程序,只是便于人机交互。计算效率提升不大。
- 多核CPU——I/O密集型任务:同单核CPU——I/O密集型任务
总结下:
- 并行从代码层次上强依赖于多进程/多线程代码,从硬件角度上则依赖于多核CPU
- 并发是一种现象:同时运行多个程序或多个任务需要被处理的现象,这些任务可能是并行执行的,也可能是串行执行的,和CPU核心数无关,是操作系统进程调度和CPU上下文切换达到的结果
2、进程和线程
(1)定义
1、进程
- 进程是程序的一次执行过程,是一个动态概念,是程序在执行过程中分配和管理资源的基本单位
- 在面向线程设计的系统(如当代多数操作系统、Linux 2.6及更新的版本)中,进程本身不是基本运行单位,而是线程的容器
- 进程拥有自己独立的内存空间,所属线程可以访问进程的空间
- 程序本身只是指令、数据及其组织形式的描述,进程才是程序的真正运行实例
2、线程
- 线程是CPU调度和分派的基本单位,它可与同属一个进程的其他的线程共享进程所拥有的全部资源
- 当前的操作系统是面向线程的,即以线程为基本运行单位,并按线程分配CPU
(2)联系
线程是进程的一部分,一个线程只能属于一个进程,而一个进程可以有多个线程,且至少有一个线程
可以看个图
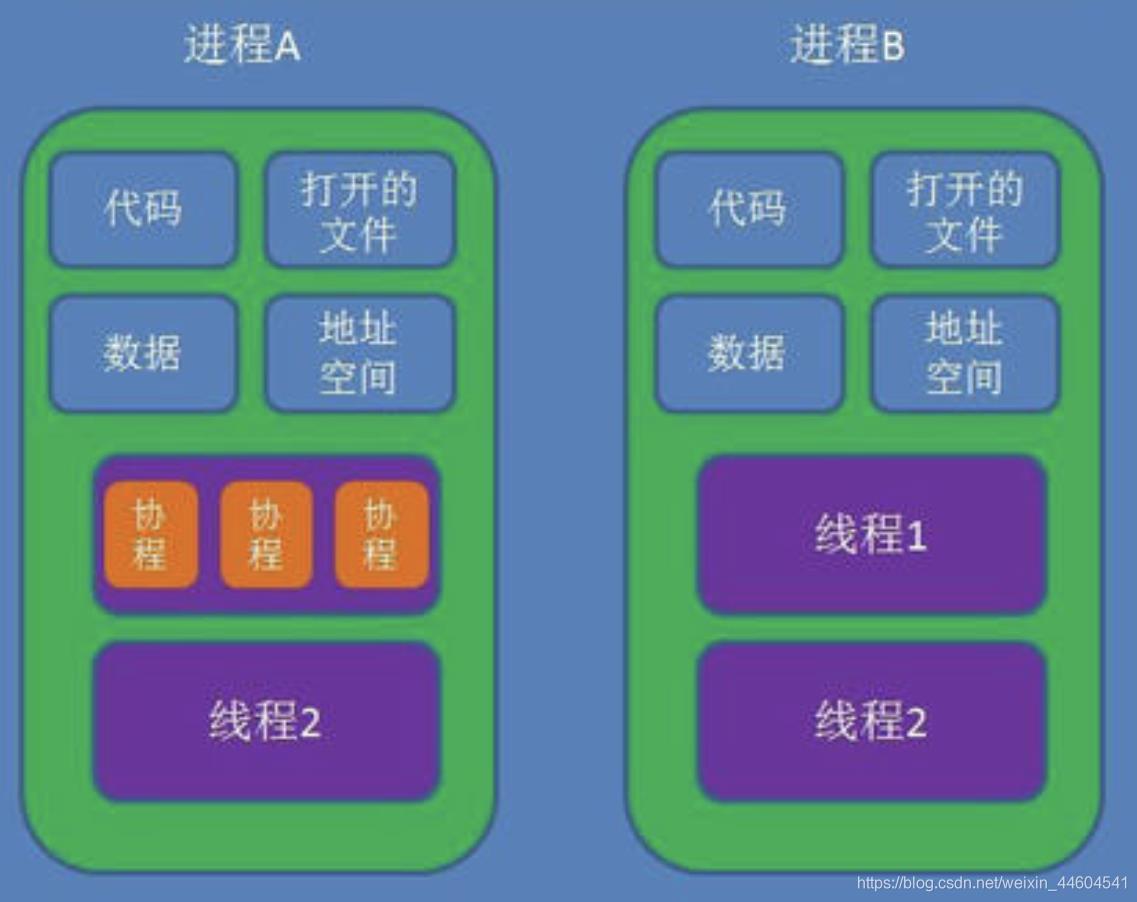
区别:理解它们的差别,从资源使用的角度出发。(所谓的资源就是计算机里的中央处理器,内存,文件,网络等等)
-
根本区别:进程是操作系统资源分配的基本单位,而线程是任务调度和执行的基本单位
-
在开销方面:每个进程都有独立的代码和数据空间(程序上下文),程序之间的切换会有较大的开销;线程共享代码和数据空间,每个线程都有自己独立的运行栈和程序计数器(PC),线程之间切换的开销小
-
所处环境:在操作系统中能同时运行多个进程(程序);而在同一个进程(程序)中有多个线程同时执行(通过CPU调度,在每个时间片中只有一个线程执行)
-
内存分配方面:系统在运行的时候会为每个进程分配不同的内存空间;而对线程而言,除了CPU外,系统不会为线程分配内存(线程所使用的资源来自其所属进程的资源),线程组之间只能共享资源
包含关系:
- 没有线程的进程可以看做是单线程的,如果一个进程内有多个线程,则执行过程不是一条线的,而是多条线(线程)共同完成的
- 线程是进程的一部分,所以线程也被称为轻量级进程
3、全局解释器锁GIL
GIL是计算机程序设计语言解释器用于同步线程的一种机制,它使得任何时刻仅有一个线程在执行。即便在多核心处理器上,使用 GIL 的解释器也只允许同一时间执行一个线程
Python的Cpython解释器(普遍使用的解释器)使用GIL(因为Cpython解释器是非线程安全的),在一个Python解释器进程内可以执行多线程程序,但每次一个线程执行时就会获得全局解释器锁,使得别的线程只能等待,由于GIL几乎释放的同时就会被原线程马上获得,那些等待线程可能刚唤醒,所以经常造成线程不平衡享受CPU资源,此时多线程的效率比单线程还要低下
在python的官方文档里,它是这样解释GIL的:
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple native threads from executing Python bytecodes at once. This lock is necessary mainly because CPython’s memory management is not thread-safe. (However, since the GIL exists, other features have grown to depend on the guarantees that it enforces.)
可以说它的初衷是很好的,为了保证线程间的数据安全性;但是随着时代的发展,GIL却成为了python并行计算的最大障碍,但这个时候GIL已经遍布CPython的各个角落,修改它的工作量太大,特别是对这种开源性的语言来说。但幸好GIL只锁了线程,我们可以再新建解释器进程来实现并行,那这就是multiprocessing的工作了
不同版本的差异:
- 在python2.x里,GIL的释放逻辑是当前线程遇见IO操作或者ticks计数达到100时进行释放。(ticks可以看作是python自身的一个计数器,专门做用于GIL,每次释放后归零,这个计数可以通过sys.setcheckinterval 来调整)。而每次释放GIL锁,线程进行锁竞争、切换线程,会消耗资源。并且由于GIL锁存在,python里一个进程永远只能同时执行一个线程(拿到GIL的线程才能执行),这就是为什么在多核CPU上,python的多线程效率并不高。
- 在python3.x中,GIL不使用ticks计数,改为使用计时器(执行时间达到阈值后,当前线程释放GIL),这样对CPU密集型程序更加友好,但依然没有解决GIL导致的同一时间只能执行一个线程的问题,所以效率依然不尽如人意。
二、threading库
1、线程的使用
(1)普通创建方式
import threading
import time
def run(n):
print("task", n)
time.sleep(1)
print('2s')
time.sleep(1)
print('1s')
time.sleep(1)
print('0s')
time.sleep(1)
if __name__ == '__main__':
t1 = threading.Thread(target=run, args=("t1",))
t2 = threading.Thread(target=run, args=("t2",))
t1.start()
t2.start()
(2)自定义线程
继承threading.Thread来自定义线程类,其本质是重构Thread类中的run方法
import threading
import time
class MyThread(threading.Thread):
def __init__(self, n):
super(MyThread, self).__init__() # 重构run函数必须要写
self.n = n
def run(self):
print("task", self.n)
time.sleep(1)
print('2s')
time.sleep(1)
print('1s')
time.sleep(1)
print('0s')
time.sleep(1)
if __name__ == "__main__":
t1 = MyThread("t1")
t2 = MyThread("t2")
t1.start()
t2.start()
(3)守护线程
我们看下面这个例子,这里使用setDaemon(True)把所有的子线程都变成了主线程的守护线程,因此当主进程结束后,子线程也会随之结束。所以当主线程结束后,整个程序就退出了。
import threading
import time
def run(n):
print("task", n)
time.sleep(1) #此时子线程停1s
print('3')
time.sleep(1)
print('2')
time.sleep(1)
print('1')
if __name__ == '__main__':
t = threading.Thread(target=run, args=("t1",))
t.setDaemon(True) #把子进程设置为守护线程,必须在start()之前设置
t.start()
print("end")
我们可以发现,设置守护线程之后,当主线程结束时,子线程也将立即结束,不再执行。
(4)主线程等待子线程结束
为了让守护线程执行结束之后,主线程再结束,我们可以使用join方法,让主线程等待子线程执行。
import threading
import time
def run(n):
print("task", n)
time.sleep(1) #此时子线程停1s
print('3')
time.sleep(1)
print('2')
time.sleep(1)
print('1')
if __name__ == '__main__':
t = threading.Thread(target=run, args=("t1",))
t.setDaemon(True) #把子进程设置为守护线程,必须在start()之前设置
t.start()
t.join() # 设置主线程等待子线程结束
print("end")
(5)多线程共享全局变量
线程是进程的执行单元,进程是系统分配资源的最小单位,所以在同一个进程中的多线程是共享资源的。
import threading
import time
g_num = 100
def work1():
global g_num
for i in range(3):
g_num += 1
print("in work1 g_num is : %d" % g_num)
def work2():
global g_num
print("in work2 g_num is : %d" % g_num)
if __name__ == '__main__':
t1 = threading.Thread(target=work1)
t1.start()
time.sleep(1)
t2 = threading.Thread(target=work2)
t2.start()
2、线程池
面向对象开发中,大家知道创建和销毁对象是很费时间的,因为创建一个对象要获取内存资源或者其它更多资源。无节制的创建和销毁线程是一种极大的浪费。那我们可不可以把执行完任务的线程不销毁而重复利用呢?仿佛就是把这些线程放进一个池子,一方面我们可以控制同时工作的线程数量,一方面也避免了创建和销毁产生的开销。
线程池在标准库中其实是有体现的,只是在官方文章中基本没有被提及:
In : from multiprocessing.pool import ThreadPool
In : pool = ThreadPool(5)
In : pool.map(lambda x: x**2, range(5))
Out: [0, 1, 4, 9, 16]
当然我们也可以自己实现一个:
#-*-coding=utf-8-*-
import time
import threading
from random import random
from Queue import Queue
def double(n):
return n * 2
class Worker(threading.Thread):
def __init__(self, queue):
super(Worker, self).__init__()
self._q = queue
self.daemon = True
self.start()
def run(self):
while 1:
f, args, kwargs = self._q.get()
try:
print 'USE: {}'.format(self.name) # 线程名字
print f(*args, **kwargs)
except Exception as e:
print e
self._q.task_done()
class ThreadPool(object):
def __init__(self, num_t=5):
self._q = Queue(num_t)
# Create Worker Thread
for _ in range(num_t):
Worker(self._q)
def add_task(self, f, *args, **kwargs):
self._q.put((f, args, kwargs))
def wait_complete(self):
self._q.join()
pool = ThreadPool()
for _ in range(8):
wt = random()
pool.add_task(double, wt)
time.sleep(wt)
pool.wait_complete()
执行一下:
USE: Thread-1
1.58762376489
USE: Thread-2
0.0652918738849
USE: Thread-3
0.997407997138
USE: Thread-4
1.69333900685
USE: Thread-5
0.726900613676
USE: Thread-1
1.69110052253
USE: Thread-2
1.89039743989
USE: Thread-3
0.96281118122
线程池会保证同时提供 5 个线程工作,但是我们有 8 个待完成的任务,可以看到线程按顺序被循环利用了
3、同步机制
(1)Semaphore(信号量)
在多线程编程中,为了防止不同的线程同时对一个公用的资源(比如全部变量)进行修改,需要进行同时访问的数量(通常是 1)。信号量同步基于内部计数器,每调用一次 acquire (),计数器减 1;每调用一次 release (),计数器加 1. 当计数器为 0 时,acquire () 调用被阻塞。
import time
from random import random
from threading import Thread, Semaphore
sema = Semaphore(3)
def foo(tid):
with sema:
print '{} acquire sema'.format(tid)
wt = random() * 2
time.sleep(wt)
print '{} release sema'.format(tid)
threads = []
for i in range(5):
t = Thread(target=foo, args=(i,))
threads.append(t)
t.start()
for t in threads:
t.join()
这个例子中,我们限制了同时能访问资源的数量为 3。看一下执行的效果:
❯ python semaphore.py
0 acquire sema
1 acquire sema
2 acquire sema
2 release sema
3 acquire sema
1 release sema
4 acquire sema
0 release sema
3 release sema
4 release sema
(2)Lock(互斥锁)
Lock 也可以叫做互斥锁,其实相当于信号量为 1
我们先看一个不加锁的例子:
import time
from threading import Thread
value = 0
def getlock():
global value
new = value + 1
time.sleep(0.001) # 使用sleep让线程有机会切换
value = new
threads = []
for i in range(100):
t = Thread(target=getlock)
t.start()
threads.append(t)
for t in threads:
t.join()
print value
执行一下:
❯ python nolock.py
16
大写的黑人问号,不加锁的情况下,结果会远远的小于 100
加上互斥锁看看:
import time
from threading import Thread, Lock
value = 0
lock = Lock()
def getlock():
global value
with lock:
new = value + 1
time.sleep(0.001)
value = new
threads = []
for i in range(100):
t = Thread(target=getlock)
t.start()
threads.append(t)
for t in threads:
t.join()
print value
我们对 value 的自增加了锁,就可以保证了结果了:
❯ python lock.py
100
写法还可以是用acquire()和release()
from threading import Thread,Lock
import os,time
def work():
global n
lock.acquire()
temp=n
time.sleep(0.1)
n=temp-1
lock.release()
if __name__ == '__main__':
lock=Lock()
n=100
l=[]
for i in range(100):
p=Thread(target=work)
l.append(p)
p.start()
for p in l:
p.join()
(3)RLock(递归锁)
RLcok类的用法和Lock类一模一样,但它支持嵌套,在多个锁没有释放的时候一般会使用RLcok类。
acquire () 能够不被阻塞的被同一个线程调用多次。但是要注意的是 release () 需要调用与 acquire () 相同的次数才能释放锁。
(4)Condition(条件)
一个线程等待特定条件,而另一个线程发出特定条件满足的信号。最好说明的例子就是「生产者 / 消费者」模型:
import time
import threading
def consumer(cond):
t = threading.currentThread()
with cond:
cond.wait() # wait()方法创建了一个名为waiter的锁,并且设置锁的状态为locked。这个waiter锁用于线程间的通讯
print '{}: Resource is available to consumer'.format(t.name)
def producer(cond):
t = threading.currentThread()
with cond:
print '{}: Making resource available'.format(t.name)
cond.notifyAll() # 释放waiter锁,唤醒消费者
condition = threading.Condition()
c1 = threading.Thread(name='c1', target=consumer, args=(condition,))
c2 = threading.Thread(name='c2', target=consumer, args=(condition,))
p = threading.Thread(name='p', target=producer, args=(condition,))
c1.start()
time.sleep(1)
c2.start()
time.sleep(1)
p.start()
执行一下:
❯ python condition.py
p: Making resource available
c2: Resource is available to consumer
c1: Resource is available to consumer
可以看到生产者发送通知之后,消费者都收到了。
(5)Event(事件)
一个线程发送 / 传递事件,另外的线程等待事件的触发。主要提供以下几个方法:
clear将flag设置为“False”set将flag设置为“True”is_set判断是否设置了flagwait会一直监听flag,如果没有检测到flag就一直处于阻塞状态
事件处理的机制:全局定义了一个“Flag”,当flag值为“False”,那么event.wait()就会阻塞,当flag值为“True”,那么event.wait()便不再阻塞。
我们同样的用「生产者 / 消费者」模型的例子:
import time
import threading
from random import randint
TIMEOUT = 2
def consumer(event, l):
t = threading.currentThread()
while 1:
event_is_set = event.wait(TIMEOUT)
if event_is_set:
try:
integer = l.pop()
print '{} popped from list by {}'.format(integer, t.name)
event.clear() # 重置事件状态
except IndexError: # 为了让刚启动时容错
pass
def producer(event, l):
t = threading.currentThread()
while 1:
integer = randint(10, 100)
l.append(integer)
print '{} appended to list by {}'.format(integer, t.name)
event.set() # 设置事件
time.sleep(1)
event = threading.Event()
l = []
threads = []
for name in ('consumer1', 'consumer2'):
t = threading.Thread(name=name, target=consumer, args=(event, l))
t.start()
threads.append(t)
p = threading.Thread(name='producer1', target=producer, args=(event, l))
p.start()
threads.append(p)
for t in threads:
t.join()
执行的效果是这样的:
77 appended to list by producer1
77 popped from list by consumer1
46 appended to list by producer1以上是关于一文搞明白Python多线程编程:threading库的主要内容,如果未能解决你的问题,请参考以下文章