答读者问:Kafka顺序消费吞吐量下降该如何优化?
Posted 中间件兴趣圈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了答读者问:Kafka顺序消费吞吐量下降该如何优化?相关的知识,希望对你有一定的参考价值。
大家好,我是威哥,《RocketMQ技术内幕》一书作者,荣获RocketMQ官方社区优秀布道师、CSDN2020博客执之星Top2等荣誉称号。目前担任中通快递技术平台部资深架构师,主要负责全链路压测、消息中间件、数据同步等产品的研发与落地,拥有千亿级消息集群的运维经验,不仅实践经验丰富,而且对其源代码有深入且系统的研究。欢迎大家关注我,一起抱团发展。
一个粉丝朋友在公众号文章中留言:威哥,Kafka顺序消费时遇到瓶颈时该如何处理?
本文将从如下三个维度展开:
- Kafka主流的顺序消费模型
- 顺序消费模型的弊端
- kafka顺序消费模型改进
1、Kafka顺序消费模型
在探究Kafka顺序消费模型时,首先我们再来回顾一下Kafka消费端端消息拉取机制,只有真正理解其消息拉取线程模型,才能构建最优的线程模型。
1.1 Kafka消息拉取模型
kafka消费端的线程拉取模型如下图所示:
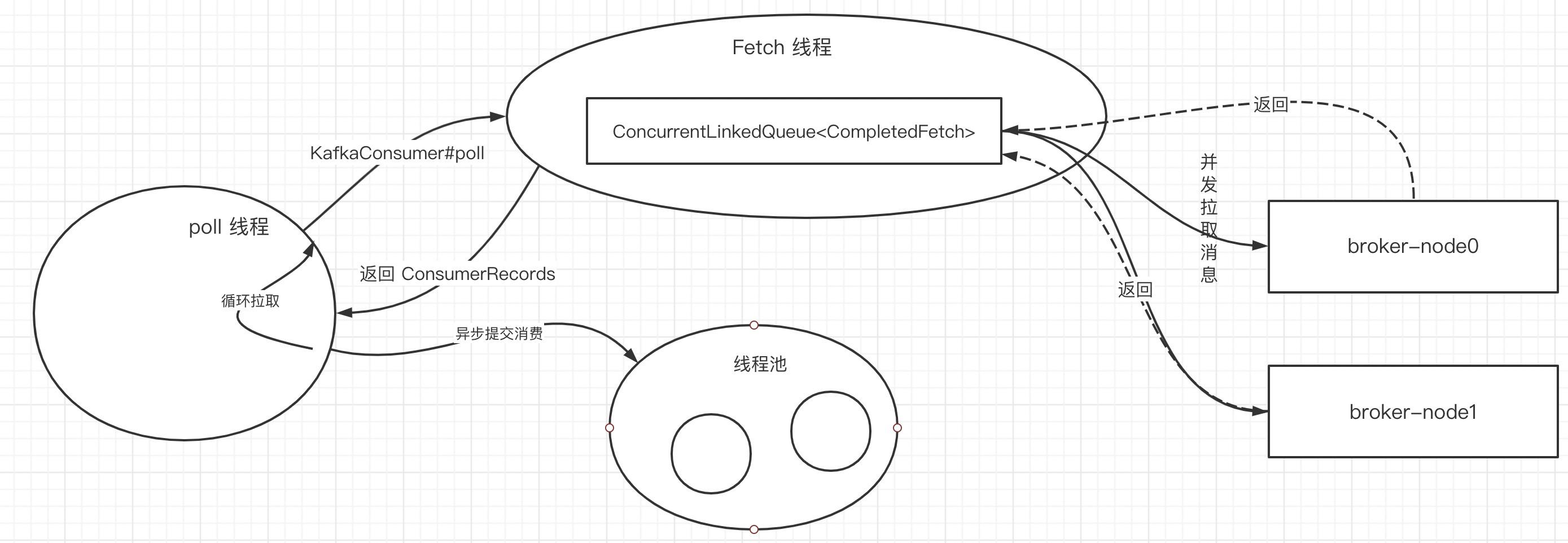
图画的比较简单,但里面蕴含的精髓不能不讲清楚,涉及到几个核心线程如下:
- poll 线程
该线程内部会持有一个KafkaConsumer对象,会循环调用KafkaConsumer的poll方法,尝试获取消息,然后提交到消费线程池中并发消费。 - fetch 线程
kafka实践的消息拉取线程,会并发异步向broker拉取消息,然后放入到结果集合中,KafkaConsumer会从该集合拉取消息。 - 消息消费线程池
为了提高消费端性能,poll线程可以不等待该批消息处理完成后继续向broker拉取消息,从而实现消息消费与消息拉取的并发执行。
Kafka Fetch端引入了限流机制:在向broker发送Fetch拉取请求之前,如果存在未处理的fetch请求或者completedFetch中存在与该broker中分区相关的消息,则本次fetch请求会忽略。
KafkaConsumer的poll方法,指的是从ConcurrentLinkedQueue< CompletedFetch>中拉取消息,每一次默认拉取500条,其拉取逻辑是遍历该集合,一个分区一个分区取消息,直到拉满500条或没有消息可拉为止,那KafkaConsumer方法返回的消息可能包含多个分区,也可能只包含一个分区的消息。
1.2 Kafka顺序消费模型
在理解了kafka的消息拉取模型后,我们来看看如何实现顺序消费,在当下主流的消息中间件的架构设计都是订阅与发布模式,一个主题下有多个分区,各个分区中的消息比较独立,既然没联系,很难有一种高效的方法来判断不同分区的顺序,故目前主流的消息中间件的顺序消费都是基于分区维度的,即可以保证一个分区中的消息顺序消费。
基于分区的顺序消费,RocketMQ的官方实现是在消息消费时对分区进行加锁,而Kafka只是提供了基本的API,整个消息端的实现需要用户基于现有的API进行“搭积木”。
接下来将提供整套代码,来阐述一个Kafka顺序消费的实现模型。
代码获取方式:私信回复KC01,即可获得。
1.2.1 类图
本次实现的代码,其类图如下:
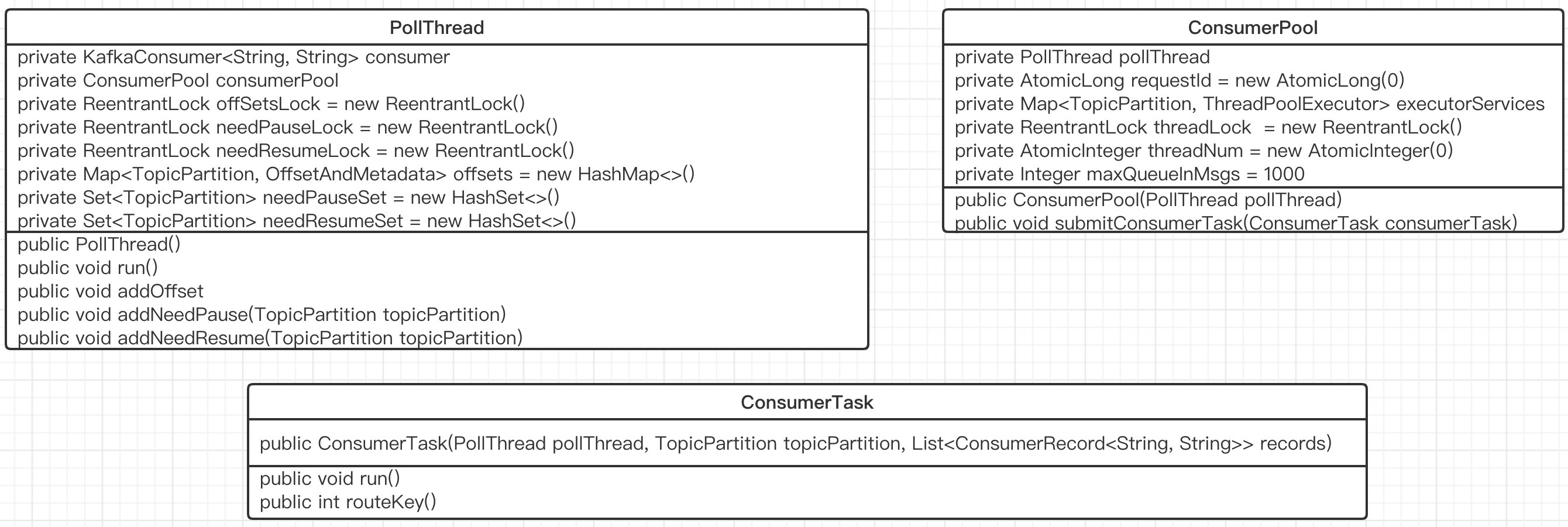
对上面相关的类的职责进行一个简单的说明:
- PollThread
即上图中 poll 线程,内部持有 KafkaConsumer,驱动整个消费流程。 - ConsumePool
消费线程池,用于解耦合消息消费与消息拉取 - ConsumeTask
具体的消费任务。
1.2.2 核心流程解读与设计理念
PollThread的核心流程如下图所示:
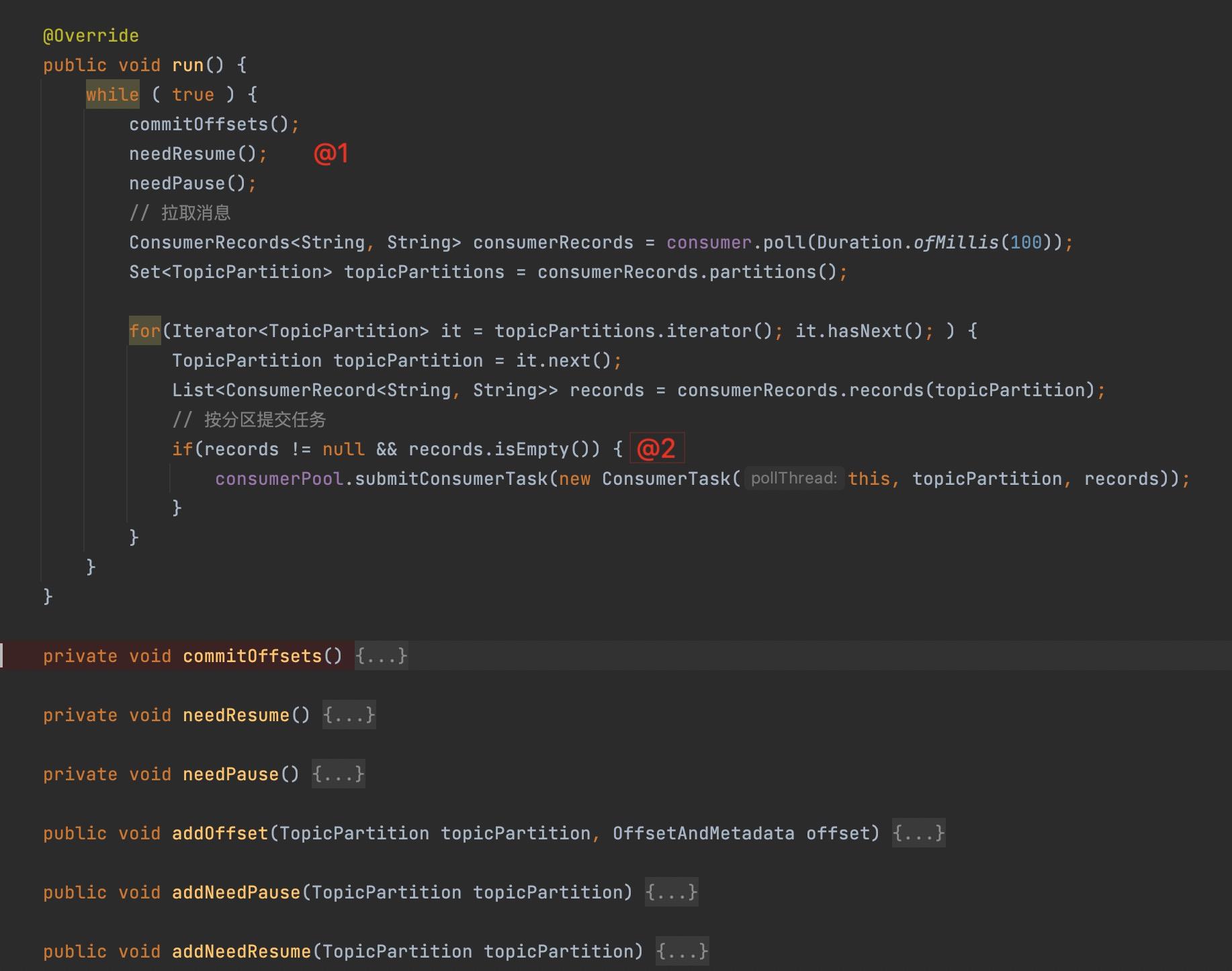
Step1:提交位点、恢复相关分区的拉取、暂停部分分区的消息拉取。
设计理念:poll 线程会持续向broker拉取消息,并且是异步将消息投递到线程池,那如果消费缓慢,消息将积压在消费端线程中,会造成消息的持续膨胀,最终会触发内存溢出,为了防止消费缓慢导致的内存溢出,故需要引入限流机制,具体做法如下:
- 以分区为维度,如果积压超过阔值,则先暂停有积压的分区的消息拉取。
Step2:按分区为维度,提交给消费线程池,其具体实现见ConsumePool。
接下来我们来看一下ConsumePool的核心实现。
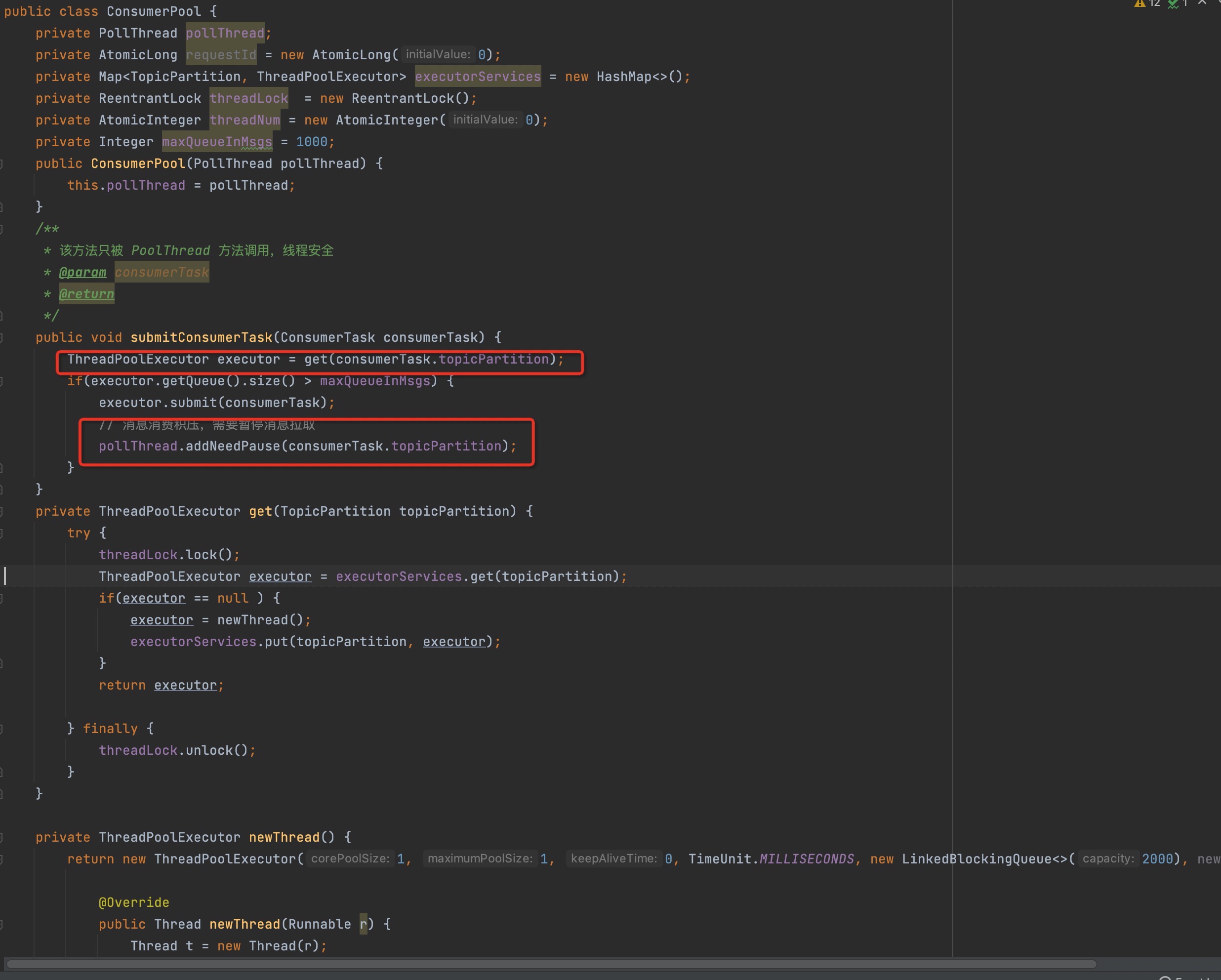
核心关键点如下:
-
在任务提交时,按照分区为维度,为分配到的分区创建一个独立的线程,注意:同一个分区的所有消息都会提交给同一个线程处理。**这也正是顺序消费的核心要点,当然还有一种主流方式是对分区加锁。
由于本例主要是Demo级别,故这里没有添加消费队列重平衡相关的处理逻辑,其实无非就是关闭不需要的线程池,及时释放资源。
-
在提交任务时,如果线程池中积压的消息数量已经超过预定的阔值,将先暂停该分区的消息拉取。
温馨提示:由于KafkaConsume对象并不是线程安全的,故在这里不能直接调用KafkaConsume的pause方法,而是添加一个任务,由poll线程(PollThread)在每次拉取任务之前先统一执行。
提交到线程后,会执行任务的run方法,即会调用ConsumeTask的run方法,接下来我们重点关注一下:
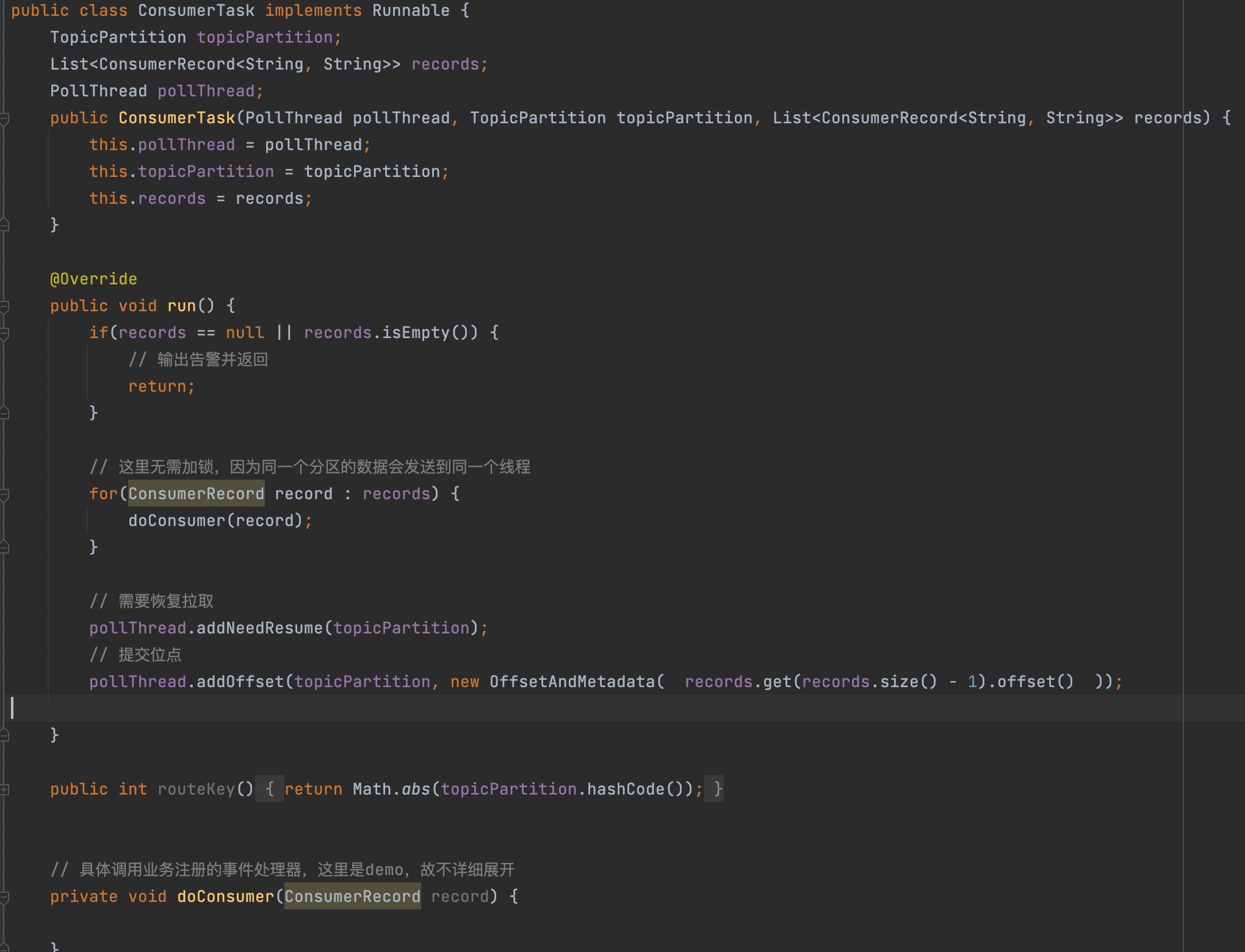
这里主要是消费消息,并提交位点,同样这里不能直接调用kafkaConsumer的提交位点方法,而是需要由Poll线程来执行。
代码获取方式:私信回复KC01,即可获得。
1.2.3 顺序消费线程设计要点
上述实现的线程模型总结提炼如下图所示:
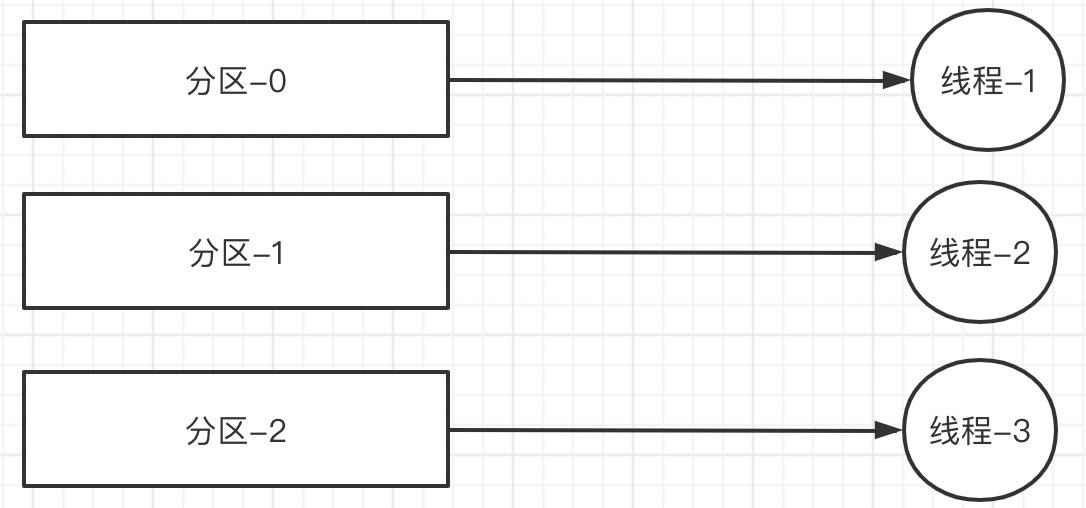
这样可以保证分区中的消息按严格顺序执行。
1.2.4 顺序消费的痛点
顺序消费目前实现的是基于分区的顺序消费,但由于并发度不高的原因,导致顺序消费消费的吞吐率往往无法满足实际应用的需求,那该如何优化?
并发消费性能优化的一个核心思想:降低锁的粒度,顺序消费真有必要按照分区维度来进行锁定?
首先我们结合一个实际的应用场景来阐述:银行账号消费余额变更短信通知。

例如先后由两个账号的余额发生变更,在一个分区中依次写入了3条消息,其中账号ac_01在09:10:01,09:10:03各写入一条消息,账户ac_02在09:10:02写入一条消息。
按照上述的顺序消费,会严格按照上述的顺序执行,但我们回到业务的视角,同一个账户的余额变更必须按照严格的发生顺序,但不同账户中的余额变更则无需强制一致,即上图中账户ac_01的处理早于ac_02对业务并没有任何影响,即在绝大部分业务场景中,所谓的顺序性并不是单纯的时间发生,而是只需要同一个账户的事件保持顺序性即可。
1.2.5 顺序消费模型优化
故基于此提出线更优的线程优化模型:
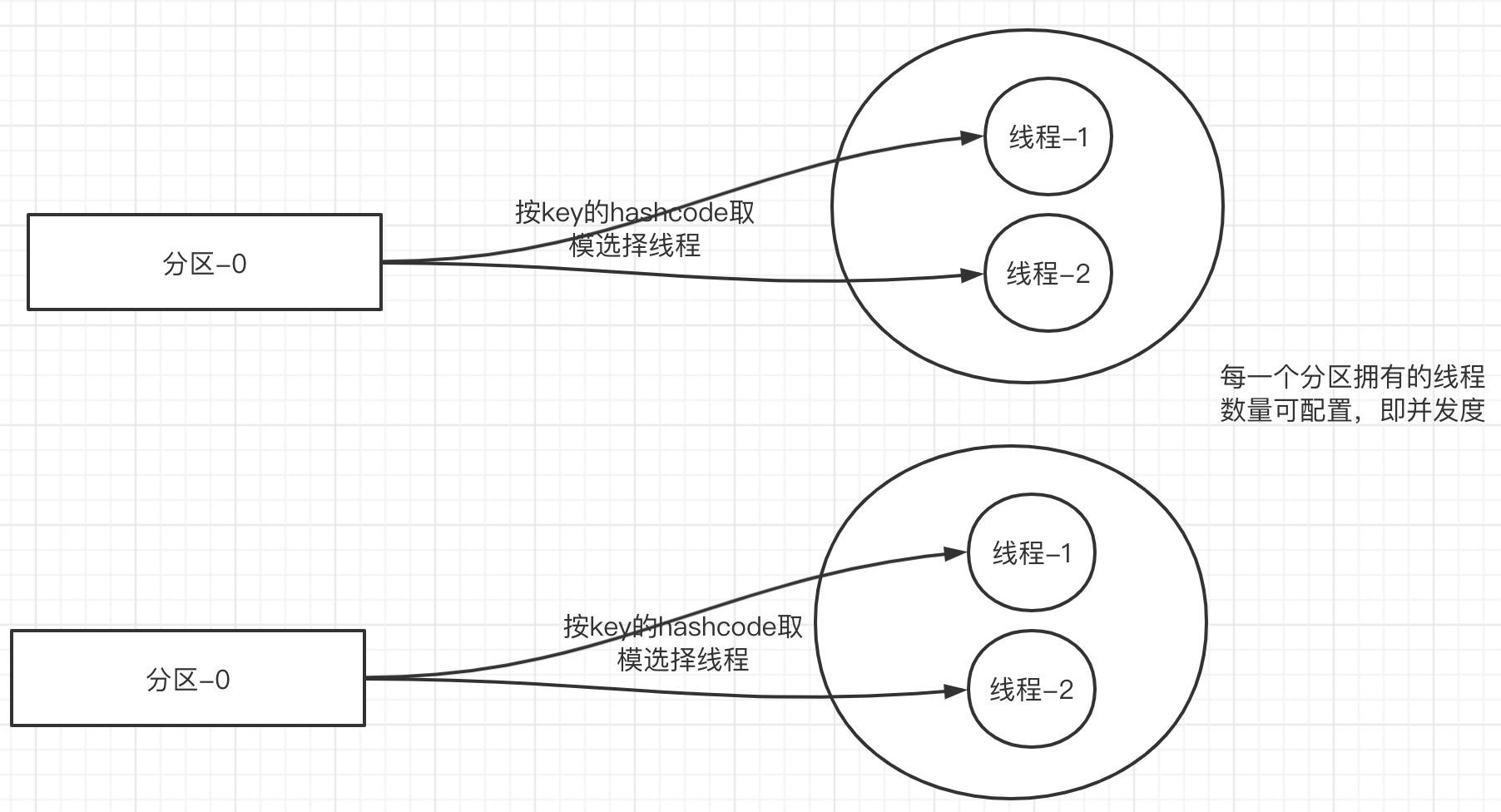
这样就提高了分区的并发度,性能将得到极大的提升。
温馨提示:优化后的代码就不再给出,只需要修改获取线程的逻辑,这里呼吁读者朋友们基于笔者提供的代码自行实现,方便更加深入理解其理念。
好了,本文就介绍到这里了,一键三连(关注、点赞、留言)是对我最大的鼓励。
掌握一到两门java主流中间件,是敲开BAT等大厂必备的技能,送给大家一个Java中间件学习路线,助力大家早日进入互联网大厂。
最后分享笔者一个硬核的RocketMQ电子书,您将获得千亿级消息流转的运维经验。
获取方式:RocketMQ电子书。
以上是关于答读者问:Kafka顺序消费吞吐量下降该如何优化?的主要内容,如果未能解决你的问题,请参考以下文章
Kafka 消费者之消费方式工作流程消费者案例(订阅主题订阅分区)消费者组案例分区的分配以及再平衡offset 位移消费者事务数据积压(消费者如何提高吞吐量)