Kafka如何保证百万级写入速度 并 保证不丢失不重复消费
Posted 华阳JAVA1980
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka如何保证百万级写入速度 并 保证不丢失不重复消费相关的知识,希望对你有一定的参考价值。
一、如何保证百万级写入速度:
目录
1、页缓存技术 + 磁盘顺序写
2、零拷贝技术
3、最后的总结
“这篇文章来聊一下Kafka的一些架构设计原理,这也是互联网公司面试时非常高频的技术考点。
Kafka是高吞吐低延迟的高并发、高性能的消息中间件,在大数据领域有极为广泛的运用。配置良好的Kafka集群甚至可以做到每秒几十万、上百万的超高并发写入。
那么Kafka到底是如何做到这么高的吞吐量和性能的呢?这篇文章我们来一点一点说一下。
1、页缓存技术 + 磁盘顺序写
首先Kafka每次接收到数据都会往磁盘上去写,如下图所示。
那么在这里我们不禁有一个疑问了,如果把数据基于磁盘来存储,频繁的往磁盘文件里写数据,这个性能会不会很差?大家肯定都觉得磁盘写性能是极差的。
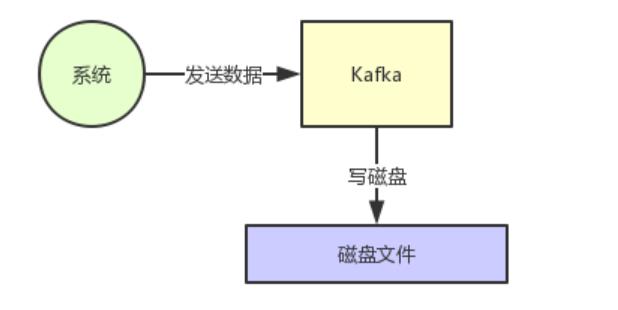
没错,要是真的跟上面那个图那么简单的话,那确实这个性能是比较差的。
但是实际上Kafka在这里有极为优秀和出色的设计,就是为了保证数据写入性能,首先Kafka是基于操作系统的页缓存来实现文件写入的。
操作系统本身有一层缓存,叫做page cache,是在内存里的缓存,我们也可以称之为os cache,意思就是操作系统自己管理的缓存。
你在写入磁盘文件的时候,可以直接写入这个os cache里,也就是仅仅写入内存中,接下来由操作系统自己决定什么时候把os cache里的数据真的刷入磁盘文件中。
仅仅这一个步骤,就可以将磁盘文件写性能提升很多了,因为其实这里相当于是在写内存,不是在写磁盘,大家看下图。

接着另外一个就是kafka写数据的时候,非常关键的一点,他是以磁盘顺序写的方式来写的。也就是说,仅仅将数据追加到文件的末尾,不是在文件的随机位置来修改数据。
普通的机械磁盘如果你要是随机写的话,确实性能极差,也就是随便找到文件的某个位置来写数据。
但是如果你是追加文件末尾按照顺序的方式来写数据的话,那么这种磁盘顺序写的性能基本上可以跟写内存的性能本身也是差不多的。
所以大家就知道了,上面那个图里,Kafka在写数据的时候,一方面基于了os层面的page cache来写数据,所以性能很高,本质就是在写内存罢了。
另外一个,他是采用磁盘顺序写的方式,所以即使数据刷入磁盘的时候,性能也是极高的,也跟写内存是差不多的。
基于上面两点,kafka就实现了写入数据的超高性能。
那么大家想想,假如说kafka写入一条数据要耗费1毫秒的时间,那么是不是每秒就是可以写入1000条数据?
但是假如kafka的性能极高,写入一条数据仅仅耗费0.01毫秒呢?那么每秒是不是就可以写入10万条数?
所以要保证每秒写入几万甚至几十万条数据的核心点,就是尽最大可能提升每条数据写入的性能,这样就可以在单位时间内写入更多的数据量,提升吞吐量。
2、零拷贝技术
说完了写入这块,再来谈谈消费这块。
大家应该都知道,从Kafka里我们经常要消费数据,那么消费的时候实际上就是要从kafka的磁盘文件里读取某条数据然后发送给下游的消费者,如下图所示。
那么这里如果频繁的从磁盘读数据然后发给消费者,性能瓶颈在哪里呢

假设要是kafka什么优化都不做,就是很简单的从磁盘读数据发送给下游的消费者,那么大概过程如下所示:
先看看要读的数据在不在os cache里,如果不在的话就从磁盘文件里读取数据后放入os cache。
接着从操作系统的os cache里拷贝数据到应用程序进程的缓存里,再从应用程序进程的缓存里拷贝数据到操作系统层面的Socket缓存里,最后从Socket缓存里提取数据后发送到网卡,最后发送出去给下游消费。
整个过程,如下图所示:

大家看上图,很明显可以看到有两次没必要的拷贝吧!
一次是从操作系统的cache里拷贝到应用进程的缓存里,接着又从应用程序缓存里拷贝回操作系统的Socket缓存里。
而且为了进行这两次拷贝,中间还发生了好几次上下文切换,一会儿是应用程序在执行,一会儿上下文切换到操作系统来执行。
所以这种方式来读取数据是比较消耗性能的。
Kafka为了解决这个问题,在读数据的时候是引入零拷贝技术。
也就是说,直接让操作系统的cache中的数据发送到网卡后传输给下游的消费者,中间跳过了两次拷贝数据的步骤,Socket缓存中仅仅会拷贝一个描述符过去,不会拷贝数据到Socket缓存。
大家看下图,体会一下这个精妙的过程:
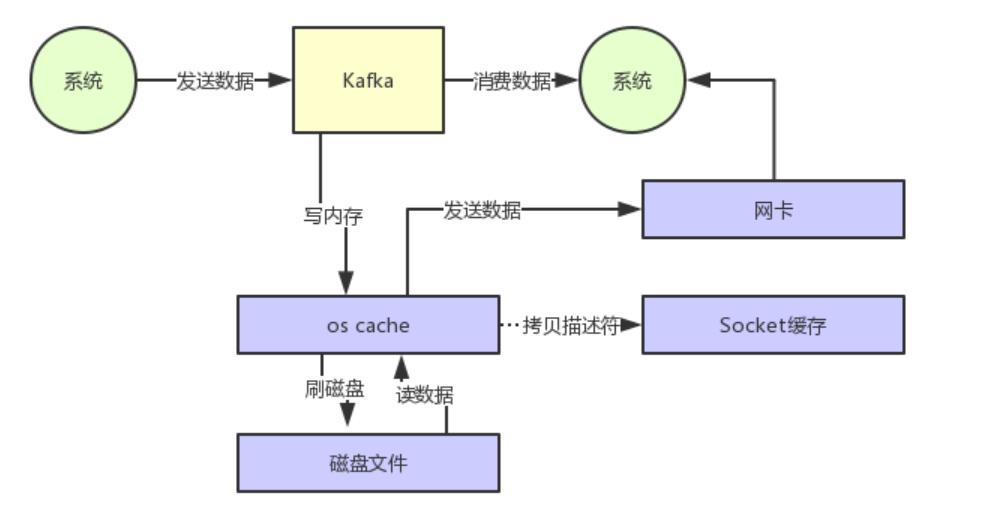
通过零拷贝技术,就不需要把os cache里的数据拷贝到应用缓存,再从应用缓存拷贝到Socket缓存了,两次拷贝都省略了,所以叫做零拷贝。
对Socket缓存仅仅就是拷贝数据的描述符过去,然后数据就直接从os cache中发送到网卡上去了,这个过程大大的提升了数据消费时读取文件数据的性能。
而且大家会注意到,在从磁盘读数据的时候,会先看看os cache内存中是否有,如果有的话,其实读数据都是直接读内存的。
如果kafka集群经过良好的调优,大家会发现大量的数据都是直接写入os cache中,然后读数据的时候也是从os cache中读。
相当于是Kafka完全基于内存提供数据的写和读了,所以这个整体性能会极其的高。
说个题外话,下回有机会给大家说一下Elasticsearch的架构原理,其实ES底层也是大量基于os cache实现了海量数据的高性能检索的,跟Kafka原理类似。
3、最后的总结
通过这篇文章对kafka底层的页缓存技术的使用,磁盘顺序写的思路,以及零拷贝技术的运用,大家应该就明白Kafka每台机器在底层对数据进行写和读的时候采取的是什么样的思路,为什么他的性能可以那么高,做到每秒几十万的吞吐量。
这种设计思想对我们平时自己设计中间件的架构。
Kafka如何做到不丢失不重复消费
有很多公司因为业务要求必须保证消息不丢失、不重复的到达,比如无人机实时监控系统,当无人机闯入机场区域,我们必须立刻报警,不允许消息丢失。
而无人机离开禁飞区域后我们需要将及时报警解除。如果消息重复了呢,我们是否需要复杂的逻辑来自己处理消息重复的情况呢,这种情况恐怕相当复杂而难以处理。但是如果我们能保证消息exactly once,那么一切都容易得多。
下面我们来简单了解一下消息传递语义,以及kafka的消息传递机制。
首先我们要了解的是message delivery semantic 也就是消息传递语义。
这是一个通用的概念,也就是消息传递过程中消息传递的保证性。
分为三种:
最多一次(at most once): 消息可能丢失也可能被处理,但最多只会被处理一次。
可能丢失 不会重复
至少一次(at least once): 消息不会丢失,但可能被处理多次。
可能重复 不会丢失
精确传递一次(exactly once): 消息被处理且只会被处理一次。
不丢失 不重复 就一次
而kafka其实有两次消息传递,一次生产者发送消息给kafka,一次消费者去kafka消费消息。
两次传递都会影响最终结果,
两次都是精确一次,最终结果才是精确一次。
两次中有一次会丢失消息,或者有一次会重复,那么最终的结果就是可能丢失或者重复的。
一、Produce端消息传递
这是producer端的代码:
Properties properties = new Properties();
properties.put("bootstrap.servers", "kafka01:9092,kafka02:9092");
properties.put("acks", "all");
properties.put("retries", 0);
properties.put("batch.size", 16384);
properties.put("linger.ms", 1);
properties.put("buffer.memory", 33554432);
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);
for (int i = 1; i <= 600; i++) {
kafkaProducer.send(new ProducerRecord<String, String>("z_test_20190430", "testkafka0613"+i));
System.out.println("testkafka"+i);
}
kafkaProducer.close();
其中指定了一个参数acks 可以有三个值选择:
0: producer完全不管broker的处理结果 回调也就没有用了 并不能保证消息成功发送 但是这种吞吐量最高
-1或者all: leader broker会等消息写入 并且ISR都写入后 才会响应,这种只要ISR有副本存活就肯定不会丢失,但吞吐量最低。
1: 默认的值 leader broker自己写入后就响应,不会等待ISR其他的副本写入,只要leader broker存活就不会丢失,即保证了不丢失,也保证了吞吐量。
所以设置为0时,实现了at most once,而且从这边看只要保证集群稳定的情况下,不设置为0,消息不会丢失。
但是还有一种情况就是消息成功写入,而这个时候由于网络问题producer没有收到写入成功的响应,producer就会开启重试的操作,直到网络恢复,消息就发送了多次。这就是at least once了。
kafka producer 的参数acks 的默认值为1,所以默认的producer级别是at least once。并不能exactly once。
Consumer端消息传递
consumer是靠offset保证消息传递的。
consumer消费的代码如下:
Properties props = new Properties();
props.put("bootstrap.servers", "kafka01:9092,kafka02:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("auto.offset.reset","earliest");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("foo", "bar"));
try{
while (true) {
ConsumerRecords<String, String> records = consumer.poll(1000);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
}finally{
consumer.close();
}
其中有一个参数是 enable.auto.commit
若设置为true consumer在消费之前提交位移 就实现了at most once
若是消费后提交 就实现了 at least once 默认的配置就是这个。
kafka consumer的参数enable.auto.commit的默认值为true ,所以默认的consumer级别是at least once。也并不能exactly once。

三、精确一次
通过了解producer端与consumer端的设置,我们发现kafka在两端的默认配置都是at least once,可能重复,通过配置也不能做到exactly once,好像kafka的消息一定会丢失或者重复的,
是不是没有办法做到exactly once了呢?
确实在kafka 0.11.0.0版本之前producer端确实是不可能的,
但是在kafka 0.11.0.0版本之后,kafka正式推出了idempotent producer。
也就是幂等的producer还有对事务的支持。
幂等的producer
kafka 0.11.0.0版本引入了idempotent producer机制,在这个机制中同一消息可能被producer发送多次,但是在broker端只会写入一次,他为每一条消息编号去重,而且对kafka开销影响不大。
如何设置开启呢? 需要设置producer端的新参数 enable.idempotent 为true。
而多分区的情况,我们需要保证原子性的写入多个分区,即写入到多个分区的消息要么全部成功,要么全部回滚。
这时候就需要使用事务,在producer端设置 transcational.id为一个指定字符串。
这样幂等producer只能保证单分区上无重复消息;事务可以保证多分区写入消息的完整性。
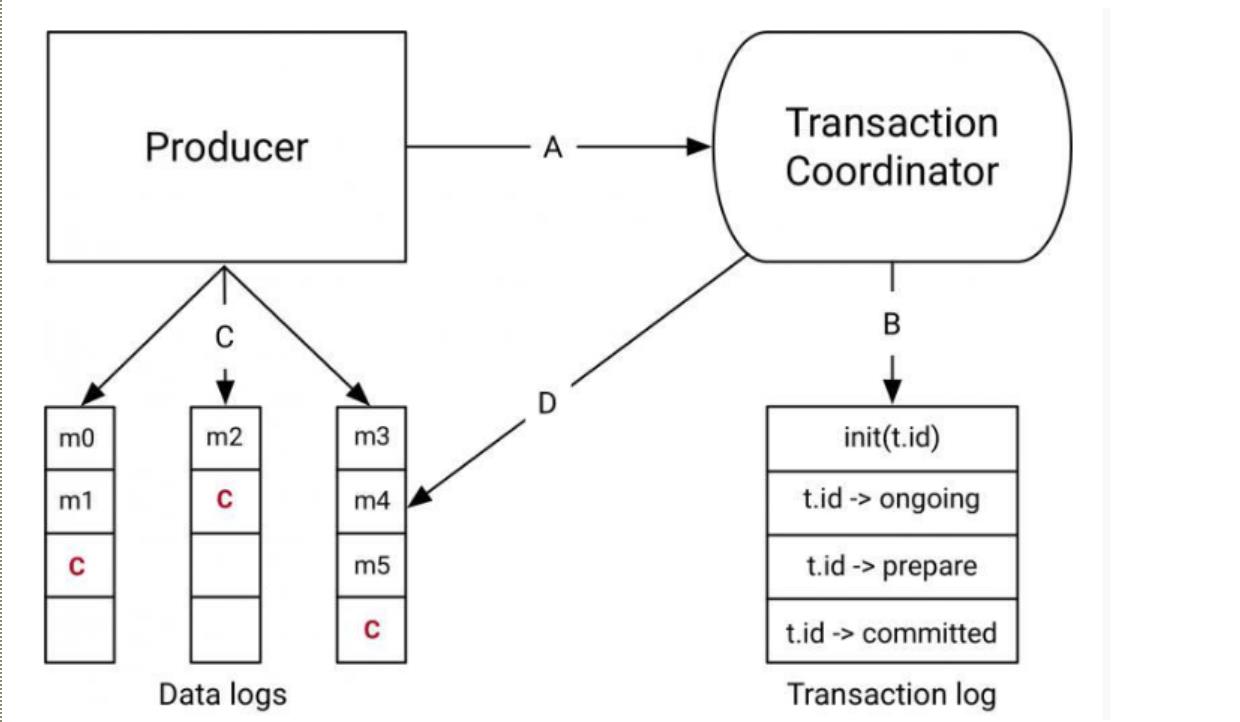
这样producer端实现了exactly once,那么consumer端呢?
consumer端由于可能无法消费事务中所有消息,并且消息可能被删除,所以事务并不能解决consumer端exactly once的问题,我们可能还是需要自己处理这方面的逻辑。比如自己管理offset的提交,不要自动提交,也是可以实现exactly once的。
还有一个选择就是使用kafka自己的流处理引擎,也就是Kafka Streams,
设置processing.guarantee=exactly_once,就可以轻松实现exactly once了。
以上是关于Kafka如何保证百万级写入速度 并 保证不丢失不重复消费的主要内容,如果未能解决你的问题,请参考以下文章