中通消息平台 Kafka 顺序消费线程模型的实践与优化
Posted phyger
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了中通消息平台 Kafka 顺序消费线程模型的实践与优化相关的知识,希望对你有一定的参考价值。
此文转载自:https://blog.csdn.net/zchdjb/article/details/110427195各类消息中间件对顺序消息实现的做法是将具有顺序性的一类消息发往相同的主题分区中,只需要将这类消息设置相同的 Key 即可,而 Kafka 会在任意时刻保证一个消费组同时只能有一个消费者监听消费,因此可在消费时按分区进行顺序消费,保证每个分区的消息具备局部顺序性。由于需要确保分区消息的顺序性,并不能并发地消费消费,对消费的吞吐量会造成一定的影响。那么,如何在保证消息顺序性的前提下,最大限度的提高消费者的消费能力?
本文将会对 Kafka 消费者拉取消息流程进行深度分析之后,对 Kafka 消费者顺序消费线程模型进行一次实践与优化。
Kafka 消费者拉取消息流程分析
在讲实现 Kafka 顺序消费线程模型之前,我们需要先深入分析 Kafka 消费者的消息拉取机制,只有当你对 Kafka 消费者拉取消息的整个流程有深入的了解之后,你才能够很好地理解本次线程模型改造的方案。
我先给大家模拟一下消息拉取的实际现象,这里 max.poll.records = 500。
1、消息没有堆积时:
可以发现,在消息没有堆积时,消费者拉取时,如果某个分区没有的消息不足 500 条,会从其他分区凑够 500 条后再返回。
2、多个分区都有堆积时:

在消息有堆积时,可以发现每次返回的都是同一个分区的消息,但经过不断 debug,消费者在拉取过程中并不是等某个分区消费完没有堆积了,再拉取下一个分区的消息,而是不断循环的拉取各个分区的消息,但是这个循环并不是说分区 p0 拉取完 500 条,后面一定会拉取分区 p1 的消息,很有可能后面还会拉取 p0 分区的消息,为了弄明白这种现象,我仔细阅读了相关源码。
org.apache.kafka.clients.consumer.KafkaConsumer#poll
private ConsumerRecords<K, V> poll(final Timer timer, final boolean includeMetadataInTimeout) {
try {
// poll for new data until the timeout expires
do {
// 客户端拉取消息核心逻辑
final Map<TopicPartition, List<ConsumerRecord<K, V>>> records = pollForFetches(timer);
if (!records.isEmpty()) {
// 在返回数据之前, 发送下次的 fetch 请求, 避免用户在下次获取数据时线程阻塞
if (fetcher.sendFetches() > 0 || client.hasPendingRequests()) {
// 调用 ConsumerNetworkClient#poll 方法将 FetchRequest 发送出去。
client.pollNoWakeup();
}
return this.interceptors.onConsume(new ConsumerRecords<>(records));
}
} while (timer.notExpired());
return ConsumerRecords.empty();
} finally {
release();
}
}
我们使用 Kafka consumer 进行消费的时候通常会给一个时间,比如:
consumer.poll(Duration.ofMillis(3000));
从以上代码逻辑可以看出来,用户给定的这个时间,目的是为了等待消息凑够 max.poll.records 条消息后再返回,即使消息条数不够 max.poll.records 消息,时间到了用户给定的等待时间后,也会返回。
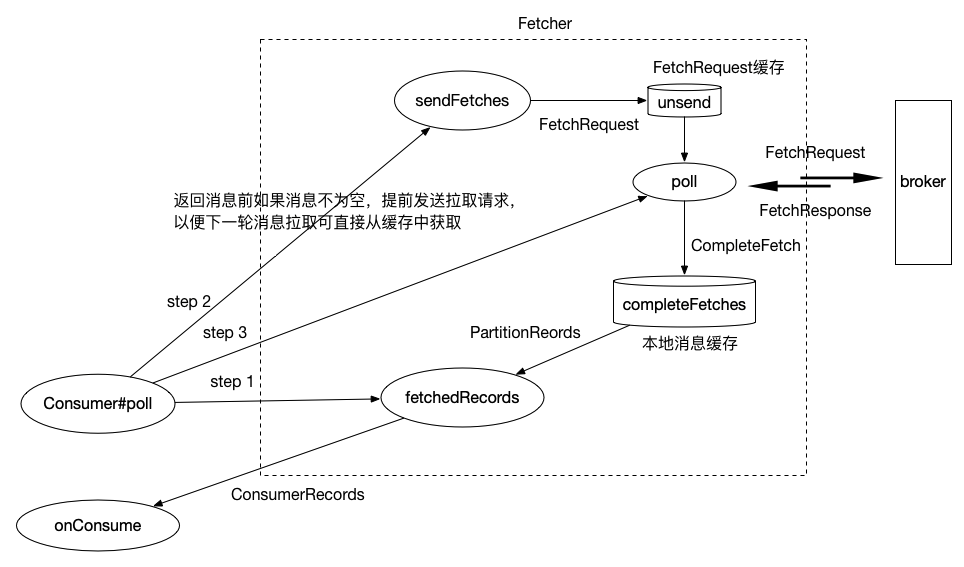
pollForFetches 方法是客户端拉取消息核心逻辑,但并不是真正去 broker 中拉取,而是从缓存中去获取消息。在 pollForFetches 拉取消息后,如果消息不为零,还会调用 fetcher.sendFetches() 与 client.pollNoWakeup(),调用这两个方法究竟有什么用呢?
fetcher.sendFetches() 经过源码阅读后,得知该方法目的是为了构建拉取请求 FetchRequest 并进行发送,但是这里的发送并不是真正的发送,而是将 FetchRequest 请求对象存放在 unsend 缓存当中,然后会在 ConsumerNetworkClient#poll 方法调用时才会被真正地执行发送。
fetcher.sendFetches() 在构建 FetchRequest 前,会对当前可拉取分区进行筛选,而这个也是决定多分区拉取消息规律的核心,后面我会讲到。
从 KafkaConsumer#poll 方法源码可以看出来,其实 Kafka 消费者在拉取消息过程中,有两条线程在工作,其中用户主线程调用 pollForFetches 方法从缓存中获取消息消费,在获取消息后,会再调用 ConsumerNetworkClient#poll 方法从 Broker 发送拉取请求,然后将拉取到的消息缓存到本地,这里为什么在拉取完消息后,会主动调用 ConsumerNetworkClient#poll 方法呢?我想这里的目的是为了下次 poll 的时候可以立即从缓存中拉取消息。
pollForFetches 方法会调用 Fetcher#fetchedRecords 方法从缓存中获取并解析消息:
public Map<TopicPartition, List<ConsumerRecord<K, V>>> fetchedRecords() {
Map<TopicPartition, List<ConsumerRecord<K, V>>> fetched = new HashMap<>();
int recordsRemaining = maxPollRecords;
try {
while (recordsRemaining > 0) {
// 如果当前获取消息的 PartitionRecords 为空,或者已经拉取完毕
// 则需要从 completedFetches 重新获取 completedFetch 并解析成 PartitionRecords
if (nextInLineRecords == null || nextInLineRecords.isFetched) {
// 如果上一个分区缓存中的数据已经拉取完了,直接中断本次循环拉取,并返回空的消息列表
// 直至有缓存数据为止
CompletedFetch completedFetch = completedFetches.peek();
if (completedFetch == null) break;
try {
// CompletedFetch 即拉取消息的本地缓存数据
// 缓存数据中 CompletedFetch 解析成 PartitionRecords
nextInLineRecords = parseCompletedFetch(completedFetch);
} catch (Exception e) {
// ...
}
completedFetches.poll();
} else {
// 从分区缓存中获取指定条数的消息
List<ConsumerRecord<K, V>> records = fetchRecords(nextInLineRecords, recordsRemaining);
// ...
fetched.put(partition, records);
recordsRemaining -= records.size();
}
}
}
} catch (KafkaException e) {
// ...
}
return fetched;
}
completedFetches 是拉取到的消息缓存,以上代码逻辑就是围绕着如何从 completedFetches 缓存中获取消息的,从以上代码逻辑可以看出:
maxPollRecords 为本次拉取的最大消息数量,该值可通过 max.poll.records 参数配置,默认为 500 条,该方法每次从 completedFetches 中取出一个 CompletedFetch 并解析成可以拉取的 PartitionRecords 对象,即方法中的 nextInLineRecords,请注意,PartitionRecords 中的消息数量可能大与 500 条,因此可能本次可能一次性从 PartitionRecords 获取 500 条消息后即返回,如果 PartitionRecords 中消息数量不足 500 条,会从 completedFetches 缓存中取出下一个要拉取的分区消息,recordsRemaining 会记录本次剩余还有多少消息没拉取,通过循环不断地从 completedFetches 缓存中取消息,直至 recordsRemaining 为 0。
以上代码即可解释为什么消息有堆积的情况下,每次拉取的消息很大概率是同一个分区的消息,因为缓存 CompletedFetch 缓存中的消息很大概率会多余每次拉取消息数量,Kafka 客户端每次从 Broker 拉取的消息数据并不是通过 max.poll.records 决定的,该参数仅决定用户每次从本地缓存中获取多少条数据,真正决定从 Broker 拉取的消息数据量是通过 fetch.min.bytes、max.partition.fetch.bytes、fetch.max.bytes 等参数决定的。
我们再想一下,假设某个分区的消息一直都处于堆积状态,Kafka 会每次都拉取这个分区直至将该分区消费完毕吗?(根据假设,Kafka 消费者每次都会从这个分区拉取消息,并将消息存到分区关联的 CompletedFetch 缓存中,根据以上代码逻辑,nextInLineRecords 一直处于还没拉取完的状态,导致每次拉取都会从该分区中拉取消息。)
答案显然不会,不信你打开 Kafka-manager 观察每个分区的消费进度情况,每个分区都会有消费者在消费中。
那 Kafka 消费者是如何循环地拉取它监听的分区呢?我们接着往下分析。
发送拉取请求逻辑:
org.apache.kafka.clients.consumer.internals.Fetcher#sendFetches
public synchronized int sendFetches() {
// 解析本次可拉取的分区
Map<Node, FetchSessionHandler.FetchRequestData> fetchRequestMap = prepareFetchRequests();
for (Map.Entry<Node, FetchSessionHandler.FetchRequestData> entry : fetchRequestMap.entrySet()) {
final Node fetchTarget = entry.getKey();
final FetchSessionHandler.FetchRequestData data = entry.getValue();
// 构建请求对象
final FetchRequest.Builder request = FetchRequest.Builder
.forConsumer(this.maxWaitMs, this.minBytes, data.toSend())
.isolationLevel(isolationLevel)
.setMaxBytes(this.maxBytes)
.metadata(data.metadata())
.toForget(data.toForget());
// 发送请求,但不是真的发送,而是将请求保存在 unsent 中
client.send(fetchTarget, request)
.addListener(new RequestFutureListener<ClientResponse>() {
@Override
public void onSuccess(ClientResponse resp) {
synchronized (Fetcher.this) {
// ... ...
// 创建 CompletedFetch, 并缓存到 completedFetches 队列中
completedFetches.add(new CompletedFetch(partition, fetchOffset, fetchData, metricAggregator,
resp.requestHeader().apiVersion()));
}
}
}
// ... ...
});
}
return fetchRequestMap.size();
}
以上代码逻辑很好理解,在发送拉取请求前,先检查哪些分区可拉取,接着为每个分区构建一个 FetchRequest 对象,FetchRequest 中的 minBytes 和 maxBytes,分别可通过 fetch.min.bytes 和 fetch.max.bytes 参数设置。这也是每次从 Broker 中拉取的消息不一定等于 max.poll.records 的原因。
prepareFetchRequests 方法会调用 Fetcher#fetchablePartitions 筛选可拉取的分区,我们来看下 Kafka 消费者是如何进行筛选的:
org.apache.kafka.clients.consumer.internals.Fetcher#fetchablePartitions
private List<TopicPartition> fetchablePartitions() {
Set<TopicPartition> exclude = new HashSet<>();
List<TopicPartition> fetchable = subscriptions.fetchablePartitions();
if (nextInLineRecords != null && !nextInLineRecords.isFetched) {
exclude.add(nextInLineRecords.partition);
}
for (CompletedFetch completedFetch : completedFetches) {
exclude.add(completedFetch.partition);
}
fetchable.removeAll(exclude);
return fetchable;
}
nextInLineRecords 即我们上面提到的根据某个分区缓存 CompletedFetch 解析得到的,如果 nextInLineRecords 中的缓存还没拉取完,则不从 broker 中拉取消息了,以及如果此时 completedFetches 缓存中存在该分区的缓存,也不进行拉取消息。
我们可以很清楚的得出结论:
当缓存中还存在中还存在某个分区的消息数据时,消费者不会继续对该分区进行拉取请求,直到该分区的本地缓存被消费完,才会继续发送拉取请求。
为了更加清晰的表达这段逻辑,我举个例子并将整个流程用图表达出来:
假设某消费者监听三个分区,每个分区每次从 Broker 中拉取 4 条消息,用户每次从本地缓存中获取 2 条消息:
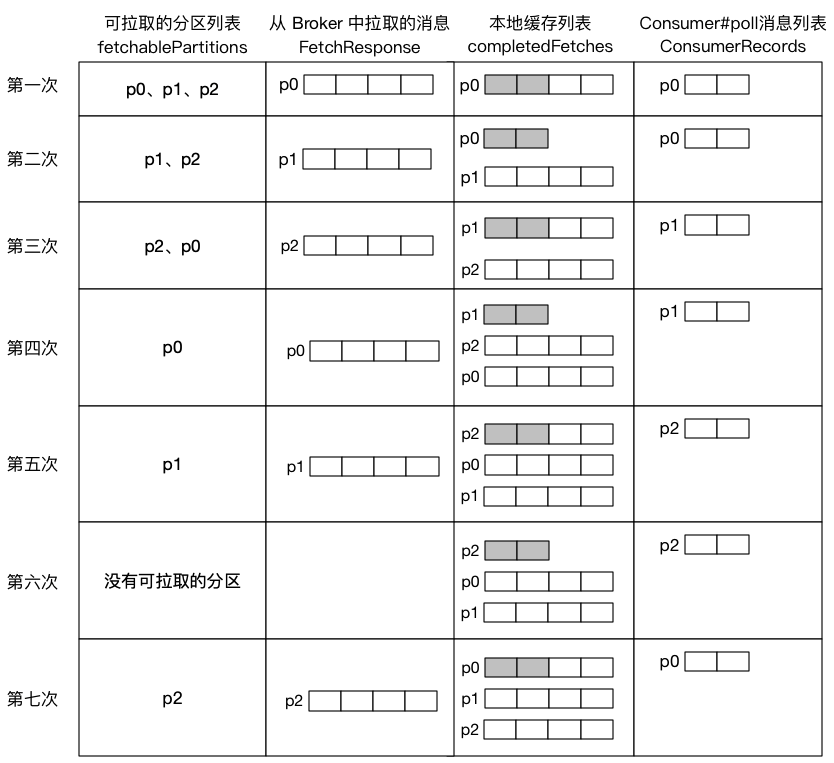
从以上流程可看出,Kafka 消费者自身已经实现了拉取限流的机制。
Kafka 顺序消费线程模型的实现
kafka 的消费类 KafkaConsumer 是非线程安全的,因此用户无法在多线程中共享一个 KafkaConsumer 实例,且 KafkaConsumer 本身并没有实现多线程消费逻辑,如需多线程消费,还需要用户自行实现,在这里我会讲到 Kafka 两种多线程消费模型:
1、每个线程维护一个 KafkaConsumer
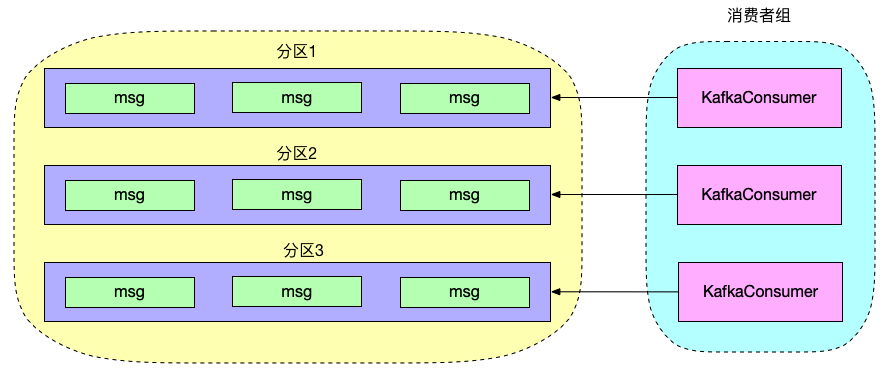
这种消费模型创建多个 KafkaConsumer 对象,每个线程维护一个 KafkaConsumer,从而实现线程隔离消费,由于每个分区同一时刻只能有一个消费者消费,所以这种消费模型天然支持顺序消费。
但是缺点是无法提升单个分区的消费能力,如果一个主题分区数量很多,只能通过增加 KafkaConsumer 实例提高消费能力,这样一来线程数量过多,导致项目 Socket 连接开销巨大,项目中一般不用该线程模型去消费。
2、单 KafkaConsumer 实例 + 多 worker 线程
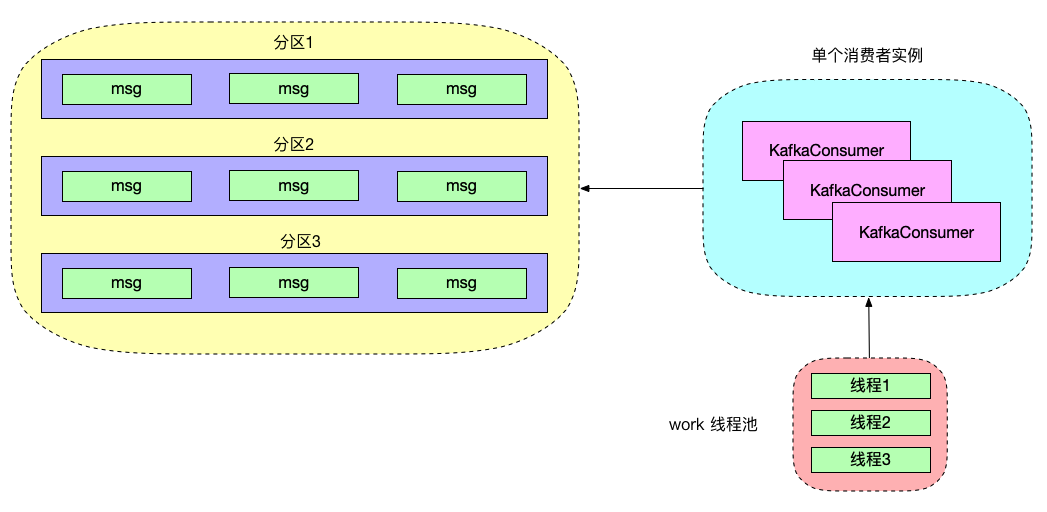
这种消费模型奖 KafkaConsumer 实例与消息消费逻辑解耦,我们不需要创建多个 KafkaConsumer 实例就可进行多线程消费,还可根据消费的负载情况动态调整 worker 线程,具有很强的独立扩展性,在公司内部使用的多线程消费模型就是用的单 KafkaConsumer 实例 + 多 worker 线程模型。但是通常情况下,这种消费模型无法保证消费的顺序性。
那么,如果在使用第二种消费模型的前提下,实现消息顺序消费呢?
接下来我们来看下 ZMS 是怎么实现顺序消费线程模型的,目前 ZMS 的顺序消费线程模型为每个分区单线程消费模式:
com.zto.consumer.KafkaConsumerProxy#addUserDefinedProperties
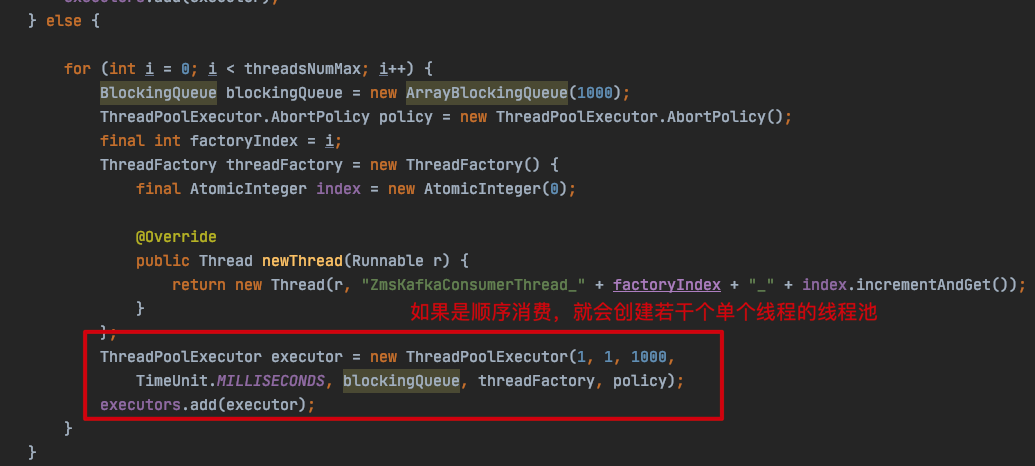
首先在初始化的时候,会对消费线程池进行初始化,具体是根据 threadsNumMax 的数量创建若干个单个线程的线程池,单个线程的线程池就是为了保证每个分区取模后拿到线程池是串行消费的,但这里创建 threadsNumMax 个线程池是不合理的,后面我会说到。
com.zto.consumer.KafkaConsumerProxy#submitRecords
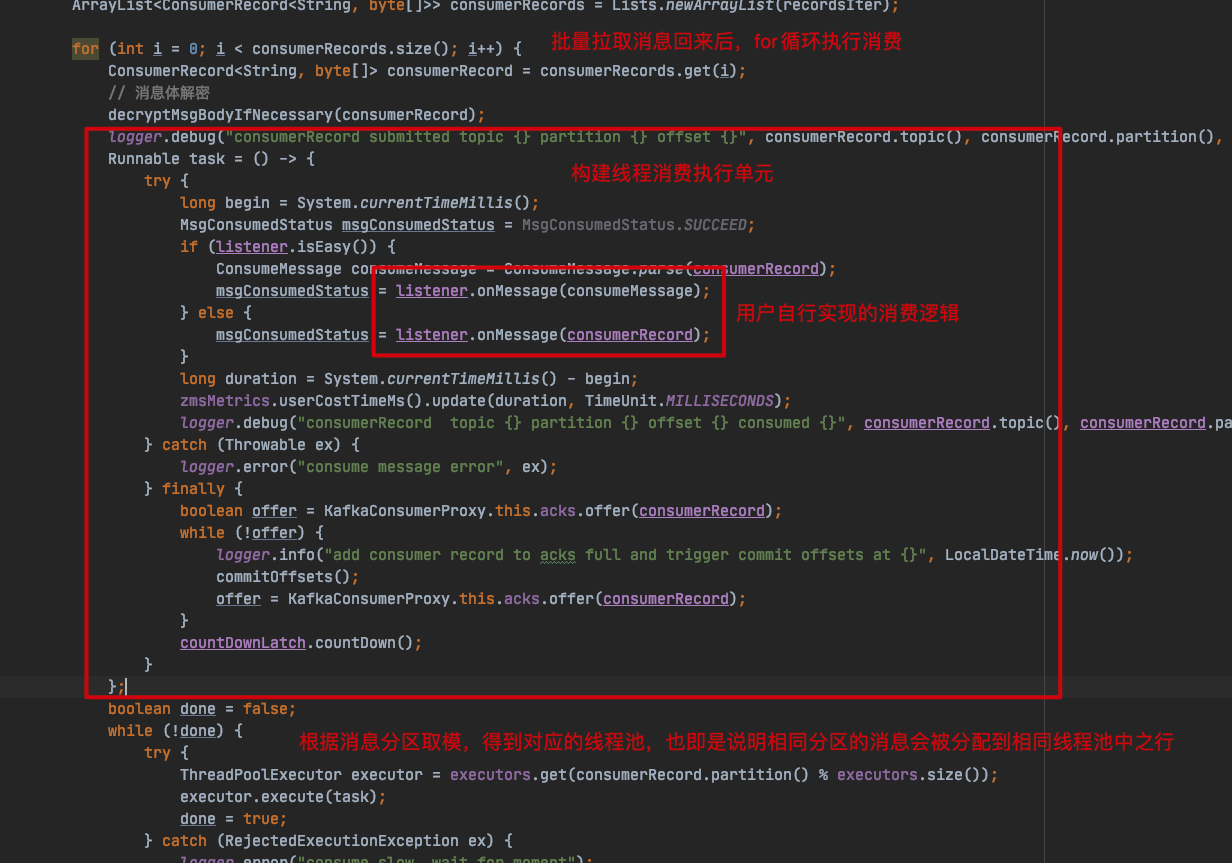
ZMS 会对消息分区进行取模,根据取模后的序号从线程池列表缓存中获取一个线程池,从而使得相同分区的消息会被分配到相同线程池中执行,对于顺序消费来说至关重要,前面我也说了,当用户配置了顺序消费时,每个线程池只会分配一个线程,如果相同分区的消息分配到同一个线程池中执行,也就意味着相同分区的消息会串行执行,实现消息消费的顺序性。
为了保证手动提交位移的正确性,我们必须保证本次拉取的消息消费完之后才会进行位移提交,因此 ZMS 在消费前会创建一个 count 为本次消息数量的 CountDownLatch:
final CountDownLatch countDownLatch = new CountDownLatch(records.count());
消费逻辑中,在 finally 进行 countDown 操作,最后会在本次消费主线程当中阻塞等待本次消息消费完成:
com.zto.consumer.KafkaConsumerProxy#submitRecords
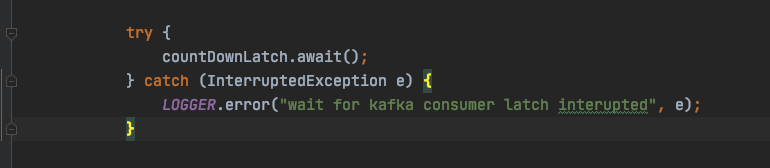
以上就是目前 ZMS 顺序消费的线程模型,用图表示以上代码逻辑:
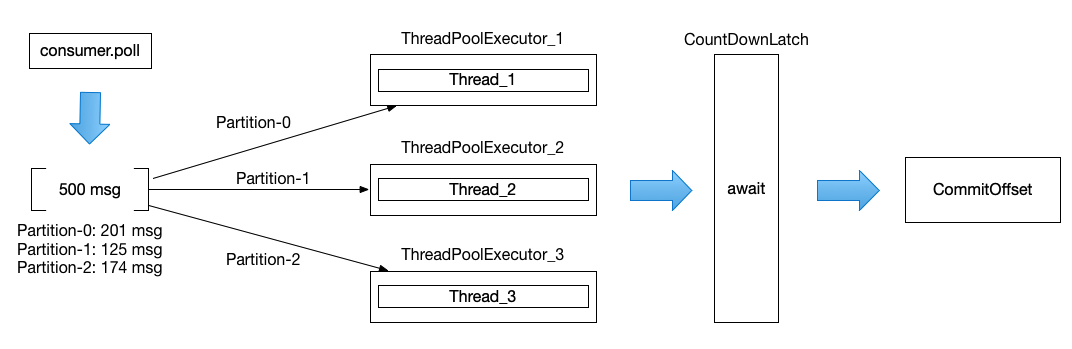
以上,由于某些分区的消息堆积量少于 500 条(Kafka 默认每次从 Broker 拉取 500 条消息),因此会继续从其它分区凑够 500 条消息,此时拉取的 500 条消息会包含 3 个分区的消息,ZMS 根据利用分区取模将同一个分区的消息放到指定的线程池中(线程池只有一条线程)进行消费,以上图来看,总共有 3 条线程在消费本次拉取的 500 条消息。
那如果每个分区的积压都超过了 500 条消息呢?这种实际的情况会更加多,因为消息中间件其中一个重要功能就是用于流量削峰,流量洪峰那段时间积压几百上千万条消息还是经常能够遇到的,那么此时每次拉取的消息中,很大概率就只剩下一个分区了,我用如下图表示:
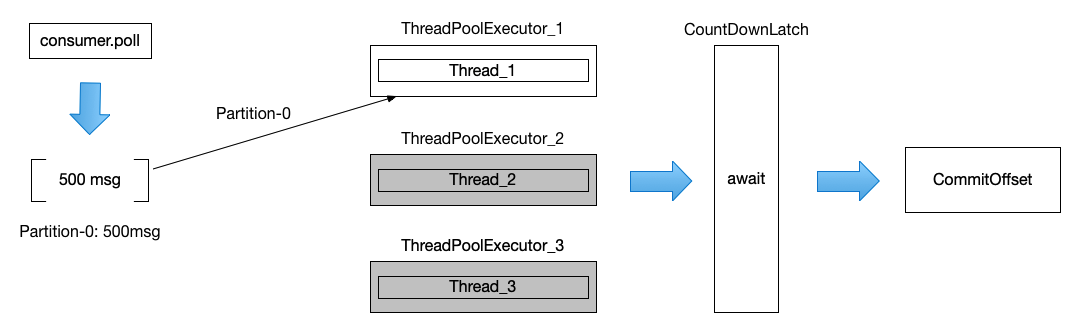
在消息流量大的时候,顺序消息消费时却退化成单线程消费了。
如何提高 Kafka 顺序消费的并发度?
经过对 ZMS 的消费线程模型以及对 Kafka 消费者拉取消息流程的深入了解之后,我想到了如下几个方面对 ZMS 的消费线程模型进行优化:
1、细化消息顺序粒度
之前的做法是将每个分区单独一条线程消费,无法再继续在分区之上增加消费能力,我们知道业务方发送顺序消息时,会将同一类型具有顺序性的消息给一个相同的 Key,以保证这类消息发送到同一个分区进行消费,从而达到消息顺序消费的目的,而同一个分区会接收多种类型(即不同 Key)的消息,每次拉取的消息具有很大可能是不同类型的,那么我们就可以将同一个分区的消息,分配一个独立的线程池,再利用消息 Key 进行取模放入对应的线程中消费,达到并发消费的目的,且不打乱消息的顺序性。
2、细化位移提交粒度
由于 ZMS 目前是手动提交位移,目前每次拉取消息必须先消费完才能进行位移提交,既然已经对分区消息进行指定的线程池消费了,由于分区之间的位移先后提交不影响,那么我们可以将位移提交交给每个分区进行管理,这样拉取主线程不必等到是否消费完才进行下一轮的消息拉取。
3、异步拉取与限流
异步拉取有个问题,就是如果节点消费跟不上,而拉取消息过多地保存在本地,很可能会造成内存溢出,因此我们需要对消息拉取进行限流,当本地消息缓存量达到一定量时,阻止消息拉取。
上面在分析 Kafka 消费者拉取消息流程时,我们知道消费者在发送拉取请求时,首先会判断本地缓存中是否存在该分区的缓存,如果存在,则不发送拉取请求,但由于 ZMS 需要改造成异步拉取的形式,由于 Comsumer#poll 不再等待消息消费完再进行下一轮拉取,因此 Kafka 的本地缓存中几乎不会存在数据了,导致 Kafka 每次都会发送拉取请求,相当于将 Kafka 的本地缓存放到 ZMS 中,因此我们需要 ZMS 层面上对消息拉取进行限流,Kafka 消费者有两个方法可以设置订阅的分区是否可以发送拉取请求:
// 暂停分区消费(即暂停该分区发送拉取消息请求)
org.apache.kafka.clients.consumer.KafkaConsumer#pause
// 恢复分区消费(即恢复该分区发送拉取消息请求)
org.apache.kafka.clients.consumer.KafkaConsumer#resume
以上两个方法,其实就是改变了消费者的订阅分区的状态值 paused,当 paused = true 时,暂停分区消费,当 paused = false 时,恢复分区消费,这个参数是在哪里使用到呢?上面在分析 Kafka 消费者拉取消息流程时我们有提到发送拉取请求之前,会对可拉取的分区进行筛选,其中一个条件即分区 paused = false:
org.apache.kafka.clients.consumer.internals.SubscriptionState.TopicPartitionState#isFetchable
private boolean isFetchable() {
return !paused && hasValidPosition();
}
由于 KafkaConsumer 是非线程安全的,如果我们在异步线程 KafkaConsumer 相关的类,会报如下错误:
KafkaConsumer is not safe for multi-threaded access
只需要确保 KafkaConsumer 相关方法在 KafkaConsumer#poll 方法线程中调用即可,具体做法可以设置一个线程安全上下文容器,异步线程操作 KafkaConsumer 相关方法是,只需要将具体的分区放到上下文容器即可,后续统一由 poll 线程执行。
因此我们只需要利用好这个特性,就可以实现拉取限流,消费者主线程的 Comsumer#poll 方法依然是异步不断地从缓存中获取消息,同时不会造成两次 poll 之间的时间过大导致消费者被踢出消费组。
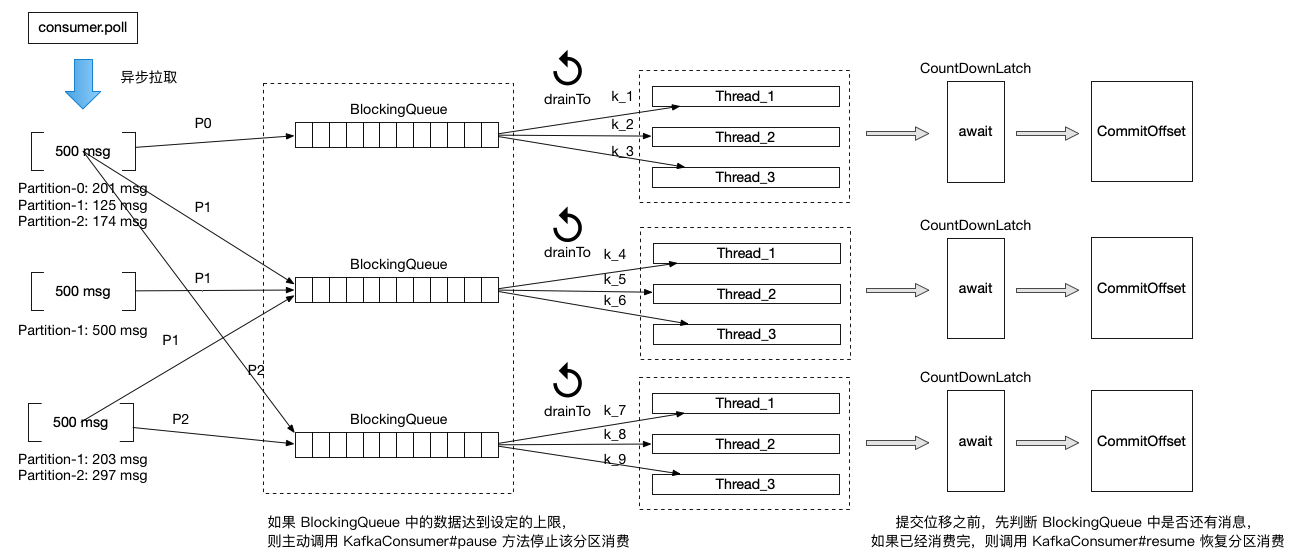
以上优化改造的核心是在不打乱消息顺序的前提下利用消息 Key 尽可能地并发消费,但如果遇到分区中的消息都是相同 Key,并且在有一定的积压下每次拉取都是同一个分区的消息时,以上模型可能没有理想情况下的那么好。这时是否可以将 fetch.max.bytes 与 max.partition.fetch.bytes 参数设置小一点,让每个分区的本地缓存都不足 500 条,这样每次 poll 的消息列表都可以包含多个分区的消息了,但这样又会导致 RPC 请求增多,这就需要针对业务消息大小,对这些参数进行调优。
以上线程模型,需要增加一个参数 orderlyConsumePartitionParallelism,用于设置分区消费并行度,假设某个消费组被分配 5 个分区进行消费,则每个分区默认启动一条线程消费,一共 5 * 1 = 5 条消费线程,当 orderlyConsumePartitionParallelism = 3,则每个分区启动 3 条线程消费,一共 5 * 3 = 15 条消费线程。orderlyConsumePartitionParallelism = 1 时,则说明该分区所有消息都处在顺序(串行)消费;当 orderlyConsumePartitionParallelism > 1 时,则根据分区消息的 Key 进行取模分配线程消费,保证不了整个分区顺序消费,但保证相同 Key 的消息顺序消费。
注意,当 orderlyConsumePartitionParallelism > 1 时,分区消费线程的有效使用率取决于该分区消息的 Key:
1、如果该分区所有消息的 Key 都相同,则消费的 Key 取模都分配都同一条线程当中,并行度退化成 orderlyConsumePartitionParallelism = 1;
2、如果该分区相同 Key 的消息过于集中,会导致每次拉取都是相同 key 的一批消息,同样并行度退化成 orderlyConsumePartitionParallelism = 1。
综合对比:
优化前,ZMS 可保证整个分区消息的顺序性,优化后可根据消息 Key 在分区的基础上不打乱相同 Key 消息的顺序性前提下进行并发消费,有效地提升了单分区的消费吞吐量;优化前,有很大的概率会退化成同一时刻单线程消费,优化后尽可能至少保证每个分区一条线程消费,情况好的时候每个分区可多条线程消费。
通过以上场景分析,该优化方案不是提高顺序消费吞吐量的银弹,它有很大的局限性,用户在业务的实现上不能重度依赖顺序消费去实现,以免影响业务性能上的需求。
总结
通过本文深度分析,我们已经认识到顺序消息会给消费吞吐量带来怎么样的影响,因此用户在业务的实现上不能重度依赖顺序消费去实现,能避免则避免,如果一定要使用到顺序消费,需要知道 Kafka 并不能保证严格的顺序消费,在消费组重平衡过程中很可能就会将消息的顺序性打乱,而且顺序消费会影响消费吞吐量,用户需要权衡这种需求的利弊。
写在最后
我们知道 RocketMQ 本身已经实现了具体的消费线程模型,用户不需要关心具体实现,只需要实现消息消费逻辑即可,而 Kafka 消息者仅提供 KafkaConsumer#poll 一个方法,消费线程模型的实现则完全交由用户去实现。
中通科技正式开源内部的消息 Pass 云平台化产品 ZMS(ZTO Messaging Service),它可以屏蔽底层消息中间件类型,封装了包括 Kafka 消费线模型在内的具体实现,提供统一的对外 API,弥补了 Kafka 消费者这部分支持的不足。同时还提供了通过唯一标识动态路由消息,为开发运维人员提供自动化部署运维集群,主题、消费组申请与审批、实时监控、自动告警、容灾迁移等功能。
同时希望更多的开源爱好者加入到该项目中,共同打造一体化的智能消息运维平台。
ZMS GitHub 地址:https://github.com/ZTO-Express/zms
作者简介
作者张乘辉,擅长消息中间件技能,负责公司百万 TPS 级别 Kafka 集群的维护,作者维护的公号「后端进阶」不定期分享 Kafka、RocketMQ 系列不讲概念直接真刀真枪的实战总结以及细节上的源码分析;同时作者也是阿里开源分布式事务框架 Seata Contributor,因此也会分享关于 Seata 的相关知识;当然公号也会分享 WEB 相关知识比如 Spring 全家桶等。内容不一定面面俱到,但一定让你感受到作者对于技术的追求是认真的!
公众号:后端进阶
技术博客:https://objcoding.com/
GitHub:https://github.com/objcoding/

以上是关于中通消息平台 Kafka 顺序消费线程模型的实践与优化的主要内容,如果未能解决你的问题,请参考以下文章