阿里云力夺FewCLUE榜首!知识融入预训练+小样本学习的实战解析
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阿里云力夺FewCLUE榜首!知识融入预训练+小样本学习的实战解析相关的知识,希望对你有一定的参考价值。
简介: 7月8日,中文语言理解权威评测基准CLUE公开了中文小样本学习评测榜单最新结果,阿里云计算平台PAI团队携手达摩院智能对话与服务技术团队,在大模型和无参数限制模型双赛道总成绩第一名,决赛答辩总成绩第一名。
作者 | 同润、归雨、熊兮
来源 | 阿里技术公众号
一 概述
7月8日,中文语言理解权威评测基准CLUE公开了中文小样本学习评测榜单最新结果,阿里云计算平台PAI团队携手达摩院智能对话与服务技术团队,在大模型和无参数限制模型双赛道总成绩第一名,决赛答辩总成绩第一名。
中文语言理解权威评测基准CLUE自成立以来发布了多项NLP评测基准,包括分类榜单,阅读理解榜单和自然语言推断榜单等,在学术界、工业界产生了深远影响。其中,FewCLUE是CLUE最新推出的一项中文小样本学习评测基准,用来评估机器学习模型是否能够通过极少样本的学习来掌握特定的自然语言处理任务。基于这项评估,科研人员可以更精准的衡量机器学习训练出来的模型的泛化性和准确率。比如智能客服场景中的用户意图识别,仅需人工标注几十条样本,就能让意图识别的准确率达到90%。
众所周知,大规模预训练模型虽然在各大任务里面取得非常大的效果,但是在特定的任务上,还是需要许多标注数据。由于收集和标注模型需要的训练的数据收集成本昂贵,所以需要攻关小样本学习技术,使用远小于经典深度学习算法需要的数据量,接近甚至超越经典深度学习算法的精度。此次,阿里云PAI团队携手达摩院提出了一套大模型+小样本的联合方案,在大规模通用预训练基础之上,结合了基于知识的预训练和Fuzzy-PET少样本学习,一举取得了优异的成绩。甚至在一个小样本学习任务上的精准度超过了人类。
二 赛题分析 & 建模思路
比赛数据集总体特点如下:
- 小样本:训练集和检验集均为每个类别16shot,考验算法在小样本情境下的鲁棒性
- 泛化性:任务特征差异明显,需要模型有较好的泛化能力
- 无标签数据:多数任务提供了数量可观的无标签数据,可以尝试continued pretrain和self-training
基于对赛题的解读,我们设计了三段式的建模方法:
- 通用领域数据的从头预训练:借助PAI-Rapidformer提供的各种加速策略以及预训练套件,我们从头预训练了3亿量级和15亿量级的中文预训练模型,预训练过程采用融入知识的预训练算法(详见3.2)。
- 多任务的继续预训练:目的是进一步强化双句匹配任务(OCNLI, BUSTM, CSL)的Performance。我们将分类任务转化为文本蕴含任务,使用文本蕴含数据进行Continued Pretrain。例如 [CLS]I like the movie[SEP]This indicates positive user sentiment[EOS]
- 针对每个任务进行小样本算法微调:选择PET(Pattern-Exploiting Training)作为下游微调的核心方法, 开发Fuzzy-PET算法,减少了PET算法标签词人工选择带来的波动,并且在任务上带来效果提升。同时使用了self-training 的半监督方法,在下游微调阶段利用上半监督学习(详见3.3)
三 核心技术
1. PyTorch大模型训练加速
自从2020年推出PAI-EasyTransfer面向NLP和迁移学习的框架之后,PAI团队开发了PyTorch版本的EasyTransfer,命名为EasyTexMiner。比赛所用的模型,是通过EasyTexMiner的高性能分布式预训练完成的。EasyTexMiner的分布式训练有机整合了微软的DeepSpeed和英伟达的Megatron优点,整体框图如下:

EasyTexMiner的分布式训练融合了以下核心的技术:
1)激活检查点(Activation Checkpoint)
在神经网络中间设置若干个检查点(checkpoint),检查点以外的中间结果全部舍弃,反向传播求导数的时间,需要某个中间结果就从最近的检查点开始计算,这样既节省了显存,又避免了从头计算的繁琐过程。
2)梯度累积 (Gradient Accumulation)
以batch_size=16为例,可以每次算16个样本的平均梯度,然后缓存累加起来,算够了4次之后,然后把总梯度除以4,然后才执行参数更新,这个效果等价于batch_size=64。这是一种有效的增加Batch Size的方法。通过该策略可以将每个step的batch size扩充到很大,结合LAMB优化器会提升收敛速度。
3)混合精度训练(Mixed Precision Training)
采用混合精度训练的好处主要有以下两点:
- 减少显存占用,由于FP16的内存占用只有FP32的一半,自然地就可以帮助训练过程节省一半的显存空间。
- 加快训练和推断的计算,FP16除了能节约内存,还能同时节省模型的训练时间。具体原理如下图所示,核心是在反向传播参数更新的时候需要维护一个FP32的备份来避免舍入误差,另外会通过Loss Scaling来缓解溢出错误。
4)即时编译JIT
当PyTorch在执行一系列element-wise的Tensor操作时,底层Kernel的实现需要反复地读写访存,但是只执行少量的计算,其中大部分时间开销并不在计算上,而在访存读写上。比如,实现一个带有N个元素的Tensor的乘/加法Kernel,需要N次加计算,2N次读和N次写访存操作。我们称计算少, 访存次数多的Kernel为访存Bound。为了避免这种反复的读写,以及降低Kernel Launch的开销,可以采用Kernel Fusion。访存Bound的Kernel Fusion的核心原理是通过访存的局部性原理,将多个element-wise的Kernel自动合并成一个Kernel,避免中间结果写到内存上,来提高访存的利用率;同时由于多个Kernel合并成一个Kernel,Kernel launch开销也减少到了1次。
5)3D并行
3D并行策略指的是:数据并行,模型并行,流水并行三种策略的混合运用,以达到快速训练百亿/千亿量级模型的目的。该项技术最早由DeepSpeed团队研发,可以加速大模型的训练。
6)CPU Offload
反向传播不在GPU上计算,而是在CPU上算,其中用到的中间变量全部存储在内存中,这样可以节省下GPU的显存占用,用时间换空间,以便能放到更大尺寸的模型。
7)Zero显存优化器
ZeRO(The Zero Redundancy Optimizer)是一种用于大规模分布式深度学习的新型内存优化技术。ZeRO具有三个主要的优化阶段:
- 优化器状态分区(Pos) :减少了4倍的内存,通信容量与数据并行性相同;
- 增加梯度分区(Pos+g) :8x内存减少,通信容量与数据并行性相同;
- 增加参数分区(Pos+g+p) :内存减少与数据并行度和复杂度成线性关系。
吞吐性能评测
本次发布使用了最新的阿里云EFLOPS AI集群系统,使用NVIDIA A100 GPU和 100Gbps Mellanonx CX6-DX网卡,结合全系统拓扑感知的高性能分布式通信库ACCL 和 EFLOPS集群多轨网络能力,实现无拥塞通信,大幅加速了模型的训练速度。如下图所示:

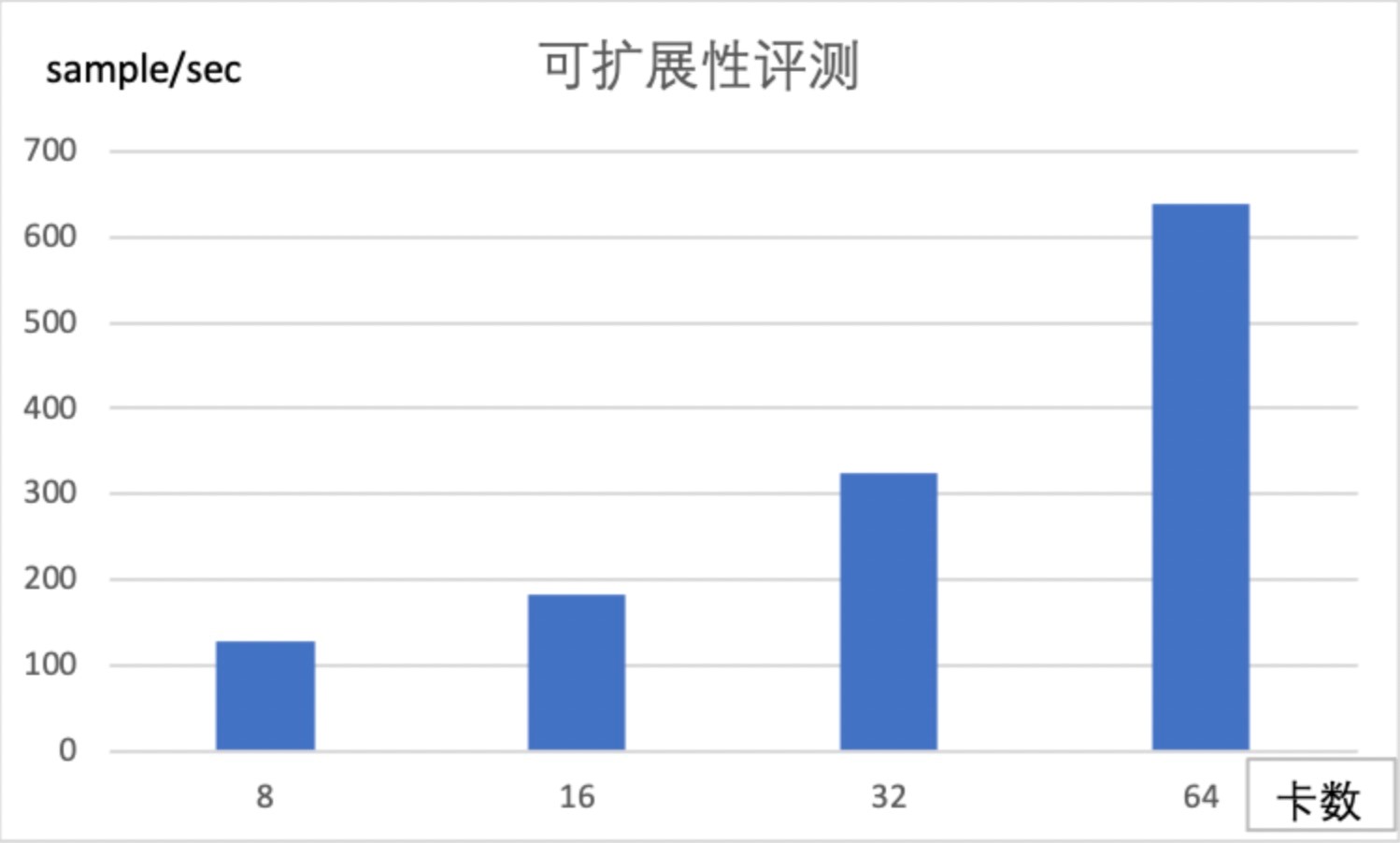
可扩展性评测
我们采用比BertLarge更大一点的单卡放不下的模型来做模型并行下的可扩展性评测。具体配置是 num-layers=24,hidden-size=2048,num-attention-heads=32,该模型的参数总量大约是1.2B。我们分别在8/16/32/64卡上进行来吞吐评测,从下图的指标来看,随着卡数的增加,吞吐几乎是近线性的提升。
2. 融入知识的预训练算法KGBERT
在通用预训练模型基础之上,我们考虑融入知识的预训练来提升预训练模型的效果。
数据和知识:通过与达摩院NLP数据团队合作,获取了大规模、高质量且具备多样性的数据与知识。
- 大规模:5亿中文图谱知识,通过远监督获取2亿 Sentence-SPO Pair;
- 高质量:针对原始语料庞杂,存在大量冗余、噪声的问题,通过DSGAN知识降噪算法,精选上亿高质量Sentence-SPO,用于模型训练;
- 多样性:FewCLUE数据集除了通用领域,还包含电商、旅游、教育、金融等垂直行业,而这部分数据和知识比较稀缺,为此我们构建了一套高效的知识生产系统,能够对各类垂直行业的文档、网页进行自动三元组抽取,从而极大的提升了知识的丰富度。
模型和预训练任务
为了高效的利用知识,我们基于“Sentence-正向SPO-负向SPO”对齐语料,设计了多粒度语义理解预训练任务:
- Mention Detection:增强模型对核心实体Mention的理解;
- Sentence-SPO joint Mask:将大规模文本数据及其对应的SPO知识同时输入到预训练模型中进行预联合训练,促进结构化知识和无结构文本之间的信息共享,提升模型语义理解能力;
- SPO Margin Magnify:设计对比学习的预训练任务,拉开Sentence相关SPO与无关SPO语义间隔,使其具备更强的语义区分能力。
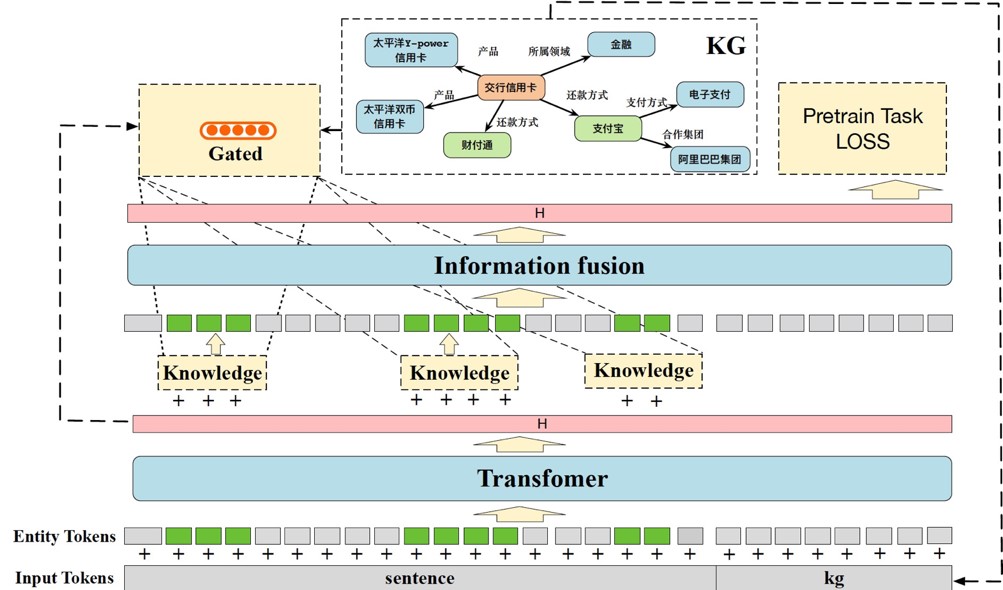
技术创新:知识筛选与融入机制
1)动机
NLP任务中,常见的做法是根据当前输入的自然语言进行建模,但是这样通常用到的信息只有当前字面局部信息。这和人类在理解语言的时候具有明显差别,人类会用到我们之前学习到的知识辅助理解。人类会利用这些外部知识来加强自己的理解,如果没有额外的知识,比如接触到我们一个不熟悉的领域,我们也很难完全理解语义。而目前NLP常见做法只利用了输入信息,没用利用外部知识,理解层次偏低。
现实中知识是庞大且繁杂的,需要针对性的采样知识,减少引入无关的知识,最大化知识的收益。
2)方法
设计一种新颖的Gated机制,先对句子进行编码,再通过GCN聚合出子图信息,通过门控机制,控制信息的流入;在预训练阶段,通过设计最大化知识增益目标函数,让模型更好的学习到有价值的信息。
3)结果
基于Gated机制的知识筛入,能够有效捕捉到高增益的三元组进行融入,在政务、金融属性识别任务上准确率有2%的提升。这样的知识筛选机制在学术公开数据集验证有效,并取得SOTA的效果,相关工作已发表在SIGIR2021。
3. 小样本学习算法
在融入知识的预训练语言模型基础上,计算平台PAI和达摩院团队联合推出了自研的多任务小样本学习算法Fuzzy-PET。由于FewClue榜单具有一系列不同类别的任务,如果在针对特定任务进行小样本微调之前,模型能学习到跨任务的可迁移的知识,模型在针对特定任务进行小样本微调过程中会获得更好的初始参数设置。基于计算平台PAI团队在Meta-Learning相关算法的积累基础上,我们在融入知识的预训练语言模型的继续预训练阶段,引入了多个FewClue任务的无标注数据进行学习,在学习过程中,模型自动从这些任务相关的数据中学习到这些任务的背景知识,从而更有利于特定任务的小样本学习。Meta-Learning的相关算法已经发表在EMNLP2020和ACL2021上。。
在特定小样本任务学习阶段,我们对Pattern-Exploiting Training(PET)算法进行了改进,引入了Fuzzy Verbalizer Mapping机制。举例来说,在经典的PET算法中,对于FewClue的任务OCNLI,我们设计了如下模板:“其实我觉得你不懂球啊”和“你不懂篮球。”的关系是MASK。
对于输出的Masked Language Token(即Verbalizer),如果预测结果为“相关”,我们将其映射为类别标签“entailment”;如果预测结果为“无关”,我们将其映射为类别标签“neural”; 如果预测结果为“相反”,我们将其映射为类别标签“contradiction”。利用Verbalizer到类别标签人工映射,PET实现了对文本分类任务的建模。在Fuzzy Verbalizer Mapping机制中,我们假设多个Verbalizer可能对某一个类别标签有映射关系,从而进一步提升模型在小样本学习过程中的泛化性。参考先前的例子,我们设计三组标签词:相关,无关,相反/蕴含,中性,矛盾/包含,中立,反向。训练时每一条样本使用多组标签词输入,在推理时每个类别计算所有候选词的预测概率并相加,最终选择总概率最高的类别。如上述例子,若预测“相关”,“蕴含”, “包含”的概率和大于预测“无关”,“中性”,“中立”或预测“相反”,“矛盾”,“反向”的概率,则预测结果为“entailment”。
这一机制在FewClue的多个任务中对预测精度提升有正面作用,并且一定程度上减轻人工选择不同标签词产生的波动。此外,我们也考虑在小样本学习阶段引入无标注的数据进行Self-training,即依靠现有模型对无标注数据进行打标,实现模型的迭代优化。
四 业务&产品
值得一提的是,基于机器学习平台PAI平台,这项技术已在实际业务场景落地且有很好的表现。这些技术增强了达摩院云小蜜KBQA能力,使其具备快速冷启动、精准问答的能力,并在政务、金融、通用线多个业务场景落地。在实际项目中,在少样本情形下(20条),可以做到快速冷启动,从而实现精准问答。同时,这些技术有望给阿里云上的机器学习算法赋予小样本学习的能力,通过很少的数据标注,就可以大大提升下游任务的效果。这意味着阿里云模型已具备低成本快速落地的实施能力,能高效且敏捷的赋能企业的业务。
基于PAI,阿里云希望构建大规模AI端到端的能力,从底层芯片到分布式系统,再到上层算法和数据的规模化,打造AI工程化集团作战的能力,服务于各行各业。目前,PAI平台支持千亿特征、万亿样本规模加速训练,内置200+成熟算法、以及图像视觉、音视频、文本等AI领域高质量深度学习预训练模型50余个,全面提升企业AI工程效率。在平台能力基础上,PAI平台还提供了成熟的行业解决方案,成为众多企业的优选服务,已经在智能推荐、用户增长、端侧超分、自动驾驶等众多场景成熟商用。
本文为阿里云原创内容,未经允许不得转载。
以上是关于阿里云力夺FewCLUE榜首!知识融入预训练+小样本学习的实战解析的主要内容,如果未能解决你的问题,请参考以下文章
阿里云力夺FewCLUE榜首!知识融入预训练+小样本学习的实战解析
阿里云力夺FewCLUE榜首!知识融入预训练+小样本学习的实战解析