PaddleNLP新增AutoPrompt自动化提示功能,登顶FewCLUE小样本学习榜单
Posted 百度大脑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PaddleNLP新增AutoPrompt自动化提示功能,登顶FewCLUE小样本学习榜单相关的知识,希望对你有一定的参考价值。

近年来,预训练语言模型已逐渐成为NLP任务的主流解决方案。但是在业务场景中,往往会遇到标注数据不足的问题,如何利用少量样本将模型快速迭代至可用状态成为了必要的研究方向。
近期,PaddleNLP团队开源了AutoPrompt方案,基于开源的文心ERNIE预训练语言模型 ,结合了领域预训练和自动化提示学习技术,以291M参数量的模型在小样本权威学习榜单FewCLUE排名第一。
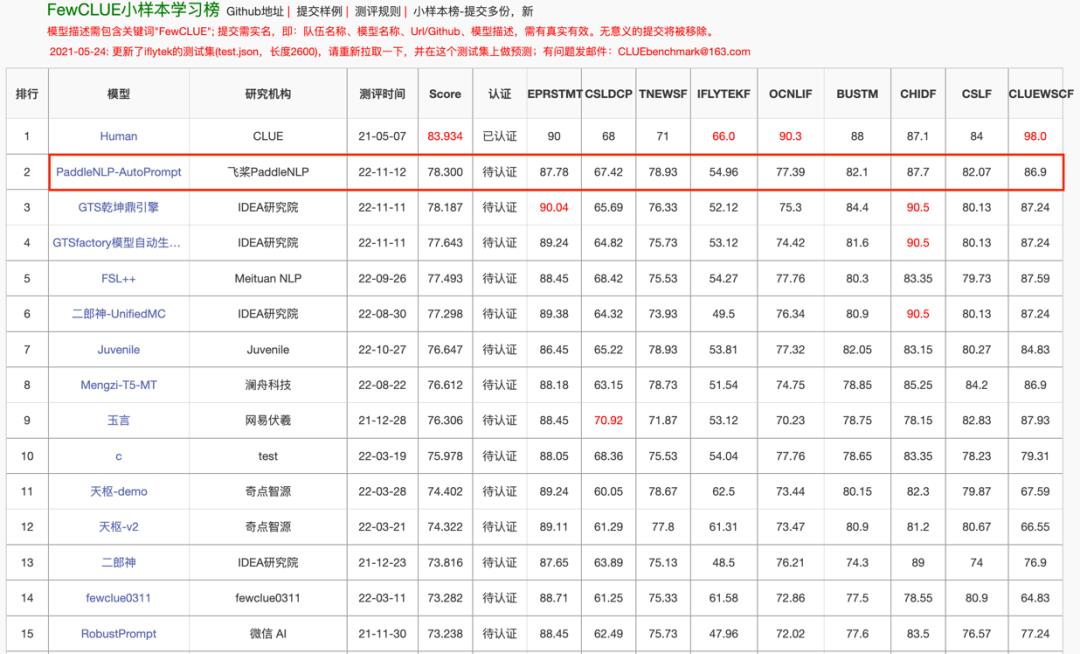
FewCLUE榜单排名(截止11月14日)
CLUE(Chinese Language Understanding Evaluation)作为中文语言理解权威测评榜单,在学术界和工业界都有着广泛影响。FewCLUE是其设立的中文小样本学习测评子榜,旨在探索小样本学习最佳模型和中文实践,自发布以来已经吸引了美团、IDEA研究院、澜舟科技、网易、腾讯微信等多家企业和研究院的参与。
PaddleNLP -
AutoPrompt介绍
登顶榜首的AutoPrompt自动化提示方案综合了基于知识增强的文心ERNIE预训练技术、提示学习(Prompt Learning)、数据增强、集成学习等策略,旨在探索小样本场景下的最佳实践方案,建设更为灵活易用的开源工具。我们利用这套方案在FewCLUE榜单上取得了优异的成绩,同时开源了完整的预训练代码、模型和Prompt设计。
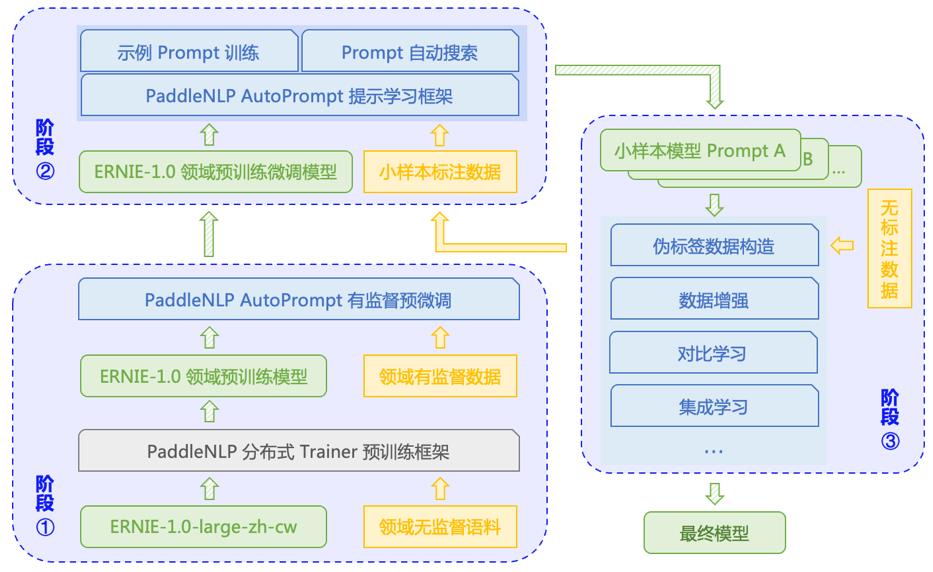
AutoPrompt整体流程方案
为什么选择
提示学习
预训练模型学习知识和模式的能力已得到了充分的验证,提示学习(Prompt Learning)的主要思想是在不显著改变预训练模型结构的前提下,通过给输入提供“提示信息”,将下游任务转化为完形填空或者文本生成任务,充分挖掘预训练模型学到的知识。具体来讲,在“预训练-微调”范式中,预训练模型仅用于文本编码,实现下游分类任务需要额外训练一个分类器。而PET这类提示学习方法,从预训练模型的输出就可以直接映射得到预测标签,无需训练额外参数。例如,在情感分类任务中,二者区别如下图所示。

情感分类任务上,微调与提示学习的区别
因此,提示学习在小样本场景下具备天然优势。近两年,学术领域涌现了诸多提示学习相关论文。随着研究工作的推进,提示学习在工业业务场景中的应用也逐步变为现实,PaddleNLP已经利用这一技术在互联网、金融、医疗、法律等场景实现落地。
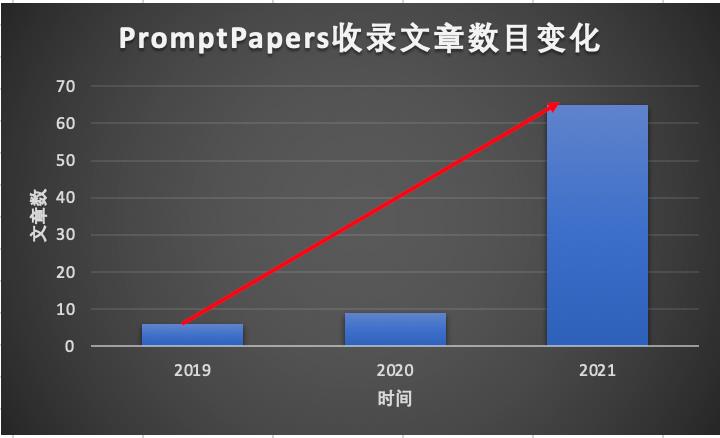
PromptPapers收录文章数目变化(统计自[1])
AutoPrompt的优势
AutoPrompt依托于PaddleNLP自然语言处理模型库,实现了通过配置自动化运行的提示学习框架,使开发者可以用最低学习成本上手提示学习。OpenPrompt[2]首次统一了提示学习框架,Template用于数据预处理,为输入增加“提示信息”;Verbalizer用于标签映射,使映射后的标签能与“提示信息”组成自然语句。AutoPrompt借鉴了其对Template、Verbalizer等概念的抽象和设计,并在此基础上扩展了更多特性,包括更灵活的提示设计,更便捷的算法切换,通过配置即可运行选择最优模型。
灵活
Template String延续了字典结构设计,支持更丰富的提示设计,以满足不同任务的需求。预训练模型、Template、Verbalizer等实现模块化,支持各种灵活扩展。

AutoPrompt支持多种prompt定义
易用
AutoPrompt封装了多种提示学习经典算法、对比学习策略和14种数据增强策略,同时基于Trainer封装了整体训练流程。无需修改代码,通过定义Template String即可快速切换提示模板、离散型和连续型提示学习算法、实现EFL算法等,通过修改配置即可快速切换不同数据策略。
自动化
只需要准备相应格式的数据,定义模型、数据、策略的配置参数,以及Template String文件,即可一键运行。AutoPrompt框架可自动从定义的Template String中选择最佳Prompt,保存效果最优的模型。

AutoPrompt框架使用流程
技术私享会
11月17日,PaddleNLP工程师,AutoPrompt作者将在线分享提示学习相关前沿技术、AutoPrompt的“自动化”理念、FewCLUE打榜经验、以及提示学习产业落地案例,欢迎有兴趣的朋友扫码报名活动,参与线上交流。(为保证交流效果,限100席位)

FewCLUE
小样本学习实践
FewCLUE榜单任务包括文本分类、句间关系和阅读理解三类任务,各个任务中的每个标签分别有25——80条标注数据用于训练,同时有等量的数据用于模型评估选择。除了指代消解任务,其他数据集中还提供了大量的无标注数据。

针对这些任务,我们的方案具体分为三个阶段:
阶段一 :领域预训练
针对FewCLUE相关领域收集了无监督数据,使用PaddleNLP开源的文心ERNIE预训练流程进行二次预训练,将领域知识进一步强化到预训练模型中。
阶段二:提示学习
在提示学习中,提升模型效果的关键在于挑选与任务适配的最优提示词。我们使用AutoPrompt框架进行了高效的提示词和相关算法搜索,大幅降低了提示词选择成本。
阶段三:数据增强&集成学习
为进一步提升结果鲁棒性,数据策略和模型策略必不可少。我们采用了多种数据增强策略,自动扩充了标注数据。最终模型结果由多模型的输出结果集成得到。
下面我们将具体介绍其中的技术细节。
领域预训练
作为提示学习的基础,预训练模型直接决定了下游任务的效果。因此针对FewCLUE任务,我们使用了PaddleNLP最佳预训练语言模型文心ERNIE 1.0-Large-CW。该模型不仅效果好,而且训练流程完全开源可复现。
PaddleNLP致力于建设中文场景的特色模型,并基于中文权威榜单CLUE Benchmark对预训练模型做了详细评测。文心ERNIE系列模型融合了知识信息,其各量级的模型都取得了非常好的成绩,下面是具体的效果对比。

文心ERNIE系列模型在CLUE评测榜单的效果表现
为了让预训练模型适配FewCLUE的任务设定,我们收集了FewCLUE相关的无监督数据进行了领域预训练(Domain-Adaptive Pretraining)以使模型具备更好的领域特性。这里借鉴了Task-Adaptive Pretraining(TAPT)[3]中的思想,使用FewCLUE训练集和无标签数据集中的文本进行了进一步的无监督预训练,以学习论文关键词识别(CSL)、代词消歧(CLUEWSC)等阅读理解任务相关知识。
上述文心ERNIE 1.0-Large-CW模型、领域预训练任务涉及的预训练流程完全开源,根据教程可复现,整个预训练流程包含:
详细的中文全词表构造方法,提供20902个中文全字符词表制作流程
高性能预训练数据生成工具,16小时轻松搞定400G预训练数据制作
混合精度、分布式4D并行训练能力,支持超大语义理解模型训练
全面的CLUE Bencmark效果测评,覆盖大多数主流中文模型
大家可以从零开始训练模型,也可以在原来模型的基础上进行领域预训练。
源码及教程地址:
https://github.com/PaddlePaddle/PaddleNLP/blob/develop/model_zoo/ernie-1.0
提示学习
在预训练模型的选择阶段,我们发现推理任务和指代消歧等任务更依赖于预训练语言模型的学习能力,当前模型规模与超大规模模型学习到的知识与模式仍有一定差距。因此,在融入领域知识的预训练模型基础上,我们收集了有监督的语言推理和指代消解数据进行多任务学习,得到了领域相关的预训练模型底座。这里主要借鉴了当前零样本学习的主流做法[4],通过多任务预训练提升下游任务上的零样本和小样本学习能力。
FewCLUE实践中主要使用了PET算法[5],对于各个任务,需要分别设计提示词将其转换为掩码预测任务。例如,针对语言推理任务(OCNLI),可以给两段文本增加提示词得到:“ ‘慢慢来啊,有人在帮我找了。’ 和 ‘我安慰别人别着急’之间的逻辑关系是MASK”。如果MASK位置预测为“矛盾”,那么对应标签为“contradiction”。同理,“蕴含”对应标签“entailment”,“中立”对应标签“neutral”。针对成语阅读理解任务(CHID),可以将多选填空题拆分为判断题,依次将候选成语填入空格处判断是否合适。
提示词设计对结果影响很明显,部分数据集上不同提示词结果可相差10个点,因此,提示词的选择就十分重要。我们使用AutoPrompt来高效搜索最优提示词。如下所示,在配置文件中定义多个提示词模板,运行脚本即可得到其中最优提示词对应的模型。
"template": [
"text": "“'text': 'text_a'”和“'text': 'text_b'”之间的逻辑关系是'mask''mask'",
"text": "'soft': '下边两句话之间有什么逻辑关系?''mask''mask'“'text': 'text_a'”'sep'“'text': 'text_b'”"
],
"verbalizer":
"contradiction": "矛盾",
"entailment": "蕴含",
"neutral": "中立"
在PET搜索得到的最优提示后,可通过修改Template String切换为连续型提示学习算法,用相应的提示词初始化连续型提示向量。在此基础上增加LSTM编码器学习提示向量之间的序列关系可以进一步提升模型学习效果。以上修改均可通过配置文件实现。
PaddleNLP AutoPrompt使用文档
https://github.com/PaddlePaddle/PaddleNLP/blob/develop/docs/advanced_guide/prompt.md
数据增强&模型集成
除了预训练模型和算法,数据也是重要的一环。数据增强策略可以扩充标注数据量,增加训练样本的多样性,从而提升模型训练效果。在FewCLUE数据集中,除了指代消解数据集CLUEWSC,每个数据集还有大量无标注数据。我们基于不同提示词及数据增强策略训练得到多组模型,然后使用准确率较高的模型对无标注数据进行预测,投票选择置信度较高的值作为“伪标签”,进一步扩展训练数据,实现模型的迭代优化。在FewCLUE实验中,我们只使用了单次迭代。

伪标签策略
AutoPrompt支持了EDA数据增强[6]以及对比学习RDrop[7]等策略,不同的数据集适用于不同的数据策略,具体选择需要分析样本决定。另外,由于样本量较少,模型训练效果会受到随机性的影响,而且不同策略训练的模型学习到的知识也各不相同。因此,我们还使用了集成学习,将不同策略/prompt训练出来的一组模型结果组合分析,通过硬投票机制选取最优结果,提高最终的准确率。

未来展望
通过这次FewCLUE的实践,我们可以看到文心ERNIE 1.0(291M)这类轻量级的预训练语言模型在小样本场景下也有相当不错的表现。当前版本的预训练模型仅针对FewCLUE中包含的任务,且相对依赖提示词的设计。未来我们将持续探索开放域分类场景的预训练模型开发,进一步降低小样本场景下的应用成本。
若我们开源工作对你有帮助,欢迎STAR支持
https://github.com/PaddlePaddle/PaddleNLP
相关地址
[1]https://github.com/thunlp/PromptPapers
[2]OpenPrompt: An Open-source Framework for Prompt-learning (Ding et al., ACL 2022, Best Demo)
[3]Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks (Gururangan et al., ACL 2020)
[4]Zero-Shot Learners for Natural Language Understanding via a Unified Multiple Choice Perspective (Yang et al., EMNLP 2022)
[5]GPT Understands, Too (Liu et al., 2021)
[6]EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks (Wei & Zou, EMNLP 2019)
[7]R-Drop: Regularized Dropout for Neural Networks (Liang et al., NeurIPS 2021)
WAVE SUMMIT+2022
WAVE SUMMIT+2022将于11月30日在深圳举办,欢迎大家扫码报名!关注飞桨公众号,后台回复关键词「WAVE」进入官网社群了解更多峰会详情!

【WAVE SUMMIT+2022报名入口】

关注【飞桨PaddlePaddle】公众号
获取更多技术内容~
以上是关于PaddleNLP新增AutoPrompt自动化提示功能,登顶FewCLUE小样本学习榜单的主要内容,如果未能解决你的问题,请参考以下文章
PaddleNLP详解及实战分享-百度飞桨AI快车道北京周末专场报名
NLP前沿研究成果大开源,百度PaddleNLP-研究版发布
PaddleNLP基于ERNIR3.0文本分类:WOS数据集为例(层次分类)