PaddleNLP基于ERNIR3.0文本分类:WOS数据集为例(层次分类)
Posted 汀、
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PaddleNLP基于ERNIR3.0文本分类:WOS数据集为例(层次分类)相关的知识,希望对你有一定的参考价值。
相关项目链接:
Paddlenlp之UIE模型实战实体抽取任务【打车数据、快递单】
Paddlenlp之UIE分类模型【以情感倾向分析新闻分类为例】含智能标注方案)
应用实践:分类模型大集成者[PaddleHub、Finetune、prompt]
PaddleNLP基于ERNIR3.0文本分类以中医疗搜索检索词意图分类(KUAKE-QIC)为例【多分类(单标签)】
基于Ernie-3.0 CAIL2019法研杯要素识别多标签分类任务
本项目链接:
基于ERNIR3.0文本分类:WOS数据集为例(层次分类)
0.前言:文本分类任务介绍
文本分类任务是自然语言处理中最常见的任务,文本分类任务简单来说就是对给定的一个句子或一段文本使用文本分类器进行分类。文本分类任务广泛应用于长短文本分类、情感分析、新闻分类、事件类别分类、政务数据分类、商品信息分类、商品类目预测、文章分类、论文类别分类、专利分类、案件描述分类、罪名分类、意图分类、论文专利分类、邮件自动标签、评论正负识别、药物反应分类、对话分类、税种识别、来电信息自动分类、投诉分类、广告检测、敏感违法内容检测、内容安全检测、舆情分析、话题标记等各类日常或专业领域中。
文本分类任务可以根据标签类型分为多分类(multi class)、多标签(multi label)、层次分类(hierarchical等三类任务,接下来我们将以下图的新闻文本分类为例介绍三种分类任务的区别。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uoHW1SRg-1658974890557)(https://ai-studio-static-online.cdn.bcebos.com/851cef351a914572ba1172db41f5126a7bd581a0d90947b29ce177e2f1229e89)]
PaddleNLP采用AutoModelForSequenceClassification, AutoTokenizer提供了方便易用的接口,可指定模型名或模型参数文件路径通过from_pretrained() 方法加载不同网络结构的预训练模型,并在输出层上叠加一层线性层,且相应预训练模型权重下载速度快、稳定。Transformer预训练模型汇总包含了如 ERNIE、BERT、RoBERTa等40多个主流预训练模型,500多个模型权重。下面以ERNIE 3.0 中文base模型为例,演示如何加载预训练模型和分词器:
from paddlenlp.transformers import AutoModelForSequenceClassification, AutoTokenizer
num_classes = 10
model_name = "ernie-3.0-base-zh"
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_classes=num_classes)
tokenizer = AutoTokenizer.from_pretrained(model_name)
0.1 层次分类任务介绍
多标签层次分类任务指自然语言处理任务中,每个样本具有多个标签标记,并且标签集合中标签之间存在预定义的层次结构,多标签层次分类需要充分考虑标签集之间的层次结构关系来预测层次化预测结果。层次分类任务中标签层次结构分为两类,一类为树状结构,另一类为有向无环图(DAG)结构。有向无环图结构与树状结构区别在于,有向无环图中的节点可能存在不止一个父节点。在现实场景中,大量的数据如新闻分类、专利分类、学术论文分类等标签集合存在层次化结构,需要利用算法为文本自动标注更细粒度和更准确的标签。
层次分类问题可以被视为一个多标签问题,以下图一个树状标签结构(宠物为根节点)为例,如果一个样本属于美短虎斑,样本也天然地同时属于类别美国短毛猫和类别猫两个样本标签。本项目采用通用多标签层次分类算法,将每个结点的标签路径视为一个多分类标签,使用单个多标签分类器进行决策,以上面美短虎斑的例子为例,该样本包含三个标签:猫、猫##美国短毛猫、猫##美国短毛猫##美短虎斑(不同层的标签之间使用##作为分割符)。下图的标签结构标签集合为猫、猫##波斯猫、猫##缅因猫、猫##美国短毛猫、猫##美国短毛猫##美短加白、猫##美国短毛猫##美短虎斑、猫##美国短毛猫##美短起司、兔、兔##侏儒兔、兔##垂耳兔总共10个标签。

0.2 文本分类应用全流程介绍
接下来,我们将按数据准备、训练、性能优化部署等三个阶段对文本分类应用的全流程进行介绍。
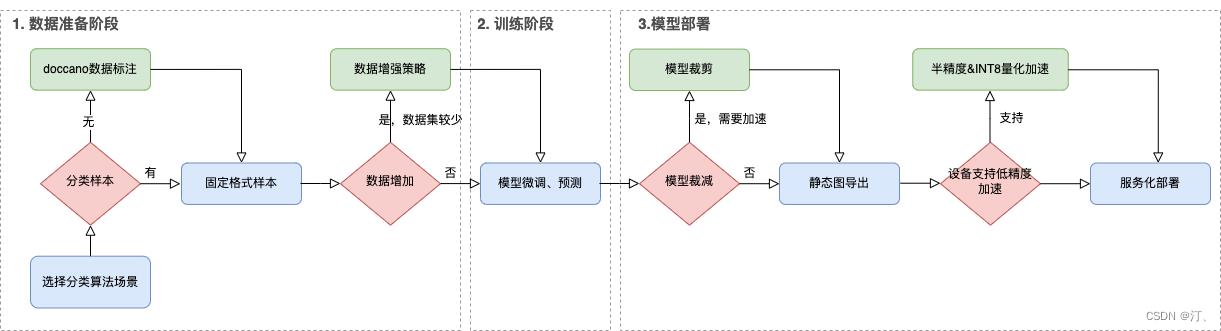
- 数据准备
如果没有已标注的数据集,推荐doccano数据标注工具,如何使用doccano进行数据标注并转化成指定格式本地数据集详见文本分类任务doccano使用指南。如果已有标注好的本地数据集,我们需要根据不同任务要求将数据集整理为文档要求的格式:多分类数据集格式要求、多标签数据集格式要求、层次分类数据集格式要求。
准备好数据集后,我们可以根据现有的数据集规模或训练后模型表现选择是否使用数据增强策略进行数据集扩充。
- 模型训练
数据准备完成后,可以开始使用我们的数据集对预训练模型进行微调训练。我们可以根据任务需求,调整可配置参数,选择使用GPU或CPU进行模型训练,脚本默认保存在开发集最佳表现模型。中文任务默认使用"ernie-3.0-base-zh"模型,英文任务默认使用"ernie-2.0-base-en"模型,ERNIE 3.0还支持多个轻量级中文模型,详见ERNIE模型汇总,可以根据任务和设备需求进行选择。
首先我们需要根据场景选择不同的任务目录,具体可以见 多分类任务点击这里 多标签任务点击这里 层次分类任务点击这里
训练结束后,我们可以加载保存的最佳模型进行模型测试,打印模型预测结果。
- 模型预测
在现实部署场景中,我们通常不仅对模型的精度表现有要求,也需要考虑模型性能上的表现。我们可以使用模型裁剪进一步压缩模型体积,文本分类应用已提供裁剪API对上一步微调后的模型进行裁剪,模型裁剪之后会默认导出静态图模型。
模型部署需要将保存的最佳模型参数(动态图)导出成静态图参数,用于后续的推理部署。
文本分类应用提供了基于ONNXRuntime的本地部署predictor,并且支持在GPU设备使用FP16,在CPU设备使用动态量化的低精度加速推理。
文本分类应用同时基于Paddle Serving的服务端部署方案。
本项目主要讲解:数据准备、模型训练、模型预测部分,对于部署部分篇幅有限,感兴趣同学可以跑一跑试一试。
参考链接:
[https://github.com/PaddlePaddle/PaddleNLP/tree/develop/applications/text_classification](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/applications/text_classification
1.文本分类任务doccano使用指南【多分类、多标签、层次分类】
安装详细事宜参考项目:
Paddlenlp之UIE分类模型【以情感倾向分析新闻分类为例】含智能标注方案)
强烈推荐:数据标注平台doccano----简介、安装、使用、踩坑记录
这里就不对安装等进行重复讲解,默认都会。
具体参考项目:
PaddleNLP基于ERNIR3.0文本分类以中医疗搜索检索词意图分类(KUAKE-QIC)为例【多分类(单标签)】
2.基于ERNIR3.0层次分类模型微调
以下是本项目主要代码结构及说明:
├── train.py # 训练评估脚本
├── predict.py # 预测脚本
├── export_model.py # 动态图参数导出静态图参数脚本
├── utils.py # 工具函数脚本
├── metric.py # metric脚本
├── prune.py # 裁剪脚本
├── prune_trainer.py # 裁剪trainer脚本
├── prune_config.py # 裁剪训练参数配置
├── requirements.txt # 环境依赖
└── README.md # 使用说明
以层次分类公开数据集WOS(Web of Science)为示例,在训练集上进行模型微调,并在开发集上验证。WOS数据集是一个两层的层次文本分类数据集,包含7个父类和134子类,每个样本对应一个父类标签和子类标签,父类标签和子类标签间具有树状层次结构关系。
程序运行时将会自动进行训练,评估,测试。同时训练过程中会自动保存开发集上最佳模型在指定的 save_dir 中,保存模型文件结构如下所示:
checkpoint/
├── model_config.json
├── model_state.pdparams
├── tokenizer_config.json
└── vocab.txt
NOTE:
如需恢复模型训练,则可以设置 init_from_ckpt , 如 init_from_ckpt=checkpoint/model_state.pdparams 。
如需训练中文文本分类任务,只需更换预训练模型参数 model_name 。中文训练任务推荐使用"ernie-3.0-base-zh",更多可选模型可参考Transformer预训练模型。
2.1.加载本地数据集
在许多情况,我们需要使用本地数据集来训练我们的文本分类模型,本项目支持使用固定格式本地数据集文件进行训练。如果需要对本地数据集进行数据标注,可以参考文本分类任务doccano数据标注使用指南进行文本分类数据标注。本项目将以CAIL2018-SMALL数据集罪名预测任务为例进行介绍如何加载本地固定格式数据集进行训练:
!wget https://paddlenlp.bj.bcebos.com/datasets/wos_data.tar.gz
!tar -zxvf wos_data.tar.gz
!mv wos_data data
本地数据集目录结构如下:
data/
├── train.txt # 训练数据集文件
├── dev.txt # 开发数据集文件
├── test.txt # 可选,测试训练集文件
├── label.txt # 分类标签文件
└── data.txt # 可选,待预测数据文件
train.txt(训练数据集文件), dev.txt(开发数据集文件), test.txt(可选,测试训练集文件)中 n 表示标签层次结构中最大层数,<level i 标签> 代表数据的第i层标签。输入文本序列及不同层的标签数据用’\\t’分隔开,每一层标签中多个标签之间用’,‘逗号分隔开。注意,对于第i层数据没有标签的,使用空字符’'来表示<level i 标签>。
train.txt/dev.txt/test.txt 文件格式:
<输入序列1>'\\t'<level 1 标签1>','<level 1 标签2>'\\t'<level 2 标签1>','<level 2 标签2>'\\t'...'\\t'<level n 标签1>','<level n 标签2>
<输入序列2>'\\t'<level 1 标签>'\\t'<level 2 标签>'\\t'...'\\t'<level n 标签>
...
...
train.txt/dev.txt/test.txt 文件样例:
unintended pregnancy continues to be a substantial public health problem. emergency contraception (ec) provides a last chance at pregnancy prevention. several safe and effective options for emergency contraception are currently available. the yuzpe method, a combined hormonal regimen, was essentially replaced by other oral medications including levonorgestrel and the antiprogestin ulipristal. the antiprogestin mifepristone has been studied for use as emergency contraception. the most effective postcoital method of contraception is the copper intrauterine device (iud). obesity and the simultaneous initiation of progestin-containing contraception may decrease the effectiveness of some emergency contraception. Medical Emergency Contraception
the objective of this paper is to present an example in which matrix functions are used to solve a modern control exercise. specifically, the solution for the equation of state, which is a matrix differential equation is calculated. to resolve this, two different methods are presented, first using the properties of the matrix functions and by other side, using the classical method of laplace transform. ECE Control engineering
...
...
label.txt(层次分类标签文件)记录数据集中所有标签路径集合,在标签路径中,高层的标签指向底层标签,标签之间用’##'连接,本项目选择为标签层次结构中的每一个节点生成对应的标签路径。
label.txt 文件格式:
<level 1: 标签>
<level 1: 标签>'##'<level 2: 标签>
<level 1: 标签>'##'<level 2: 标签>'##'<level 3: 标签>
...
...
label.txt 文件样例:
CS
ECE
CS##Computer vision
CS##Machine learning
ECE##Electricity
ECE##Lorentz force law
...
...
data.txt(可选,待预测数据文件)
data.txt 文件格式:
<输入序列1>
<输入序列2>
...
data.txt 文件样例:
<输入序列1>
<输入序列2>
...
previous research exploring cognitive biases in bulimia nervosa suggests that attentional biases occur for both food-related and body-related cues. individuals with bulimia were compared to non-bulimic controls on an emotional-stroop task which contained both food-related and body-related cues. results indicated that bulimics (but not controls) demonstrated a cognitive bias for both food-related and body related cues. however, a discrepancy between the two cue-types was observed with body-related cognitive biases showing the most robust effects and food-related cognitive biases being the most strongly associated with the severity of the disorder. the results may have implications for clinical practice as bulimics with an increased cognitive bias for food-related cues indicated increased bulimic disorder severity. (c) 2016 elsevier ltd. all rights reserved.
posterior reversible encephalopathy syndrome (pres) is a reversible clinical and neuroradiological syndrome which may appear at any age and characterized by headache, altered consciousness, seizures, and cortical blindness. the exact incidence is still unknown. the most commonly identified causes include hypertensive encephalopathy, eclampsia, and some cytotoxic drugs. vasogenic edema related subcortical white matter lesions, hyperintense on t2a and flair sequences, in a relatively symmetrical pattern especially in the occipital and parietal lobes can be detected on cranial mr imaging. these findings tend to resolve partially or completely with early diagnosis and appropriate treatment. here in, we present a rare case of unilateral pres developed following the treatment with pazopanib, a testicular tumor vascular endothelial growth factor (vegf) inhibitory agent.
...
2.2模型预测
#单卡训练
!python train.py --early_stop --epochs 5 --warmup --save_dir "./checkpoint" --batch_size 32 --dataset_dir "data/wos_data"
输出结果部分展示:
[2022-07-27 17:54:18,773] [ INFO] - global step 1870, epoch: 2, batch: 930, loss: 0.04018, micro f1 score: 0.56644, macro f1 score: 0.04182, speed: 1.79 step/s
[2022-07-27 17:54:24,434] [ INFO] - global step 1875, epoch: 2, batch: 935, loss: 0.03838, micro f1 score: 0.56670, macro f1 score: 0.04185, speed: 1.79 step/s
[2022-07-27 17:54:29,539] [ INFO] - global step 1880, epoch: 2, batch: 940, loss: 0.03892, micro f1 score: 0.56682, macro f1 score: 0.04187, speed: 1.98 step/s
[2022-07-27 17:55:27,020] [ INFO] - eval loss: 0.03925, micro f1 score: 0.59396, macro f1 score: 0.04428
[2022-07-27 17:55:27,021] [ INFO] - Current best macro f1 score: 0.04428
[2022-07-27 17:55:28,033] [ INFO] - tokenizer config file saved in ./checkpoint/tokenizer_config.json
[2022-07-27 17:55:28,034] [ INFO] - Special tokens file saved in ./checkpoint/special_tokens_map.json
[2022-07-27 17:55:30,385] [ INFO] - global step 1885, epoch: 3, batch: 5, loss: 0.03854, micro f1 score: 0.64000, macro f1 score: 0.04778, speed: 0.16 step/s
[2022-07-27 17:55:31,980] [ INFO] - global step 1890, epoch: 3, batch: 10, loss: 0.03603, micro f1 score: 0.63455, macro f1 score: 0.04747, speed: 6.57 step/s
[2022-07-27 17:55:33,539] [ INFO] - global step 1895, epoch: 3, batch: 15, loss: 0.03707, micro f1 score: 0.62945, macro f1 score: 0.04679, speed: 6.73 step/s
[2022-07-27 17:55:35,138] [ INFO] - global step 1900, epoch: 3, batch: 20, loss: 0.03549, micro f1 score: 0.62788, macro f1 score: 0.04674, speed: 6.56 step/s
[2022-07-27 17:55:36,823] [ INFO] - global step 1905, epoch: 3, batch: 25, loss: 0.03838, micro f1 score: 0.62448, macro f1 score: 0.04646, speed: 6.20 step/s
[2022-07-27 17:55:38,457] [ INFO] - global step 1910, epoch: 3, batch: 30, loss: 0.03717, micro f1 score: 0.62339, macro f1 score: 0.04635, speed: 6.42 step/s
[2022-07-27 17:55:40,075] [ INFO] - global step 1915, epoch: 3, batch: 35, loss: 0.04115, micro f1 score: 0.62302, macro f1 score: 0.04632, speed: 6.48 step/s
[2022-07-27 17:55:41,742] [ INFO] - global step 1920, epoch: 3, batch: 40, loss: 0.03842, micro f1 score: 0.61973, macro f1 score: 0.04607, speed: 6.29 step/s
[2022-07-27 17:55:43,423] [ INFO] - global step 1925, epoch: 3, batch: 45, loss: 0.03772, micro f1 score: 0.61950, macro f1 score: 0.04606, speed: 6.22 step/s
[2022-07-27 17:55:45,118] [ INFO] - global step 1930, epoch: 3, batch: 50, loss: 0.04074, micro f1 score: 0.61848, macro f1 score: 0.04602, speed: 6.17 step/s
样本集过大这边就部继续演示了,
可支持配置的参数:
save_dir保存训练模型的目录;默认保存在当前目录checkpoint文件夹下。
dataset:训练数据集;默认为"cail2018_small"。
dataset_dir:本地数据集路径,数据集路径中应包含train.txt,dev.txt和label.txt文件;默认为None。
task_name:训练数据集;默认为wos数据集。
max_seq_length:ERNIE模型使用的最大序列长度,最大不能超过512, 若出现显存不足,请适当调低这一参数;默认为512。
model_name:选择预训练模型;默认为"ernie-2.0-base-en",中文数据集推荐使用"ernie-3.0-base-zh"。
device: 选用什么设备进行训练,可选cpu、gpu、xpu、npu。如使用gpu训练,择使用参数gpus指定GPU卡号。
batch_size:批处理大小,请结合显存情况进行调整,若出现显存不足,请适当调低这一参数;默认为32。
learning_rate:Fine-tune的最大学习率;默认为3e-5。
weight_decay:控制正则项力度的参数,用于防止过拟合,默认为0.00。
early_stop:选择是否使用早停法(EarlyStopping);默认为False。
early_stop_nums:在设定的早停训练轮次内,模型在开发集上表现不再上升,训练终止;默认为6。
epochs: 训练轮次,默认为1000。
warmup:是否使用学习率warmup策略;默认为False。
warmup_steps:学习率warmup策略的steps数,如果设为2000,则学习率会在前2000 steps数从0慢慢增长到learning_rate, 而后再缓慢衰减;默认为2000。
logging_steps: 日志打印的间隔steps数,默认5。
seed:随机种子,默认为3。
depth:层次结构最大深度,默认为2。
2.2.1 评价指标定义
对评价指标进行阐述一下:
criterion = paddle.nn.BCEWithLogitsLoss()
metric = MetricReport() #得到F1 值 如果需要修改参考多分类文章
micro_f1_score, macro_f1_score = evaluate(model, criterion, metric,
dev_data_loader)
可以看到性能指标主要关于F1值,具体大家可以参考文档
本次使用的是metrics.py文件从sklearn库导入的:
from sklearn.metrics import f1_score, classification_report
如有额外需求可以,使用metrics1.py文件从sklearn库导入的:
from sklearn.metrics import roc_auc_score, f1_score, precision_score, recall_score
import numpy as np
from sklearn.metrics import roc_auc_score, f1_score, precision_score, recall_score
from paddle.metric import Metric
class MultiLabelReport(Metric):
"""
AUC and F1 Score for multi-label text classification task.
"""
def __init__(self, name='MultiLabelReport', average='micro'):
super(MultiLabelReport, self).__init__()
self.average = average
self._name = name
self.reset()
def f1_score(self, y_prob):
'''
Returns the f1 score by searching the best threshhold
'''
best_score = 0
for threshold in [i * 0.01 for i in range(100)]:
self.y_pred = y_prob > threshold
score = f1_score(y_pred=self.y_pred, y_true=self.y_true, average=self.average)
if score > best_score:
best_score = score
precison = precision_score(y_pred=self.y_pred, y_true=self.y_true, average=self.average)
recall = recall_score(y_pred=self.y_pred, y_true=self.y_true, average=self.average)
return best_score, precison, recall
def reset(self):
"""
Resets all of the metric state.
"""
self.y_prob = None
self.y_true = None
def update(self, probs, labels):
if self.y_prob is not None:
self.y_prob = np.append(self.y_prob, probs.numpy(), axis=0)
else:
self.y_prob = probs.numpy()
if self.y_true is not None:
self.y_true = np.append(self.y_true, labels.numpy(), axis=0)
else:
self.y_true = labels.numpy()
def accumulate(self):
auc = roc_auc_score(
y_score=self.y_prob, y_true=self.y_true, average=self.average)
f1_score, precison, recall = self.f1_score(y_prob=self.y_prob)
return auc, f1_score, precison, recall
def name(self):
"""
Returns metric name
"""
return self._name
详细细节参考项目:
#多卡训练:
#unset CUDA_VISIBLE_DEVICES
#!python -m paddle.distributed.launch --gpus "0" train.py --early_stop --dataset_dir data
#使用多卡训练可以指定多个GPU卡号,例如 --gpus "0,1"
2.3 模型预测
输入待预测数据和数据标签对照列表,模型预测数据对应的标签
使用默认数据进行预测:
python predict.py --params_path ./checkpoint/
也可以选择使用本地数据文件data/data.txt进行预测:
!python predict.py --params_path ./checkpoint/ --dataset_dir data/wos_data
输出结果:
input data: a high degree of uncertainty associated with the emission inventory for china tends to degrade the performance of chemical transport models in predicting pm2.5 concentrations especially on a daily basis. in this study a novel machine learning algorithm, geographically -weighted gradient boosting machine (gw-gbm), was developed by improving gbm through building spatial smoothing kernels to weigh the loss function. this modification addressed the spatial nonstationarity of the relationships between pm2.5 concentrations and predictor variables such as aerosol optical depth (aod) and meteorological conditions. gw-gbm also overcame the estimation bias of pm2.5 concentrations due to missing aod retrievals, and thus potentially improved subsequent exposure analyses. gw-gbm showed good performance in predicting daily pm2.5 concentrations (r-2 = 0.76, rmse = 23.0 g/m(3)) even with partially missing aod data, which was better than the original gbm model (r-2 = 0.71, rmse = 25.3 g/m(3)). on the basis of the continuous spatiotemporal prediction of pm2.5 concentrations, it was predicted that 95% of the population lived in areas where the estimated annual mean pm2.5 concentration was higher than 35 g/m(3), and 45% of the population was exposed to pm2.5 >75 g/m(3) for over 100 days in 2014. gw-gbm accurately predicted continuous daily pm2.5 concentrations in china for assessing acute human health effects. (c) 2017 elsevier ltd. all rights reserved.
predicted result:
level 1: CS
level 2:
----------------------------
input data: previous research exploring cognitive biases in bulimia nervosa suggests that attentional biases occur for both food-related and body-related cues. individuals with bulimia were compared to non-bulimic controls on an emotional-stroop task which contained both food-related and body-related cues. results indicated that bulimics (but not controls) demonstrated a cognitive bias for both food-related and body related cues. however, a discrepancy between the two cue-types was observed with body-related cognitive biases showing the most robust effects and food-related cognitive biases being the most strongly associated with the severity of the disorder. the results may have implications for clinical practice as bulimics with an increased cognitive bias for food-related cues indicated increased bulimic disorder severity. (c) 2016 elsevier ltd. all rights reserved.
predicted result:
level 1: Psychology
level 2:
----------------------------
input data: posterior reversible encephalopathy syndrome (pres) is a reversible clinical and neuroradiological syndrome which may appear at any age and characterized by headache, altered consciousness, seizures, and cortical blindness. the exact incidence is still unknown. the most commonly identified causes include hypertensive encephalopathy, eclampsia, and some cytotoxic drugs. vasogenic edema related subcortical white matter lesions, hyperintense on t2a and flair sequences, in a relatively symmetrical pattern especially in the occipital and parietal lobes can be detected on cranial mr imaging. these findings tend to resolve partially or completely with early diagnosis and appropriate treatment. here in, we present a rare case of unilateral pres developed following the treatment with pazopanib, a testicular tumor vascular endothelial growth factor (vegf) inhibitory agent.
predicted result:
level 1: Medical
level 2:
3.结论
相关项目链接:
Paddlenlp之UIE模型实战实体抽取任务【打车数据、快递单】
Paddlenlp之UIE分类模型【以情感倾向分析新闻分类为例】含智能标注方案)
应用实践:分类模型大集成者[PaddleHub、Finetune、prompt]
PaddleNLP基于ERNIR3.0文本分类以中医疗搜索检索词意图分类(KUAKE-QIC)为例【多分类(单标签)】
基于Ernie-3.0 CAIL2019法研杯要素识别多标签分类任务
本项目主要讲解了层次分类任务、以及doccano标注指南(对于多分类多标签问题),和对性能指标的简单探讨,由于需要训练很久暂时就没长时间跑程序,从预测结果看来模型还能更佳精准,就交给后续的你了!
欢迎大家关注我的主页:https://aistudio.baidu.com/aistudio/usercenter
以及博客:https://blog.csdn.net/sinat_39620217?type=blog
以上是关于PaddleNLP基于ERNIR3.0文本分类:WOS数据集为例(层次分类)的主要内容,如果未能解决你的问题,请参考以下文章