Selenium万字长文&&全网最详(上)-王者笔记❤️建议收藏❤️
Posted 孤寒者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Selenium万字长文&&全网最详(上)-王者笔记❤️建议收藏❤️相关的知识,希望对你有一定的参考价值。
目录
- 👻👻相信不少小伙伴们在经历过我的上几篇关于爬虫技术的万字博文的轮番轰炸后,已经可以独立开发出属于自己的爬虫项目!!!——爬虫之路,已然开启!👻👻
💦第一篇之爬虫入坑文;一篇万字博文带你入坑爬虫这条不归路(你还在犹豫什么&抓紧上车) 【❤️熬夜整理&建议收藏❤️】
💦第二篇之爬虫库requests库详解。两万字博文教你python爬虫requests库,看完还不会我把我女朋友都给你【❤️熬夜整理&建议收藏❤️】
💦第三篇之解析库Xpath库详解。万字博文教你python爬虫必备XPath库,看完还不会我把我女朋友都给你【❤️建议收藏系列❤️】
💦第四篇之解析库Beautiful Soup库详解。Python万字博文教你玩透Beautiful Soup库,不信你学不会【❤️建议收藏系列❤️】
- 😬😬但是前几天有粉丝VX问了我这样一个问题:“我在浏览器中通过开发者工具看到的网页源码与我通过requests库爬取下来的网页源码完全不一样!这是怎么一回事啊?通过博主你教的方法都解决不了哎!”😬😬
其实这就涉及到了前端方面的知识,但是本人精力时间有限,所以目前暂只更新了一篇html的必备知识文,关注本博主——后面会加把劲继续更新CSS及javascript相关知识的文哦!
💦身为爬虫人也必须要会的前端知识第一篇之HTML讲解。前端HTML两万字图文大总结,快来看看你会多少!【❤️熬夜整理&建议收藏❤️】
- ⏰⏰关于这个问题,我们先要知道为啥子会出现这种情况然后才能对症下药。首先要知道的是requests获取的都是原始的HTML文档,而浏览器中的页面都是经过JavaScript处理数据后生成的结果,这些数据的来源多种多样,可能是通过Ajax加载的,可能是包含在HTML文档里的,也可能是经过JavaScript和特定算法计算后生成的。 ⏰⏰
对于第一种情况:数据加载是一种异步加载方式,原始的页面最初不会包含某些数据,原始页面加载完后,会再向服务器请求某个接口获取数据,然后数据才被处理从而呈现在网页上,这其实就是发送了一个Ajax请求(这就是JavaScript动态渲染页面的一种情形!);
对于第三种情况:数据加载是通过JavaScript和特定算法计算后生成的,并非原始HTML代码,这其中也并不包含Ajax请求。
- 📻📻原理知道了,下面的问题就是我们到底该如何解决呢?📻📻
|
| 分栏名称 | 传送门 |
|---|---|
| 🎐爬虫难,跟我一起入爬虫坑,爬虫一条龙服务!🎐 | 《入坑Python爬虫》 |
| 🐲Django框架难,跟我一起一条龙教学(附带多个小型项目实战!)🐲 | 《Django框架一条龙》 |
| 🐋Scrapy框架难,跟我一起一条龙教学(附带多个小型项目实战!)🐋 | 《Scrapy框架一条龙》 |
| 🐠Tornado框架难,跟我一起一条龙教学(附带一个完整项目!)🐠 | 《Tornado框架一条龙》 |
| 🐝爬虫——JS渗透;三大验证码(滑块,点触,图形);字体反爬;移动端!🐝 | 《爬虫高级一条龙》 |
- 🔩🔩本篇博文就会带领小伙伴们全面而又细致的学习上述第二种方法——直接使用模拟浏览器运行的方式来解决上面所说的问题!我会尽量把技术文写的通俗易懂/生动有趣,保证每一个想要学习知识&&认认真真读完本文的读者们能够有所获,有所得。当然,如果你读完感觉本文写的还可以,真正学习到了东西,希望给我个「 赞 」 和 「 收藏 」,这个对我很重要,谢谢了!🔩🔩
我们伟大的Python为我们提供了许多模拟浏览器运行的库,其中比较强大&&用的较多的就是Selenium。本篇博文带领小伙伴们走入Selenium的世界!
🎅第一部分——初识Selenium!
🍏1.Selenium是什么?
| Selenium是一个自动化测试工具,利用它可以驱动浏览器执行特定的动作,如点击,下拉等操作,同时还可以获取浏览器当前程序的页面的源代码,做到可见即可爬。对于一些JS动态渲染的界面来说,此种抓取方式非常有效! |
🍒2.运行环境
Selenium测试直接运行在浏览器中,就好像一个真正的用户在操作一样, 支持大部分主流的浏览器,包括IE(7,8,9,10,11),Firefox,Safari,Chrome,Opera等。 我们可以利用它来模拟用户点击访问网站,绕过一些复杂的认证场景 通过selenium+驱动浏览器这种组合可以直接渲染解析js,绕过大部分的参数构造和反爬。
🍓3.安装
本人使用的浏览器是Chrome,没有谷歌浏览器的小伙伴们先自行去应用市场或者官网下载哦!
1️⃣安装selenium库:
直接pip安装(一句命令&&一步到位):
pip install selenium
2️⃣安装ChromeDriver驱动:
(根据浏览器版本安装对应的浏览器驱动)
步骤:
-
获取当前浏览器版本(谷歌为例:帮助里面)
-
访问下载地址 下载对应的driver版本(注意你的浏览器版本和driver驱动版本没有一一对应的版本号,请前往ChromeDriver官网查看确认自己浏览器对应的驱动版本哦!)
-
解压,获取可执行文件:
windows为chromedriver.exe
linux/mac为chromedriver -
chromedriver环境变量配置:
①Windows环境下,需要将chromedriver.exe所在的目录设置为path环境变量中的路径/直接将chromedriver.exe文件拖到Python的Scripts目录下(建议这样做!);
②linux/mac环境下,将chromedriver所在的目录设置到系统的PATH环境值中。 -
验证安装——CMD窗口中输入chromedriver出现如下图所示界面:
🍌4.selenium的作用和工作原理
1️⃣作用:
- 自动化测试,通过它我们可以写出自动化程序,模拟浏览器里操作web界面。 比如点击界面按钮,在文本框中输入文字 等操作。
- 获取信息——从web界面获取信息。 比如招聘网站职位信息,财经网站股票价格信息 等等,然后用程序进行分析处理。
- 官网地址。
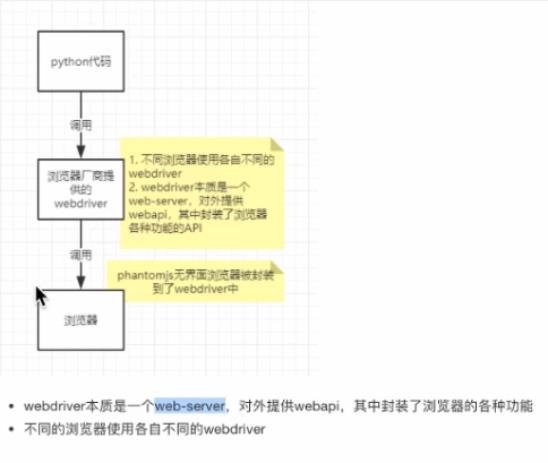
2️⃣工作原理:
(开发使用有头浏览器,部署使用无界面浏览器无界面浏览器phantomjs官方下载地址)。
注意事项:
| 新版本的Selenium已经不再支持phantomjs,原作者也已经放弃维护该项目了。还有在做爬虫的时候尽量不要用这种方法,Selenium+浏览器的组合速度慢,应付不了数据量比较大的爬取以及并发爬取。并且很吃电脑资源。 |
🍠5. 实战例子 之 简单使用:
⛔️①上代码:
from selenium import webdriver # 控制浏览器的模块
import time # 加入睡眠,不然运行的太快了录屏效果不行!
# 声明浏览器对象——如果是火狐浏览器的话:driver = webdriver.Firefos()
driver = webdriver.Chrome() # 获取chrome控制对象——webdriver对象
# 1.向一个url发起请求
driver.get('http://www.baidu.com')
time.sleep(1)
# 2.定位到搜索框标签
input_tag = driver.find_element_by_id('kw')
# 3.往搜索框中输入搜索内容
input_tag.send_keys('猫咪图片')
# 4.定位到百度一下的搜索图标
submit_tag = driver.find_element_by_id('su')
time.sleep(1)
# 5.单击搜索图标
submit_tag.click()
time.sleep(5)
# 6.一定要退出!不退出会有残留进程!!!
driver.quit()
⛔️②代码解析:
- webdriver.Chrome() 如果没有将驱动加入环境变量,则需要在Chrome中加入executable参数,值为下载好的chromedriver文件路径;
- driver.find_element_by_id(‘kw’).send_keys(‘猫咪图片’) 定位id属性值是‘kw’的标签,并向其中输入字符串‘猫咪图片’;
- driver.find_element_by_id(‘su’).click()定位id属性值是su的标签;
- click函数的作用是:触发标签的js的click事件。
⛔️③效果展示:
selenium简单使用!
🎍第二部分——Selenium进阶操作!
🐱1.操作浏览器的常用骚操作:
🚩(1)骚操作及代码实现:
| 浏览器操作 | 代码 |
|---|---|
| 最大化浏览器 | driver.maximize_window() |
| 刷新 | driver.refresh() |
| 后退 | driver.back() |
| 前进 | driver.forward() |
| 设置浏览器大小 | driver.set_window_size(300,300) |
| 设置浏览器位置 | driver.set_window_position(300,200) |
| 关闭浏览器单个窗口,如果只有一个标签页则关闭整个浏览器 | driver.close() |
| 关闭浏览器所有窗口 | driver.quit() |
🚩(2)实战使用:
连续访问三个页面——天猫,淘宝,京东,然后调用back()方法回到第二个页面——淘宝,接下来再调用forward()方法又可以前进到第三个页面——京东!
⚠️①上代码:
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.tmall.com/')
time.sleep(1)
browser.get('https://taobao.com/')
time.sleep(1)
browser.get('https://www.jd.com/')
time.sleep(1)
browser.back()
time.sleep(1)
browser.forward()
time.sleep(1)
browser.close()
⚠️②实现效果:
selenium操作实战
🐹2.元素选取/查找节点:
第一种方法——find_element(s)by_…方法:
⚓️(1)单个节点:
在一个页面中有很多不同的策略可以定位一个元素。我们可以选择最合适的方法去查找元素。Selenium提供了下列的方法:
| 单个元素查找方法 | 作用 |
|---|---|
| find_element_by_xpath() | 通过Xpath查找 |
| find_element_by_class_name() | 通过class属性查找 |
| find_element_by_id() | 通过id属性查找 |
| find_element_by_name() | 通过name属性进行查找 |
| find_element_by_css_selector() | 通过css选择器查找 语法规则 |
| find_element_by_link_text() | 通过链接文本查找 |
| find_element_by_partial_link_text() | 通过链接文本的部分匹配查找 |
| find_element_by_tag_name() | 通过标签名查找 (只有目标元素在当前html中是唯一标签或者是众多定位出来的标签中的第一个的时候才使用!) |
注意:通过上述不管是哪一种方法,其返回的节点类型都是WebElement类型!
⚓️(2)多个节点:
| 上面方法的element加上一个s,则是对应的多个元素的查找方法。 |
如下可知其返回内容是列表类型,列表中每个节点仍然是WebElement类型:
[<selenium.webdriver.remote.webelement.WebElement (session="73974727c0ec09e0b7d57639c3", element="1b33ea80-ba15-91ac-635903f79df2")>,
<selenium.webdriver.remote.webelement.WebElement (session="739747be09cb27c0ecd57639c3", element="1ac2f257-4364-be00-84de883b265d")>]
注意:find_element匹配不到就抛出异常,但是find_elements匹配不到返回空列表!
第二种方法——By对象查找:
| 除了以上的多种查找方式,还有两种私有方法集成了上面的所有的查找方法,让我们更方便的使用! |
| 方法 | 作用 |
|---|---|
| find_element(By.XPATH, ‘//button/span’) | 通过Xpath查找一个 |
| find_elements(By.XPATH, ‘//button/span’) | 通过Xpath查找多个 |
其中的第一个参数可以选择使用查找的方法,By.xxx 使用xxx方式解析,解析方法如下(注意——By对象导入: from selenium.webdriver.common.by import By):
- ID = “id”
- XPATH = “xpath”
- LINK_TEXT = “link text”
- PARTIAL_LINK_TEXT = “partial link text”
- NAME = “name”
- TAG_NAME = “tag name”
- CLASS_NAME = “class name”
- CSS_SELECTOR = “css selector”
🐸3.节点交互:
Selenium可以驱动浏览器来执行一些操作,也就是说可以让浏览器模拟执行一些动作。
🚀(1)常见用法:
| 方法 | 作用 |
|---|---|
| send_keys() | 输入文字 |
| clear() | 清空文字 |
| click() | 点击按钮 |
| submit() | 提交表单 |
🚀(2)示例之骚操作:
# 定位用户名
element=driver.find_element_by_id("userA")
# 输入用户名
element.send_keys("admin1")
# 删除输入的用户名
element.send_keys(Keys.BACK_SPACE)
# 重新输入用户名
element.send_keys("admin_new")
# 全选
element.send_keys(Keys.CONTROL,'a')
# 复制
element.send_keys(Keys.CONTROL,'c')
# 粘贴
driver.find_element_by_id('passwordA').send_keys(Keys.CONTROL,'v')
🐻4.动作链:
👑(1)讲解:
-
在selenium当中除了简单的点击动作外,还有一些稍微复杂的动作,就需要用到ActionChains(动作链)这个子模块来满足我们的需求。
-
ActionChains可以完成复杂一点的页面交互行为,例如元素的拖拽,鼠标移动,悬停行为,内容菜单交互。 它的执行原理就是当调用ActionChains方法的时候不会立即执行,而是将所有的操作暂时储存在一个队列中,当调用perform()方法的时候,会按照队列中放入的先后顺序执行前面的操作。
-
导入ActionChains包:
from selenium.webdriver.common.action_chains import ActionChains
👑(2)方法:
| ActionChains提供的方法 | 作用 |
|---|---|
| click(on_element=None) | 鼠标左键单击传入的元素 |
| double_click(on_element=None) | 双击鼠标左键 |
| context_click(on_element=None) | 点击鼠标右键 |
| click_and_hold(on_element=None) | 点击鼠标左键,按住不放 |
| release(on_element=None) | 在某个元素位置松开鼠标左键 |
| drag_and_drop(source, target) | 拖拽到某个元素然后松开 |
| drag_and_drop_by_offset(source, xoffset, yoffset) | 拖拽到某个坐标然后松开 |
| move_to_element(to_element) | 鼠标移动到某个元素 |
| move_by_offset(xoffset, yoffset) | 移动鼠标到指定的x,y位置 |
| move_to_element_with_offset(to_element, xoffset, yoffset) | 将鼠标移动到距某个元素多少距离的位置 |
| perform() | 执行链中的所有动作 |
👑(3)示例:
示例:
1. 导包:from selenium.webdriver.common.action_chains import ActionChains
2. 实例化ActionChains对象:Action=ActionChains(driver)
3. 调用右键方法:element=Action.context_click(username)
4. 执行:element.perform()
🐮5.提取节点文本内容和属性值:
♥️(1)获取文本内容:
- element.text
通过定位获取的标签对象的 text 属性,获取文本内容。
♥️(2)获取属性值:
- element.get_attribute(‘属性名’)
通过定位获取的标签对象的 get_attribute()函数,传入属性名,来获取属性的值。
🐒6.执行JavaScript代码:
| 对于某些操作:Selenium是没有提供相关的API的。比如:往下滑动页面,但是Selenium伟大的创造者给了我们另一个更为方便的方法——它可以直接模拟运行JavaScript,使用execute_script()方法即可! |
⚽️实战演示:
📌①上代码:
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://baike.baidu.com/item/%E7%99%BE%E5%BA%A6%E6%96%87%E5%BA%93/4928294?fr=aladdin')
# 执行JS代码,滑动网页至最底部!
js = 'window.scrollTo(0, document.body.scrollHeight)'
browser.execute_script(js)
# 执行JS代码,弹窗提示文字!
browser.execute_script('alert("到达最底部啦!")')
time.sleep(3)
📌②效果展示:
滑动
🐫7.标签页/窗口的切换:
💊(1)方法:
用selenium操作浏览器如果需要再打开新的页面,这个时候会有问题,因为我们用selenium操作的是第一个打开的窗口,所以新打开的页面我们是无法去操作的,所以我们要用到切换窗口——即handle切换的方法!
| 方法 | 作用 |
|---|---|
| js = 'window.open(“https://www.baidu.com”);'chrome.execute_script(js) | 打开新标签 |
| window_handles | 获取所有页面窗口的句柄 |
| current_window_handle | 获取当前页面窗口的句柄 |
| switch_to.window(window_name) | 定位页面转到指定的window_name页面 |
注意:Window_handles的顺序并不是浏览器上标签的顺序,尽量避免多标签操作!
💊(2)实战演示:
🔆①思路解析:
窗口切换:
首先要获取所有标签页的窗口句柄;
然后利用窗口句柄切换到句柄指向的标签页。
窗口句柄:指的是指向标签页对象的标识!
解析:
#1.获取当前所有的标签页的句柄构成的列表
current_windows = driver.window_handles
#2.根据标签页句柄列表索引下标进行切换
driver.switch_to.window(windows[0])
🔆②上代码:
import time
from selenium import webdriver
driver=webdriver.Chrome()
driver.get('https://www.baidu.com/')
time.sleep(1)
driver.find_element_by_id('kw').send_keys('python')
time.sleep(1)
driver.find_element_by_id('su').click()
time.sleep(1)
# 通过执行js来新开一个标签页
js = "window.open('https://www.sougou.com');"
driver.execute_script(js)
time.sleep(1)
# 1.获取当前所有的窗口
windows = driver.window_handles
time.sleep(2)
# 2.根据窗口索引进行切换
driver.switch_to.window(windows[0])
time.sleep(2)
driver.switch_to.window(windows[1])
time.sleep(6)
driver.quit()
🔆③效果展示:
窗口切换
🏃8.实战——Selenium过滑块验证码:
🔮第三部分——In The End!

| 从现在做起,坚持下去,一天进步一小点,不久的将来,你会感谢曾经努力的你! |
本博主会持续更新爬虫基础分栏及爬虫实战分栏,认真仔细看完本文的小伙伴们,可以点赞收藏并评论出你们的读后感。并可关注本博主,在今后的日子里阅读更多爬虫文!
如有错误或者言语不恰当的地方可在评论区指出,谢谢!
如转载此文请联系我征得本人同意,并标注出处及本博主名,谢谢 !
以上是关于Selenium万字长文&&全网最详(上)-王者笔记❤️建议收藏❤️的主要内容,如果未能解决你的问题,请参考以下文章
万字长文!全网最全最细MySQL sql语句大全(建议收藏)