数学建模暑期集训13:Pandas实战——处理Excel大数据
Posted Z|Star
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数学建模暑期集训13:Pandas实战——处理Excel大数据相关的知识,希望对你有一定的参考价值。
前言
Pandas是python中用于数据分析的一个强大的库。在数学建模中,往往会遇到大数据的题目,数量级通常在六位数以上。若使用人工处理数据的方法,根本不可能在四天之内处理完,并且电脑内存不够Excel会很卡。
因此,要选大数据的题目,必须要掌握Pandas的一些基本操作。
笔者认为,一个个API学习并不是最有效的方式,最有效的方式是通过实战案例来进行学习。本篇内容将以2020年国赛C题数据为例,进行处理。
1.源数据
为了不污染原数据,我建立一个temp的xlsx文件,复制进需要处理的数据,共210948条数据,数据如下:

2.导入数据
运行下面这段程序就能导入.xlsx文件的数据
import pandas as pd
data = pd.read_excel('temp.xlsx')
print(data)
把数据导入查看结果:

发现系统自动给第一列加了索引。
如果不需要索引,怎么办呢?
只需修改读取语句,增加条件:
data = pd.read_excel('temp.xlsx', index_col=0)
再打印出数据看看:

发现索引果然消失了。
有时候,官方给的数据很多是csv格式。
读取csv文件只需稍微修改读取语句:
data = pd.read_csv('temp.xlsx', index_col=0)
这样,数据就已经加载到编辑器中了。
3.导出数据
导出数据更简单,先前我们将数据读取,存到data这个变量中,导出xlsx数据只需执行下面的语句:
data.to_excel("mydata.xlsx")
执行完后,就可以发现同名文件夹中多了mydata.xlsx文件。
若要导出csv文件,则只需执行:
data.to_csv("mydata.csv")
4.实战环节:自动统计每个企业的运营时间
4.1需求说明
现在总共有123家企业,每一个企业对应着不同的企业代号。我需要统计每一个企业的运营时间,即企业最迟开具的发票时间-最早开具的发票时间。
4.2全部代码
先上代码,之后再逐行解析:
import pandas as pd
data = pd.read_excel('tempdata.xlsx')
temp = data['企业代号'].unique()
a1 = []
a1 = pd.DataFrame(a1)
for num in range(len(temp)):
id = temp[num]
a1.loc[num, "企业代号"] = id
t1 = data[data["企业代号"] == id]
if len(t1['开票日期']) == 0:
day_min = 0
day_max = 0
else:
day_min = min(t1['开票日期'])
day_max = max(t1['开票日期'])
a1.loc[num, '日期(day)'] = day_max - day_min
a1.to_csv('mydata.csv')
4.3代码解析
(1)data = pd.read_excel(‘tempdata.xlsx’) 首先读取了数据存在变量data中;
(2)temp = data[‘企业代号’].unique()
temp用来记录每一家企业的代号。data[‘企业代号’]代表data中“企业代号”这列数据,unique()作用是去重,即若同一家企业代号相同,只记录一次。
(3)a1 = [] a1 = pd.DataFrame(a1)
创建了一个a1变量,该变量结构是DataFrame,DataFrame可以理解为一种特殊的数据结构,即存在内存中的一个工作表。
(4)for num in range(len(temp)):
id = temp[num]
用num做一个循环,id记录企业代号的具体值。
(5) a1.loc[num, “企业代号”] = id
loc是写入DataFrame数据,比如,第一轮循环,num=0,在第0行“企业代号”列标题下写入id的值。
(6) t1 =data[data[“企业代号”] == id]
t1起数据截取功能,意思就是将(data[“企业代号”] ==id)这部分截取出来,比如第一个企业代号是E1,那t1就存取了所有有关E1的数据。
(7)if len(t1[‘开票日期’]) == 0:
由于有些企业不存在发票信息,因此做个单独判断。
(8) day_min = min(t1[‘开票日期’])
day_max = max(t1[‘开票日期’])
day_min记录开票日期最小值,day_max记录开票日期最大值
(9) a1.loc[num, ‘日期(day)’] = day_max - day_min
在a1上开出新列"日期(day)",记录具体数值。
(10)a1.to_csv(‘mydata.csv’) 保存,导出数据。
查看效果:

4.4手动优化效果
由于是日期数据相加减,导出的数据会带有单位days,不想要这个单位,可以通过手动进行数据分列。
在wps中,选择数据->分列,即可完成。
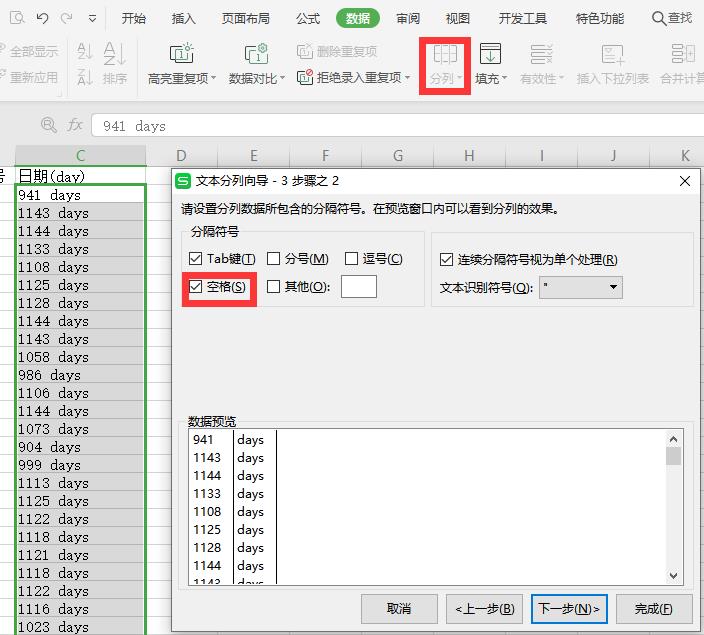
5.实战环节2:自动统计每个企业
5.1需求说明
下面的需求是统计2017年-2020年各企业的发票金额和税收合计。
5.2完整代码
直接放代码,和上面类似。
import numpy as np
import pandas as pd
data = pd.read_excel('temp.xlsx')
temp = data['企业代号'].unique()
a1 = []
a1 = pd.DataFrame(a1)
for num in range(len(temp)):
id = temp[num]
a1.loc[num, "企业代号"] = id
t1 = data[data["企业代号"] == id]
for i in range(12):
if i <= 10:
a2 = t1[(t1['开票日期'] >= '2017-%s' % str(i + 1)) & (t1['开票日期'] < '2017-%s' % str(i + 2))]
a1.loc[num, '2017年%s月进项' % str(i + 1)] = sum(a2['金税'])
else:
a2 = t1[(t1['开票日期'] >= '2017-12') & (t1['开票日期'] < '2018')]
a1.loc[num, '2017年12月进项'] = sum(a2['金税'])
for i in range(12):
if i <= 10:
a2 = t1[(t1['开票日期'] >= '2018-%s' % str(i + 1)) & (t1['开票日期'] < '2018-%s' % str(i + 2))]
a1.loc[num, '2018年%s月进项' % str(i + 1)] = sum(a2['金税'])
else:
a2 = t1[(t1['开票日期'] >= '2018-12') & (t1['开票日期'] < '2019')]
a1.loc[num, '2018年12月进项'] = sum(a2['金税'])
for i in range(12):
if i <= 10:
a2 = t1[(t1['开票日期'] >= '2019-%s' % str(i + 1)) & (t1['开票日期'] < '2019-%s' % str(i + 2))]
a1.loc[num, '2019年%s月进项' % str(i + 1)] = sum(a2['金税'])
else:
a2 = t1[(t1['开票日期'] >= '2019-12') & (t1['开票日期'] < '2020')]
a1.loc[num, '2019年12月进项'] = sum(a2['金税'])
for i in range(12):
if i <= 10:
a2 = t1[(t1['开票日期'] >= '2020-%s' % str(i + 1)) & (t1['开票日期'] < '2020-%s' % str(i + 2))]
a1.loc[num, '2020年%s月进项' % str(i + 1)] = sum(a2['金税'])
else:
a2 = t1[(t1['开票日期'] >= '2020-12') & (t1['开票日期'] < '2021')]
a1.loc[num, '2020年12月进项'] = sum(a2['金税'])
a1.to_csv('second.csv')
6.更多补充
看见评论区有读者指出,分组部分可以用groupby来更方便的实现。
例如:统计每个企业开票日期的最小值和最大值:
import pandas as pd
data = pd.read_excel('temp.xlsx')
g = data.groupby('企业代号')
max1 = g['开票日期'].max()
min1 = g['开票日期'].min()
print(list(max1))
print(list(min1))
打印结果:

注:直接打印groupby是该数据的地址,转化成list可正常显示。
7.总结
本篇内容以需求为导向,没有完整的将Pandas功能一一描述,以后遇到类似情况,将案例再看一遍即可快速上手。
以上是关于数学建模暑期集训13:Pandas实战——处理Excel大数据的主要内容,如果未能解决你的问题,请参考以下文章
数学建模暑期集训11:逻辑回归(Logistic Regression)处理二分类问题