数学建模暑期集训7:TOPSIS法(优劣解距离法)
Posted Z|Star
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数学建模暑期集训7:TOPSIS法(优劣解距离法)相关的知识,希望对你有一定的参考价值。
在本专栏第28篇数学建模学习笔记(二十八)评价类:TOPSIS模型中,简单介绍了TOPSIS模型。本篇内容参照清风数学建模课程,对该部分内容进行重新整理和补充。
C.L.Hwang 和 K.Yoon 于1981年首次提出 TOPSIS (Technique for Order Preference by Similarity to an Ideal Solution),可翻译为逼近理想解排序法,国内常简称为优劣解距离法。
1.指标正向化
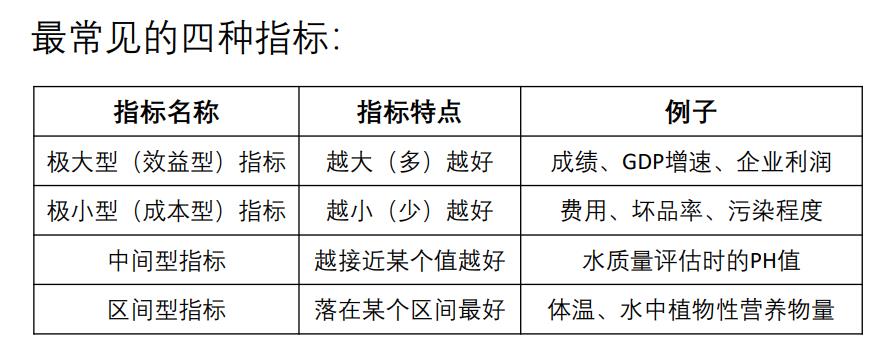
为了方便计算,需要将所有指标均转换成极大型。
1.1极小型->极大型

1.2中间型->极大型

1.3区间型->极大型

2.矩阵标准化
为了消除量纲的影响,需要将所有指标标准化。

3.计算得分并归一化

4.(拓展)增加权重
在计算D+和D-时,每个指标前面系数默认为1,为了考虑不同指标的影响关系,可以增加权重。
权重的增加可以用层次分析法(主观)和熵权法(客观)
可以参见本专栏的往期内容
数学建模学习笔记(三)熵权法Excel实现
数学建模学习笔记(四)层次分析法(AHP)
5.matlab实现
下面是一个交互性强的matlab程序,实际使用可以直接运行。
%自定义函数 Positivization.m
function [posit_x] = Positivization(x,type,i)
% 输入变量有三个:
% x:需要正向化处理的指标对应的原始列向量
% type: 指标的类型(1:极小型, 2:中间型, 3:区间型)
% i: 正在处理的是原始矩阵中的哪一列
% 输出变量posit_x表示:正向化后的列向量
if type == 1 %极小型
disp(['第' num2str(i) '列是极小型,正在正向化'] )
posit_x = Min2Max(x); %调用Min2Max函数来正向化
disp(['第' num2str(i) '列极小型正向化处理完成'] )
disp('~~~~~~~~~~~~~~~~~~~~分界线~~~~~~~~~~~~~~~~~~~~')
elseif type == 2 %中间型
disp(['第' num2str(i) '列是中间型'] )
best = input('请输入最佳的那一个值: ');
posit_x = Mid2Max(x,best);
disp(['第' num2str(i) '列中间型正向化处理完成'] )
disp('~~~~~~~~~~~~~~~~~~~~分界线~~~~~~~~~~~~~~~~~~~~')
elseif type == 3 %区间型
disp(['第' num2str(i) '列是区间型'] )
a = input('请输入区间的下界: ');
b = input('请输入区间的上界: ');
posit_x = Inter2Max(x,a,b);
disp(['第' num2str(i) '列区间型正向化处理完成'] )
disp('~~~~~~~~~~~~~~~~~~~~分界线~~~~~~~~~~~~~~~~~~~~')
else
disp('没有这种类型的指标,请检查Type向量中是否有除了1、2、3之外的其他值')
end
end
主函数(自行输入权重)
%% 第一步:把数据复制到工作区,并将这个矩阵命名为X
% (1)在工作区右键,点击新建(Ctrl+N),输入变量名称为X
% (2)在Excel中复制数据,再回到Excel中右键,点击粘贴Excel数据(Ctrl+Shift+V)
% (3)关掉这个窗口,点击X变量,右键另存为,保存为mat文件(下次就不用复制粘贴了,只需使用load命令即可加载数据)
% (4)注意,代码和数据要放在同一个目录下哦,且Matlab的当前文件夹也要是这个目录。
clear;clc
load data_water_quality.mat
%% 第二步:判断是否需要正向化
[n,m] = size(X);
disp(['共有' num2str(n) '个评价对象, ' num2str(m) '个评价指标'])
Judge = input(['这' num2str(m) '个指标是否需要经过正向化处理,需要请输入1 ,不需要输入0: ']);
if Judge == 1
Position = input('请输入需要正向化处理的指标所在的列,例如第2、3、6三列需要处理,那么你需要输入[2,3,6]: '); %[2,3,4]
disp('请输入需要处理的这些列的指标类型(1:极小型, 2:中间型, 3:区间型) ')
Type = input('例如:第2列是极小型,第3列是区间型,第6列是中间型,就输入[1,3,2]: '); %[2,1,3]
% 注意,Position和Type是两个同维度的行向量
for i = 1 : size(Position,2) %这里需要对这些列分别处理,因此我们需要知道一共要处理的次数,即循环的次数
X(:,Position(i)) = Positivization(X(:,Position(i)),Type(i),Position(i));
% Positivization是我们自己定义的函数,其作用是进行正向化,其一共接收三个参数
% 第一个参数是要正向化处理的那一列向量 X(:,Position(i)) 回顾上一讲的知识,X(:,n)表示取第n列的全部元素
% 第二个参数是对应的这一列的指标类型(1:极小型, 2:中间型, 3:区间型)
% 第三个参数是告诉函数我们正在处理的是原始矩阵中的哪一列
% 该函数有一个返回值,它返回正向化之后的指标,我们可以将其直接赋值给我们原始要处理的那一列向量
end
disp('正向化后的矩阵 X = ')
disp(X)
end
%% 在这里增加是否需要算加权
% % 假如原始数据为:
% A=[1, 2, 3;
% 2, 4, 6]
% % 权重矩阵为:
% B=[ 0.2, 0.5 ,0.3 ]
% % 加权后为:
% C=A .* B
% 0.2000 1.0000 0.9000
% 0.4000 2.0000 1.8000
% 类似的,还有矩阵和向量的点除, 大家可以自己试试计算A ./ B
% 注意,矩阵和向量没有 .- 和 .+ 哦 ,大家可以试试,如果计算A.+B 和 A.-B会报什么错误。
%% 让用户判断是否需要增加权重
disp("请输入是否需要增加权重向量,需要输入1,不需要输入0")
Judge = input('请输入是否需要增加权重: ');
if Judge == 1
disp(['如果你有3个指标,你就需要输入3个权重,例如它们分别为0.25,0.25,0.5, 则你需要输入[0.25,0.25,0.5]']);
weigh = input(['你需要输入' num2str(m) '个权数。' '请以行向量的形式输入这' num2str(m) '个权重: ']);
OK = 0; % 用来判断用户的输入格式是否正确
while OK == 0
if abs(sum(weigh) - 1)<0.000001 && size(weigh,1) == 1 && size(weigh,2) == m % 这里要注意浮点数的运算是不精准的。
OK =1;
else
weigh = input('你输入的有误,请重新输入权重行向量: ');
end
end
else
weigh = ones(1,m) ./ m ; %如果不需要加权重就默认权重都相同,即都为1/m
end
%% 第三步:对正向化后的矩阵进行标准化
Z = X ./ repmat(sum(X.*X) .^ 0.5, n, 1);
disp('标准化矩阵 Z = ')
disp(Z)
%% 第四步:计算与最大值的距离和最小值的距离,并算出得分
D_P = sum([(Z - repmat(max(Z),n,1)) .^ 2 ] .* repmat(weigh,n,1) ,2) .^ 0.5; % D+ 与最大值的距离向量
D_N = sum([(Z - repmat(min(Z),n,1)) .^ 2 ] .* repmat(weigh,n,1) ,2) .^ 0.5; % D- 与最小值的距离向量
S = D_N ./ (D_P+D_N); % 未归一化的得分
disp('最后的得分为:')
stand_S = S / sum(S)
[sorted_S,index] = sort(stand_S ,'descend')
以上是关于数学建模暑期集训7:TOPSIS法(优劣解距离法)的主要内容,如果未能解决你的问题,请参考以下文章